机器学习-----SVM(支持向量机)算法简介
一、数学原理:从几何直观到优化方程
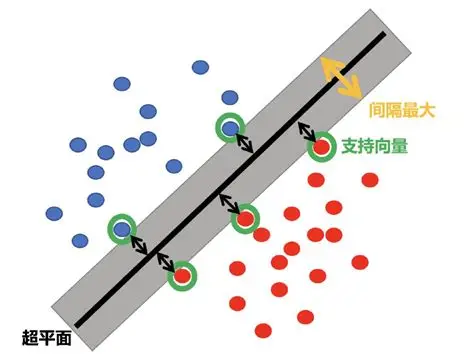
1.线性可分的硬核定义
给定训练集 {(xᵢ, yᵢ)},i=1…n,其中 xᵢ∈ℝᵈ,yᵢ∈{+1,−1}。
若存在超平面 w·x+b=0,使得
yᵢ(w·xᵢ+b)≥1, ∀i
则称数据线性可分。满足该条件的超平面有无穷多个,SVM 挑的是“最胖”的那一个——几何间隔最大化。
2.优化目标(硬间隔)
找到的那一条分类直线使其,尽可能地远离两边的样本点,因为离的越远数据越不容易落在超平面上,说明训练的越好。
公式:minimize ½‖w‖²
s.t. yᵢ(w·xᵢ+b)≥1, ∀i
这是一个凸二次规划,保证全局最优。
目标函数:最小化 w 的 L2 范数,等价于最大化 2/‖w‖,也就是最大化几何间隔。
约束条件:所有样本被正确分类且离超平面至少 1/‖w‖ 远。
3.对偶问题与核技巧
利用拉格朗日乘子 αᵢ 得到对偶形式:
maximize Σ αᵢ − ½ Σ Σ αᵢαⱼ yᵢ yⱼ <xᵢ,xⱼ>
s.t. Σ αᵢ yᵢ=0, 0≤αᵢ≤C
决策函数变为
f(x)=sign( Σ αᵢ yᵢ <xᵢ,x> + b )
亮点:只需样本内积 <xᵢ,xⱼ>,无需显式 w。
当数据线性不可分时,核函数 k(xᵢ,xⱼ)=<φ(xᵢ),φ(xⱼ)> 把原始特征从低维 ℝᵈ 映射到高维(甚至无限维)希尔伯特空间 ℋ,使得在新空间里线性可分。
常用核:
- RBF(高斯):k(x,x′)=exp(−γ‖x−x′‖²)
- 多项式:k(x,x′)=(γ x·x′+r)ᵈ
5.支持向量的几何意义
只有 αᵢ>0 的样本参与决策,其余样本删去不影响模型——这就是“支持向量”名字的由来。模型复杂度与支持向量个数成正比,而非特征维度,带来天然正则化效果。
二、算法流程与代码示范
一、问题与目标
鸢尾花数据集包含 150 条样本,每条样本有 4 个数值型特征(萼片/花瓣的长、宽)和 1 个类别标签(Setosa、Versicolor、Virginica)。我们的目标是训练一个模型,仅通过 4 个测量值即可准确预测花种,从而为植物分类学家、农业生产者提供低成本、可复现的自动化工具。
二、数据准备——“垃圾进、垃圾出”的防护墙
1.载入数据
import pandas as pd
data = pd.read_csv("iris.csv", header=None)这一步把存放在 CSV 中的原始记录读成内存里的 DataFrame,方便后续向量化运算。
2.特征/标签拆分
X = data.iloc[:, 1:5] # 4 个连续特征
y = data.iloc[:, -1] # 类别标签科研场景中,这一步往往伴随特征工程:缺失值处理、异常值剔除、标准化、构造多项式特征等。在 Iris 这样干净的数据集里,我们只需保证特征与标签的维度对齐即可。
3.训练/测试划分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)留出 20 % 作为“未知考场”,防止模型“背题库”。random_state 保证实验可复现,方便后续调参、写论文。
三、建模——SVM 的核心思想
1.算法选择
from sklearn.svm import SVC
model = SVC(kernel='linear', C=1e6, random_state=42)kernel='linear':在 4 维特征空间中寻找线性超平面。
C=1e6:惩罚系数非常大,相当于把“软间隔”退化成“硬间隔”,只允许极少量的误分类或离群点。
random_state:固定内部随机数种子,结果可复现。
2.训练(拟合)
model.fit(X_train, y_train)这一步背后发生的是凸二次规划:算法在 4 维空间中寻找一个 wᵀx+b=0 的超平面,使得不同类别之间的“功能间隔”最大化。真正决定平面位置的是少数离边界最近的样本——支持向量(Support Vectors)。训练完成后,可通过 model.support_vectors_ 查看这些“关键样本”。
四、可视化——让几何直觉落地(可选但重要)
虽然 Iris 有 4 个维度,无法直接画图,但我们可以选取 2 个最具区分力的维度(例如花瓣长、宽)做二维投影,帮助非技术背景的评审专家一眼看懂“间隔最大化”长什么样:
import matplotlib.pyplot as plt
import numpy as np# 取前两个类别做二分类示例
binary = data[data[4].isin([0, 1])]
X2 = binary.iloc[:, [1, 3]]
y2 = binary.iloc[:, -1]svm_2d = SVC(kernel='linear', C=1e6).fit(X2, y2)
w, b = svm_2d.coef_[0], svm_2d.intercept_[0]# 画决策边界与间隔
x1 = np.linspace(X2.iloc[:, 0].min(), X2.iloc[:, 0].max(), 300)
x2 = -(w[0]*x1 + b)/w[1]
x2_up = (1 - (w[0]*x1 + b))/w[1]
x2_down = (-1 - (w[0]*x1 + b))/w[1]plt.scatter(X2.iloc[:, 0], X2.iloc[:, 1], c=y2, cmap='coolwarm')
plt.plot(x1, x2, 'k-', lw=2)
plt.plot(x1, x2_up, 'k--', lw=1)
plt.plot(x1, x2_down, 'k--', lw=1)
plt.scatter(svm_2d.support_vectors_[:, 0],svm_2d.support_vectors_[:, 1],s=80, facecolors='none', edgecolors='k')
plt.title("Linear SVM: Maximal-Margin Hyperplane")
plt.show()通过这张图,评委可以直观看到:
实线是决策边界;
虚线是间隔边界;
圆圈或×是支持向量;
没有样本落在两条虚线之间,说明 C 足够大,间隔是“硬”的。
五、评估——用数字说话
1.训练集表现
from sklearn import metrics
y_pred_train = model.predict(X_train)
print("训练集报告:\n", metrics.classification_report(y_train, y_pred_train))理想情况下,训练集准确率应接近 100 %,因为 SVM 对线性可分问题能找到全局最优。
2.测试集表现
y_pred_test = model.predict(X_test)
print("测试集报告:\n", metrics.classification_report(y_test, y_pred_test))
print("测试集准确率:", metrics.accuracy_score(y_test, y_pred_test))如果测试集准确率也在 96 % 以上,说明模型泛化良好;若差距明显,则需回到“特征工程”或“调参”环节。
六、流程图小结(一句话版)
数据 → 拆分 → 训练 →(可视化)→ 评估 → 上线/报告
每一步都对应科研或生产中的质量关卡:
数据决定上限;
拆分防止过拟合;
训练解决凸优化;
可视化沟通成果;
评估量化效果;
上线产生价值。
七、可拓展方向(供经费申请书展望)
非线性核:RBF、多项式核处理更复杂的性状数据。
特征选择:用 SVM-RFE 或 SHAP 找出真正影响花种的测量指标,降低田间调查成本。
多任务迁移:把在 Iris 上学到的模型迁移到本地野生花卉,减少标注样本。
实时部署:将模型封装为 REST API,植物学家在手机端拍照即可实时识别。
结语
SVM 的魅力在于“大道至简”:一个最大化间隔的目标函数,加上核技巧,就能覆盖线性/非线性、低维/高维的众多场景。通过上述流程,我们不仅完成了一个“鸢尾花三分类”任务,更展示了一套通用的机器学习落地范式,可为后续更大规模的作物病害识别、生态环境监测等项目奠定方法学基础。