猫头虎AI分享| 智谱开源了为 RL scaling 设计的 LLM post‑training 框架用于GLM-4.5强化学习训练:slime
猫头虎AI分享|智谱开源了用于GLM-4.5的强化学习训练框架:slime 为 RL scaling 设计的 LLM post‑training 框架
在大规模语言模型(LLM)的后训练过程中,强化学习(RL)已经成为优化模型性能的重要手段。智谱AI推出了一个专为强化学习扩展(RL scaling)设计的post-training框架——slime,它为模型训练提供了两大核心功能:高效的训练支持和灵活的数据生成流程。通过将Megatron与SGLang结合,slime能够支持包括稠密模型、混合专家模型等多种大规模模型的训练。它为开发者提供了包括多轮对话、工具调用、监督微调等多种场景的应用示例,可以帮助开发者快速上手,并进行定制化的训练流程。
GitHub:slime GitHub Repository:https://github.com/THUDM/slime

文章目录
- 猫头虎AI分享|智谱开源了用于GLM-4.5的强化学习训练框架:**slime** 为 RL scaling 设计的 LLM post‑training 框架
- **slime** 框架介绍
- **框架架构**
- **模块说明**
- **快速开始**
- **环境准备**
- **示例**
- **Dense模型示例:GLM-4-9B 与 Qwen3-4B**
- **MoE模型示例:GLM-4.5、Qwen3-30B-A3B 与 DeepSeek-R1**
- **多轮对话 + 工具调用示例:Search-R1 lite**
- **SFT示例:Qwen3-4B-Base + OpenHermes-2.5**
- **Checkpoint 格式转换**
- **HF → Megatron torch\_dist ckpt**
- **Megatron torch\_dist → HF ckpt**
- **任意 Megatron ckpt → HF**
- **启动训练流程**
- **参数说明**
- **开发指南**
slime 框架介绍
slime 旨在为大规模语言模型的后训练(post-training)提供高效支持,特别是在强化学习训练的过程中。它通过结合Megatron和SGLang,提供了以下两大核心功能:
- 高性能训练:通过将Megatron与SGLang结合,支持各种训练模式下的高效训练。
- 灵活的数据生成:通过自定义的数据生成接口以及基于服务器的引擎,支持任意训练数据生成流程。
slime 支持的模型包括:稠密模型(如GLM-4-9B、Qwen3-4B),混合专家模型(如GLM-4.5、Qwen3-30B-A3B、DeepSeek-R1)等。
框架架构
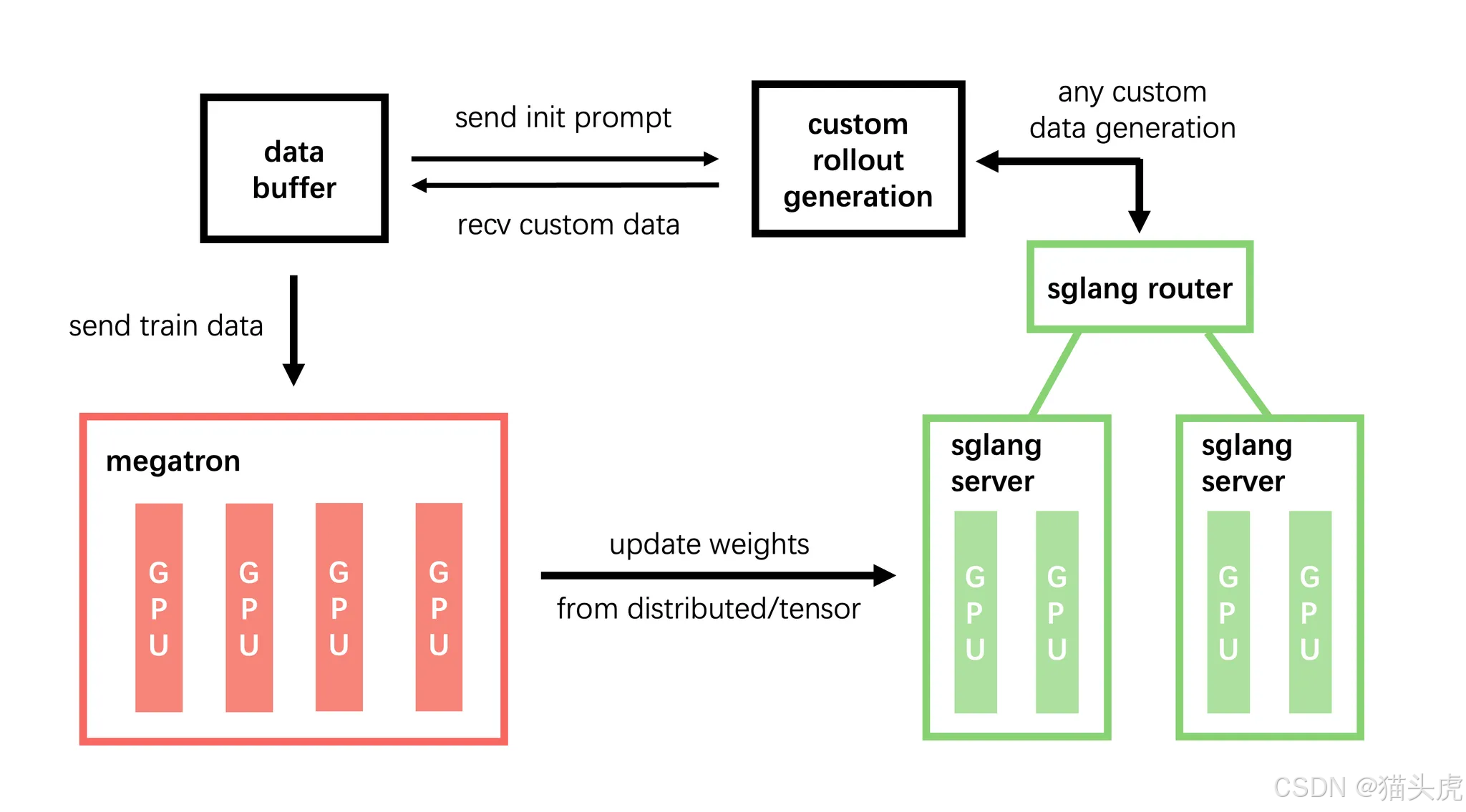
模块说明
- training (Megatron):负责模型的主训练流程,从Data Buffer读取数据,训练完成后将模型参数同步到rollout模块。
- rollout (SGLang + router):根据训练的需求生成新数据(含reward和verifier),将这些数据存储至Data Buffer。
- data buffer:作为数据管理模块,负责管理prompt初始化、自定义数据和rollout生成的数据。
快速开始
环境准备
我们提供了基于镜像 zhuzilin/slime:latest(已经预装了SGLang 0.4.7和Megatron)的环境,您可以快速开始使用:
docker run --rm --gpus all --ipc=host --shm-size=16g \--ulimit memlock=-1 --ulimit stack=67108864 \-it zhuzilin/slime:latest /bin/bashgit clone https://github.com/THUDM/slime.git
cd slime
pip install -e .
如果您的环境无法使用 Docker,您可以参考以下文档,手动搭建环境:
- 从零搭建环境
- AMD 使用教程
示例
Dense模型示例:GLM-4-9B 与 Qwen3-4B
我们提供了关于GLM-4-9B和Qwen3-4B的使用示例,可以帮助您快速上手:
- 示例:GLM-4-9B
- 示例:Qwen3-4B
MoE模型示例:GLM-4.5、Qwen3-30B-A3B 与 DeepSeek-R1
对于混合专家模型(MoE),我们提供了以下示例:
- 示例:64xH100 训练 GLM-4.5
- 示例:8xH100 训练 Qwen3-30B-A3B
- 示例:128xH100 训练 DeepSeek-R1
多轮对话 + 工具调用示例:Search-R1 lite
针对多轮对话和工具调用场景,我们提供了一个简化版的Search-R1复现,具体示例如下:
- 示例:Search-R1 lite
SFT示例:Qwen3-4B-Base + OpenHermes-2.5
除了RL训练,slime 还支持监督微调(SFT),相关示例请参考:
- 示例:Qwen3-4B-Base + OpenHermes-2.5
Checkpoint 格式转换
由于slime使用Megatron,而Megatron不支持直接加载Huggingface的checkpoint格式,因此我们提供了一个转换工具mbridge,帮助将HF checkpoint转换为Megatron支持的torch_dist格式。
HF → Megatron torch_dist ckpt
cd slime/source scripts/models/glm4-9B.sh
PYTHONPATH=/root/Megatron-LM python tools/convert_hf_to_torch_dist.py \${MODEL_ARGS[@]} \--hf-checkpoint /root/GLM-Z1-9B-0414 \--save /root/GLM-Z1-9B-0414_torch_dist
Megatron torch_dist → HF ckpt
在训练过程中生成的torch_dist checkpoint可以转换回HF的checkpoint格式:
cd slime/
PYTHONPATH=/root/Megatron-LM python tools/convert_torch_dist_to_hf.py \--input-dir /path/to/torch_dist_ckpt/iter_xxx/ \--output-dir /root/GLM-Z1-9B-0414-iter_xxx \--origin-hf-dir /root/GLM-Z1-9B-0414
任意 Megatron ckpt → HF
如果您使用的是自定义保存格式(如--ckpt-format torch),可以使用以下方式将Megatron格式的checkpoint转化为HF格式:
torchrun --nproc_per_node ${NUM_GPU} tools/convert_to_hf.py \--load /your/saved/megatron_ckpt \--output-dir /your/converted/hf_ckpt \... # 其他训练 args
启动训练流程
整个训练流程基于Ray进行管理,首先需要启动Ray集群:
# Node0(HEAD)
ray start --head --node-ip-address ${MASTER_ADDR} \--num-gpus 8 --disable-usage-stats# 其他 Node
ray start --address=${MASTER_ADDR}:6379 --num-gpus 8
在Ray集群启动后,可以在Node0提交任务:
ray job submit --address="http://127.0.0.1:8265" \--runtime-env-json='{"env_vars": { ... }}' \-- python3 train.py \--...(其他 Megatron/SGLang/slime 参数)
参数说明
在训练过程中,参数分为三类:
- Megatron 参数:这些参数可以通过
--tensor-model-parallel-size 2等方式进行配置。 - SGLang 参数:需要以
--sglang前缀传入,例如--sglang-mem-fraction-static。 - slime 自身的参数:具体参数请参考slime/utils/arguments.py。
开发指南
- 欢迎贡献! 若有功能建议、性能调优或使用体验反馈,欢迎提交 Issue / PR 😊
- 使用 pre-commit 保证提交代码风格:
apt install pre-commit -y
pre-commit install
- 调试技巧请参考 debug 指南。
总结:
智谱AI推出的slime框架为大规模语言模型的后训练提供了极大的便利,特别是在强化学习扩展(RL scaling)方面的创新,使得开发者能够以高效和灵活的方式进行模型训练。无论是稠密模型还是混合专家模型,slime 都能够为各种模型提供强大的支持,帮助开发者实现更复杂的应用场景。通过丰富的示例与详细的文档,开发者可以快速上手,开始自己的训练与微调任务。
GitHub:slime GitHub Repository:https://github.com/THUDM/slime