RocketMq面试集合
RockerMq面试题集合
观看 徐庶说java 时做的RocketMq做的知识梳理,附带自己的补充
1.为什么要使用 MQ?
| 作用 | 说明 |
|---|---|
| 异步通信 | 解除上下游间同步调用关系,发送方无需等待接收方处理完成,提高系统响应速度 |
| 削峰填谷 | 缓冲突发流量(如秒杀场景),避免下游系统因瞬间高负载崩溃 |
| 解耦系统 | 降低模块间依赖,上游系统只需发送消息,无需关心下游如何处理,便于系统扩展 |
| 数据分发 | 同一消息可被多个消费者订阅,实现一对多通信(如订单创建后通知库存、支付、物流系统) |
| 可靠性保障 | 提供消息持久化、重试机制,确保消息不丢失,解决分布式系统数据一致性问题 |
2.多个 MQ 如何选型?

综上,各种对比之后,有如下建议:
- 一般的业务系统要引入 MQ,最早大家都用 ActiveMQ,但是现在确实大家用的不多了,没经过大
规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了;
后来大家开始用 RabbitMQ,但是确实 erlang 语言阻止了大量的 Java 工程师去深入研究和掌控
它,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也
高;
- 不过现在确实越来越多的公司会去用 RocketMQ,确实很不错,毕竟是阿里出品,但社区可能有
突然黄掉的风险(目前 RocketMQ 已捐给Apache,但 GitHub 上的活跃度其实不算高)对自己公
司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃
的开源社区,绝对不会黄。
- 所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大型
公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活
跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
3.RocketMQ 由哪些角色组成,每个角色作用和特点是什么?
| 角色 | 作用 | 特点 |
|---|---|---|
| Producer(生产者) | 发送消息到 Broker | 支持同步 / 异步发送、单向发送;可集群部署;通过分区键指定消息发送到的队列,保证顺序性 |
| Consumer(消费者) | 从 Broker 订阅并消费消息 | 支持集群消费(消息只被一个消费者处理)和广播消费(消息被所有消费者处理);提供顺序消费(MessageListenerOrderly)和并发消费(MessageListenerConcurrently)两种模式 |
| Broker | 存储消息、转发消息 | 分为 Master 和 Slave,Master 负责读写,Slave 负责同步数据并在 Master 故障时切换;支持消息持久化(存储到 CommitLog);单个 Broker 可包含多个 Topic,每个 Topic 包含多个 Queue |
| NameServer | 路由中心 | 管理 Broker 注册与心跳检测;维护 Topic 路由信息(消息所在的 Broker 和 Queue);无状态集群,节点间互不通信,可水平扩容;轻量级,仅存储元数据 |
| Topic | 消息的逻辑分类 | 生产者按 Topic 发送消息,消费者按 Topic 订阅消息;每个 Topic 可分布在多个 Broker 上,通过 Queue 实现负载均衡 |
| Queue | 消息的物理存储单元 | 每个 Topic 包含多个 Queue(默认 4 个),消息实际存储在 Queue 中;Queue 是有序的,同一 Queue 内的消息按发送顺序存储和消费,实现分区有序 |
4.如何保证消息幂等性
影响消息正常发送和消费的重要原因是网络的不确定性。
引起重复消费的原因:
正常情况下在consumer真正消费完消息后应该发送ack,通知broker该消息已正常消费,从queue中剔除
当ack因为网络原因无法发送到broker,broker会认为词条消息没有被消费,此后会开启消息重投机制把消息再次投递到consumer
解决方案:ConcurrentHashMap(单机)、数据库表、Redis(分布式)
以下是Redis解决方案流程
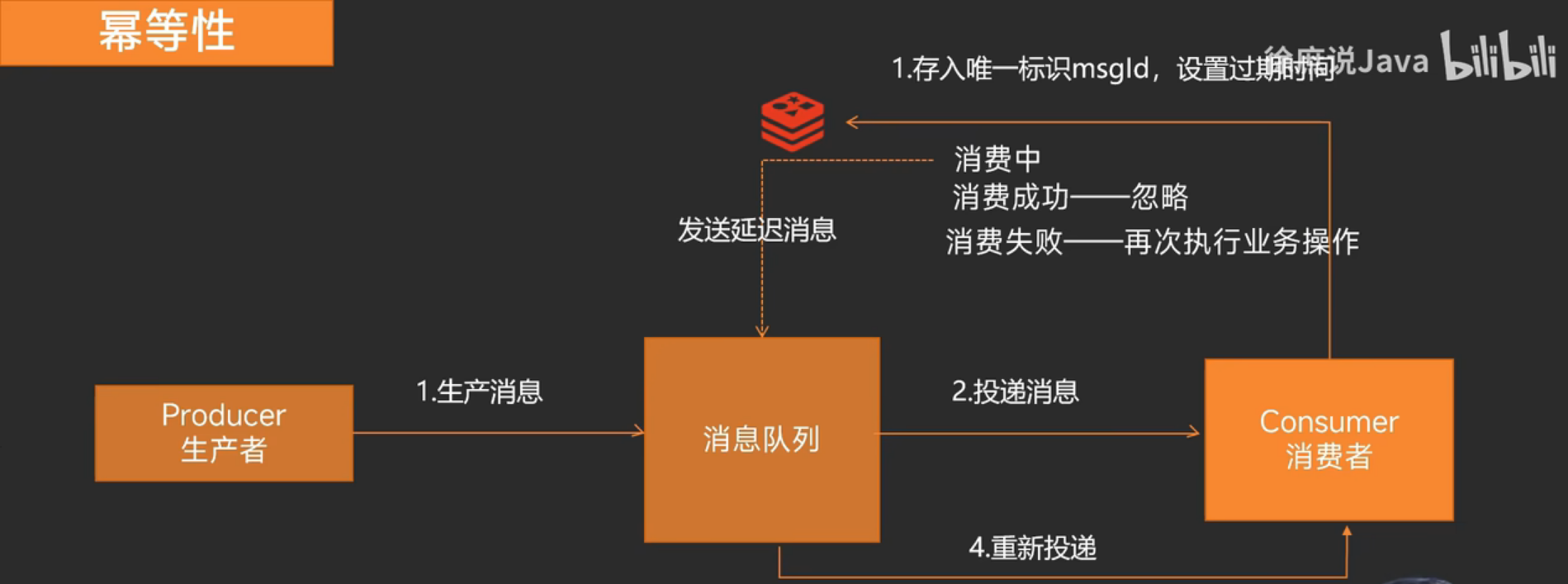
(要用业务Id做唯一标识,因为重发消息时msgId不一样)
5.如何保证消息顺序性
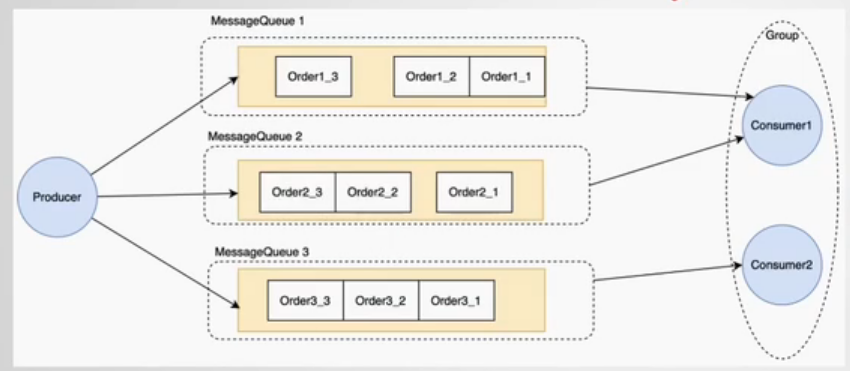
-
生产者
并行生产改串行(根据业务,如顾客A的订单产生的一系列消息串行;秒杀系统多人抢单可并行,因为允许后下单的先抢到,网络问题先下单的可能失败)
-
消息队列
分区,一个topic有多个queue,同上根据业务,需要顺序性的放同一queue,可重写MessageQueueSelector接口根据订单Id路由
-
消费者
同一队列的消息由单线程串行处理,底层通过对每个队列加并发锁实现(RocketMq特有)
MessageListenerOrderly(顺序消费) MessageListenerConcurrently(并发消费)
注册监听器选MessageListenerOrderly即可
// 注册顺序消费监听器 consumer.registerMessageListener(new MessageListenerOrderly() {@Overridepublic ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {// 处理消息(同一队列的消息会串行执行)for (MessageExt msg : msgs) {System.out.println("消费消息:" + new String(msg.getBody()) + ",队列ID:" + msg.getQueueId());}// 返回消费成功状态return ConsumeOrderlyStatus.SUCCESS;} });
6.如何解决消息丢失问题
| 环节 | 可能导致消息丢失的原因 | 解决方案 |
|---|---|---|
| 生产者 | 1. 消息发送失败(网络波动、Broker 宕机) 2. 未确认发送结果就结束流程 | 1. 使用可靠发送机制:采用同步发送 + 确认机制 **,生产者发送消息后等待 Broker 的 ACK 响应,确保消息成功写入 2. 实现重试机制:对发送失败的消息进行有限次数重试(避免无限重试导致消息积压) 3. 事务消息:关键业务使用 RocketMQ 的事务消息,确保本地事务与消息发送的原子性 |
| 消息队列 | 1. 消息未持久化时 Broker 宕机 2. 主从同步延迟导致数据丢失 | 1. 开启持久化存储:将消息写入磁盘(如 RocketMQ 的 CommitLog、Kafka 的日志文件),避免内存中数据丢失 2. 同步刷盘:配置 Broker 为 “同步刷盘” 模式(而非异步),确保消息写入磁盘后再返回 ACK(牺牲部分性能换取可靠性) 3. 主从同步:启用 Broker 主从架构,配置 “同步复制”(消息同步到 Slave 后再返回 ACK),避免 Master 宕机导致数据丢失 |
| 消费者 | 1. 消息未处理完成就提交 Offset 2. 消费过程中应用崩溃 | 1. 关闭自动提交:采用手动提交 Offset 机制,确保消息处理完成后再提交消费进度(如 RocketMQ 的context.commit()、Kafka 的commitSync()) 2. 异常处理与重试:消费失败时返回明确状态(如 RocketMQ 的SUSPEND_CURRENT_QUEUE_A_MOMENT),触发重试机制,避免消息被标记为 “已消费” 3. 幂等性处理:即使消息重复消费(如重试导致),通过唯一 ID(消息 ID 或业务 ID)确保业务逻辑正确执行,避免重复处理 |
7.如何处理消息积压问题
| 环节 | 问题原因 | 解决方案 |
|---|---|---|
| 预防机制 | 1. 生产者发送速度远大于消费者处理速度 2. 消费者处理逻辑耗时过长 3. 队列容量设计不足 | 1. 流量控制: - 生产者端:通过限流(如令牌桶算法)控制发送速率,避免突发流量压垮队列 - 消费者端:根据处理能力动态调整消费线程数(如 RocketMQ 可配置 consumeThreadMin/max) 2. 优化消费逻辑: - 简化消费流程,将耗时操作(如数据库写入)异步化 - 批量处理消息(如设置 batchSize 批量拉取和处理) 3. 队列扩容: - 增加 Topic 分区数(Queue 数量),提高并行消费能力 - 部署多个消费者实例,利用负载均衡分担消费压力 |
| 监控告警 | 1. 消息积压未及时发现 2. 积压阈值不明确 | 1. 关键指标监控: - 积压数量:队列中未消费消息数(如 RocketMQ 的 msgTotalInQueue) - 积压时长:消息从生产到被消费的延迟时间 - 消费速率:消费者每秒处理消息数 2. 告警配置: - 当积压数量超过阈值(如 10 万条)或积压时长超预期(如 5 分钟)时,通过监控系统(如 Prometheus + Grafana)触发告警(邮件、短信) |
| 紧急处理 | 1. 大量消息积压导致队列满 2. 消费者处理能力不足 3. 消费逻辑异常导致消息处理失败 | 1. 临时扩容消费者: - 快速部署更多消费者实例,加入同一消费组,分担消费压力(需确保队列数 ≥ 消费者实例数,否则部分实例空闲) - 临时调大消费线程池(如 RocketMQ 调大 consumeThreadMax) 2. 跳过非核心消息: - 对可丢弃的非核心消息(如日志),临时修改消费逻辑直接跳过,优先处理核心消息(如订单、支付) 3. 离线消费积压消息: - 创建临时 Topic,将积压消息按业务类型拆分,用专门的离线消费程序处理 - 若消息有序,可按队列拆分,多实例并行消费不同队列 4. 修复消费逻辑: - 若积压因消费逻辑报错导致,紧急修复代码并重启消费者,确保消息能正常处理 - 对失败消息,通过死信队列(DLQ)单独处理,避免阻塞正常消息 |
| 长期优化 | 1. 架构设计不合理 2. 缺乏容量规划 | 1. 消息分级: - 核心消息(如交易)使用高优先级队列,非核心消息(如通知)使用普通队列,避免相互影响 2. 削峰填谷机制: - 引入缓冲层(如 Kafka 的分区副本),应对突发流量 3. 定期压测: - 模拟高并发场景,测试队列和消费者的最大承载能力,提前扩容 4. 异步化与批量处理: - 消费者将消息批量写入数据库(如 JDBC 批量提交),减少 IO 开销 - 非实时业务采用定时任务批量消费,错峰处理 |
8.广播模式
8.1广播模式和集群模式有什么区别?
- 消息分配:集群模式下,同组消费者竞争消费,一条消息仅被组内一个消费者消费;广播模式下,组内每个消费者都能收到并消费同一条消息 。
- 消费进度:集群模式进度由 Broker 统一管理;广播模式进度由消费者各自保存 。
- 应用场景:集群模式用于负载均衡、避免重复消费;广播模式用于需多消费者全收消息场景(如本地缓存刷新) 。
8.2广播模式启动方式
consumer.setMessageModel(org.apache.rocketmq.common.consumer.MessageModel.BROADCASTING);
8.3广播模式下,消费者在启动时会不会消费生产者之前发送的消息?
若消费者订阅 Topic 且 Broker 未清理历史消息,启动后会消费之前未被自身消费过的消息(因广播模式按消费者自身进度,只要消息还在 Broker 存储且未超保留时间,就可能被消费 )。
8.4广播模式下,消费者的消费进度丢失会怎样?
一旦消费进度丢失,消费者没有可参考的已消费偏移量信息,默认策略往往是从最早的消息开始消费,也就是 “从零开始”
9.延迟消息
-
消息存储:生产者发送延迟消息时,RocketMQ 会根据延迟级别,将消息存储在名为
SCHEDULE_TOPIC_XXXX的特殊 Topic 中,而不是直接存储到目标 Topic 。 -
延迟级别设定:RocketMQ 预设了 18 个延迟级别,分别对应不同的延迟时间,从 1s 到 2h 不等,级别值与延迟时间的对应关系如下:
-

延迟级别 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 延迟时间 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h -
**延迟级别设定修改:**编辑 Broker 的配置文件
broker.conf,找到或添加messageDelayLevel参数,按照从小到大的顺序设置延迟级别及其对应的延迟时间,时间单位支持s(秒)、m(分)、h(时)、d(天)等。修改完成后,需要重启 Broker 使配置生效。 -
定时任务扫描:Broker 端启动了一个定时任务,按照延迟级别定时扫描
SCHEDULE_TOPIC_XXXX中的消息。当消息的延迟时间到达后,定时任务会将消息重新投递到目标 Topic ,此时消费者才能消费到该消息。 -
5.x版本支持自定义时间
3. 使用方式
- 发送延迟消息:在生产者代码中,通过设置消息的延迟级别来发送延迟消息。示例代码如下:
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.common.message.Message;
import java.util.concurrent.TimeUnit;public class DelayMessageProducer {public static void main(String[] args) throws Exception {DefaultMQProducer producer = new DefaultMQProducer("producer_group");producer.setNamesrvAddr("localhost:9876");producer.start();// 创建消息Message message = new Message("your_topic", "your_tag", "Hello, RocketMQ".getBytes());// 设置延迟级别为 3,表示延迟 10smessage.setDelayTimeLevel(3); producer.send(message);producer.shutdown();}
}
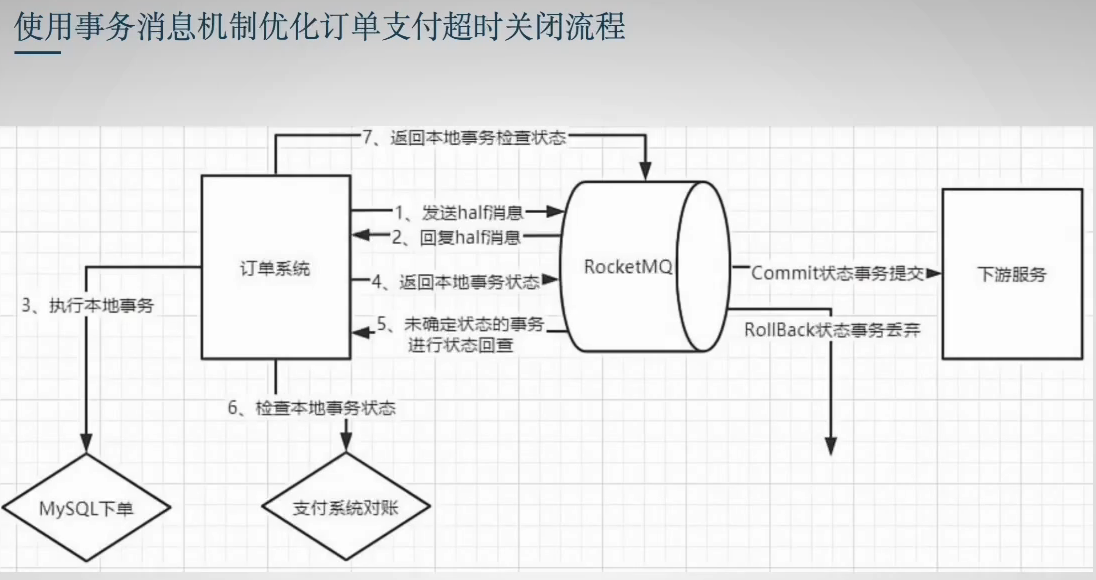
10.事务消息
流程如下图:
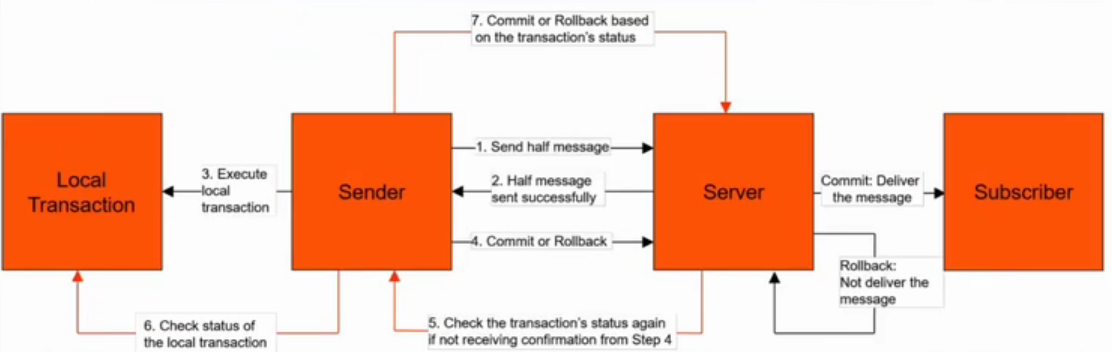
半消息包含完整消息体,附带状态为事务执行中,在Broker的内置消息队列中,消费者端不可见
在分布式事务中,只保证了一半,即生产者端完成事务且消息到消息队列(第4步失败,重试次数超阈值到死信队列),未保证消费者端事务完成,
**最终一致性:**若消费者未返回消费成功,server会一直给subscriber发消息,直到消费成功
场景示例:
参数设置:
同样在broker.conf配置文件中修改
-
transactionCheckInterval=60000 // 事务重试时间间隔 -
transactionCheckMax=15 // 事务重试次数,加上第一次默认16次
11.长轮询
长轮询是Broker 与 Consumer 之间高效推送消息的核心策略
1. 核心目标
- 减少无效请求:避免 Consumer 频繁轮询却无消息可消费(传统短轮询的弊端)。
- 接近实时推送:当有消息到达时,能快速通知 Consumer 拉取,兼顾实时性。
2. 工作流程
步骤 1:Consumer 发起长轮询请求
Consumer 向 Broker 发送拉取消息的请求(PullMessageRequest),并在请求中指定:
- 目标 Topic、队列(Queue)、消费偏移量(Offset)。
- 长轮询超时时间(默认 30 秒,可配置)。
此时,Broker 不会立即返回响应,而是进入 “等待状态”。
步骤 2:Broker 暂存请求并等待消息
Broker 收到请求后,先检查对应队列中是否有可消费的消息(即消息偏移量大于 Consumer 当前的 Offset):
- 有消息:立即将消息打包返回给 Consumer。
- 无消息:将该请求存入 Broker 的 挂起请求队列(SuspendedRequestQueue),一般由synchronized实现,并注册一个 “唤醒触发器”,然后保持连接不关闭。
步骤 3:消息到达时唤醒请求
当有新消息被发送到该队列(或之前的消息变为可消费状态,如事务消息提交),Broker 会触发以下操作:
- 遍历挂起请求队列,找到对应队列的挂起请求。
- 立即处理这些请求,将新消息返回给 Consumer。
步骤 4:超时未收到消息则释放连接
若超过长轮询超时时间(如 30 秒)仍无消息,Broker 会向 Consumer 返回 “无消息” 的响应,Consumer 收到后,间隔短暂时间(如几百毫秒)再次发起长轮询请求,循环往复。
12.消息过滤机制
一、Broker 端过滤(服务端过滤)
Broker 端过滤在消息投递到消费者之前完成,仅将符合条件的消息发送给消费者,减少网络传输和 Consumer 负载,是 RocketMQ 推荐的过滤方式。
主要支持两种实现:Tag 过滤 和 SQL92 表达式过滤。
1. Tag 过滤(最常用)
-
原理:通过消息的
Tag标签进行过滤,Tag是消息的二级分类(类似 “子主题”),由生产者在发送消息时指定。 -
使用方式:
-
生产者发送消息时设置Tag
// 格式:Topic:Tag,如 "OrderTopic:CREATE" 表示订单创建消息 Message msg = new Message("OrderTopic", "CREATE", "订单123".getBytes()); producer.send(msg); -
消费者订阅时通过Tag
过滤,支持*(匹配所有)、||(逻辑或):
// 订阅 "OrderTopic" 中 Tag 为 CREATE 或 PAY 的消息 consumer.subscribe("OrderTopic", "CREATE || PAY"); // 订阅所有 Tag 的消息 consumer.subscribe("OrderTopic", "*");
-
-
特点:
- 轻量高效,基于哈希匹配,性能极佳,适合简单分类场景。
- 一个消息只能设置一个
Tag,不支持复杂逻辑(如范围判断)。
2. SQL92 表达式过滤(高级过滤)
-
原理:基于消息的 用户属性(User Property) 进行过滤,支持类似 SQL 的条件表达式(如
>、<、=、AND、OR等),满足复杂过滤需求。 -
使用方式:
-
生产者发送消息时设置用户属性:
Message msg = new Message("OrderTopic", "CREATE", "订单123".getBytes()); // 设置用户属性:金额、用户等级 msg.putUserProperty("amount", "500"); msg.putUserProperty("level", "VIP"); producer.send(msg); -
消费者订阅时使用 SQL 表达式过滤:
// 订阅金额 > 100 且用户等级为 VIP 的消息 consumer.subscribe("OrderTopic", MessageSelector.bySql("amount > 100 AND level = 'VIP'"));
-
-
支持的语法:
- 比较运算符:
=、!=、>、>=、<、<= - 逻辑运算符:
AND、OR、NOT - 常量:字符串(单引号包裹,如
'VIP')、数字(如100)、布尔值(TRUE、FALSE)
- 比较运算符:
-
特点:
- 灵活强大,支持复杂条件,但性能略低于 Tag 过滤(需解析表达式)。
- 需在 Broker 配置中开启 SQL 过滤:
enablePropertyFilter=true(默认开启)。
二、Consumer 端过滤(客户端过滤)
Consumer 端过滤是指 Broker 将所有消息推送给消费者后,由消费者在本地根据自定义逻辑过滤,适用于 Broker 端过滤不满足需求的场景。
-
实现方式:
消费者接收消息后,在消费逻辑中手动判断是否符合条件:consumer.registerMessageListener((msgs, context) -> {for (MessageExt msg : msgs) {// 从消息属性中获取条件String level = msg.getUserProperty("level");int amount = Integer.parseInt(msg.getUserProperty("amount"));// 本地过滤:只处理 level 为 VIP 且 amount > 100 的消息if ("VIP".equals(level) && amount > 100) {System.out.println("处理消息:" + new String(msg.getBody()));}}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; }); -
特点:
- 完全自定义,支持任意复杂逻辑(如调用外部接口校验)。
- 缺点:无效消息会被传输到 Consumer,浪费网络带宽和内存,不适合高并发场景。
13.刷盘实现
RocketMQ提供了两种刷盘策略:同步刷盘和异步刷盘
- 同步刷盘:在消息达到Broker的内存之后,必须刷到commitLog日志文件中才算成功,然后返回
Producer数据已经发送成功。
- 异步刷盘:异步刷盘是指消息达到Broker内存后就返回Producer数据已经发送成功,会唤醒一个
线程去将数据持久化到CommitLog日志文件中。
优缺点分析:同步刷盘保证了消息不丢失,但是响应时间相对异步刷盘要多出10%左右,适用于
对消息可靠性要求比较高的场景。异步刷盘的吞吐量比较高,RT小,但是如果broker断电了内存
中的部分数据会丢失,适用于对吞吐量要求比较高的场景。
14.推拉消费模式
PULL:拉取型消费者主动从broker中拉取消息消费,只要拉取到消息,就会启动消费过程,称为
主动型消费。
PUSH:推送型消费者就是要注册消息的监听器,监听器是要用户自行实现的。当消息达到broker
服务器后,会触发监听器拉取消息,然后启动消费过程。但是从实际上看还是从broker中拉取消
息,称为被动消费型。
一、推模式(Push Consumer)
核心特点:Broker 主动将消息推送给消费者,消费者被动接收并处理消息,开发简单,无需手动控制拉取逻辑。
工作原理:
- 消费者启动时,向 Broker 注册监听,订阅目标 Topic。
- Broker 内部通过长轮询机制(见前文)检测到有新消息时,主动将消息推送给消费者。
- 消费者接收到消息后,通过注册的监听器(如
MessageListenerConcurrently)处理消息,并返回消费状态(成功 / 重试)。
代码示例:
// 创建推模式消费者
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("push_consumer_group");
consumer.setNamesrvAddr("localhost:9876");
// 订阅 Topic 和 Tag
consumer.subscribe("test_topic", "TagA");
// 注册消息监听器(被动接收消息)
consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {System.out.println("接收到消息:" + msgs);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 消费成功}
});
consumer.start();
适用场景:
- 对实时性要求较高,希望消息到达后立即处理(如订单通知、实时监控)。
- 业务逻辑简单,无需手动控制拉取频率和批量大小。
二、拉模式(Pull Consumer)
核心特点:消费者主动向 Broker 发起请求拉取消息,可自主控制拉取时机、频率和批量,灵活性更高,但开发复杂度增加。
工作原理:
- 消费者需要手动指定拉取的 Topic、队列(Queue)和起始偏移量(Offset)。
- 主动调用拉取方法(如
pull())从 Broker 获取消息,获取结果后自行处理。 - 处理完成后,需手动更新消费偏移量(Offset),避免重复消费。
代码示例:
// 创建拉模式消费者
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("pull_consumer_group");
consumer.setNamesrvAddr("localhost:9876");
consumer.start();// 获取 Topic 下的所有队列
Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("test_topic");
for (MessageQueue mq : mqs) {// 拉取消息(指定队列、偏移量、批量大小)PullResult result = consumer.pull(mq, "TagA", 0, 32); // 从偏移量 0 拉取,最多 32 条switch (result.getPullStatus()) {case FOUND: // 拉取到消息System.out.println("拉取到消息:" + result.getMsgFoundList());// 手动更新偏移量consumer.updateConsumeOffset(mq, result.getNextBeginOffset());break;case NO_NEW_MSG: // 无新消息break;// 其他状态处理...}
}
consumer.shutdown();
适用场景:
- 需灵活控制消息拉取节奏(如流量削峰,避开业务高峰拉取)。
- 批量处理消息(如累计一定数量后批量入库)。
- 对消费进度有精细化控制需求(如自定义偏移量管理)。
15.负载均衡
1.生产者
生产者的负载均衡:实质是在选择MessageQueue对象(内部包含了brokerName和queueId),
第一种是默认策略,从MessageQueue列表中随机选择一个,算法时通过自增随机数对列表打下
取余得到位置信息,但获得的MessageQueue所在集群不能是上次失败集群。第二种是超时容忍
策略,先随机选择一个MessageQueue,如果因为超时等异常发送失败,会优先选择该broker集
群下其他MessageQueue发送,如果没找到就从之前发送失败的Broker集群中选一个进行发送,
若还没有找到才使用默认策略。
2.消费者
消费者的负载均衡:这里可选的有六种算法。
1、平均分配算法
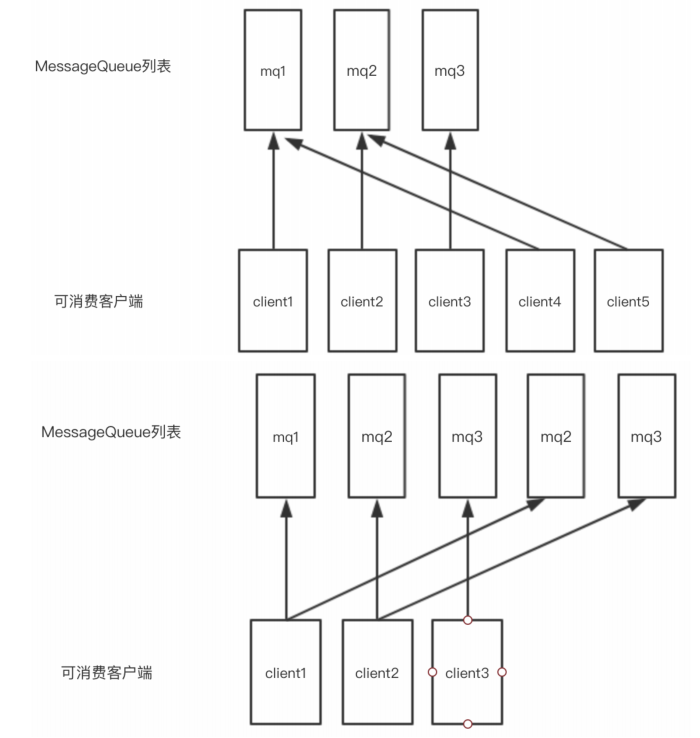
2、环形算法
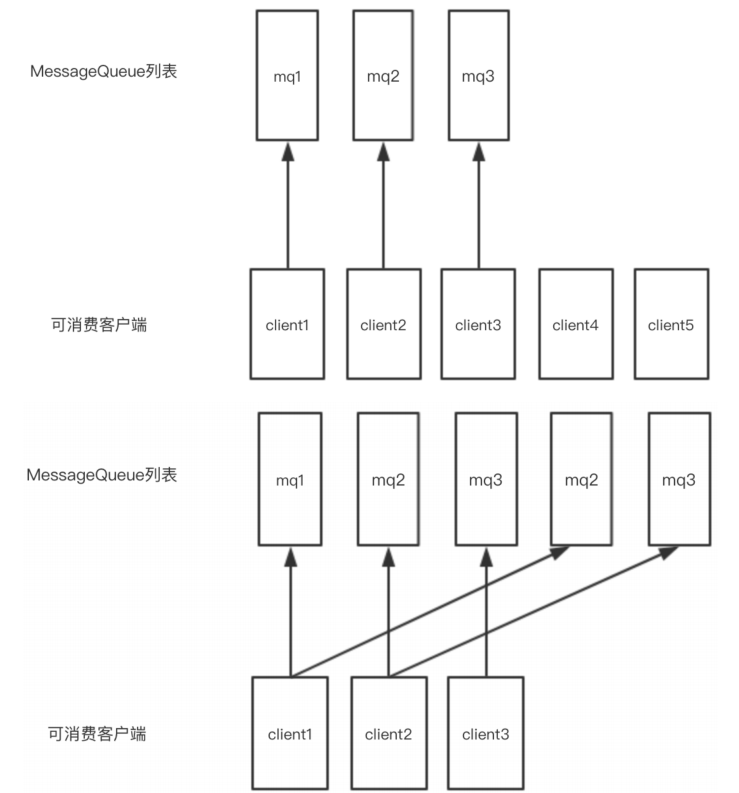
3、指定机房算法
4、就近机房算法
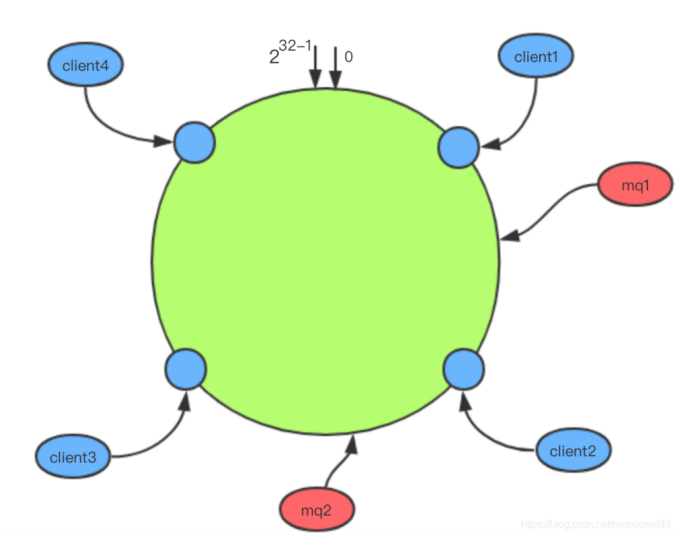
5、统一哈希算法
使用一致性哈希算法进行负载,每次负载都会重建一致性hash路由表,获取本地客户端负责的所有队
列信息。默认的hash算法为MD5,假设有4个消费者客户端和2个消息队列mq1和mq2,通过hash后分
布在hash环的不同位置,按照一致性hash的顺时针查找原则,mq1被client2消费,mq2被client3消
费。
sageQueue,如果因为超时等异常发送失败,会优先选择该broker集
群下其他MessageQueue发送,如果没找到就从之前发送失败的Broker集群中选一个进行发送,
若还没有找到才使用默认策略。