Pytorch进阶-timm库-00快速开始
什么是timm?
timm, 别称 pytorch-vision-model 库,是一个包含了各种计算机视觉任务中各种
- SOTA模型
- 常用层
- 实用小工具
- 优化器
- 调度器
- 数据加载器
- 数据增强工具
- 训练/评估脚本
的一个无所不包的库。它一共有700多个预训练的视觉模型,你可以直接通过几行代码把他们的架构或者权重直接拿过来为你所用。
什么人可能需要使用timm库?
- 需要快速复现SOTA论文模型的研究生/原型设计工程师
- 需要进行迁移学习的开发者
- 对视觉模型原理感兴趣,想找到模型优秀工业实现代码进行阅读的学生。
timm快速入门
1. 安装timm
pip install timm
2. 加载网络结构/预训练模型
你可以使用timm.create_model()来快速加载网络模型或者预训练权重。
import timmm = timm.create_model('mobilenetv3_large_100', pretrained=True) # 后面指定为True则加载预训练权重,False则不加载权重并随机初始网络参数。、
m.eval()
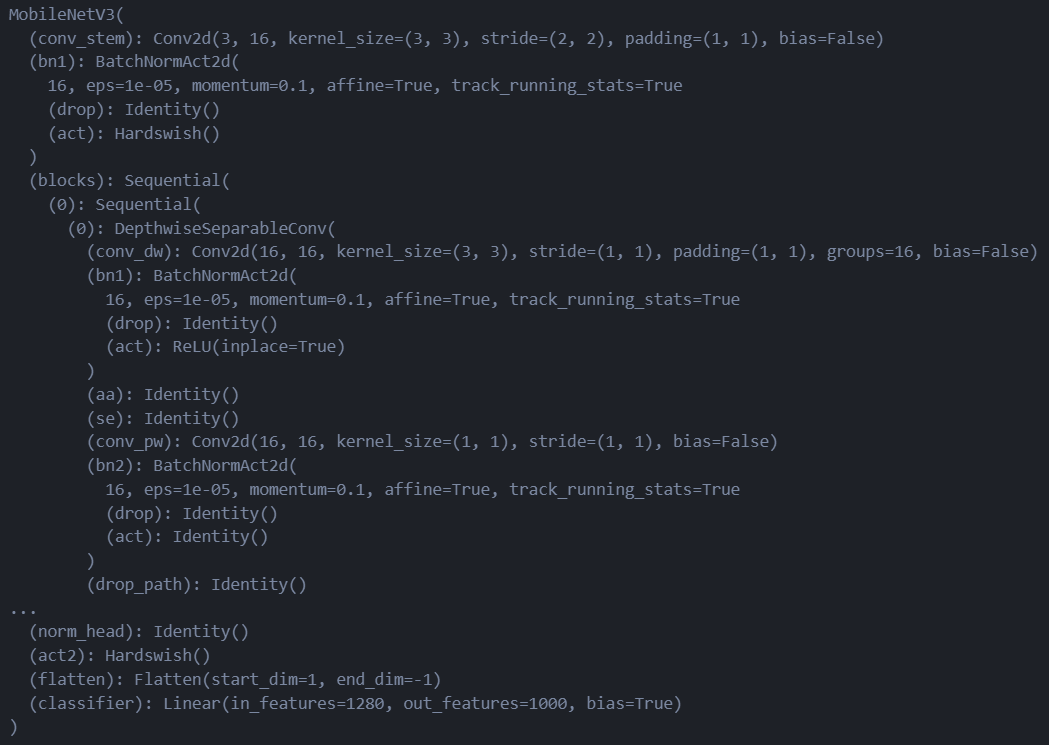
注意:
timm.create_model()返回的Pytorch模型默认设置为训练模型,因此如果你打算使用它进行推理,务必先把模型的模型用.eval()改成评估模式。
3. 列出具有与训练权重的模型
要列出timm已经打包好的网络模型,可以使用timm.list_models()方法。
- 过滤方法1:如果指定了
pretrained=True,还能只列出有预训练模型权重的模型。
from pprint import pprintmodel_names = timm.list_models(pretrained=True)
pprint(model_names)# 以下是输出
['aimv2_1b_patch14_224.apple_pt','aimv2_1b_patch14_336.apple_pt','aimv2_1b_patch14_448.apple_pt','aimv2_3b_patch14_224.apple_pt','aimv2_3b_patch14_336.apple_pt','aimv2_3b_patch14_448.apple_pt','aimv2_huge_patch14_224.apple_pt','aimv2_huge_patch14_336.apple_pt','aimv2_huge_patch14_448.apple_pt','aimv2_large_patch14_224.apple_pt','aimv2_large_patch14_224.apple_pt_dist','aimv2_large_patch14_336.apple_pt','aimv2_large_patch14_336.apple_pt_dist','aimv2_large_patch14_448.apple_pt','bat_resnext26ts.ch_in1k','beit3_base_patch16_224.in22k_ft_in1k','beit3_base_patch16_224.indomain_in22k_ft_in1k','beit3_base_patch16_224.indomain_pt','beit3_base_patch16_224.pt','beit3_large_patch16_224.in22k_ft_in1k','beit3_large_patch16_224.indomain_in22k_ft_in1k','beit3_large_patch16_224.indomain_pt','beit3_large_patch16_224.pt','beit_base_patch16_224.in22k_ft_in22k','beit_base_patch16_224.in22k_ft_in22k_in1k',
...'xcit_tiny_24_p8_384.fb_dist_in1k','xcit_tiny_24_p16_224.fb_dist_in1k','xcit_tiny_24_p16_224.fb_in1k','xcit_tiny_24_p16_384.fb_dist_in1k']
可以看到就算指定了有权重的网络,也有一大堆模型。
- 过滤方法2:字符串匹配,你可以使用字符串匹配的方法来找对应的模型,比如说你想找
vit相关的模型:
model_names = timm.list_models('*vit*')
pprint(model_names)# 输出,也还是有一大堆
['convit_base','convit_small','convit_tiny','crossvit_9_240','crossvit_9_dagger_240','crossvit_15_240','crossvit_15_dagger_240','crossvit_15_dagger_408','crossvit_18_240','crossvit_18_dagger_240','crossvit_18_dagger_408','crossvit_base_240','crossvit_small_240','crossvit_tiny_240','davit_base','davit_base_fl','davit_giant','davit_huge','davit_huge_fl','davit_large','davit_small','davit_tiny','efficientvit_b0','efficientvit_b1','efficientvit_b2',
...'vitamin_small_224','vitamin_xlarge_256','vitamin_xlarge_336','vitamin_xlarge_384']
4. 微调预训练模型(迁移学习,把模型骨架拿来用于你的任务)
这个技巧相当实用!也是迁移学习的核心操作!
要想挪用骨干网络已经训练好的强特征提取能力来处理你自己的视觉任务,你只需要修改最后一层的分类器,就可以微调任何预训练模型
model = timm.create_model('mobilenetv3_large_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
当然,开启这个微调还需要你自己编写pytorch train_loop(训练循环)或者调整已有的
timm训练脚本,并且你得有自己的微调数据集。
5. 使用预训练模型进行特征提取
无需修改任何网络,只需要调用模型的model.forward_features(x)方法(x是输入张量),就可以直接跳过模型的头部分类器和全局池化层,直接输出模型最后提取到的,在经过最后的分类器之前的特征。
import torchx = torch.randn(1, 3, 224, 224)
model = timm.create_model('mobilenetv3_large_100', pretrained=True)
features = model.forward_features(x)
print(features.shape)# 以下是输出
torch.Size([1, 960, 7, 7])更多有关timm进行特征提取的深入指南: Using timm to extract feature
6. 图像增强
要将图像转换为模型的有效输入,我们可以用pytorch通过实现自带的transform方法,在数据读取的时候实现预处理。但是这个的弊端就是你什么转换都得自己写。
为了省事,timm.data.create_transform() 提供了一个方便,快速定义数据transform的方法。
例子:规范图片尺寸+转tensor+normalize
举个例子,假设你想把不管多大的图片全部规范为3x224x244尺寸的图片,并且转换为tensor之后再Normalize,直接手动定义transform你会要写一大堆,但是在timm中你可以直接这么做:
timm.data.create_transform((3, 224, 224))# 以下为输出
Compose(Resize(size=256, interpolation=bilinear, max_size=None, antialias=True)CenterCrop(size=(224, 224))MaybeToTensor()Normalize(mean=tensor([0.4850, 0.4560, 0.4060]), std=tensor([0.2290, 0.2240, 0.2250]))
)
其直接返回了一个Compose对象,可以直接传给Datasets的transform参数,在预取数据的时候这些transform步骤将会被依次执行。
有了这个机制,在复现模型的时候,我们就没必要自己苦逼的把它的数据预处理逻辑自己写一遍了。而是可以直接把它定义好的转换拿过来用就完事,以下是具体把定义好的转换(JSON)文件转为可以直接传入transform参数的Compose实例的步骤:
- 先看下
model.pretrained_cfg的配置
model.pretrained_cfg# 以下是输出
{'url': 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_large_100_ra-f55367f5.pth','hf_hub_id': 'timm/mobilenetv3_large_100.ra_in1k','architecture': 'mobilenetv3_large_100','tag': 'ra_in1k','custom_load': False,'input_size': (3, 224, 224),'fixed_input_size': False,'interpolation': 'bicubic','crop_pct': 0.875,'crop_mode': 'center','mean': (0.485, 0.456, 0.406),'std': (0.229, 0.224, 0.225),'num_classes': 1000,'pool_size': (7, 7),'first_conv': 'conv_stem','classifier': 'classifier'}
- 使用
timm.data.resolve_data_config()解析出与数据预处理相关的配置
timm.data.resolve_data_config(model.pretrained_cfg)# 以下为输出
{'input_size': (3, 224, 224),'interpolation': 'bicubic','mean': (0.485, 0.456, 0.406),'std': (0.229, 0.224, 0.225),'crop_pct': 0.875,'crop_mode': 'center'}
- 将以上内容传递给
timm.data.create_transform()来初始化一个transform对象:
data_cfg = timm.data.resolve_data_config(model.pretrained_cfg)
transform = timm.data.create_transform(**data_cfg) # 字典解包,以键-值形式传递给create_transform函数pprint(transform)# 以下是输出
Compose(Resize(size=256, interpolation=bicubic, max_size=None, antialias=True)CenterCrop(size=(224, 224))MaybeToTensor()Normalize(mean=tensor([0.4850, 0.4560, 0.4060]), std=tensor([0.2290, 0.2240, 0.2250]))
)
7. 使用预训练模型进行推理
在这里,我们将把上述部分放在一起,并使用预训练模型进行推理。
首先,我们需要一张图像来进行推理。在这里,我们从网络加载一张猫的图片:
import requests
from PIL import Image
from io import BytesIO
url = 'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/timm/cat.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image

现在,我们将再次创建模型和变换,并将模型设置为评估模式
model = timm.create_model('mobilenetv3_large_100', pretrained=True).eval()
transform = timm.data.create_transform(**timm.data.resolve_data_config(model.pretrained_cfg)
)
我们可以直接把image传递给transform来给模型准备输入的tensor图像格式:
image_tensor = transform(image)
image_tensor.shape# 输出
torch.Size([3, 224, 224])
现在我们可以将该图像传递给模型以获得预测。在这种情况下,我们使用 unsqueeze(0)给张量的首部加一个维度, 因为模型需要批处理维度。
input = iamge_tensor.unsqueeze(0)
print(input.shape)
output = model(input)
print(output.shape)# 输出
torch.Size([1, 3, 224, 224])
torch.Size([1, 1000]) # 输出一共有1000类的概率
为了获得预测的概率,我们将 softmax 应用于输出。这会输出了一个尺寸为(num_classes,)的张量。
probabilities = torch.nn.functional.softmax(output[0], dim=0) # 沿着batch维度softmax
probabilities.shape # 输出
torch.Size([1000])
现在我们将使用 torch.topk 找到前 5 个预测的类索引和值。
values, indices = torch.topk(probabilities, 5)
indices# 输出
tensor([281, 282, 285, 673, 670])
如果我们检查顶部索引的 imagenet 标签,我们可以看到模型预测的内容:
IMAGENET_1k_URL = 'https://storage.googleapis.com/bit_models/ilsvrc2012_wordnet_lemmas.txt'
IMAGENET_1k_LABELS = requests.get(IMAGENET_1k_URL).text.strip().split('\n')
[{'label': IMAGENET_1k_LABELS[idx], 'value': val.item()} for val, idx in zip(values, indices)]# 以下是输出
[{'label': 'tabby, tabby_cat', 'value': 0.5101025700569153},{'label': 'tiger_cat', 'value': 0.22490699589252472},{'label': 'Egyptian_cat', 'value': 0.1835290789604187},{'label': 'mouse, computer_mouse', 'value': 0.006752475164830685},{'label': 'motor_scooter, scooter', 'value': 0.004942195490002632}]