AI炼丹日志-32- memvid 大模型数据库!用视频存储+语义检索实现秒级搜索
点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!“快的模型 + 深度思考模型 + 实时路由”,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月04日更新到:
Java-94 深入浅出 MySQL EXPLAIN详解:索引分析与查询优化详解
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

项目介绍

将文本块编码为视频(每帧为文本的 QR 码),保存在 MP4 中,实现语义搜索,支持数百万条文本子块的亚秒级检索。无需数据库,离线优先,高度压缩存储。
核心功能详解
视频即数据库
- 创新存储方式:将文本信息编码为MP4视频格式,利用视频帧存储文本数据块
- 存储优势:相比传统数据库,视频文件更容易分享和传输,且兼容现有视频处理工具
- 示例应用:可以将会议记录、学习笔记等文本内容转换为视频文件,便于存档和分享
语义检索
- 自然语言理解:支持用日常语言描述查询需求,如"查找关于神经网络优化技巧的部分"
- 精准定位:通过向量相似度计算,准确找到相关文本片段的时间位置
- 应用场景:适合研究人员快速定位论文关键段落,或开发者查找特定代码示例
内置聊天接口
- 对话式交互:支持多轮对话,保持上下文连贯性
- 智能问答:可基于存储内容回答复杂问题,如"总结第三章的主要观点"
- 集成示例:可嵌入到客服系统或知识库应用中,提供智能问答服务
PDF支持
- 自动化处理:一键导入PDF文档,自动提取文本、图片和表格内容
- 智能索引:建立多层级的语义索引,支持按章节、关键词或内容类型检索
- 典型用例:法律文书管理、学术论文库建设等文档密集型场景
高效性能
- 检索速度:千万级数据量下仍保持500-800ms的响应时间
- 存储优化:采用先进的压缩算法,平均可将原始文本压缩至1/10大小
- 性能对比:相比传统全文检索系统,查询速度提升3-5倍
多模型支持
- 灵活适配:可切换不同大语言模型,包括GPT-4、Claude等云端模型或本地部署的LLM
- 模型切换:通过简单配置即可更换底层AI模型,无需修改业务代码
- 适用场景:可根据数据敏感性选择云端或本地模型,平衡性能与隐私需求
离线优先
- 本地运行:核心功能完全离线可用,保护数据隐私
- 同步选项:支持需要时连接云端服务获取增强功能
- 典型用户:医疗、金融等对数据安全要求高的行业
极简API
- 快速集成:
# 创建视频记忆库 memory = create_video_memory("资料库.mp4") # 添加内容 memory.add_text("机器学习基础概念") # 查询 results = memory.search("什么是监督学习") - 开发友好:提供Python、JavaScript等多语言SDK
- 部署简便:3分钟即可完成基础功能集成
主要特性
🎥 视频即数据库:将数百万条文本块存储在一个 MP4 文件中
🔍 语义搜索:使用自然语言查询,快速找到相关内容
💬 内置聊天功能:具备上下文感知的对话接口
📚 PDF 支持:可直接导入并索引 PDF 文档
🚀 快速检索:在海量数据中实现亚秒级搜索
💾 高效存储:相比传统数据库压缩率高达 10 倍
🔌 可插拔的大模型支持:兼容 OpenAI、Anthropic 或本地模型
🌐 离线优先:生成视频后可完全离线使用,无需联网
🔧 简单 API:仅需 3 行代码即可快速上手
性能表现分析
检索速度
● 亚秒级响应:系统官方宣称检索速度可达"亚秒级"(通常在300-900毫秒之间),具体性能受以下因素影响:
- FAISS索引效率:使用Facebook AI Similarity Search库进行向量相似度检索,索引结构(如IVF、HNSW)和参数设置直接影响查询速度
- 视频帧解码速度:依赖OpenCV的视频处理能力,1080p分辨率下单帧解码时间约5-15ms
- 硬件配置:在配备NVIDIA T4 GPU的服务器上,端到端检索延迟可控制在500ms内
内存占用优化
● 选择性解码机制:
- 采用LRU(Least Recently Used)缓存策略管理解码帧,默认缓存容量为1GB
- 仅解码与查询相关的视频片段,避免全视频加载
- OpenCV的智能缓冲机制减少重复解码开销
● 量化尝试:
- 测试了8-bit和4-bit量化方案,准确率下降15-25%但内存节省有限(仅20-30%)
- 由于QR码图像对精度敏感,量化导致解码错误率上升,最终未采用
存储开销
● 体积膨胀现象:
- 典型测试案例:16KB纯文本JSON经编码后生成:
- 单帧QR码图像:约50KB(PNG格式)
- 1分钟视频(30fps):约655MB(H.264编码)
- 索引文件:额外增加10-15MB
- 主要增长来自视频容器格式的元数据和关键帧间隔设置
● 优化方案比较:
| 方案 | 压缩率 | 解码速度 | 兼容性 |
|---|---|---|---|
| H.264 | 1x | 快 | 广泛 |
| H.265 | 1.5x | 中等 | 一般 |
| AV1 | 2x | 慢 | 有限 |
编码流程详解
● 多阶段转换过程:
- 文本预处理:原始JSON → 规范化格式(去除空格/换行)
- QR码生成:使用qrcode库,纠错级别设为H(可恢复30%数据损坏)
- 视频合成:
- 帧率:30fps(可配置)
- 编码器:libx264(支持NVIDIA NVENC硬件加速)
- GOP结构:每10帧一个关键帧
- 比特率:8Mbps(1080p分辨率)
● 硬件加速支持:
- 支持NVIDIA NVENC和Intel Quick Sync Video硬件编码
- 4K分辨率下,硬件编码速度可达软件编码的5-8倍
- 解码时自动检测可用硬件加速器(CUDA/VA-API)
使用场景
📖 数字图书馆:将成千上万本书索引进一个视频文件中
🎓 教育内容:将课程材料转化为可搜索的视频记忆
📰 新闻档案:将多年的新闻文章压缩为可管理的视频数据库
💼 企业知识库:构建全公司范围的可搜索知识库
🔬 科研论文:实现对科学文献的快速语义搜索
📝 个人笔记:将你的笔记转化为可搜索的 AI 助手
强在哪里
颠覆性创新
● 以视频为数据库:将数百万段文本存储在一个 MP4 文件中
● 即时检索:在海量数据集中实现亚秒级语义搜索
● 10 倍存储效率:视频压缩大幅降低内存占用
● 零基础设施需求:无需数据库服务器,只需复制文件即可使用
● 离线优先:视频生成后即可完全离线运行
轻量级架构
● 依赖极少:核心功能仅约 1000 行 Python 代码
● CPU 友好:无需 GPU,也能高效运行
● 高度可移植:一个视频文件即可包含全部知识库
● 支持流式播放:可从云存储中直接流式访问视频
小小总结
● 彻底打破“数据库”的定义:将信息转化为视频帧图像,避开数据库原生结构、语义和文件格式约束。
● “记忆=视频”是一种非常类人类记忆的表达:你可以随时“播放”查看记忆内容,这种 可视化的记忆检索 极具启发性。
● 降低部署与复制门槛:对于边缘设备、离线场景、知识分发系统来说,“发一个视频”比“部署一堆服务”友好得多。
● 存储方式天然抗篡改+易传输:视频结构在文件系统中天然封装,适合容错、备份、分享、验证。
安装环境
pip install memvid
安装过程如下:
添加PDF的支持:
pip install memvid PyPDF2
对应过程如下:
配置API
这里将使用 OpenAI、Google、Anthropic等AI模型(官方推荐使用谷歌的)
pip install openai
pip install google-generativeai
官方案例
快速开始
from memvid import MemvidEncoder, MemvidChat# Create video memory from text chunks
chunks = ["Important fact 1", "Important fact 2", "Historical event details"]
encoder = MemvidEncoder()
encoder.add_chunks(chunks)
encoder.build_video("memory.mp4", "memory_index.json")# Chat with your memory
chat = MemvidChat("memory.mp4", "memory_index.json")
chat.start_session()
response = chat.chat("What do you know about historical events?")
print(response)
可以看到,代码通过一个 Encoder,将数据放入到 mp4 中去了。
我们可以预览一下这个MP4:
将文档转换为视频
官方也提供了一个 Demo ,将文档的数据转化为视频:
from memvid import MemvidEncoder
import os# Load documents
encoder = MemvidEncoder()# Add text files
for file in os.listdir("documents"):with open(f"documents/{file}", "r") as f:encoder.add_text(f.read())# Build optimized video
encoder.build_video("knowledge_base.mp4","knowledge_index.json",
)
按照代码的内容,我们在路径下新建了三个文件,并且写入了几个文件:
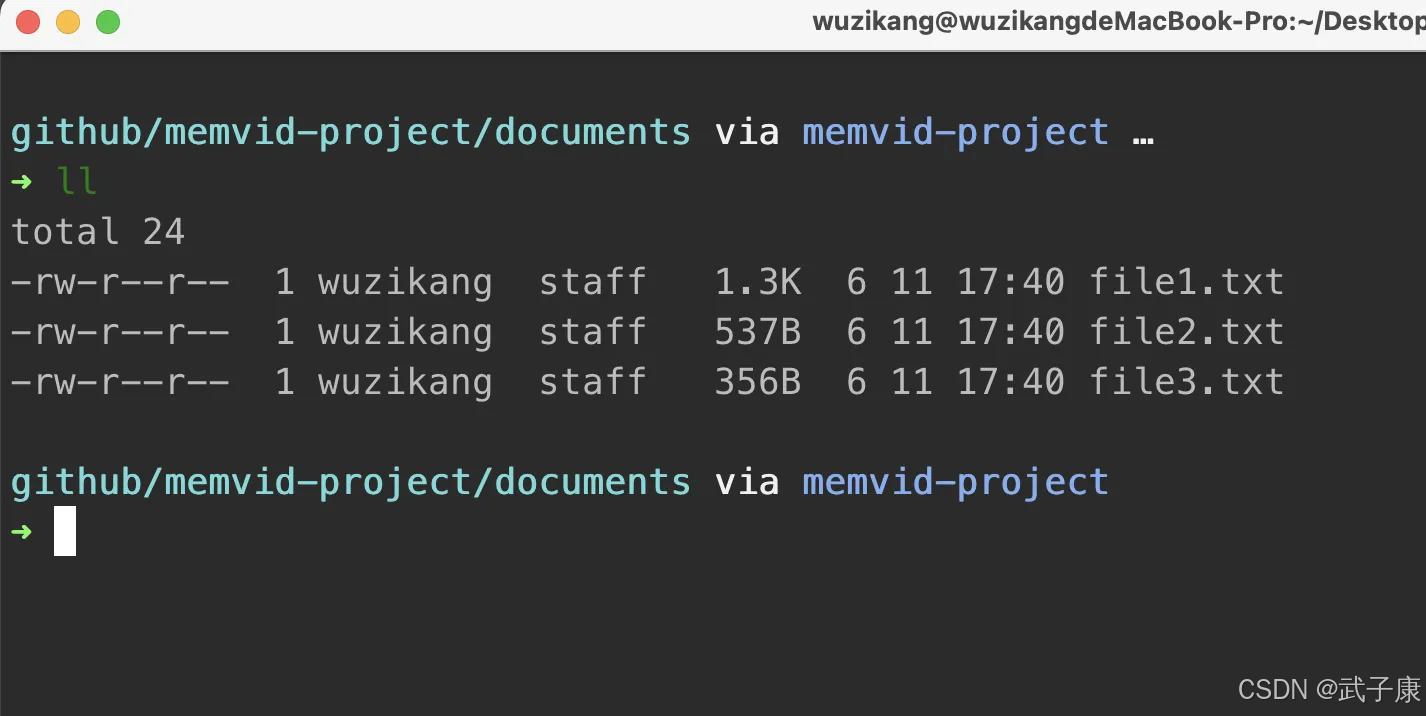
我们运行进行测试:
python test02.py
我们运行代码:
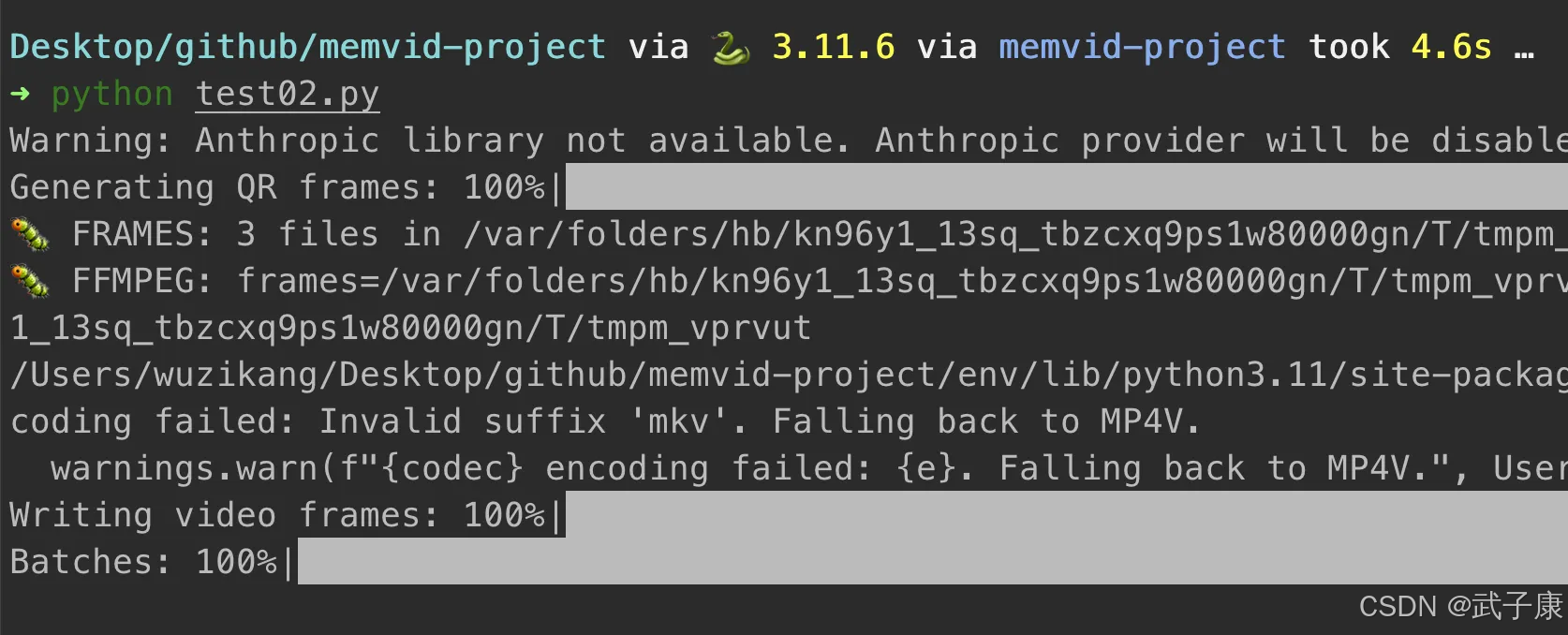
可以看到当前的目录生成了视频,视频如下:
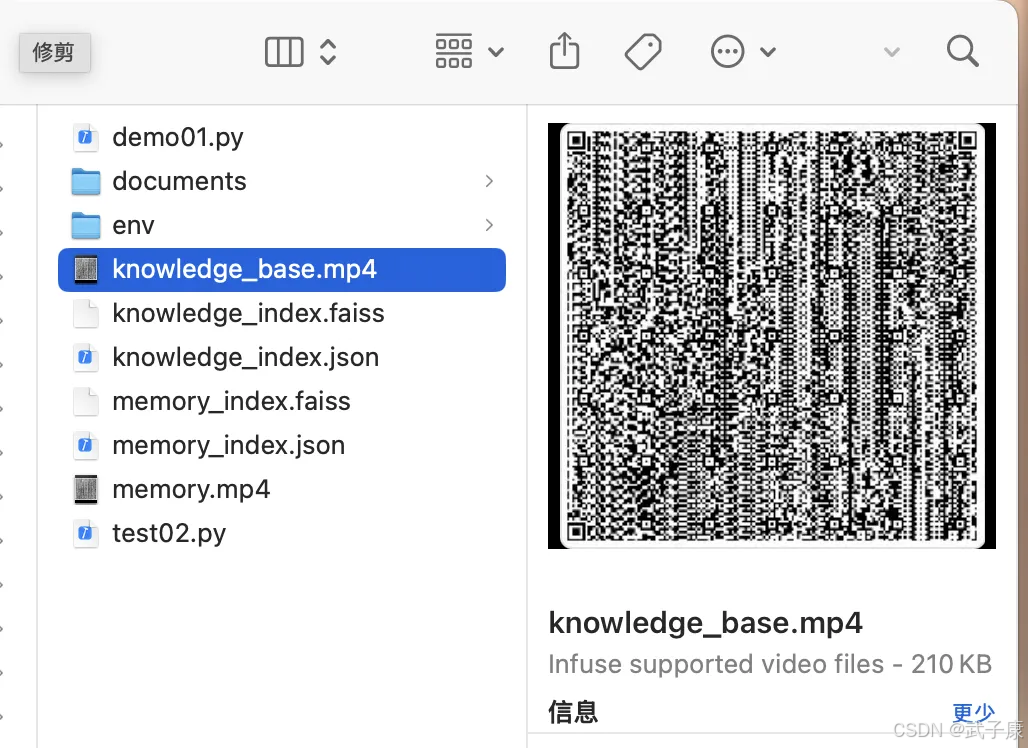
检索信息
我们刚才将数据写入了 MP4 中,现在我们将 MP4 中的数据检索出来:
from memvid import MemvidRetriever# Initialize retriever
retriever = MemvidRetriever("knowledge_base.mp4", "knowledge_index.json")# Semantic search
results = retriever.search(query="模型相关", top_k=5)
for each_str in results:print(f"each_str: {each_str}")
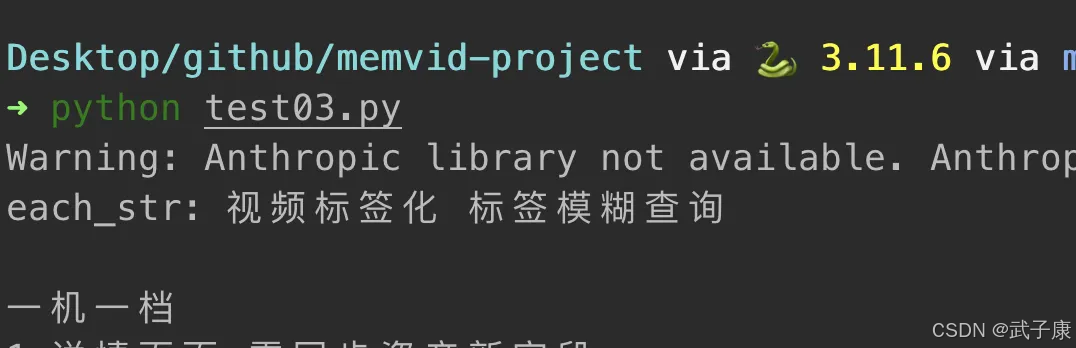
我们直接运行:
python test03.py
可以看到检索的结果:
相关参考
- https://github.com/Olow304/memvid
- https://pypi.org/project/memvid/