2024年ASOC SCI1区TOP:改进灰狼算法IGWO+股票指数收益预测,深度解析+性能实测
目录
- 1.摘要
- 2.灰狼算法GWO原理
- 3.改进策略
- 4.结果展示
- 5.参考文献
- 6.代码获取

1.摘要
股票指数收益预测是商业经理和投资者进行资产配置与投资决策的重要依据,为提高预测精度,本文提出了一种基于改进灰狼算法(IGWO)与树突神经模型(DNM)相结合的模型。DNM具有更透明的结构、较强的非线性处理能力,并具备独特的自动修剪机制,能够有效应对金融市场的复杂性。IGWO为全局和局部搜索算法开发了用于动态平衡的非线性控制参数,引入混沌理论来优化灰狼的权重分配,Alpha狼局部搜索策略。
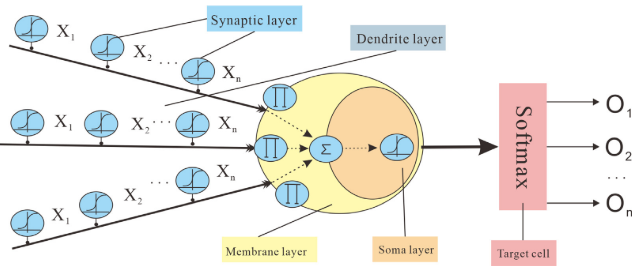
2.灰狼算法GWO原理
【智能算法】灰狼算法(GWO)原理及实现
3.改进策略
非线性探索因子
探索率的设置对灰狼探索区域的影响较大,并且是平衡前期探索和后期局部搜索的关键。GWO算法基于线性递减,在某些不规则数据结构中未能充分关注当前位置附近的解,采用非线性探索因子:
θ = i t e r a t i o n M a x i t e r \theta=\frac{\mathrm{iteration}}{\mathrm{Max~iter}} θ=Max iteriteration
φ = ( 1.5 − 1 1 + e − 15 ( θ − 0.6 ) ) × 1.2 \varphi=\left(1.5-\frac{1}{1+e^{-15(\theta-0.6)}}\right)\times1.2 φ=(1.5−1+e−15(θ−0.6)1)×1.2
a = 2 ( ( cos ( tanh ( θ ) ) 2 + ( θ sin ( π θ ) ) 5 ) ( tanh ( 1 ) ) 2 ⋅ π 2 ) 2 ⋅ φ a=2\left(\frac{\left(\cos(\tanh(\theta))^2+(\theta\sin(\pi\theta))^5\right)}{(\tanh(1))^2}\cdot\frac{\pi}{2}\right)^2\cdot\varphi a=2((tanh(1))2(cos(tanh(θ))2+(θsin(πθ))5)⋅2π)2⋅φ
领导权重分布
IGWO采用混沌映射函数利用进化法则的确定性特性、长期行为的不可预测性以及迭代过程中搜索多样性的增加,有助于全局搜索首狼的权重。混沌状态有助于算法快速找到最优解并加速收敛:
ω t = i t e r a t i o n M a x i t e r \omega_t=\frac{iteration}{Max_iter} ωt=Maxiteriteration
ω t + 1 = 0.7 + 0.1 ⋅ sin ( a ⋅ π ⋅ ω t ) + 0.1 ⋅ cos ( b ⋅ π ⋅ ω t ) \omega_{t+1}=0.7+0.1\cdot\sin(a\cdot\pi\cdot\omega_{t})+0.1\cdot\cos(b\cdot\pi\cdot\omega_{t}) ωt+1=0.7+0.1⋅sin(a⋅π⋅ωt)+0.1⋅cos(b⋅π⋅ωt)
ω t + 1 ′ = 1 2 ( 1 − ω t + 1 ) \omega_{t+1}{}^{\prime}=\frac{1}{2}\left(1-\omega_{t+1}\right) ωt+1′=21(1−ωt+1)
X i , j t + 1 = ω t + 1 ⋅ X α , j t + 1 + ω t + 1 ′ ⋅ X β , j t + 1 + ω t + 1 ′ ⋅ X δ , j t + 1 X_{i,j}^{t+1}=\omega_{t+1}\cdot X_{\alpha,j}^{t+1}+\omega_{t+1}{^{\prime}}\cdot X_{\beta,j}^{t+1}+\omega_{t+1}{^{\prime}}\cdot X_{\delta,j}^{t+1} Xi,jt+1=ωt+1⋅Xα,jt+1+ωt+1′⋅Xβ,jt+1+ωt+1′⋅Xδ,jt+1
α \alpha α狼局部搜索
结合sin和cos函数,IGWO在局部探索过程中进行随机扰动。当狼群离leader越远时,两者产生的值越小,这意味着当个体离leader越远时,个体更容易被激励去探索新的解。
f = exp ( − α ⋅ ( t − t 0 ) ) f=\exp(-\alpha\cdot(t-t_0)) f=exp(−α⋅(t−t0))
d = ∥ X α , j t − X i , j t ∥ d=\|X_{\alpha,j}^t-X_{i,j}^t\| d=∥Xα,jt−Xi,jt∥
λ = f ⋅ exp ( − β ⋅ d 2 ) ⋅ ( cos ( γ π d ) ⋅ sin ( γ π d ) ) \lambda=f\cdot\exp(-\beta\cdot d^2)\cdot(\cos(\gamma\pi d)\cdot\sin(\gamma\pi d)) λ=f⋅exp(−β⋅d2)⋅(cos(γπd)⋅sin(γπd))
X i , j t + 1 = X α , j t − λ d X_{i,j}^{t+1}=X_{\alpha,j}^{t}-\lambda d Xi,jt+1=Xα,jt−λd
伪代码

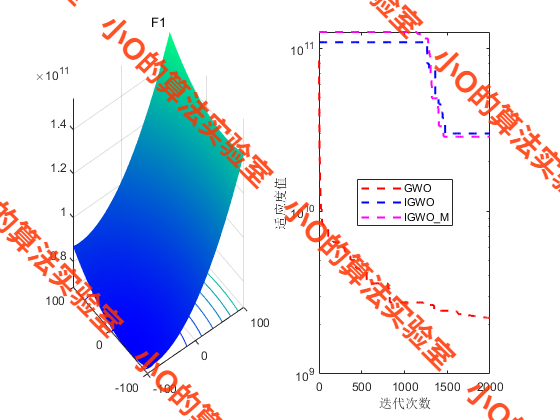
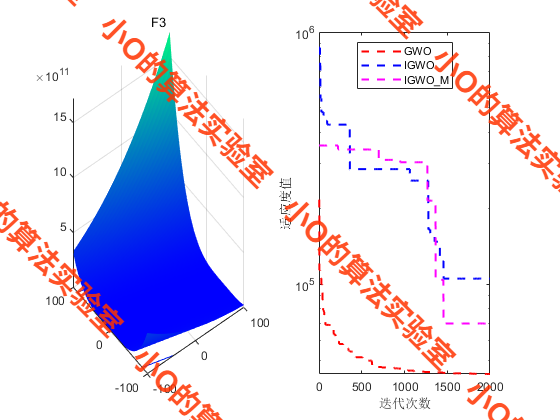
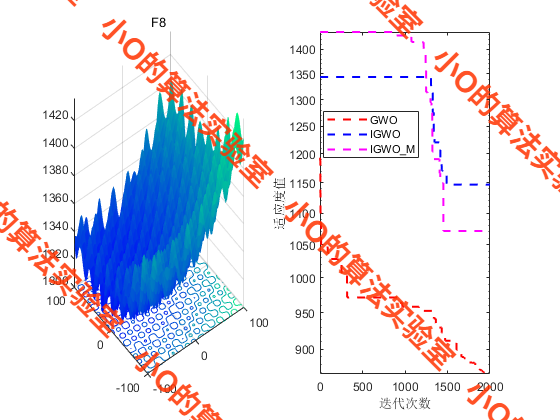
4.结果展示
PS:在用CEC2017测试,其实遇到了一些问题,从流程图那里for each leader使用Levy飞行扰动,似乎并不能像原GWO有更好地引导作用。这里我注释掉了这一段,名为IGWO_M进行对比。
X i , j t + 1 = X i , j t + L ⋅ ( X α , j t − X i , j t ) X_{i,j}^{t+1}=X_{i,j}^{t}+L\cdot\left(X_{\alpha,j}^{t}-X_{i,j}^{t}\right) Xi,jt+1=Xi,jt+L⋅(Xα,jt−Xi,jt)
5.参考文献
[1] Wang R. A modified grey wolf optimization-based dendritic neural model for stock index return prediction[J]. Applied Soft Computing, 2024, 167: 112305.