MuJoCo 机械臂 PPO 强化学习逆向运动学(IK)

视频讲解:
MuJoCo 机械臂 PPO 强化学习逆向运动学(IK)
代码仓库:https://github.com/LitchiCheng/mujoco-learning
结合上期视频,我们安装了stable_baselines3和gym,今天用PPO尝试强化学习得到关节空间到达给定末端位置的实现过程,如下是几个关键的地方:
创建动作空间和观测空间以及目标位置
# 动作空间,7个关节
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(7,))
# 观测空间,包含关节位置和目标位置
self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(7 + 3,))
self.goal = np.random.uniform(-0.3, 0.3, size=3)step函数,增加碰撞的惩罚和末端位姿的惩罚,同时mujoco viewer渲染显示
def step(self, action):self.data.qpos[:7] = actionmujoco.mj_step(self.model, self.data)achieved_goal = self.data.body(self.end_effector_id).xposreward = -np.linalg.norm(achieved_goal - self.goal)reward -= 0.3*self.data.nconterminated = np.linalg.norm(achieved_goal - self.goal) < 0.01truncated = Falseinfo = {'is_success': terminated}obs = np.concatenate([self.data.qpos[:7], achieved_goal])mujoco.mj_forward(self.model, self.data)mujoco.mj_step(self.model, self.data)self.handle.sync()return obs, reward, terminated, truncated, info网络设计和模型超参设置
策略网络(Policy Network):
输入层 -> 隐藏层1 (256个神经元, ReLU激活) -> 隐藏层2 (128个神经元, ReLU激活) -> 输出层(动作概率分布)
值网络(Value Network):
输入层 -> 隐藏层1 (256个神经元, ReLU激活) -> 隐藏层2 (128个神经元, ReLU激活) -> 输出层(状态价值估计)
policy_kwargs = dict(activation_fn=nn.ReLU,net_arch=[dict(pi=[256, 128], vf=[256, 128])]
)model = PPO("MlpPolicy",env,policy_kwargs=policy_kwargs,verbose=1,n_steps=2048,batch_size=64,n_epochs=10,gamma=0.99,learning_rate=3e-4,device="cuda" if torch.cuda.is_available() else "cpu"
)完整代码
import numpy as np
import mujoco
import gym
from gym import spaces
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
import torch.nn as nn
import warnings
import torch
import mujoco.viewer# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="stable_baselines3.common.on_policy_algorithm")class PandaEnv(gym.Env):def __init__(self):super(PandaEnv, self).__init__()self.model = mujoco.MjModel.from_xml_path('/home/dar/MuJoCoBin/mujoco-learning/franka_emika_panda/scene.xml')self.data = mujoco.MjData(self.model)self.end_effector_id = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, 'link7')self.handle = mujoco.viewer.launch_passive(self.model, self.data)self.handle.cam.distance = 3self.handle.cam.azimuth = 0self.handle.cam.elevation = -30# 动作空间,7个关节self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(7,))# 观测空间,包含关节位置和目标位置self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(7 + 3,))self.goal = np.random.uniform(-0.3, 0.3, size=3)print("goal:", self.goal)self.np_random = None def reset(self, seed=None, options=None):if seed is not None:self.seed(seed)mujoco.mj_resetData(self.model, self.data)self.goal = self.np_random.uniform(-0.3, 0.3, size=3)print("goal:", self.goal)obs = np.concatenate([self.data.qpos[:7], self.goal])return obs, {}def step(self, action):self.data.qpos[:7] = actionmujoco.mj_step(self.model, self.data)achieved_goal = self.data.body(self.end_effector_id).xposreward = -np.linalg.norm(achieved_goal - self.goal)reward -= 0.3*self.data.nconterminated = np.linalg.norm(achieved_goal - self.goal) < 0.01truncated = Falseinfo = {'is_success': terminated}obs = np.concatenate([self.data.qpos[:7], achieved_goal])mujoco.mj_forward(self.model, self.data)mujoco.mj_step(self.model, self.data)self.handle.sync()return obs, reward, terminated, truncated, infodef seed(self, seed=None):self.np_random = np.random.default_rng(seed)return [seed]if __name__ == "__main__":env = make_vec_env(lambda: PandaEnv(), n_envs=1)policy_kwargs = dict(activation_fn=nn.ReLU,net_arch=[dict(pi=[256, 128], vf=[256, 128])])model = PPO("MlpPolicy",env,policy_kwargs=policy_kwargs,verbose=1,n_steps=2048,batch_size=64,n_epochs=10,gamma=0.99,learning_rate=3e-4,device="cuda" if torch.cuda.is_available() else "cpu")model.learn(total_timesteps=2048*50)model.save("panda_ppo_model")过程中显示运动,很疯狂。。。
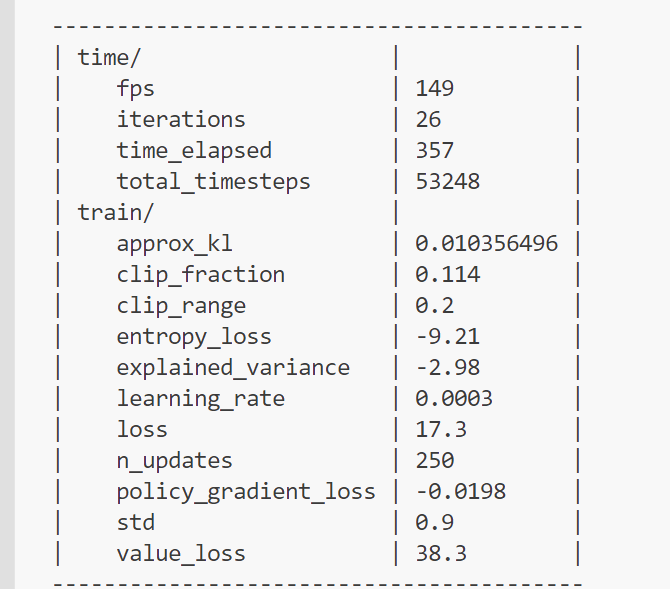
过程中会输出每轮的训练信息
最后在接近的位置疯狂抽搐收敛。。。