【论文阅读】Multimodal Graph Contrastive Learning for Multimedia-based Recommendation
Multimodal Graph Contrastive Learning for Multimedia-based Recommendation
摘要
当前多模态推荐方法存在严重的噪声污染问题:大量与用户偏好无关的多媒体内容(如图像的背景、布局、亮度,标题中的语序与无意义词汇)被误纳入用户兴趣建模,干扰了推荐效果。此外,主流方法多采用图神经网络进行表示学习,导致这些噪声信息在图结构中不断传播和扩散,进一步放大了对用户与物品表示的污染,影响推荐性能。
为解决多模态噪声污染问题,论文提出了MGCL框架,主要通过两点实现优化:一是采用三个并行的图卷积网络,分别独立建模协同信号、视觉偏好线索和文本偏好线索,从结构上隔离噪声传播;二是引入对比学习构建自监督信号,通过优化目标对多模态表示进行去噪和增强,从而提升用户和物品表示的表达能力。该方法不仅适用于图学习模型,也能扩展到大多数矩阵分解类推荐方法中。
一、引言
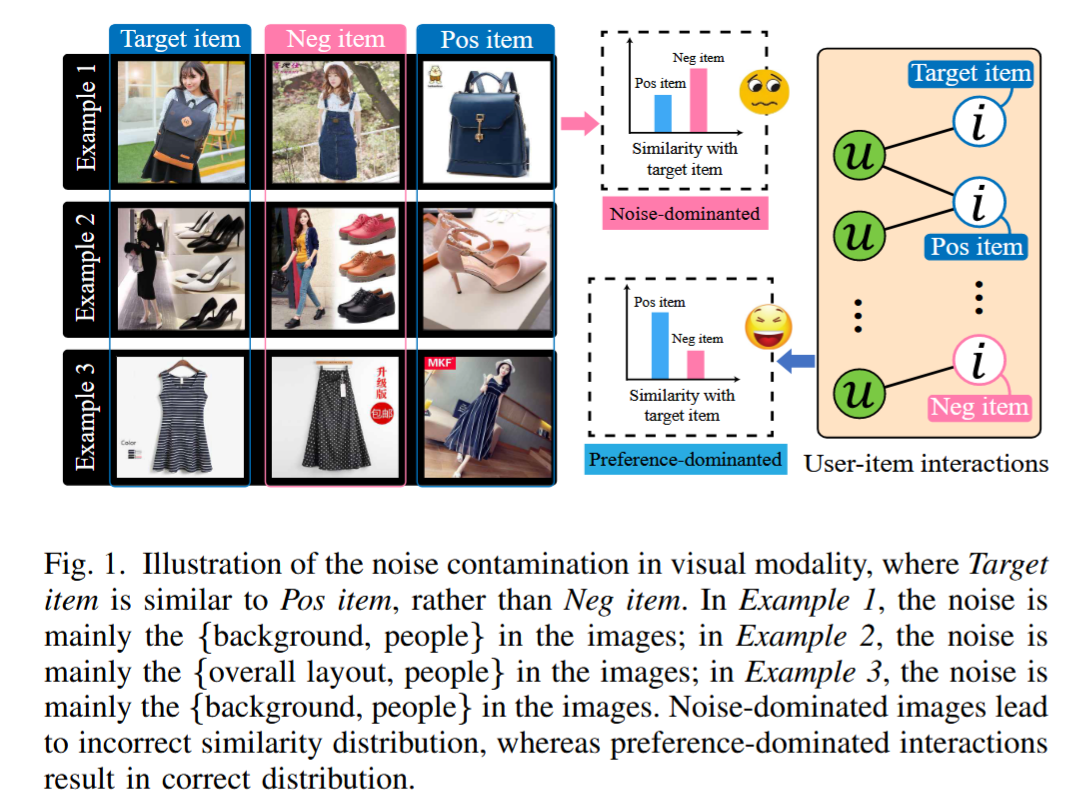
图1主要展示了视觉模态中噪声污染的影响,以及它如何导致推荐系统的相似度判断偏差。
1. 左侧三个例子(Example 1~3)
- Target item:目标物品(用户交互过的物品)
- Pos item:与用户偏好一致的正样本物品
- Neg item:与用户偏好无关的负样本物品
在理想情况下,Target item 应该与 Pos item 相似度更高,而与 Neg item 相似度更低。
但是在图中:
- Example 1:噪声主要来自图片的背景和人物,这些信息与用户对物品的真实偏好无关。
- Example 2:噪声来自图片整体布局和人物。
- Example 3:噪声同样来自背景和人物。
2. 中间的相似度分布
- Noise-dominated(噪声主导):由于噪声的影响,Neg item 反而与 Target item 的相似度高于 Pos item,导致模型判断错误。
- Preference-dominated(偏好主导):在噪声被抑制的情况下,Pos item 相似度更高,Neg item 更低,符合真实用户偏好。
3. 右侧用户-物品交互图
- 节点 u 表示用户,节点 i 表示物品。
- 连接线表示交互关系。
- 噪声污染会影响这种图结构中的相似度计算和信息传播,从而误导推荐结果。
简单来说,这张图强调了一个核心问题:如果视觉特征中噪声成分过多,推荐系统可能会把不相关的物品当成相似物品,从而降低推荐准确率。
如果你愿意,我可以帮你画一张更直观的噪声扩散示意图,方便理解噪声是怎么在图结构中放大的。你要我画吗?
主流的多模态推荐方法(MMRec)在整合图像、文本等模态信息时,面临 多模态噪声污染(multimodal noise contamination) 的严重问题,具体体现在:
- 多模态内容复杂:图像中可能包含背景、人像等与用户偏好无关的信息;
- 用户偏好多样:导致模型很难准确区分“偏好相关”和“偏好无关”的特征;
- 协同信号被弱化:多模态特征污染了 ID 表征,使得基于用户行为的协同信号不再纯净;
- 偏好建模偏离方向:模型可能学习到视觉上相似但偏好上无关的物品特征(见 Fig.1 的“noise-dominated”示例)。
💡 MGCL 方法的解决思路
为解决上述问题,作者提出 MGCL(Multimodal Graph Contrastive Learning),其核心策略包括两个方面:
1. 分离图学习(Separated Graph Learning)
-
构建三个并行 GCN 模块:
- 一个用于捕捉用户与物品的协同信号(基于 ID);
- 一个用于提取视觉偏好线索;
- 一个用于提取文本偏好线索;
-
各模态间信息流彼此隔离,避免噪声传播污染 ID 表征,从而保留更纯净的协同信息。
2. 对比学习(Contrastive Learning)引导
- 利用对比学习将“协同信号”作为监督信号,引导多模态表示学习;
- 最大化协同信号与模态偏好之间的互信息,推动模型从复杂内容中提取偏好相关的特征;
- 本质上是表征对齐(representation alignment):将偏好相似的物品靠近,偏好无关的物品拉远,从而一定程度上消除噪声影响。
三、方法
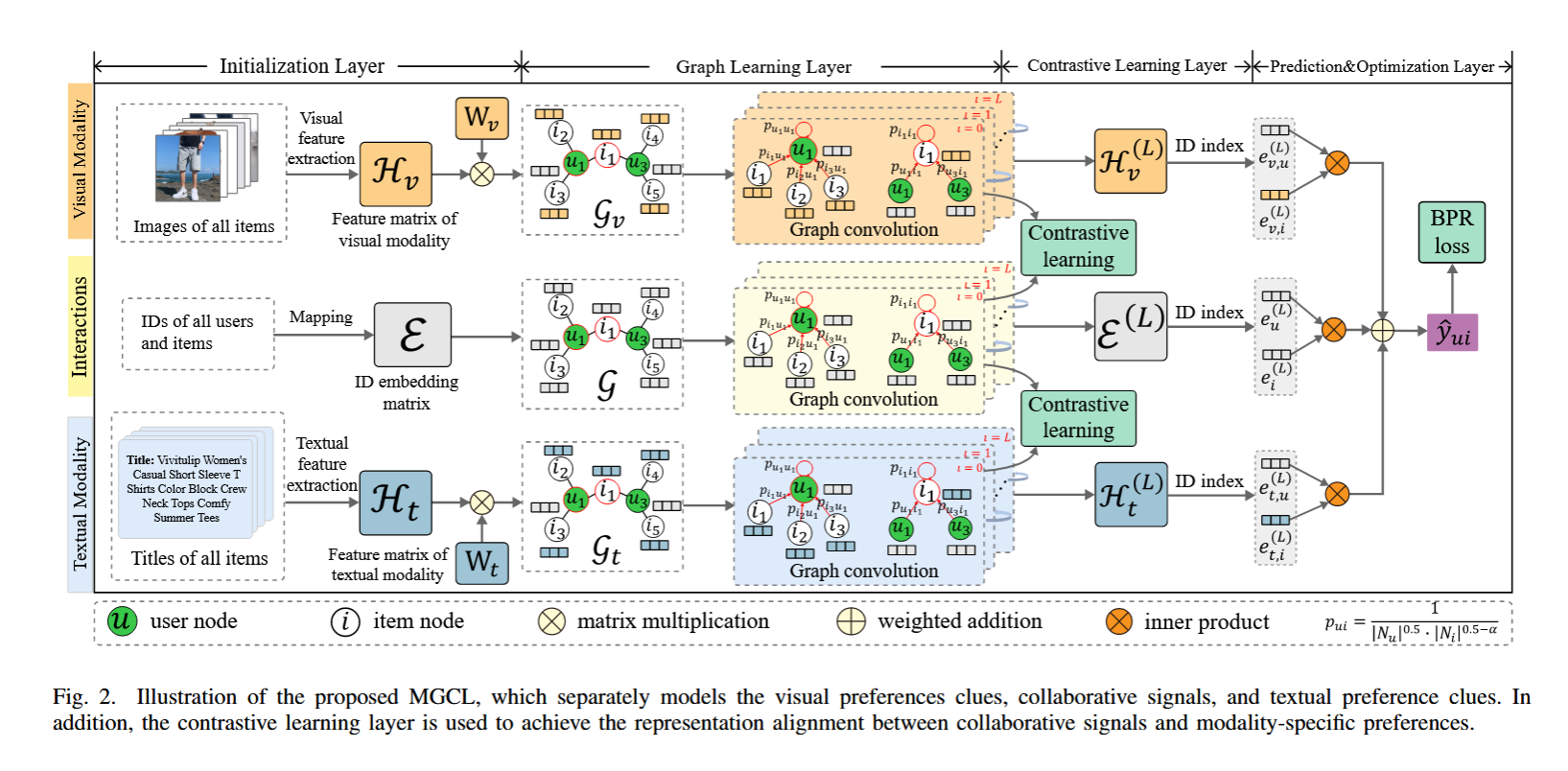
图2展示了MGCL(Multimodal Graph Contrastive Learning)模型的整体结构,包含四大模块:初始化层、图学习层、对比学习层、预测与优化层。其核心思想是将协同信号、视觉偏好、文本偏好分开建模并通过对比学习进行对齐,以减轻多模态噪声影响。下面按流程解读每一部分:
🔶 1. Initialization Layer(初始化层)
📷 视觉模态:
- 提取所有物品的图像特征,形成视觉特征矩阵 H_v\mathcal{H}\_vH_v;
- 通过可学习权重矩阵 W_vW\_vW_v 对图像特征进行线性变换。
🔤 文本模态:
- 提取所有物品标题的文本特征,形成文本特征矩阵 H_t\mathcal{H}\_tH_t;
- 同样使用可学习的 W_tW\_tW_t 对文本特征进行线性变换。
🧍 用户-物品ID嵌入:
- 对用户与物品 ID 进行嵌入映射,得到 ID 表征矩阵 E\mathcal{E}E。
🟧 2. Graph Learning Layer(图学习层)
构建三个平行子图卷积网络:
- GGG: 基于 ID 交互图(协同信号图),用于捕捉用户与物品之间的协同偏好;
- G_vG\_vG_v: 图像模态图(视觉子图);
- G_tG\_tG_t: 文本模态图(文本子图);
每个图中,用户和物品都是节点,边权 p_uip\_{ui}p_ui 依赖于用户-物品之间的交互频率和节点度,见图右下角公式。
三个 GCN 分别对三个输入特征矩阵进行卷积,得到三种高阶表示:
- H_v(L)\mathcal{H}\_v^{(L)}H_v(L):图像卷积后的特征;
- H_t(L)\mathcal{H}\_t^{(L)}H_t(L):文本卷积后的特征;
- E(L)\mathcal{E}^{(L)}E(L):协同图卷积后的 ID 表征。
🟩 3. Contrastive Learning Layer(对比学习层)
此层通过 对比学习 机制,引导模态表示与协同信号对齐:
- 将 H_v(L)\mathcal{H}\_v^{(L)}H_v(L) 和 H_t(L)\mathcal{H}\_t^{(L)}H_t(L) 分别与 E(L)\mathcal{E}^{(L)}E(L) 对比;
- 目标是使视觉和文本模态中的用户偏好线索靠近协同信号方向,抑制模态中的无关噪声。
🟪 4. Prediction & Optimization Layer(预测与优化层)
- 将三种表示通过加权加法融合成最终的用户表示 e_u(L)e\_u^{(L)}e_u(L) 和物品表示 e_i(L)e\_i^{(L)}e_i(L);
- 计算它们的内积作为预测评分 y^_ui\hat{y}\_{ui}y^_ui;
- 使用 BPR Loss(Bayesian Personalized Ranking) 作为训练目标,优化排序效果。
🧠 总结
MGCL 的核心架构亮点在于:
模块 作用 多图建模 分离建模协同信号、视觉线索、文本线索,避免信息干扰 对比学习 对齐模态表示与协同信号,提升判别性 GCN 捕捉高阶连接结构,增强表示能力 加权融合 & BPR Loss 综合各模态并优化排序推荐
协同信号,提升判别性 |
| GCN | 捕捉高阶连接结构,增强表示能力 |
| 加权融合 & BPR Loss | 综合各模态并优化排序推荐 |