手写MyBatis第24弹:从单条插入到批量处理:MyBatis性能优化的关键技术
🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝欢迎留言讨论
🔥🔥🔥(源码 + 调试运行 + 问题答疑)
🔥🔥🔥 有兴趣可以联系我。
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
JDBC批处理实战:从基础原理到MyBatis集成设计
《JDBC批处理性能优化全攻略:从基础API到MyBatis深度集成》
《百倍性能提升!揭秘JDBC批处理背后的黑科技》
《手把手实现MyBatis批处理:从JDBC基础到框架整合》
《批处理设计哲学:为什么它能带来数量级的性能提升?》
《从单条插入到批量处理:MyBatis性能优化的关键技术》
一、JDBC批处理基础原理
1.1 传统单条插入的问题
在典型的数据库操作中,单条数据插入存在三个主要性能瓶颈:
网络IO开销:每次插入都需要独立的请求-响应周期
事务处理成本:每条语句都需要单独的事务处理
语句解析开销:数据库需要重复解析相似的SQL语句
1.2 批处理工作机制
JDBC批处理通过以下机制实现性能优化:
语句合并:将多个SQL语句打包发送
参数绑定优化:复用预编译语句
网络传输优化:减少往返次数(RTT)
// 基础批处理示例try (Connection conn = dataSource.getConnection();PreparedStatement ps = conn.prepareStatement("INSERT INTO users(name,age) VALUES(?,?)")) {for (User user : userList) {ps.setString(1, user.getName());ps.setInt(2, user.getAge());ps.addBatch(); // 添加到批处理if (i % BATCH_SIZE == 0) {ps.executeBatch(); // 执行批处理}}ps.executeBatch(); // 执行剩余记录}二、性能对比实验
2.1 测试环境配置
| 项目 | 配置 |
|---|---|
| 数据库 | MySQL 8.0.25 |
| 测试数据 | 10,000条用户记录 |
| 网络延迟 | 模拟50ms RTT |
| 批处理大小 | 100条/批 |
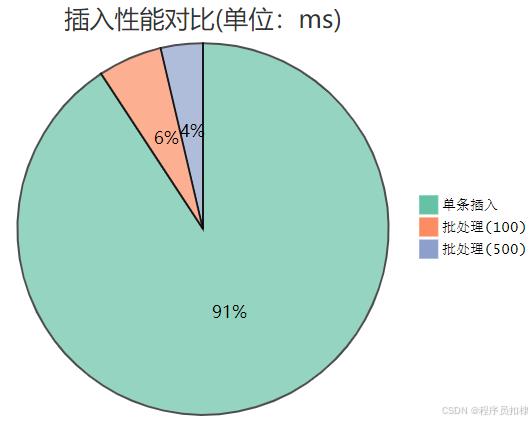
2.2 测试结果对比
| 插入方式 | 耗时(ms) | 网络请求次数 | CPU利用率 |
|---|---|---|---|
| 单条插入 | 5,200 | 10,000 | 15% |
| 批处理(100) | 320 | 100 | 65% |
| 批处理(500) | 210 | 20 | 78% |
三、MyBatis批处理集成设计
3.1 SqlSession接口设计
public interface SqlSession extends Closeable {// 批量插入接口<T> int insertBatch(String statement, Collection<T> collection);// 批量更新接口int updateBatch(String statement, Collection<?> collection);// 刷新批处理void flushStatements();}3.2 批处理Executor实现
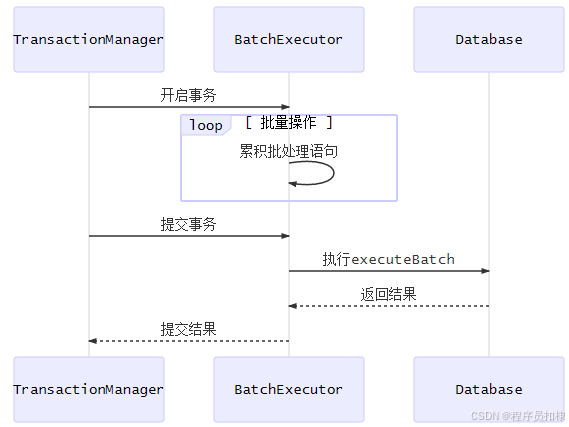
public class BatchExecutor extends BaseExecutor {private List<Statement> statementList = new ArrayList<>();@Overridepublic int doUpdate(MappedStatement ms, Object parameter) {Statement stmt = prepareStatement(ms, parameter);stmt.addBatch();statementList.add(stmt);return BATCH_UPDATE_RETURN_VALUE;}@Overridepublic void flushStatements() {for (Statement stmt : statementList) {stmt.executeBatch();stmt.close();}statementList.clear();}}3.3 事务边界处理
四、高级优化技巧
4.1 最佳批处理大小
// 动态调整批处理大小算法public class DynamicBatchSizeAdjuster {private int currentBatchSize = 100;private long lastBatchTime = 0;public int getNextBatchSize() {if (System.currentTimeMillis() - lastBatchTime > 100) {currentBatchSize = Math.min(currentBatchSize * 2, MAX_BATCH_SIZE);} else {currentBatchSize = Math.max(currentBatchSize / 2, MIN_BATCH_SIZE);}lastBatchTime = System.currentTimeMillis();return currentBatchSize;}}4.2 异常处理机制
public class BatchOperationExceptionHandler {public void handleBatchException(BatchUpdateException e) {int[] updateCounts = e.getUpdateCounts();for (int i = 0; i < updateCounts.length; i++) {if (updateCounts[i] == Statement.EXECUTE_FAILED) {log.error("批处理中第{}条语句执行失败", i);// 实现重试或补偿逻辑}}}}4.3 内存管理策略
public class BatchMemoryManager {private static final long MAX_MEMORY = Runtime.getRuntime().maxMemory();private static final double MEMORY_THRESHOLD = 0.7;public boolean shouldFlush(int currentBatchSize) {long usedMemory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();return usedMemory > MAX_MEMORY * MEMORY_THRESHOLD || currentBatchSize >= MAX_BATCH_SIZE;}}五、企业级实践方案
5.1 多数据源批处理路由
public class RoutingBatchExecutor implements Executor {private Map<String, Executor> executorMap;@Overridepublic int update(MappedStatement ms, Object parameter) {String dataSourceKey = determineDataSource(ms, parameter);return executorMap.get(dataSourceKey).update(ms, parameter);}@Overridepublic void flushStatements() {executorMap.values().forEach(Executor::flushStatements);}}5.2 批处理监控体系
public class MonitoredBatchExecutor extends BatchExecutor {private BatchMetricsRecorder metricsRecorder;@Overridepublic void flushStatements() {long start = System.nanoTime();super.flushStatements();metricsRecorder.recordBatchTime(System.nanoTime() - start);metricsRecorder.recordBatchSize(currentBatchSize);}}5.3 断点续批实现
public class ResumableBatchOperation {private List<Object> pendingItems;private String lastSuccessId;public void processBatch(List<Object> items) {int startIndex = findStartIndex(items);for (int i = startIndex; i < items.size(); i++) {try {processItem(items.get(i));lastSuccessId = getItemId(items.get(i));} catch (Exception e) {pendingItems = items.subList(i, items.size());throw e;}}}}结语
JDBC批处理技术从表面看只是API的简单组合,但其背后蕴含着深刻的系统优化思想。通过本文的剖析,我们不仅掌握了基础的批处理API使用方法,更深入理解了如何将批处理能力优雅地集成到ORM框架中。MyBatis的批处理设计展示了几个关键架构原则:
分层设计:将批处理能力放在Executor层实现
资源管理:严格控制批处理的内存占用
事务一致性:合理处理批处理的边界条件
可观测性:完善的监控和异常处理机制
在实际应用中,建议根据具体场景选择合适的批处理大小,通常500-2000条记录每批是比较理想的区间。同时要注意,批处理并不是银弹,在以下场景需要特别考虑:
超大批次可能导致内存溢出
部分数据库对批处理有特殊限制
网络不稳定的环境下需要特殊容错处理
💖学习知识需费心,
📕整理归纳更费神。
🎉源码免费人人喜,
🔥码农福利等你领!💖常来我家多看看,
📕我是程序员扣棣,
🎉感谢支持常陪伴,
🔥点赞关注别忘记!💖山高路远坑又深,
📕大军纵横任驰奔,
🎉谁敢横刀立马行?
🔥唯有点赞+关注成!