测试18种RAG技术,找出最优方案(四)
HyDE
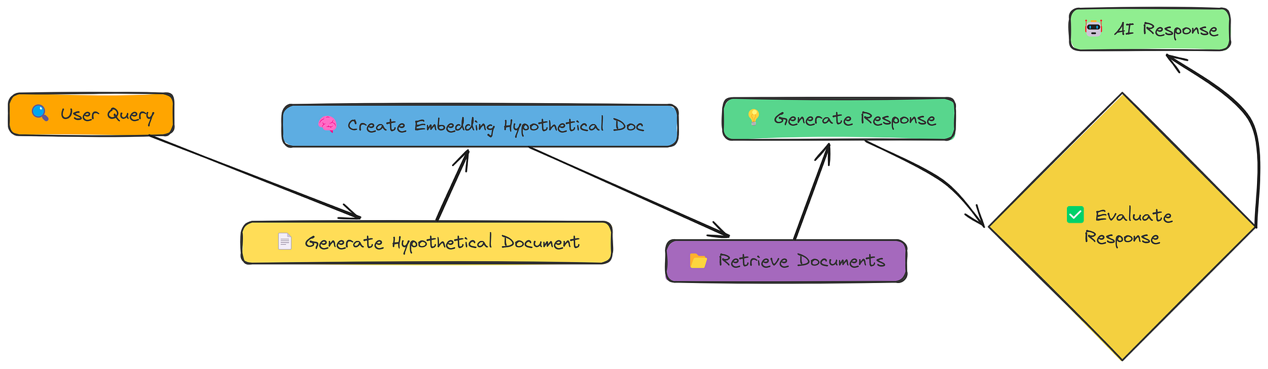
到目前为止,我们一直在直接对用户的查询或其转换版本进行嵌入处理。HyDE(Hypothetical Document Embedding,假设文档嵌入)则采用了不同的方法。它不对查询进行嵌入,而是对一个能回答该查询的假设文档进行嵌入。
HyDE工作流程
流程如下:
生成假设文档:使用LLM创建一个(若存在的话)能回答该查询的文档。
对假设文档进行嵌入:为这个假设文档创建嵌入,而不是原始查询。
检索:找到与假设文档嵌入相似的文档。
生成:使用检索到的文档(不是假设的那个!)来回答查询。
其核心思想是,一个完整的文档,即使是假设的,也比一个简短的查询具有更丰富的语义表达。这有助于弥合查询与嵌入空间中的文档之间的差距。
让我们看看它是如何工作的。首先,我们需要一个生成假设文档的函数。
我们使用generate_hypothetical_document来实现:
def generate_hypothetical_document(query, desired_length=1000):"""生成一个能回答该查询的假设文档。"""# 定义系统提示,指导模型如何生成文档system_prompt = f"""你是一名专业的文档创作者。给定一个问题,生成一份详细的文档来直接回答这个问题。该文档长度应约为{desired_length}个字符,并且要对该问题提供深入、翔实的回答。撰写时要让这份文档看起来像是来自该主题的权威来源。包含具体的细节、事实和解释。不要提及这是一份假设文档——直接撰写内容即可。"""# 定义包含查询的用户提示user_prompt = f"问题:{query}\n\n生成一份能完整回答该问题的文档:"# 向OpenAI API请求生成假设文档response = client.chat.completions.create(model="meta-llama/Llama-3.2-3B-Instruct", # 指定要使用的模型messages=[{"role": "system", "content": system_prompt}, # 指导助手的系统消息{"role": "user", "content": user_prompt} # 包含查询的用户消息],temperature=0.1 # 设置响应生成的温度参数)# 返回生成的文档内容return response.choices[0].message.content这个函数接收查询,并使用LLM虚构一个能回答该查询的文档。
现在,让我们将所有内容整合到hyde_rag函数中:
def hyde_rag(query, vector_store, k=5, should_generate_response=True):"""使用假设文档嵌入(Hypothetical Document Embedding)执行RAG。"""print(f"\n=== 使用HyDE处理查询:{query} ===\n")# 步骤1:生成能回答该查询的假设文档print("生成假设文档...")hypothetical_doc = generate_hypothetical_document(query)print(f"生成的假设文档长度为{len(hypothetical_doc)}个字符")# 步骤2:为假设文档创建嵌入print("为假设文档创建嵌入...")hypothetical_embedding = create_embeddings([hypothetical_doc])[0]# 步骤3:基于假设文档检索相似的文本块print(f"检索{k}个最相似的文本块...")retrieved_chunks = vector_store.similarity_search(hypothetical_embedding, k=k)# 准备结果字典results = {"query": query,"hypothetical_document": hypothetical_doc,"retrieved_chunks": retrieved_chunks}# 步骤4:如果需要,生成响应if should_generate_response:print("生成最终响应...")response = generate_response(query, retrieved_chunks)results["response"] = responsereturn resultshyde_rag函数现在的功能是:
生成假设文档。
为该文档(不是查询!)创建嵌入。
使用该嵌入进行检索。
像之前一样生成响应。
让我们运行它,看看生成的响应:
# 运行HyDE RAG
hyde_result = hyde_rag(query, vector_store)# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{hyde_result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)### 输出
0.5我们的评估分数约为0.5。
虽然HyDE是个巧妙的想法,但它并不总是更有效。在这个案例中,假设文档的方向可能与我们实际的文档集合略有不同,导致检索到的内容相关性较低。
这里的关键经验是,不存在单一的“最佳”RAG技术。不同的方法在不同的查询和不同的数据上表现更好。
融合检索
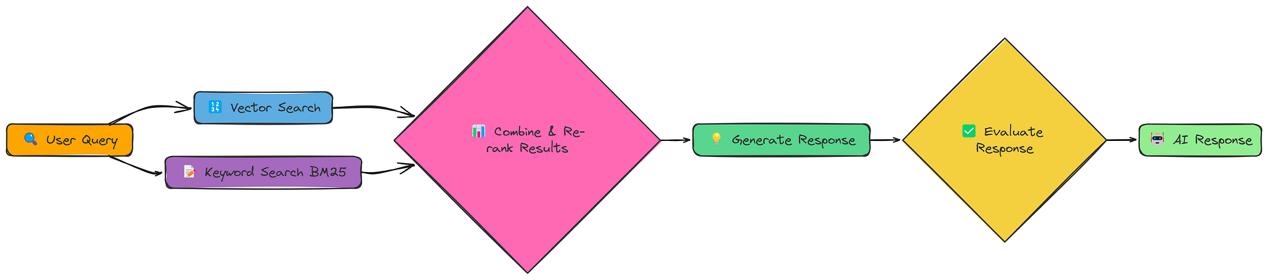
我们已经了解到,不同的检索方法各有优势。向量搜索擅长语义相似性,而关键词搜索则在查找精确匹配方面表现出色,如果我们能将它们结合起来会怎样?这就是Fusion RAG背后的理念。
融合 RAG工作流程
融合 RAG不局限于选择一种检索方法,而是两种都用,然后对结果进行合并和重新排序。这样我们就能同时捕捉语义含义和精确的关键词匹配。
我们实现的核心是fusion_retrieval函数。该函数同时执行基于向量和基于BM25的检索,对每种方法的分数进行归一化,使用加权公式将它们组合起来,然后根据组合后的分数对文档进行排序。
以下是融合检索的函数:
import numpy as npdef fusion_retrieval(query, chunks, vector_store, bm25_index, k=5, alpha=0.5):"""通过结合基于向量和BM25的搜索结果执行融合检索。"""# 为查询生成嵌入query_embedding = create_embeddings(query)# 执行向量搜索,并将结果存储在字典中(索引 -> 相似度分数)vector_results = {r["metadata"]["index"]: r["similarity"] for r in vector_store.similarity_search_with_scores(query_embedding, len(chunks))}# 执行BM25搜索,并将结果存储在字典中(索引 -> BM25分数)bm25_results = {r["metadata"]["index"]: r["bm25_score"] for r in bm25_search(bm25_index, chunks, query, len(chunks))}# 从向量存储中检索所有文档all_docs = vector_store.get_all_documents()# 使用向量分数和BM25分数的加权和计算每个文档的组合分数scores = [(i, alpha * vector_results.get(i, 0) + (1 - alpha) * bm25_results.get(i, 0)) for i in range(len(all_docs))]# 按组合分数降序对文档进行排序,并保留前k个结果top_docs = sorted(scores, key=lambda x: x[1], reverse=True)[:k]# 返回前k个文档,包含文本、元数据和组合分数return [{"text": all_docs[i]["text"], "metadata": all_docs[i]["metadata"], "score": s} for i, s in top_docs]它融合了两种方法的优点:
向量搜索:使用我们现有的create_embeddings和SimpleVectorStore来实现语义相似性检索。
BM25搜索:使用BM25算法(一种标准的信息检索技术)实现基于关键词的搜索。
分数组合:将两种方法的分数结合起来,为我们提供一个统一的排名。
让我们运行完整的流程并生成响应:
# 首先,处理文档以创建文本块、向量存储和BM25索引
chunks, vector_store, bm25_index = process_document(pdf_path)# 使用融合检索运行RAG
fusion_result = answer_with_fusion_rag(query, chunks, vector_store, bm25_index)
print(fusion_result["response"])# 评估
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{fusion_result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)###输出
AI响应的评估分数为0.83最终分数为0.83。
Fusion RAG通常能给我们带来显著的提升,因为它结合了不同检索方法的优势。这就像有两位专家协同工作——一位擅长理解查询的含义,另一位擅长查找精确匹配。
多模态
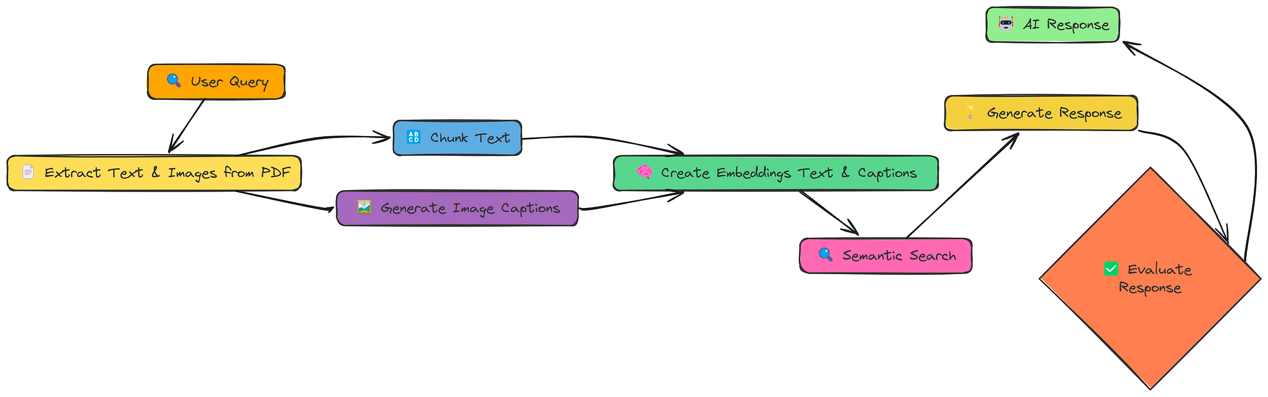
到目前为止,我们只处理过文本信息。但很多信息都存在于图像、图表和示意图中。多模态RAG(Multi-Modal RAG)旨在解锁这些信息,并利用它们来优化我们的响应。
多模态工作流程
这里的关键变化如下:
提取文本和图像:我们从PDF中同时提取文本和图像。
生成图像描述:我们使用LLM(具体来说,是具备视觉能力的模型)为每个图像生成文本描述(字幕)。
创建嵌入(文本和描述):我们为文本块和图像描述都创建嵌入。
嵌入模型:在本笔记本中,我们使用BAAI/bge-en-icl嵌入模型。
LLM模型:用于生成响应和图像描述的模型是llava-hf/llava-1.5–7b-hf。
通过这种方式,我们的向量存储既包含文本信息也包含视觉信息,并且我们可以跨这两种模态进行搜索。
下面我们定义process_document函数:
def process_document(pdf_path, chunk_size=1000, chunk_overlap=200):"""为多模态RAG处理文档。"""# 创建用于存储提取图像的目录image_dir = "extracted_images"os.makedirs(image_dir, exist_ok=True)# 从PDF中提取文本和图像text_data, image_paths = extract_content_from_pdf(pdf_path, image_dir)# 对提取的文本进行分块chunked_text = chunk_text(text_data, chunk_size, chunk_overlap)# 处理提取的图像以生成描述image_data = process_images(image_paths)# 合并所有内容项(文本块和图像描述)all_items = chunked_text + image_data# 提取用于嵌入的内容contents = [item["content"] for item in all_items]# 为所有内容创建嵌入print("为所有内容创建嵌入...")embeddings = create_embeddings(contents)# 构建向量存储并添加带有嵌入的项vector_store = MultiModalVectorStore()vector_store.add_items(all_items, embeddings)# 准备包含文本块和图像描述数量的文档信息doc_info = {"text_count": len(chunked_text),"image_count": len(image_data),"total_items": len(all_items),}# 打印已添加项的摘要print(f"已向向量存储添加{len(all_items)}个项({len(chunked_text)}个文本块,{len(image_data)}个图像描述)")# 返回向量存储和文档信息return vector_store, doc_info这个函数负责图像提取和描述生成,以及MultiModalVectorStore(多模态向量存储)的创建。
我们假设图像描述的效果相当不错(在实际场景中,你需要仔细评估描述的质量)。现在,让我们结合查询来整合所有内容:
# 处理文档以创建向量存储。我们为此准备了一个新的PDF
pdf_path = "data/attention_is_all_you_need.pdf"
vector_store, doc_info = process_document(pdf_path)# 运行多模态RAG流程。这和之前非常相似!
result = query_multimodal_rag(query, vector_store)# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)### 输出
0.79我们得到了约0.79的分数。
多模态RAG具有很大的潜力,特别是对于那些图像包含关键信息的文档。不过,它并没有超过我们目前看到的其他技术。
CRAG
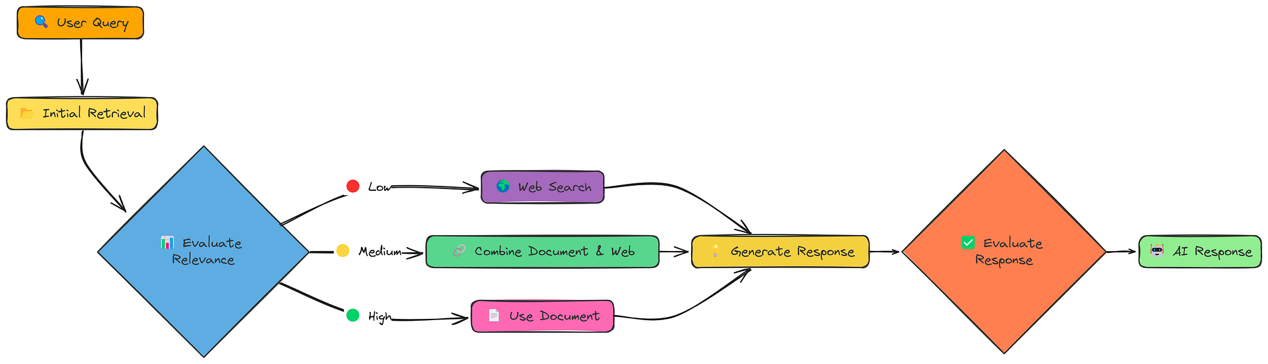
到目前为止,我们的RAG系统相对被动。它们检索信息并生成响应。但如果检索到的信息质量很差呢?如果信息不相关、不完整甚至相互矛盾呢?Corrective RAG(CRAG,纠错型RAG)直面了这个问题。
CRAG工作流程
CRAG增加了一个关键步骤:评估。在初始检索后,它会检查检索到的文档的相关性。重要的是,它会根据评估结果采取不同的策略:
高相关性:如果检索到的文档质量良好,则按常规流程进行。
低相关性:如果检索到的文档质量很差,则转而使用网络搜索!
中等相关性:如果文档质量一般,则结合文档信息和网络信息。
这种“纠错”机制使CRAG比标准RAG更稳健。它不只是寄希望于最好的结果,而是主动检查并调整。
让我们看看实际如何运作。我们将使用一个名为rag_with_compression的函数来实现。
# 运行CRAG
crag_result = rag_with_compression(pdf_path, query, compression_type="selective")这个单一函数调用完成了很多工作:
初始检索:像往常一样检索文档。
相关性评估:为每个文档的查询相关性打分。
决策:决定是使用文档、进行网络搜索,还是两者结合。
响应生成:使用选定的知识源生成响应。
和往常一样,进行评估:
# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{crag_result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)### 输出
0.824我们得到的分数约为0.824。
CRAG具备检测并纠正检索失败的能力,这使其比标准RAG可靠得多。通过在必要时动态切换到网络搜索,它可以处理更广泛的查询,避免陷入不相关或信息不足的困境。这种“自我纠错”能力是迈向更稳健、更可信的RAG系统的重要一步。
结论
所测试的18种RAG技术代表了改善检索质量的多种方法,从简单的分块策略到Adaptive RAG等高级方法。
简单RAG提供了一个基准,更复杂的方法如层次索引(0.84)、Fusion(0.83)和CRAG(0.824)通过解决检索挑战的不同方面,显著优于简单RAG。
自适应RAG凭借根据查询类型智能选择检索策略,成为表现最佳的方法(0.86),这表明具有上下文感知能力的灵活系统能在多样化的信息需求中提供最佳结果。