【Virtual Globe 渲染技术笔记】8 顶点变换精度
顶点变换精度
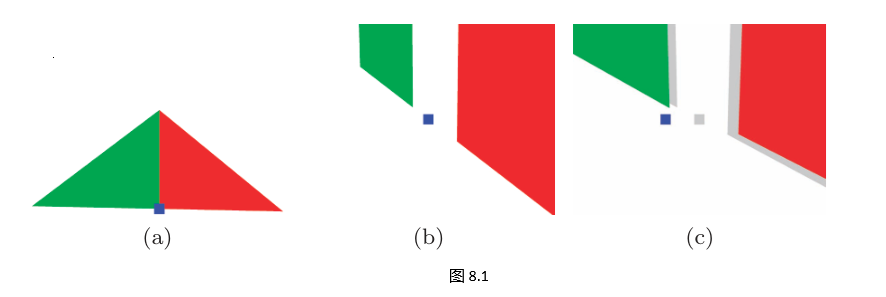
考虑一个简单的场景:原点处一个点,以及两个三角形,都位于平面 x = 0,间距 1 m(图 8.1(a)(a)(a))。
当相机拉近时,我们期望它们看起来共面(图 8.1(b)(b)(b))。
如果把它们平移到 x = 6 378 137 m(地球赤道半径),再拉近,就会出现抖动(jitter):点和三角形不再共面,而是在视图中“蹦跳”(图 8.1(c)(c)(c))。
抖动源于 32 位浮点数对大数值(如 6 378 137)精度不足。由于 WGS84 坐标通常也是这种量级,抖动成为虚拟地球必须解决的问题。
—
8.1 抖动解释
8.1.1 浮点舍入误差
- 32 位单精度约 7 位十进制有效数字;64 位双精度约 16 位。
- 大数值之间的可表示间隔变大,如 17 000 000 m 附近,相邻数相差 2 m。
- 大、小数相加时,小数会丢失低位精度,误差累积。
8.1.2 抖动的根本原因
以点 (6 378 137, 0, 0) 为例,当相机距其 800 m 时,视图矩阵 V 与投影矩阵 P 的乘积 MVP 第四列会出现极大数值。
MVP=(2.171.770.00−13844652.950.76−0.943.53−4867968.95−0.600.730.323810548.18−0.600.730.323810548.19)\mathbf{MVP} = \begin{pmatrix}
2.17 & 1.77 & 0.00 & -13844652.95 \\
0.76 & -0.94 & 3.53 & -4867968.95 \\
-0.60 & 0.73 & 0.32 & 3810548.18 \\
-0.60 & 0.73 & 0.32 & 3810548.19
\end{pmatrix}MVP=2.170.76−0.60−0.601.77−0.940.730.730.003.530.320.32−13844652.95−4867968.953810548.183810548.19
CPU 用 64 位计算 MVP,但传入顶点着色器时转为 32 位,导致舍入误差。顶点着色器再用 32 位 MVP 乘以顶点坐标,误差放大,最终使裁剪坐标出现抖动。
抖动视距相关:
- 拉近时,像素对应世界空间尺寸小,误差>1 像素,可见;
- 拉远时,像素覆盖大区域,误差<1 像素,不可见。
8.1.3 坐标缩放为何无效
把坐标整体缩小 637837 倍,虽让数值靠近 1,但所需精度也同步缩小;32 位浮点间距仍无法满足厘米级要求,抖动依旧。
8.2 相对于中心(RTC)
思路:把几何体顶点转成以自身包围盒中心为原点的小坐标,再在 CPU 用 64 位重新计算 MV 的平移列。
- 计算包围盒中心
centerWGS84; - CPU 用 64 位求
centerEye = MV * centerWGS84; - 构造
MV_RTC,把MV第四列改为centerEye; - 传入顶点着色器的顶点坐标为
p_local = p_WGS84 - centerWGS84。
优点:
- 顶点坐标、矩阵平移值都很小,32 位足够;
- 代码仅几行,CPU 开销低。
缺点:
- 适用于尺寸 ≤ 131 km(1 cm 精度) 的对象;
- 大型对象需拆分为多个中心,增加 Draw Call。
8.3 CPU 相对于眼(CPU RTE)
思路:所有顶点以相机眼为原点,CPU 每帧用 64 位计算:
p_RTE = p_WGS84 - eyeWGS84
然后以 32 位写入动态顶点缓冲。
实现:
- 把
MV平移列清零得MV_RTE; - 每帧更新全部顶点(静态对象也“动”了);
- 其他属性仍可用静态缓冲。
优点:
- 精度最高,无尺寸限制;
- 所有对象共享同一
MV_RTE,批处理友好。
缺点:
- 每帧 CPU 需遍历所有顶点,显存/总线负担大;
- 静态对象失去静态缓冲优势。
8.4 GPU 相对于眼(GPU RTE)
思路:把 64 位坐标编码为两个 32 位浮点(high/low),在顶点着色器里完成 p_RTE = p_high - eye_high + p_low - eye_low,避免 CPU 每帧重算。
8.4.1 精度与实现
-
Ohlarik 编码:
- high:39 位整数 + 16 位步进;
- low:7 位小数。
误差 < 1.35 cm,足够虚拟地球。
-
DSFUN90 编码(Knuth):
- high = float§;
- low = p - float§。
精度接近真 64 位,但顶点着色器指令更多(8 减 4 加)。
8.4.2 精度 LOD(Precision LOD)
- 远视角:仅使用 high(RTW(Reative to World) 方式),节省一半顶点内存;
- 近视角:同时用 high+low(DSFUN90),提供全精度;
- 可动态创建 low 缓冲,按需节省显存。
8.5 推荐方案
| 场景 | 推荐算法 |
|---|---|
| 通用、静态几何 | GPU RTE DSFUN90(简单、无抖动) |
| 小模型/建筑 (<131 km) | RTC(内存省一半) |
| 高度动态几何 | CPU RTE(CPU 已频繁更新,额外开销小) |
| 大静态几何 | GPU RTE DSFUN90(避免 RTC 拆分) |
| 混合策略 | 远 RTC + 近 GPU RTE(或 Precision LOD) |
Patrick 的反思:
早期 STK 用 CPU RTE;2008 年为利用 GPU 并行,改 GPU RTE。
曾尝试 RTC/GPU RTE 混合,因拆分逻辑复杂,最终倾向统一 GPU RTE,以代码简洁优先。
结论
- 抖动根源:32 位浮点在大坐标、近距离下精度不足;
- 解决手段:把顶点或矩阵“变小”——RTC、CPU RTE、GPU RTE 均围绕这一点;
- 选择依据:对象尺寸、动态性、内存预算、开发复杂度。