基于机器学习的赌博网站识别系统设计与实现
近年来,互联网赌博网站的泛滥不仅威胁网络安全,也带来了一系列社会问题。因此,设计一套高效的赌博网站识别系统具有重要意义。本论文设计并实现了一个基于机器学习的赌博网站识别系统,采用Spring Boot构建后端服务,Vue框架实现前端页面交互,利用Jsoup工具对网页数据进行爬取与解析,并基于贝叶斯算法完成赌博网站的分类识别。
首先,系统通过Jsoup对目标网页进行高效数据抓取,提取网站的标题、关键词、正文内容等特征,并对数据进行清洗与预处理。然后,利用自然语言处理技术构建特征向量,结合大量已标注数据对贝叶斯分类器进行训练,生成识别模型。模型训练后,系统能够对目标网站进行自动分类,并识别其是否为赌博网站。同时,设计了基于可视化的前端界面,展示识别结果,包括网站分类概率分布、特征贡献度等关键信息。
实验结果表明,本系统在赌博网站识别任务中具有较高的准确率和召回率,特别是在处理多样化网站数据时表现出较好的鲁棒性。系统还支持动态更新训练数据和模型优化,确保在面对新型赌博网站时依然能够保持高效识别性能。此外,本系统通过良好的架构设计,实现了模块化开发,具有较强的可扩展性。
本论文的研究成果为互联网安全提供了一种实用的技术手段,可广泛应用于网络安全审查、内容过滤以及违法网站监管等领域,对维护健康的网络环境具有重要意义。
关 键 词:赌博网站识别、贝叶斯算法、Spring Boot、Jsoup、网络安全
ABSTRACT
In recent years, the proliferation of Internet gambling websites not only threatens network security, but also brings a series of social problems. Therefore, designing an efficient gambling website recognition system is of great significance. This paper designs and implements a machine learning based gambling website recognition system, using Spring Boot to build backend services, Vue framework to implement frontend page interaction, using Jsoop tool to crawl and parse webpage data, and based on Bayesian algorithm to complete the classification and recognition of gambling websites.
Firstly, the system efficiently captures data from the target webpage through Jsoup, extracts features such as website titles, keywords, and main content, and cleans and preprocesses the data. Then, using natural language processing techniques to construct feature vectors, combined with a large amount of labeled data, the Bayesian classifier is trained to generate a recognition model. After model training, the system can automatically classify the target website and identify whether it is a gambling website. At the same time, a visualization based front-end interface was designed to display recognition results, including key information such as website classification probability distribution and feature contribution.
The experimental results show that this system has high accuracy and recall in the task of identifying gambling websites, especially exhibiting good robustness when dealing with diverse website data. The system also supports dynamic updating of training data and model optimization, ensuring efficient recognition performance when facing new gambling websites. In addition, this system has achieved modular development through a well-designed architecture and has strong scalability.
The research results of this paper provide a practical technical means for Internet security, which can be widely used in network security review, content filtering, illegal website supervision and other fields, and is of great significance for maintaining a healthy network environment.
KEY WORDS: Gambling website recognition, Bayesian algorithm Spring Boot、Jsoup、 network security
目 录
1 绪论
1.1 研究背景和意义
1.2 研究现状
1.3 系统设计思路
1.4 设计方法
2 相关技术介绍
2.1 B/S架构
2.2 贝叶斯算法
2.3 MySQL数据库
2.4 IDEA开发工具
3 系统需求分析
3.1 功能需求分析
3.2 非功能需求分析
3.3 可行性分析
3.3.1 时间可行性
3.3.2 经济可行性
3.3.3 技术可行性
3.4 系统业务流程
4 系统设计
4.1 系统界面设计
4.2 系统总体模块
4.3 E-R图
4.4 数据表设计
5 系统实现
5.1 首页页面
5.2 网站识别页面
5.3 个人中心页面
6 结论
参考文献
致 谢
随着互联网的迅猛发展,网络信息的传播速度和覆盖范围不断扩大,极大地促进了社会经济和文化的交流。然而,非法赌博网站的泛滥对社会带来了极大的负面影响。这些网站不仅破坏了互联网环境的安全性和公正性,还诱发了用户经济损失、网络诈骗、未成年人接触不良内容等问题,甚至成为洗钱和犯罪活动的重要渠道。因此,如何高效识别和拦截赌博网站已成为一个亟待解决的技术难题。
传统的赌博网站识别方法多依赖于人工规则与关键词匹配,这种方法虽简单易用,但难以应对赌博网站的多样化表现形式。例如,部分赌博网站通过使用动态生成内容、特殊字符替换、隐匿关键字等手段逃避检测,同时不断更新域名和页面结构以规避监管。基于此,仅依靠传统方法已无法有效应对这些复杂情况,需要引入更为智能和动态的技术手段。
机器学习作为近年来兴起的智能技术,已在文本分类、图像识别等领域取得了显著成效。通过训练分类模型,机器学习技术能够从大量数据中提取隐含模式,对未见数据进行准确预测。结合网络爬虫技术和自然语言处理技术,机器学习在赌博网站的自动识别中具备较大潜力。
本论文设计并实现了一套基于机器学习的赌博网站识别系统,采用Spring Boot构建后端服务,Vue实现前端交互界面,Jsoup用于网页数据的高效爬取,贝叶斯算法用于赌博网站的分类与识别。系统能够快速抓取目标网站的内容数据,提取并处理特征信息,通过训练好的分类模型完成赌博网站的自动识别。
该研究不仅丰富了机器学习技术在网络安全领域的应用,也为非法赌博网站的监管提供了一种高效的技术手段。系统可进一步扩展到其他非法网站的识别任务,如钓鱼网站和虚假广告网站,对促进互联网的健康发展具有重要意义。
随着非法赌博网站对社会和经济的威胁加剧,国内外学术界和产业界对赌博网站识别技术的研究日益深入。目前,相关研究主要集中在基于规则的传统方法和基于机器学习的智能方法两大方向。
传统方法主要依赖于人工规则匹配,例如关键词过滤、URL模式分析和域名黑名单等。以中国国家互联网应急中心(CNCERT)为例,该机构通过建立赌博网站关键字库和域名黑名单,对非法网站进行监测和封禁。然而,这种方法面临诸多挑战,尤其是赌博网站通过变换关键字、动态内容生成和使用特殊编码等方式规避检测。例如,某些赌博网站会将“赌博”替换为拼音、谐音或其他符号,如“du-bó”,增加了传统规则检测的难度。
近年来,基于机器学习的智能识别技术得到了广泛关注。例如,腾讯公司结合大数据和机器学习技术,在其“安全云镜”项目中成功应用了多种算法来识别包括赌博网站在内的非法网站。该系统通过提取网站的文本、图片及用户行为数据,利用深度学习技术构建分类模型,在多个非法网站检测竞赛中表现优异。此外,百度安全实验室也开发了基于贝叶斯分类和深度学习的网络内容过滤系统,通过分析网页结构、文本特征和行为轨迹,识别赌博网站的准确率达到90%以上。
国外研究方面,卡内基梅隆大学(Carnegie Mellon University)开发了一种基于自然语言处理(NLP)技术的网页分类系统,用于检测非法内容,包括赌博和色情网站。该系统通过提取网页标题、元数据和正文内容,结合机器学习算法进行分类,其对赌博网站的识别能力得到了广泛认可。此外,谷歌的“Safe Browsing”项目也在赌博网站识别中发挥了重要作用。通过构建庞大的网络数据库,并结合机器学习模型,谷歌能够对包含恶意行为的网站进行精准标记。
尽管上述研究和系统取得了一定成果,但仍存在一些问题亟待解决。一方面,赌博网站内容和表现形式的复杂性不断增加,例如利用加密流量、动态域名解析(DNS)以及隐匿内容,使得识别难度显著提升;另一方面,现有研究中缺乏实时动态更新的能力,难以应对新型赌博网站的快速变化。此外,现有技术更多地关注特定区域的赌博网站,缺乏跨地域、跨语言的普适性方法。
针对这些不足,本研究基于Spring Boot、Vue、Jsoup等技术,结合贝叶斯算法设计了一个高效的赌博网站识别系统,旨在提高系统的智能性和适应性,推动赌博网站识别技术的进一步发展。
本系统以高效、准确地识别赌博网站为目标,结合Spring Boot、Vue、Jsoup和贝叶斯算法,设计了一套模块化的赌博网站识别系统。系统设计包括以下四个主要方面:
数据采集与预处理模块
使用Jsoup工具对目标网站进行数据爬取,包括网站的标题、正文、关键词和元标签等内容。爬取数据后,进行清洗和标准化处理,剔除HTML标签、特殊字符及无关信息,并通过分词和去停用词操作生成文本特征,为后续分类模型提供高质量输入。
特征提取与建模模块
利用自然语言处理技术对网站文本内容进行特征提取,通过TF-IDF算法生成特征向量。然后,使用贝叶斯分类算法对样本数据进行训练,构建赌博网站识别模型。训练过程中对数据进行多次交叉验证,以提高模型的准确性和鲁棒性。
后端服务模块
基于Spring Boot框架实现系统的核心逻辑,包括数据管理、分类模型的调用和结果处理。后端服务支持动态更新训练数据和模型参数,同时提供API接口供前端调用。
前端展示与交互模块
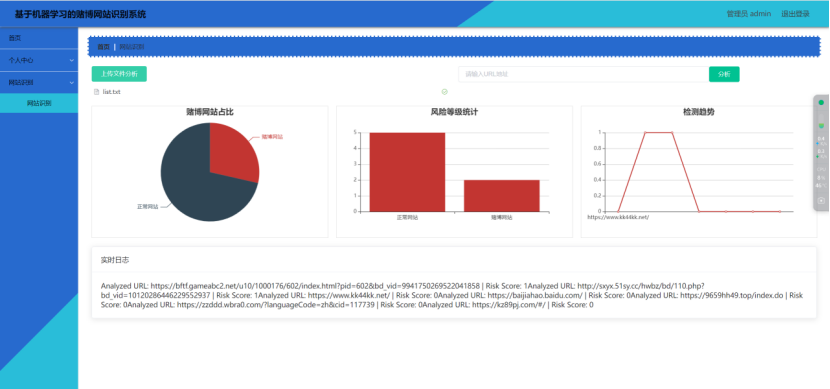
前端采用Vue框架实现用户界面,包括网站识别输入、识别结果展示和统计分析功能。系统通过可视化图表直观呈现识别结果,例如分类概率、主要特征贡献度和数据分布情况,提高用户体验和系统易用性。
在研究和设计赌博网站识别系统的过程中,不同的方法适应于不同的目标需求。研究方法的选择至关重要,正确的方法不仅提升效率,还能大大提高成果的质量。以下将针对赌博网站识别系统的研究方法进行逐一说明:
资料搜集法
资料搜集法是一种常用的研究方法,在系统设计和论文编写中尤为重要。互联网安全和赌博网站识别领域的发展经历了多个阶段,每个阶段都积累了大量宝贵的技术经验与理论知识。这些知识通常以论文、专利、技术报告等形式保存下来,供后人参考。在本研究中,通过查阅相关领域的文献、案例分析等方式,获取已有研究成果和技术框架。这种方法类似于数学问题中的公式应用,通过使用现有理论与方法,避免重复推导和验证,从而加快了研究进程。
比对分析法
比对分析法在技术研究和系统开发中同样具有重要作用。通过对比当前主流的赌博网站识别系统和本研究设计的系统,可以直观地了解自身系统的优劣势。例如,市场上已有的检测方法可能存在准确率低、扩展性差的问题,而的系统可以通过分析与改进逐步优化功能。此外,比对分析法还能帮助从不同角度完善模型算法,提升系统的识别性能。
需求调研法
需求调研法是一种以解决实际问题为核心的研究方法。在赌博网站识别系统的设计中,需求调研主要针对不同用户群体的需求展开。例如,如何提升系统的易用性和操作性?如何提高识别准确率和响应速度?这些问题不能仅凭主观假设完成,而是通过实际调研收集目标用户的反馈意见,结合真实使用场景进行分析。本系统的友好性设计也通过需求调研法获得了明确方向,例如界面交互的简化和分类结果的直观展示。
以上研究方法相辅相成,贯穿于赌博网站识别系统的整个设计与实现过程,为系统的高效开发和论文的科学性提供了重要保障。
基于B/S架构的赌博网站识别系统可以通过服务器端的统一更新,实现所有使用者端的功能同步升级。特别是在采用分布式部署的情况下,用户甚至无需感知系统的更新过程即可享受到最新版本的服务。对于系统的使用者而言,个人设备的性能要求极低。所有数据处理、算法运算和逻辑判断均在服务器端完成,仅需要一台能够运行浏览器的设备即可正常使用系统,这也极大降低了用户的硬件门槛。
此外,在系统的便利性方面,B/S架构的赌博网站识别系统进一步展现了其优势。用户无需安装任何额外的软件应用,只需通过浏览器访问指定的系统地址,无论是使用智能手机还是笔记本电脑,都可以轻松完成操作。无需安装客户端的特性不仅提高了使用的便捷性,也降低了用户的学习和使用成本,为系统的大规模推广和应用提供了保障。
基于机器学习技术的赌博网站识别系统结合B/S架构,在提升系统灵活性、易用性和扩展性的同时,也为用户提供了一种轻量化、高效化的使用体验。
贝叶斯算法是一种基于概率论的分类方法,其核心思想源于贝叶斯定理,利用已知条件的概率来推断未知事件的发生概率。在赌博网站识别系统中,贝叶斯算法因其简单、高效且具有良好的分类性能而被广泛采用。
具体而言,贝叶斯算法通过计算给定输入特征(如网站标题、关键词、正文内容等)属于某一类别(赌博网站或非赌博网站)的条件概率进行分类。该算法假设输入特征之间相互独立,利用训练数据学习每个类别的先验概率和特征的条件概率分布,从而在实际分类过程中快速计算后验概率,并根据最大后验概率原则将网站归类。
在本系统中,首先通过Jsoup爬取目标网站的文本数据,并对这些数据进行分词、去噪等预处理。然后使用贝叶斯算法构建分类器,对训练数据进行学习,生成用于识别赌博网站的模型。在实际应用中,该算法可快速处理大批量网站数据,并有效识别赌博相关特征,为系统提供高准确率和高效性保障。同时,通过动态更新训练样本,贝叶斯模型能够持续优化适应新型赌博网站的特征变化。
MySQL数据库是本系统中数据存储与管理的重要工具,凭借其高效、可靠和可扩展的特性,在赌博网站识别系统的设计与实现中发挥了关键作用。
MySQL负责存储系统所需的多种数据类型,包括网站爬取的原始数据、经过特征提取后的结构化信息、模型训练的样本数据以及识别结果。系统通过规范化的数据库设计,构建了多个功能表,如网站信息表、特征向量表和分类结果表,从而实现了数据的有序存储和快速查询。
MySQL提供了强大的事务处理能力和并发支持,使系统能够在高负载情况下保持数据的一致性与完整性。例如,当系统同时处理多个识别请求时,数据库事务确保每个请求的数据操作独立完成,避免因资源竞争导致的错误或数据丢失。
MySQL的索引机制和优化查询能力显著提升了系统的响应速度。在特征向量检索、分类结果存储和统计分析等操作中,合理设计索引提高了数据查询效率,为用户提供快速而精准的反馈。同时,通过与Spring Boot的无缝集成,系统可以灵活调用数据库接口,实现动态数据的更新与管理。
总之,MySQL数据库为赌博网站识别系统提供了强有力的支撑,为系统的高效运行和数据安全奠定了基础。
在赌博网站识别系统的开发过程中,IntelliJ IDEA作为主要的开发工具,为系统的设计与实现提供了全面的支持和便捷的开发环境。
IDEA支持Spring Boot框架的高效开发,提供了完善的代码补全、智能提示和快速导航功能,使开发人员能够专注于功能逻辑的实现。例如,通过内置的Spring Boot插件,可以快速创建项目模板,配置依赖环境,并简化启动和调试过程,从而提升开发效率。
IDEA具有强大的集成功能,与前端开发工具和数据库管理工具无缝协作。在本系统中,IDEA结合Vue.js的开发环境,实现了前后端分离架构的开发模式。同时,通过内置的数据库工具,开发者可以直接在IDEA中对MySQL数据库进行操作,包括查询、建表、索引优化等,从而减少了在多个工具之间切换的麻烦。
IDEA的调试功能为系统的开发和测试提供了保障。通过断点调试、变量监控和性能分析等功能,开发者可以快速定位问题并优化系统性能。在处理复杂的机器学习算法调用和网站爬取逻辑时,IDEA的调试工具显著提高了代码质量与开发效率。
总之,IntelliJ IDEA在赌博网站识别系统开发中的应用,为团队提供了高效的开发环境和强大的技术支持,助力系统功能的高质量实现。
基于机器学习的赌博网站识别系统的主要目标是自动识别互联网上的赌博网站,为用户提供精准的分类与风险评估。根据系统的设计要求,功能需求分析如下:
数据爬取与预处理
系统需要能够从互联网上爬取大量网站数据,主要包括网页的文本内容、标题、URL等信息。通过使用Jsoup等工具,系统能够高效抓取网页数据,并对爬取的内容进行清洗、去噪和格式化处理,为后续的特征提取和分类模型训练做准备。
特征提取与分析
系统需要从爬取的网页中提取有效特征,如关键词、域名特征、页面内容密度等,构建特征向量。通过对不同网站特征的分析,系统能够识别出赌博网站的典型特征,并为模型训练提供数据支持。
机器学习模型训练与分类
系统使用贝叶斯算法等机器学习方法,对已标注的赌博网站数据进行训练,构建一个高效、精准的分类模型。该模型能够根据输入的特征信息对新的网站进行自动分类,判断其是否为赌博网站。
实时检测与反馈
系统需要提供实时的网站检测功能,用户可以输入网站URL,系统即时返回该网站是否为赌博网站的结果。同时,系统应能够显示相关的风险评估信息,如网站风险等级等,为用户提供安全建议。
数据存储与管理
系统需要将爬取的数据、特征信息和分类结果存储在MySQL数据库中,确保数据的长期管理和查询功能,支持后续的分析和模型优化。
通过上述功能需求,系统将能够高效、准确地识别赌博网站,并为用户提供安全保障。
非功能需求是指系统在性能、可用性、安全性等方面的要求,这些需求对于系统的稳定性和用户体验至关重要。针对基于机器学习的赌博网站识别系统,非功能需求分析如下:
性能要求
系统应具备高效的数据处理能力,能够在短时间内处理大量网站数据,尤其在爬取和特征提取阶段,要求能快速响应并完成任务。此外,系统的分类模型应具备较高的预测速度,能够实现网站URL的实时识别和快速反馈,确保用户能够即时获得识别结果。
可用性要求
系统的用户界面应简洁直观,便于用户操作。前端设计需要考虑到用户体验,确保用户能够方便地输入网址并查看识别结果。后端系统应稳定可靠,支持多用户同时访问,能够应对高并发场景,避免因系统故障影响用户使用。
安全性要求
系统必须保证数据的安全性,尤其是用户输入的敏感信息(如网址)。数据传输应使用加密协议(如HTTPS)保障安全,同时,系统在处理爬取的数据时应进行去标识化处理,避免泄露用户隐私。数据库存储的数据也应做好访问控制和备份,以防止数据丢失或遭受攻击。
可维护性与扩展性要求
系统应具备良好的可维护性,代码结构清晰、模块化,便于后期的优化和功能扩展。随着新的赌博网站类型和特征的出现,系统应能够轻松更新训练数据集,并通过在线学习或重新训练模型的方式,保持高效的识别能力。
通过以上非功能需求的设计,系统能够在保证高效性、安全性和易用性的前提下,提供长时间的稳定运行,并支持未来的扩展与优化。
对于基于机器学习的赌博网站识别系统而言,首先需要确保项目的时间可行性。时间可行性是项目成功实施的基本标准,虽然对系统的设计和预期功能充满信心,但如果开发周期过长,超出预定的时间框架,且需要过多的资源和团队支持,那么这个项目的时间可行性就无法得到保证。时间可行性是指项目在规划的时间范围内完成的可能性。如果该系统的开发工作超出了预定的开发周期,例如超过两三年的时间,并且需要大量的技术团队来协作,那么这个时间框架显然不可行。因此,项目的时间可行性必须在合理的期限内进行评估和调整,确保能够在规定的时间内顺利完成开发与部署。
在基于机器学习的赌博网站识别系统中,经济可行性是一个至关重要的考虑因素。经济可行性可以理解为完成该项目所需的资金和资源,就像在一定预算下购买所需的物品一样。在评估系统的经济可行性时,需要考虑到开发该系统的整体费用,包括硬件设备、软件工具和技术支持等。首先,选择商业化的数据库或开发工具可能会产生额外的费用,这对于毕业设计项目来说是不合适的。因为的项目预算是有限的,而且毕业设计通常要求在经济上可承受,所以应该选择开源的、免费的技术和工具来实现系统功能。
在进行毕业设计时,经济可行性是最初需要评估的因素之一。为了实现系统的功能需求,无需采用高成本的商业解决方案,选择开源的框架和工具是完全可行且符合预算要求的。作为学生,通常无法承担高昂的费用,因此,必须确保选择的技术和工具符合预算限制,确保项目的经济可行性。
在基于机器学习的赌博网站识别系统中,技术可行性是评估项目是否能够顺利实施的关键因素。技术可行性主要涉及在现有的技术条件下,如何有效地解决问题。在本项目中,所使用的技术大多是在大学课程中学到的,这使得能够利用已有的知识和资源来解决技术难题。通过选择熟悉且易于实现的技术,可以减少开发过程中可能遇到的困难,确保项目能够顺利推进。
此外,避免选择非开源的技术或工具,以减少许可费用和技术实施上的难度。开源技术具有广泛的社区支持和丰富的文档资源,这大大简化了技术实现过程。因此,通过选择开源的编程语言和框架,如Python、Vue.js等,可以确保技术实施的灵活性和高效性,同时也提高了系统的可维护性和扩展性。
总体而言,技术可行性在本项目中得到了充分保证,采用的技术方案符合现有技术条件,能够有效支持系统的设计与实现,从而大大降低了技术实施的难度。
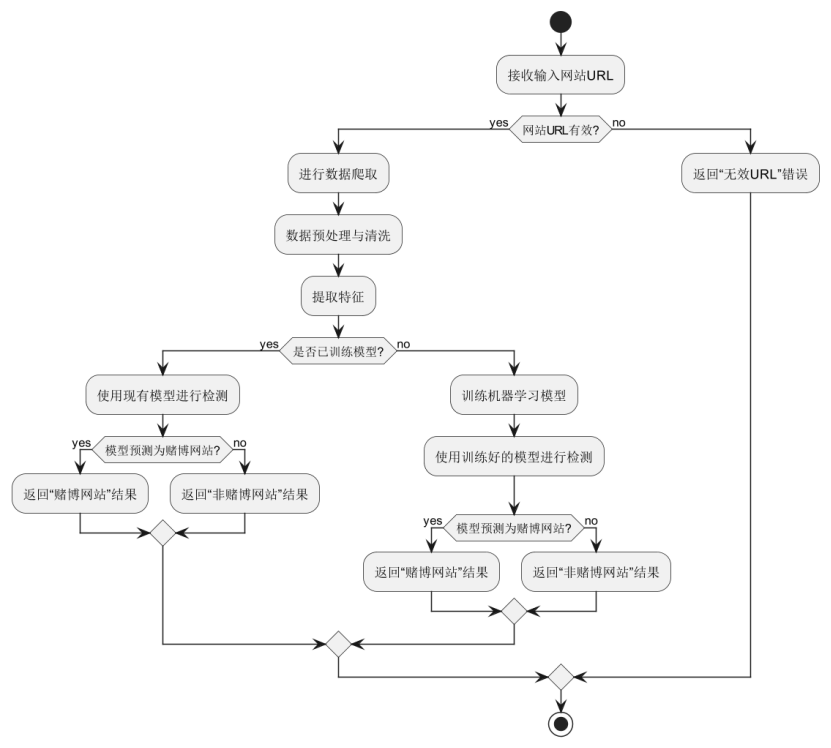
基于机器学习的赌博网站识别系统的业务流程图展示了系统从接收输入到返回结果的完整过程。首先,系统接收用户输入的URL并进行有效性检查。如果URL无效,系统直接返回“无效URL”的错误提示,结束流程。若URL有效,系统开始爬取该网站的数据,并进行必要的预处理与清洗。接着,系统提取网站的特征,为后续的机器学习模型检测做准备。
如果已有训练好的机器学习模型,系统将直接使用该模型进行预测,并判断该网站是否为赌博网站。如果模型预测为赌博网站,系统返回“赌博网站”结果;若为非赌博网站,则返回相应结果。若系统没有现成的训练模型,则首先启动模型训练过程,完成后再使用训练好的模型进行预测,最终得出网站的分类结果。
整个流程中,系统通过多个条件判断(if-else)来确保业务逻辑的正确执行。通过这种多分支的设计,系统能够灵活地处理不同的情境,如URL有效性、模型是否存在等,从而确保对每个网站进行准确有效的分类判断,提供用户所需的识别结果。这种设计方式有效地保证了系统的鲁棒性和可扩展性。业务流程图如下: