大厂主力双塔模型实践与线上服务
在推荐系统中,召回阶段是整个流程的关键环节之一,其目标是从海量的物品中快速筛选出用户可能感兴趣的候选集。本文将详细解析该方案的训练方式、正负样本选择策略、线上服务流程以及模型更新机制。
1. 双塔模型训练方式
双塔模型的核心思想是将用户和物品分别通过两个独立的神经网络(用户塔和物品塔)映射到同一个向量空间,通过计算用户向量和物品向量的余弦相似度来预估用户对物品的兴趣。模型的训练方式主要有以下三种:
1.1 Pointwise 训练
Pointwise 训练将召回任务视为一个二元分类问题。对于正样本,模型的目标是使用户向量和物品向量的余弦相似度尽可能接近 1;对于负样本,则希望余弦相似度接近 -1。在实际操作中,通常控制正负样本的比例为 1:2 或 1:3,这是业内总结出的经验法则。
-
目标函数:
L=−1N∑i=1N[yilog(σ(si))+(1−yi)log(1−σ(si))]\mathcal{L} = -\frac{1}{N} \sum_{i=1}^N \big[ y_i \log(\sigma(s_i)) + (1-y_i)\log(1-\sigma(s_i)) \big] L=−N1i=1∑N[yilog(σ(si))+(1−yi)log(1−σ(si))]
其中 si=sim(ui,vi)s_i = \text{sim}(u_i,v_i)si=sim(ui,vi), σ\sigmaσ为sigmoid函数 -
样本比例:
- 正样本:用户点击物品(y=1y=1y=1)
- 负样本:没有被召回的、召回但是被粗排精排淘汰的,(召回不能用曝光未点击)(y=0y=0y=0)
- 经验比例1:2~1:3
1.2 Pairwise 训练
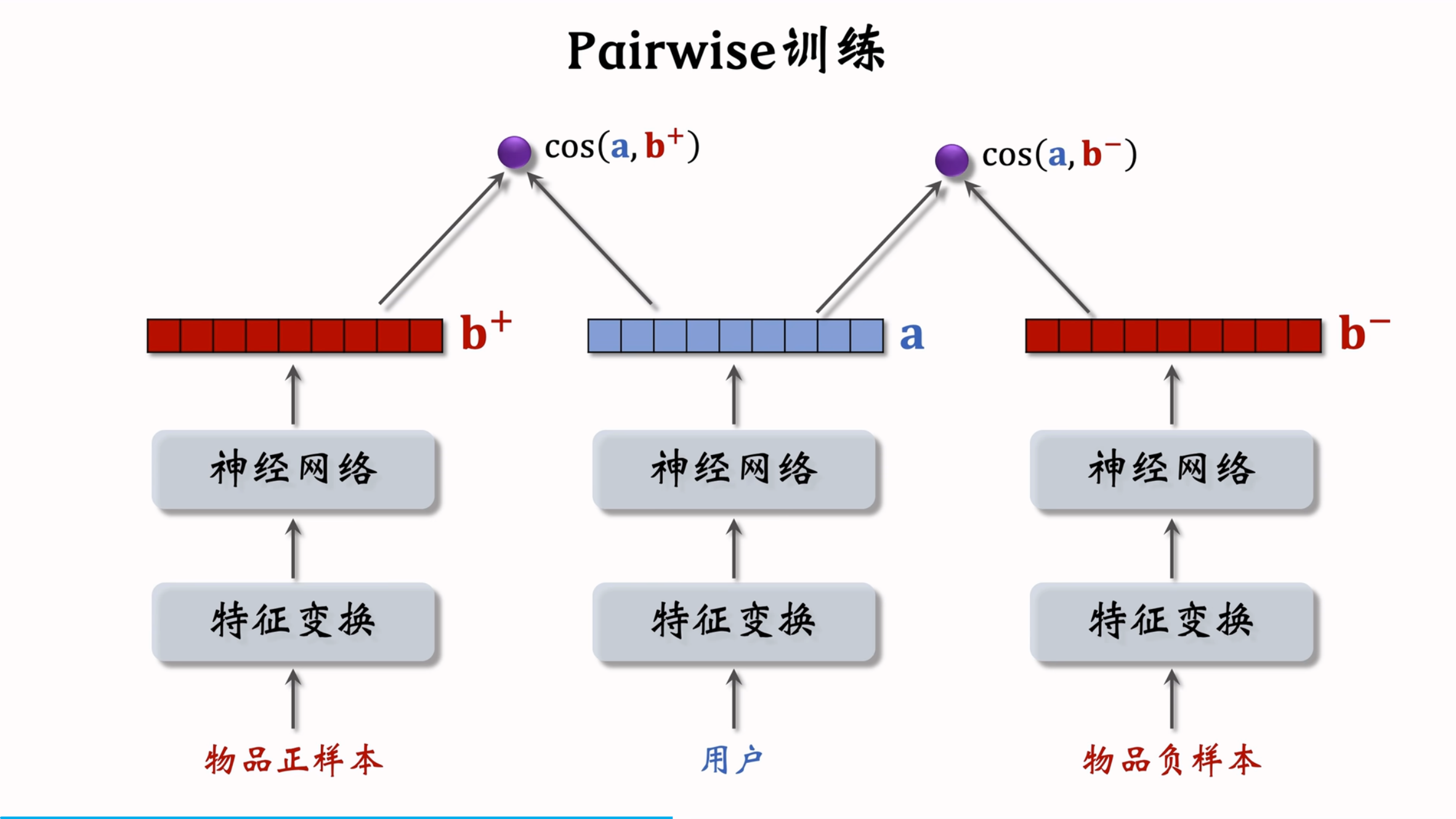
Pairwise 训练的核心是三元组(用户、正样本、负样本)。模型通过计算用户向量与正样本向量和负样本向量的余弦相似度,鼓励正样本的余弦相似度大于负样本的余弦相似度,并且差距越大越好。Trinplet hinge loss损失函数可以表示为:
L(a,b+,b−)=max(0,cos(a,b−)+m−cos(a,b+))L(a,b+,b-) = \max(0, \cos(a,b-) + m - \cos(a,b+)) L(a,b+,b−)=max(0,cos(a,b−)+m−cos(a,b+))
其中,m 是一个超参数,表示正负样本之间的最小差距。此外,还有其他损失函数,如 Triplet Logistic Loss:
L(a,b+,b−)=log(1+exp([σ⋅(cos(a,b−)−cos(a,b+))]))L(a,b+,b-) = \log(1 + \exp([\sigma \cdot (\cos(a,b-) - \cos(a,b+))])) L(a,b+,b−)=log(1+exp([σ⋅(cos(a,b−)−cos(a,b+))]))
该损失函数通过最小化 cos(a,b−)−cos(a,b+)\cos(a,b-) - \cos(a,b+)cos(a,b−)−cos(a,b+) 来优化模型,其中 σ\sigmaσ是一个大于 0 的超参数。
1.3 Listwise 训练
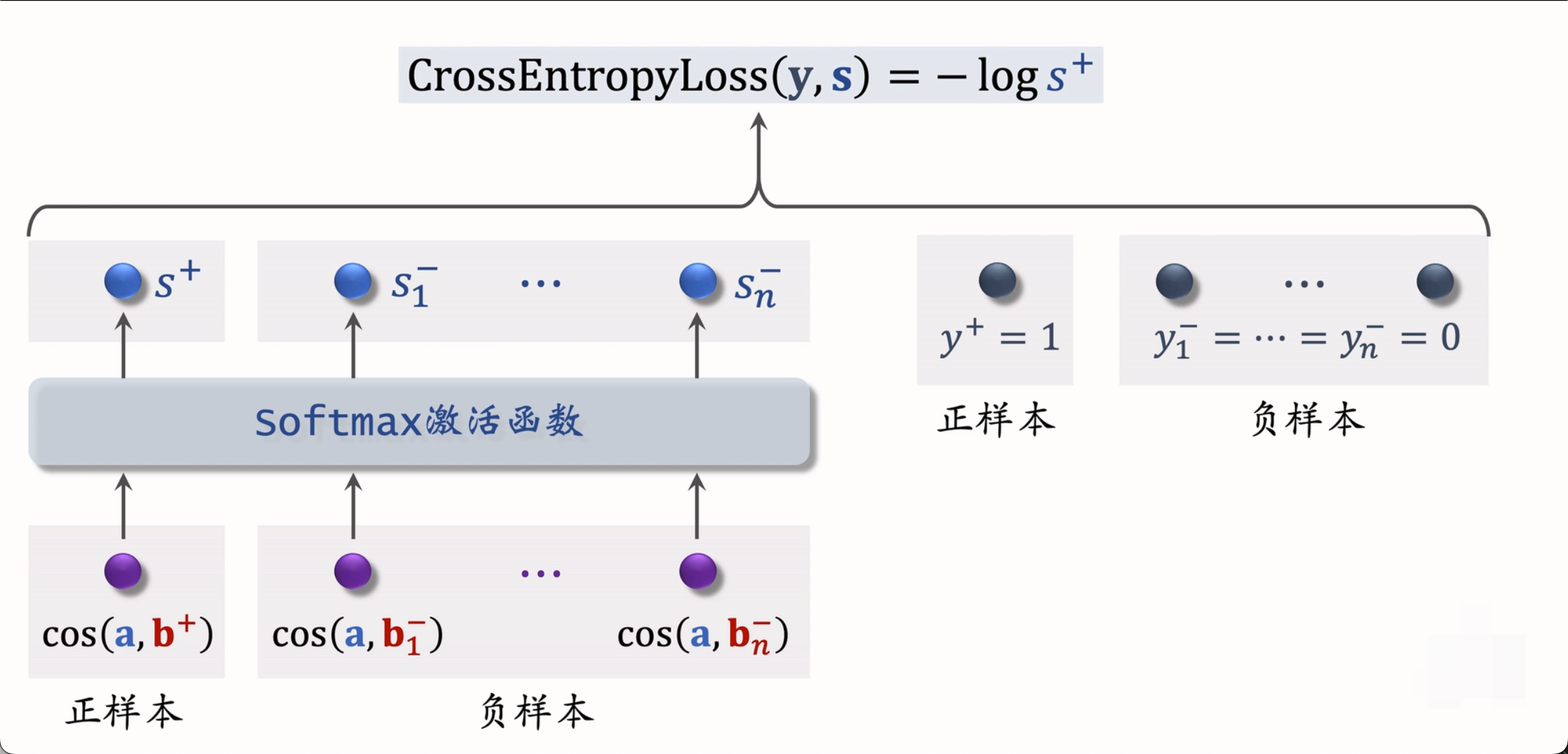
Listwise 训练每次使用一个用户、一个正样本和多个负样本。模型的目标是通过 softmax 函数将正样本的余弦相似度拉近 1,而将负样本的余弦相似度拉近 0。其损失函数可以表示为:
CrossEntropyLoss(y,s)=−logs+\text{CrossEntropyLoss}(y, s) = - \log s_+ CrossEntropyLoss(y,s)=−logs+
其中,( s ) 是 softmax 后的结果,s+s_+s+ 是正样本的 softmax 值。这种训练方式类似于多元分类,能够更好地处理多个负样本的情况。
2. 正负样本选择策略
2.1 正样本
正样本的选择相对简单,通常是用户点击过的物品。然而,由于少部分热门物品占据了大部分点击,这可能导致正样本过于集中在热门物品上。为了解决这一问题,可以采用过采样冷门物品或降采样热门物品的策略。
- 解决方案: 过采样冷门物品,或者降采样热门物品
- 过采样(up-sampling):一个样本出现多次
- 降采样(down-sampling):一些样本被抛弃,抛弃概率与点击概率成正比
2.2 负样本
负样本的选择更为复杂,主要有以下几种方式:
2.2.1 简单负样本
简单负样本通常是从全体物品中随机抽样得到的。然而,这种方法存在一个问题:热门物品更容易被抽样为负样本,从而导致模型对热门物品的打压过强。
-
未被召回的物品,大概率是用户不感兴趣的。
-
未召回物品 ≈ 全体物品
-
从全体样品中做抽样,作为负样本
-
均匀抽样 / 非均匀抽样
- 均匀采样:对冷门物品不公平
- 正样本大多都是热门物品
- 如果均匀抽样出产生出负样本,那么负样本大多数都是冷门物品。对冷门物品不公平,这样会导致热门物品更热,冷门物品更冷
- 非均匀抽采用:目的是打压热门物品
- 负样本抽样的概率与 热门程度(点击次数)正相关)
- 抽样概率 ∝(点击次数)0.75\propto (点击次数)^{0.75}∝(点击次数)0.75
- 均匀采样:对冷门物品不公平
2.2.2 Batch 内负样本
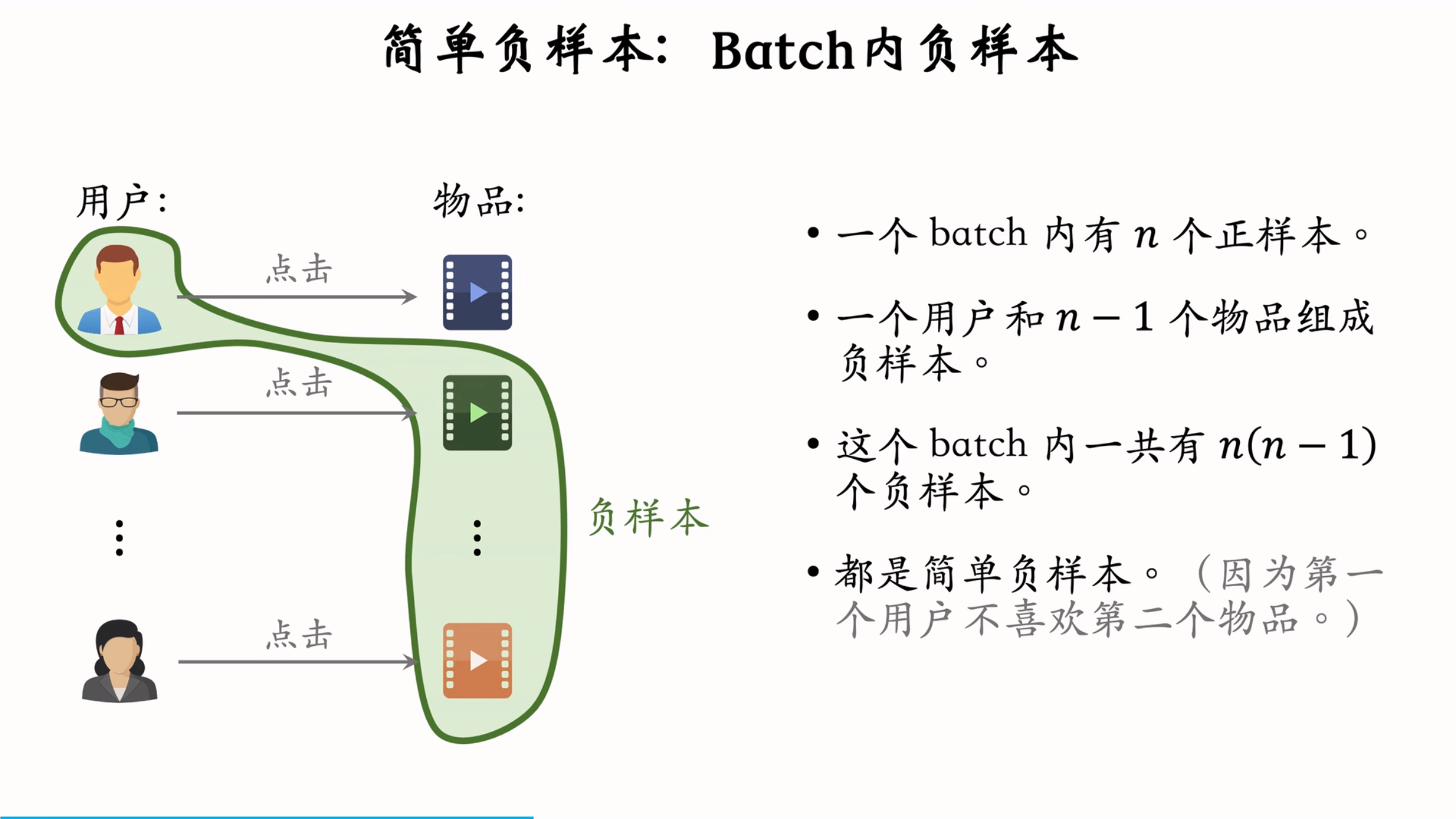
Batch 内负样本是指在一个 batch 中,将用户未点击的其他物品作为负样本。这种方法虽然简单,但也存在热门物品被过度打压的问题。
- 存在问题: 一个物品出现在batch内的概率 ∝\propto∝点击次数
- 但是为了打压热门商品,物品成为负样本的概率应该是,抽样概率应该是 ∝(点击次数)0.75\propto(点击次数)^{0.75}∝(点击次数)0.75 但这里是∝\propto∝点击次数
- 热门物品成为负样本的概率过大,模型对其打压太狠
为了解决这一问题,可以在训练时对负样本的余弦相似度进行调整,具体公式为:
cos(a,bi)k−logpicos(a,b_i) k- \log p_icos(a,bi)k−logpi
其中,pip_ipi 是物品 iii 的抽样概率,线上做召回的时候,不用−logpi-logpi−logpi,
2.2.3 困难负样本
困难负样本是指那些被召回但被排序淘汰的物品。这些物品与用户兴趣有一定的相关性,但不够强。使用困难负样本可以提高模型的区分能力。
- 困难负样本:
- 被粗排淘汰的物品(比较困难)、因为其多少跟用户兴趣有关,但是不大
- 精排分数靠后的物品(非常困难)。 说明物品比较符合用户兴趣,但未必是最感兴趣
- 对正负样本做二元分类
- 全体物品(简单) 分类比较高,因为其明显跟用户兴趣不相关
- 被粗排淘汰的物品(比较困难)容易分错。
- 精排分数靠后的物品(非常困难)更容易分错。
2.3 训练数据组成
在实际应用中,通常将简单负样本和困难负样本混合使用。例如,50% 的负样本来自全体物品,另外 50% 来自被排序淘汰的物品。这种混合方式可以平衡模型对热门物品和冷门物品的处理能力。
2.4 常见问题
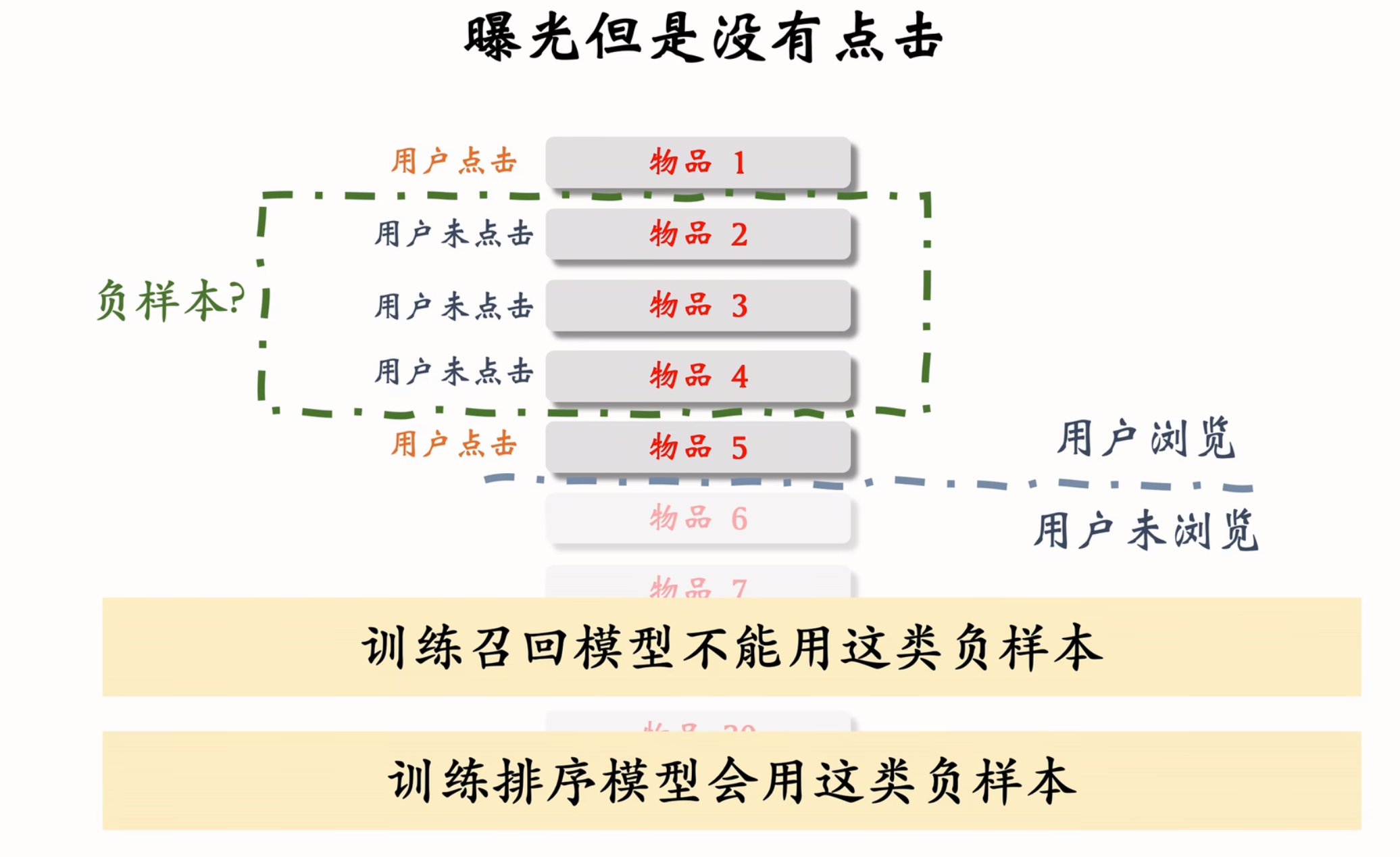
曝光但是没有点击,不能用作于 召回,这是给后面排序用的
召回的目标:快速找到用户可能感兴趣的物品,是区分不感兴趣的和比较感兴趣的,而排序才是区分比较感兴趣和非常感兴趣
-
全体物品(easy):绝大多数物品用户都根本不感兴趣
-
被排序淘汰物品(hard: 用户可能感兴趣,但是不够感兴趣
-
有曝光未点击(没用): 用户感兴趣,可能碰巧没有点击 (只要用了这种样本,召回效果肯定会非常差,这些物品已经是非常符合用户的兴趣,但是推送给用户几十条,用户不可能条条都点击,但是不代表用户不感兴趣,可能是有其他跟感兴趣,或者碰巧不点击,这种数据甚至可以拿来做正样本,如果拿来做负样本,肯定是会有问题的)
-
这是工业界的共识,是反复试验的结论。
总结
- 正样本,曝光而且有点击
- 简单负样本:
- 全体物品
- batch内负样本
- 困难负样本:被召回,但是被排序淘汰。
- 错误: 不能使用曝光、未点击的物品做召回的负样本
3. 线上服务与模型更新
3.1 线上召回
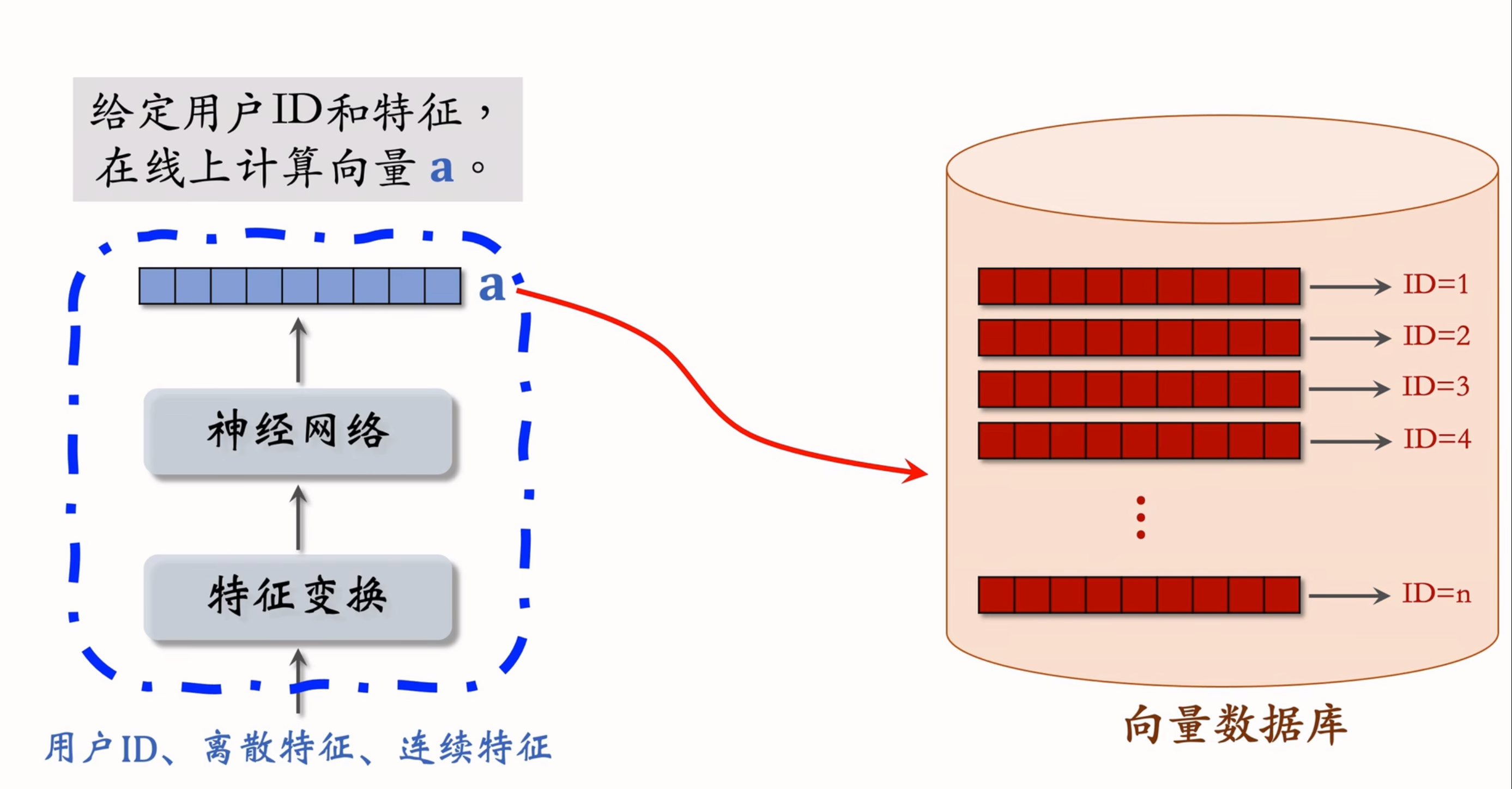
线上召回阶段,模型的主要任务是快速找到用户最感兴趣的物品。具体步骤如下:
- 离线存储:将物品特征向量和物品 ID 存储到向量数据库(如 Milvus、Faiss 等)。
- 实时计算用户向量:根据用户 ID 和画像,通过用户塔实时计算用户向量。
- 最近邻查找:将用户向量作为查询向量,调用向量数据库进行最近邻查找,返回余弦相似度最高的 K 个物品。
3.2 模型更新
模型更新是保持推荐系统性能的关键。主要有以下两种方式:
3.2.1 全量更新
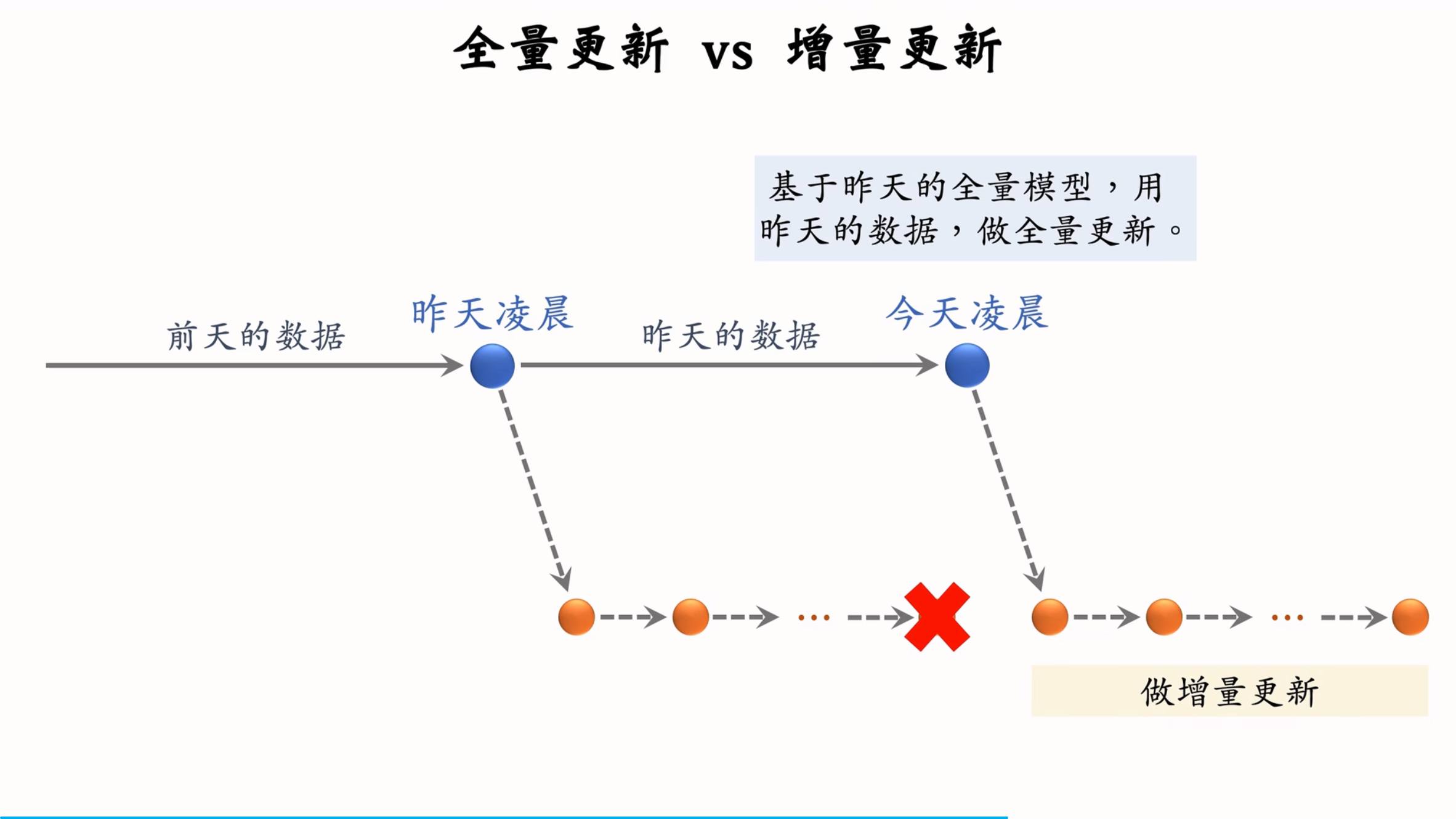
全量更新是指使用前一天的全部数据对模型进行训练。具体步骤如下:
- 数据准备:使用前一天的全部数据。
- 模型训练:random shuffle 一天的数据,通常训练 1 个 epoch。
- 发布新模型:发布新的用户塔神经网络和物品向量。
全量更新的优点是能够充分利用全天的数据,减少偏差。
3.2.2 增量更新
增量更新是指使用实时数据对模型进行更新。具体步骤如下:
- 数据收集:实时收集线上数据,进行流式处理。
- 模型更新:对模型进行在线学习,通常只更新 ID Embedding 参数。
- 发布新参数:发布最新的用户 ID Embedding 参数。
增量更新的优点是能够实时捕捉用户的兴趣变化。
3.3 全量更新与增量更新的结合
在实际应用中,通常将全量更新和增量更新相结合。全量更新用于处理全天数据,减少偏差;增量更新用于实时捕捉用户兴趣变化。这种结合方式能够充分发挥两者的优点,提高推荐系统的性能。
4. 总结
- 用户塔和物品塔分别输出用户向量和物品向量,通过余弦相似度预估用户兴趣。
- 训练方式包括 Pointwise、Pairwise 和 Listwise,各有优缺点。
- 正样本为用户点击的物品,负样本包括全体物品、被排序淘汰的物品等。
- 线上召回通过向量数据库进行最近邻查找,快速返回用户最感兴趣的物品。
- 模型更新采用全量更新和增量更新相结合的方式,既保证了数据的全面性,又能够实时捕捉用户兴趣变化。
通过这些技术和策略的综合应用,推荐系统能够在海量数据中快速、准确地召回用户感兴趣的物品,为用户提供个性化的推荐服务。
Reference
- Jui-Ting Huang et al. Embedding-based Retrieval in Facebook Search. In KDD, 2020.
- Xinyang Yi et al. Sampling-Bias-Corrected Neural Modeling fot Large Corpus Item Recommendations. In RecSys, 2019
- Shusen Wang. 推荐系统课程. Bilibili, 2022