(论文速读)ViDAR:视觉自动驾驶预训练框架
论文题目:Visual Point Cloud Forecasting enables Scalable Autonomous Driving(视觉点云预测实现可扩展的自动驾驶)
会议:CVPR2024
摘要:与对通用视觉的广泛研究相比,可扩展视觉自动驾驶的预训练很少被探索。视觉自动驾驶应用需要同时包含语义、3D几何和时间信息的功能,以进行联合感知、预测和规划,这对预训练提出了巨大的挑战。为了解决这个问题,我们提出了一种新的预训练任务,称为视觉点云预测-从历史视觉输入预测未来的点云。该任务的关键优点是捕获语义,3D结构和时间动态的协同学习。因此,它在各种下游任务中显示出优势。为了解决这个新问题,我们提出了一种通用的预训练下游视觉编码器的模型ViDAR。它首先通过编码器提取历史嵌入。然后通过一种新的潜在渲染算子将这些表示转换为3D几何空间,用于未来的点云预测。实验表明,在下游任务中有显著的增益,例如,3D检测的NDS降低3.1%,运动预测的误差降低~ 10%,规划的碰撞率降低~ 15%。
源码链接:https://github.com/OpenDriveLab/ViDAR
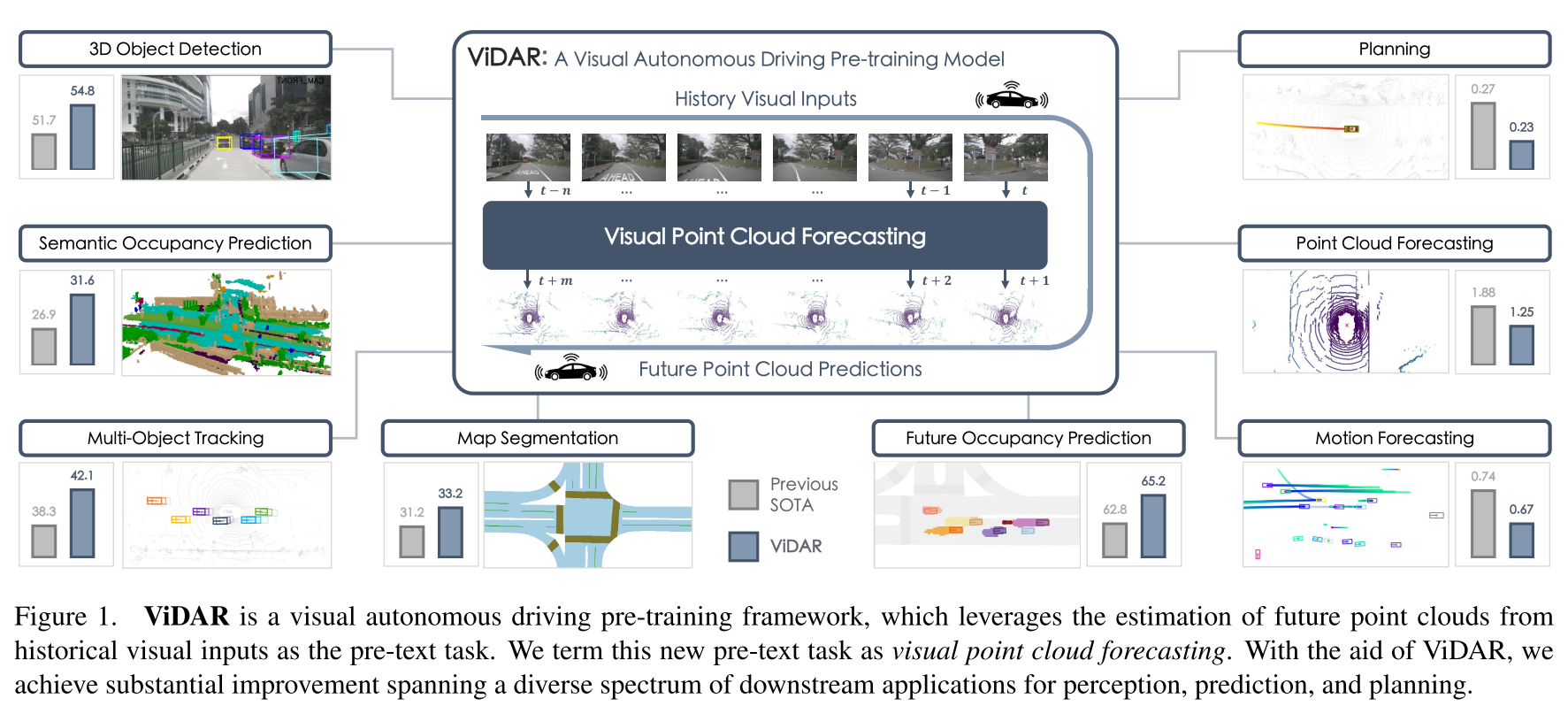
前言
自动驾驶技术正在快速发展,但面临着一个关键挑战:如何在减少对昂贵3D标注依赖的同时,训练出既能感知环境、又能预测未来、还能做出安全规划决策的智能系统?
背景:自动驾驶预训练的困境
现有方法的局限性
在计算机视觉领域,预训练已经取得了巨大成功,但在视觉自动驾驶领域却面临独特挑战:
- 多维度需求:自动驾驶系统需要同时理解语义信息(这是什么)、3D几何结构(在哪里)和时序动态(如何运动)
- 数据标注昂贵:3D边界框、占用网格、轨迹等标注成本极高,难以大规模获取
- 时序建模缺失:现有预训练方法如深度估计仅处理单帧,缺乏时序信息
传统预训练方法对比
| 方法 | 多视图几何 | 时序建模 | 标注需求 |
|---|---|---|---|
| 深度估计 | ❌ | ❌ | 中等 |
| 场景渲染 | ✅ | ❌ | 中等 |
| ViDAR | ✅ | ✅ | 极低 |
ViDAR:创新的解决方案
核心思想:视觉点云预测
ViDAR的核心创新在于提出了一个全新的预训练任务——视觉点云预测:
给定历史的多视图图像序列,预测未来的3D点云
这个看似简单的任务实际上非常巧妙:
- 语义理解:需要识别场景中的物体和结构
- 3D几何建模:需要理解物体的三维空间关系
- 时序动态学习:需要建模物体的运动模式
系统架构详解
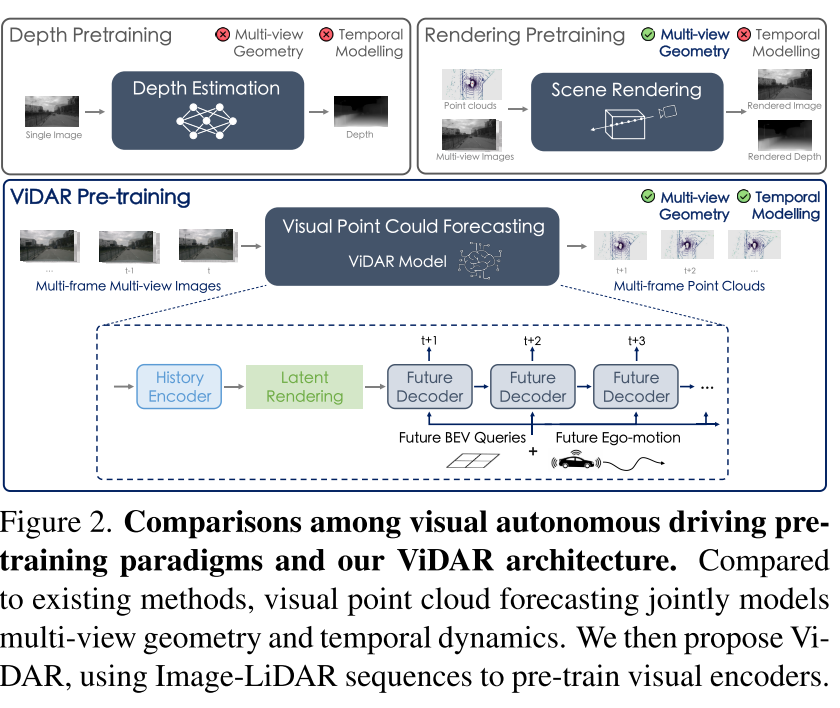
ViDAR包含三个核心组件:
1. History Encoder(历史编码器)
- 这是预训练的目标结构
- 可以是任何视觉BEV编码器(如BEVFormer)
- 将多视图图像序列编码为BEV特征
2. Latent Rendering(潜在渲染算子)
这是ViDAR最关键的创新组件,解决了一个重要问题:
问题:直接使用可微光线投射会导致"射线形状特征"——同一射线上的网格趋向于学习相似特征,缺乏判别性。
解决方案:
特征期望函数:F̂(i) = Σ p̂(i,k) * F(k)_bev
几何特征计算:F̂_bev = p̂ · F̂
通过条件概率函数为每个网格分配权重,确保学习到有判别性的几何特征。
3. Future Decoder(未来解码器)
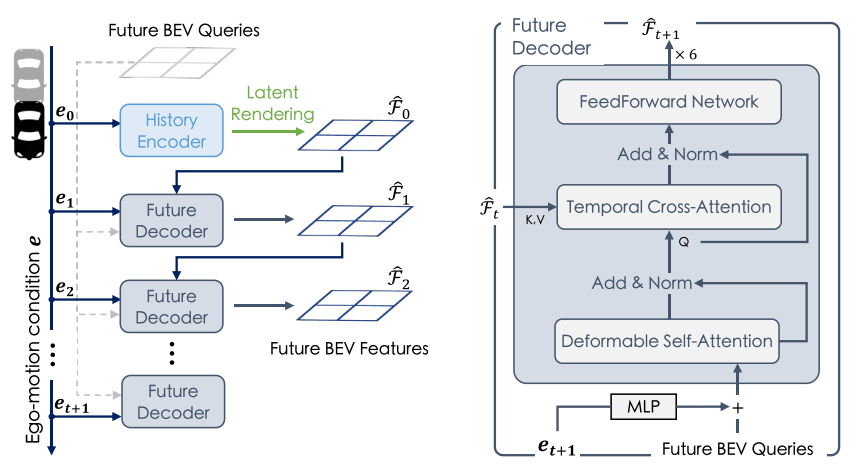
- 基于Transformer的自回归架构
- 包含时序交叉注意力机制
- 处理自车运动导致的坐标系变化
技术深度解析
Latent Rendering的数学原理

传统的可微光线投射使用以下公式:
条件概率:p̂(i,j) = (∏(1-p(i,k))) * p(i,j) [k=1到j-1]
距离期望:λ̂(i) = Σ p̂(i,j) * λ(j)
ViDAR的创新在于在潜在空间中进行类似操作:
特征期望:F̂(i) = Σ p̂(i,k) * F(k)_bev
权重分配:F̂_bev = p̂ · F̂
这种设计使得模型能够:
- 避免射线形状特征问题
- 学习更有判别性的几何表示
- 保持3D结构的一致性
多组并行设计
为了增强特征多样性,ViDAR采用了多组并行的Latent Rendering:
- 将256维特征分为16组,每组16维
- 每组独立进行潜在渲染
- 最后拼接得到完整的几何特征
实验表明,随着组数增加,性能持续提升:
| 组数 | 1 | 2 | 4 | 8 | 16 |
|---|---|---|---|---|---|
| NDS | 39.18 | 43.36 | 45.53 | 47.01 | 47.58 |
实验结果:全面的性能提升
点云预测能力
ViDAR在点云预测任务上显著超越现有方法:
| 时间范围 | 4D-Occ (LiDAR) | ViDAR (视觉) | 改进 |
|---|---|---|---|
| 1s预测 | 1.88 m² | 1.25 m² | -33% |
| 3s预测 | 2.11 m² | 1.73 m² | -18% |
令人惊喜的是,仅使用视觉输入的ViDAR竟然超越了使用LiDAR的方法!
下游任务全面提升
ViDAR在所有自动驾驶任务上都带来了显著提升:
感知任务
- 3D目标检测:NDS提升3.1%,mAP提升4.3%
- 语义占用预测:mIoU提升5.2%
- 地图分割:lane IoU提升1.9%
- 多目标跟踪:AMOTA提升6.1%
预测任务
- 运动预测:minADE减少10.7%,minFDE减少8.3%
- 未来占用预测:近距离VPQ提升2.7%,远距离VPQ提升2.5%
规划任务
- 碰撞率:降低14.8%
- 规划精度:L2误差减少18.8%
数据效率革命
ViDAR最令人印象深刻的优势在于大幅减少了对标注数据的依赖:
- 使用一半监督数据,ViDAR预训练的模型仍能超越全监督基线1.7% mAP
- 随着可用标注减少,ViDAR的优势越来越明显
- 在1/8数据量时,性能提升达到7.3% mAP
这意味着通过ViDAR,我们可以用一半的标注数据达到更好的性能!
技术亮点与创新
1. 统一的预训练范式
ViDAR首次提出了能够同时提升感知、预测和规划的统一预训练方法,这是端到端自动驾驶的重要突破。
2. 几何感知的特征学习
通过Latent Rendering,ViDAR学习到的特征具有更强的3D几何感知能力,这对自动驾驶至关重要。
3. 可扩展的数据利用
仅需Image-LiDAR序列,无需精确标注,使得大规模预训练成为可能。
4. 即插即用的架构
ViDAR可以与任何BEV编码器结合,具有良好的通用性。
实际应用价值
产业影响
- 降低开发成本:减少对昂贵3D标注的依赖
- 加速模型训练:提供更好的初始化权重
- 提升系统性能:在所有关键任务上都有显著提升
研究意义
- 新的预训练范式:为视觉自动驾驶提供了新的研究方向
- 理论创新:Latent Rendering为3D视觉任务提供了新的技术路径
- 基准设定:为未来相关研究提供了强基线
局限性与未来方向
当前局限
- 数据规模:主要在nuScenes数据集上验证,规模相对有限
- 计算复杂度:多组Latent Rendering增加了计算开销
- 泛化能力:跨数据集的泛化能力有待进一步验证
未来发展
研究团队计划:
- 扩大预训练数据规模
- 研究跨数据集的视觉点云预测
- 构建视觉自动驾驶的基础模型
总结:迈向可扩展的自动驾驶
ViDAR代表了视觉自动驾驶预训练的重大进步。通过巧妙的任务设计和技术创新,它解决了长期困扰该领域的核心问题:
✅ 统一建模:同时处理语义、几何和时序信息
✅ 数据高效:大幅减少对标注数据的依赖
✅ 性能优异:在所有关键任务上都有显著提升
✅ 可扩展性:为大规模预训练奠定基础
随着自动驾驶技术的快速发展,ViDAR这样的创新方法将为构建更安全、更智能的自动驾驶系统提供强有力的技术支撑。我们有理由相信,这一研究将推动整个行业向着更加成熟和实用的方向发展。