【Dolphinscheduler】docker搭建dolphinscheduler集群并与安全的CDH集成
1 文档编写目的
Apache DolphinScheduler(以下简称 DS)是一个分布式、去中心化、易扩展的可视化 DAG 工作流任务调度平台,致力于解决数据处理流程中复杂的依赖关系,使调度系统开箱即用。本篇文档主要介绍如何在 CDH 安全集群环境中部署 DolphinScheduler 集群。
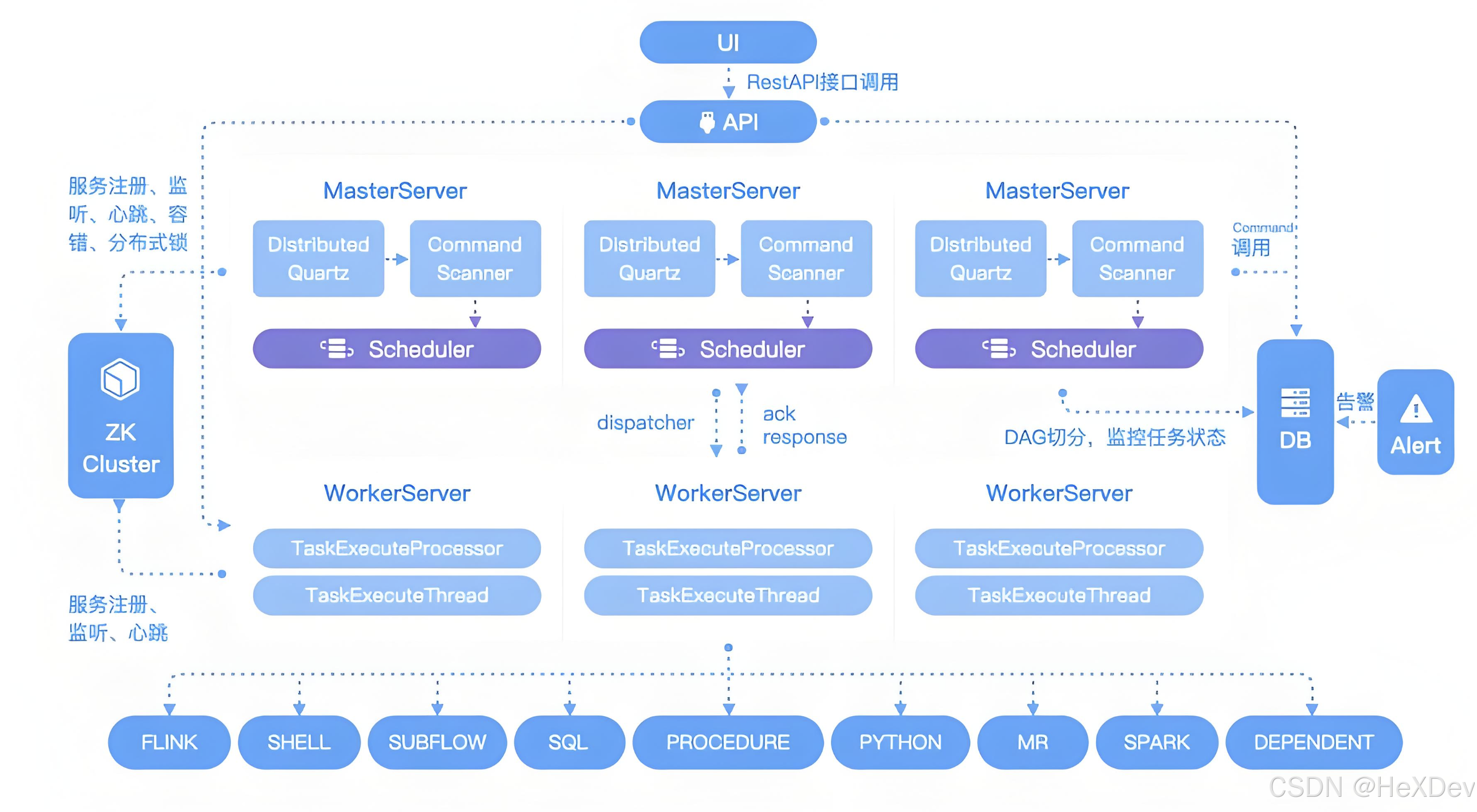
高可靠性
采用去中心化架构,Master 与 Worker 节点对等部署,避免单点瓶颈和性能压力。内置任务缓冲队列,有效应对高并发任务,确保系统稳定运行。
简单易用
提供可视化 DAG 流程定义界面,支持拖拽式任务编排,实时监控任务状态。支持通过 API 与外部系统集成,实现一键部署与自动化调度。
丰富的使用场景
支持多租户隔离、任务暂停与恢复操作,深度集成大数据生态系统,内置支持 Spark、Hive、MapReduce、Python、Shell、SubProcess 等近 20 种任务类型,覆盖多种数据处理需求。
高扩展性
调度器采用分布式架构,具备良好的横向扩展能力,Master 和 Worker 节点可动态扩缩容。支持自定义任务插件,满足多样化业务场景的调度需求。
2 部署环境说明
1.CM和CDH版本为6.3.2
2.DolphinScheduler版本为3.1.9
3.Zookeeper为3.7.1
本次使用3个节点来部署DolphinScheduler集群,搭建一个具备高可用性的集群,具体部署节点及角色分配如下:
| IP | 主机名 | 备注 |
|---|---|---|
| 172.10.0.2 | cm.hadoop | Master/Worker/API/Altert/ZK |
| 172.10.0.3 | cdh01.hadoop | Master/Worker/API |
| 172.10.0.4 | cdh02.hadoop | Master/Worker |
3 前置条件准备
安装zookeeper
由于cdh集群中的zookeepr是给cdh定制使用的是3.4.5版本无法满足dolphinscheduler3.1.9的使用要求(最低 3.5),所以需要单独安装
1、下载:
wget https://downloads.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
2、快速启动(单机):
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
cd apache-zookeeper-3.7.1-bin
mkdir data
echo "tickTime=2000
dataDir=./data
clientPort=2181
initLimit=5
syncLimit=2" > conf/zoo.cfgbin/zkServer.sh start
然后配置 DolphinScheduler 指向这个 ZooKeeper。
4 安装DolphinScheduler
4.1 环境准备
1.准备最新的DolphinScheduler安装包地址如下:
https://dolphinscheduler.apache.org/zh-cn/download/download.html
将下载好的安装包上传至cm节点的/root目录下。
2.分别在CDH3台服务器上执行以下命令,配置java环境变量:
sudo bash -c 'cat >> /etc/profile <<EOFexport JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera/
export PATH=\$JAVA_HOME/bin:\$PATH
export CLASSPATH=\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tool.jar:\$CLASSPATHEOF'
source /etc/profile
3.确保集群所有节点安装了psmisc包,安装命令如下:
yum -y install psmisc
4.创建DS的部署用户和集群所有节点的hosts映射,在集群所有节点配置/etc/hosts映射文件,内容如下:

5.在集群所有节点使用root用户执行如下命令,向操作系统添加一个dolphin用户,设置用户密码为dolphin123,并为该用户配置sudo免密权限
useradd dolphin
echo "dolphin123" | passwd --stdin dolphin
echo 'dolphin ALL=(ALL) NOPASSWD: NOPASSWD: ALL' >> /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers

在所有节点执行如下命令切换只dolphin用户下验证sudo免密权限配置是否成功
su - dolphin
sudo ls /root/
注意:此处必须创建部署用户dolphin,且为该用户配置sudo免密,否则该用户无法通过sudo -u的方式切换不同的Linux用户的方式来实现多租户运行作业。
6.选择cm.hadoop节点作为主节点,配置cm节点本机ssh免密登录及到01和02节点的免密登录(这里使用dolphin用户配置)
在集群所有节点执行如下命令为dolphin用户生成秘钥文件(一路回车即可):
su - dolphin
ssh-keygen -t rsa
将dolphin用户/home/dolphin/.ssh目录下的公钥文件内容添加到authorized_keys文件中,并修改文件权限为600
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ll ~/.ssh/authorized_keys
测试cm节点免密登录配置是否成功
ssh localhost
将cm节点生成的authorized_keys文件拷贝至其他节点的/home/dolphin/.ssh目录下(密码为:dolphin123):
scp ~/.ssh/authorized_keys dolphin@cdh01:/home/dolphin/.ssh/
scp ~/.ssh/authorized_keys dolphin@cdh02:/home/dolphin/.ssh/
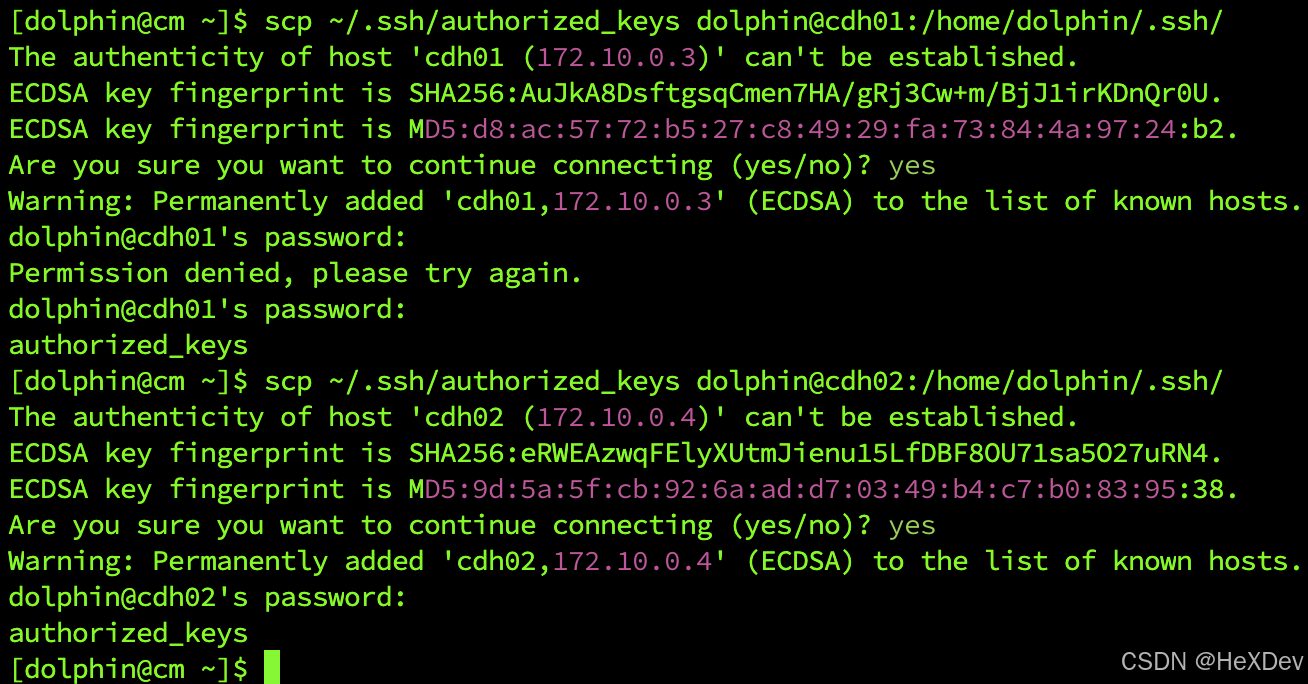
完成上述操作后,验证01到其他节点的免密登录配置是否成功,不需要配置密码则表示配置成功。

7.将上传到cm节点的DolphinScheduler安装包拷贝解压至/home/dolphin目录下
将宿主机dolphin文件上传到cm容器
docker cp apache-dolphinscheduler-3.1.9-bin.tar.gz cm.hadoop:/home/dolphin/
cd /home/dolphin
tar -zxvf apache-dolphinscheduler-3.1.9-bin.tar.gz
chown -R dolphin. apache-dolphinscheduler-3.1.9-bin
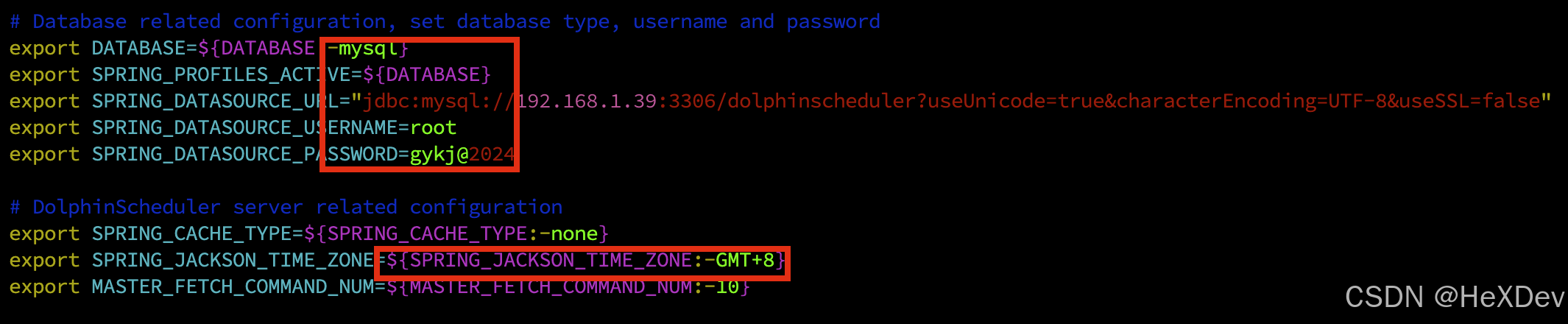
4.2 配置dolphinscheduler_env.sh
修改./bin/env/dolphinscheduler_env.sh 配置文件,配置DolphinScheduler的环境变量:
1.mysql配置:
vim ./bin/env/dolphinscheduler_env.sh
2.jdk配置:
修改JAVA_HOME:

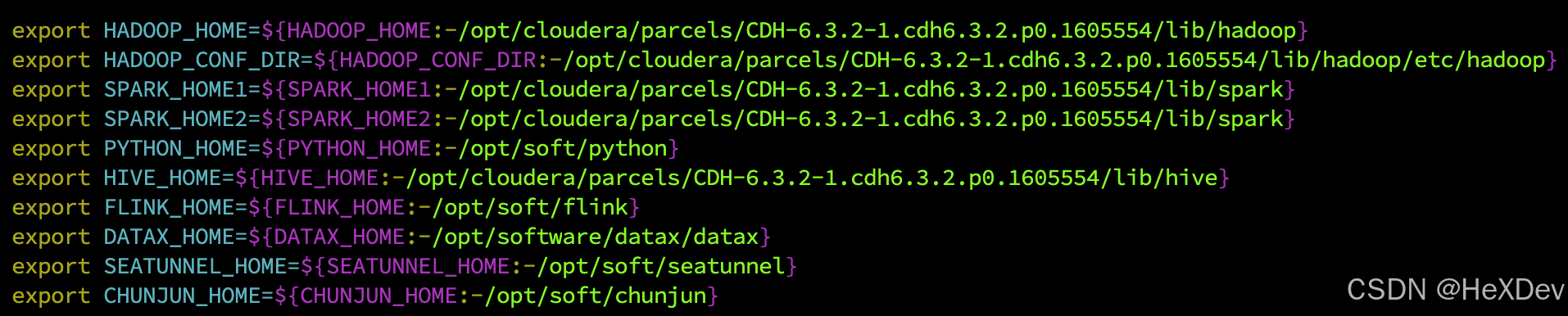
3.hadoop相关配置:
因为我们的hadoop的相关服务是使用cdh搭建的所以目录全都在/opt/cloudera/parcels/CDH/lib目录下,下面是具体的配置:
export HADOOP_HOME=${HADOOP_HOME:-/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/etc/hadoop}
export SPARK_HOME1=${SPARK_HOME1:-/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark}
export SPARK_HOME2=${SPARK_HOME2:-/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark}
export PYTHON_HOME=${PYTHON_HOME:-/opt/soft/python}
export HIVE_HOME=${HIVE_HOME:-/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive}
export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
export DATAX_HOME=${DATAX_HOME:-/opt/software/datax/datax}
export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/opt/soft/seatunnel}
export CHUNJUN_HOME=${CHUNJUN_HOME:-/opt/soft/chunjun}
4.3 配置common.properties
修改 api-server/conf/ 和 worker-server/conf/ ⽬录下的这个⽂件,该⽂件主要⽤来配置资源上传相关参数,⽐如将海豚的资源上传到 hdfs 等,文件内容如下:
# user data local directory path, please make sure the directory exists and have read write permissions
data.basedir.path=/tmp/dolphinscheduler# resource view suffixs
#resource.view.suffixs=txt,log,sh,bat,conf,cfg,py,java,sql,xml,hql,properties,json,yml,yaml,ini,js# resource storage type: HDFS, S3, OSS, NONE
resource.storage.type=HDFS
# resource store on HDFS/S3 path, resource file will store to this base path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.storage.upload.base.path=/dolphinscheduler# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id=minioadmin
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key=minioadmin123
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region=cn-north-1
# The name of the bucket. You need to create them by yourself. Otherwise, the system cannot start. All buckets in Amazon S3 share a single namespace; ensure the bucket is given a unique name.
resource.aws.s3.bucket.name=dolphinscheduler
# You need to set this parameter when private cloud s3. If S3 uses public cloud, you only need to set resource.aws.region or set to the endpoint of a public cloud such as S3.cn-north-1.amazonaws.com.cn
resource.aws.s3.endpoint=http://192.168.1.39:10020# alibaba cloud access key id, required if you set resource.storage.type=OSS
resource.alibaba.cloud.access.key.id=<your-access-key-id>
# alibaba cloud access key secret, required if you set resource.storage.type=OSS
resource.alibaba.cloud.access.key.secret=<your-access-key-secret>
# alibaba cloud region, required if you set resource.storage.type=OSS
resource.alibaba.cloud.region=cn-hangzhou
# oss bucket name, required if you set resource.storage.type=OSS
resource.alibaba.cloud.oss.bucket.name=dolphinscheduler
# oss bucket endpoint, required if you set resource.storage.type=OSS
resource.alibaba.cloud.oss.endpoint=https://oss-cn-hangzhou.aliyuncs.com# if resource.storage.type=HDFS, the user must have the permission to create directories under the HDFS root path
resource.hdfs.root.user=hdfs
# if resource.storage.type=S3, the value like: s3a://dolphinscheduler; if resource.storage.type=HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir
resource.hdfs.fs.defaultFS=hdfs://cm:8020# whether to startup kerberos
hadoop.security.authentication.startup.state=false# java.security.krb5.conf path
java.security.krb5.conf.path=/opt/krb5.conf# login user from keytab username
login.user.keytab.username=hdfs-mycluster@ESZ.COM# login user from keytab path
login.user.keytab.path=/opt/hdfs.headless.keytab# kerberos expire time, the unit is hour
kerberos.expire.time=2# resourcemanager port, the default value is 8088 if not specified
resource.manager.httpaddress.port=8088
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
yarn.application.status.address=http://cm:%s/ws/v1/cluster/apps/%s
# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000)
yarn.job.history.status.address=http://cm:19888/ws/v1/history/mapreduce/jobs/%s# datasource encryption enable
datasource.encryption.enable=false# datasource encryption salt
datasource.encryption.salt=!@#$%^&*# data quality option
data-quality.jar.name=dolphinscheduler-data-quality-dev-SNAPSHOT.jar#data-quality.error.output.path=/tmp/data-quality-error-data# Network IP gets priority, default inner outer# Whether hive SQL is executed in the same session
support.hive.oneSession=false# use sudo or not, if set true, executing user is tenant user and deploy user needs sudo permissions; if set false, executing user is the deploy user and doesn't need sudo permissions
sudo.enable=true
setTaskDirToTenant.enable=false# network interface preferred like eth0, default: empty
#dolphin.scheduler.network.interface.preferred=# network IP gets priority, default: inner outer
#dolphin.scheduler.network.priority.strategy=default# system env path
#dolphinscheduler.env.path=dolphinscheduler_env.sh# development state
development.state=false# rpc port
alert.rpc.port=50052# set path of conda.sh
conda.path=/opt/anaconda3/etc/profile.d/conda.sh# Task resource limit state
task.resource.limit.state=false# mlflow task plugin preset repository
ml.mlflow.preset_repository=https://github.com/apache/dolphinscheduler-mlflow
# mlflow task plugin preset repository version
ml.mlflow.preset_repository_version="main"
api-server修改成功之后可以直接将它的文件复制到worker-server中,因为他们的内容都是一样的
使用命令:
cp ./api-server/conf/common.properties ./worker-server/conf/
4.4 配置mysql
1.初始化DolphinScheduler数据库
由于数据库选择的是MySQL,在初始化前,需要将mysql(8.x)驱动分别放到./api-server/libs、./alert-server/libs、./master-server/libs、./worker-server/libs、./tools/libs、./standalone-server/libs、`` 目录下
cd /home/dolphin/apache-dolphinscheduler-3.1.9-bin;
wget -O /home/dolphin/apache-dolphinscheduler-3.1.9-bin/mysql-connector-j-8.0.33.tar.gz \
https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.33.tar.gz \
&& tar -zxvf mysql-connector-j-8.0.33.tar.gz
cp ./mysql-connector-j-8.0.33/mysql-connector-j-8.0.33.jar ./api-server/libs/
cp ./mysql-connector-j-8.0.33/mysql-connector-j-8.0.33.jar ./alert-server/libs/
cp ./mysql-connector-j-8.0.33/mysql-connector-j-8.0.33.jar ./master-server/libs/
cp ./mysql-connector-j-8.0.33/mysql-connector-j-8.0.33.jar ./standalone-server/libs/
cp ./mysql-connector-j-8.0.33/mysql-connector-j-8.0.33.jar ./worker-server/libs/
cp ./mysql-connector-j-8.0.33/mysql-connector-j-8.0.33.jar ./tools/libs/
2.使用root用户登录,执行如下SQL语句创建DS的数据库
由于cdh安装的mysql是5.7版本所以我们需要更新,mysql客户端
yum install -y https://dev.mysql.com/get/mysql80-community-release-el7-11.noarch.rpm \
&& yum install -y mysql-community-client
mysql -h mysql -uroot -p123456Aa.
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE USER IF NOT EXISTS 'dolphins'@'%' IDENTIFIED BY '123456Aa.';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphins'@'%';ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456Aa.';
flush privileges;
最后执行
bash tools/bin/upgrade-schema.sh
执行结果大概就是这样
4.5 更换dolphinscheduler连接hive jar包
由于cdn6.3.2的hive版本是2.1.1,耳dolphinscheduler3.1.9自带的版本比较高会导致连不上hive的问题,所以这里需要降级处理
1.先上传至docker容器内
docker cp hive-common-2.1.1.jar cm.hadoop1:/opt
docker cp hive-jdbc-2.1.1.jar cm.hadoop1:/opt
docker cp hive-metastore-2.1.1.jar cm.hadoop1:/opt
docker cp hive-orc-2.1.1.jar cm.hadoop1:/opt
docker cp hive-serde-2.1.1.jar cm.hadoop1:/opt
docker cp hive-service-2.1.1.jar cm.hadoop1:/opt
docker cp hive-service-rpc-2.1.1.jar cm.hadoop1:/opt
docker cp hive-storage-api-2.1.1.jar cm.hadoop1:/opt
2.删除原有的jar包
cd /home/dolphin/dolphinscheduler3.1.9/rm -rf ./api-server/libs/hive-*
rm -rf ./alert-server/libs/hive-*
rm -rf ./worker-server/libs/hive-*
rm -rf ./tools/libs/hive-*
3.将上传至容器的jar复制到对应的服务中
cp /opt/hive-* ./api-server/libs/
cp /opt/hive-* ./alert-server/libs/
cp /opt/hive-* ./worker-server/libs/
cp /opt/hive-* ./tools/libs/
执行安装脚本
bash bin/install.sh
安装后会自动启动
浏览器访问
http:[IP]:12345/dolphinscheduler