基于数据驱动来写提示词(一)
序
本篇由来,在COC上我当面感谢了组委会和姜宁老师,随即被姜宁老师催稿,本来当天晚上写了一个流水账,感觉甚为不妥。于是决定慢慢写,缓缓道来。要同时兼顾Show me the code,Show me the vide。希望能形成一个从不同侧面观测我自己Community Over Code 2025参会心的,收获的内容集合。
感觉这个系列正慢慢变成一场开发过程的图文慢直播,肯能有助于大家一步一步的从零开始构建自己的Agent。
我定了一个番茄钟,每天写稿大概1~2个钟,写到哪儿算哪儿。
今天也对内容进行了调整把前略改成附录了,颇有一种写论文的感觉。
BTW,知乎我一般隔一天发。插曲可以TL;DR。
词汇表
异人智能,我从KK和建忠老师的直播,个人笔记,了解到的词汇,我很喜欢。大家请自行替换为大模型,Agent就好了。
kv_cache数据在说话
https://api-docs.deepseek.com/zh-cn/guides/kv_cache
上文说到token爆炸了,认认真真的开始做实验。比如我们读一篇文章,要做ABCDE,一个提示词大模型注意力不够的时候我们势必要拆两个提示词来处理任务。任务太多了大模型做完A就不管E了。
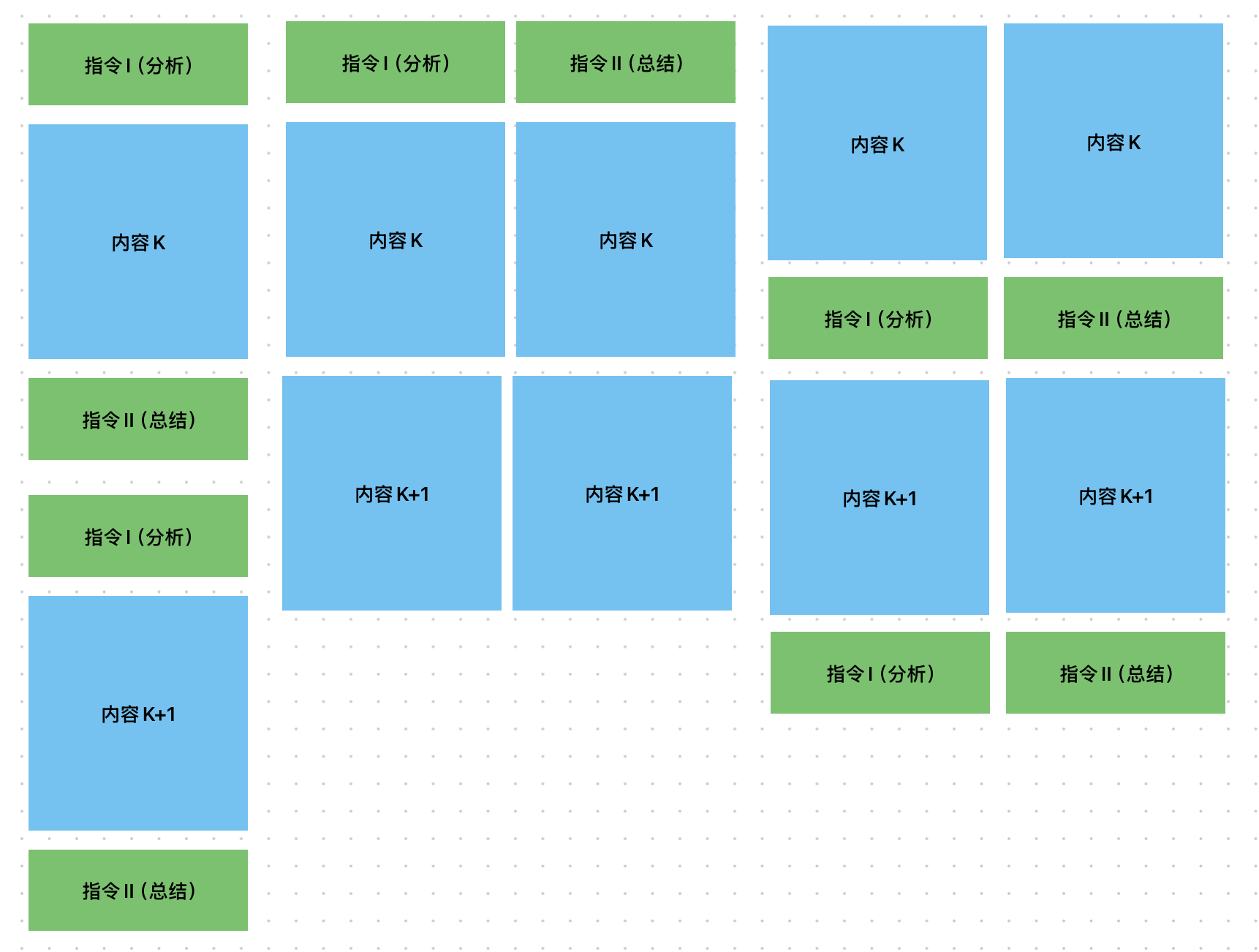
我们要做一个文章内容分析的Agent,那么文章的段落用蓝色的内容K以归纳法,K,K+1到N表示。而我们分析的内容一指令I,指令II到指令XX表示。
万万没想到实验结果居然是这样的。
前置提示词(逻辑处理)
那么此时,如果我们按照逻辑循序处理(最左边)
那么实际上只有