Highly Compressed Tokenizer Can Generate Without Training
GitHub - lukaslaobeyer/token-opt: Code for ICML 2025 Paper "Highly Compressed Tokenizer Can Generate Without Training"
目录
论文核心思想:Tokenizer即生成器
Figure 1: 核心能力展示
第一部分:为什么1D Tokenizer的潜空间如此特别?
Figure 2: 令牌位置决定语义 (Token Position Is Key to Token Semantics)
Figure 3: 潜空间中的“复制粘贴”编辑
第二部分:如何通过梯度优化进行生成?
Figure 4 & 公式 (4): 文本引导的图像编辑
Figure 5, 6, 7: 框架的灵活性
第三部分:定量评估与分析
Table 1, 2, 3: 关键因素分析
Table 6: 系统级对比
总结
这篇论文的核心观点非常惊人:一个足够强大的图像编码器(Tokenizer),本身就具备了生成和编辑图像的能力,甚至不需要训练一个专门的生成模型(如Diffusion Model或GAN)。它通过一种“测试时优化”的巧妙方法,直接在编码器的压缩空间里“雕刻”出想要的图像。
让我们围绕论文中的图表和公式,一步步揭示这个魔法是如何实现的。
论文核心思想:Tokenizer即生成器
传统的图像生成流程是“两步走”:
- Tokenizer (编码器): 将图像压缩成一个紧凑的、离散的“令牌”(token)序列。这一步是为了降维和效率。
- Generative Model (生成模型): 在这个令牌序列上学习,比如用一个Transformer或扩散模型来预测下一个令牌或去噪。
作者提出了一个大胆的设想:如果第一步的Tokenizer压缩能力极强,比如把一张256x256的图像压缩到仅仅32个令牌(这被称为1D Tokenizer),那么这个Tokenizer的解码器(Decoder)本身就必须具备强大的“脑补”能力,也就是生成能力。既然如此,我们为什么不直接利用它来生成呢?
Figure 1: 核心能力展示
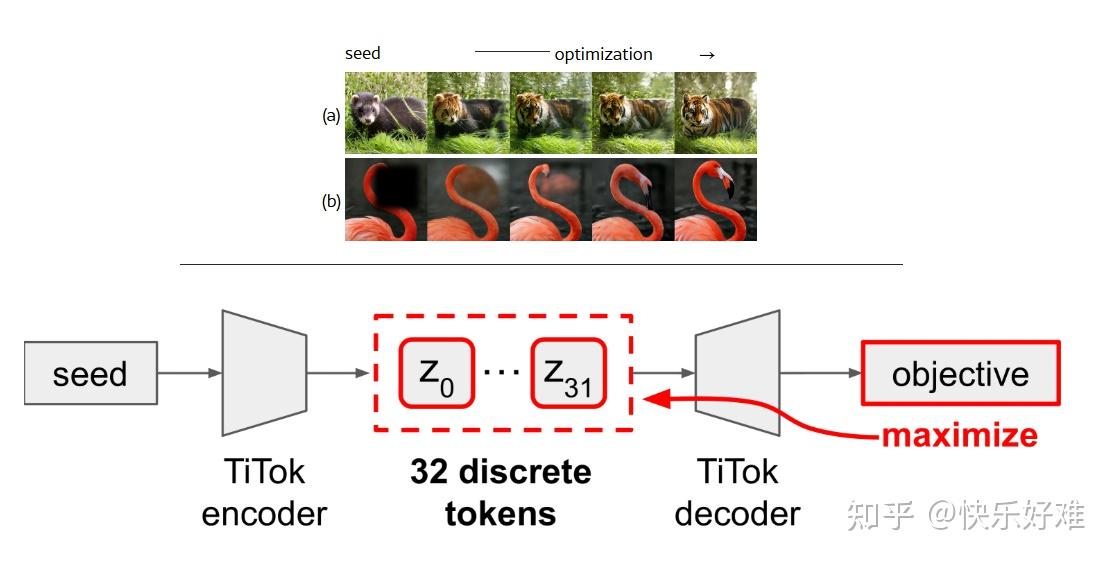
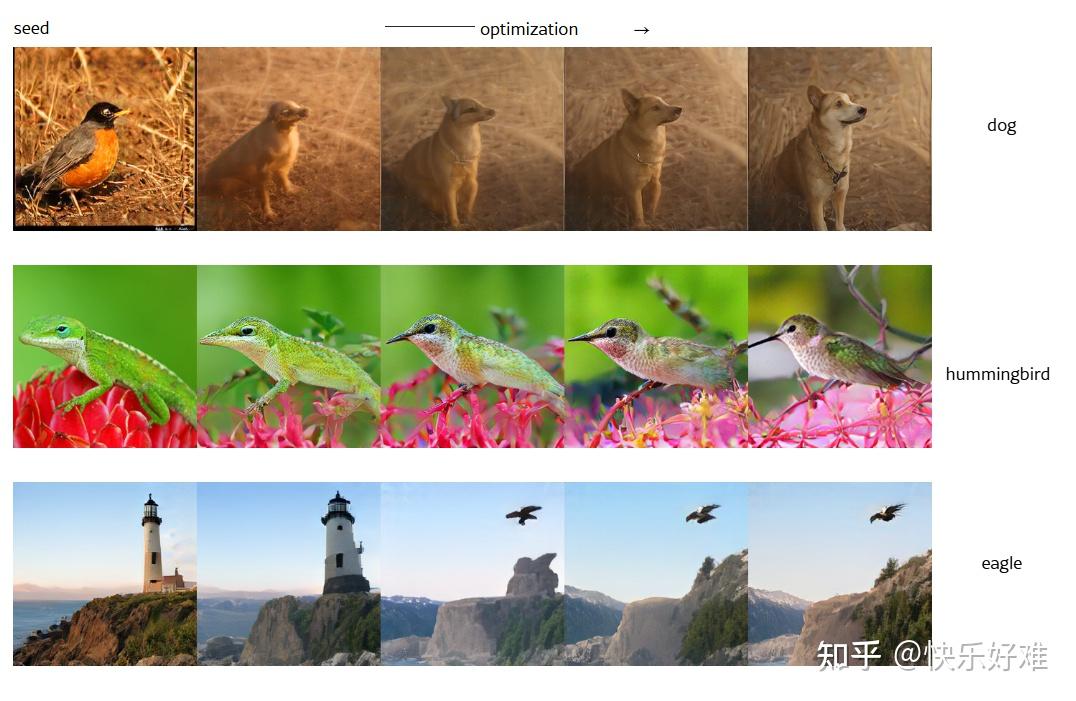
这张图是论文的开篇暴击,直接展示了最终成果:
- (a) 文本引导的编辑 (Text-guided editing): 从一张狗的图片(seed)出发,通过优化,把它变成了鹰、蜂鸟等。这个过程没有训练,仅仅是根据文本提示(如"an eagle")进行优化 (optimization)。
- (b) 图像修复 (Inpainting): 给一张有遮罩的图片,模型能“脑补”出缺失的部分。同样,这也是通过优化完成的,目标是让生成区域和已知区域看起来和谐。
这里的关键信息是:所有这些生成任务,都没有训练一个新模型,而是基于一个预训练好的Tokenizer,在测试时通过梯度优化直接完成。
第一部分:为什么1D Tokenizer的潜空间如此特别?
在解释如何优化之前,论文先用实验证明了1D Tokenizer的潜空间(latent space)是多么“神奇”和“有意义”。
Figure 2: 令牌位置决定语义 (Token Position Is Key to Token Semantics)
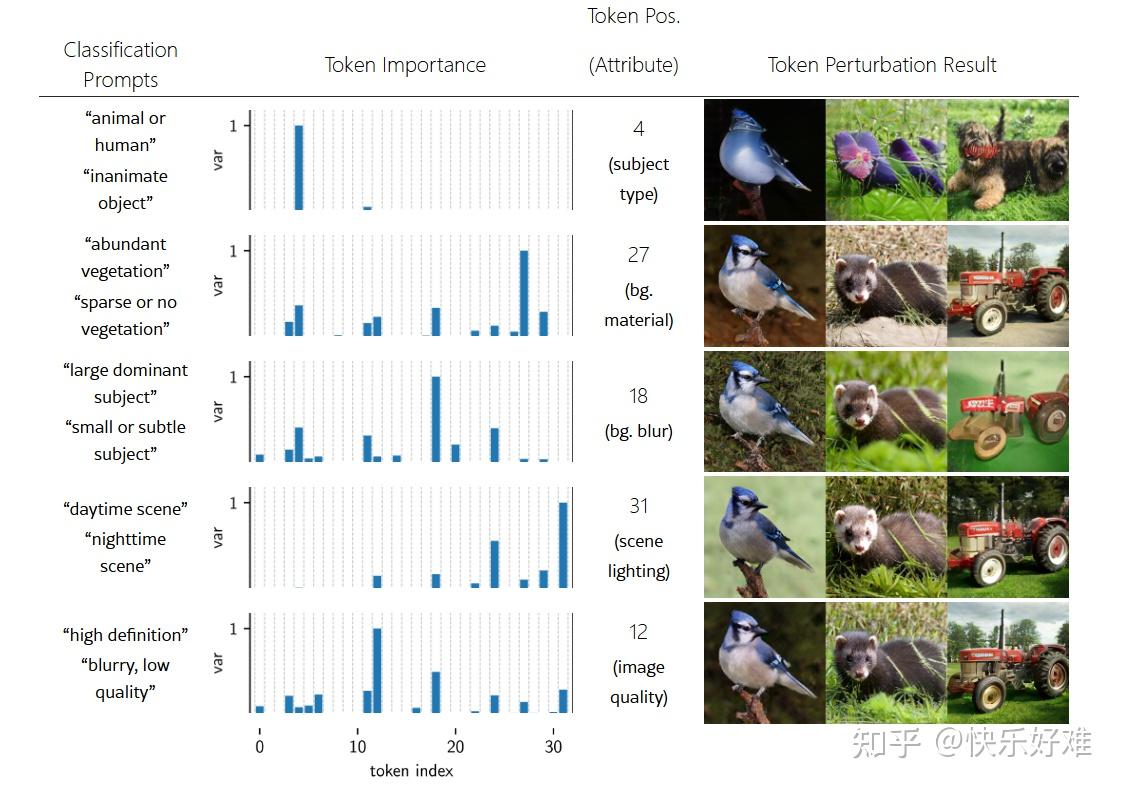
这张图揭示了一个惊人的发现:1D Tokenizer的不同令牌位置,天然地解耦了图像的高层语义属性。
作者做了两个实验来证明这一点:
- 左侧(Token Importance):
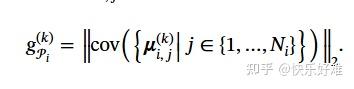
-
- 做法: 将ImageNet数据集按不同概念分组(如“动物 vs. 无生命物体”,“植被茂盛 vs. 稀疏”)。然后,观察在不同组之间,32个令牌位置中,哪个位置的特征差异最大。
- 公式(1): g(k) 就是用来衡量这个差异的。它计算的是在某个分类标准下,不同类别在第k个令牌位置上的平均特征的方差。方差越大,说明这个位置k对于区分这些类别越重要。
- 发现: 如图所示,对于“动物 vs. 物体”这个分类,第4个令牌最重要;对于“白天 vs. 黑夜”,第31个令牌最重要。这说明特定的令牌位置编码了特定的全局属性。
- 右侧(Token Perturbation):
- 做法: 为了验证上述发现,作者进行了“令牌扰动”实验。他们固定一张图,只改变某个特定位置的令牌(比如第18个),尝试所有可能的令牌值,找出能让图像变化最大的那个。
- 发现: 扰动第18个令牌,图像的背景变得模糊;扰动第12个令牌,图像变得更清晰。这与左侧实验的发现完全吻合!第18个令牌控制背景模糊,第12个控制图像质量。
Figure 3: 潜空间中的“复制粘贴”编辑
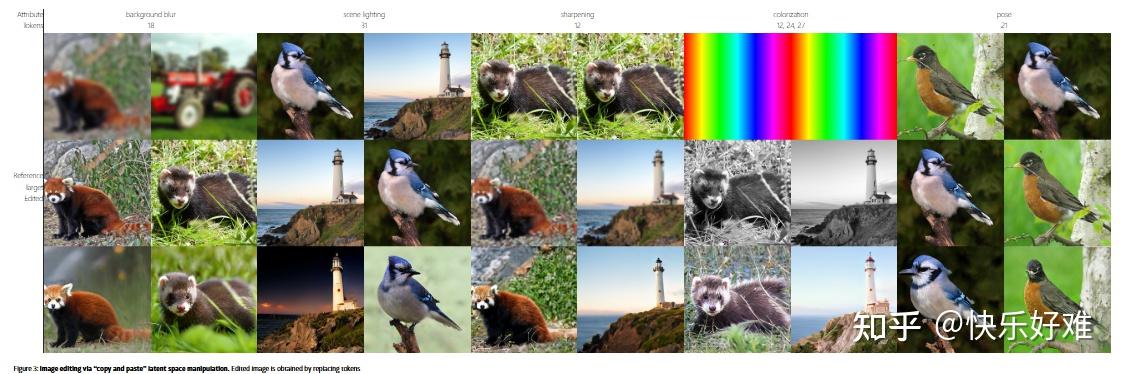
基于Figure 2的发现,作者展示了一种极为简单粗暴的编辑方法:“复制粘贴”。
- 做法: 想要把A图的某个属性(如“傍晚的光照”)应用到B图上?很简单:
- 将A图和B图都编码成32个令牌。
- 从Figure 2我们知道,第31个令牌控制“光照”。
- 把A图的第31个令牌,直接复制到B图的第31个令牌位置上,然后解码。
- 结果: B图神奇地拥有了A图的光照风格,而主体内容保持不变。
这张图有力地证明了1D Tokenizer的潜空间是高度结构化和语义化的。这在传统的2D Tokenizer(令牌与图像块对应)中是不可想象的,修改一个令牌只会影响一小块区域。而1D Tokenizer的每个令牌都具有全局视野。
第二部分:如何通过梯度优化进行生成?
“复制粘贴”虽然神奇,但不够灵活。于是,作者提出了一个通用的梯度优化框架。
Figure 4 & 公式 (4): 文本引导的图像编辑
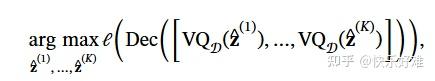
这是整个方法的核心机制。
- 目标: 给定一张种子图和一句文本提示(如“a photo of a hummingbird”),修改图像使其符合文本描述。
- 公式 (4):
我们来拆解一下这个优化过程:
- 初始化: 从种子图编码得到一组连续的特征向量
z^z^
(在量化之前)。 - 量化(VQ): 将这些连续特征 z^z^通过向量量化(Vector Quantization),变成离散的、最接近的码本条目 zz。这是不可导的,但可以用Straight-Through Estimator技巧来传递梯度。
- 解码(Dec): 将量化后的离散令牌序列解码成一张图像。
- 计算损失(
ℓℓ): 用CLIP模型计算生成图像和文本提示的相似度得分。 - 梯度上升: 计算相似度得分相对于初始连续特征
z^z^
的梯度,并更新 z^z^。 - 循环: 重复2-5步,直到生成的图像与文本足够匹配。
Figure 4 展示了这个迭代过程,图像从一只狗逐渐“变身”成蜂鸟或鹰,非常直观。
Figure 5, 6, 7: 框架的灵活性
- Figure 5: 展示了更灵活的编辑,可以只改变背景或情境(如“在沙滩上”,“在雪地里”),而主体保持不变。
- Figure 6: 展示了**“从零开始”的生成**。此时没有种子图,直接从随机噪声初始化的令牌开始优化。这证明了该方法具备真正的文本到图像生成 (Text-to-Image) 能力。
- Figure 7: 展示了图像修复 (Inpainting)。只需把优化目标从“CLIP相似度”换成“与已知像素的L1重构损失”,同一个框架就能解决新问题。这体现了其“即插即用”(Plug-and-play)的特性。
第三部分:定量评估与分析
光有酷炫的图还不够,还需要用数据证明。
Table 1, 2, 3: 关键因素分析
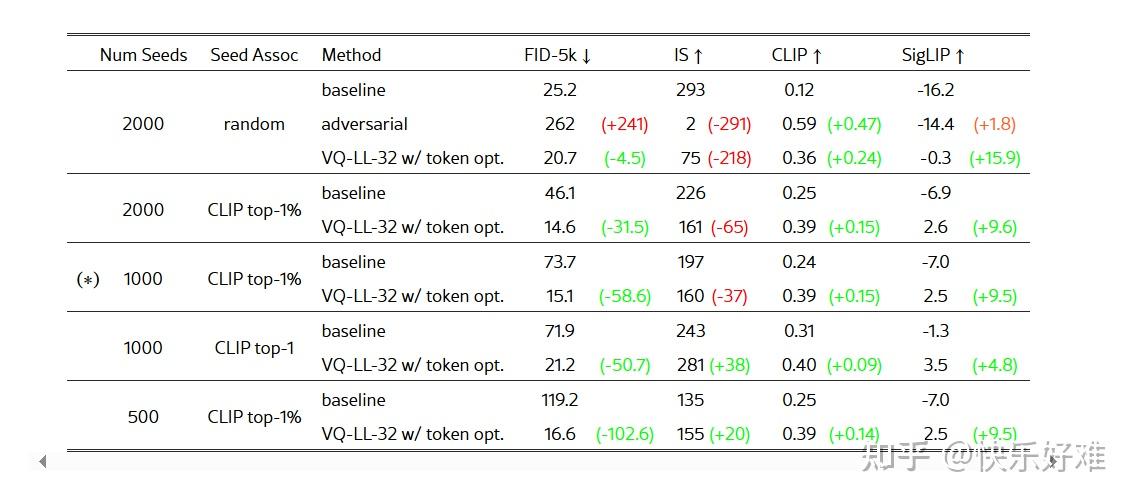
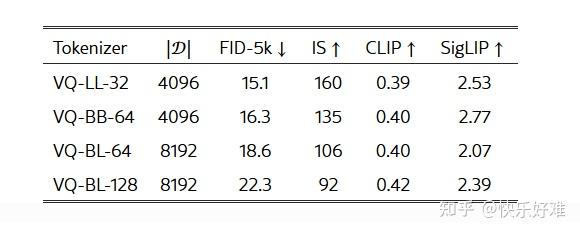
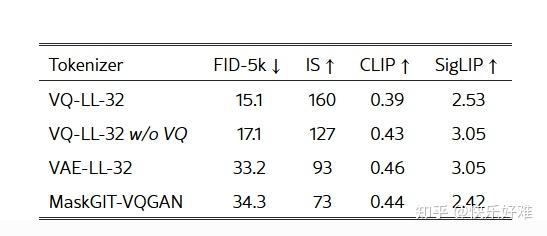
这三张表揭示了方法成功的核心要素:
- Table 1: 证明了该方法效果显著。与基线(直接用种子图)相比,FID(越低越好)大幅降低,而CLIP/SigLIP相似度(越高越好)显著提升。并且只需要很少的种子图(如1000张)就能生成多样化的结果。
- Table 2: 压缩率是王道。当令牌数量从32增加到64、128时,生成质量(FID)反而变差。这印证了论文的核心假设:高压缩率迫使Tokenizer学习到更强大的生成先验。
- Table 3: 1D 和 离散化 是关键。
- 1D vs. 2D: 使用传统的2D Tokenizer (MaskGIT-VQGAN),该方法完全失效。
- 离散 vs. 连续: 使用连续令牌的VAE,或者在优化时绕过VQ步骤,效果都会急剧下降。这说明向量量化 (VQ) 起到了至关重要的正则化作用,防止优化过程跑偏。
Table 6: 系统级对比

这是最令人振奋的对比。
- Gen. Model Training (是否需要训练生成模型): 我们的方法是No,而其他方法都是Yes。
- Plug & Play Guidance (是否支持即插即用的引导): 我们的方法是Yes。
- FID (生成质量): 我们的方法(FID 8.2)接近甚至超过了许多需要专门训练复杂生成模型的SOTA方法(如ADDP的7.6,RCDM的19.0)。
结论: 一个预训练好的1D Tokenizer,仅通过测试时优化,就能达到与需要大量训练的完整生成模型相媲美的性能。
总结
这篇论文的核心贡献可以概括为:
- 发现了1D Tokenizer的强大潜力: 证明了其高度压缩的、语义化的潜空间本身就蕴含了生成能力,甚至可以通过“复制粘贴”进行精细编辑。
- 提出了一个训练无关的生成框架: 通过测试时梯度优化,可以在不训练任何新模型的情况下,完成文本到图像生成、图像编辑、修复等多种任务。
- 指明了新的研究方向: 论文的结果表明,未来的研究重点或许可以更多地放在构建更强大的Tokenizer上,而不是仅仅把它当作一个简单的预处理工具。一个足够好的编码器,本身就是半个生成器。
转自:论文速读:20250612 - 知乎