buuctf_crypto26-30
1.[AFCTF2018]Morse
显然题目一看就是一个摩斯密码,我们先解码,得到:61666374667B317327745F73305F333435797D,验证一下不是flag,我们猜测可能是base编码或者md5,但是一看不符合base32,base64,md5等等,但是却符合base16的所有要求,我们base16解码(也就是16进制转ascll编码(hex解码)),字符串HEX转换解出来是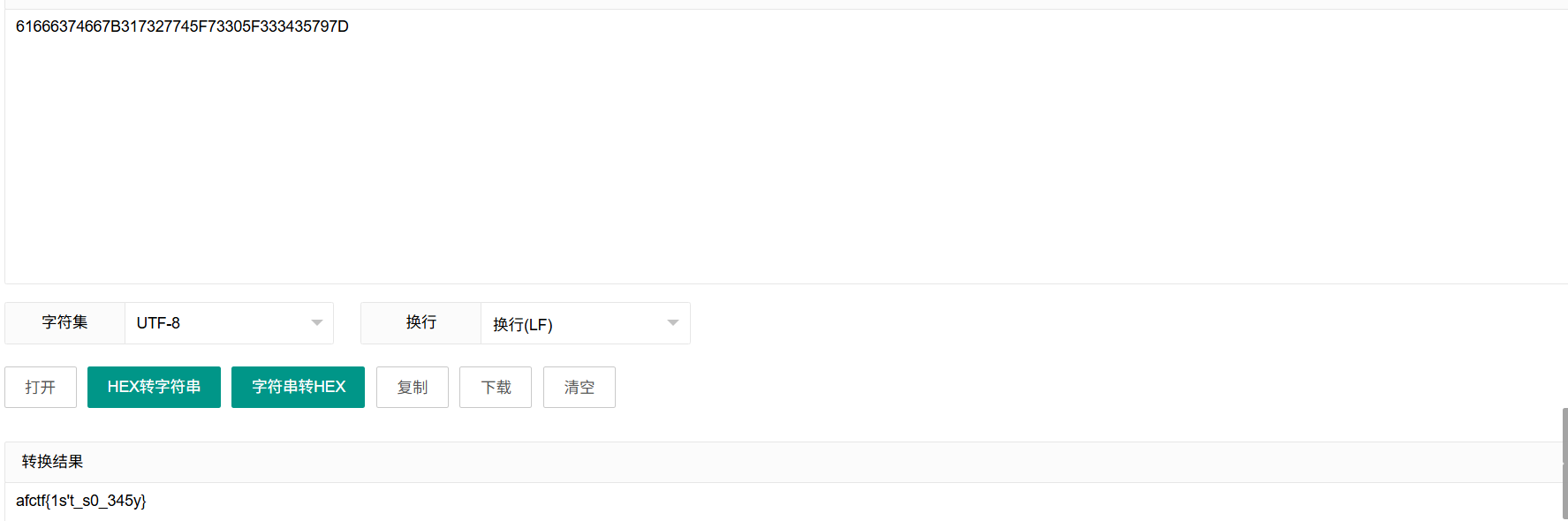
最后改一下前缀
flag{1s't_s0_345y}
2.RSA3
我们看题目,给了c1,c2,e1,e2,n,典型的共模攻击题目
在CTF题目中,就是同一明文,同一n,不同e,进行加密。
m,n相同;e,c不同,且e1和e2互质
(有不懂的可以去看我之前写的共模攻击脚本-CSDN博客)
套用解题代码得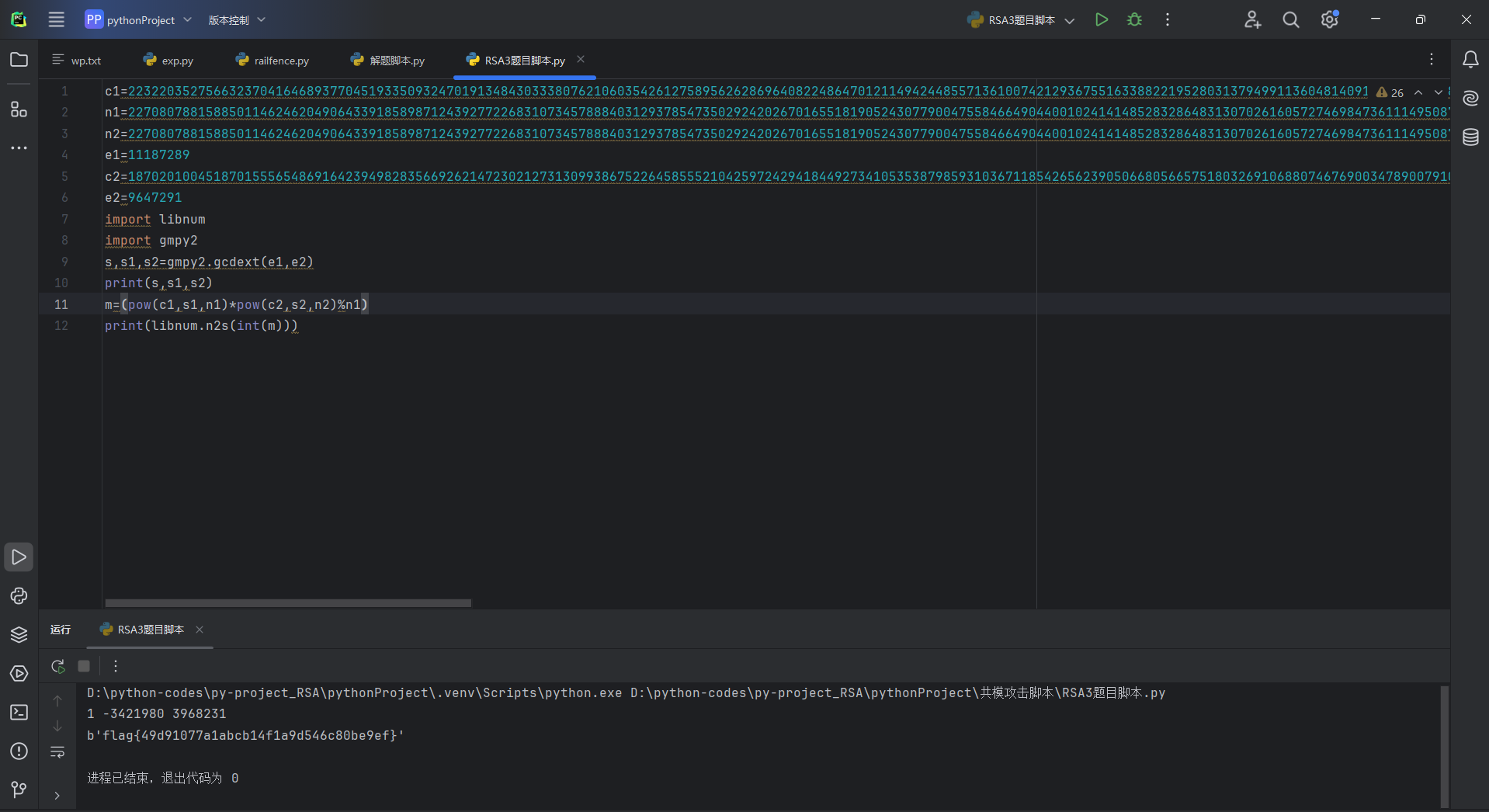
flag{49d91077a1abcb14f1a9d546c80be9ef}
3.RSA2
我们看本题给了e,n.,dp,c,一眼dp泄露类型的题目,都是利用dp得出结论
p=gcd(2^(dp*e)%n-2,n)
不懂可以去参考我之前的写的rsa_dp泄露-CSDN博客
弄懂之后直接套用脚本
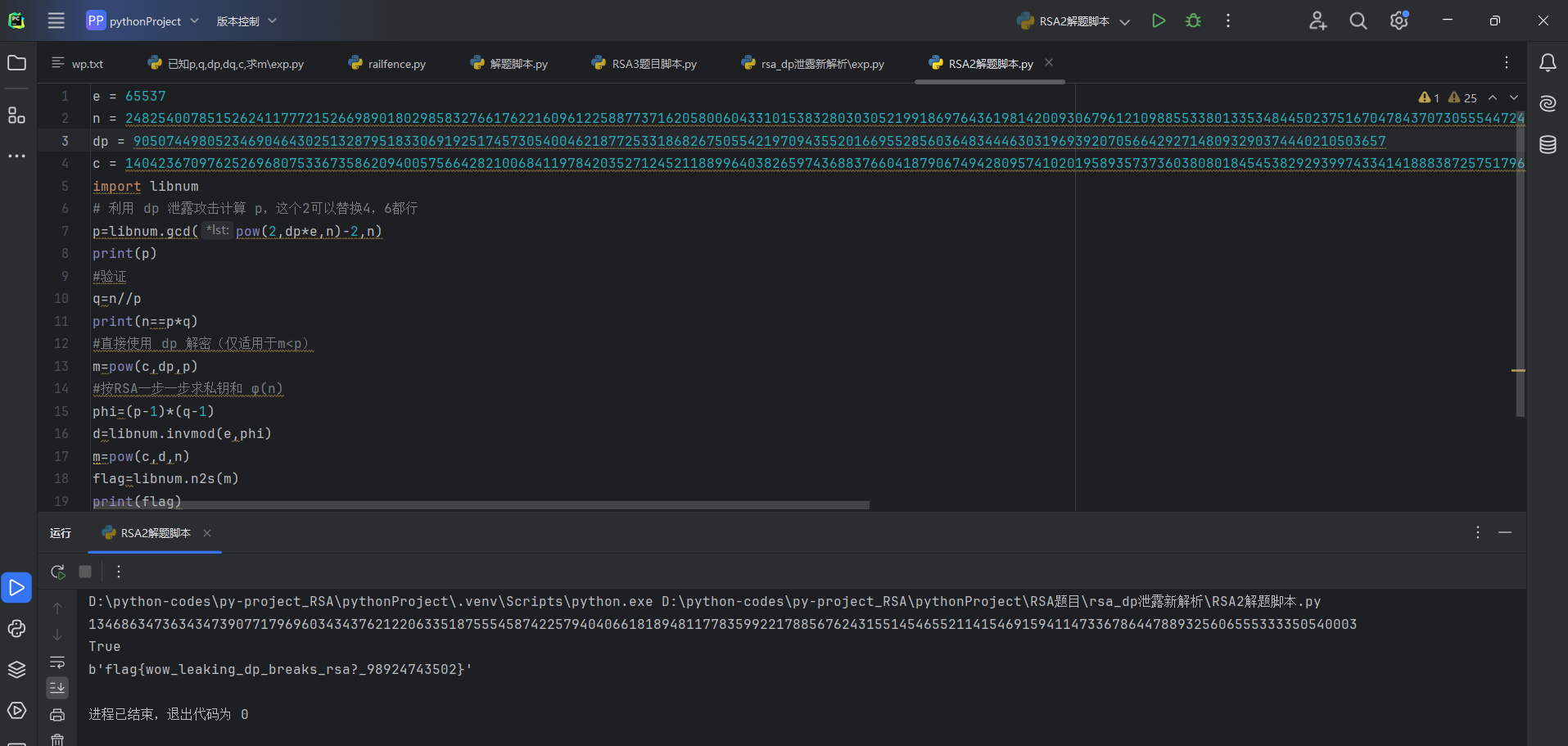
flag{wow_leaking_dp_breaks_rsa?_98924743502}
4.还原大师
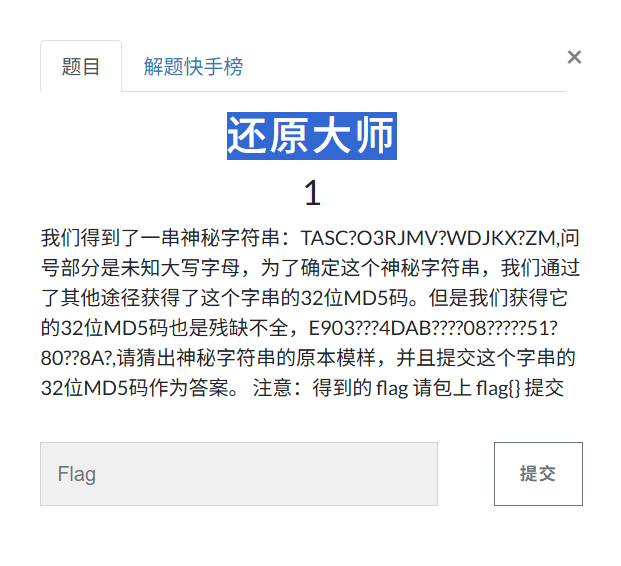
我们直接参考大佬的脚本:
import hashlib
import itertools# 给定的字符串模板和残缺的MD5码
template = "TASC?O3RJMV?WDJKX?ZM"
incomplete_md5 = "e903???4dab????08?????51?80??8a?"# 生成所有可能的大写字母组合
letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
possible_replacements = itertools.product(letters, repeat=template.count('?'))for replacement in possible_replacements:# 构造当前的字符串current_str = templatefor ch in replacement:current_str = current_str.replace('?', ch, 1)# 计算当前字符串的MD5哈希值current_md5 = hashlib.md5(current_str.encode()).hexdigest()# 检查当前MD5哈希值是否符合给定的残缺MD5码match = Truefor i in range(len(incomplete_md5)):if incomplete_md5[i] != '?' and incomplete_md5[i] != current_md5[i]:match = Falsebreak# 如果找到匹配的MD5码,打印结果并退出循环if match:print("找到匹配的字符串:", current_str)print("完整的MD5码:", current_md5)break
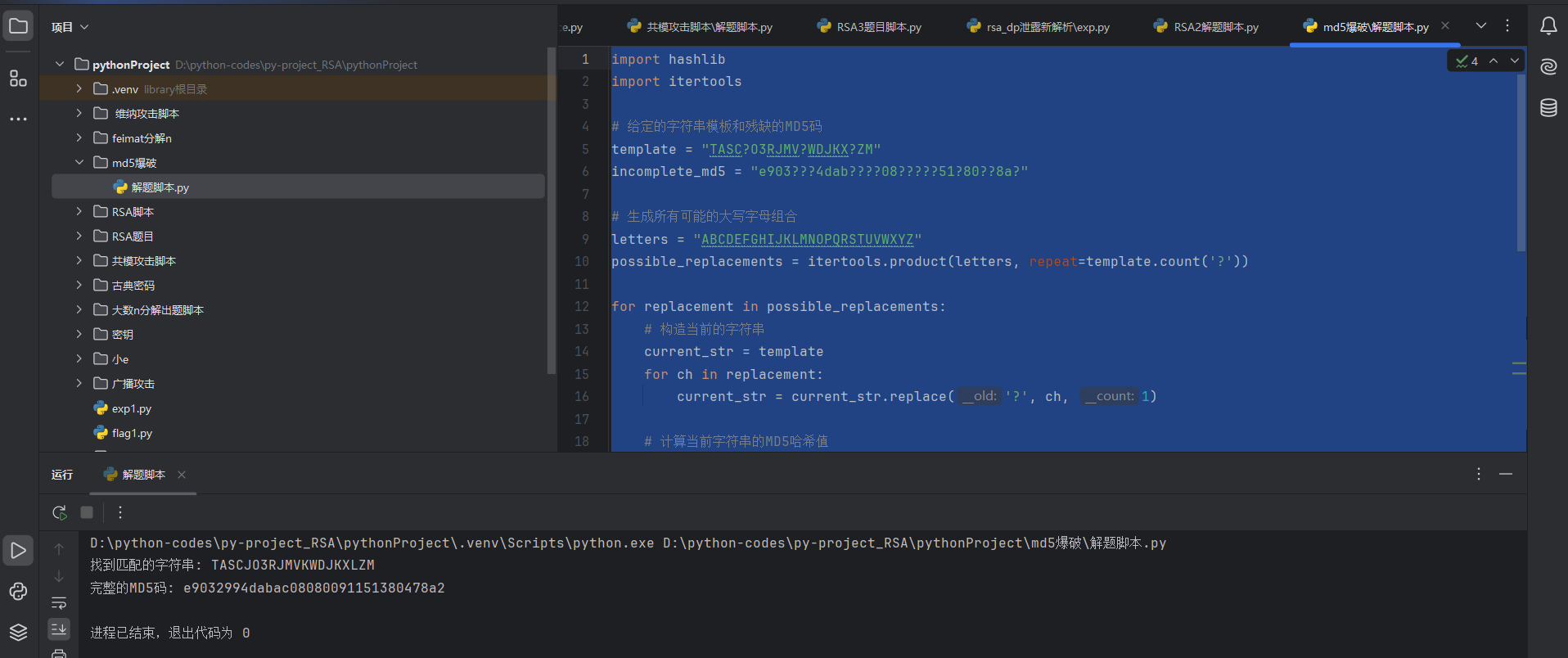
我们提交后发现还是不对,全部改成大写字母后在尝试发现成功
flag{E9032994DABAC08080091151380478A2}
5.异性相吸
题目文件给了两个,一个key,一个密文,我们看题目提示异性相吸,我们可以想象到二进制之间的异或,那么我们先将两个文件全部转为二进制
密文:
00000111 00011111 00000000 00000011 00001000 00000100 00010010 01010101 00000011 00010000 01010100 01011000 01001011 01011100 01011000 01001010 01010110 01010011 01000100 01010010 00000011 01000100 00000010 01011000 01000110 00000110 01010100 01000111 00000101 01010110 01000111 01010111 01000100 00010010 01011101 01001010 00010100 00011011
key:
01100001 01110011 01100001 01100100 01110011 01100001 01110011 01100100 01100001 01110011 01100100 01100001 01110011 01100100 01100001 01110011 01100100 01100001 01110011 01100100 01100001 01110011 01100100 01100001 01110011 01100100 01100001 01110011 01100100 01100001 01110011 01100100 01110001 01110111 01100101 01110011 01110001 01100110
我们发现转为二进制后位数都相同,更验证我之前的猜想,写脚本直接来:
# 给定的二进制密文和密钥
binary_cipher = "0000011100011111000000000000001100001000000001000001001001010101000000110001000001010100010110000100101101011100010110000100101001010110010100110100010001010010000000110100010000000010010110000100011000000110010101000100011100000101010101100100011101010111010001000001001001011101010010100001010000011011"
binary_key = "0110000101110011011000010110010001110011011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011000010111001101100100011100010111011101100101011100110111000101100110"# 确保密钥长度与密文相同
if len(binary_cipher) != len(binary_key):print("密文和密钥的长度不匹配!")
else:# 进行XOR操作xor_result = int(binary_cipher, 2) ^ int(binary_key, 2)# 将XOR结果转换为二进制字符串,去除前缀'0b'xor_binary_str = bin(xor_result)[2:].zfill(len(binary_cipher))# 将二进制字符串转换为字节串xor_bytes = int(xor_binary_str, 2).to_bytes(len(xor_binary_str) // 8, byteorder='big')# 将字节串解码为文本text = xor_bytes.decode('utf-8')print("解密后的文本:", text)
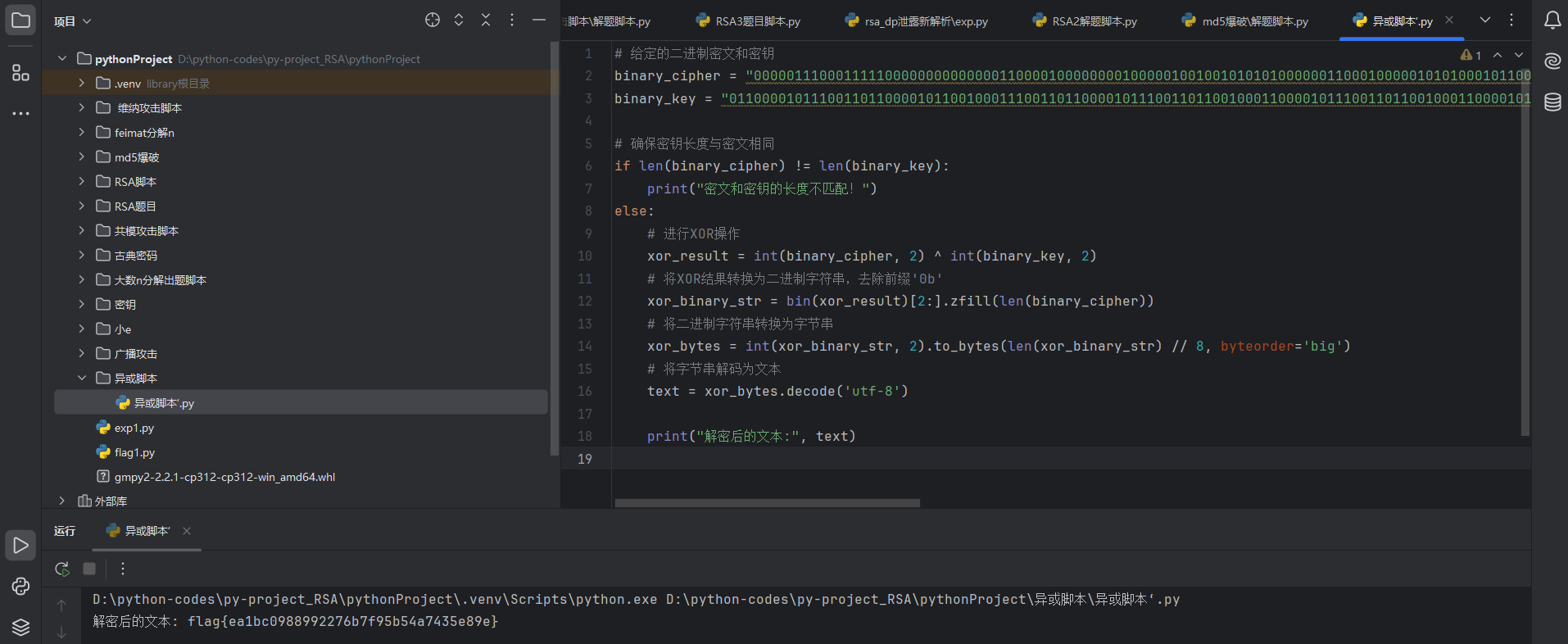
flag{ea1bc0988992276b7f95b54a7435e89e}