大模型推理框架vLLM 中的Prompt缓存实现原理
背景:为什么需要Prompt缓存模块?
在大模型问答多轮对话应用场景中,不同请求的 Prompt 往往有相同的前缀,比如:
第一次问答:
你是一名专业的电子产品客服,负责回答客户关于手机产品的咨询。请根据以下问题提供准确、友好的回答。
当前产品库支持查询的品牌包括:Apple、华为、小米、三星。用户问题:
iPhone 16 的电池容量是多少?
模型回答:
iPhone 16 的电池容量为 3227 mAh。第二次问答:
(保留之前所有上下文)
你是一名专业的电子产品客服...(同上)用户问题:
iPhone 16 的电池容量是多少?
模型回答:
iPhone 16 的电池容量为 3227 mAh.用户新问题:
那它的快充功率呢?
模型回答:
iPhone 16 支持 20W 快充。两轮问答请求中,系统预设的客服角色描述、产品库范围等前缀内容完全一致,这就会导致模型推理流程:
每次都从头计算整个 Prompt 的 attention
重复计算前缀浪费算力
Prefix Cache 通过缓存这个已计算好的 Prompt 编码结果(KV 对)直接复用,前面的结果会存储在GPU缓存中,生成时只算后半部分。
这里说的Prompt缓存实际是vLLM中Prefix Cache的实现
vLLM 的 Prefix Cache 原理
vLLM 中的 Prefix Cache 是基于 KV Cache 的静态共享机制,主要思路:
前缀哈希(Prefix Hashing)
将 Prompt 转成 token 序列后计算哈希值
相同 token 序列的哈希值相同
哈希值作为缓存 key
存储 KV 对(Key/Value Tensors)
KV 对是 attention 层计算后的结果
存在 GPU 显存中(或部分放在 CPU 内存)
复用机制(Reuse)
当新的请求到来时,如果前缀哈希匹配,就直接加载已有的 KV 对
只需对新增的 token 做计算
分页管理(PagedAttention 兼容)
Prefix Cache 依旧用 page(block)方式管理
可与普通 KV Cache 混用,不影响批处理
工作流程:
以一次批处理请求为例:
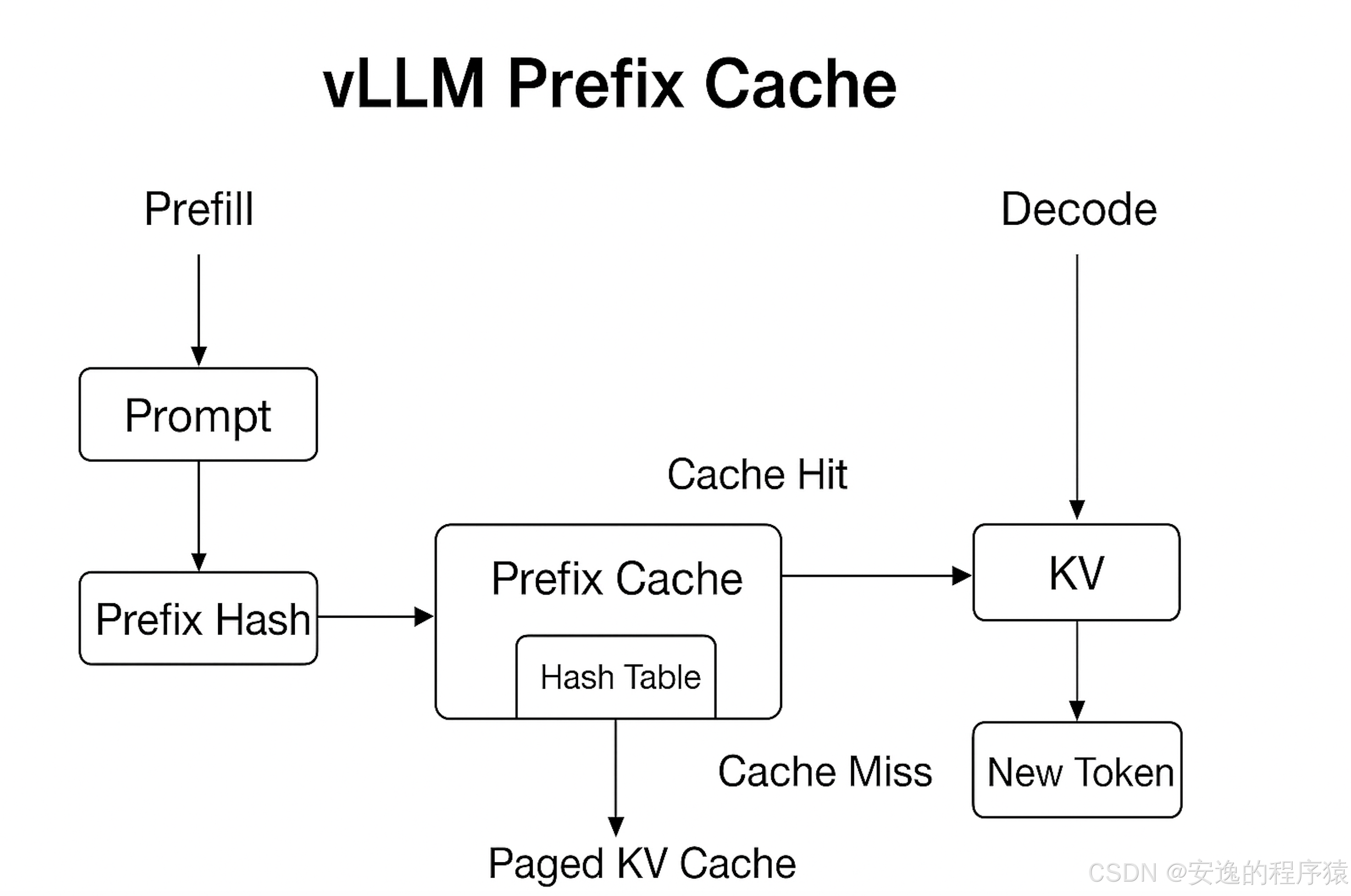
Prefill 阶段
Tokenizer 将输入文本转成 token 序列
对序列做哈希(如 MurmurHash)
检查哈希表:
命中:直接取 KV 对 → 进入生成阶段
未命中:计算 KV 对并存入哈希表
Decode 阶段
使用已缓存的 KV 对作为上下文
新 token 持续追加到 KV Cache
这样的好处是可以减少重复计算:多个请求共享相同前缀的计算结果,同时加速批处理:常见系统提示(system prompt)复用率很高