RAG 入门指南:从概念到最小系统搭建
文章目录
- 一、什么是 RAG?核心概念解析
- 1.1 定义:不止是 “检索 + 生成”
- 1.2 技术原理:三组件构成的双阶段架构
- 1.3 技术演进:从基础到模块化
- 二、为什么要用 RAG?解决 LLM 的核心痛点
- 2.1 LLM 的 4 大局限与 RAG 的应对方案
- 2.2 RAG 的 4 个关键优势
- 2.3 适用场景:按风险等级选择
- 三、如何上手 RAG?从工具到 MVP 搭建
- 3.1 必选工具链:按需求选型
- 开发框架(二选一即可)
- 向量数据库(按规模选)
- 其他工具
- 3.2 四步搭建最小可行系统(MVP)
- 步骤 1:数据准备(文档处理)
- 步骤 2:构建索引(向量存储)
- 步骤 3:检索优化(找相关文档)
- 步骤 4:生成集成(LLM 写回答)
- 3.3 新手友好的 “零代码” 方案
- 3.4 进阶方向:如何优化 RAG 性能?
- 总结
- 参考
在大语言模型(LLM)广泛应用的今天,“幻觉输出”“知识过时”“领域适配难” 等问题逐渐凸显。而RAG(Retrieval-Augmented Generation,检索增强生成) 作为融合 “信息检索” 与 “文本生成” 的技术范式,恰好为这些痛点提供了高效解决方案。本文将从基础概念出发,带你理解 RAG 的核心原理、应用价值,并手把手教你搭建第一个 RAG 最小可行系统(MVP)。
一、什么是 RAG?核心概念解析
1.1 定义:不止是 “检索 + 生成”
RAG 的核心逻辑是:在 LLM 生成回答前,先从外部知识库中动态检索与查询相关的信息,将这些信息作为上下文输入 LLM,最终生成更准确、可溯源的内容。
简单来说,RAG 相当于给 LLM“配了一个实时更新的‘参考书库’”——LLM 不再只依赖训练时的静态知识,而是能随时 “查阅资料”,避免无中生有或知识过时。
注意:RAG 的定义会随技术演进拓展,当前表述为最基础、通用的框架。
1.2 技术原理:三组件构成的双阶段架构
RAG 的工作流程可拆解为 “索引构建” 和 “检索生成” 两个阶段,核心包含 3 个组件:

- 索引(Indexing):把非结构化文档(PDF、Word、网页等)“拆碎”“编码”
- 先将文档按语义(如段落)或固定长度切分为小片段(避免信息碎片化);
- 用 “嵌入模型”(如 text-embedding-ada-002)将每个片段转换成向量;
- 把向量存入 “向量数据库”,方便后续快速检索。
- 检索(Retrieval):根据查询找最相关的 “资料”
- 用户输入查询后,先将查询也转换成向量;
- 从向量数据库中,通过 “相似度匹配” 召回 Top-K 个与查询最相关的文档片段(即 “上下文”);
- 可选:结合关键词检索(如 BM25)或重排序模型(如 Cohere Reranker),进一步提升召回质量。
- 生成(Generation):LLM 结合 “资料” 写回答
- 把 “用户查询 + 检索到的上下文” 按固定模板组合成提示词(Prompt);
- 输入 LLM(如 GPT、Claude、Ollama),生成最终回答 —— 此时 LLM 会基于检索到的真实信息输出内容,而非凭空捏造。
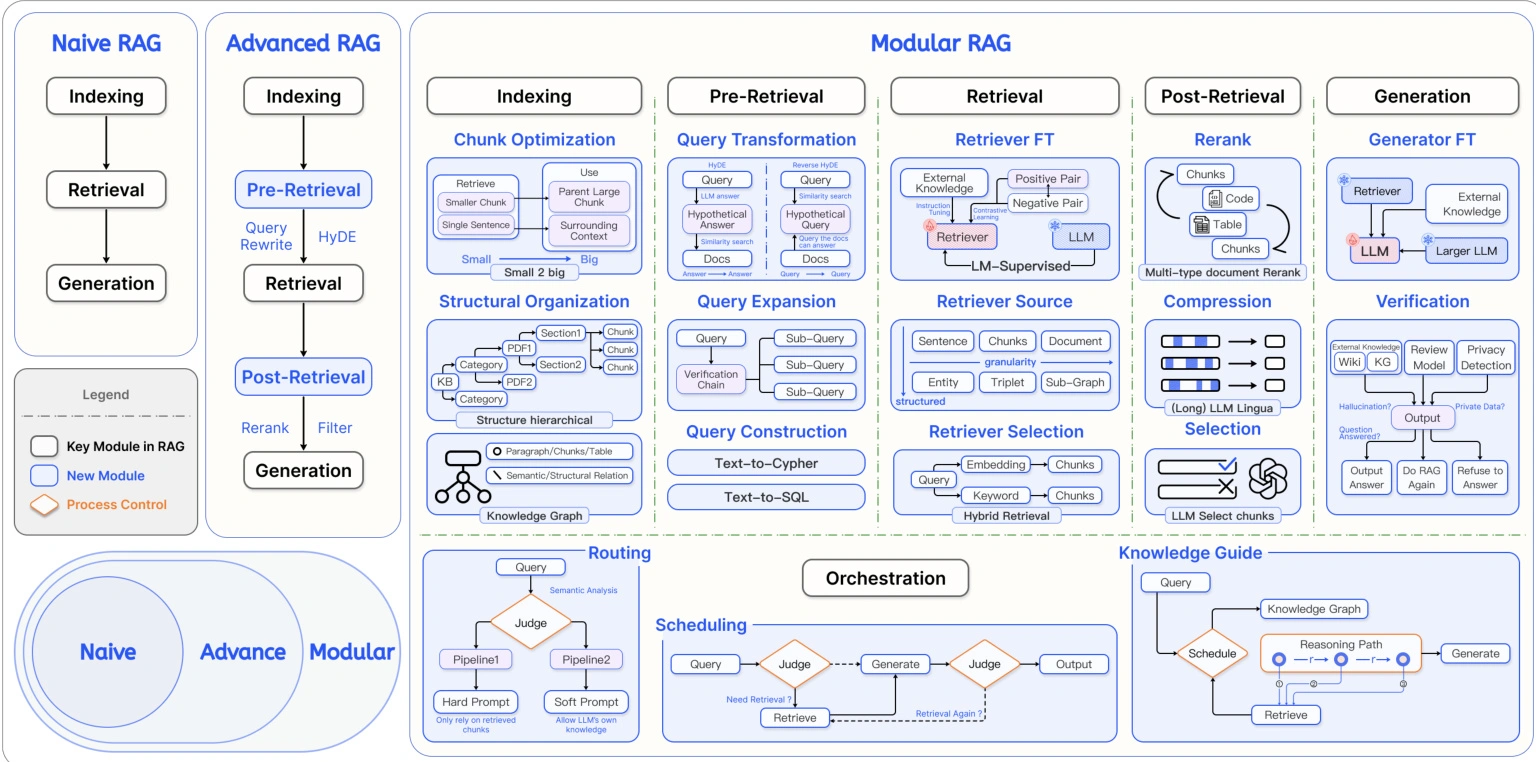
1.3 技术演进:从基础到模块化
RAG 并非单一技术,而是随场景需求不断迭代,按复杂度可分为三级:
| 技术层级 | 核心特征 | 适用场景 |
|---|---|---|
| 初级 RAG | 基础 “索引 - 检索 - 生成” 流程,简单分块 + 基本向量检索 | 个人学习、简单问答(如文档查询) |
| 高级 RAG | 增加数据清洗、元数据优化、多轮检索 | 企业内部知识库、客服问答 |
| 模块化 RAG | 集成搜索引擎、强化学习优化、知识图谱增强 | 复杂业务场景(如医疗咨询、法律分析) |
二、为什么要用 RAG?解决 LLM 的核心痛点
LLM 虽强,但在实际应用中存在明显局限,而 RAG 恰好能针对性解决:
2.1 LLM 的 4 大局限与 RAG 的应对方案
| LLM 的核心问题 | RAG 的解决方案 |
|---|---|
| 静态知识局限 | 外部知识库可独立更新(如新增政策、行业动态),无需重新训练 LLM |
| 幻觉(Hallucination) | 基于真实检索文档生成,减少 “无中生有”,且支持溯源引用 |
| 领域专业性不足 | 接入领域专用知识库(如医疗文献、法律条文),提升专业回答能力 |
| 数据隐私风险 | 知识库可本地化部署,敏感数据无需上传至第三方 LLM 服务 |
2.2 RAG 的 4 个关键优势
- 准确性更高:
不仅能补充 LLM 的知识盲区,还能通过 “引用原始文档” 提升回答可信度 —— 比如法律场景中,RAG 可直接引用法条原文,避免 LLM 曲解法律条款。 - 知识实时性更强:
LLM 的训练数据有 “截止日期”(如 GPT-4 截止到 2023 年 10 月),而 RAG 的知识库可实时更新 —— 比如财经场景中,能随时接入最新股票数据、政策文件。 - 成本效益更优:
反复微调 LLM 的成本极高(需大量数据 + 算力),而 RAG 只需维护知识库,甚至可搭配轻量级 LLM(如 Llama 3 8B)实现接近大模型的效果,降低推理成本。 - 扩展性更好:
支持多源数据集成(文本、表格、图片等),且检索组件可独立优化 —— 比如后续想提升检索速度,只需更换向量数据库,无需改动生成逻辑。
2.3 适用场景:按风险等级选择
RAG 并非 “万能药”,需根据场景风险等级判断适用性:
| 风险等级 | 典型场景 | RAG 使用建议 |
|---|---|---|
| 低风险 | 文档翻译、语法检查、常识问答 | 高可靠,可直接使用 |
| 中风险 | 合同起草、法律咨询、行业报告 | 需结合人工审核(如律师核对合同条款) |
| 高风险 | 证据分析、签证决策、医疗诊断 | 需严格质量控制(如多轮检索 + 专家复核) |
三、如何上手 RAG?从工具到 MVP 搭建
对于新手,无需从零开发,借助成熟工具链可快速搭建 RAG 系统。
3.1 必选工具链:按需求选型
开发框架(二选一即可)
- LangChain:生态最丰富,提供预置的 “RAG 链”(如
rag_chain),支持快速集成 LLM 与向量数据库,适合需要灵活扩展的场景。 - LlamaIndex:专为知识库优化,简化文档分块、嵌入流程,对 “文档理解” 更友好(如处理复杂 PDF 的表格、公式)。
向量数据库(按规模选)
- FAISS:轻量级开源库,无需部署服务,适合小体量数据(如个人项目、万级文档片段)。
- Milvus:开源高性能数据库,支持大规模数据(百万级 + 向量),适合企业级场景。
- Pinecone:云服务向量数据库,无需运维,按使用量计费,适合快速验证想法。
其他工具
- 嵌入模型:开源可选
all-MiniLM-L6-v2(轻量)、bge-large-en(精准);闭源可选 OpenAI 的text-embedding-ada-002。 - LLM:新手推荐 Ollama(本地部署,如 Llama 3)、GPT-3.5(API 调用,成本低)。
3.2 四步搭建最小可行系统(MVP)
以 “个人文档查询” 为例,用 LangChain+FAISS+GPT-3.5 搭建 RAG:
步骤 1:数据准备(文档处理)
-
输入文档:准备 1-2 份 PDF(如技术手册、读书笔记);
-
文档分块:用 LangChain 的
RecursiveCharacterTextSplitter按语义切分(建议每块 200-500 字符,保留上下文连贯性); -
代码示例:
from langchain.text_splitter import RecursiveCharacterTextSplitter# 读取PDF(需先安装PyPDF2) from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("tech_manual.pdf") docs = loader.load()# 分块 text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, # 每块字符数chunk_overlap=50 # 块间重叠(避免语义断裂) ) chunks = text_splitter.split_documents(docs)
步骤 2:构建索引(向量存储)
-
加载嵌入模型:用 OpenAI 的嵌入模型;
-
向量化并存储:将分块转换成向量,存入 FAISS;
-
代码示例:
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import FAISS# 初始化嵌入模型(需设置OpenAI API Key) embeddings = OpenAIEmbeddings()# 构建向量库并保存 db = FAISS.from_documents(chunks, embeddings) db.save_local("faiss_index") # 本地保存,下次可直接加载
步骤 3:检索优化(找相关文档)
-
加载向量库:下次使用时无需重新构建;
-
检索上下文:根据用户查询召回 Top-3 相关片段;
-
代码示例:
# 加载本地向量库 db = FAISS.load_local("faiss_index", embeddings)# 用户查询 query = "如何解决文档分块时的语义断裂问题?"# 检索Top-3相关片段 retriever = db.as_retriever(search_kwargs={"k": 3}) context = retriever.get_relevant_documents(query)
步骤 4:生成集成(LLM 写回答)
-
构建提示词:将 “查询 + 上下文” 组合成模板;
-
调用 LLM 生成回答;
-
代码示例:
from langchain.chat_models import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.chains import LLMChain# 提示词模板(引导LLM基于上下文回答) prompt = PromptTemplate(input_variables=["query", "context"],template="""基于以下上下文,回答用户查询: 上下文:{context} 用户查询:{query} 要求:1. 只基于上下文回答;2. 若上下文无相关信息,直接说“无法回答”;3. 引用上下文时标注来源片段。 """ )# 初始化LLM和链 llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) # temperature=0减少随机性 chain = LLMChain(llm=llm, prompt=prompt)# 生成回答 response = chain.run({"query": query,"context": "\n".join([doc.page_content for doc in context]) }) print(response)
3.3 新手友好的 “零代码” 方案
如果不想写代码,可直接用现成工具快速验证:
- FastGPT:开源知识库平台,上传文档后可视化配置 RAG 流程,支持本地部署;
- LangChain4j Easy RAG:仅需上传文档,自动完成分块、索引、检索,适合快速测试;
- GitHub 模板:如TinyRAG,提供完整示例代码,一键运行。
3.4 进阶方向:如何优化 RAG 性能?
当基础系统跑通后,可从以下维度调优:
- 检索质量:用 “关键词检索 + 向量检索” 混合策略,或加入重排序模型提升上下文相关性;
- 生成质量:优化提示词模板(如增加 “避免幻觉” 的约束),或选用更精准的 LLM;
- 性能优化:对高频查询结果缓存,或用 “分层索引”(高频数据放内存,低频放磁盘);
- 多模态支持:扩展至图像、表格检索(如用 CLIP 模型处理图像,pandas 处理表格)。
总结
RAG 的核心价值在于 “让 LLM 更靠谱”—— 通过外部知识库解决 LLM 的静态知识、幻觉等问题,同时兼顾成本与扩展性。对于新手,从 “文档查询” 这类简单场景入手,借助 LangChain、FAISS 等工具,4 步即可搭建 RAG MVP;后续再根据需求逐步优化检索质量、扩展场景。
随着技术演进,RAG 正从 “基础流程” 向 “模块化架构” 发展,未来还会融合强化学习、知识图谱等技术,进一步提升性能。如果你想深入,可关注学术论文(如 Gao 等人的《Retrieval-Augmented Generation for Large Language Models: A Survey》)或工业界实践(如 LangChain、LlamaIndex 的官方文档)。
参考
[1]: Genesis, J. (2025). Retrieval-Augmented Text Generation: Methods, Challenges, and Applications.
[2]: Gao et al. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey.
[3]: Lewis et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
[4]: Gao et al. (2024). Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
[5]: RAG: Why Does It Matter, What Is It, and Does It Guarantee Accuracy?
[6]: TinyRAG: GitHub项目.