华为昇腾NPU卡 文生视频[T2V]大模型WAN2.1模型推理使用
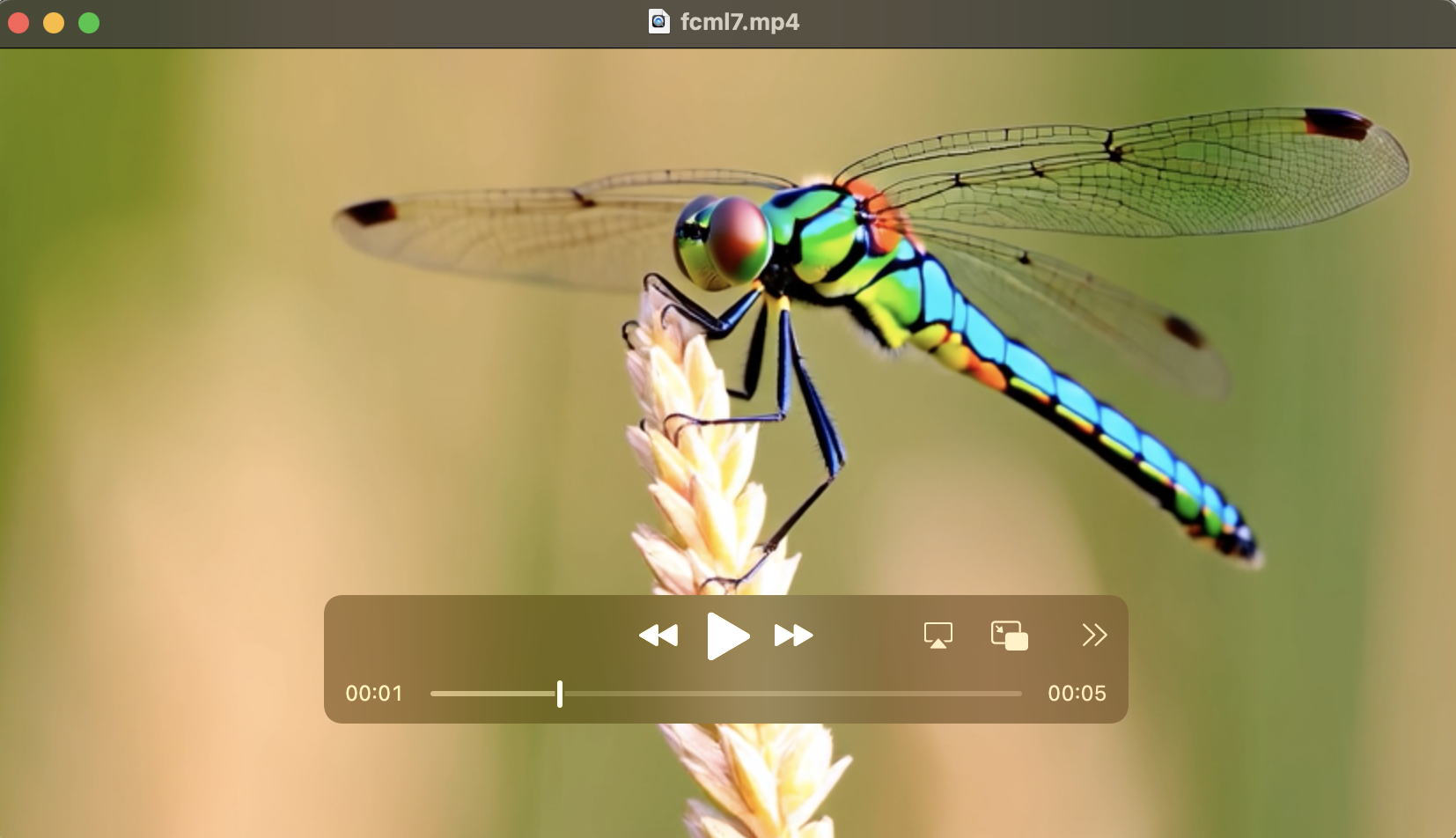
先看效果:
output_video
output_video是之前使用910B系列 NPU,Wan2.1-T2V-1.3B模型生成的,效果没有我之前用的Wan2.1-T2V-14B生成的质量好。(参考链接:https://www.mindspore.cn/news/detail?id=3632)
(最新的是Wan2.2-TI2V-5B/T2V-A14B/I2V-A14B: 可以从国内源魔搭下载:https://modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B/summary?version=bf16)
下面详细说下文生视频的大模型详细部署过程。
(硬件、软件配置和上次文生图片[T2I]及文生语音[T2A]一样。
华为昇腾NPU卡 文生图[T2I]大模型stable_diffusion_v1_5模型推理使用)
及(华为昇腾NPU卡 文生音频[T2A]大模型suno/bark模型推理使用)
环境:
1.硬件配置
申请华为云AI Notebook。
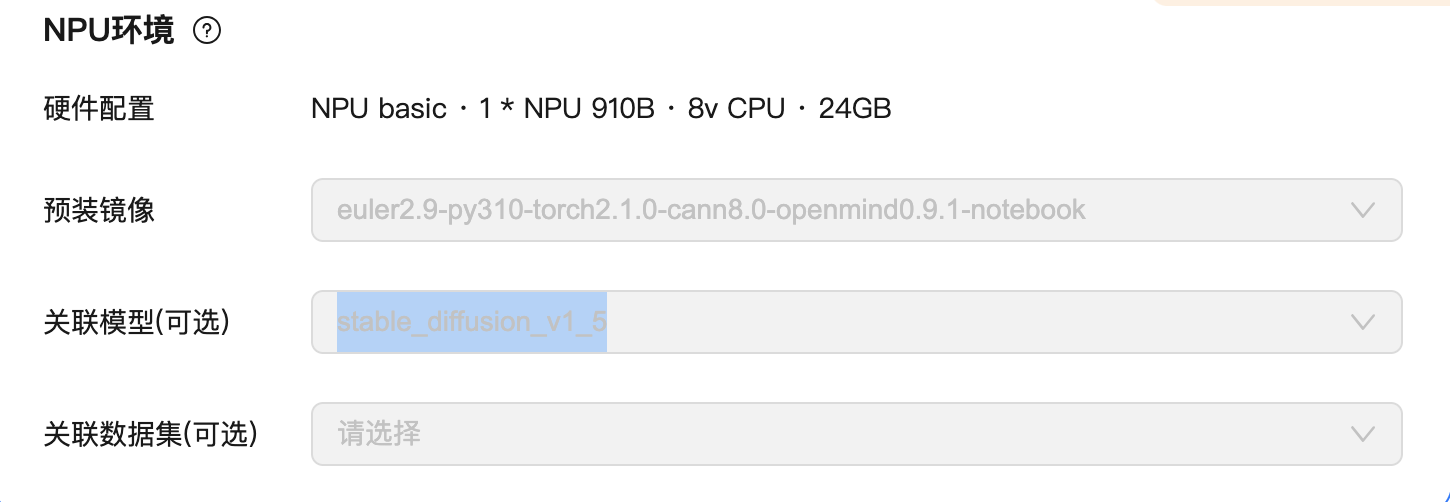
NPU basic · 1 * NPU 910B · 8v CPU · 24GB
2.软件:
预装镜像:euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook
openmind版本太旧,可以升级一下。
1. clone openmind源码:
git clone https://gitee.com/ascend/openmind.git2. 安装openmind:
进入到openmind代码仓根目录,执行
pip install .[pt] -i https://mirrors.aliyun.com/pypi/simple/
openmind安装完成后,需要配置一个环境变量,才能使用openmind-cli相关命令,在openmind安装完成后可以看到相关提示WARNING: The script shtab is installed in '/home/openmind/.local/bin' which is not on PATH.
vi编辑~/.bashrc文件,在文件结尾添加如下内容:
export PATH=/home/openmind/.local/bin:$PATH
然后 执行source ~/.bashrc
jupyter lab中新建一个终端
3.操作步骤:
注意:软件镜像加载完后,里面就包含了所需的基本python包,如果是本地安装,参考上面说的文生图、文生音频的文章。
3.1 下载模型到model目录下,我们采用从本地加载模型方式推理。
在下载前,请先通过如下命令安装ModelScope(https://www.modelscope.cn/models/mapjack/bark/files)
pip install modelscope
采用命令行下载完整模型库
modelscope download --model Wan-AI/Wan2.1-T2V-1.3B --local_dir /{yourmodelpath}/model/Wan2.1-T2V-1.3B
大概40GB的文件,提前准备好存储空间。–local_dir 指定下载存储路径,需要把路径改为自己的。文件已经在Jupyter的notebook下,这样方便显示。
3.2 执行模型推理
最好使用conda建立虚拟环境,不知道怎么建立的,搜索我之前的文章。输入python后,执行下列代码,如果整体报错,可以一行一行的运行,方便修改错误。
创建好输出路径文件/yourpath/output,yourpath替换成自己的路径。
mkdir -p {/yourpath}/output
视频生成的脚本已经集成在wan2.x里了,需要下载代码:(根据自己的显卡类型选择0/1)
-------分支线----------------------------开始
--------- 0.NPU
没有科学上网的,可以去国内源下载。
git clone https://github.com/mindspore-lab/mindone
cd mindone/examples/wan2_1
安装依赖项:
pip install -r requirements.txt
---------1.GPU
从https://github.com/Wan-Video/
本地我们使用wan2.1,所以执行下列代码。
克隆仓库:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
安装依赖项:
# Ensure torch >= 2.4.0
pip install -r requirements.txt
-------合并线----------------------------
不同类型的卡都准备好了,我们开始执行模型推理。
python generate.py --task t2v-1.3B --size "480*832" --ckpt_dir /{yourmodelpath}/model/Wan2.1-T2V-1.3B --prompt "Lion running under snow in Samarkand" --save_file /{youroutputpath}/output/output_video.mp4
注意:替换自己的{yourmodelpath}、{youroutputpath}
等待7分钟左右,就会生成完成。
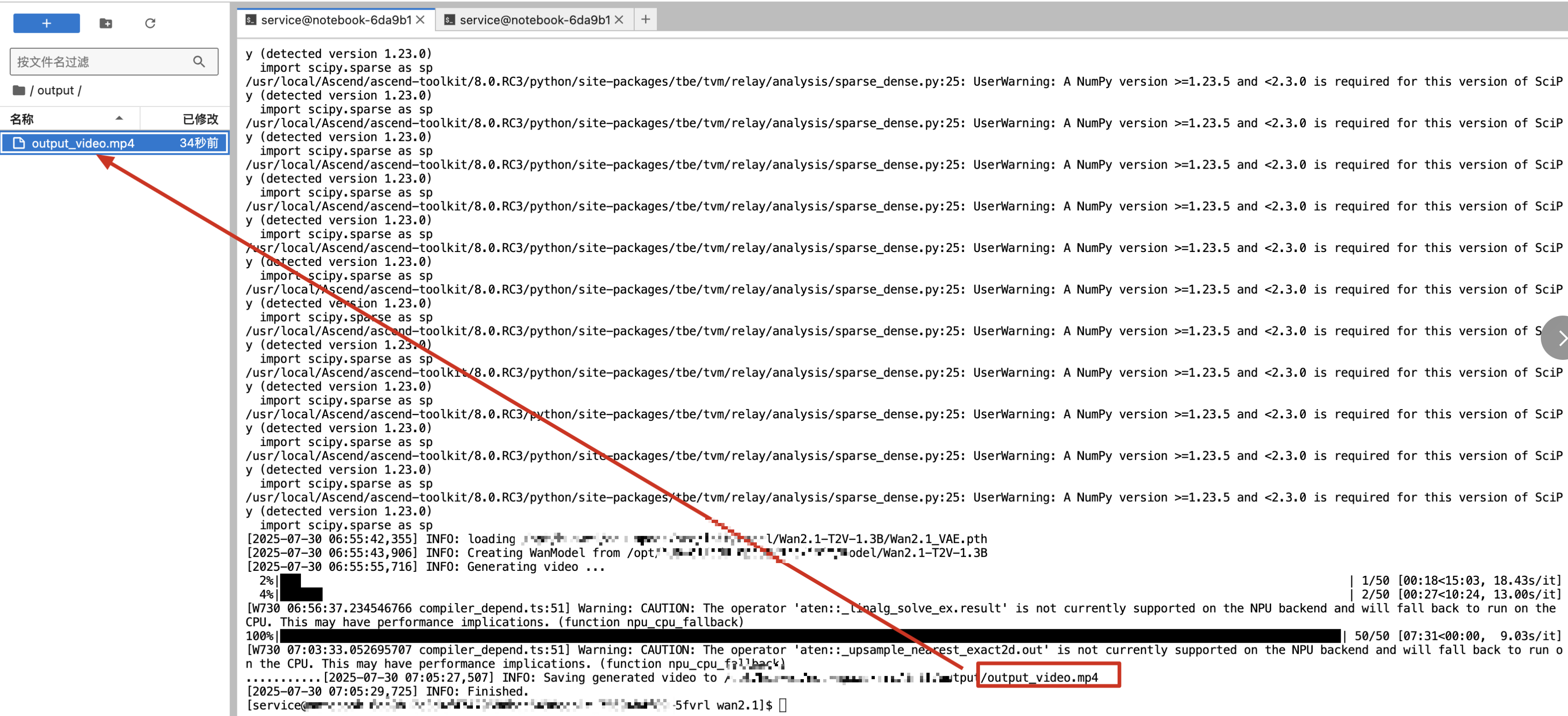
这时候在note book左侧的output文件夹下下载文件,浏览器播放mp4文件。
或者使用notebook播放文件。
from IPython.display import Video# 播放当前目录下的 output_video.mp4(若文件在其他路径,需替换为完整路径,如 './data/output_video.mp4')
Video("/{youroutputpath}/output/output_video.mp4", embed=True) # embed=True 确保视频嵌入 Notebook 中直接播放,自选
结束!
恭喜你学会了,
1.文生图片(T2I);
2.文生音频(T2A);
3.文生视频【T2V】(本文);