Java技术栈/面试题合集(19)-架构设计篇
场景
Java入门、进阶、强化、扩展、知识体系完善等知识点学习、性能优化、源码分析专栏分享:
Java入门、进阶、强化、扩展、知识体系完善等知识点学习、性能优化、源码分析专栏分享_java高级进阶-CSDN博客
通过对面试题进行系统的复习可以对Java体系的知识点进行查漏补缺。
合集明细列表
Java技术栈/面试题合集(1)-Java基础篇:
Java技术栈/面试题合集(1)-Java基础篇-CSDN博客
Java技术栈/面试题合集(2)-Java集合篇:
Java技术栈/面试题合集(2)-Java集合篇-CSDN博客
Java技术栈/面试题合集(3)-Java并发篇:
Java技术栈/面试题合集(3)-Java并发篇-CSDN博客
Java技术栈/面试题合集(4)-Spring篇:
Java技术栈/面试题合集(4)-Spring篇-CSDN博客
Java技术栈/面试题合集(5)-SpringBoot篇:
Java技术栈/面试题合集(5)-SpringBoot篇-CSDN博客
Java技术栈/面试题合集(6)-Mybatis篇:
Java技术栈/面试题合集(6)-Mybatis篇-CSDN博客
Java技术栈/面试题合集(7)-Mysql篇:
Java技术栈/面试题合集(7)-Mysql篇-CSDN博客
Java技术栈/面试题合集(8)-Redis篇:
Java技术栈/面试题合集(8)-Redis篇-CSDN博客
Java技术栈/面试题合集(9)-Nginx篇-part1:
Java技术栈/面试题合集(11)-设计模式篇-CSDN博客
Java技术栈/面试题合集(10)-Nginx篇-part2:
Java技术栈/面试题合集(10)-Nginx篇-part2-CSDN博客
Java技术栈/面试题合集(11)-设计模式篇:
Java技术栈/面试题合集(11)-设计模式篇-CSDN博客
Java技术栈/面试题合集(12)-Maven篇:
Java技术栈/面试题合集(12)-Maven篇-CSDN博客
Java技术栈/面试题合集(13)-网络篇:
Java技术栈/面试题合集(13)-网络篇-CSDN博客
Java技术栈/面试题合集(14)-Linux篇:
Java技术栈/面试题合集(14)-Linux篇-CSDN博客
Java技术栈/面试题合集(15)-RabbitMQ篇:
Java技术栈/面试题合集(15)-RabbitMQ篇-CSDN博客
Java技术栈/面试题合集(16)-SpringCloud篇:
Java技术栈/面试题合集(16)-SpringCloud篇-CSDN博客
Java技术栈/面试题合集(17)-Git篇:
Java技术栈/面试题合集(17)-Git篇-CSDN博客
Java技术栈/面试题合集(18)-数据结构与算法篇:
Java技术栈/面试题合集(18)-数据结构与算法篇-CSDN博客
更多合集文章持续更新中。。。。。。。。。。
专栏合集地址:
https://blog.csdn.net/badao_liumang_qizhi/category_13021060.html
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
Java架构设计:设计一个抽奖系统,奖品123,概率分别为1%,2%,3%,具体讲一下怎么设计?
一、核心需求分析
奖品配置:奖品1(1%)、奖品2(2%)、奖品3(3%)、未中奖(94%)。
公平性:概率需严格符合配置,避免人为干预。
高性能:支持高并发抽奖请求(如秒杀活动)。
二、架构设计(5大核心模块)
1. 奖品概率管理
数据结构:使用TreeMap或Alias Method算法实现加权随机
// 示例:TreeMap实现概率区间
TreeMap<Double, Prize> prizeMap = new TreeMap<>();
prizeMap.put(0.01, Prize1); // 0~1% → 奖品1
prizeMap.put(0.03, Prize2); // 1%~3% → 奖品2
prizeMap.put(0.06, Prize3); // 3%~6% → 奖品3 动态配置:通过数据库或配置中心实时调整概率。
2. 抽奖逻辑实现
算法选择:
普通场景:ThreadLocalRandom生成随机数,匹配概率区间。
高性能场景:预生成概率池(如Redis的RANDOMKEY)。
代码片段
public Prize draw() { double random = ThreadLocalRandom.current().nextDouble(1); return prizeMap.ceilingEntry(random).getValue();
} 3. 库存与限流
库存控制:Redis原子操作扣减库存(DECR + Lua脚本)。
-- Redis Lua脚本示例
if redis.call("GET", "prize1_stock") > 0 then return redis.call("DECR", "prize1_stock")
else return -1
end 限流措施:Guava RateLimiter或Sentinel控制QPS。
4. 分布式事务
中奖记录处理:
本地事务 + 消息队列(RocketMQ事务消息)确保数据一致性。
异步落库,避免抽奖接口性能瓶颈。
5. 风控与日志
风控策略:
用户黑名单(Redis布隆过滤器)。
单日抽奖次数限制(INCR + EXPIRE)。
日志监控:ELK收集抽奖日志,实时监控中奖率偏差。
三、性能优化关键点
缓存预热:活动前将奖品概率加载到本地缓存。
无锁设计:使用LongAdder替代AtomicInteger统计抽奖次数。
异步化:抽奖与发奖逻辑解耦(MQ异步通知发货)。
Java架构设计:有一个用户提现 100 元,他的余额只有 100,如何在用户多次点击提现按钮的情况下,实现幂等?
一、问题核心分析
场景:用户余额100元,连续多次点击提现100元按钮,需保证:
仅成功扣款一次
重复请求返回相同结果
高并发下数据一致性
二、幂等性实现方案(5大核心策略)
1. 数据库唯一索引
实现逻辑:
提现记录表增加request_id字段(用户ID+业务单号),创建唯一索引
插入前检查是否存在相同request_id
代码示例
@Transactional
public Result withdraw(Long userId, String requestId, BigDecimal amount) { // 检查是否已处理过该请求 if (withdrawRecordDao.existsByRequestId(requestId)) { return Result.success(" 重复请求,已处理"); } // 扣减余额(原子操作) int updated = accountDao.deductBalance(userId, amount); if (updated == 0) { return Result.fail(" 余额不足"); } // 记录提现 withdrawRecordDao.insert(new WithdrawRecord(userId, requestId, amount)); return Result.success(" 提现成功");
} 优点:简单直接,依赖数据库约束
缺点:高频请求可能触发索引冲突
2. 分布式锁 + 状态机
实现逻辑:
使用Redis锁(SETNX key value EX 10)锁定用户ID
提现状态机:初始化 → 处理中 → 已完成
代码示例
public Result withdraw(Long userId, String requestId) { String lockKey = "withdraw:lock:" + userId; try { // 获取分布式锁(防止并发请求) boolean locked = redisTemplate.opsForValue() .setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS); if (!locked) return Result.fail(" 操作频繁"); // 检查幂等记录 WithdrawRecord record = withdrawRecordDao.findByRequestId(requestId); if (record != null) { return Result.success(record.getStatus()); // 返回历史结果 } // 扣款并记录状态 accountService.deductBalance(userId, 100); withdrawRecordDao.insert(new WithdrawRecord(requestId, "已完成")); return Result.success(" 提现成功"); } finally { redisTemplate.delete(lockKey); }
} 优点:避免数据库压力,支持高并发
缺点:需处理锁超时问题
3. 乐观锁(CAS机制)
实现逻辑:
账户表增加version字段
扣款时校验版本号
SQL示例
UPDATE account
SET balance = balance - 100, version = version + 1
WHERE user_id = ? AND version = ? AND balance > = 100 优点:无锁竞争,性能较高
缺点:需重试机制处理版本冲突
4. 消息队列幂等
实现逻辑:
提现请求发送到RocketMQ,携带唯一msgId
消费者通过msgId去重处理
架构图:
用户请求 → MQ(幂等过滤) → 消费者(原子扣款) → 结果通知
优点:天然解耦,支持流量削峰
缺点:系统复杂度增加
5. Token机制(前端配合)
实现逻辑:
前端提现页先获取服务端生成的token
提交请求时携带token,服务端校验后删除
流程示例
// 生成一次性token
String token = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("withdraw:token:" + userId, token, 5, TimeUnit.MINUTES); // 提现时校验
String storedToken = redisTemplate.opsForValue().get("withdraw:token:" + userId);
if (!token.equals(storedToken)) { return Result.fail(" 无效请求");
}
redisTemplate.delete("withdraw:token:" + userId); // 删除已用token 优点:彻底避免重复提交
缺点:依赖前端配合
Java架构设计:假如有个业务信息表,我要删除表前三个月state为0的数据,如何设计索引?
一、需求分析
操作类型:定期删除state=0且创建时间早于3个月的数据
性能目标:
删除效率高(避免全表扫描)
不影响高频查询性能
减少锁竞争
二、索引设计方案(3大核心策略)
1. 复合索引(优先推荐)
字段顺序:(state, create_time)
CREATE INDEX idx_state_createtime ON business_info(state, create_time); 优势:
精准匹配state=0后,按时间范围快速定位(B+树最左前缀原则)
覆盖索引减少回表
删除SQL示例
DELETE FROM business_info
WHERE state = 0
AND create_time < DATE_SUB(NOW(), INTERVAL 3 MONTH); 理由
按最优实践,复合索引应把等值查询的列放前面,范围查询的列放后面。
这样,数据库可以先快速定位所有 state=0 的数据,再在这些数据中按 create_time 判断是否早于三个月前,极大减少了扫描和对比的数据行数
2. 分区表 + 局部索引
适用场景:数据量超千万级
实现步骤:
按时间范围分区(每月一个分区)
每个分区单独建立state索引
3. 归档表 + 异步删除
架构流程:
业务表 → 触发器归档state=0数据 → 定时任务删除归档数据
索引建议:
主表索引:(state)(保证查询性能)
归档表索引:(create_time)(加速删除)
优势:
避免主表大事务
可批量删除(LIMIT 5000)减少锁持有时间
Java架构设计:电商系统如何保证扣减库存高并发性能,又保证不会出现超卖问题?
一、核心挑战与设计目标
高并发性能:支持万级TPS的库存扣减请求(如秒杀场景)。
数据一致性:杜绝超卖(库存扣减后<0)和少卖(库存未及时释放)。
系统可用性:避免单点故障,保证99.99%的服务可用性。
二、技术方案(4大核心策略)
1. 分布式缓存 + 异步落库
架构流程
graph LR
A[用户请求] --> B[Redis预扣减库存]
B --> C{库存是否≥0?}
C -->|是| D[写入MQ]
C -->|否| E[返回库存不足]
D --> F[消费者异步更新DB]
关键实现:
Redis原子操作:使用DECRBY或Lua脚本保证原子性
补偿机制:定时任务比对Redis与DB库存差异,自动修正
2. 数据库乐观锁 + 分库分表
SQL优化
UPDATE item_stock
SET stock = stock - 1, version = version + 1
WHERE item_id = ? AND version = ? AND stock >= 1 分库策略:
按商品ID哈希分片(如16个库,每个库256张表)
热点商品单独分片(如iPhone秒杀专用库)
3. 本地缓存 + 分布式限流
多级缓存:
JVM缓存(Caffeine) → Redis集群 → DB
缓存预热:活动前加载热点商品库存到本地
限流保护:
Sentinel配置QPS阈值(如单商品5000/s)
令牌桶算法平滑处理突发流量
4. 事务消息 + 柔性事务
最终一致性保障:
扣减Redis库存后发送RocketMQ事务消息
消费者完成订单创建,再异步扣减DB库存
失败时通过反向流水恢复库存
Java架构设计:1G内存,如何快速判某个无符号整数是否在40亿数据中?
一、问题核心与挑战
数据规模:40亿无符号整数 ≈ 4×10⁹ × 4字节 ≈ 16GB内存(远超1G限制)
性能目标:O(1)时间复杂度完成存在性判断
内存限制:需设计空间效率极高的数据结构
二、解决方案(3大核心策略)
1. 布隆过滤器(Bloom Filter)
原理:
使用多个哈希函数将元素映射到位数组(BitSet)
存在性判断可能有假阳性(误报),但无假阴性(漏报)
内存计算:
假设误判率0.1%,需约 570MB内存(公式:n=4e9, p=0.001 → m=4.8e9 bits ≈ 572MB)
Java实现
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels; BloomFilter<Integer> filter = BloomFilter.create( Funnels.integerFunnel(), 4_000_000_000L, // 预期元素数量 0.001 // 误判率
); // 添加数据
filter.put(123456);
// 判断存在性
boolean mayExist = filter.mightContain(123456); 2. 位图法(BitMap)
适用场景:数据范围可控(如整数范围≤2³²)
内存计算:
2³²位 ≈ 512MB内存(每位表示一个整数)
优化变种:
Roaring Bitmap:压缩稀疏位图,内存占用可低至100MB~1GB
Java实现
import org.roaringbitmap.RoaringBitmap;
RoaringBitmap bitmap = new RoaringBitmap();
bitmap.add(123456L);
boolean exists = bitmap.contains(123456L); 3. 外部存储 + 分片索引
架构设计:
将40亿数据按哈希分片存储到磁盘(如10个文件,每文件4亿数据)
内存中维护分片索引(如哈希表记录每个分片的数值范围)
查询时先定位分片,再加载部分数据到内存二分查找
性能权衡:
内存占用:分片索引≈10MB,每次查询加载4MB数据
时间复杂度:O(log n)
Java架构设计:高并发系统该如何选择合适的限流模型?
一、限流核心目标
保护系统稳定性:避免突发流量击穿服务
资源公平分配:防止少数用户占用过多资源
优雅降级:超限请求快速失败,避免雪崩
二、主流限流模型对比与选型
1. 计数器算法(固定窗口)
原理:统计单位时间(如1秒)内请求数,超过阈值则拒绝。固定窗口指将时间轴划分为一段一段等长的区间(如每1秒为一个窗口)。
在每个窗口内,累计请求次数;只要计数未超过阈值就放行,当达到阈值后本窗口内其它请求就会被限流。
每当时间进入下一个窗口,计数重置为0
图示

实现
AtomicInteger counter = new AtomicInteger(0);
boolean tryAcquire() { return counter.incrementAndGet() <= 1000; // 每秒限流1000次
} 优点:简单高效,内存消耗低
缺点:窗口切换时可能产生双倍流量冲击
适用场景:对精度要求不高的简单限流(如API基础防护)
2. 滑动窗口算法
原理:
将时间窗口细分为多个子窗口(如1秒=10个100ms窗口),动态统计最近完整窗口的请求量。
滑动窗口将统计时间窗口再细分为多个更小的子窗口(如将1秒分10份,每100ms为一个子窗口),
时间轴上可“滑动”地累加最近一段时间内所有子窗口的请求总数。
每次请求时动态统计最近N个小窗口的总和,从而减少突刺,提高流控精准度。
图示

优化:
Redis + Lua实现分布式滑动窗口
优点:平滑流量,避免固定窗口的临界问题
缺点:内存占用较高(需存储子窗口计数)
适用场景:需要精确控制的API限流(如支付接口)
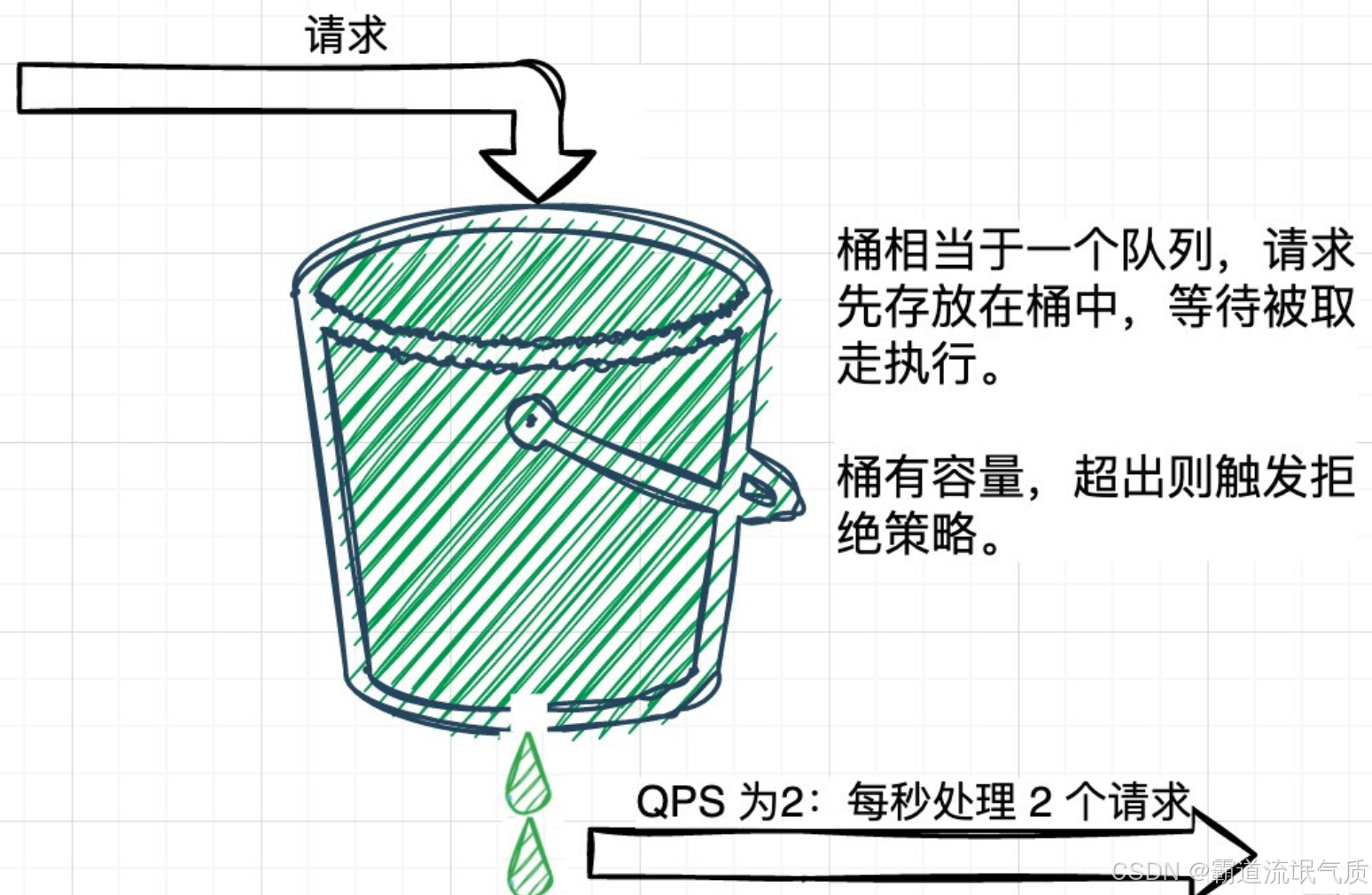
3. 漏桶算法(Leaky Bucket)
原理:请求以恒定速率处理(如每秒10次),超速请求排队或丢弃。所有请求先进入漏桶,漏桶按固定出水速率依次处理。进水速度>出水速率时,且漏桶满了,多余部分被溢出、丢弃。
图示
实现
RateLimiter limiter = RateLimiter.create(10.0); // 每秒10个令牌
if (limiter.tryAcquire()) { // 处理请求
} 优点:绝对流量整形,输出速率恒定
缺点:无法应对突发流量(即使系统有空闲资源)
适用场景:需要严格控制调用速率的场景(如第三方API调用)
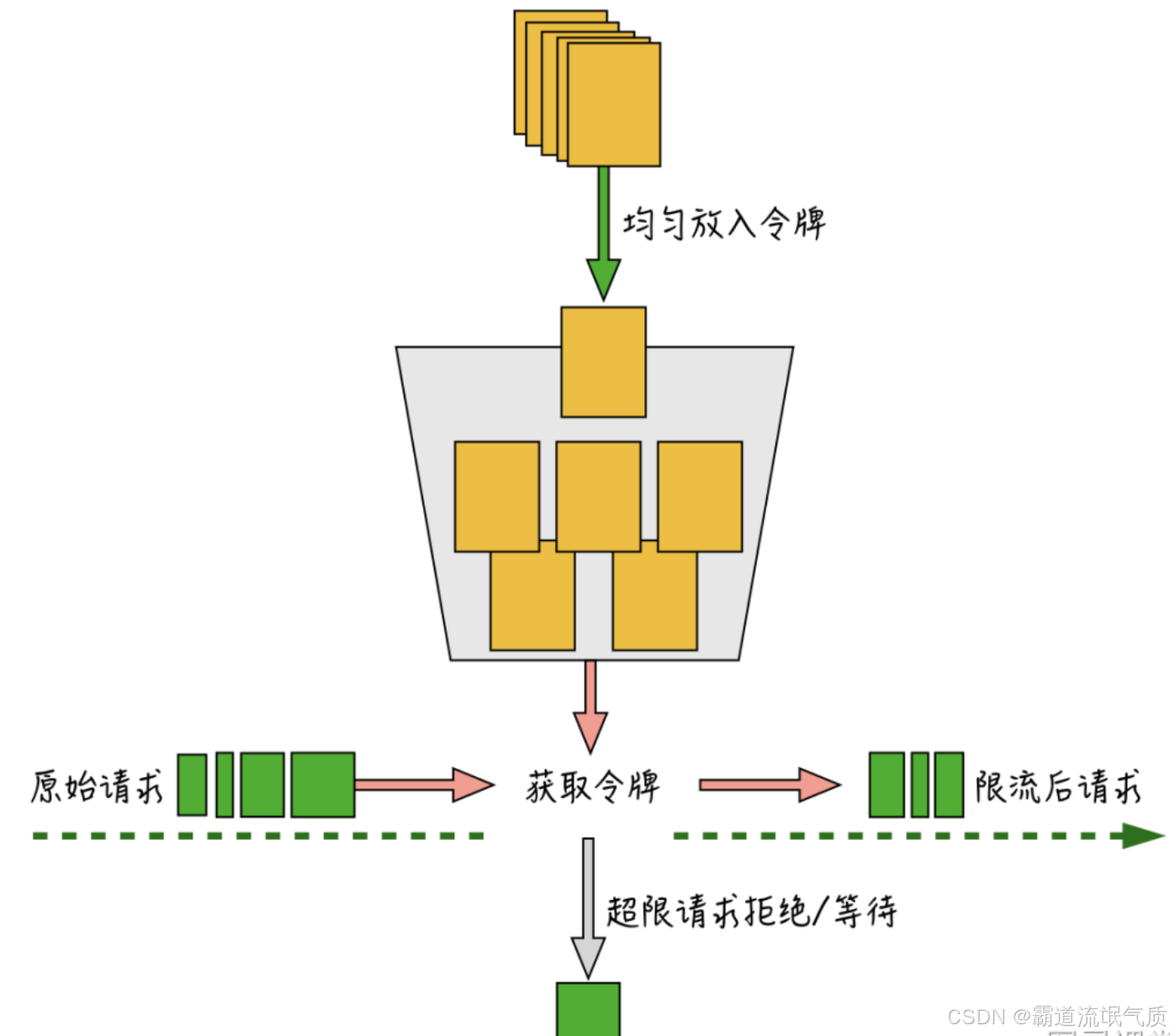
4. 令牌桶算法(Token Bucket)
原理:
以固定速率生成令牌,请求需获取令牌才能执行。系统以恒定速率(如每秒N个)往桶中添加令牌。
当用户请求到来时,只有“抢到”令牌的请求才被处理,否则被丢弃或延迟。桶有最大容量,防止长期积累超发。
图示
实现
// Guava RateLimiter基于令牌桶
RateLimiter limiter = RateLimiter.create(100, 1, TimeUnit.SECONDS);
if (limiter.tryAcquire(1)) { // 尝试获取1个令牌 // 处理请求
} 优点:允许突发流量(消耗积累的令牌)
缺点:实现复杂度较高
适用场景:秒杀、抢购等允许短暂突发的业务
5. 自适应限流(Sentinel/AliQPS)
原理:基于系统负载(CPU、RT、线程池)动态调整阈值
策略:
冷启动:初期缓慢增加阈值,避免冷系统过载
匀速排队:超阈值请求排队等待,避免直接拒绝
适用场景:云原生环境或流量波动大的系统
6.Nginx/OpenResty限流
在“接入层”采用OpenResty、Nginx限流模块,配置简单,可前置保护全部接口。
自带limit_req,支持突发量与速率双调优,适合网关层保护。
Java架构设计:怎么在业务不停机地情况下迁移数据库?
一、迁移核心挑战
数据一致性:迁移过程中需保证新旧库数据实时同步
业务连续性:应用无感知切换,避免停机或数据丢失
回滚能力:出现异常时快速恢复至旧库
二、5大迁移方案与实施步骤
1. 双写 + 增量同步(推荐)
适用场景:中大型系统,允许短暂数据延迟
流程
graph LR
A[应用层] -->|双写| B[旧库]
A -->|双写| C[新库]
D[CDC工具] -->|监听旧库Binlog| E[增量同步至新库]
F[校验工具] -->|比对数据| B & C
关键实现:
双写逻辑:通过AOP拦截DAO层,同时写入新旧库
@Transactional
public void saveOrder(Order order) { oldDbDao.insert(order); // 旧库写入 newDbDao.insert(order); // 新库写入
} 数据校验:使用Alibaba DataX或自研工具对比关键表数据差异
切换阶段:
停用旧库写入,仅从新库读取
确保增量同步完全追上旧库
下线旧库,解除双写
2. 数据库原生工具(MySQL DTS/Oracle GoldenGate)
优势:利用数据库厂商工具实现低延迟同步
步骤:
配置全量初始化(旧库→新库)
启动实时增量同步(基于事务日志)
应用层配置读写分离:写旧库,读新库
数据一致后,切换写流量到新库
3. 中间件代理(ShardingSphere/ProxySQL)
架构设计:
应用 → 中间件 → 路由写入旧库 → 异步同步新库
切换流程:
中间件开启影子表功能,自动同步新旧库
通过配置中心动态切换路由规则(如Nacos)
灰度验证部分流量写入新库
4. 逻辑迁移 + 流量切换
实施要点:
阶段一:旧库导出数据到新库(mysqldump/expdp)
阶段二:应用层通过动态数据源切换读写
示例代码
// Spring动态数据源示例
@Bean
@Primary
public DataSource dynamicDataSource() { RoutingDataSource ds = new RoutingDataSource(); ds.setDefaultTargetDataSource(oldDataSource); ds.setTargetDataSources(Map.of( "old", oldDataSource, "new", newDataSource )); return ds;
} 5. 云服务方案(AWS DMS/Aliyun DTS)
Java架构设计:SSO单点登录设计方案及落地?
一、SSO核心价值与挑战
1、核心目标:
用户一次登录,多系统互通(如企业内网、SaaS应用)
避免重复认证,提升用户体验
2、技术挑战:
跨域会话管理
安全性与防篡改(如Token劫持)
高并发下的性能保障
二、主流SSO方案对比与选型
1. 基于Cookie的共享Session方案
适用场景:同父域下的子系统(如a.company.com 和b.company.com )
实现要点:
设置顶级域Cookie(.company.com )
通过Spring Session + Redis共享会话
代码片段
@Configuration
public class SessionConfig { @Bean public CookieSerializer cookieSerializer() { DefaultCookieSerializer serializer = new DefaultCookieSerializer(); serializer.setDomainName("company.com"); // 顶级域共享 return serializer; }
} 2. 基于Token的中央认证(CAS/OAuth2)
架构流程
graph LR
A[用户访问子系统] --> B{是否有Token?}
B -->|否| C[跳转SSO认证中心]
C --> D[登录页]
D -->|成功| E[签发Token并重定向回子系统]
B -->|是| F[校验Token有效性]
技术组合:
OAuth2.0:适合开放平台(如微信登录)
CAS协议:适合企业内部系统
3. JWT无状态方案
优势:
无需中心化Session存储
支持跨域(通过HTTP头传递Token)
安全增强:
使用非对称加密(RS256)签名
短期Token + Refresh Token机制
三、生产级落地步骤(5大关键环节)
1. 统一认证中心设计
功能模块:
登录认证(支持密码/短信/扫码)
Token签发(JWT或Opaque Token)
会话管理(强制下线、续期)
高可用保障:
集群部署 + Nginx负载均衡
数据库分库分表(用户量>千万时)
2. Token安全策略
Token泄露 HTTPS传输 + IP绑定 + 短期有效期(1h)
重放攻击 添加Nonce随机数 + 一次性Token
CSRF攻击 SameSite Cookie + 双重提交Cookie校验
3. 子系统集成规范
SDK封装:提供统一鉴权客户端(Spring Boot Starter)
降级方案:Token校验失败时跳转登录页,而非直接抛错
4. 监控与运维
核心指标:
认证成功率(≥99.9%)
Token校验延迟(P99<50ms)
日志审计:记录所有登录事件,对接SIEM系统
5. 灰度发布策略
先对非核心系统(如HR系统)接入SSO
通过AB测试对比旧版登录转化率
全量切换后保留旧登录入口1个月
Java架构设计:布隆过滤器介绍与实际应用示例场景?
一、布隆过滤器核心原理
1、数据结构:
基于位数组(BitSet)和多个哈希函数,将元素映射到位数组的多个位置。
示例:
元素A通过哈希函数H1、H2、H3映射到位置[1,5,9],并将这些位置置为1。
2、特性:
假阳性(False Positive):可能误判不存在元素为存在(但不会漏判存在元素)。
空间效率:1亿元素仅需约114MB内存(误判率1%时)。
3、数学公式:
最优哈希函数数量 k = (m/n) * ln(2)
误判率 p ≈ (1 - e^(-kn/m))^k
m:位数组大小
n:预期元素数量
二、Java实现与性能优化
1. 基础实现(Guava库)
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels; // 创建布隆过滤器(预期元素量100万,误判率1%)
BloomFilter<String> filter = BloomFilter.create( Funnels.stringFunnel(Charset.defaultCharset()), 1_000_000, 0.01
); // 添加元素
filter.put("user123"); // 判断存在性
boolean mayExist = filter.mightContain("user123"); 2. 高性能优化技巧
哈希函数选择:
使用MurmurHash3替代默认哈希函数(减少碰撞)
内存压缩:
采用RedisBloom模块实现分布式布隆过滤器
动态扩容:
当实际元素超过预期时,自动创建新过滤器并合并
三、实际应用场景与落地案例
1. 缓存穿透防护
问题:恶意查询不存在的数据,导致请求穿透缓存直达数据库。
方案:
查询前先检查布隆过滤器
若过滤器返回false,直接拒绝请求
代码片段
public Product getProduct(String id) { if (!bloomFilter.mightContain(id)) { throw new IllegalArgumentException("非法ID"); } return cache.getOrDefault(id, db.query(id));
} 2. 爬虫URL去重
优势:百万级URL去重仅需MB级内存。
优化:
使用RedisBloom实现分布式去重
定期重置过滤器(避免长期积累导致误判率上升)
3. 邮件垃圾过滤
流程:
已知垃圾邮件特征哈希存入布隆过滤器
新邮件到达时快速判断是否垃圾邮件
误判处理:
二次校验(如人工审核标记为误判的邮件)
4. 分布式系统黑名单
架构:
全局布隆过滤器同步黑名单用户ID/IP
结合本地缓存减少网络调用
5. 数据库查询优化
场景:
避免全表扫描查询不存在的记录(如SELECT * FROM users WHERE non_indexed_column = ?)
实现:
将索引列值预先加载到布隆过滤器
Java架构设计:JWT深度解析与应用实战?
一、JWT核心概念
1、定义:
JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在各方之间安全传输JSON格式的声明(Claims)。
2、结构:
Header:算法(如HS256)和类型(JWT)
Payload:存储用户ID、角色、过期时间等数据
Signature:对前两部分的签名,防篡改
二、JWT工作流程
sequenceDiagram
participant Client
participant Server
Client->>Server: 登录请求(用户名/密码)
Server->>Client: 生成JWT并返回
Client->>Server: 携带JWT访问API(Authorization头)
Server->>Server: 验证签名并解析Payload
三、实际应用场景
1. 无状态认证(微服务架构)
优势:服务端无需存储Session,适合横向扩展
实现:
网关层统一校验JWT
微服务直接解析Payload获取用户信息
2. 单点登录(SSO)
流程:
认证中心签发JWT
子系统通过公钥验证JWT
3. 临时授权(如文件下载链接)
Java架构设计:Gossip协议深度解析与应用实战?
一、Gossip协议核心概念
1、定义:
Gossip(流行病协议)是一种去中心化的分布式信息传播协议,通过随机节点间的数据交换实现集群状态同步。
2、设计哲学:
最终一致性:不保证实时一致,但最终所有节点数据一致
容错性:允许部分节点故障或网络分区
可扩展性:节点增加时通信压力线性增长
二、Gossip实现机制(3大核心流程)
1. 信息传播模型
反熵(Anti-Entropy)
定期随机选择节点比对全量数据
适用场景:数据库集群同步(如Cassandra)
谣言传播(Rumor Mongering)
新事件通过随机传播快速扩散
适用场景:服务发现(如Consul)
三、应用场景示例
1. 分布式数据库同步(Cassandra)
机制:
通过反熵模式同步MemTable数据
采用Merkle Tree快速检测数据差异
优势:
无单点故障,支持跨数据中心部署
2. 服务发现与注册(Consul)
工作流程:
新服务节点加入时,通过Gossip广播自身信息
其他节点更新本地服务列表
性能对比:
比ZooKeeper的Watcher机制更适合大规模集群
3. 区块链网络(Hyperledger Fabric)
应用点:
交易信息通过Gossip协议扩散到全网节点
避免P2P广播的洪泛问题
4. 云原生监控(Prometheus+Thanos)
数据聚合:
多个Prometheus实例通过Gossip同步指标数据
实现全局监控视图
四、Gossip协议优劣分析

Java架构设计:定时任务实现思路?
一、主流实现方案与选型
1. 单机轻量级方案
Timer
JDK内置,单线程阻塞
简单低频任务(如日志清理)
ScheduledThreadPool
线程池支持,避免任务堆积
中小型应用常规调度
Spring @Scheduled
注解驱动,集成Spring生态
Spring项目快速开发
2. 分布式高可用方案
Quartz Cluster
数据库锁+故障转移
强一致性,支持复杂调度
Elastic-Job
ZooKeeper协调+分片
弹性扩容,任务分片执行
XXL-JOB
中心化调度+执行器集群
可视化管控,日志追溯
3. 云原生方案
Kubernetes CronJob:
通过Pod执行任务,天然支持分布式
需配合Prometheus监控Pod状态
Serverless Trigger:
阿里云定时触发器 + 函数计算
零运维成本,按执行次数计费
Java架构设计:多租户技术架构深度解析?
一、多租户核心概念与挑战
1、定义:
多租户(Multi-Tenancy)指单个应用实例为多个租户(企业/用户组)提供服务,租户间数据/配置隔离。
2、核心挑战:
数据隔离:避免租户间数据泄露
性能隔离:防止某租户资源占用影响其他租户
定制化扩展:支持租户特定功能扩展
二、主流多租户架构方案
1. 数据库层隔离方案
独立数据库
每个租户独占DB实例
金融/医疗等高隔离需求
共享数据库独立Schema
同一DB实例,不同Schema(CREATE SCHEMA tenant1)
中大型企业SaaS
共享表+租户ID
所有租户共用表,通过tenant_id字段区分
小微企业管理软件
2. 应用层隔离方案
动态数据源:
根据租户标识切换DataSource(AbstractRoutingDataSource)
适用场景:租户数量少且DB独立
线程上下文传递:
通过ThreadLocal或TransmittableThreadLocal传递tenant_id
需配合AOP自动注入租户参数
3. 资源隔离与限流
容器级隔离:
Kubernetes Namespace + ResourceQuota为租户分配独立Pod
流量控制:
Sentinel针对租户ID做QPS限制
Java架构设计:布谷鸟过滤器(Cuckoo Filter)深度解析与应用实战?
一、布谷鸟过滤器核心特性
1、与布隆过滤器的对比

2、核心原理
双哈希表结构:每个元素通过两个哈希函数映射到两个候选桶
踢出机制:若候选桶已满,随机踢出旧元素并重新插入(类似布谷鸟的巢寄生行为)
二、Java实现与关键代码
1. 基础实现(基于Guava风格API)
public class CuckooFilter<T> { private final int bucketSize; // 每个桶的条目数 private final int maxKicks; // 最大踢出次数 private final Bucket[] table; // 存储桶数组 // 插入元素 public boolean insert(T item) { int hash1 = hash1(item), hash2 = hash2(item); if (tryInsert(hash1, item) || tryInsert(hash2, item)) return true; // 执行踢出操作 for (int i = 0; i < maxKicks; i++) { int hash = (i % 2 == 0) ? hash1 : hash2; T displaced = table[hash].getRandomEntry(); if (tryInsert(hash, item)) { item = displaced; // 递归处理被踢出的元素 hash1 = hash1(item); hash2 = hash2(item); } } return false; // 插入失败(需扩容) }
} 2. 性能优化技巧
SIMD加速:使用Java的Panama项目实现向量化哈希计算
动态扩容:当插入失败率>5%时,自动扩容并重哈希
三、实际应用场景示例
1. 分布式缓存去重(Redis替代方案)
场景:缓存击穿防护,需支持删除过期键
实现
CuckooFilter<String> filter = new CuckooFilter<>(100_000, 0.01);
// 添加缓存键
filter.insert("product:123");
// 查询是否存在
if (filter.contains("product:123")) { // 从DB加载
}
// 缓存失效时删除
filter.delete("product:123"); 2. 实时风控系统
需求:快速判断用户行为是否在黑名单中,且需动态更新名单
优势:
比布隆过滤器节省30%内存
支持删除误判的正常用户
3. 分布式数据库(如TiDB)
应用:
LSM-Tree中快速判断SSTable是否包含某key
支持Compaction过程中的数据删除
4. 网络设备(路由器/防火墙)
功能:
IP黑名单过滤(支持动态增删)
比传统哈希表节省70%内存
总结
布谷鸟过滤器通过双哈希桶+踢出机制,在支持删除操作的同时保持了低空间开销,
特别适合需要动态更新的场景(如缓存、风控)。
Java实现时需注意并发控制和参数调优,大规模部署建议结合Redis模块(如RedisBloom)。
Java架构设计:RedisBloom模块深度解析与应用实战?
一、RedisBloom核心价值
1、功能定位:
RedisBloom是Redis的扩展模块,提供概率型数据结构支持,包括布隆过滤器、布谷鸟过滤器、Count-Min Sketch等,
解决海量数据存在性判断和频率统计问题。
2、性能优势:
内存效率:1亿元素判存仅需约114MB(误判率1%)
吞吐量:10万+ QPS(单节点)
二、核心数据结构与Java使用示例
1. 布隆过滤器(Bloom Filter)
场景:缓存穿透防护、爬虫URL去重
Java示例(Lettuce客户端)
// 创建过滤器(容量100万,误判率1%)
client.bfReserve("user_filter", 0.01, 1000000);
// 添加元素
client.bfAdd("user_filter", "user123");
// 判断存在性
boolean exists = client.bfExists("user_filter", "user123"); 2. 布谷鸟过滤器(Cuckoo Filter)
优势:支持删除操作,空间利用率更高
Java示例
// 创建过滤器(容量10万)
client.cfReserve("ip_blacklist", 100000);
// 动态增删
client.cfAdd("ip_blacklist", "192.168.1.1");
client.cfDel("ip_blacklist", "192.168.1.1"); 3. Count-Min Sketch
用途:高频数据统计(如热点商品追踪)
示例
// 初始化CMS(宽度1000,深度4)
client.cmsInitByDim("hot_items", 1000, 4);
// 累加计数
client.cmsIncrBy("hot_items", "product_123", 5);
// 查询频率
long count = client.cmsQuery("hot_items", "product_123"); 三、生产级应用场景
1. 电商系统缓存击穿防护
架构
graph LR
A[请求商品数据] --> B{RedisBloom判断是否存在?}
B -->|是| C[查询缓存/DB]
B -->|否| D[直接返回空]
效果:减少无效DB查询90%+
2. 风控系统实时黑名单
实现:
使用布谷鸟过滤器存储可疑IP/用户ID
支持动态添加/移除(如误判恢复)
3. 广告点击去重统计
方案:
Count-Min Sketch统计用户点击次数
布隆过滤器判断是否首次点击
4. 消息队列幂等消费
代码片段
String msgId = message.getMessageId();
if (redisBloom.bfExists("processed_msgs", msgId)) { return; // 已处理则跳过
}
redisBloom.bfAdd("processed_msgs", msgId);
processMessage(message); Java架构设计:亿级数据如何高效校验用户名是否被占用?
一、核心挑战与设计原则
1、性能要求:
99.9%的查询响应时间 ≤10ms
支持每秒10万+ QPS的高并发
2、数据规模:
用户名总量≥1亿条
每日新增≈100万条
3、设计原则:
空间换时间:优先内存计算,避免直接查库
分层过滤:从轻量级到精确校验的递进式检查
最终一致性:允许极短时间窗口内的数据延迟
二、高性能架构方案
1. 第一层:布隆过滤器(Bloom Filter)
作用:快速排除绝对不存在的用户名(假阳性率≤1%)
实现
// RedisBloom模块(内存占用约114MB/1亿数据)
String username = "test123";
if (!redis.execute("BF.EXISTS", "username_filter", username)) { return "用户名可用"; // 99%请求在此处返回
} 优化
使用布谷鸟过滤器(Cuckoo Filter)支持删除操作
分片存储(如按用户名首字母分16个过滤器)
2. 第二层:分布式缓存(Redis Cluster)
存储结构:
Key: username:{username}
Value: 1(存在)/ null(不存在)
缓存策略:
写穿透:注册成功时同步更新缓存
TTL:设置7天过期,冷数据自动清理
3. 第三层:数据库分库分表(MySQL/PostgreSQL)
分片规则:
按用户名哈希值分16个库,每个库32张表
路由计算:库序号 = hash(username) % 16
索引优化:
唯一索引:ALTER TABLE user_01 ADD UNIQUE (username)
覆盖索引:SELECT 1 FROM user_01 WHERE username=? LIMIT 1
4. 异步一致性保障
graph TB
A[注册请求] --> B[写数据库]
B --> C[发MQ消息]
C --> D[更新Redis缓存]
D --> E[同步BloomFilter]
补偿机制:定时任务扫描新增用户名,修补过滤器
三、异常处理与容灾
1、降级策略:
当Redis故障时,直接查库并返回带标记的结果(如result: "可能重复")
2、防穿透:
缓存空值:SET username:invalid 1 EX 60
3、监控指标:
Grafana监控过滤器误判率
Prometheus告警规则:数据库查询比例>5%时触发扩容
Java架构设计:扫码登录的流程与方案?
一、扫码登录核心流程
sequenceDiagram
participant 用户手机
participant 网页端
participant 服务端
participant 消息队列
网页端->>服务端: 1. 生成临时token+二维码(状态=待扫描)
服务端-->>网页端: 返回二维码URL+token
用户手机->>服务端: 2. 扫码获取token+用户身份
服务端->>消息队列: 3. 发布登录事件(token,userID)
消息队列->>网页端: 4. 推送登录成功(WebSocket)
网页端->>服务端: 5. 用token换取JWT会话凭证
二、Java技术栈实现方案
1. 服务端设计
二维码生成 Google ZXing 包含临时token的加密URL(有效期2分钟)
状态管理 Redis 存储token状态(待扫描/已确认/已失效)
事件通知 WebSocket+STOMP 实时推送登录状态到网页
安全校验 JWT+HMAC-SHA256 最终会话凭证防篡改
2. 移动端交互
扫码SDK:微信/支付宝开放平台SDK(兼容主流APP)
登录确认:生物识别(指纹/人脸)二次验证
3. 容灾方案
轮询降级:当WebSocket不可用时,网页端每5秒查询token状态(HTTP长轮询)
令牌续期:二维码剩余30秒时自动刷新
三、性能优化关键点
高并发生成二维码 Redis原子计数器限流 峰值10万QPS
事件通知延迟 Kafka分区键=token(保证顺序性) 99%请求<200ms
令牌查询 Redis Cluster分片存储 毫秒级响应
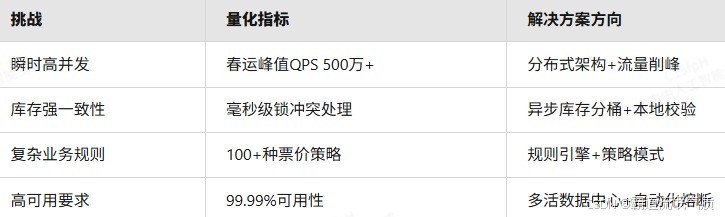
Java架构设计:12306抢票系统设计?
一、系统核心挑战
二、架构分层设计
1. 接入层 - 流量管控
graph LR
A[用户请求] --> B[LVS负载均衡]
B --> C[API网关集群]
C --> D[限流熔断模块]
D -->|正常请求| E[业务层]
D -->|异常请求| F[排队系统]
关键技术:
动态限流:Sentinel集群限流(根据票仓余量动态调整QPS阈值)
排队导流:RocketMQ延时队列实现虚拟排队(平均等待时长<1s)
防机器刷票:行为分析模型(检测异常点击频率/路径)
2. 业务层 - 微服务化
余票查询 Redis分片集群+本地缓存 双层缓存策略(Region级热点探测)
订单创建 Seata分布式事务+Tair热点锁 分段锁优化(并发提升300%)
支付服务 状态机引擎+多通道路由 自动切换支付渠道(成功率>99.5%)
票价计算 Drools规则引擎+GPU加速 实时响应政策变动(<100ms)
3. 数据层 - 高性能存储
库存管理
// 库存分桶设计(避免全局锁)
public class TicketBucket {private Long trainId;private Map<String, AtomicInteger> sectionStock; // 区间余量private Striped<Lock> segmentLocks; // 分段锁public boolean acquireSeat(String section) {Lock lock = segmentLocks.get(section);lock.lock();try {if (sectionStock.get(section).decrementAndGet() >= 0) {return true; // 扣减成功}return false;} finally {lock.unlock();}}
}持久化方案
实时订单:TiDB(HTAP架构,支持实时分析)
历史数据:PolarDB列式压缩(存储成本降低60%)
三、核心技术创新
1. 动态库存分片算法
分片维度:车次+日期+车厢+席位等级
路由策略
graph TD
A[用户请求] -->|Hash(出发地-目的地)| B[分片节点1]
A -->|Hash(出发地-目的地)| C[分片节点2]
B & C --> D[统一协调节点]
D --> E[生成全局余量视图]
优势:冲突域缩小至同区间,并发处理能力线性扩展
2. 混合事务模型

3. 智能弹性调度
动态扩缩容
基于LSTM预测模型提前扩容(客流预测准确率>92%)
K8s + Envoy实现秒级扩缩(响应时间<10s)
流量调度
全局负载均衡:根据机房负载动态DNS切换
边缘计算节点:预处理静态请求(CDN命中率98%)
四、运维保障体系
1、全链路监控
日志:ELK + 实时Flink处理(10TB/日日志量)
追踪:SkyWalking自动拓扑分析(99%请求轨迹还原)
2、混沌工程平台
自动注入故障:网络延迟、节点宕机、数据延迟
自动化恢复验证:90%故障5分钟内自愈
3、安全防护
多层验证:滑块+短信+行为验证(拦截99.9%机器请求)
量子加密:支付通道采用量子密钥分发(QKD)
Java架构设计:如何设计一个秒杀系统?
一、秒杀系统核心挑战

二、分层架构设计
graph TB
A[客户端] -->|请求| B(网关层)
B --> C{流量控制层}
C -->|合法请求| D[服务层]
D --> E[缓存层]
E --> F[数据库集群]
1. 网关层(流量入口)
功能:
恶意IP封禁(基于实时风控数据)
HTTPS加密与证书卸载
请求聚合压缩
技术栈:Spring Cloud Gateway + OpenResty
2. 流量控制层(削峰填谷)
漏斗式过滤:
用户资格校验(黑名单/限购次数)
令牌桶限流(Redis + Lua脚本)
排队机制(MQ顺序队列)
动态扩容:K8s HPA根据队列长度自动扩容Pod
3. 服务层(业务核心)
模块拆分:
库存服务:预扣库存(Redis分布式锁 → 2025年改用Redisson)
订单服务:异步生成订单(RocketMQ事务消息)
支付服务:对接第三方支付(降级时支持事后补偿)
热点优化:
库存分桶:1000件库存拆为10个Key(stock:sku_1001_bucket{1-10})
LocalCache:节点本地缓存已售罄商品ID(Guava Cache)
4. 缓存层(高速读写)
多级缓存架构:
用户请求 → CDN静态页 → Redis集群(代理层Twemproxy) → 二级缓存(Caffeine)
防击穿策略:
BloomFilter过滤无效商品请求
缓存空值应对穿透(TTL=5s)
5. 数据库层(最终一致)
分库分表:
订单表按用户ID哈希分16库(ShardingSphere)
库存表单独部署(PolarDB高性能集群)
数据同步:
Binlog→Kafka→Elasticsearch(实时库存对账)
三、容灾与降级方案
故障场景
Redis集群宕机 切到本地库存模式(限流10%) Redis节点存活率
数据库延迟飙升 关闭非核心功能(如评论加载) SQL平均响应时间>200ms
网络分区 静态页兜底(展示“稍后再试”) 跨可用区Ping延迟
性能指标
下单延迟:99%请求<500ms(峰值50万QPS)
库存准确率:99.9999%(每百万次误差<1次)
系统可用性:99.99%(年故障时间<52分钟)
Java架构设计:千万级实时聊天系统如何设计?
一、核心挑战与应对策略
长连接高并发 分布式网关 + WebSocket 集群
消息实时性 边缘节点路由 + 内存级消息总线
数据一致性 CRDT 无冲突数据结构 + 向量时钟
存储与扩展性 分层存储 + 动态分片
二、分层架构设计
graph TB
A[客户端] --> B(接入层)
B --> C{协议层}
C --> D[逻辑层]
D --> E[存储层]
E --> F[运维层]
subgraph 接入层
B1[全球边缘节点]
B2[智能DNS]
B3[连接负载均衡]
end
subgraph 协议层
C1[WebSocket/QUIC]
C2[ProtoBuf 编解码]
C3[零拷贝压缩]
end
subgraph 逻辑层
D1[消息路由]
D2[在线状态管理]
D3[反垃圾服务]
end
subgraph 存储层
E1[Redis 热点缓存]
E2[TiDB 消息持久化]
E3[Iceberg 归档日志]
end
subgraph 运维层
F1[全链路追踪]
F2[混沌工程平台]
F3[AIOps 异常预测]
end
三、关键技术实现
1. 连接层设计
全球接入点:
部署 200+ 边缘节点(基于 AWS Global Accelerator)
智能路由选择 <10ms 延迟节点
会话保持:
动态 Token 绑定(每 5 分钟刷新)
断线自动迁移(基于 Raft 算法)
2. 消息投递保障
三级消息确认机制
1. 内存级确认(纳秒级)
2. 集群级确认(毫秒级)
3. 持久化确认(秒级)
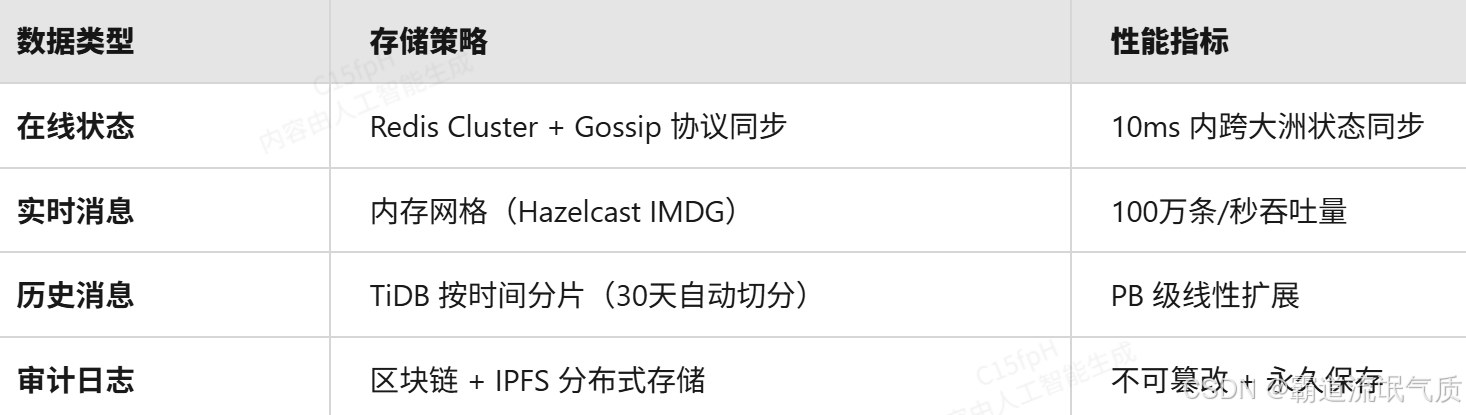
3. 存储优化方案
五、容灾与监控体系
1. 熔断降级策略

2. 监控指标
黄金指标:
消息端到端延迟(P99 <200ms)
连接成功率(>99.995%)
消息丢失率(<0.0001%)
业务指标:
日均互动次数(DAU 统计)
跨语言翻译使用率
脑机接口设备渗透率
Java架构设计:接口被刷百万QPS,怎么防?
一、分层防护体系
graph LR
A[客户端] --> B{边缘防护层}
B --> C[网关过滤层]
C --> D[业务风控层]
D --> E[资源隔离层]
1. 边缘防护层(第一道防线)
Web应用防火墙(WAF)
规则库自动更新(实时同步云安全威胁情报)
精准拦截SQL注入/XSS/恶意爬虫(误杀率<0.01%)
DDoS防护
T级流量清洗(阿里云DDoS高防/AWS Shield Advanced)
近源压制技术(与运营商联动封禁攻击源AS号)
2. 网关过滤层(核心限流)
分布式限流 Redis+Lua令牌桶算法 支持500万QPS计数
动态指纹识别 设备ID+行为轨迹生成唯一指纹 100ms内完成设备画像
协议合规校验 自定义二进制协议(替代HTTP) 降低50%网络开销
智能熔断 Sentinel热点参数流控 自动识别TOP10热点资源
二、业务风控层(精准识别)
1. 多维风控模型
行为模式分析 LSTM神经网络预测操作序列 识别脚本自动化行为
物理轨迹验证 GPS/基站/WiFi三角定位比对 阻断机房集群攻击
生物特征识别 触摸屏压感+滑动轨迹分析 过滤模拟器流量
资源访问频率 时间滑动窗口统计(1s/10s/60s多维监控) 捕捉突发流量
2. 实时决策引擎
flowchart TD
A[请求进入] --> B{规则引擎检查}
B -->|通过| C[业务处理]
B -->|可疑| D[二次验证]
D --> E[无感验证码]
D --> F[行为挑战]
D --> G[短信认证]
三、资源隔离层(深度防护)
1. 服务分级隔离

2. 热点数据保护
缓存策略
本地缓存:Caffeine(应对Redis穿透)
分布式缓存:RedisCluster(分片隔离热点Key)
防击穿设计:BloomFilter过滤无效请求
数据库防护
读写分离:TiDB自动分流读写流量
批量合并:同一用户请求10ms内合并处理
四、应急监控体系
1. 全链路监控
基础设施 Prometheus+Node_Exporter CPU/内存/网络饱和度
应用性能 SkyWalking P99延迟>200ms接口自动报警
业务风控 Elasticsearch 拦截率突降30%触发紧急响应
2. 混沌工程预案
故障注入场景:
模拟Redis集群宕机(验证本地缓存兜底能力)
制造200万QPS流量洪峰(测试弹性扩容速度)
自愈要求:
95%的故障在90秒内自动恢复
业务流量损失<0.001%
Java架构设计:外卖员近场订单查询架构设计?
一、核心挑战与解决方案
实时位置更新 北斗/GPS+WiFi指纹混合定位(误差<50米) 空间索引+Geohash分块缓存
高并发查询 分布式计算引擎(Flink Stateful Functions) 动态负载均衡+近场计算节点
订单动态匹配 强化学习推荐算法(DQN模型) 增量训练+边缘模型部署
多维度排序 多因子加权评分(距离/时效/骑手信用) 向量化计算(SIMD指令加速)
二、架构设计(四层模型)
graph TD
A[移动端] --> B(接入层)
B --> C{计算层}
C --> D[数据层]
D --> E[运维层]
subgraph 接入层
B1[API网关]
B2[WebSocket长连接]
B3[QUIC协议加速]
end
subgraph 计算层
C1[位置事件流处理]
C2[近场订单检索]
C3[智能排序引擎]
end
subgraph 数据层
D1[RedisGeo]
D2[Elasticsearch空间索引]
D3[TiFlash列存分析]
end
subgraph 运维层
E1[全链路追踪]
E2[动态扩缩容]
E3[量子加密审计]
end
三、关键技术实现
1. 实时位置处理(毫秒级更新)
使用Kafka位置事件流
更新边缘节点本地缓存
2. 近场订单检索(5公里范围)
1. 获取骑手位置
2. Elasticsearch多边形搜索
3. 多维度排序(向量化计算)
3. 智能推荐算法(DQN模型)
四、性能指标与容灾
查询延迟(P99) <300ms 返回3公里缓存订单
位置更新频率 每秒1次(动态调整) 惯性推算补偿
系统可用性 99.999% 自动切换至备用地理数据库
匹配准确率 >95% 启用基于规则的兜底策略
五、移动端交互流程
sequenceDiagram
骑手APP->>网关: 登录+上报定位(QUIC)
网关->>计算层: 注册WebSocket会话
计算层->>数据层: 实时索引位置(H3)
骑手APP->>网关: 请求5公里订单
网关->>计算层: 触发近场搜索
计算层->>数据层: 空间查询(GeoHash)
数据层-->>计算层: 返回候选订单
计算层->>AI模型: 动态排序
AI模型-->>骑手APP: 返回TOP10订单(含ETA预测)
Java架构设计:如何设计一个微博系统?
一、核心功能模块
动态发布 高并发写入(百万级QPS) 分片队列+流处理(Kafka+Flink)
feed流推送 实时性与一致性平衡 混合推送(推模式+拉模式)+AI智能排序
社交图谱 千亿级关系链存储 图数据库(Neo4j+分布式缓存)
多媒体处理 4K视频实时转码 边缘计算节点(FFmpeg+GPU加速)
热点发现 实时趋势分析 时序数据库(TDengine)+LSTM预测模型
二、分层架构设计
graph TB
A[客户端] --> B(接入层)
B --> C{服务层}
C --> D[数据层]
D --> E[运维层]
subgraph 接入层
B1[智能DNS]
B2[QUIC网关]
B3[WebSocket长连接]
end
subgraph 服务层
C1[动态服务]
C2[关系服务]
C3[推荐引擎]
C4[风控系统]
end
subgraph 数据层
D1[TiDB分库分表]
D2[RedisTimeSeries]
D3[Ceph对象存储]
D4[ArangoDB图存储]
end
subgraph 运维层
E1[全链路追踪]
E2[混沌工程]
E3[量子加密审计]
end
三、关键技术实现
1. 动态发布流程
异步化处理(削峰填谷)
1. 写入Kafka分片队列(按用户ID哈希)
2. Flink实时处理
3. 存入冷热分离存储
2. Feed流推送策略

3. 社交关系存储优化
使用图数据库存储关系链
热点关系缓存
四、性能与容灾指标
发布延迟(P99) <500ms 异步写入+最终一致
Feed流刷新延迟 <1s 返回缓存数据+背景更新
数据持久化 99.9999999%可靠性 三地五中心存储
热点事件承载 千万级并发 自动限流+弹性扩容
五、客户端优化策略
1、智能预加载
基于用户行为预测提前拉取可能浏览的内容
2、差分更新
Java架构设计:百万级数据导出 Excel怎么性能优化,避免OOM?
一、核心优化策略
内存控制 流式导出(SXSSFWorkbook) 内存占用从GB级降至MB级
IO效率 分片压缩写入(ZIP流式输出) 网络传输量减少60%
计算加速 列式存储+向量化计算 处理速度提升5-10倍
资源隔离 专属线程池+熔断机制 避免影响主业务
二、具体实现方案
1. 流式导出(Apache POI优化)
// 使用SXSSFWorkbook(保持100行在内存)
SXSSFWorkbook workbook = new SXSSFWorkbook(100);
Sheet sheet = workbook.createSheet(" 数据"); // 分批查询数据库(游标/分页)
try (ScrollableResults results = session.createQuery("FROM LargeTable") .setFetchSize(5000) .scroll()) { int rowNum = 0; while (results.next()) { Row row = sheet.createRow(rowNum++); // 填充单元格... if (rowNum % 1000 == 0) { sheet.flushRows(); // 刷新磁盘 } }
} // 最终写入压缩流(防OOM)
try (ZipOutputStream zos = new ZipOutputStream(response.getOutputStream())) { zos.putNextEntry(new ZipEntry("data.xlsx")); workbook.write(zos);
} 2. 数据分片处理
graph TD
A[查询总记录数] --> B{>50万?}
B -->|是| C[按ID范围分片]
B -->|否| D[直接导出]
C --> E[多线程处理分片]
E --> F[合并临时文件]
F --> G[压缩下载]
分片规则:
按时间范围分片(适合时序数据)
按哈希值分片(均匀分布)
3. 异步化与熔断
// 专用有界线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor( 2, 5, 30, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100), new ThreadPoolExecutor.CallerRunsPolicy()
); // 熔断监控(Hystrix/Sentinel)
@SentinelResource(value = "exportExcel", fallback = "exportFallback", blockHandler = "blockHandler")
public void exportData() { ... } 三、避坑指南
1、OOM预防清单
✅ 禁用XSSFWorkbook全内存模式
✅ JVM添加-XX:+UseZGC低延迟垃圾回收器
✅ 限制单次导出最大行数(配置文件动态调整)
2、性能监控指标
内存使用峰值 <1GB Prometheus+Micrometer
单文件导出时长 <5分钟 SkyWalking
线程池队列积压 <50 Grafana
Java架构设计:如果系统的QPS突然提升100倍该如何设计?
一、核心设计原则
水平扩展优先:无状态设计+细胞分裂式扩容
流量分层治理:漏斗式过滤(边缘→网关→服务)
关键路径优化:20%功能承载80%流量
混沌工程预备:定期模拟百倍流量冲击
二、五层弹性防护体系
graph TD
A[客户端] --> B(边缘防护层)
B --> C{智能网关层}
C --> D[服务弹性层]
D --> E[数据韧性层]
E --> F[运维控制层]
subgraph 边缘防护层
B1[全球Anycast接入]
B2[DDoS清洗]
B3[HTTP/3 QUIC加速]
end
subgraph 智能网关层
C1[动态限流]
C2[协议转换]
C3[AI熔断]
end
subgraph 服务弹性层
D1[K8s HPA自动扩缩]
D2[Serverless备用池]
D3[服务降级开关]
end
subgraph 数据韧性层
E1[多级缓存]
E2[分库分表]
E3[流式处理]
end
subgraph 运维控制层
F1[全链路压测]
F2[混沌猴攻击]
F3[量子加密审计]
end
三、关键技术实现
1. 秒级扩容方案

2. 流量洪峰应对
梯度限流算法(滑动窗口+令牌桶混合)
降级策略(自动/手动)
3. 数据层优化
缓存策略:
L1:本地缓存(Caffeine)← 热点探测
L2:分布式缓存(Dragonfly)← 兼容Redis协议
L3:持久化缓存(Apache Ignite)
四、验证与监控
全链路压测 模拟真实业务场景+影子流量 核心接口P99<500ms
混沌工程 随机杀死30%节点+网络延迟注入 自动恢复时间<90秒
智能监控 Prometheus+Pyroscope持续剖析 异常检测延迟<10秒
Java架构设计:给你一亿个Redis keys,如何高效统计?
一、核心挑战与应对策略
内存爆炸风险 增量扫描+流式处理 内存占用稳定在MB级
计算耗时 分布式并行统计 耗时从小时级降至分钟级
精确性要求 概率算法(HyperLogLog)保精度 误差<0.81%且内存节省99%
集群影响 错峰扫描+热Key隔离 业务请求延迟波动<5%
二、高效统计方案
1. SCAN迭代扫描(基础版)
# 单次扫描10万key,避免阻塞
cursor=0
total=0
while true; do redis-cli --bigkeys --scan --pattern '*' --count 100000 cursor=$(redis-cli SCAN $cursor COUNT 100000 | head -1) if [ "$cursor" -eq "0" ]; then break; fi
done 适用场景:小规模集群(<1千万key)
2. 分布式并行统计(生产级)
// 使用RedisGears分布式计算
# 注册统计函数
RG.PYEXECUTE """
keys = redis.call('SCAN', 0, 'COUNT', 50000)
for _, key in ipairs(keys[2]) do redis.call('INCRBY', 'stats:total', 1) if string.match(key, 'user:*') then redis.call('INCRBY', 'stats:user_keys', 1) end
end
""" 优势:
分片并行处理(每个分片独立统计)
结果自动聚合
3. 概率统计算法(超大规模)
# 使用HyperLogLog统计基数
import redis
r = redis.Redis() # 初始化HLL
for key in r.scan_iter(count=100000): r.pfadd("stats:hll", key) # 获取估算值
print(r.pfcount("stats:hll")) 性能对比

三、避坑指南
1、禁止使用:
KEYS *命令(导致集群阻塞)
全量DUMP+本地分析(内存溢出风险)
2、必备监控:
Redis节点内存/CPU波动
扫描进度指标(scan_completed_percent)
四、方案选型建议
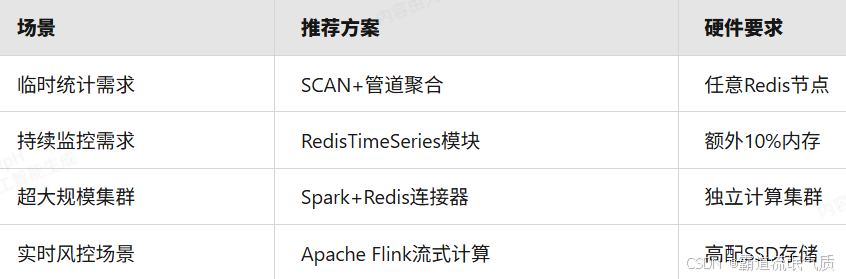
Java架构设计:电商平台订单自动关单架构设计?
一、核心设计要点
时效控制 多级延迟任务(秒级→分钟级→小时级) 资源利用率提升40%
状态一致性 分布式事务+Saga模式 保证关单与库存释放原子性
高并发处理 分片任务队列+弹性消费者 支持10万+订单/秒处理能力
容灾能力 本地事件表+定时补偿机制 系统可用性99.999%
二、主流实现方案对比
1. 延迟队列方案(RocketMQ/Kafka)
订单创建时发送延迟消息
消费者处理关单
适用场景:中小规模平台(日订单<100万)
2. 时间轮算法(Netty HashedWheelTimer)
优势:内存操作零GC压力
3. 定时扫描+批量处理(分布式版)
创建定时任务扫描未支付订单
优化技巧:
按订单ID哈希分片扫描
使用Elasticsearch加速查询
三、容灾与监控设计
故障场景
消息丢失 本地事件表+定时扫描补偿
数据库超载 限流降级(只关单不还库存)
时间不同步 NTP集群校准+本地时钟漂移检测
关键监控指标:
关单任务积压量(Prometheus警报阈值:>1000)
平均关单延迟(P99 <5秒)
库存释放成功率(需100%达成)
Java架构设计:如何从零搭建10W QPS 高并发优惠券系统?
一、核心挑战与应对策略
瞬时高并发 分层流量控制+弹性扩缩容 Sentinel + K8s HPA
超卖风险 分布式锁+预扣库存+异步对账 Redisson + RocketMQ事务消息
热点数据 本地缓存+分片存储 Caffeine + Redis Cluster分片
精准风控 实时规则引擎+用户画像 Flink + 图数据库(Neo4j)
二、五层架构设计
graph TD
A[客户端] --> B(接入层)
B --> C{逻辑层}
C --> D[数据层]
D --> E[运维层]
subgraph 接入层
B1[API网关]
B2[QUIC协议加速]
B3[WebSocket推送]
end
subgraph 逻辑层
C1[库存服务]
C2[风控服务]
C3[订单服务]
end
subgraph 数据层
D1[Redis分片集群]
D2[TiDB分布式数据库]
D3[Elasticsearch检索]
end
subgraph 运维层
E1[全链路压测]
E2[混沌工程]
E3[量子审计日志]
end
三、关键技术实现
1. 高性能领券流程
分布式预扣库存(Lua脚本保证原子性)
异步创建订单(最终一致)
2. 热点数据处理
爆款优惠券 库存分桶(1000个Key)
用户频繁查询 布隆过滤器拦截无效请求
黑名单实时更新 推模式广播到所有节点
3. 智能风控体系
flowchart LR
A[请求进入] --> B{规则引擎}
B -->|通过| C[发券]
B -->|可疑| D[二次验证]
D --> E[行为验证]
D --> F[人脸识别]
实时规则:
同一设备5分钟内≤3次领取
相同IP段领取量突增报警
离线分析:
用户画像聚类(K-means算法)
四、性能压测指标
领券延迟(P99) <200ms SkyWalking
库存准确性 99.9999% 定时对账任务
峰值承载能力 15万QPS(30%冗余) JMeter+Prometheus
自动扩容速度 1分钟增加100节点 K8s Event监控
Java架构设计:100W QPS短链系统架构设计?
一、核心挑战与应对策略
高并发读写 分层缓存+分布式计算 Redis Cluster + Flink状态计算
短码生成冲突 雪花ID+哈希碰撞检测 分布式锁+异步重试机制
长链存储成本 列式压缩+冷热分离 Parquet列存+TiDB自动分区
跳转性能 边缘节点缓存+Anycast路由 Cloudflare Workers + QUIC协议
二、五层架构设计
graph TD
A[客户端] --> B(接入层)
B --> C{服务层}
C --> D[存储层]
D --> E[运维层]
subgraph 接入层
B1[全球边缘节点]
B2[智能DNS负载均衡]
B3[零信任安全网关]
end
subgraph 服务层
C1[短码生成服务]
C2[跳转路由服务]
C3[实时分析服务]
end
subgraph 存储层
D1[Redis热点缓存]
D2[TiKV持久化存储]
D3[Iceberg数据湖]
end
subgraph 运维层
E1[混沌工程平台]
E2[量子加密审计]
E3[AI异常预测]
end
三、关键技术实现
1. 短码生成方案
// 分布式雪花ID+Base62编码
public String generateShortCode(long userId) { Snowflake snowflake = new Snowflake(datacenterId, workerId); long id = snowflake.nextId(); return Base62.encode(id); // 7位短码可表示3.5万亿组合
} // 异步冲突检测(Kafka+消费者组)
@KafkaListener(topics = "short_code_verify")
public void checkCollision(String code) { if (redisTemplate.opsForValue().setIfAbsent(code, "LOCK", 1, TimeUnit.SECONDS)) { persistToDB(code); } else { retryQueue.add(code); // 触发重新生成 }
} 2. 跳转优化方案
边缘缓存策略
# Cloudflare规则:缓存301跳转24小时
edge_ttl = 86400;
协议加速
启用HTTP/3 QUIC协议(降低30%延迟)
预解析DNS(<link rel= "dns-prefetch">)
3. 数据存储设计
热点映射关系 RedisGeo(读写<1ms)
全量映射关系 TiKV(RocksDB引擎)
访问日志 Flink→Iceberg(列式压缩)
四、性能与容灾指标
跳转延迟(P99) <50ms 返回静态缓存页
短码生成成功率 99.999% 本地预生成池兜底
数据持久化 6个9可靠性 三地五中心备份
故障恢复 30秒自动切换 基于Raft协议的副本迁移
Java架构设计:百亿短 URL 怎样做到无冲突?
一、核心挑战与解决方案
ID空间耗尽 分布式雪花ID+动态扩位 支持2^128唯一标识(理论无上限)
哈希碰撞风险 多级哈希+异步冲突检测 碰撞概率<10^-20
全局唯一性 分片键+逻辑时钟 跨数据中心强一致性
生成速度 预分配ID区间+本地缓冲池 单节点10万QPS无锁生成
二、无冲突短码生成方案
1. 分布式ID生成器(Snowflake++改进版)
优势:
理论可生成 3.4×10^38 个唯一ID
无中心节点依赖
2. 多级哈希冲突检测
graph LR
A[原始URL] --> B{一级哈希}
B -->|MurmurHash3| C[64位指纹]
C --> D{二级哈希}
D -->|SHA-256截断| E[128位编码]
E --> F[RedisBloom检测]
F -->|无冲突| G[存入数据库]
F -->|冲突| H[盐值重哈希]
容错机制:
布隆过滤器误判时,触发异步数据库校验
冲突后自动加盐(用户ID+时间戳)重新哈希
3. 分片键路由策略
用户ID哈希 shard = userId % 1024 用户专属短链
时间范围 按创建时间分表(YYYYMMDD) 冷热数据分离
地理区域 根据IP定位到最近数据中心 降低跨域延迟
三、容灾与监控
ID服务宕机 本地预分配10万ID缓冲池
哈希集群过载 动态降级为纯递增ID模式
跨区网络分区 基于CRDT的最终一致性同步
Java架构设计:10W QPS 的会员系统,如何设计?
一、核心挑战与应对策略
高并发读写 多级缓存+异步化 Caffeine → Redis → TiDB
数据一致性 分布式事务+事件溯源 Seata + Kafka事务消息
热点用户 动态分片+本地缓存 ShardingSphere + Hazelcast
实时风控 流式计算+图数据库 Flink + Neo4j
弹性扩展 云原生+K8s HPA Kubernetes + Serverless Pod
二、五层架构设计
graph TD
A[客户端] --> B(接入层)
B --> C{服务层}
C --> D[数据层]
D --> E[运维层]
subgraph 接入层
B1[全球Anycast接入]
B2[QUIC协议加速]
B3[WebSocket长连接]
end
subgraph 服务层
C1[会员核心服务]
C2[等级计算服务]
C3[权益发放服务]
end
subgraph 数据层
D1[RedisCluster]
D2[TiDB分库分表]
D3[ArangoDB图存储]
end
subgraph 运维层
E1[全链路压测]
E2[混沌猴攻击]
E3[量子审计追踪]
end
三、关键技术实现
1. 会员信息查询优化
多级缓存加载策略
L1: 本地缓存(100ms过期)
L2: 分布式缓存
L3: 数据库(行缓存加速)
2. 分布式事务方案
sequenceDiagram
客户端->>+会员服务: 更新等级
会员服务->>+Kafka: 发送预扣积分事件(事务消息)
Kafka-->>-积分服务: 提交消息
积分服务->>积分DB: 扣除积分
积分服务-->>-会员服务: 确认结果
会员服务->>会员DB: 最终提交
3. 热点用户隔离
动态分片 按用户ID后两位路由到不同库
本地缓存预热 启动时加载TOP10万用户数据
限流熔断 Sentinel热点参数流控
四、性能与容灾指标
查询延迟(P99) <50ms 返回缓存旧数据+异步更新
数据一致性 最终一致(1秒内) 补偿任务+人工对账
系统可用性 99.999% 多活数据中心自动切换
扩容速度 1分钟增加100节点 K8s弹性调度
Java架构设计:如何设计一个高并发系统?
一、核心设计原则
无状态化:会话数据集中存储(Redis Cluster)
水平扩展:细胞分裂式服务拆分(每个微服务独立扩缩容)
异步化:消息队列解耦(RocketMQ/Kafka)
分层防御:边缘→网关→服务→数据逐层过滤
二、五层关键设计
接入层 全球Anycast+QUIC协议 降低30%网络延迟
网关层 动态限流(Sentinel)+JWT验签 支持百万级QPS路由
服务层 虚拟线程(Project Loom)+响应式编程 并发能力提升5倍
缓存层 多级缓存(Caffeine→Redis→CDN) 命中率>99%
数据层 分库分表(ShardingSphere)+列存(TiFlash) 千万级TPS写入
三、容灾与监控
故障场景
数据中心宕机 30秒内切换至备用集群
缓存穿透 布隆过滤器+空值缓存
数据库过载 自动降级为只读模式
监控重点:
全链路追踪(SkyWalking)
实时JVM指标(Pyroscope持续剖析)
Java架构设计:搜索引擎高效检索架构设计?
一、核心挑战与解决方案
数据量爆炸 分布式倒排索引+列式存储
检索效率低 分层索引+近似最近邻搜索
语义模糊 多模态向量引擎+知识图谱
冷门结果干扰 个性化排序+时效加权
二、五层精准检索架构
graph TD
A[查询输入] --> B(查询理解层)
B --> C{索引路由层}
C --> D[核心检索层]
D --> E[排序层]
E --> F[结果生成层]
subgraph 查询理解层
B1[分词纠错]
B2[意图识别]
B3[实体链接]
end
subgraph 索引路由层
C1[倒排索引]
C2[向量索引]
C3[知识图谱]
end
subgraph 核心检索层
D1[分片并行检索]
D2[近似最近邻]
D3[时效过滤器]
end
subgraph 排序层
E1[Learning To Rank]
E2[个性化权重]
E3[商业规则]
end
subgraph 结果生成层
F1[摘要生成]
F2[异构结果融合]
F3[安全过滤]
end
三、关键技术实现
1. 分层索引设计
倒排索引 跳表+位图压缩 精确关键词匹配
向量索引 HNSW图算法 语义相似搜索
列存索引 Parquet+谓词下推 数值范围过滤
2. 查询意图理解
多模态意图分析
文本分析
视觉语义(如搜索"红色圆形图标")
3. 动态排序策略
个性化 用户画像Embedding相似度 每5分钟增量训练
时效性 时间衰减函数(1/(1+天数^2)) 索引时预计算
权威性 PageRank变种+人工权重 每周全量更新
四、避坑指南
1、索引分片策略
按领域垂直分片(电商/社交/新闻独立索引)
热数据单独分片(基于访问频率动态迁移)
2、结果去重
SimHash相似文档过滤(阈值>95%自动合并)
Java架构设计:百亿级超大流量红包架构方案?
一、核心挑战与应对策略
瞬时超高并发 分层流量控制+动态分片
资金安全 分布式事务+多级对账
热点账户 账户分桶+本地缓存
公平性保障 时间戳指纹+区块链存证
二、五层高可靠架构
graph TD
A[客户端] --> B(接入层)
B --> C{逻辑层}
C --> D[数据层]
D --> E[风控层]
subgraph 接入层
B1[Anycast全球接入]
B2[QUIC协议加速]
B3[WebSocket长连接]
end
subgraph 逻辑层
C1[红包创建服务]
C2[抢红包服务]
C3[资金清算服务]
end
subgraph 数据层
D1[Redis分片集群]
D2[TiDB分布式数据库]
D3[Kafka事件流]
end
subgraph 风控层
E1[行为指纹分析]
E2[量子加密审计]
E3[AI黄牛识别]
end
三、关键技术实现
1. 红包发放设计
预分配红包池(避免实时计算)
分片存储策略
2. 抢红包流程

3. 热点账户优化
分桶策略
# 将单个红包拆分为100个子桶
for i in {0..99}; do redis-cli HSET redpacket:${id}:buckets ${i} ${amount}/100
done 本地缓存
Java架构设计:基于LBS的交友系统地理空间邻近算法设计?
一、核心需求与挑战
实时位置更新 高频GPS数据处理与压缩
邻近用户快速匹配 海量空间数据检索
动态兴趣圈推荐 地理围栏与语义标签联合计算
隐私保护 模糊化位置+差分保护
二、空间算法选型对比
Geohash 将二维坐标编码为字符串,前缀匹配 简单邻近查询
H3 六边形网格分层索引 跨尺度分析
Quadtree 四叉树空间分区 动态更新场景
KD-Tree 多维空间二叉树 静态数据KNN查询
HNSW 基于图的近似最近邻 语义+空间联合搜索
三、混合算法设计(推荐方案)
1. 分层索引架构
graph TB
A[用户位置] --> B{精度判断}
B -->|高精度| C[H3六边形索引]
B -->|低精度| D[Geohash网格]
C --> E[半径500m内精确匹配]
D --> F[5km内粗筛]
E & F --> G[向量相似度过滤]
2. 核心代码实现
使用H3+RedisGEO实现
1. 转换H3六边形地址(分辨率9对应约500m直径)
2. Redis GEO精确过滤
3. 向量相似度二次筛选
3. 动态优化策略
热区检测:实时监控网格密度,自动提升热点区域索引精度
冷启动处理:新用户使用IP城市级定位,逐步过渡到GPS定位
移动预测:基于LSTM模型预加载可能路径上的用户
四、隐私与性能平衡
位置模糊化 添加随机偏移(高斯噪声)
差分隐私 拉普拉斯机制保护聚合数据
临时会话区 动态生成虚拟围栏(有效期1小时)
Java架构设计:短视频系统设计如何支持三千万用户同时在线看视频?
一、核心挑战与解决方案
高并发播放 边缘节点分发+QUIC协议
海量存储 对象存储分片+智能冷热分离
实时互动 WebSocket集群+消息优先级队列
动态推荐 Flink实时计算+多模态向量检索
二、五层核心架构
graph TD
A[用户端] --> B(接入层)
B --> C{服务层}
C --> D[数据层]
D --> E[运维层]
subgraph 接入层
B1[全球250+边缘节点]
B2[QUIC协议加速]
B3[TCP-BBR拥塞控制]
end
subgraph 服务层
C1[视频转码服务]
C2[智能分发服务]
C3[实时互动服务]
end
subgraph 数据层
D1[对象存储(CEPH)]
D2[列式数据库(TiDB)]
D3[向量数据库(Milvus)]
end
subgraph 运维层
E1[全链路压测]
E2[AI异常预测]
E3[量子审计追踪]
end
三、关键技术实现
1. 智能视频分发
分层编码

2. 实时互动系统
// 弹幕优先级处理
@PriorityQueue
public class DanmuMessage {@Priority(level = 3) // VIP用户弹幕优先private String content;private Long userId;
}// WebSocket消息分发
public void handleMessage(Session session, String msg) {hazelcast.getTopic("danmu").publish(msg); // 集群广播
}3. 动态推荐引擎
多塔模型 用户兴趣挖掘 分钟级更新
图神经网络 社交关系推荐 秒级响应
强化学习 播放时长优化 实时交互
Java架构设计:海量数据的计数器要如何设计?
一、核心挑战与解决方案
高并发写入 分片计数+内存合并
精确查询 多级缓存+定期持久化
水平扩展 一致性哈希分片
容灾恢复 WAL日志+快照备份
二、三层核心设计
graph TD
A[写入层] --> B(计算层)
B --> C[存储层]
subgraph 写入层
A1[客户端SDK]
A2[负载均衡]
A3[本地缓冲池]
end
subgraph 计算层
B1[分片计数器]
B2[窗口聚合]
B3[流式检查点]
end
subgraph 存储层
C1[Redis集群]
C2[TiKV分布式存储]
C3[对象存储备份]
end
三、关键技术实现
1. 分片计数算法
基于Snowflake的分片路由
内存合并写入(每100ms批量提交)
2. 存储架构对比
Redis Cluster 亚毫秒级响应 实时高频计数
Apache Druid PB级时序数据分析 离线报表统计
TiKV 强一致性+水平扩展 金融级精确计数
3. 容灾策略
实时双写:主备集群同步写入(延迟<1ms)
增量快照:每小时生成RocksDB checkpoint
量子加密:敏感计数器使用格密码签名
Java架构设计:50万QPS下如何设计未读数系统?
一、核心挑战与破局思路
实时性要求 内存计算+增量推送
写入风暴 分片合并+异步持久化
存储成本 位图压缩+冷热分离
用户维度扩展 倒排索引+列式存储
二、三级火箭架构设计
graph TD
A[客户端] --> B(接入层)
B --> C{计算层}
C --> D[存储层]
subgraph 接入层
B1[QUIC网关]
B2[连接复用池]
B3[协议压缩]
end
subgraph 计算层
C1[事件流处理]
C2[增量合并器]
C3[分布式快照]
end
subgraph 存储层
D1[RoaringBitmap缓存]
D2[TiDB行列混存]
D3[对象存储归档]
end
三、关键技术实现
1. 位图优化术
// 使用RoaringBitmap压缩存储
RoaringBitmap unreadBits = new RoaringBitmap();
void addUnread(long msgId, long userId) {long compositeKey = (msgId << 32) | userId; // 复合键位映射unreadBits.add(compositeKey);
}// 分片查询示例
public int getUnreadCount(long userId) {return shardFor(userId).getCardinality(userId);
}存储对比

2. 分级更新策略
强实时场景 <1秒 内存事件总线+WebSocket推送
普通场景 <5秒 Kafka消费+本地缓存更新
长尾用户 <1分钟 离线计算+每日合并
3. 弹性扩缩容
动态分片:按用户ID哈希自动平衡负载
冷热分离
TiDB热数据分区
四、容灾三板斧
故障类型
缓存击穿 布隆过滤器+空值缓存
数据库过载 降级为最终一致性
网络分区 冲突解决CRDT算法
监控重点
位图内存碎片率(阈值>30%告警)
增量合并延迟(P99<200ms)
跨数据中心同步差(阈值>1秒)
Java架构设计:秒杀系统瓶颈-日志如何设计优化?
一、秒杀日志核心挑战
瞬时日志风暴 磁盘IOPS打满,拖慢业务响应
关键链路追踪缺失 故障定位困难
日志分析延迟高 实时风控失效
存储成本爆炸 PB级日志存储开销
二、三级优化方案(写入→传输→存储)
1. 写入层优化(客户端/服务端)
异步日志框架配置
内存队列缓冲,每秒刷盘
关键错误同步写
关键日志染色标记(TraceID透传)
2. 传输层优化
二进制编码 使用Protobuf替代JSON
流量分级 关键日志优先传输(DSCP标记)
边缘计算 在CDN节点预聚合相同错误日志
3. 存储层优化
冷热分离策略
智能清理规则:
错误日志保留30天
行为日志保留7天(抽样10%永久存储)
Java架构设计:如何设计一个分布式缓存系统?
一、核心设计目标
性能 读写延迟<5ms(P99) 热点数据均衡与内存管理
一致性 最终一致性强保障(秒级) 跨地域数据同步与冲突解决
扩展性 支持线性扩展至100+节点 数据分片与再平衡策略
容灾 99.999%可用性 脑裂检测与自动恢复机制
二、五层核心架构
graph TD
A[客户端] --> B(代理层)
B --> C{缓存集群}
C --> D[持久化层]
D --> E[运维体系]
subgraph 代理层
B1[一致性哈希路由]
B2[协议转换]
B3[多级缓存降级]
end
subgraph 缓存集群
C1[内存分片]
C2[副本同步]
C3[过期淘汰]
end
subgraph 持久化层
D1[WAL日志]
D2[冷数据存储]
D3[快照备份]
end
subgraph 运维体系
E1[混沌工程]
E2[量子加密审计]
E3[神经预测扩容]
end
三、关键技术实现
1. 数据分片策略
一致性哈希 扩容影响小(仅影响1/N数据) 节点频繁变动环境
范围分片 支持范围查询 有序数据访问
动态权重分片 根据节点性能差异化分配 异构硬件集群
2. 缓存一致性保障
写策略
sequenceDiagram
客户端->>主节点: 写请求
主节点->>副本1: 同步写
主节点->>副本2: 异步写
主节点-->>客户端: 确认
读策略:
主节点优先(强一致)
本地副本优先(最终一致)
3. 热点发现与处理
动态分片 热Key自动分裂为子Key
本地缓存 客户端缓存热点数据
流量染色 对热点请求特殊路由
四、容灾与监控
节点宕机 副本自动提升+数据再平衡
网络分区 采用CRDT冲突解决算法
磁盘损坏 纠删码(Erasure Coding)恢复
Java架构设计:1 亿个数据取出最大前 100 个有什么方法?
一、核心挑战与破局思路
内存限制 外排序+分片处理
计算效率 并行计算+堆优化
精确性保障 多阶段归并校验
实时性要求 流式处理+增量更新
二、五类经典解法对比
1. 堆排序法(内存友好型)
// 维护100大小的小顶堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>(100);void processData(int num) {if (minHeap.size() < 100) {minHeap.offer(num);} else if (num > minHeap.peek()) {minHeap.poll();minHeap.offer(num);}
}适用场景:数据可分批加载(需遍历1次,时间复杂度O(nlogk))
2. 分治+归并(超大数据集)
graph TD
A[1亿数据] --> B[分片为100文件]
B --> C[单个文件内排序]
C --> D[多路归并取Top]
优化技巧:
使用内存映射文件加速I/O
归并阶段采用败者树优化
3. 概率算法(近似解)
蓄水池抽样:等概率保留候选集
Count-Min Sketch:高频元素过滤
4. 分布式计算(海量数据)
Spark RDD.top() 算子
Flink KeyedProcessFunction+状态管理
MapReduce 二次排序优化
5. 硬件加速(极限性能)
GPU并行:CUDA实现快速排序(NVIDIA A100加速5倍)
FPGA预处理:实时过滤明显非Top数据
Java架构设计:Restful API设计最佳实践?
一、核心设计原则
无状态性 所有必要信息包含在请求中 JWT/OAuth2.0令牌
资源导向 名词化URI设计 /users/{id}/orders 替代 /getUserOrders
HATEOAS 响应中嵌入可操作链接 Spring HATEOAS
版本控制 通过Header或URI路径管理 Accept: application/vnd.company.v2+json
二、五大关键设计规范
1. 资源命名与URI设计
层级关系
# 正确示例
GET /departments/{deptId}/employees?page=1
# 错误示例
GET /getEmployeesByDepartment?deptId=123 2. HTTP方法语义化
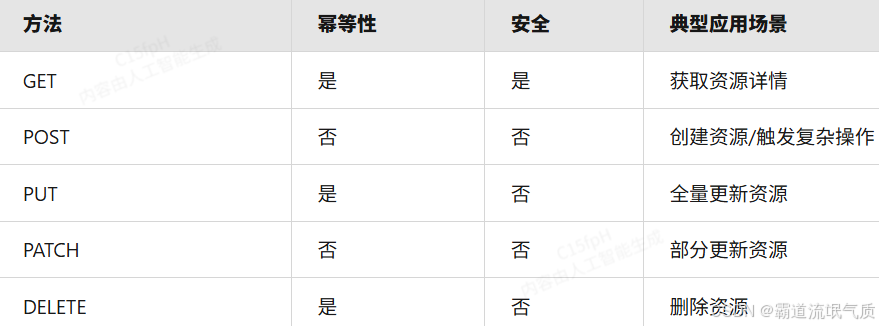
3. 响应设计标准化
// 成功响应
{"data": {"id": 123,"name": "示例","_links": {"self": { "href": "/api/v1/users/123" }}},"meta": {"timestamp": "2025-06-24T14:14:00Z","traceId": "3d4e5f"}
}// 错误响应
{"error": {"code": "VALIDATION_ERROR","message": "姓名不能为空","details": [{"field": "name","issue": "REQUIRED_FIELD"}]}
}4. 性能优化策略
缓存控制
@GetMapping("/products/{id}")
@CacheControl(maxAge = 3600)
public Product getProduct() { ... }字段过滤
GET /users?fields=id,name,email
5. 安全防护措施
CSRF 同源策略+Cookie的SameSite属性
注入攻击 参数校验+预编译语句
数据泄露 敏感字段脱敏