【OpenAI】今日话题: GPT-4o-Audio-Preview 多模态语音交互模型介绍+API的使用教程!
文章目录
- 一、GPT-4o-Audio-Preview的核心特性
- 1. 全模态混合输入输出,打破交互边界
- 2. 情感语义双维度分析,精准捕捉用户情绪
- 3. 实时交互与低延迟响应,媲美人类对话流畅度
- 4. 风格可控的高表现力语音生成
- 二、技术架构深度剖析:端到端流式处理的秘密
- 1. 三层流式处理架构
- 2. 关键技术模块
- 3. 开发接口与调用方式
- 三、GPT-4o-Audio-Preview的独特优势
- 四、获取GPT-4o-Audio-Preview 模型的API
- 方式一:通过“OpenAI官网”获取API Key(国外)
- 步骤1:访问OpenAI官网
- 步骤2:创建或登录账户
- 步骤3:进入API管理界面
- 步骤4:生成新的API Key
- 使用 OpenAI API代码
- 方式二:通过“能用AI”获取API Key(国内)
- 步骤1:访问能用AI工具
- 步骤2:进入API管理界面
- 步骤3:生成新的API Key
- 使用OpenAI API的实战教程
- 1.可以调用的模型
- 2.Python示例代码(基础)
- 3.Python示例代码(高阶)
- 更多文章
2024年,OpenAI重磅推出了多模态语音交互模型——GPT-4o-Audio-Preview,它不仅支持文本与音频的混合输入输出,还在情感识别、实时响应、语音合成等方面实现了多项技术突破,彻底颠覆了传统语音交互体验。今天我将介绍一下 GPT-4o-Audio-Preview 多模态语音交互模型和API的使用教程!

一、GPT-4o-Audio-Preview的核心特性
1. 全模态混合输入输出,打破交互边界
GPT-4o-Audio-Preview支持文本和音频的任意组合输入,输出形式也可以是文本、语音,甚至两者同时出现。举个例子,用户在客服场景中既可以发送语音指令,也能输入文字查询,模型会根据上下文智能生成自然流畅的语音回复或结构化文本,大幅提升交互的灵活性和自然度。
2. 情感语义双维度分析,精准捕捉用户情绪
模型利用卷积神经网络(CNN)提取音频的声学特征,再结合Transformer架构进行深度语义理解,能够识别语音中的情感倾向(如愤怒、喜悦)、语调变化(升调、降调)以及重音位置。这意味着它不仅“听懂”了你说什么,更能“感受到”你说话时的情绪波动,为客服体验和用户满意度提升提供了强大支持。
3. 实时交互与低延迟响应,媲美人类对话流畅度
采用流式处理技术,模型实现了“边听边说”的实时交互,首包响应延迟低至100毫秒,全链路峰值响应延迟仅800毫秒,接近人类对话的自然节奏。特别是在车载语音助手场景中,驾驶员可以无缝与系统对话,极大提升驾驶安全和便利性。
4. 风格可控的高表现力语音生成
GPT-4o-Audio-Preview支持通过prompt控制语音的音色、语速、语调,能够模拟不同角色的语音风格,比如客服、教师、朋友等,满足虚拟主播、智能助理等多样化需求。端到端训练架构避免了传统ASR+TTS级联模型的误差累积,语音自然度达到4.5分(满分5分),听感极佳。
二、技术架构深度剖析:端到端流式处理的秘密
1. 三层流式处理架构
- Audio Encoder:12层CNN+6层Transformer,将音频信号转为声学特征向量,支持8kHz-48kHz多格式音频。
- GPT-4o LLM:基于1750亿参数Transformer,支持最长3000秒上下文,融合音频特征与文本token。
- Audio Head:流式语音生成器+风格控制模块,输出WAV、MP3等格式,支持多样化语音风格。
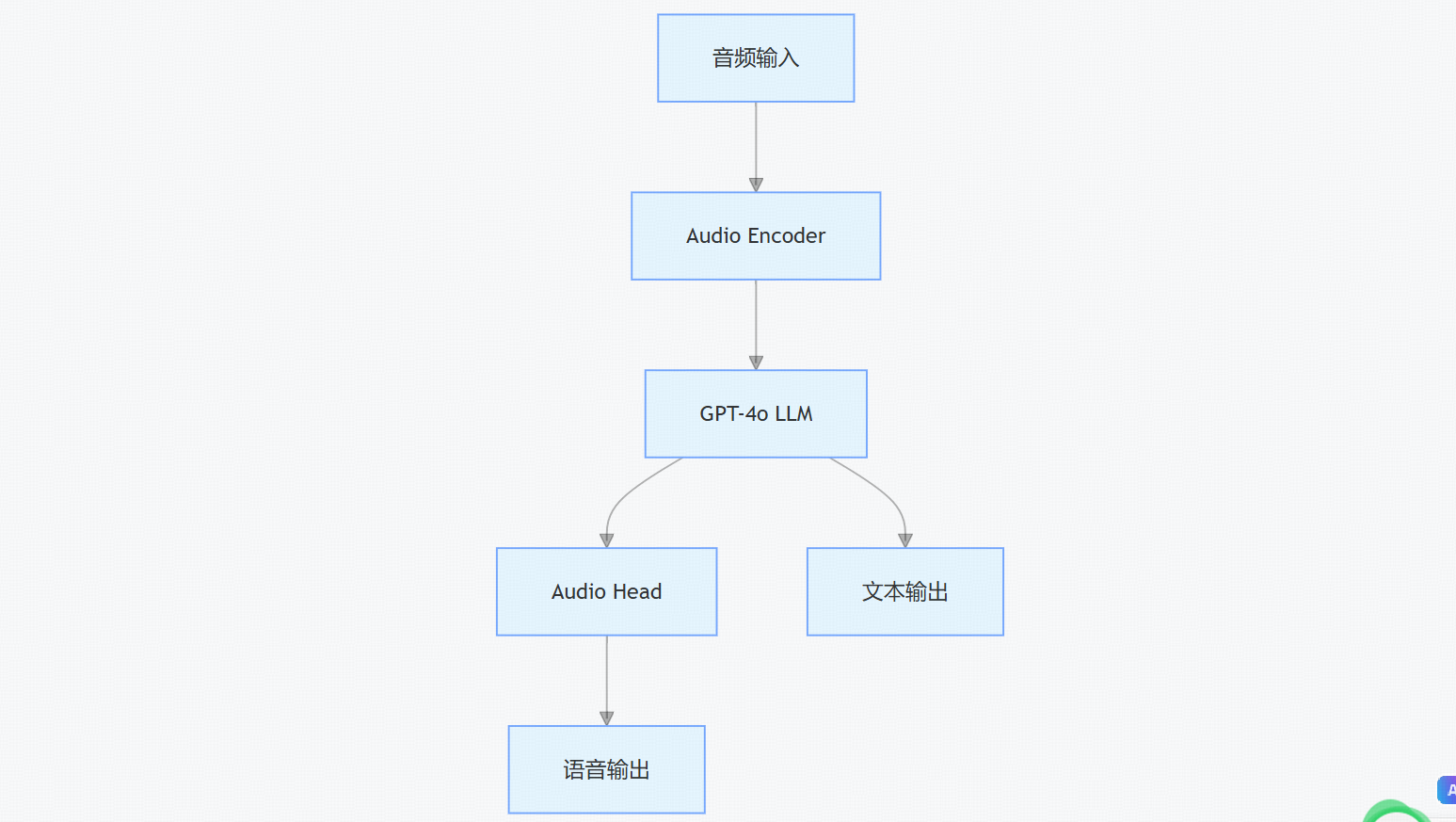
2. 关键技术模块
- Duplex交互模块:实时监测用户语音状态,动态调整响应策略,实现自然对话轮次切换。
- Style CoT技术:引入思维链机制,先预判语音风格token,再融入生成过程,提升风格一致性和多样性。
- 安全防护机制:内置深度伪造检测和敏感内容过滤,保障用户隐私和数据安全。
3. 开发接口与调用方式
通过OpenAI Chat Completions API调用,支持音频格式、音色、语速等参数配置,支持流式响应和动态调整,极大方便开发者集成。
三、GPT-4o-Audio-Preview的独特优势
| 维度 | GPT-4o-Audio-Preview | Whisper | Realtime API | MindGPT-4o-Audio |
|---|---|---|---|---|
| 核心定位 | 多模态交互模型 | 专业语音识别 | 通用实时数据处理 | 车载场景深度优化 |
| 输入类型 | 文本+音频混合输入 | 纯音频输入 | 纯音频输入输出 | 文本+音频混合输入 |
| 输出能力 | 语音+文本混合输出 | 仅文本转录 | 仅文本转录 | 语音+文本混合输出 |
| 情感分析 | 支持语义与情感双维度 | 基础声学特征 | 基础语音转写 | 支持情感分析 |
| 典型场景 | 智能客服、实时翻译 | 语音转写、会议记录 | 实时语音翻译 | 车载语音助手 |
此外,GPT-4o-Audio-Preview采用端到端训练架构,显著降低误差率(5%以内),响应速度提升至400-600毫秒,远优于传统ASR+TTS级联模型。
四、获取GPT-4o-Audio-Preview 模型的API
方式一:通过“OpenAI官网”获取API Key(国外)
步骤1:访问OpenAI官网
在浏览器中输入OpenAI官网的地址,进入官方网站主页。
https://www.openai.com
步骤2:创建或登录账户
- 点击右上角的“Sign Up”进行注册,或选择“Login”登录已有账户。
- 完成相关的账户信息填写和验证,确保账户的安全性。
步骤3:进入API管理界面
登录后,导航至“API Keys”部分,通常位于用户中心或设置页面中。
步骤4:生成新的API Key
- 在API Keys页面,点击“Create new key”按钮。
- 按照提示完成API Key的创建过程,并将生成的Key妥善保存在安全的地方,避免泄露。🔒

使用 OpenAI API代码
现在你已经拥有了 API Key 并完成了充值,接下来是如何在你的项目中使用 GPT-4.0 API。以下是一个简单的 Python 示例,展示如何调用 API 生成文本:
import openai
import os# 设置 API Key
openai.api_key = os.getenv("OPENAI_API_KEY")# 调用 GPT-4.0 API
response = openai.Completion.create(model="gpt-4o-audio-preview",prompt="鲁迅与周树人的关系。",max_tokens=100
)# 打印响应内容
print(response.choices[0].text.strip())
方式二:通过“能用AI”获取API Key(国内)
针对国内用户,由于部分海外服务访问限制,可以通过国内平台“能用AI”获取API Key。
步骤1:访问能用AI工具
在浏览器中打开能用AI进入主页
https://ai.nengyongai.cn/register?aff=PEeJ
步骤2:进入API管理界面
登录后,导航至API管理页面。
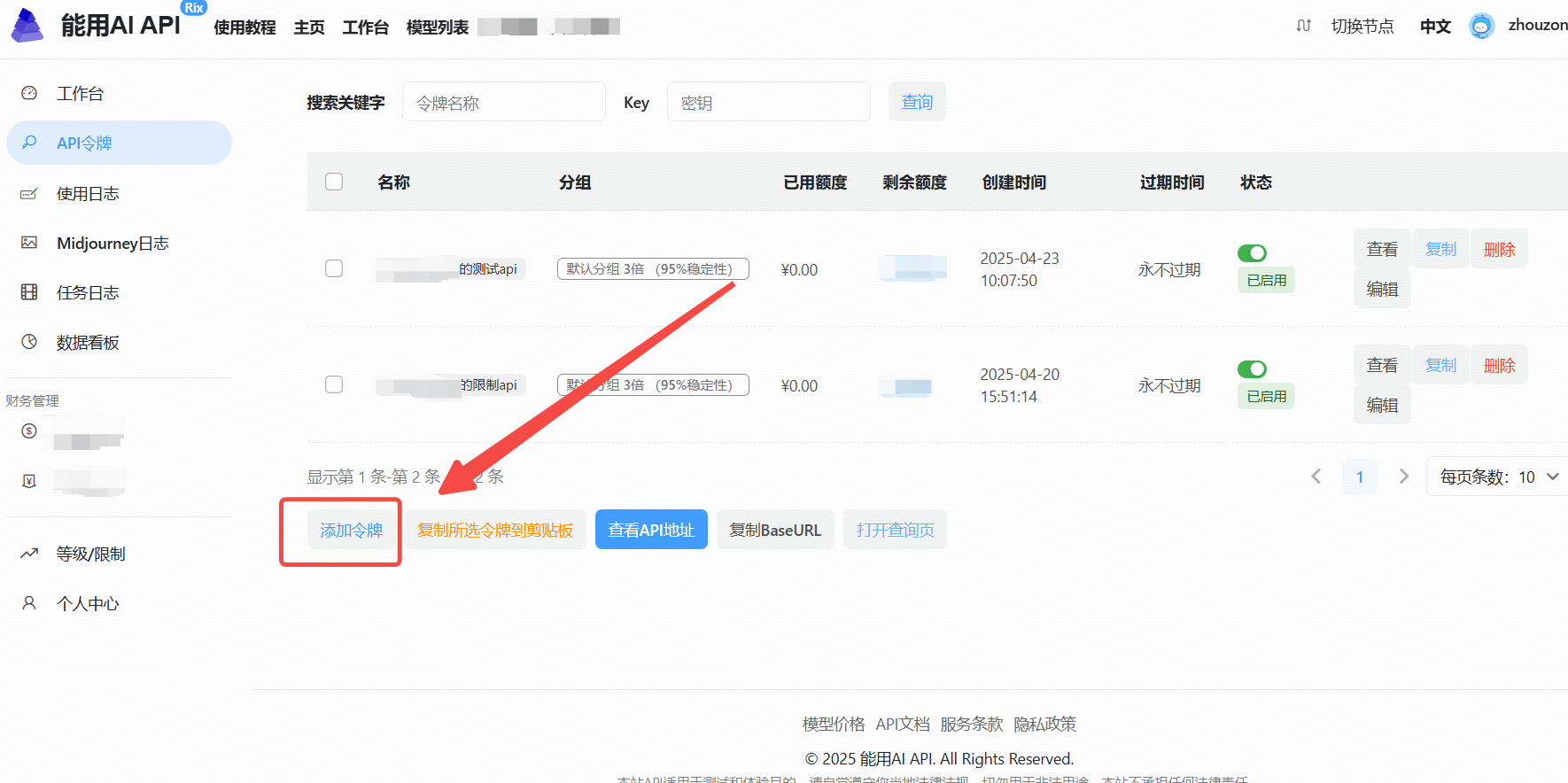
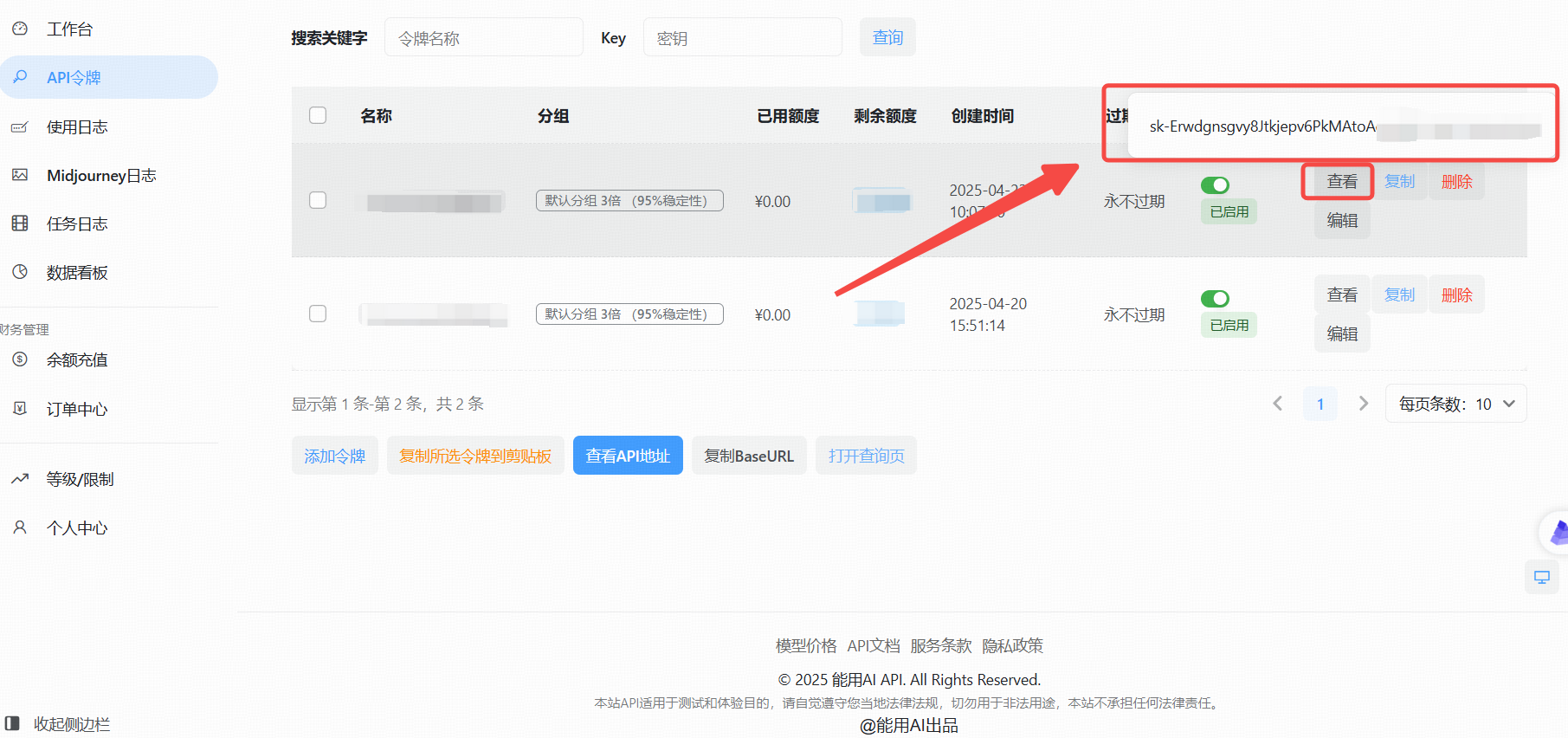
步骤3:生成新的API Key
- 点击“添加令牌”按钮。
- 创建成功后,点击“查看KEY”按钮,获取你的API Key。
使用OpenAI API的实战教程
拥有了API Key后,接下来就是如何在你的项目中调用OpenAI API了。以下以Python为例,详细展示如何进行调用。
1.可以调用的模型
gpt-3.5-turbo
gpt-3.5-turbo-1106
gpt-3.5-turbo-0125
gpt-3.5-16K
gpt-4
gpt-4-1106-preview
gpt-4-0125-preview
gpt-4-1106-vision-preview
gpt-4-turbo-2024-04-09
gpt-4o-2024-05-13
gpt-4-32K
gpt-4o-audio-preview
claude-2
claude-3-opus-20240229
claude-3-sonnet-20240229
等等
2.Python示例代码(基础)
基本使用:直接调用,没有设置系统提示词的代码
from openai import OpenAI
client = OpenAI(api_key="这里是能用AI的api_key",base_url="https://ai.nengyongai.cn/v1"
)response = client.chat.completions.create(messages=[# 把用户提示词传进来content{'role': 'user', 'content': "鲁迅为什么打周树人?"},],model='gpt-4', # 上面写了可以调用的模型stream=True # 一定要设置True
)for chunk in response:print(chunk.choices[0].delta.content, end="", flush=True)
在这里插入代码片
3.Python示例代码(高阶)
进阶代码:根据用户反馈的问题,用GPT进行问题分类
from openai import OpenAI# 创建OpenAI客户端
client = OpenAI(api_key="your_api_key", # 你自己创建创建的Keybase_url="https://ai.nengyongai.cn/v1"
)def api(content):print()# 这里是系统提示词sysContent = f"请对下面的内容进行分类,并且描述出对应分类的理由。你只需要根据用户的内容输出下面几种类型:bug类型,用户体验问题,用户吐槽." \f"输出格式:[类型]-[问题:{content}]-[分析的理由]"response = client.chat.completions.create(messages=[# 把系统提示词传进来sysContent{'role': 'system', 'content': sysContent},# 把用户提示词传进来content{'role': 'user', 'content': content},],# 这是模型model='gpt-4', # 上面写了可以调用的模型stream=True)for chunk in response:print(chunk.choices[0].delta.content, end="", flush=True)if __name__ == '__main__':content = "这个页面不太好看"api(content)

通过这段代码,你可以轻松地与GPT-4o-Audio-Preview模型进行交互,获取所需的文本内容。✨
更多文章
【IDER、PyCharm】免费AI编程工具完整教程:ChatGPT Free - Support Key call AI GPT-o1 Claude3.5
【VScode】VSCode中的智能编程利器,全面揭秘ChatMoss & ChatGPT中文版