学习分库分表的前置知识:高可用系统架构理论与实践
引言 🌟
《阿里巴巴 Java 开发手册》中提到: 🔔 【推荐】单表行数超过 500 万行 或 单表容量超过 2GB,才推荐进行分库分表。说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
过早的分库分表会导致架构复杂度增加、维护成本上升;而忽视数据增长则可能导致查询性能下降,甚至引发服务崩溃。因此,理解并实施高可用系统架构设计至关重要。
本文将探讨以下内容:
- 读写分离架构
- CAP 定理及其应用
- 数据分片(垂直分片 & 水平分片)
- 高可用数据库架构实现方式
1. 🔁 读写分离架构:提升数据库读性能
1.1 基本原理
在高并发场景下,数据库的“读”操作通常远多于“写”操作。通过读写分离,我们可以显著提高系统的读取效率。
- 主服务器 (Master):负责处理所有写操作(增删改)。
- 从服务器 (Slave):负责处理读请求。
这种架构不仅分散了读写压力,还能有效避免因频繁的数据更新导致的行锁问题,从而提升整体性能。
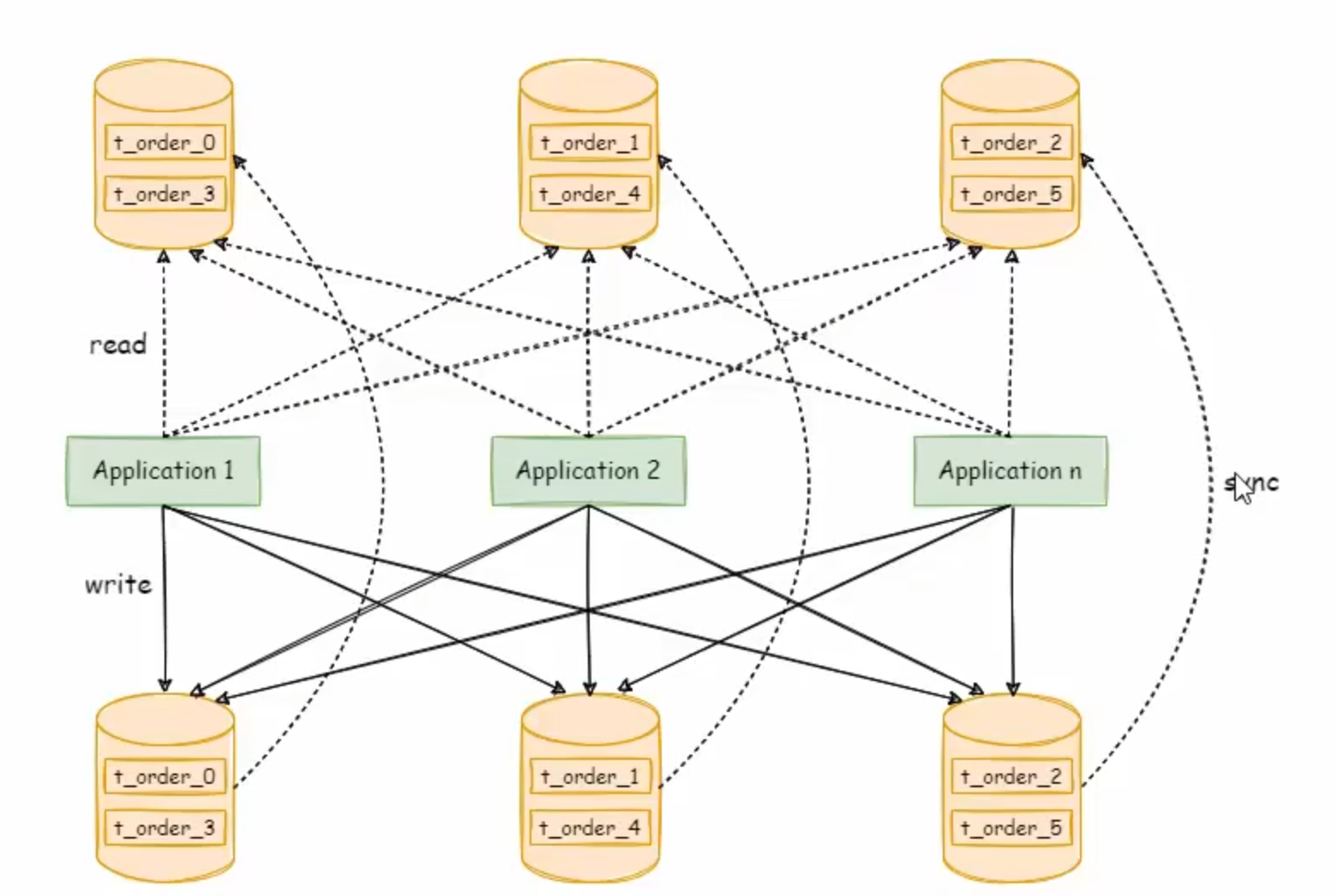
1.2 实现方式
1.2.1 程序逻辑实现
在数据访问层中实现读写分离,通过配置不同的数据库连接池来管理主从数据库的连接。
// 示例代码:基于 Spring 的 JdbcTemplate 实现读写分离
@Autowired
private JdbcTemplate jdbcTemplate; // 主库模板
@Autowired
private JdbcTemplate slaveJdbcTemplate; // 从库模板public User getUserById(Long id) {return slaveJdbcTemplate.queryForObject("SELECT * FROM user WHERE id = ?", new Object[]{id}, new UserRowMapper());
}public void updateUser(User user) {jdbcTemplate.update("UPDATE user SET name = ? WHERE id = ?", user.getName(), user.getId());
}1.2.2 中间件实现
使用中间件如 MyCat 或 ShardingSphere 可以更灵活地实现读写分离,无需修改业务代码即可动态调整读写策略。
2. 📊 CAP 定理:分布式系统的权衡
2.1 CAP 定理简介
CAP 定理指出,在一个分布式数据存储系统中,最多只能同时满足以下三个条件中的两个:
- 一致性 (Consistency):所有节点必须同时返回相同的数据。
- 可用性 (Availability):非故障节点在合理时间内返回合理的响应。
- 分区容错性 (Partition Tolerance):即使网络分区发生,系统仍然能够正常工作。
2.2 CAP 取舍案例
CP 架构:优先保证一致性和分区容错性。例如,银行系统需要确保交易的一致性,即使在网络分区时也要保证数据正确无误【例:当 N1 节点上的数据更新到 y,但由于网络分区,N2 节点无法同步最新数据。此时,N2 节点会返回错误提示,而不是旧数据。】。
AP 架构:优先保证可用性和分区容错性。例如,社交平台可以接受一定程度的数据不一致,只要用户能快速获取信息即可【例:当 N1 节点上的数据更新到 y,但由于网络分区,N2 节点无法同步最新数据。此时,N2 节点会返回旧数据 x,虽然不是最新的数据,但仍然是合理的。】。
需要注意的是,CA 架构实际上是一个误解——在分布式环境中,分区是不可避免的,因此 CA 并不是一个可行的选择。
3. 🛠️ 数据分片:应对大规模数据挑战
3.1 垂直分片
3.1.1 垂直分库
按照业务模块拆分数据库,例如订单数据、用户数据、商品数据分别存放在不同的数据库中。
-- 用户数据库
CREATE DATABASE user_db;-- 订单数据库
CREATE DATABASE order_db;3.1.2 垂直分表
将单表按列拆分为多个子表,遵循字段相关性原则。例如,用户表可以拆分为高频访问字段表、安全敏感字段表和低频大字段表。
-- 原始用户表
CREATE TABLE user (id INT PRIMARY KEY,name VARCHAR(50),email VARCHAR(100),password_hash CHAR(60),profile_text TEXT, -- 大字段last_login DATETIME
);-- 垂直拆分后
CREATE TABLE user_base (id INT PRIMARY KEY,name VARCHAR(50),email VARCHAR(100),last_login DATETIME
);CREATE TABLE user_security (user_id INT PRIMARY KEY,password_hash CHAR(60)
);CREATE TABLE user_profile (user_id INT PRIMARY KEY,profile_text TEXT
);3.2 水平分片
3.2.1 水平分表
将单表切分为多表,适用于单表数据量较大的情况。例如,一张表有 100 万条记录,可以将其拆分为 10 张表,每张表 10 万条记录。
-- 水平分表示例
CREATE TABLE user_01 LIKE user;
CREATE TABLE user_02 LIKE user;
...3.2.2 水平分库
当单表拆分为多表后,若单台服务器仍无法满足性能要求,则需将多个表分散在不同的数据库服务器中。
4. 🛡️ 高可用数据库架构实现方式
4.1 程序逻辑实现
在数据访问层中实现读写分离及数据库服务器连接管理,确保在不同场景下选择合适的数据库实例。
4.2 中间件实现
利用 MyCat 或 ShardingSphere 等中间件,实现更为灵活的读写分离和数据分片策略,减少对业务代码的影响。
✅ 总结
构建高可用系统架构是一项复杂的任务,涉及读写分离、CAP 定理的应用以及数据分片等多种技术手段。通过合理的架构设计和工具选型,可以在保障系统稳定性的同时,提升性能和可扩展性。