【Datawhale AI夏令营】让AI读懂财报PDF(多模态RAG)(Task 2)
一、此次项目是一个复杂的生成类任务
多模态RAG任务 有四大核心要素:
数据源:一堆图文混排的PDF,这是我们唯一的数据。
这直接决定了我们系统的第一步必须是 文档解析 (Document Parsing) 。我们不能简单地把PDF当成一个黑盒。需要设计一个流程,能自动化、结构化地从这些PDF中提取出两种核心信息: 文本块 (Text Chunks) 和 图片 (Images) 。更进一步,提取出的每一份信息,都必须牢牢绑定它的元数据——它来自 哪个文件 (filename) 和 哪一页 (page) 。
可溯源:必须明确指出答案的出处。
这要求我们在整个处理流水线中实现 元数据(Metadata)的持续追踪 。
多模态:问题可能需要理解文本,也可能需要理解图表(图像)。
我们需要建立一个能让机器“看懂”图片,并将其与文本关联起来的机制。至少有三种主流的建模路径:
图片描述 (Image Captioning) : 对每张图片,使用一个视觉语言模型(如Qwen-VL, BLIP等)生成一段描述性的文字。
然后,我们将图和文的问题,统一转换成对“文本+图片描述”的纯文本检索问题。这是最简单直接的“降维”思路。
多模态向量化 (Multimodal Embedding) : 使用像
CLIP这样的多模态嵌入模型,将文本块和图片都转换到同一个高维向量空间。这样,一个文本形式的提问,可以直接在向量空间中寻找到语义上最相关的文本块和 图片本身 。
多模态大模型直接推理 : 将检索到的相关文本和图片 直接 喂给具备多模态理解能力的大语言模型(如Qwen-VL),让模型自己在内部完成信息的融合与推理。
这是最前沿的思路,对模型能力要求也最高。 我们的Baseline可以先从思路1或2开始构建。
问答:根据检索的信息生成一个回答。
系统的最终产出是一个自然、流畅、准确的答案,而不是简单地把检索到的原文丢给用户。
这是我们系统的最后一个核心模块—— 生成器 (Generator) 。这个角色通常由一个大语言模型(LLM)来扮演。
这个环节的成败,极度依赖 提示工程 (Prompt Engineering) 的质量。
二、那么任务要求究竟是怎么样的、以及有哪些重难点呢?
2.1 我们需要通过财报PDF,输出对应的多模态答案
略
2.2 分析一下赛题数据、探索如何处理
pymupdf:基于规则的方式提取pdf里面的数据,mineru:基于深度学习模型通过把PDF内的页面看成是图片进行各种检测,识别的方式提取。
2.3 赛题主要有四大难点
略
2.4 这里有一份参考的解题思考过程
略
三、来仔细了解一下Baseline方案是如何实现解题的!
baseline主要有两个处理阶段:
阶段一:离线预处理 (构建知识库)
包含文档解析 ( Parse ) 和知识库构建 ( Index ) 。
这个阶段的目标是将原始的PDF知识库,制作成一个可供快速检索的向量数据库。
阶段二:在线推理 (生成答案)
包含问题向量化 ( Query ) ,信息检索 ( Retrieve ) 和答案生成 ( Generate ) 。
这个阶段是用户提问时,系统实时响应的过程。
Baseline核心逻辑
首先是离线预处理构建知识库:从 PDF 文档出发,用 PyMuPDF 提取并分块文本,再聚合形成统一知识库(fitz_pipeline_all.py);接着是在线推理生成答案:接收用户问题后,先向量化,再基于向量数据库检索相关内容块,结合大语言模型,用检索内容构建 Prompt 生成答案,最后解析输出最终结果(rag_from_page_chunks.py)。
【AI生成】附录:知识点概述
RAG (Retrieval-Augmented Generation) : 检索增强生成。
1. 它是干嘛的?
简单来说,RAG 是让大语言模型(LLM)先查资料,再回答问题的一种方法。
普通 LLM:直接用自己“记住的”知识回答,但可能过时或不准确。
RAG:在回答前,先去外部资料库(文档、数据库、网页)找相关信息,然后结合这些资料来生成答案。
就像:
普通 LLM = 一个很聪明的朋友,靠记忆回答问题。
RAG = 这个朋友在回答前,先翻一下百科全书或 Google,然后再回答你。
2. 它是怎么做的?
RAG 分成两个步骤:
检索(Retrieval)
输入你的问题,比如 “今年的奥运会在哪举办?”
系统去外部知识库里搜索相关内容,找到几段最可能有用的文本。
这些文本可能是 PDF 里的段落、网页内容、数据库记录等。
生成(Generation)
把“问题 + 检索到的资料”一起喂给 LLM。
LLM 根据这些最新的资料来生成答案,而不是只靠训练时的旧知识。
3. 为什么有用?
避免幻觉:LLM 有时会“胡编乱造”,RAG 可以用检索到的真实资料来支撑答案。
更新快:不需要重新训练模型,直接更新知识库就能回答最新问题。
可定制:能针对特定领域(公司内部文档、科研资料、法律条款)提供更专业的回答。
4. 生活中的比喻
你问我:
“古代中国最长的运河是哪条?”
普通 LLM:我靠记忆回答,“京杭大运河”,但可能记忆不完整,还可能说错长度。
RAG:我先去查百度百科或史书,找到确切资料,然后说:
“古代中国最长的运河是京杭大运河,全长约 1794 公里,始建于隋朝。”
这样既准确,又能提供来源。
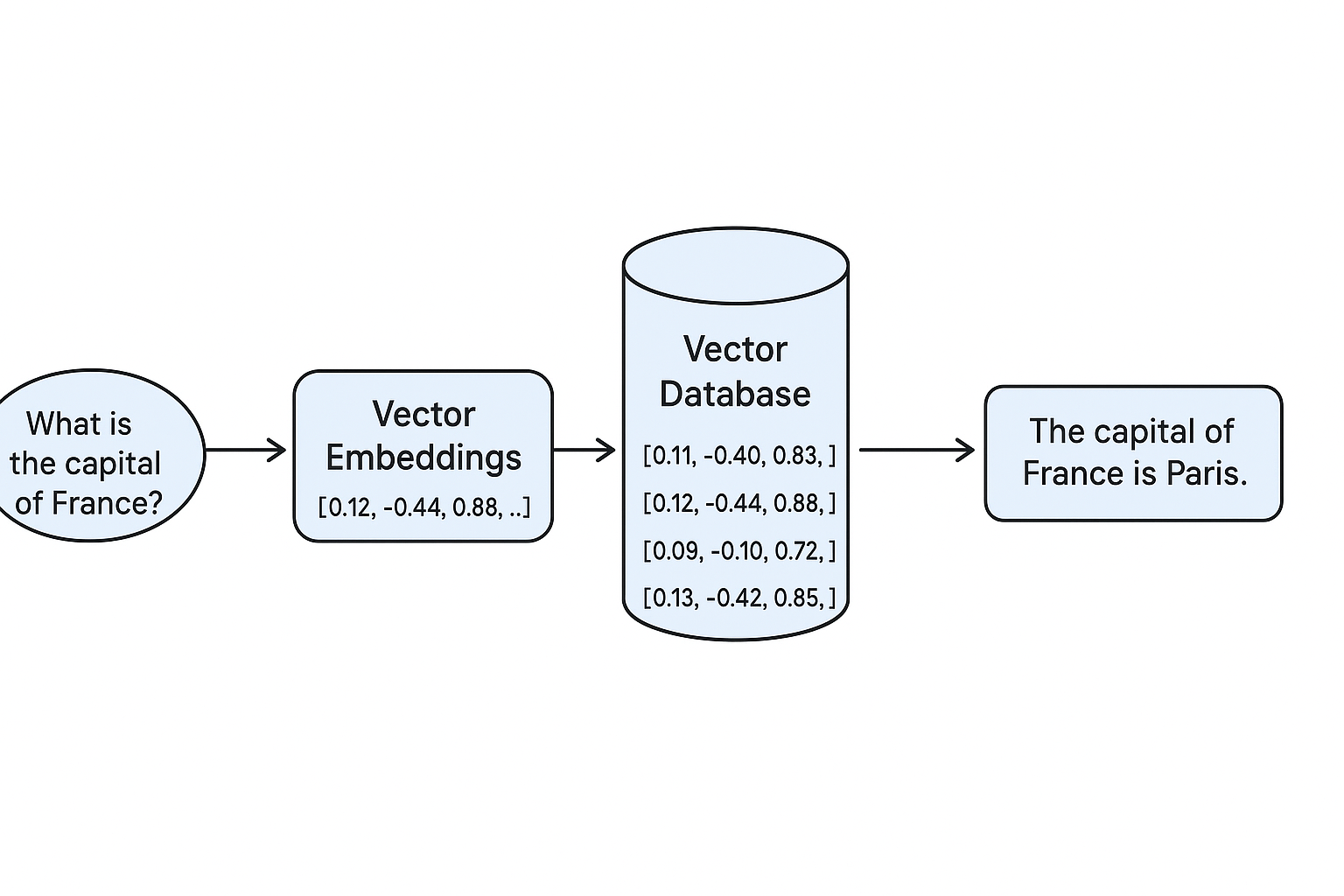
向量嵌入 (Vector Embeddings) : 这是让计算机理解文本语义的桥梁。
1. 它是干嘛的?
向量嵌入就是把一段内容(文字、图片、音频等)转换成一组数字,
让计算机能用“数学方式”去理解和比较它们的含义。
📌 换句话说:
向量嵌入 = 把内容翻译成计算机的“语义坐标”。
2. 为什么要这么做?
计算机不像人类能直接理解“苹果”和“香蕉”的意思。
如果我们用普通的字符串比较,"apple" ≠ "banana",它们只是不同的字母组合。
但用向量嵌入后:
“apple” 可能变成
[0.12, -0.44, 0.88, …]“banana” 可能变成
[0.11, -0.40, 0.83, …]
两个向量的距离很近,说明它们语义相似(都是水果)。
3. 它是怎么做的?
大致步骤:
训练嵌入模型(例如 Word2Vec、BERT、OpenAI Embeddings),让它学会把相似意思的内容映射到相近的向量空间。
把内容转成向量(embedding)。
用数学方法比较向量(常用余弦相似度、欧几里得距离)判断内容是否相似。
4. 生活中的比喻
想象我们有一张地图,
北京的坐标是 (116.4, 39.9)
上海的坐标是 (121.5, 31.2)
地理坐标表示“物理距离”,
而向量嵌入表示“语义距离”。
比如:
“猫” 和 “狗” 在语义地图上很近(都是宠物)。
“猫” 和 “汽车” 在语义地图上很远。
5. 和 RAG 的关系
在 RAG 里,向量嵌入经常用在检索步骤:
把知识库里的每段文本转成向量,存到“向量数据库”(如 FAISS、Milvus、Pinecone)。
用户提问时,也把问题转成向量。
用向量相似度找出最接近的问题或资料,再送给 LLM 生成答案。
向量数据库 (Vector Database) : 一个专门用于存储和高效查询海量向量的数据库。
1. 它是干嘛的?
向量数据库就是**专门用来存储和搜索“向量嵌入”**的数据库。
它的目标是:
给我一个向量(比如一个问题的向量)
快速找到数据库里最相似的向量(比如最相关的文档)
📌 换句话说:
如果普通数据库是“精确匹配”数据的,向量数据库就是“找最像”的。
2. 为什么普通数据库不行?
普通关系型数据库(MySQL、PostgreSQL)主要用主键、索引做精确或范围匹配。
但在语义搜索里,我们要找的是“意思相近”的内容,靠 WHERE text LIKE '%苹果%' 太死板。
向量数据库能做:
相似度搜索(Similarity Search)
用 余弦相似度、内积、欧几里得距离 来衡量两个向量有多接近。
3. 它是怎么做的?
向量数据库会:
存储向量嵌入(通常是几百到几千维的浮点数组)。
建立专门的索引结构(如 HNSW、IVF、PQ)来加速相似度搜索。
提供 API,让你用一个向量查找最相似的 K 条记录。
4. 生活中的比喻
想象你是一个“气味收藏家”:
你把每种气味(玫瑰、咖啡、汽油)转成“气味坐标”记录下来。
当有人给你闻一个新气味,你就能用数学计算找出最接近的几种气味。
向量数据库就是那个“存气味坐标+找最像”的工具。
5. 和 RAG、向量嵌入的关系
三者的关系可以这样看:
向量嵌入:把文本/图片/音频 转成向量(语义坐标)。
向量数据库:存这些向量,并能快速找到最相似的向量。
RAG:
输入问题 → 生成向量嵌入
在向量数据库里找最相关的内容
把找到的内容和问题一起送给 LLM 生成答案。