ARPO:让LLM智能体更高效探索
ARPO:让LLM智能体更高效探索
本文将聚焦Agentic Reinforced Policy Optimization(ARPO)算法,它针对大型语言模型在多轮工具交互中存在的不确定性问题,提出熵基自适应采样与优势归因估计策略。在13项基准测试中,ARPO不仅性能超越传统方法,还能节省一半工具使用预算,为LLM与动态环境的高效对齐提供新方向。
论文标题:Agentic Reinforced Policy Optimization
来源:arXiv:2507.19849 [cs.LG],链接:https://arxiv.org/abs/2507.19849
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
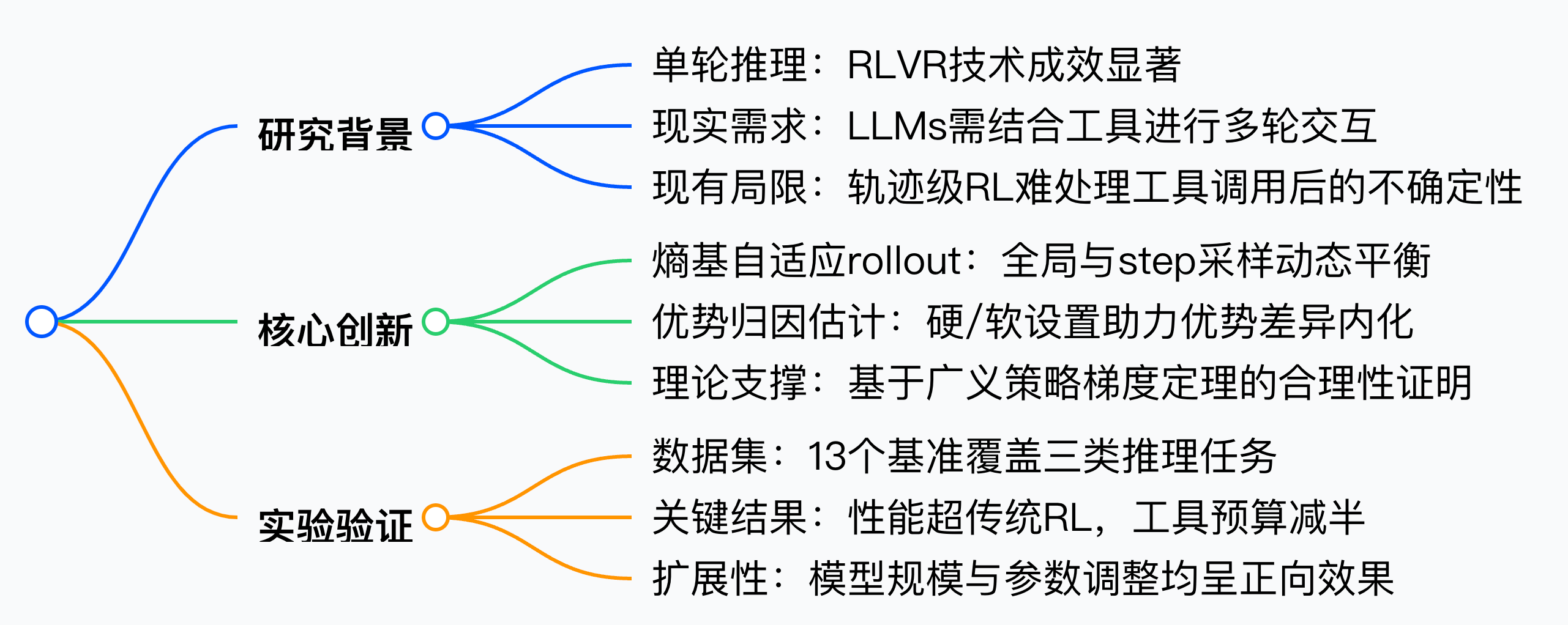
文章核心
研究背景
大规模可验证奖励强化学习(RLVR)已在释放大型语言模型(LLMs)的单轮推理能力方面展现出潜力,但现实推理场景中,LLMs需通过外部工具进行多轮动态交互。当前强化学习算法难以平衡模型的长程推理能力与多轮工具交互熟练度,轨迹级RL方法(如GRPO、DAPO)侧重完整轨迹采样,忽视工具调用后高不确定性步骤的细粒度行为探索,导致工具使用效率低、行为多样性不足,限制了LLM基智能体的性能。
研究问题
-
现有轨迹级RL算法过度关注完整轨迹采样比较,忽视工具使用步骤的细粒度行为探索,限制了工具使用行为的多样性与对齐效果。
-
LLM在接收工具反馈后,生成token的熵值显著升高(不确定性增加),但现有方法未针对这一特性优化采样策略,导致高潜力区域探索不足。
-
多轮工具交互中的优势差异难以被LLM有效内化,影响step级工具使用行为的学习效率,加剧了工具过度使用或使用不足的问题。
主要贡献
-
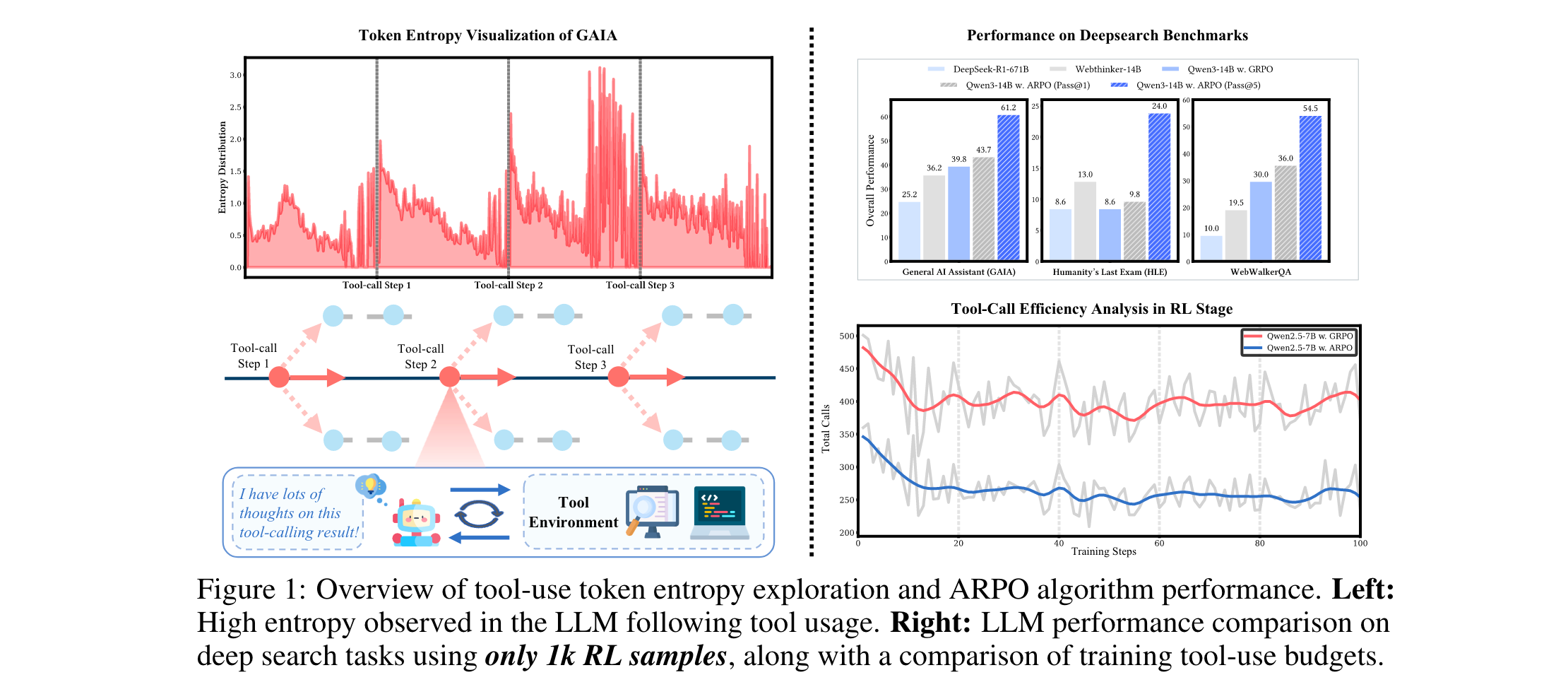
量化了LLM在智能体推理过程中的token熵变化,揭示出工具调用后存在高不确定性区域,而轨迹级RL算法无法有效捕捉这一特性,为新算法设计提供了关键洞察。
-
提出ARPO算法,其核心包括:熵基自适应rollout机制(动态平衡全局轨迹与step级采样,增强高熵工具使用步骤的探索);优势归因估计(通过硬/软两种设置,帮助LLM内化step级工具交互的优势差异)。
-
从理论上证明ARPO基于广义策略梯度(GPG)定理的合理性,并在13个基准测试(涵盖计算推理、知识推理、深度搜索)中持续优于主流RL算法,且工具使用预算仅为现有方法的一半,验证了其高效性与可扩展性。
思维导图
方法论精要
熵基自适应Rollout机制
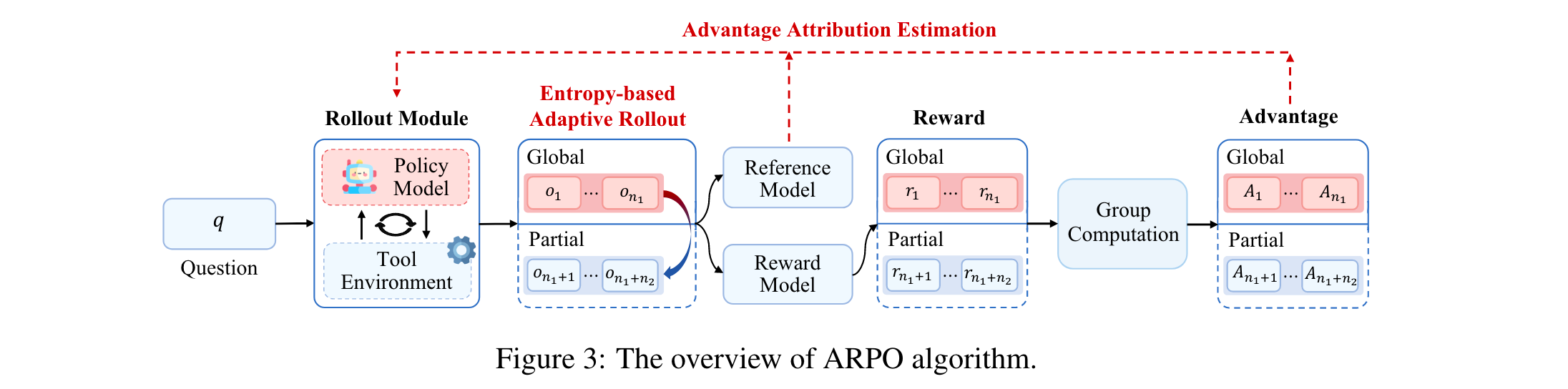
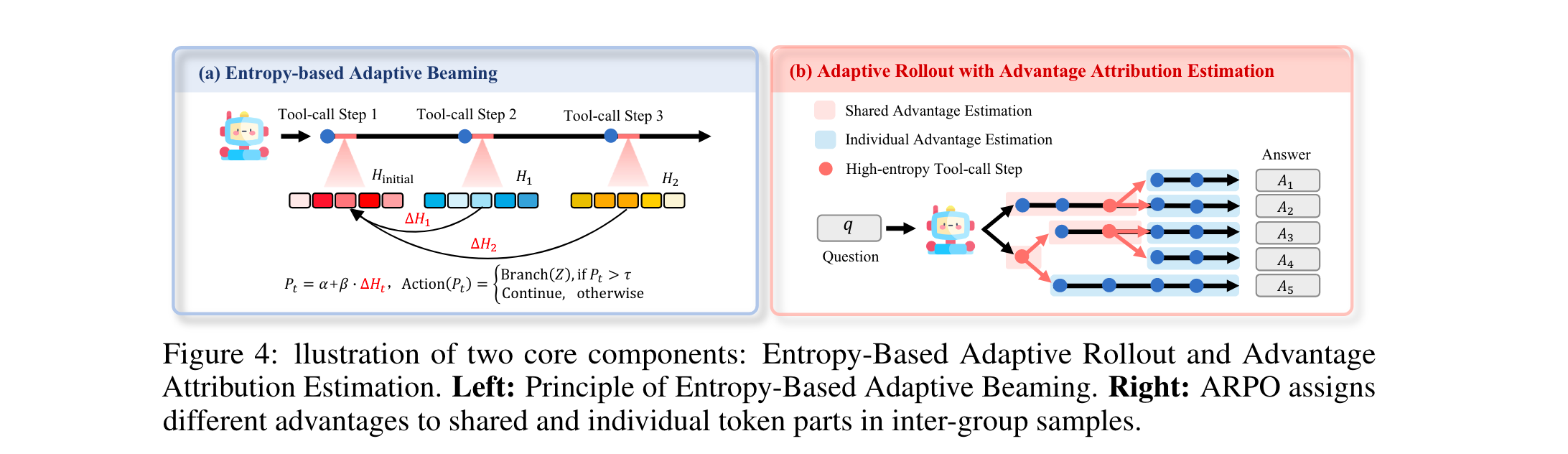
该机制旨在结合全局轨迹采样与step级部分采样,针对性探索工具调用后的高不确定性区域,具体步骤如下:
-
Rollout初始化
给定全局rollout规模(M),先通过轨迹级采样生成(N)条轨迹,剩余(M-N)预算保留用于部分采样。计算每条轨迹首token的初始熵矩阵HinitialH_{initial}Hinitial -
熵变化监测
工具调用后,模型生成额外token以计算step级熵矩阵HtH_tHt,通过归一化公式量化熵变化:
ΔHt=Normalize(Ht−Hinitial)\Delta H_t = \text{Normalize}(H_t - H_{\text{initial}})ΔHt=Normalize(Ht−Hinitial)
其中归一化通过除以词汇表大小(V)实现,正值表示不确定性增加。
-
熵基自适应分支
部分采样概率定义为Pt=α+β⋅ΔHtP_t = \alpha + \beta \cdot \Delta H_tPt=α+β⋅ΔHt(α\alphaα为基础概率,β\betaβ为稳定性系数)。若Pt>τP_t > \tauPt>τ(阈值),则从当前节点分支(Z)条部分推理路径;否则继续当前轨迹,实现高熵区域的定向探索。 -
终止条件
当分叉路径总数达(M-N)或所有路径提前终止(需补充采样至满足预算)时停止。该机制将计算复杂度从轨迹级RL的O(n2)O(n^2)O(n2)降至O(nlogn)O(n \log n)O(nlogn)到O(n2)O(n^2)O(n2)之间。
优势归因估计
为适配自适应rollout机制,ARPO设计了两种优势分配策略,帮助LLM内化step级工具交互的优势差异:
-
硬优势估计
明确区分轨迹的共享与独立部分:- 独立token的优势为归一化奖励
- 共享token的优势为包含该片段的(d)条轨迹的平均优势

- 软优势估计
基于GRPO框架,通过重要性采样比隐式区分共享与独立token:

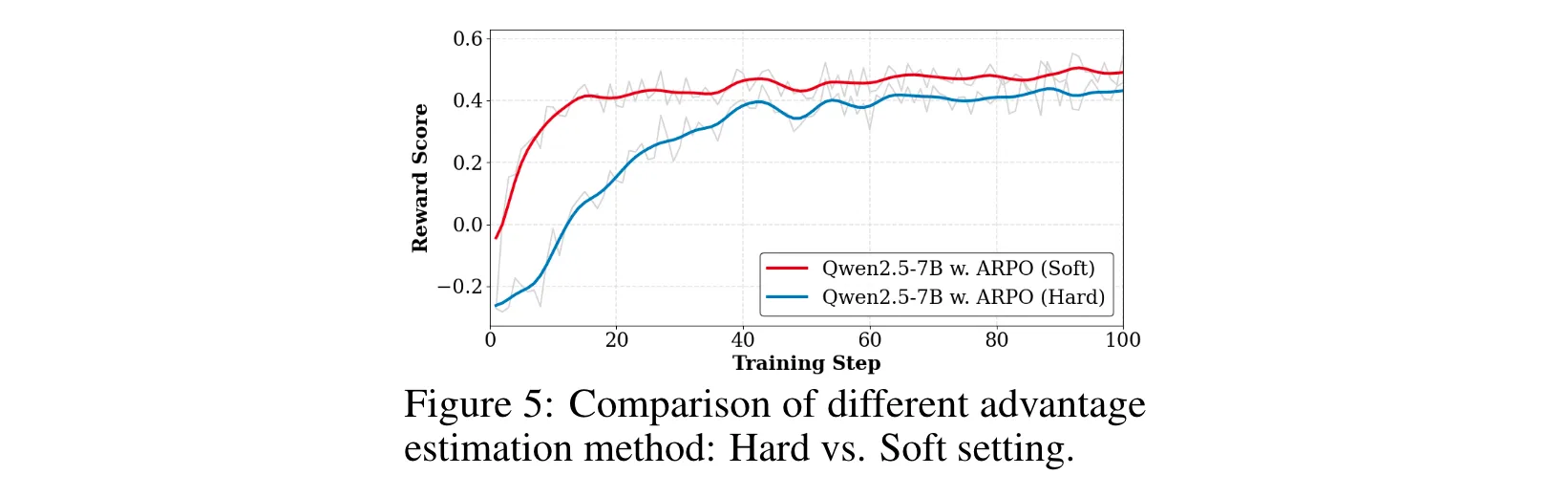
共享前缀token的ri,t(θ)r_{i,t}(\theta)ri,t(θ)相同,优势贡献近似硬估计中的共享优势。实验表明软设置训练更稳定,故为默认方案。
层级奖励设计
奖励函数综合正确性、格式与多工具协作因素,其中rM=0.1r_M = 0.1rM=0.1(当使用多工具时),激励模型规范且高效地使用工具。

实验洞察
数据集与基线设置
- 数据集
13个基准涵盖三类任务:
- 数学推理:AIME2024、AIME2025、MATH500、GSM8K等
- 知识密集型推理:WebWalker、HotpotQA、2WikiMultihopQA、Musique等
- 深度搜索:GAIA、HLE、WebWalker、xbench-DeepSearch等
- 基线
- 直接推理:Qwen2.5系列、Llama3.1系列、GPT-4o、o1-preview等
- 轨迹级RL算法:GRPO、DAPO、REINFORCE++
- LLM基搜索智能体:vanilla RAG、Search o1、Webthinker、ReAct等
- 训练设置
采用冷启动SFT+RL范式:SFT阶段使用Tool-Star的54K样本与STILL数据集;RL阶段对深度推理任务用10K样本,深度搜索任务用1K样本,工具包括搜索引擎、浏览器、Python解释器。
主要实验结果
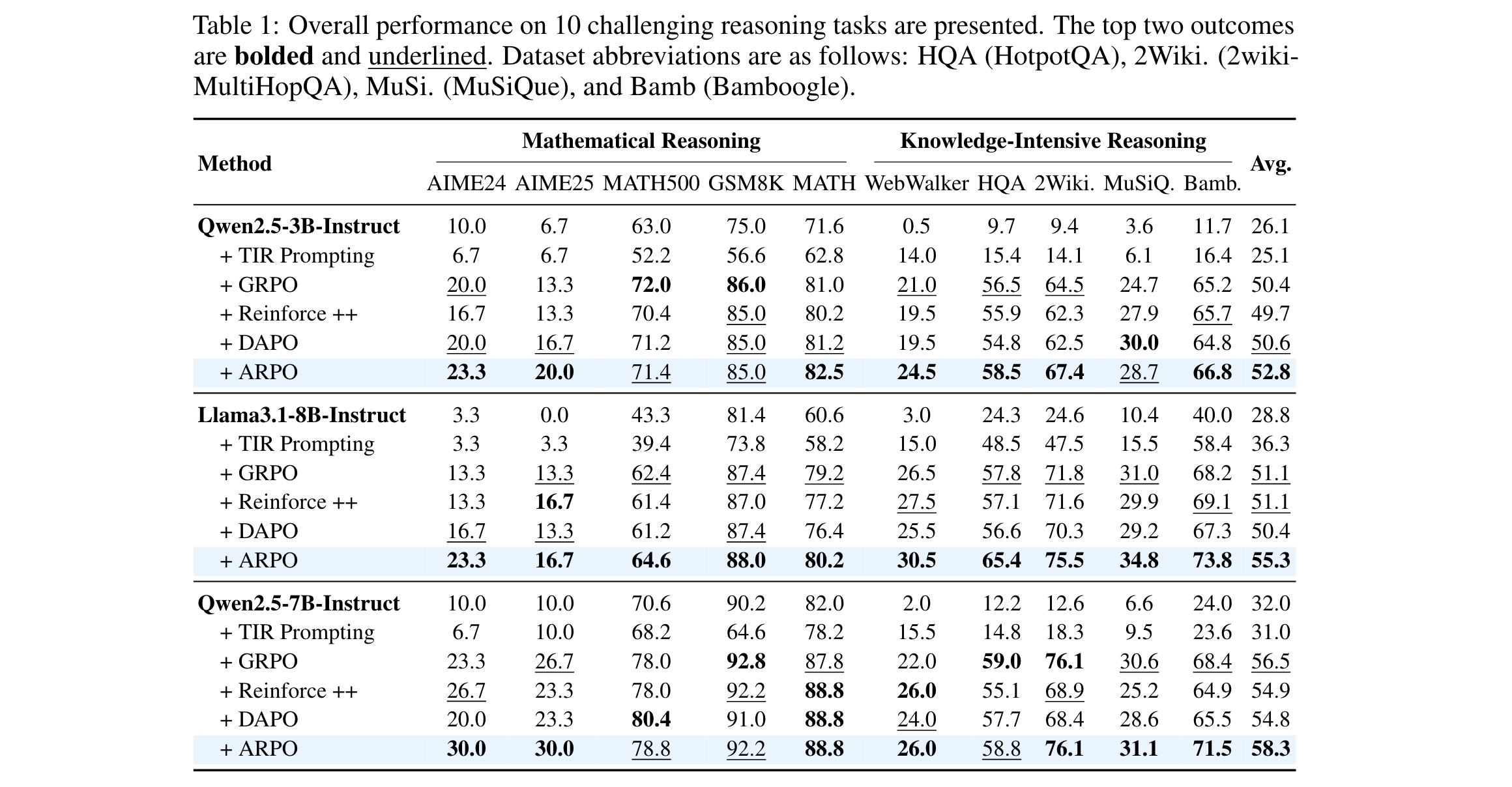
- 数学与知识推理任务
如表1所示,ARPO在10个数据集上均优于其他RL算法:
- Qwen2.5-7B+ARPO平均准确率达58.3%,较GRPO(56.5%)、DAPO(54.8%)分别提升1.8%和3.5%
- Llama3.1-8B+ARPO平均准确率达55.3%,较轨迹级RL平均提升4%
- 在AIME25、Bamboogle等任务中,ARPO的优势尤为显著(准确率提升3-5%)。
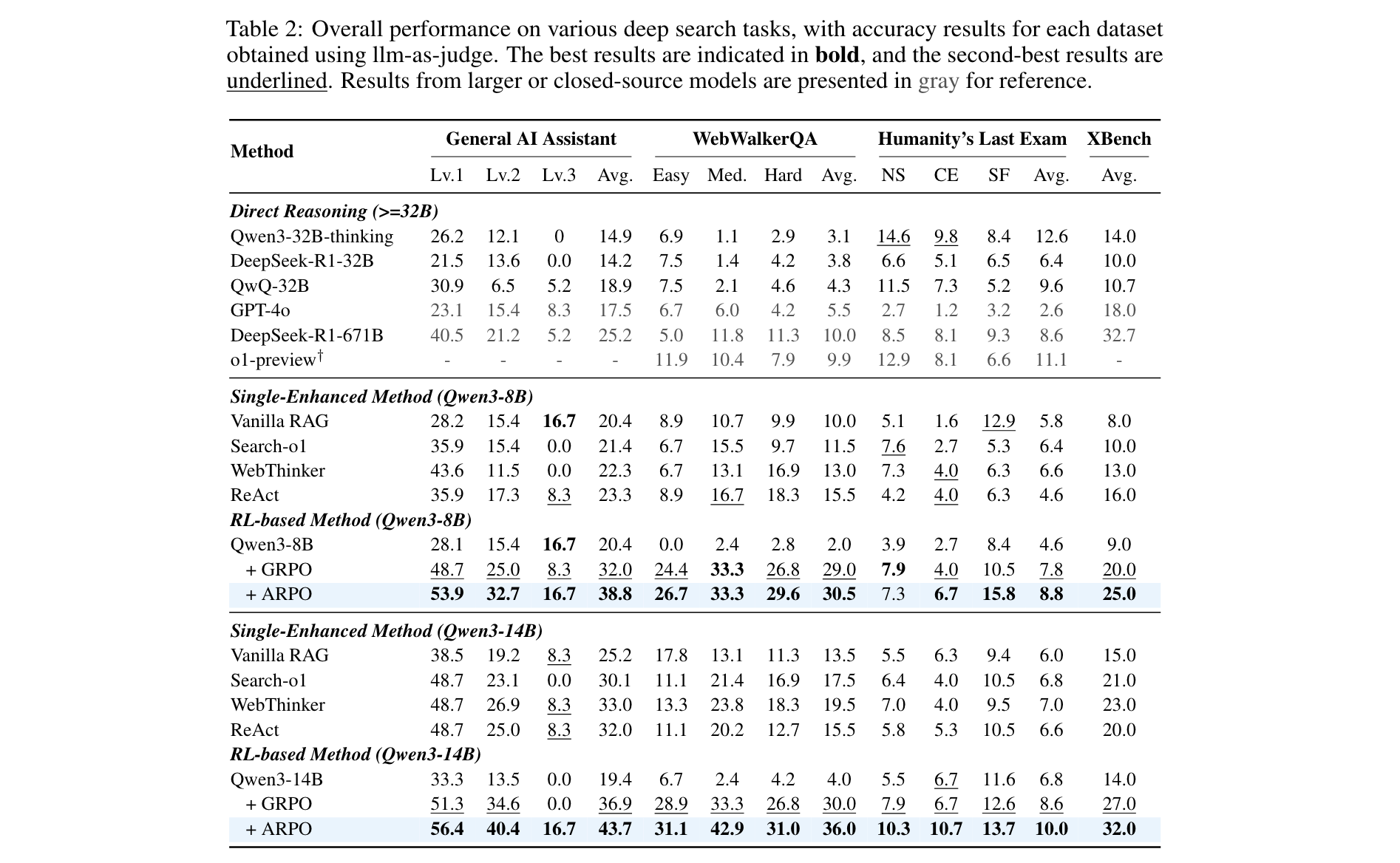
- 深度搜索任务
仅用1K RL样本训练时,ARPO表现突出(表2):
- Qwen3-8B+ARPO在GAIA的平均准确率达38.8%,超GRPO(32.0%)6.8%;在HLE达8.8%,显著优于GPT-4o(2.6%)
- Qwen3-14B+ARPO在WebWalkerQA的平均准确率达36.0%,超GRPO(30.0%)6%,且在xbench-DeepSearch的Pass@5达59%。
- 效率与扩展性分析
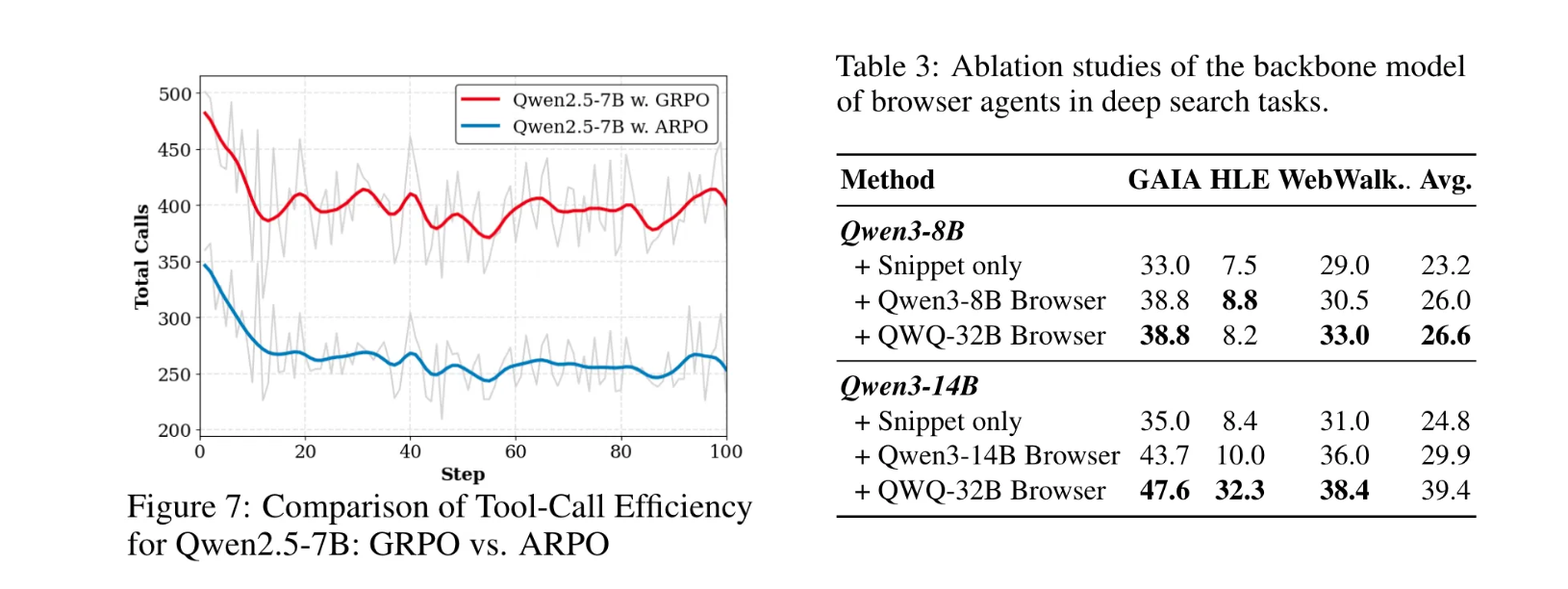
- 工具调用效率:Qwen2.5-7B+ARPO达到相同准确率时,工具调用次数仅为GRPO的一半(图7),证明其高效性。
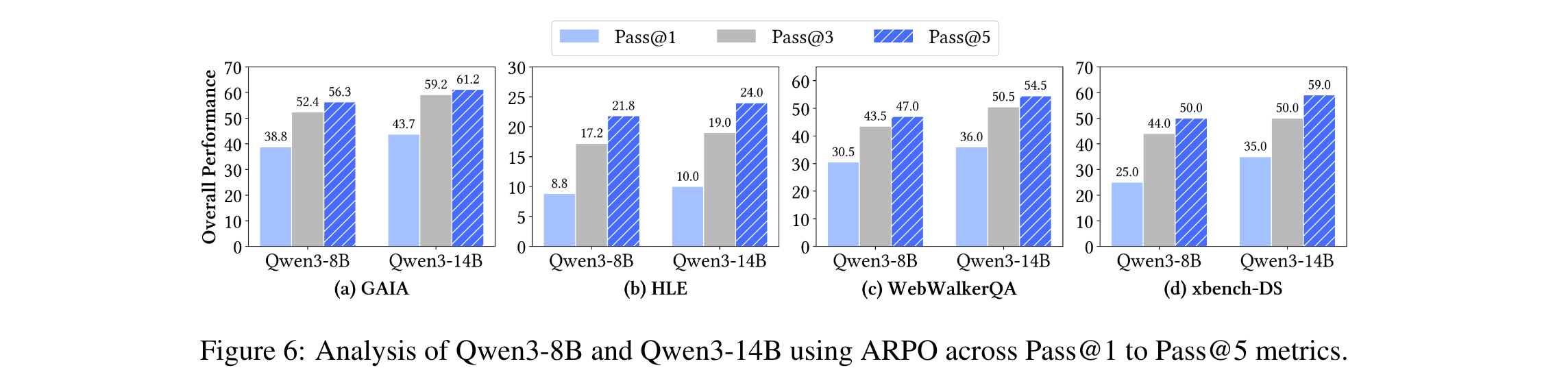
- 采样扩展性:Pass@3和Pass@5指标显示,ARPO在多采样场景下性能持续提升,Qwen3-14B+ARPO在GAIA的Pass@5达61.2%(图6)。
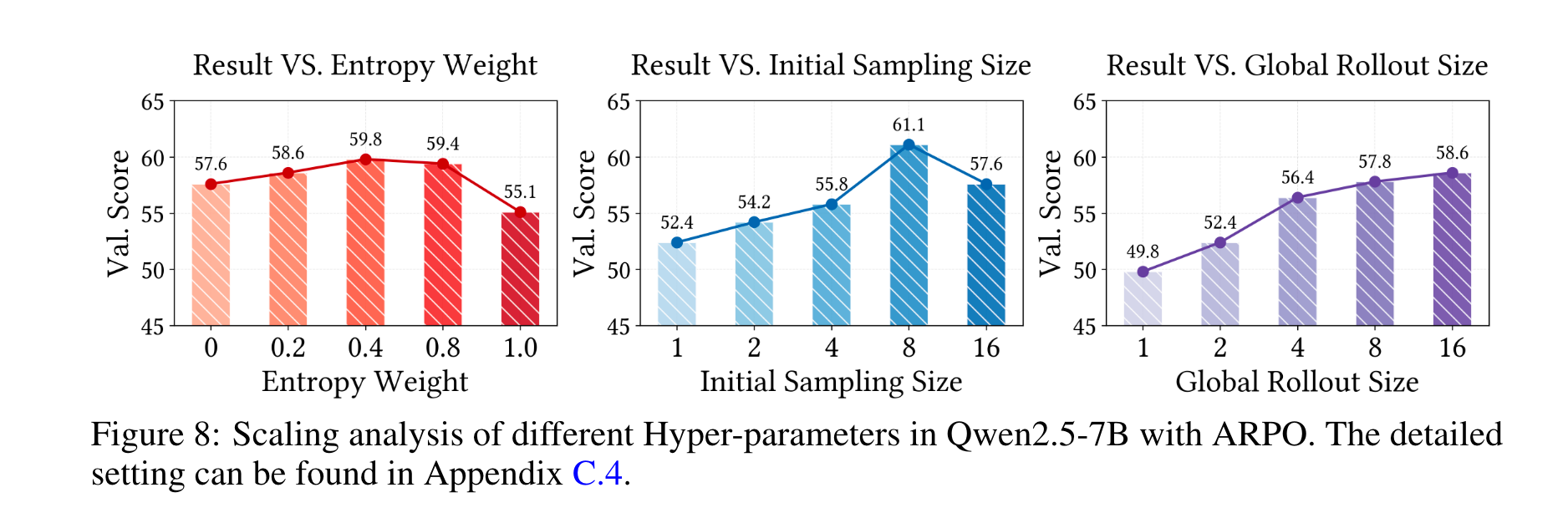
- 参数敏感性:熵值0.4、初始采样规模8、全局rollout规模增大时性能最优(图8),验证了算法的稳定性。
- 消融实验
浏览器智能体能力显著影响深度搜索性能(表3):
- 无浏览器(仅用片段)时,Qwen3-8B的平均准确率为23.2%;
- 同规模浏览器智能体提升至26.0%;
- 更大参数浏览器智能体(QWQ-32B)进一步提升至39.4%,表明外部工具能力与任务准确率正相关。
关键发现
- 提示工程(如TIR)对工具使用行为优化效果有限,甚至低于直接推理,说明仅靠提示难以引导LLM实现高效工具交互。
- 轨迹级RL在多轮工具交互中存在固有局限,而ARPO的step级探索更适配LLM与环境的动态交互特性,尤其在高熵区域的探索增益显著。
- ARPO的优势在不同模型骨干(Qwen、Llama系列)上均稳定存在,证明其算法设计的通用性与有效性。