Note4:Self-Attention
目录
应用
输出形式
Self-Attention实现Sequence Labeling
self-attention原理
Query(Q)、Key(K)、Value(V)
从矩阵乘法理解self-attention过程
全过程
Multi-head Self-Attention(多头注意力)介绍
Positional Encoding(位置编码)
其他应用
1. NLP
2. Speech
3. Image
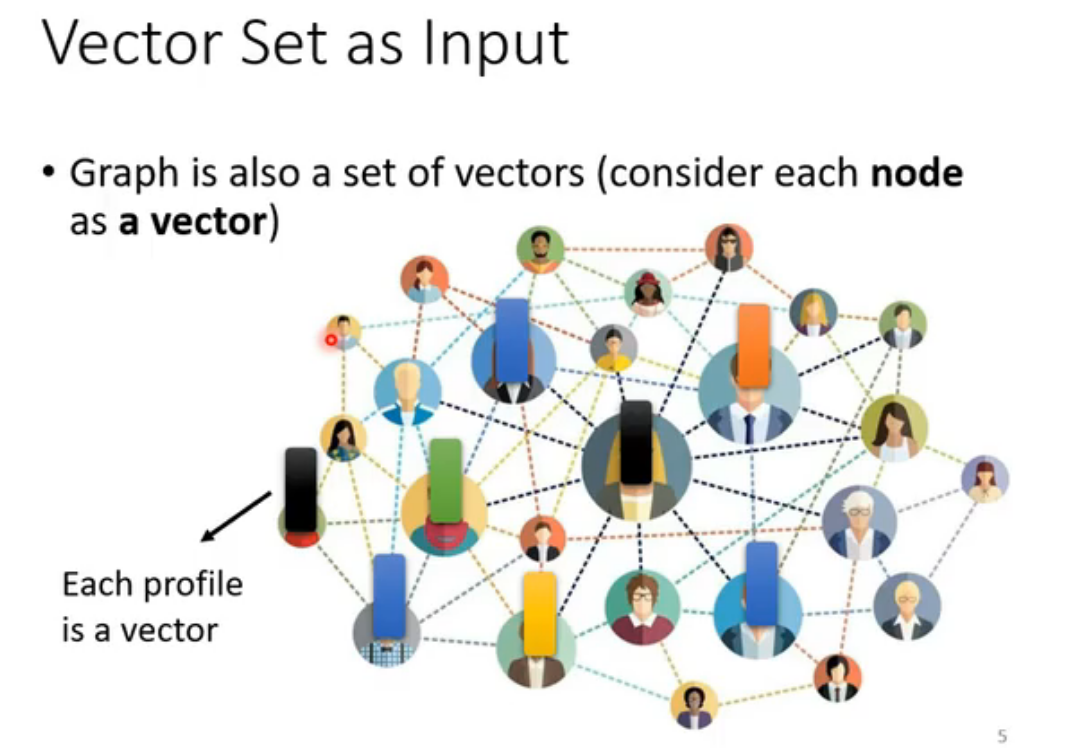
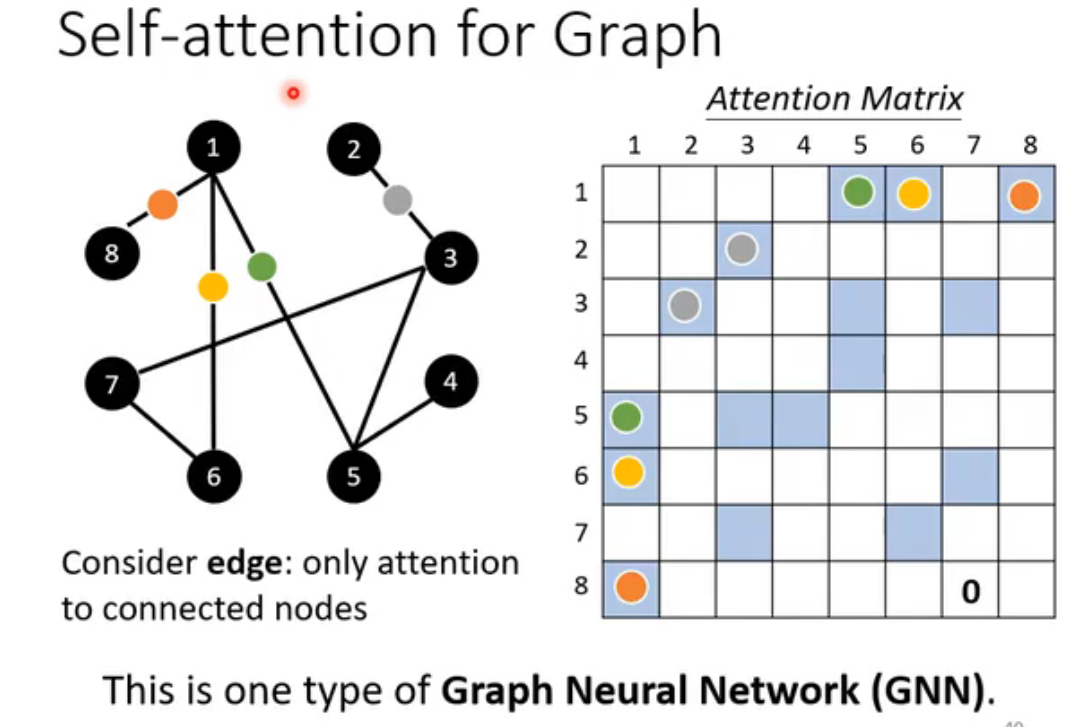
4. Graph(图)
拓展
Self-Attention v.s. CNN
Self-Attention v.s. RNN (Recurrent Neural Network)
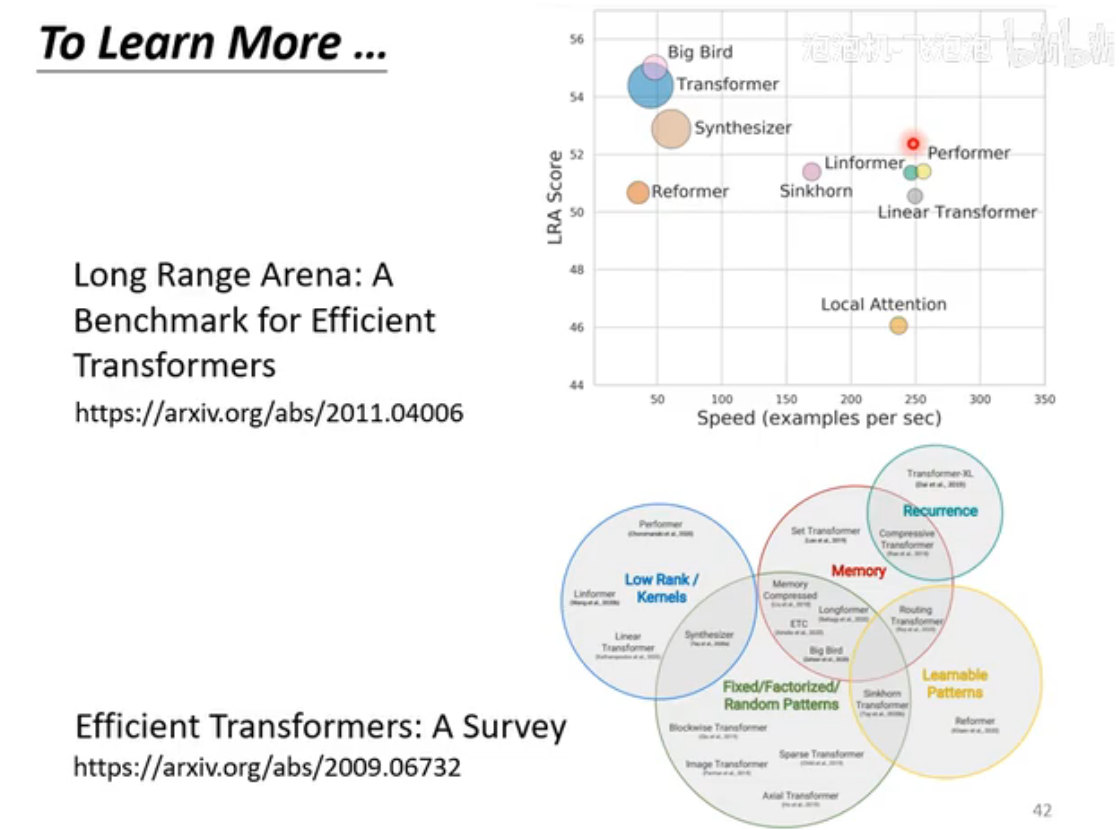
To learn more
Self-Attention是transformer核心结构之一,可以处理input为一组向量的情况。
应用
此前学习的全连接神经网络、CNN输入都是一个vector,无法应用于输入是一组个数可变vector。而self-attention可以很好处理这一点。拓展一点:Self-Attention名字源于《Attention is all you need》这篇著名的论文。
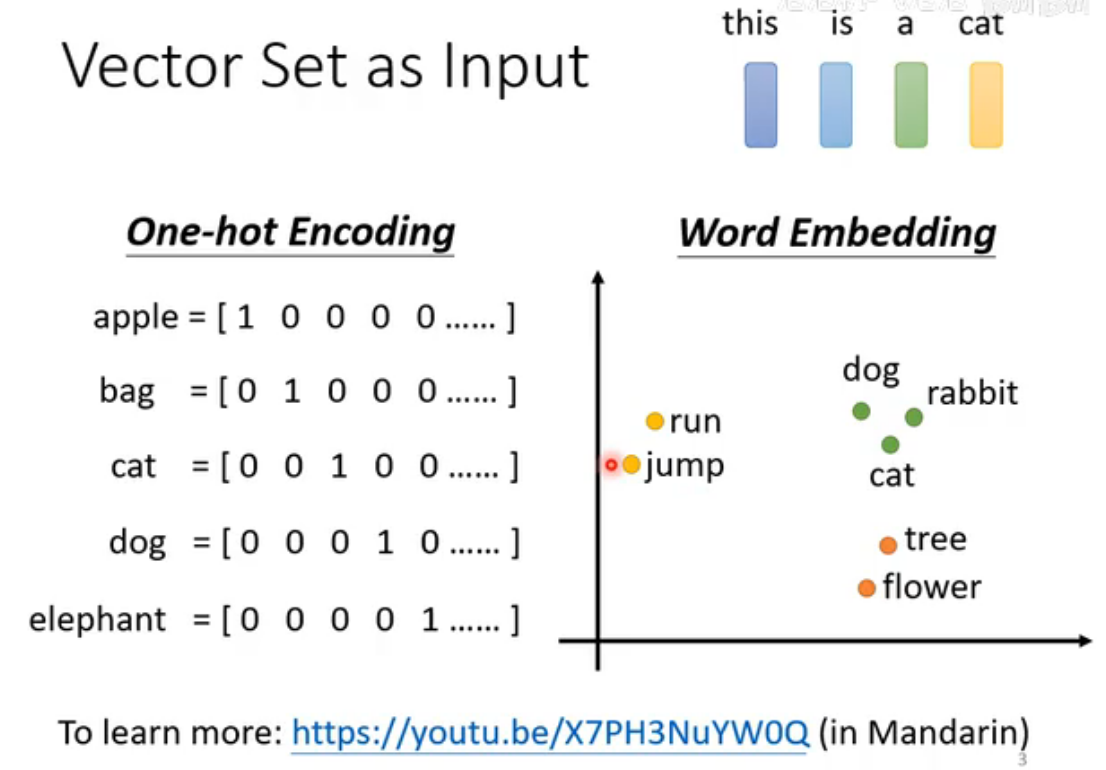
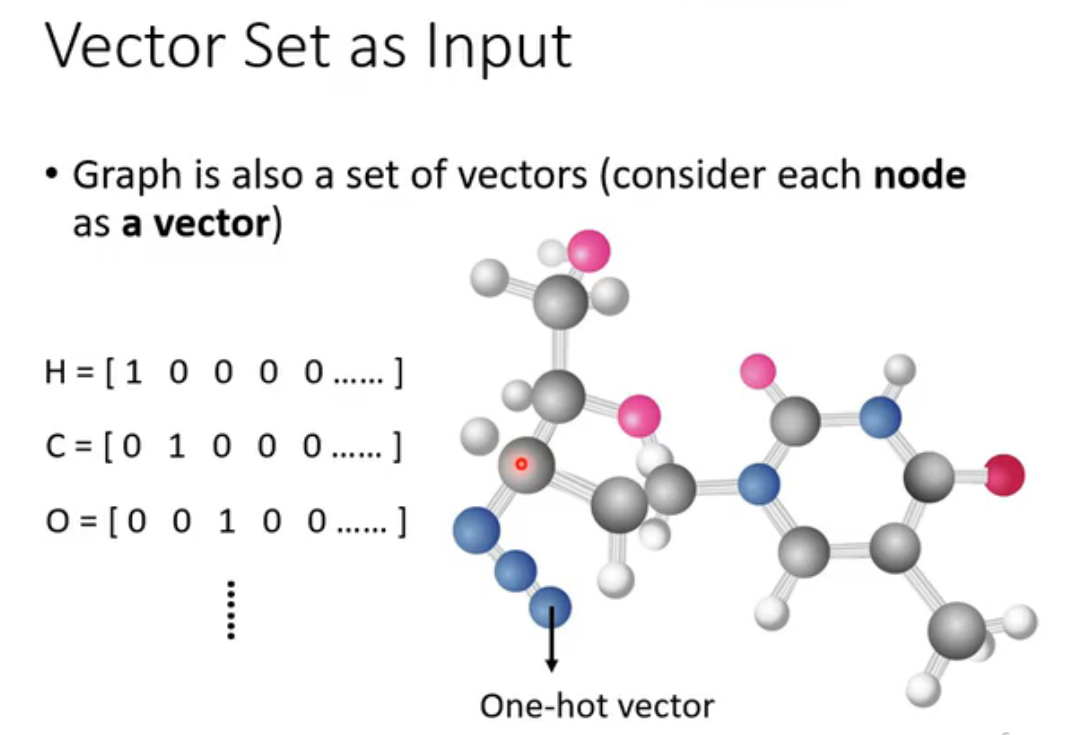
以文字处理为例,若每个单词可以用one-hot vector表示,存在严重的问题:单词间无任何关联。所以采取word enbedding(词嵌入)技术,将自然语言中的词语映射为低维连续向量,使得语义或语法相似的词在向量空间中距离更近,从而表示了不同单词的内在联系。
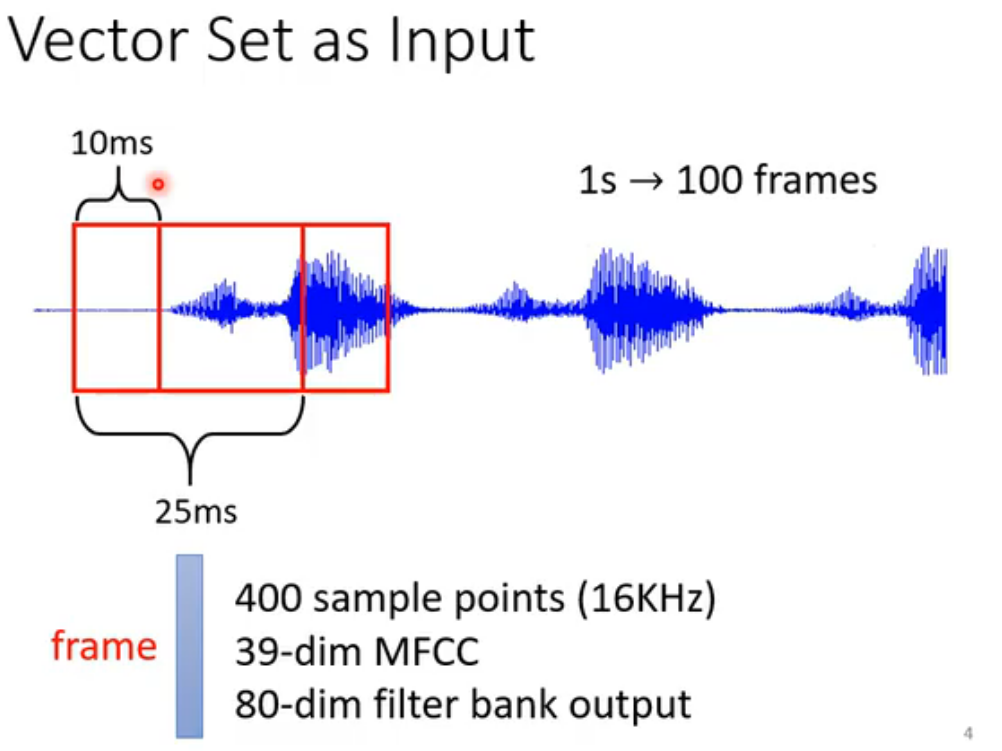
self-attention同样可以处理语音、图(数学意义上的)、分子结构。
输出形式
分为三种,本文只介绍第一种:Sequence Labeling。
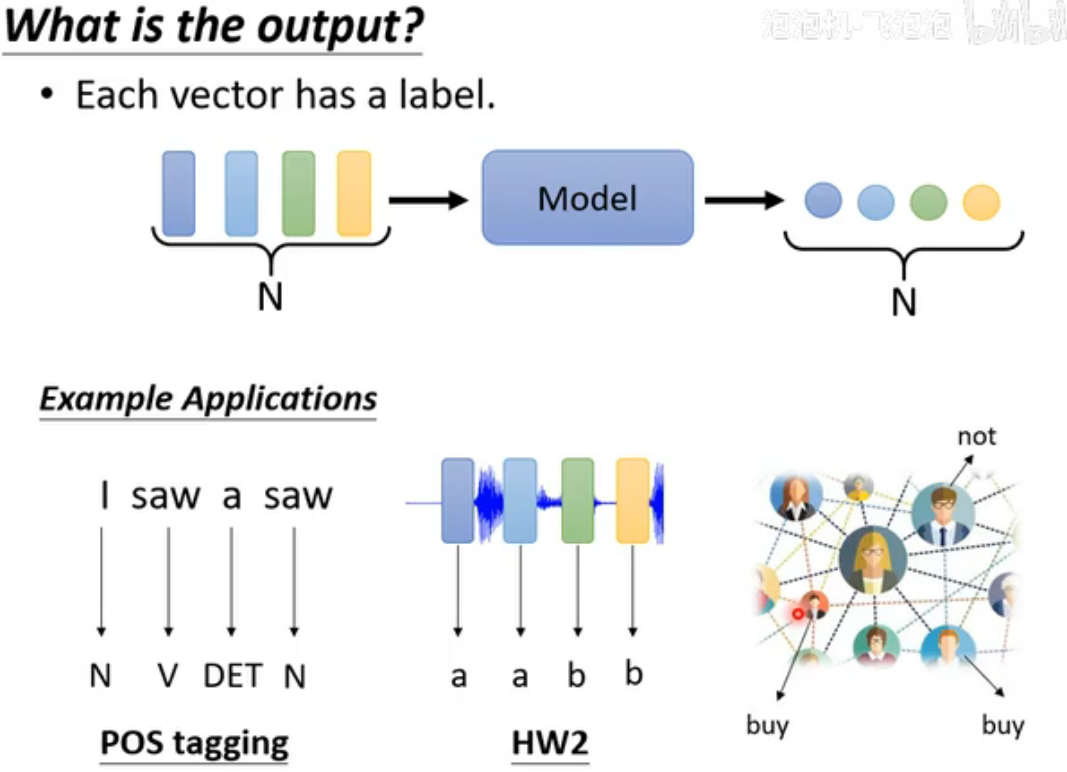
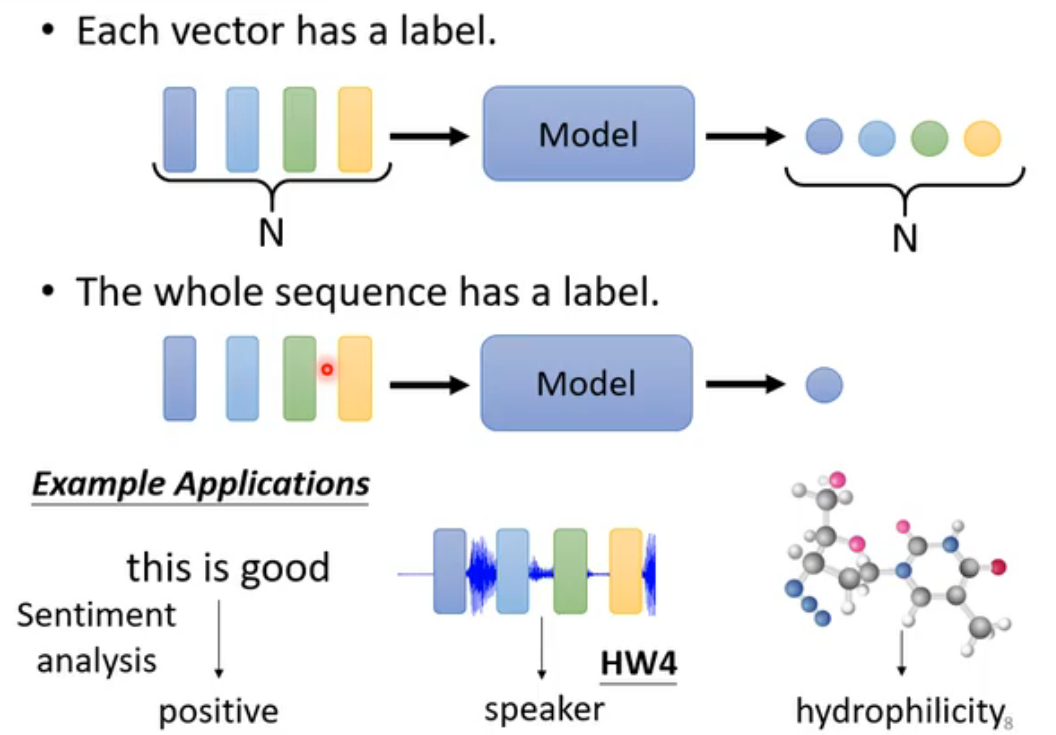
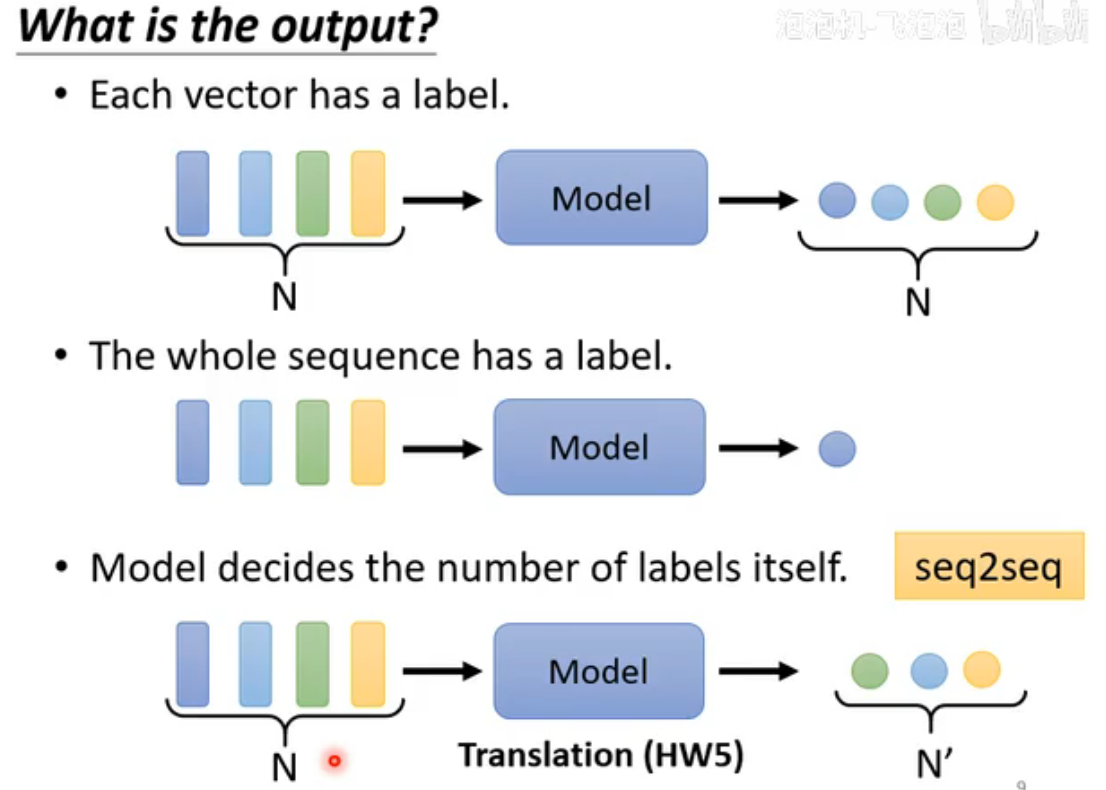
Self-Attention实现Sequence Labeling
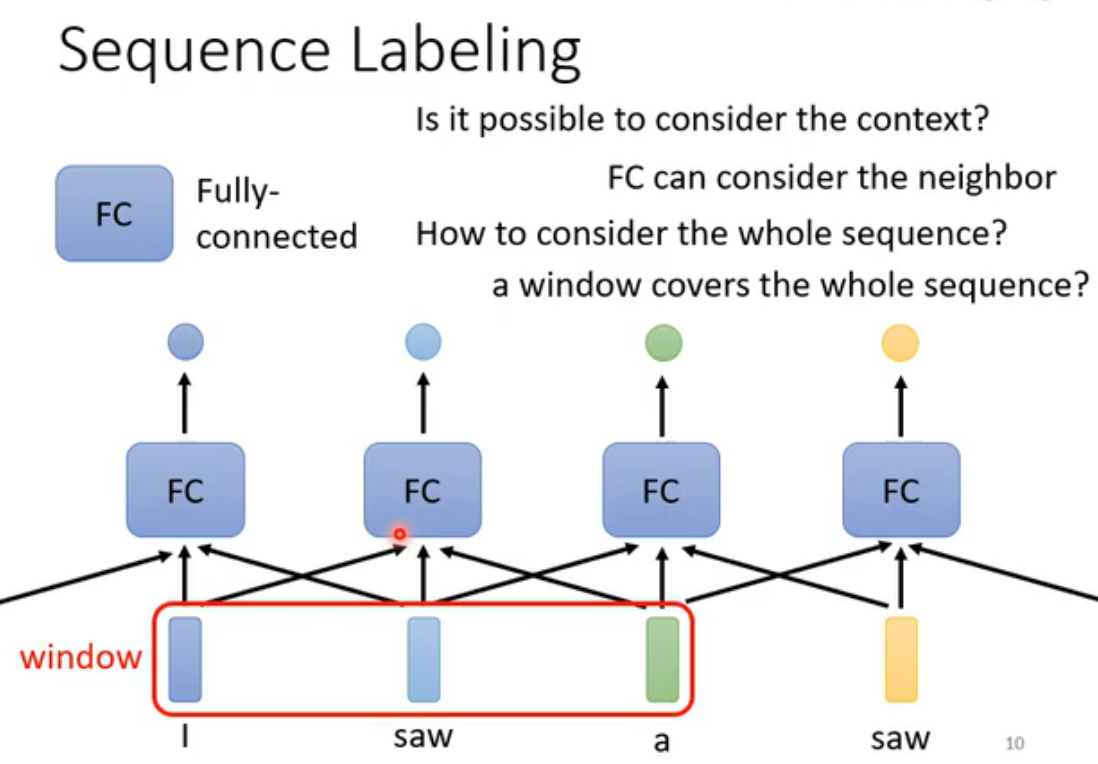
一个自然想法是用FC实现:通过连接相邻向量可以在语境中学习,但是很难覆盖整个Sequence,如果真的要覆盖整个Sequence,需要以训练资料中最长的Sequence长度为准(因为Sequence长度可变),这意味着参数量会变得极大,训练难且容易Overfitting。
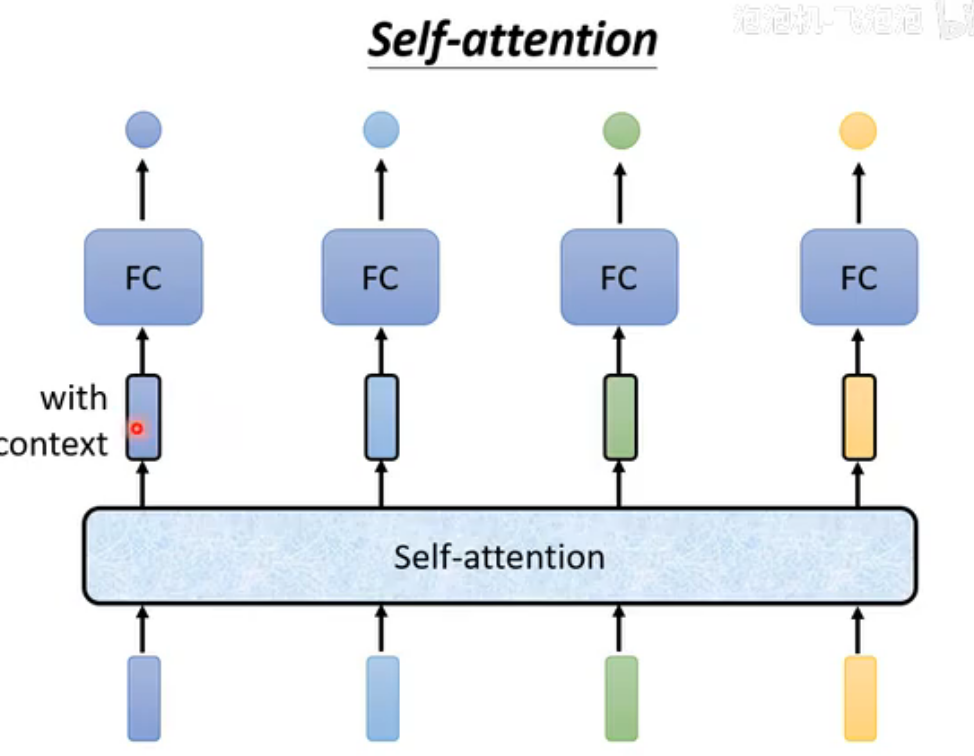
而self-attention可以考虑整个语境:
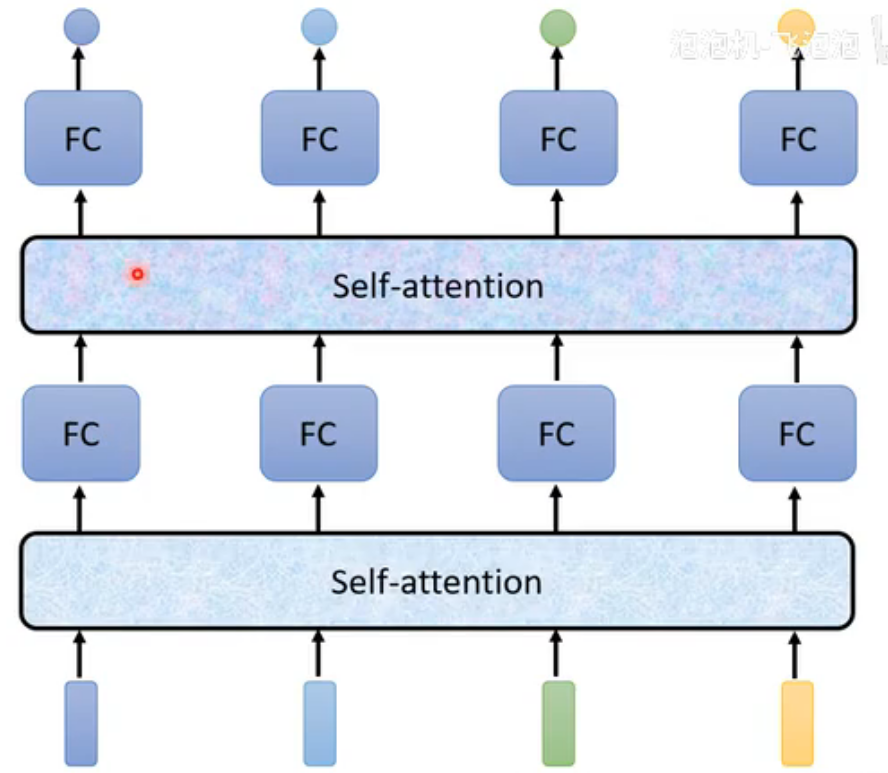
self-attention不仅限于第一层。
self-attention原理
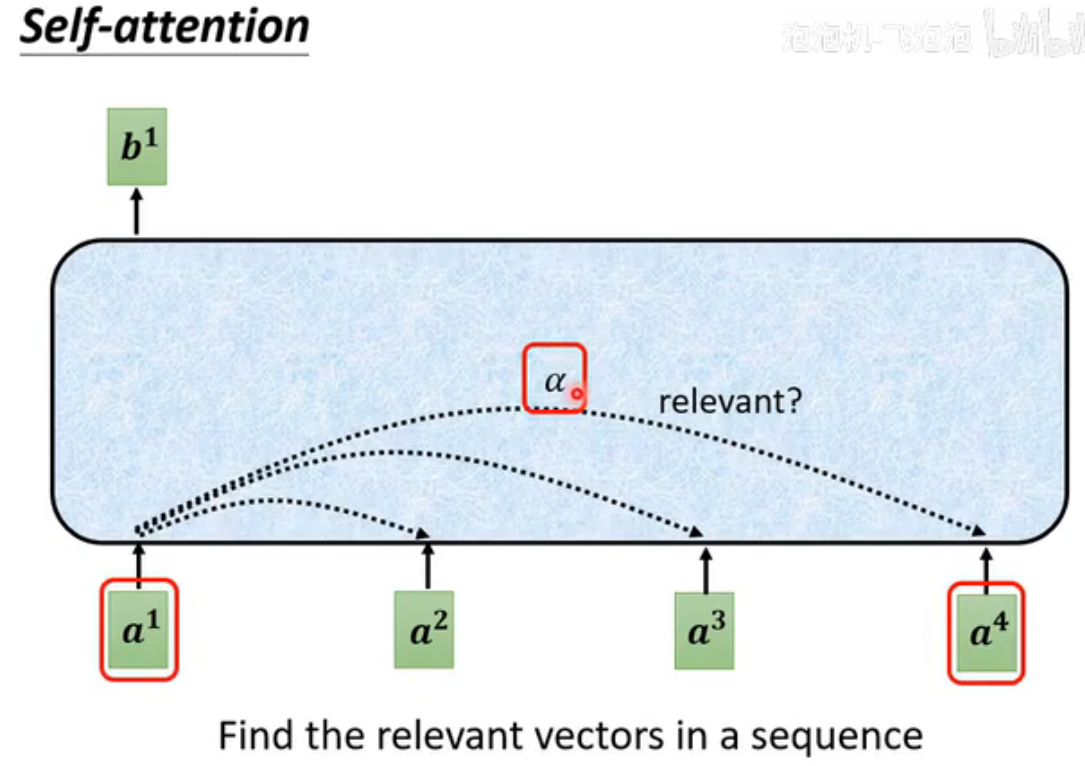
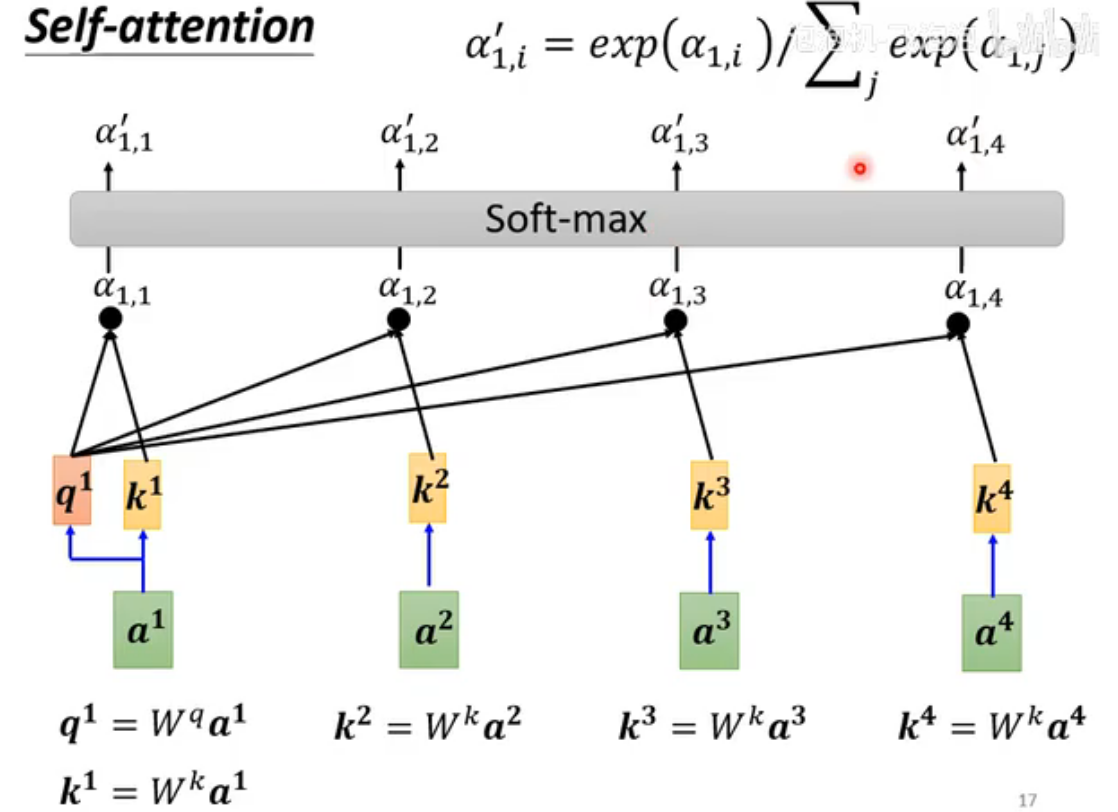
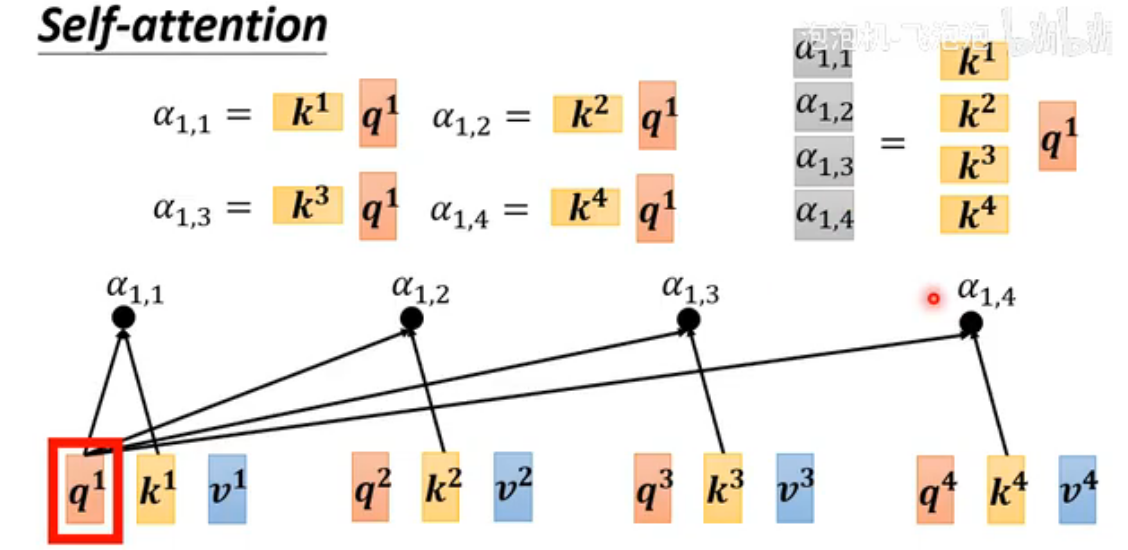
计算不同向量的关联程度α方法有很多,本文介绍最主流的Dot-product:把两个向量先与两个矩阵相乘,再把结果作点积得到α(attention score)。
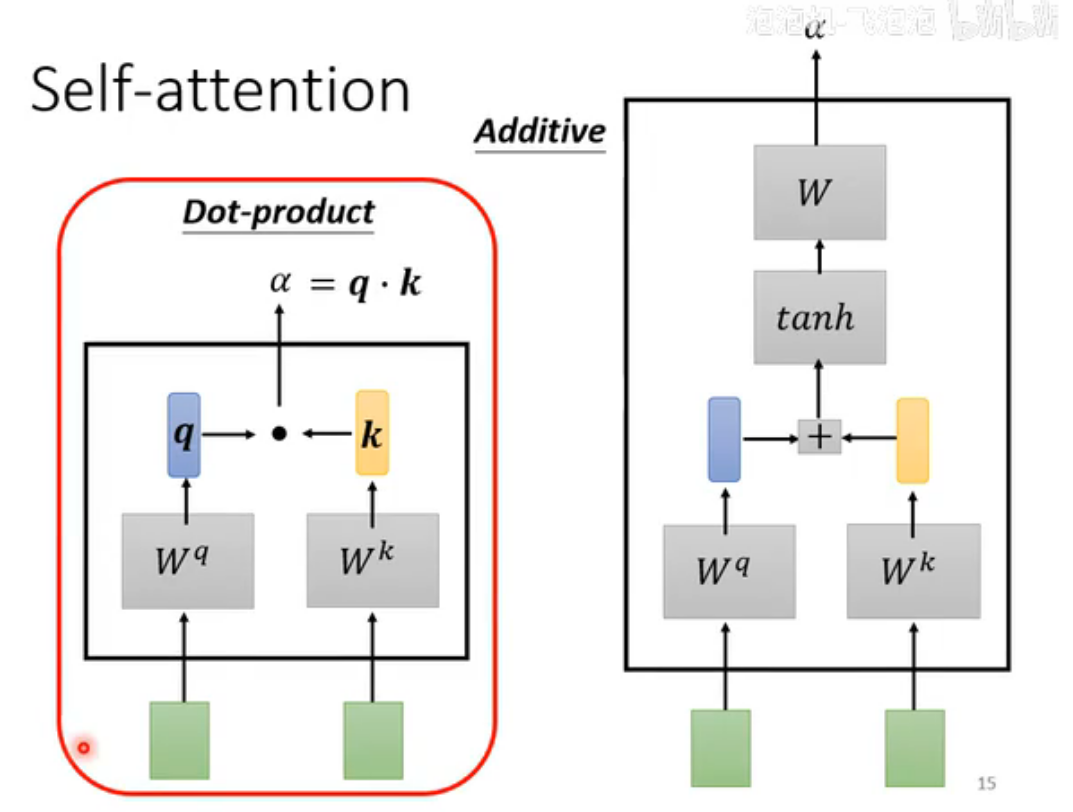
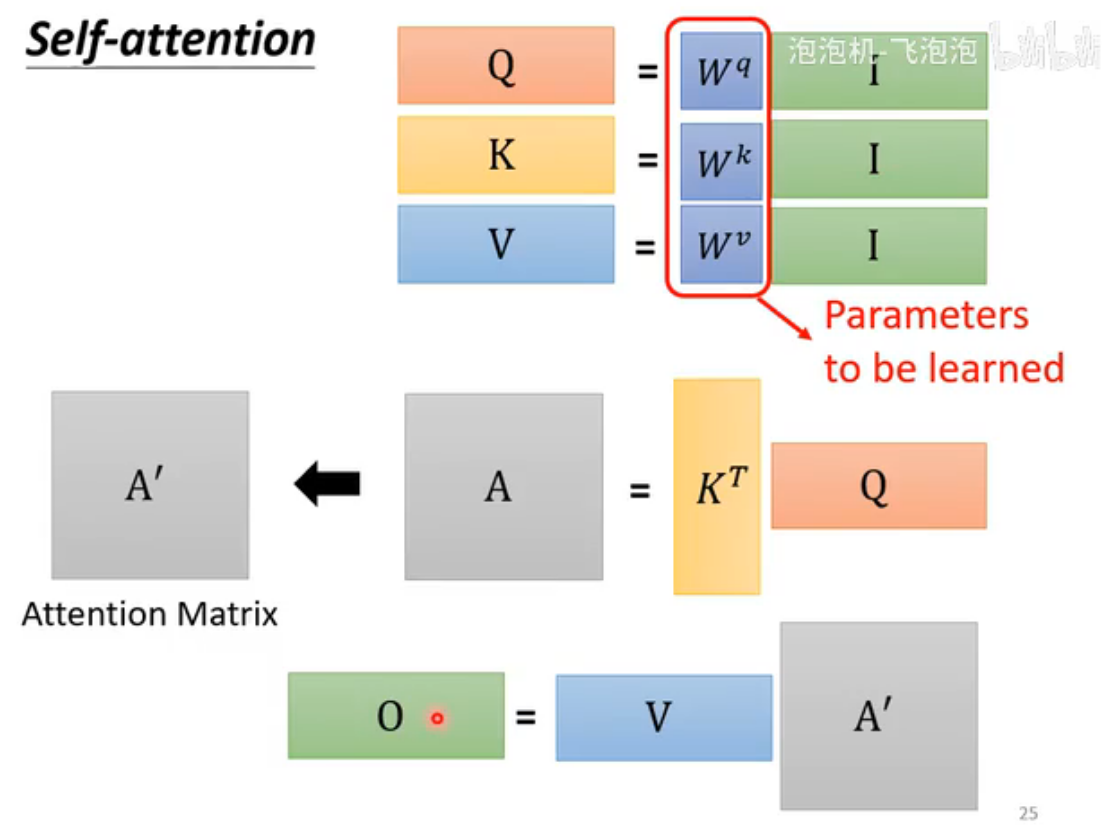
Query(Q)、Key(K)、Value(V)
Query(Q)代表当前需要计算注意力的位置(即“我关注谁”);Key(K)代表序列中所有位置的标识(即“谁能被关注”),用于与Query匹配相似度;Value(V)存储实际用于加权求和的信息(即“被关注的内容”),注意力权重确定后与V相乘得到输出。注意:要计算与自己的相关性(便于进行矩阵运算)
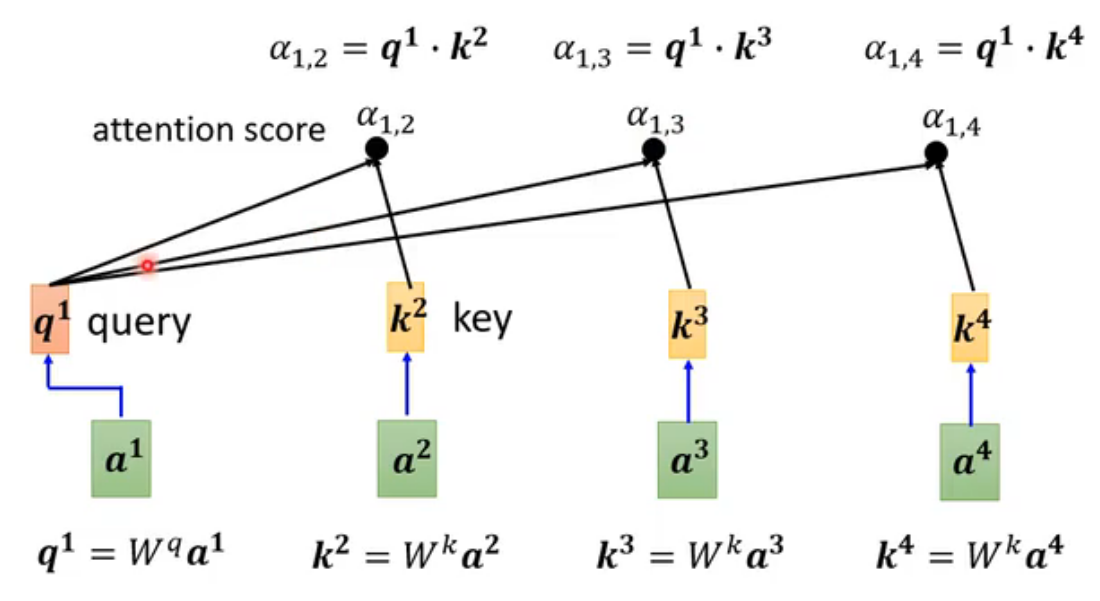
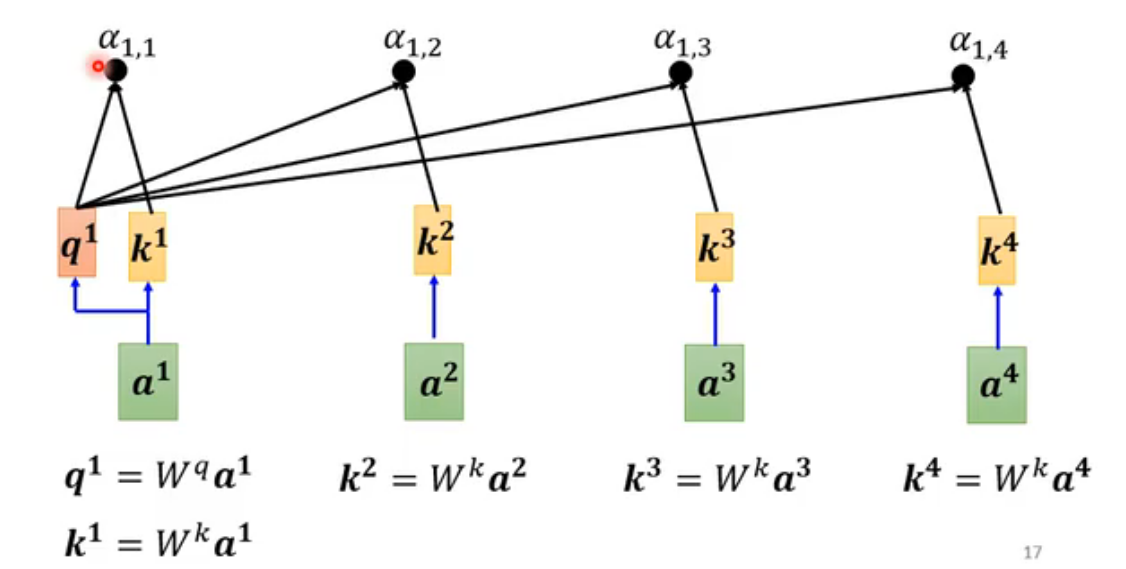
接下来要用softmax处理α(分类任务也会用到),将注意力权重转换为一个概率分布。但不是必须使用softmax,其他的也行,activation function都可以,有人尝试过ReLu,甚至效果更好。不过softmax最常用。
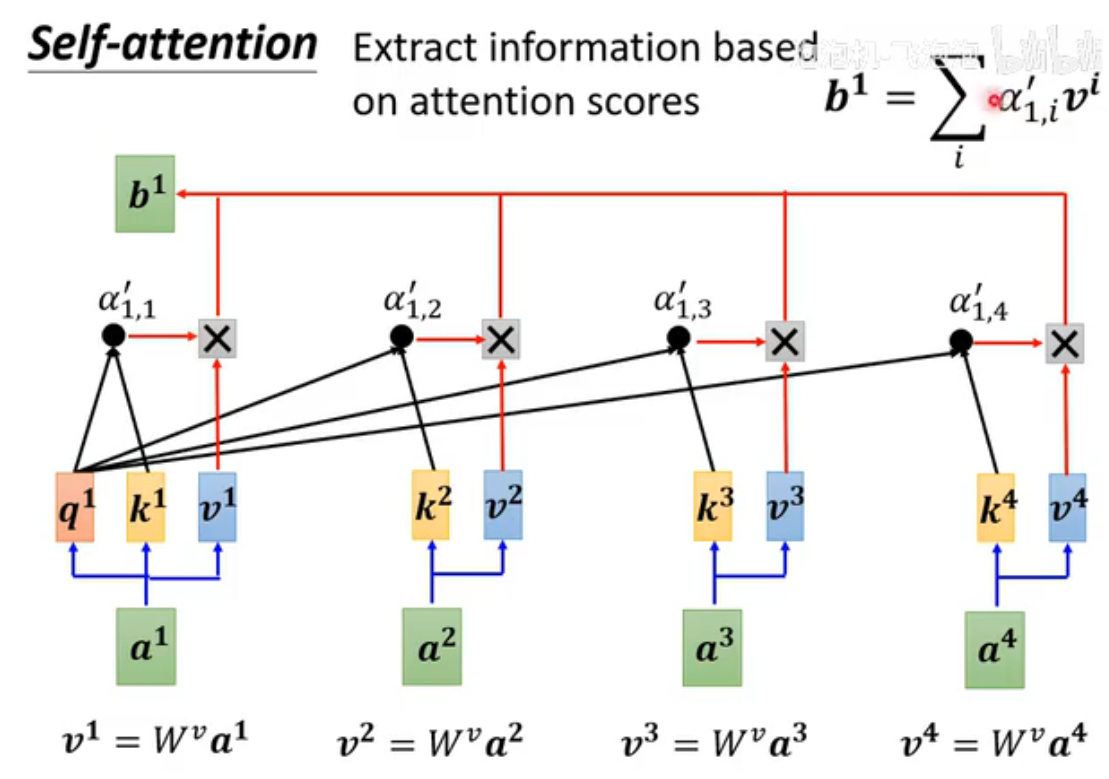
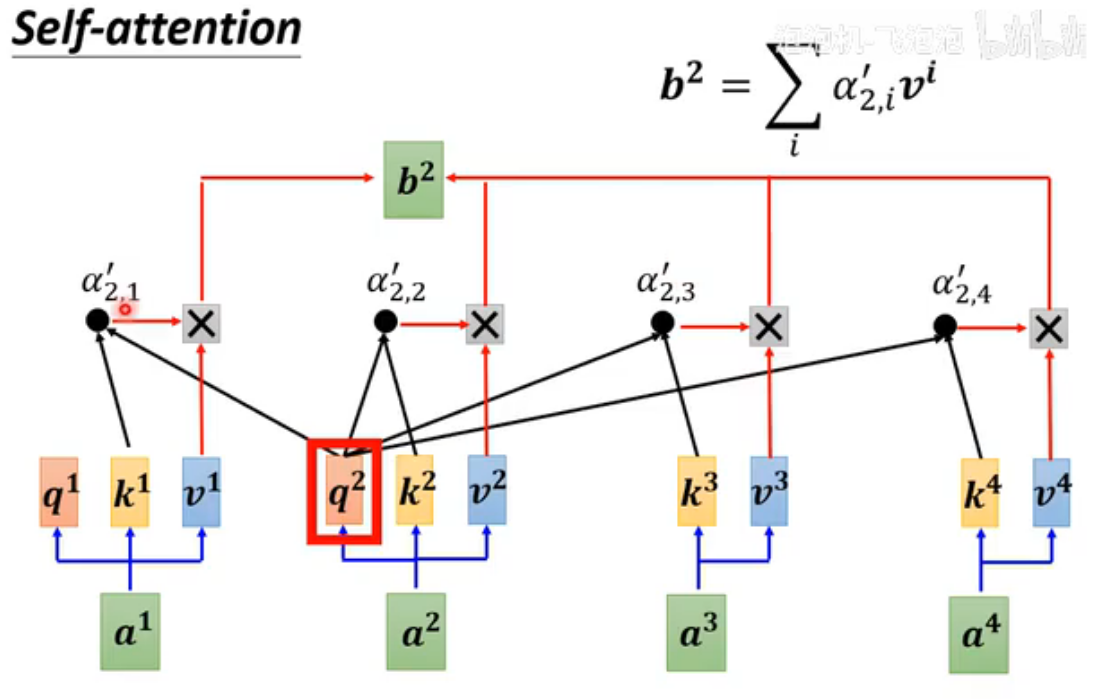
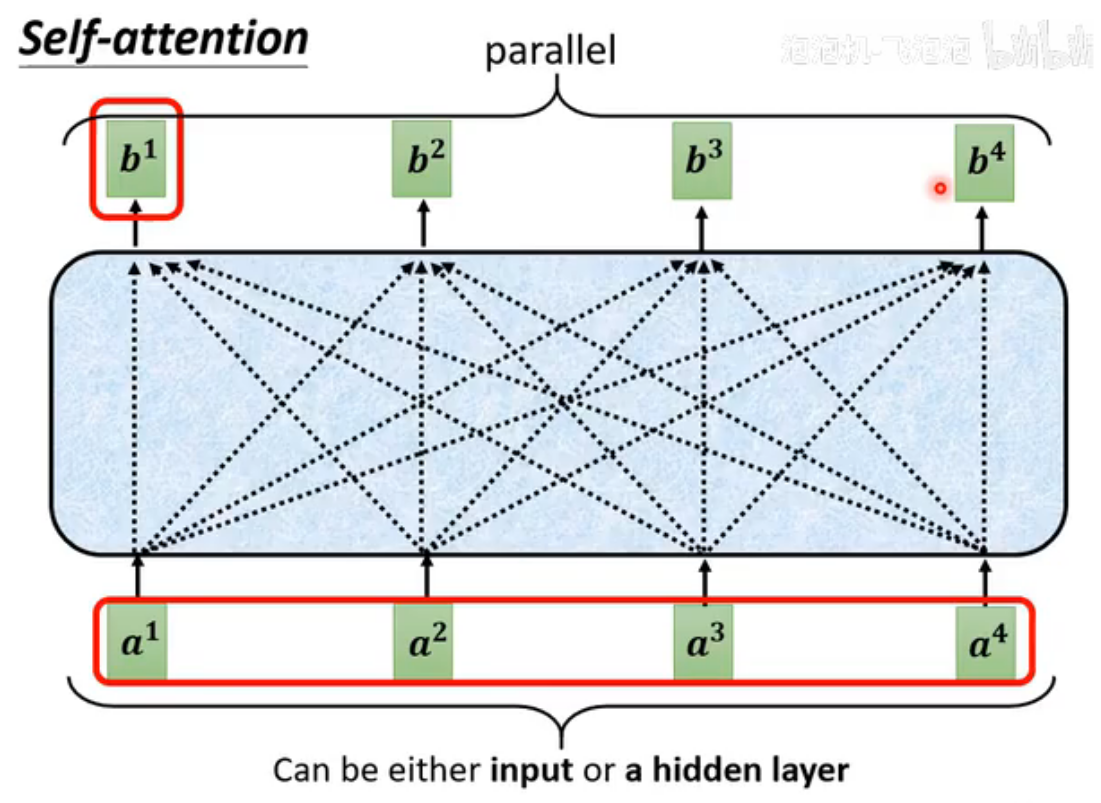
输出结果是并行计算,效率很高
从矩阵乘法理解self-attention过程
把每个input作为列拼成矩阵I,Q、K、V分别由相应矩阵与I相乘得到。
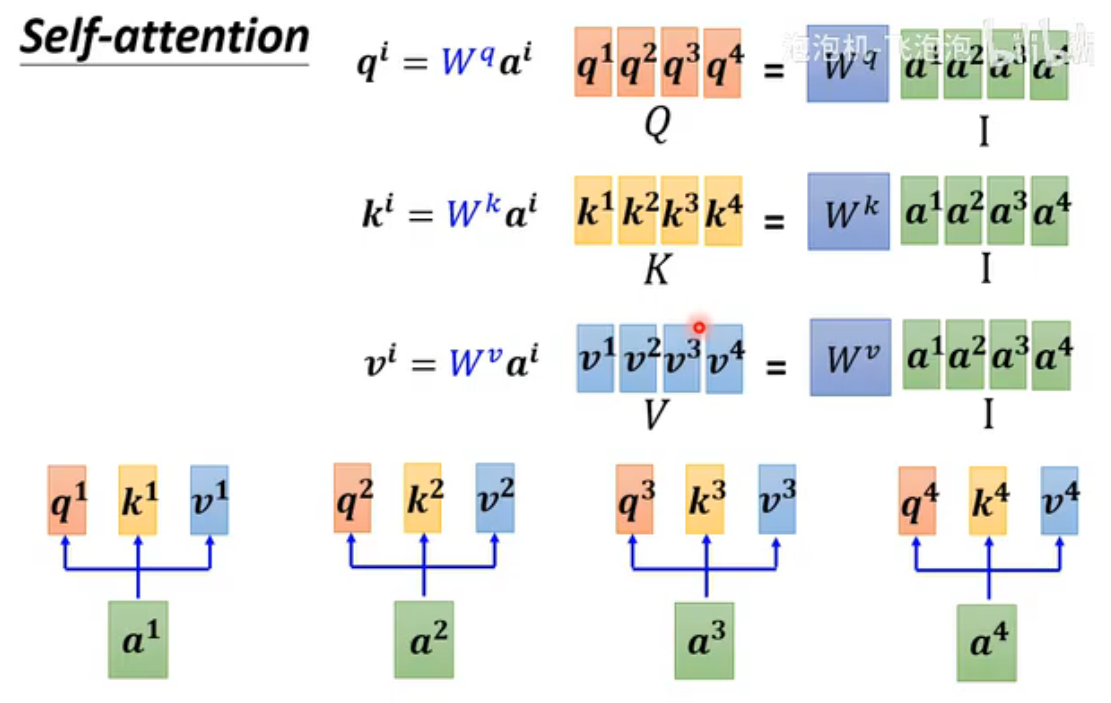
注意下图中k是转置的
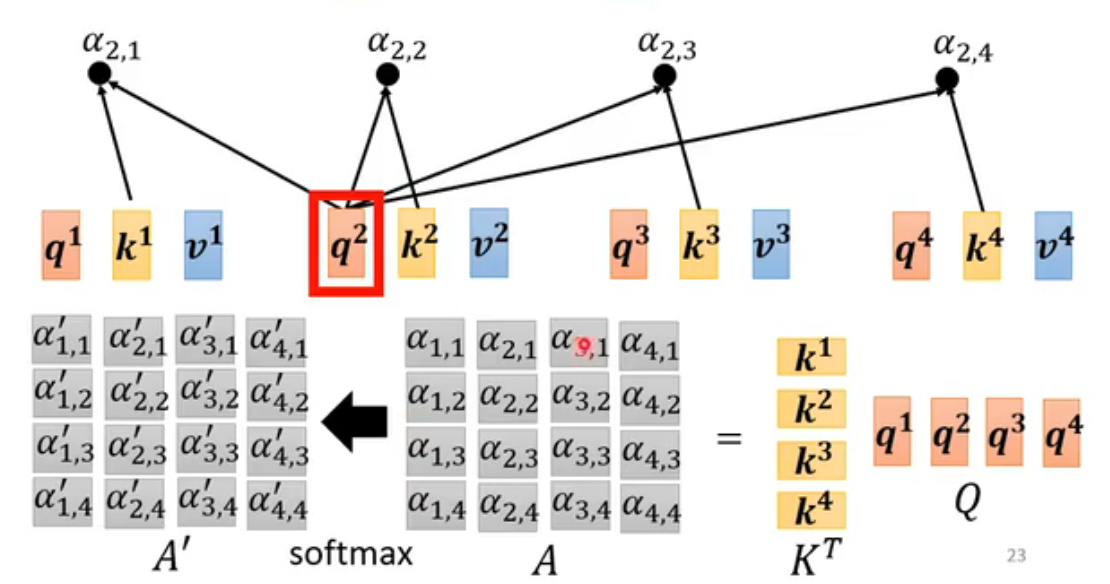
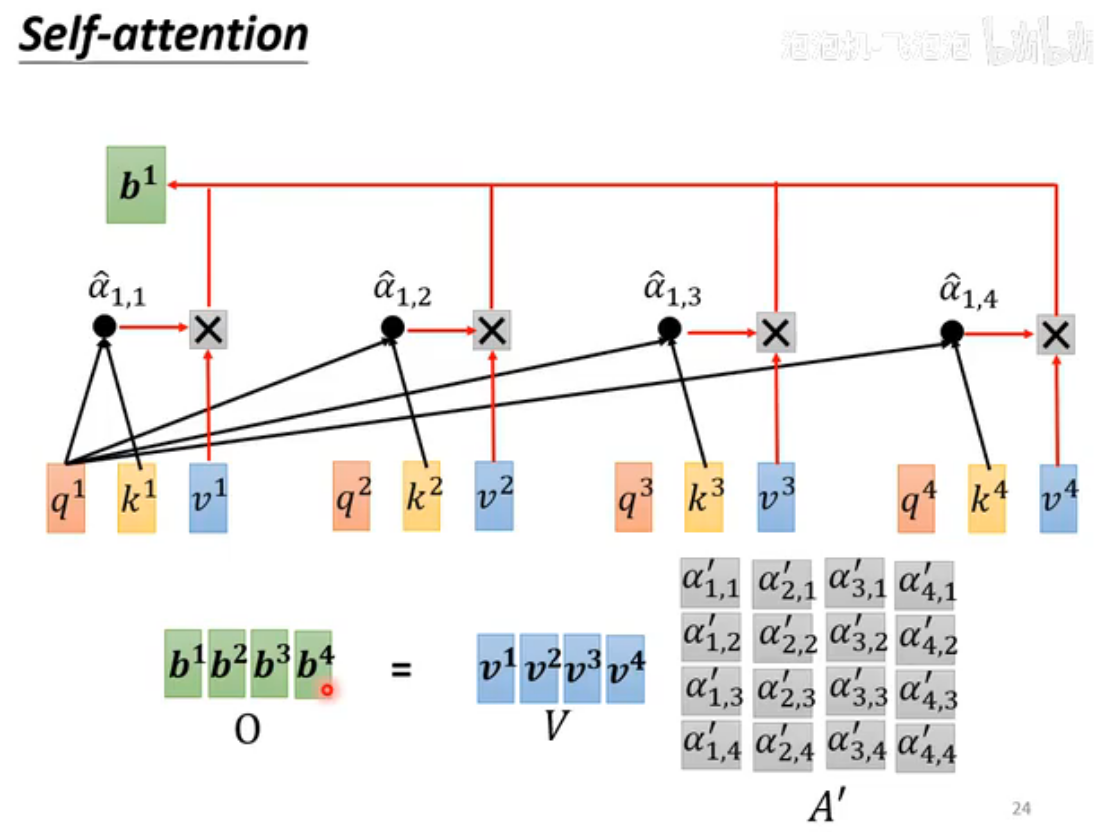
全过程
只有Q、K、V三个矩阵是未知的参数
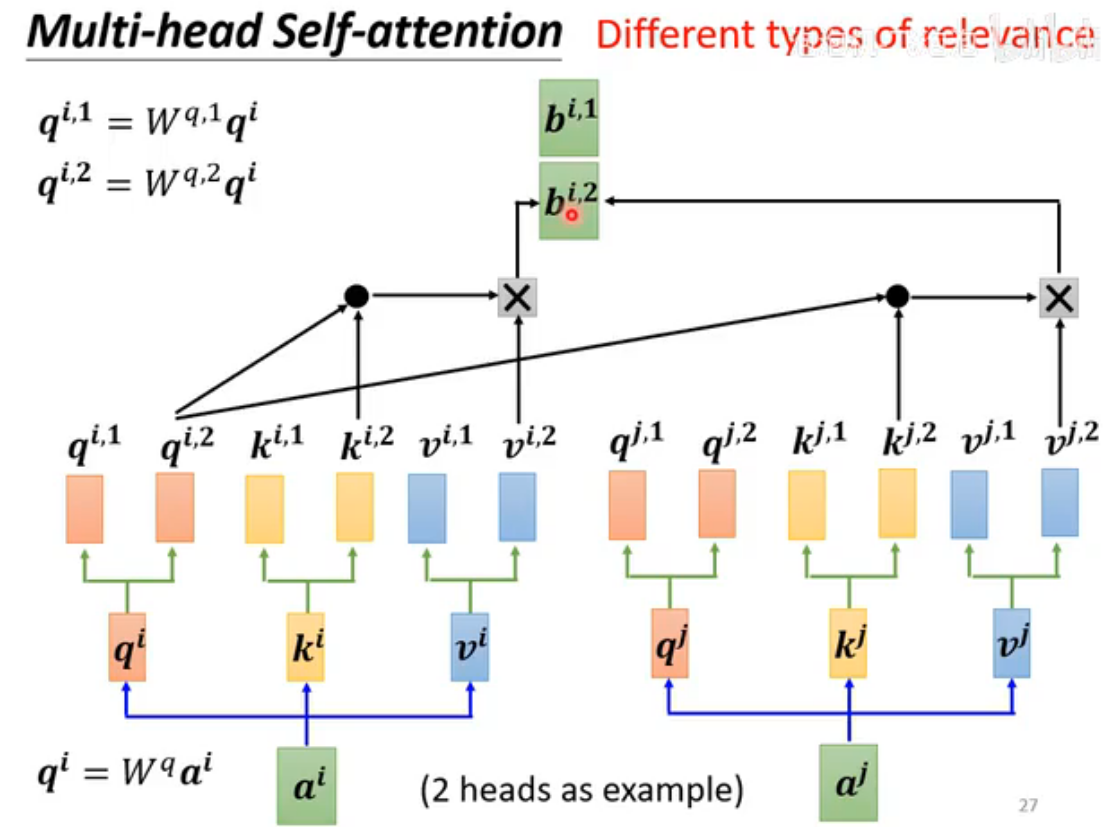
Multi-head Self-Attention(多头注意力)介绍
Multi-Head Attention 是 Self-Attention 的扩展,通过将注意力机制并行地执行多次(即多个“头”),每个头学习不同的关注模式,最后将结果拼接成一个向量后再乘以一个矩阵,映射回原始维度。
head数量是hyperparameter,需要自己设定。在机器翻译、文本生成等任务中,多头注意力显著优于单头,尤其在处理复杂句子结构或长序列时。
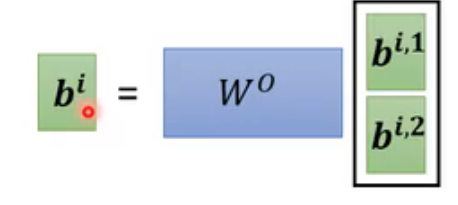
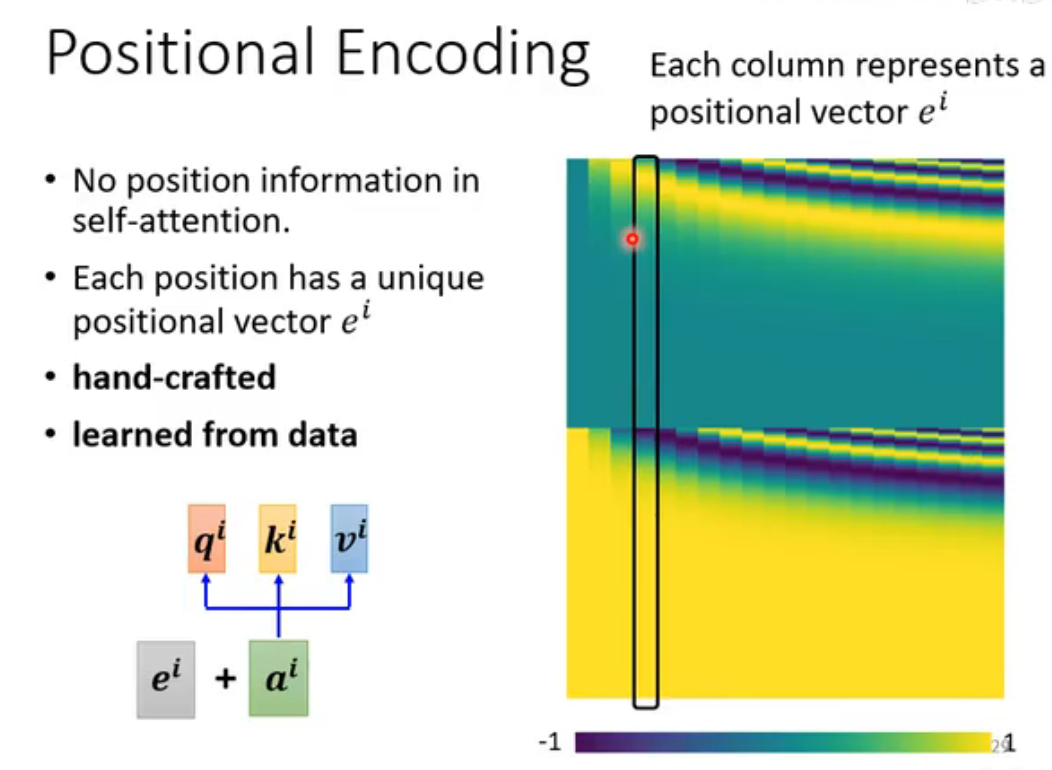
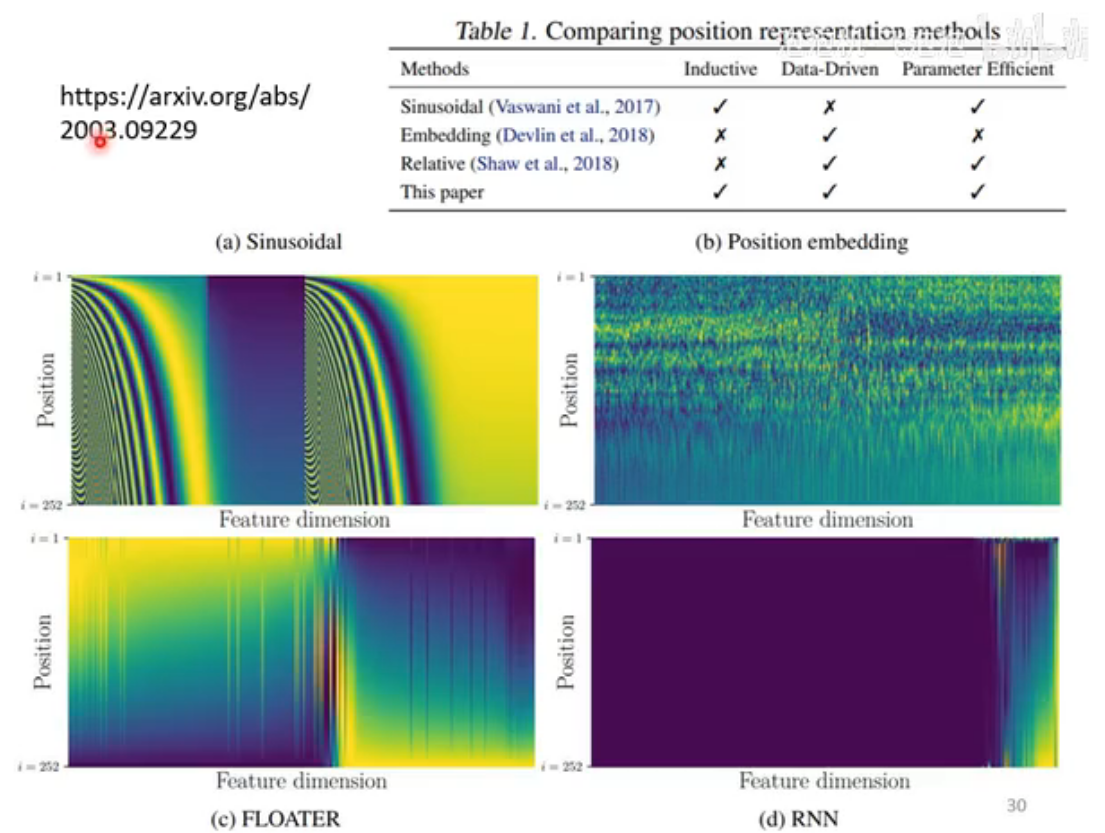
Positional Encoding(位置编码)
self-attention无法体现出不同输入间的位置关系:所有位置间距离都是一样的,无法体现出在Sequence中出现的先后顺序。但位置信息在某些任务中很重要,比如词性标注。使用Positional Encoding可以加入位置信息。
最早的Positional Encoding是人工确定的,但Sequence长度超过positional vector数量会出现问题。Positional Encoding也可由神经网络训练得出。总之,positional encoding的实现方法非常多,在此课程对应的时期里,哪种Positional Encoding的方法最好还没有形成共识,是一个尚待研究的问题。
其他应用
1. NLP

2. Speech
此时为避免参数量过大,架构进行了调整,限制了Attention的范围(这也符合语音辨识的domain knowledge)。产生的变式称为truncated self-attention。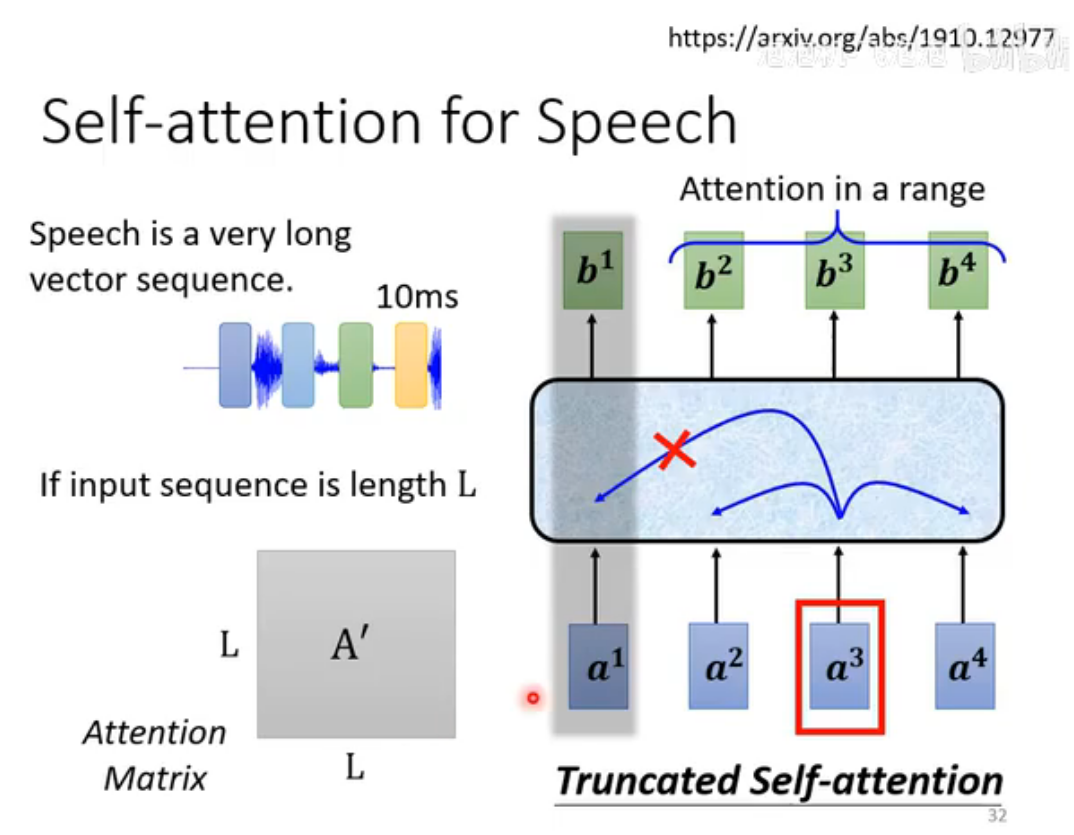
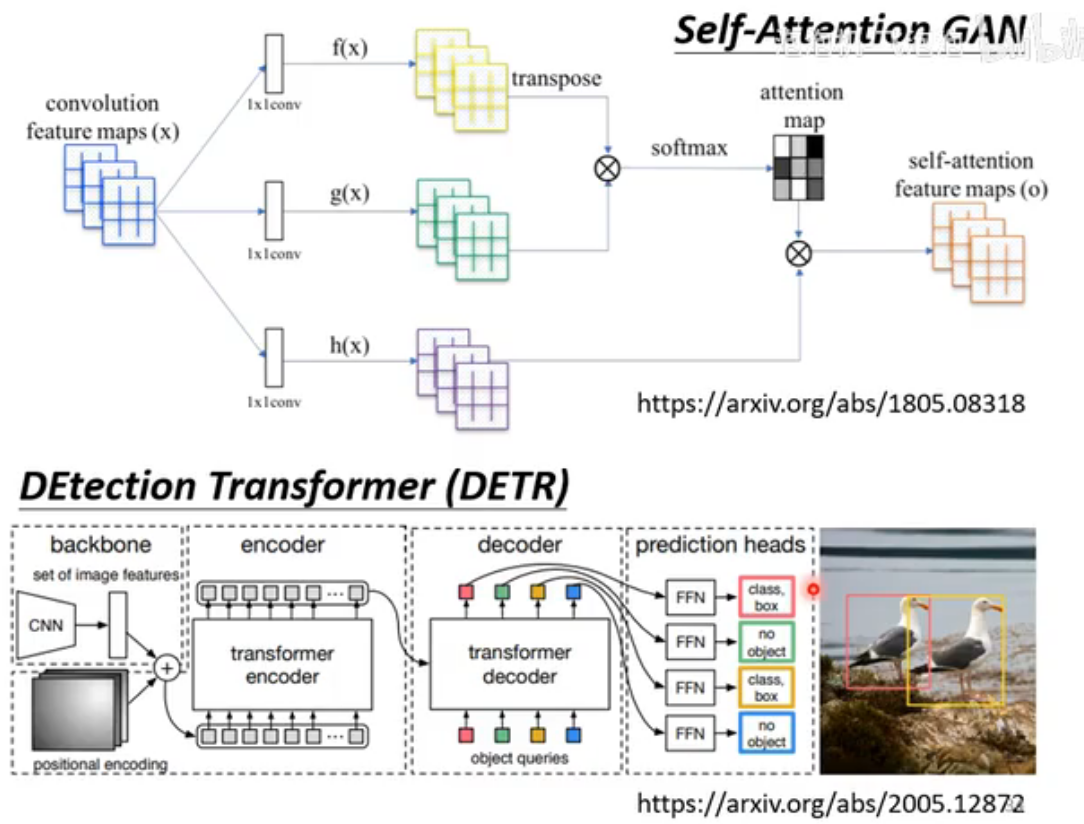
3. Image
4. Graph(图)
此时self-attention变为GNN的一种。GNN涉及到很深的技术,难以快速讲清。
拓展
Self-Attention v.s. CNN
CNN可视为简化的self-attention,而self-attention可视为复杂版的CNN:receptive filed不再是hyperparameter,而是模型学习所得。

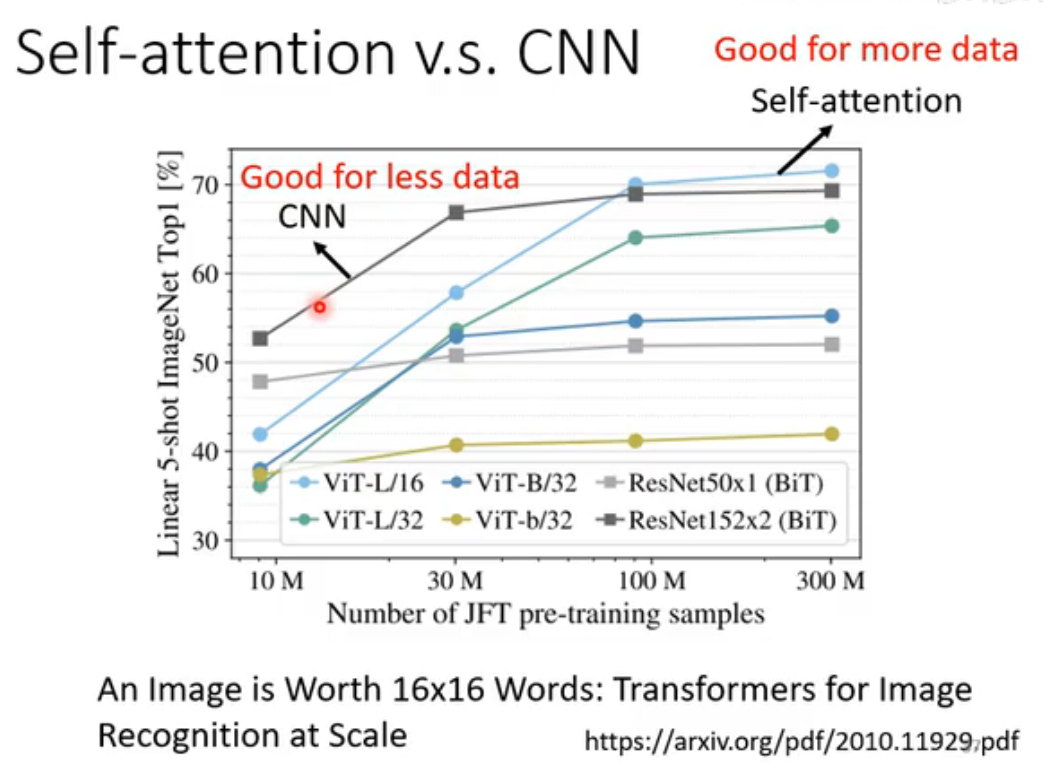
下图中的论文从数学严格证明了CNN是self-attention的特例,是限制更大的model。由此可推测self-attention处理图像时比CNN更flexible,所以更容易Overfitting,在训练数据较少时,CNN表现更好,但训练数据够大时,self-attention效果更好。实验证明了上述推测。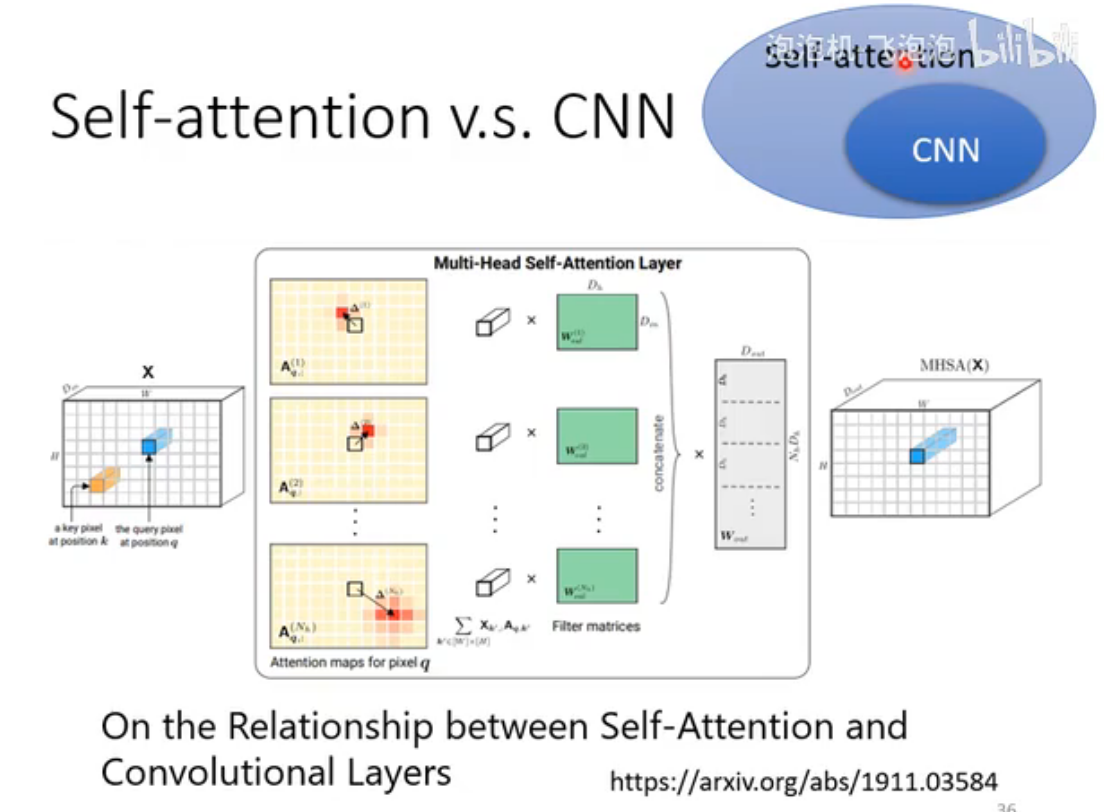
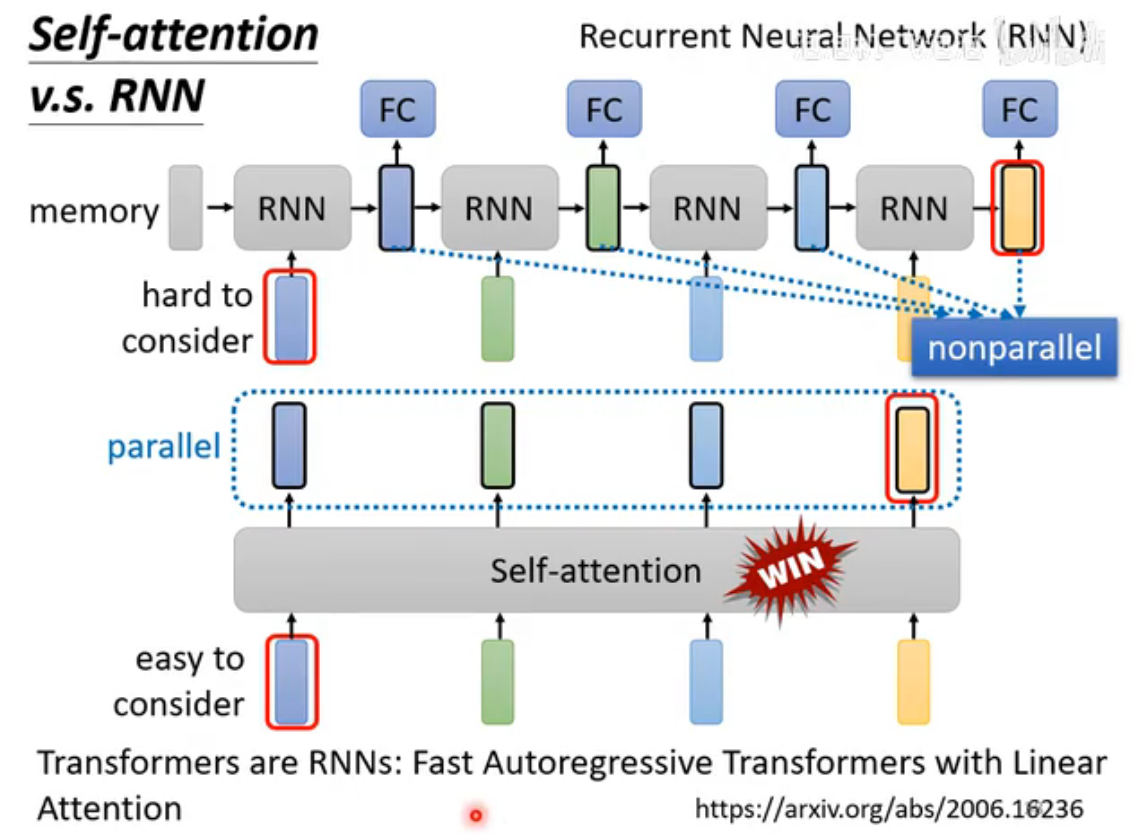
Self-Attention v.s. RNN (Recurrent Neural Network)
目前RNN很大一部分作用已经被self-attention取代了。
RNN(循环神经网络)用于处理序列数据(如句子、语音、时间序列),特点是能记住之前的信息,适合需要“上下文”的任务。核心思想:每次处理一个数据时,不仅看当前输入,还结合上一刻的“记忆”(隐藏状态)。
RNN无法并行运算,而self-attention可以;图中RNN是单向的,但也可以改为双向,但对内存资源消耗大:如最后一个黄色的向量如果要考虑最左边的蓝色向量结果,那么就必须把结果储存在内存中。
To learn more