嵌入式Linux学习 - 数据结构6
五、哈希表
1. 哈希算法
将数据通过哈希算法映射成一个键值,存取都在同一位置实现数据的高效存储和查找
将时间复杂度尽可能降低至O(1)
2. 哈希碰撞
多个数据通过哈希算法得到的键值相同,称为产生哈希碰撞
3. 哈希表
构建哈希表存放0-100之间的数据
将0 - 100之间的数据的个位作为键值
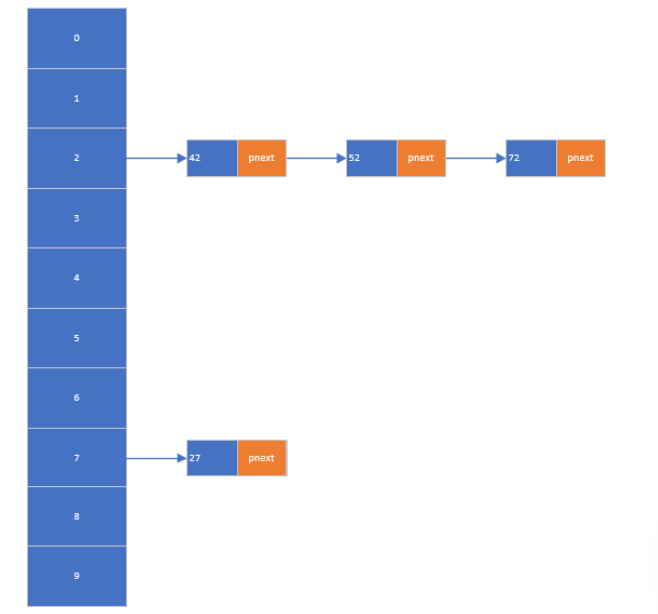
4. 哈希表的相关操作
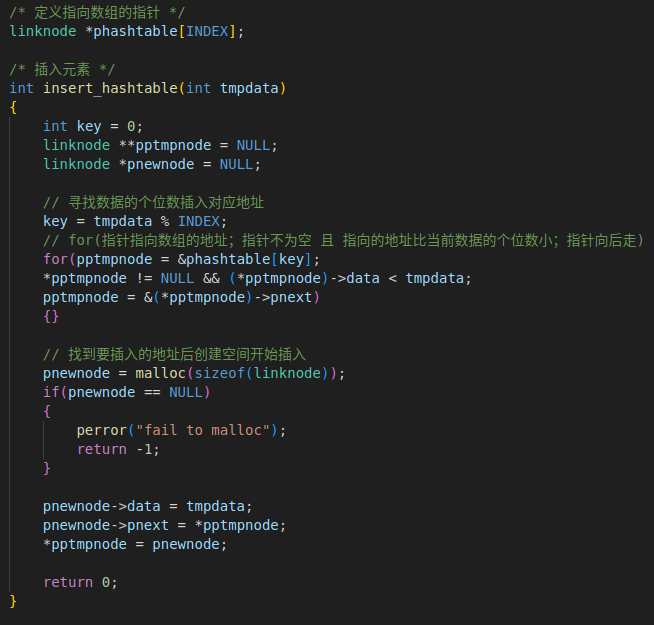
1. 插入元素
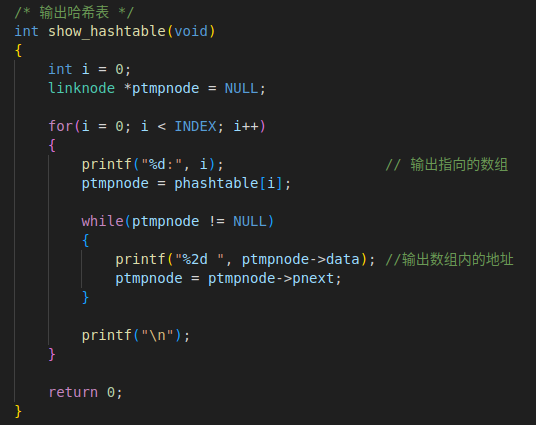
2. 遍历输出哈希表
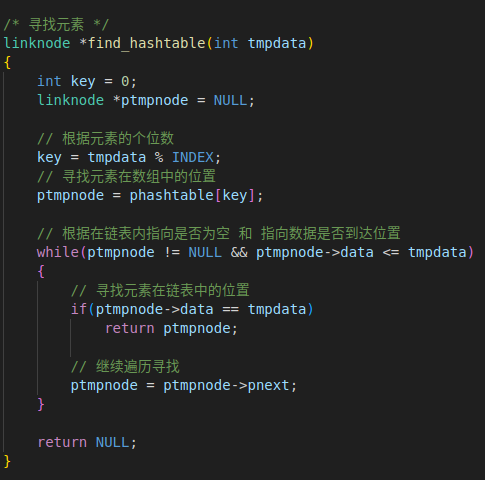
3. 查找元素’
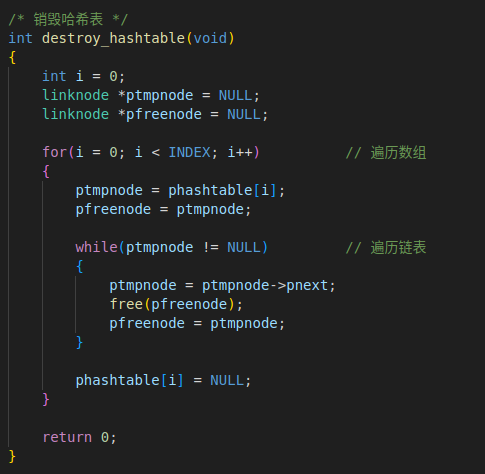
4. 销毁哈希表
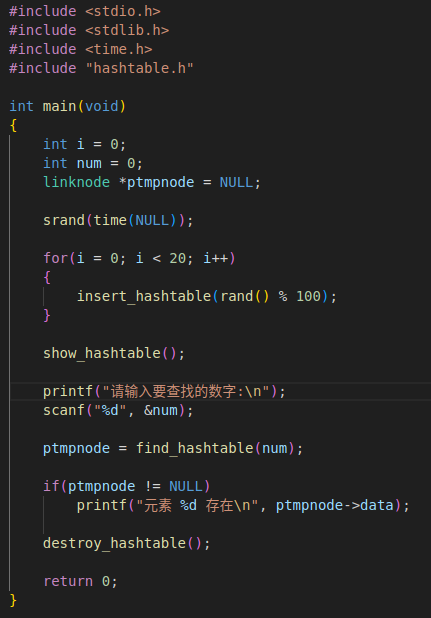
主函数:
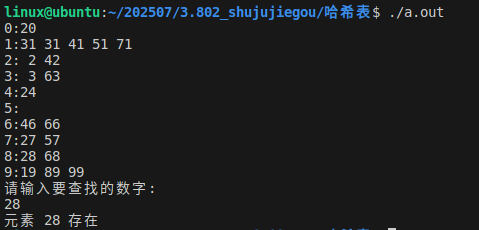
结果:
六、排序和查找算法
建立和输出被排序元素10000个
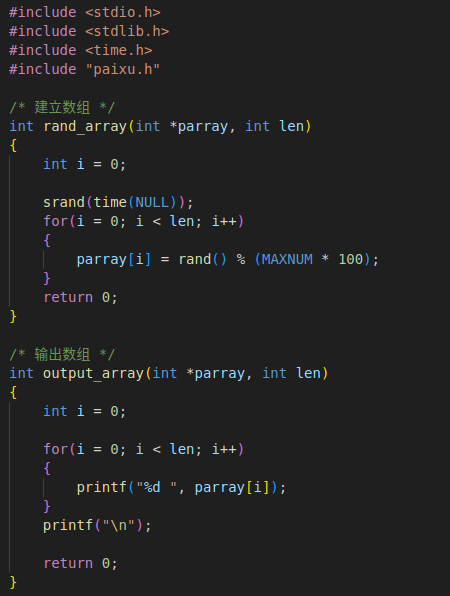
1. 冒泡排序
1. 时间复杂度为O(n^2)
2. 稳定的排序算法
3. 耗时:190 - 210ms
4. 运行原理:相邻的两个元素比较,大的向后走,小的向前走
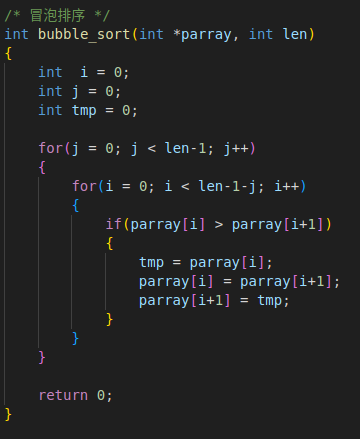
2. 选择排序
1. 时间复杂度为O(n^2)
2. 不稳定的排序算法
3. 耗时:120 - 130ms
4. 运行原理:从前到后找最小值与前面的元素交换
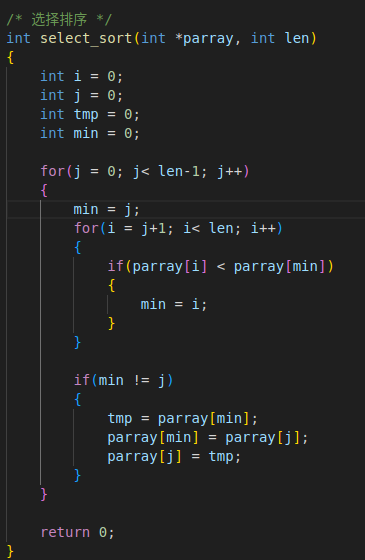
3. 插入排序
1. 时间复杂度为O(n^2)。若数组有序,时间复杂度降低至O(n)
2. 稳定的排序算法
3. 耗时:70ms - 80ms
4. 运行原理
将数组中的每个元素插入到有序数列中
先将要插入的元素取出
依次和前面元素比较,比元素大的向后走,直到前一个元素比要插入的元素小,或者到达有序数列开头停止
最后插入被取出的元素
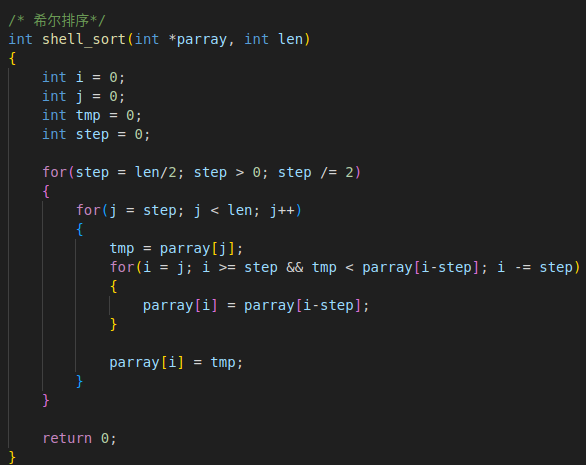
4. 希尔排序
1. 时间复杂度为O(nlogn)
2. 不稳定的排序算法
3. 耗时: 5 - 10ms
4. 运行原理
通过选择不同的步长,将数组拆分成若干个小的数组实现插入排序
若干个小的数组称为有序数列后,使得数组中的数据大致有序
最后再对整体完成一个插入排序
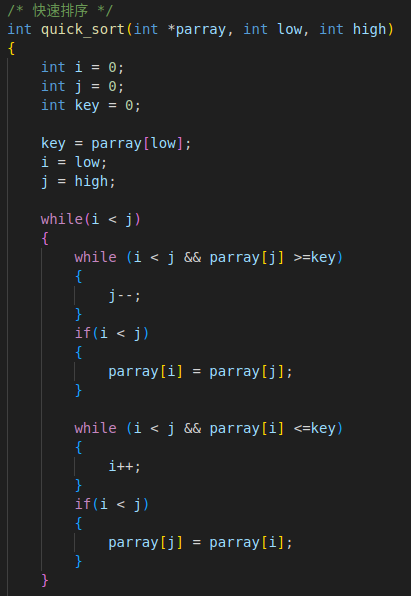
5. 快速排序
1. 时间复杂度为O(nlogn)
2. 不稳定的排序算法
3. 耗时:4 - 10ms
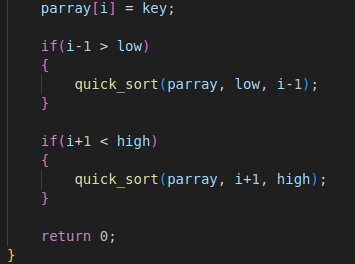
4. 运行原理
选择左边的作为键值,从后面找一个比键值小的放前面,从前面找一个比键值大的放后面
左右两边有元素则递归调用快速排序
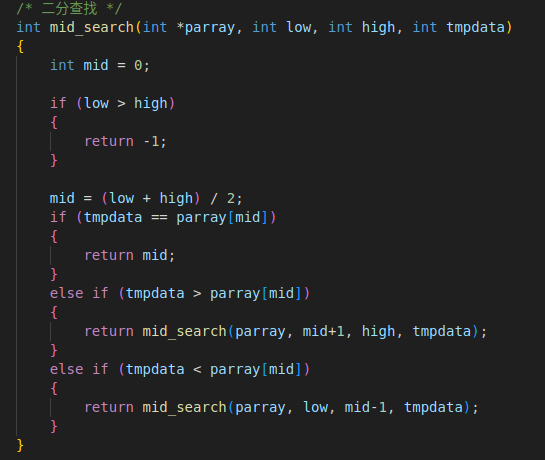
6. 折半查找 -- 二分查找