【Linux系统】Ext2文件系统 | 软硬链接
1. Ext2文件系统
1.1 宏观认识
在开始深入理解文件系统之前,我们需要先建立宏观层面的认知。所有的准备工作(包括硬件连接、分区划分等)都已经完成,接下来就是认识文件系统的关键环节了。文件系统就像是一个精密的仓库管理系统,它决定了我们如何在存储设备上高效地组织和存取数据。
当我们需要在硬盘上存储文件时,必须先将硬盘格式化为特定格式的文件系统,这个过程就像是在空地上建造一个结构化的仓库。不同的文件系统格式(如NTFS、FAT32、ext系列等)采用不同的组织方式和管理策略。在Linux系统中,最主流的是ext2系列的文件系统,这个家族包括:
- ext2:第二代扩展文件系统,发布于1993年
- ext3:在ext2基础上增加了日志功能
- ext4:进一步改进,支持更大的文件和分区
虽然ext3和ext4在ext2基础上增加了许多新特性(如日志记录、更大的文件支持等),但其核心架构设计理念保持一致。为了便于理解基础原理,我们选择以较早期的ext2作为演示对象,因为掌握了ext2的核心概念后,理解ext3/ext4的改进就相对容易了。
ext2文件系统采用了一种模块化的设计方法。它将整个分区划分成若干个大小相同的块组(Block Group),这个设计类似于将大仓库划分为多个标准化的储物间。每个块组都包含完整的元数据和数据存储结构,这样设计的好处是:
- 提高并行处理能力
- 减少磁头移动距离
- 便于故障隔离和修复
下图展示了ext2文件系统的典型布局:
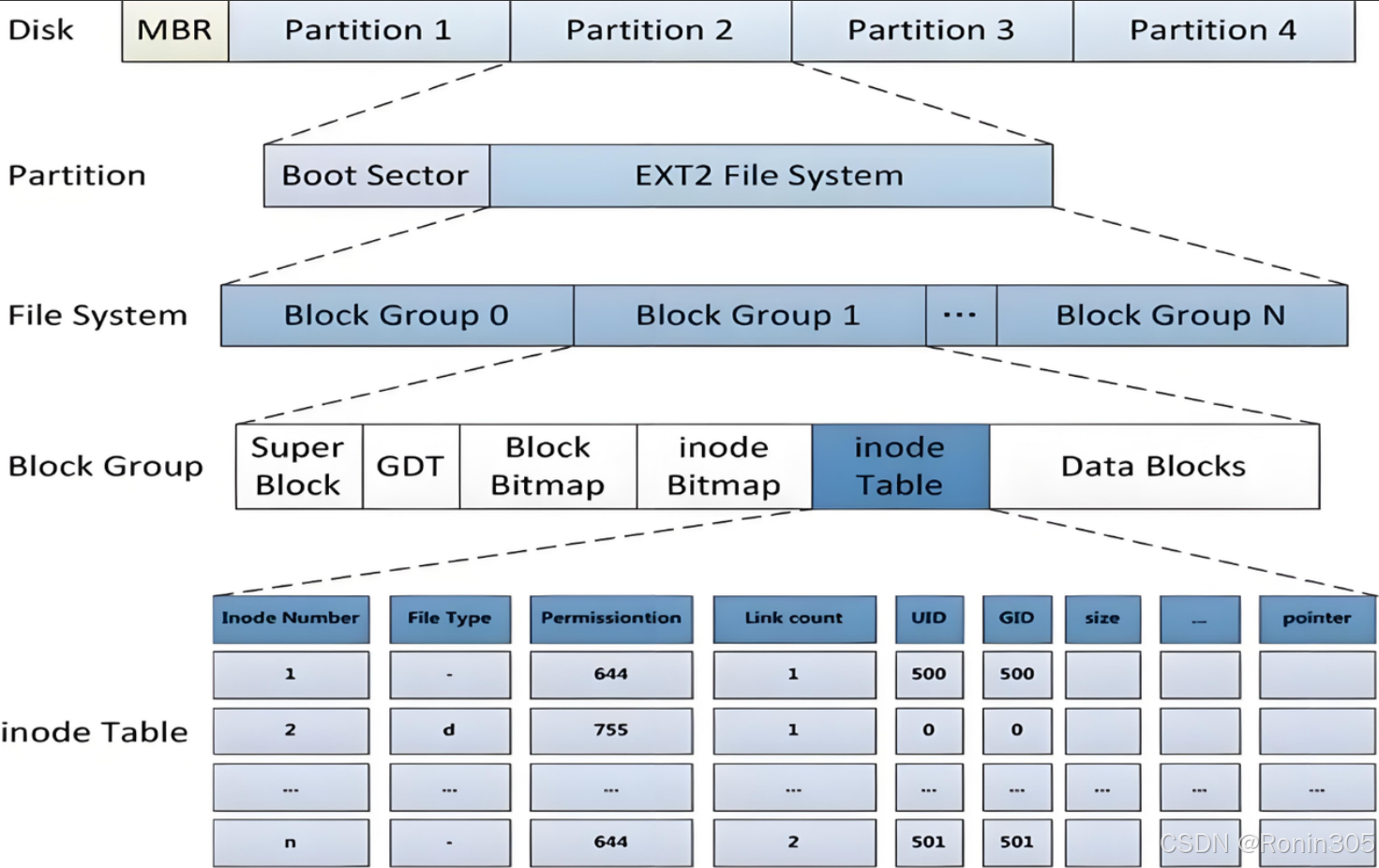
通过这种划分方式,我们只需要理解如何管理一个块组,就能推广到管理整个分区,进而管理整块磁盘上的所有文件。这种"分而治之"的思想是许多现代文件系统的共同特点。
上图中启动块(Boot Block/Sector)是遵循PC标准的一个固定区域,其大小为1KB(1024字节),这个标准由IBM PC兼容机体系结构所规定。该启动块位于存储设备的最开始位置(通常是LBA 0扇区),包含两个关键部分:
主引导记录(MBR,446字节):
- 存储基本的启动加载程序代码,这段代码负责加载操作系统的第一阶段引导程序
- 包含磁盘签名(Disk Signature),这是一个4字节的唯一标识符,用于区分不同磁盘
- 示例1:GRUB等引导加载器的第一阶段通常写在这里,其代码长度通常不超过446字节
- 示例2:Windows的NTLDR或bootmgr的初始加载代码也存储于此
- 示例3:一些特殊工具(如Parted Magic)会在此区域写入自定义的引导代码
分区表(64字节):
- 最多支持4个主分区记录,如果需要更多分区则需要使用扩展分区
- 每个分区记录16字节,包含以下信息:
- 起始柱面/磁头/扇区(CHS寻址)
- 结束柱面/磁头/扇区
- 分区类型标识(如0x83表示Linux分区,0x07表示NTFS)
- 分区起始LBA地址(4字节)
- 分区大小(4字节)
- 包含可引导标志(0x80表示活动分区),这个标志告诉BIOS从哪个分区启动
- 示例:在双系统环境中,通常会将Windows分区标记为活动分区
启动块的最后2字节固定为0x55AA的魔数(Magic Number),用于标识有效的启动扇区。这个魔数的检测是BIOS启动过程中的关键步骤,如果检测失败,BIOS通常会显示"Invalid boot disk"等错误信息。
这个区域对于任何文件系统(包括ext2)都是只读且受保护的,操作系统和文件系统驱动都无权修改此区域的内容。只有在以下特定情况下会修改此区域:
- 操作系统安装时写入引导程序
- 使用fdisk等分区工具修改分区表时
- 通过dd等底层工具直接操作磁盘时
在启动块之后,ext2文件系统才正式开始布局,通常从第2个扇区(LBA 1)开始。这种设计具有以下优势:
- 保持与PC体系结构的兼容性,确保BIOS能够正确识别和加载启动代码
- 为各个文件系统保留了标准化的起始区域,便于多系统共存
- 为磁盘管理工具提供了统一的处理标准
- 支持不同操作系统使用相同的磁盘布局规范
在现代系统中,虽然UEFI逐渐取代了传统的BIOS+MBR启动方式,但MBR分区表格式仍然被广泛支持,特别是在传统硬盘和兼容性要求高的场景中。
1.2 Block Group
ext2文件系统会根据分区的大小划分为数个Block Group(块组)。这种划分方式类似于政府将一个国家划分为多个行政区域进行管理,每个行政区域都有相似的组织结构和职能分工。
在ext2文件系统中,每个Block Group都有着相同的结构组成,这种设计具有以下优势:
- 提高数据局部性,减少磁头移动距离
- 便于实现并行操作
- 提供数据冗余备份机制
- 简化文件系统管理
块组内部结构
| 组件 | 作用 | 存储位置 | |
|---|---|---|---|
| Super Block | 记录文件系统全局信息(如块/ inode总量、大小等) | 块组0必须存在,其他组可冗余备份 | |
| Group Descriptor | 描述当前块组详情(如位图位置、空闲块数等) | 紧跟Super Block | |
| Block Bitmap | 标记数据块使用状态(1bit/块) | 由Group Descriptor指向 | |
| Inode Bitmap | 标记inode使用状态 | 同上 | |
| Inode Table | 存储inode结构体数组 | 连续多个块 | |
| Data Blocks | 存储实际文件内容 | 文件数据的最小单元(通常4KB) |
1.3 块组内部构成
每个Block Group由以下几个关键部分组成,形成一个完整的存储管理单元:
超级块(Super Block)
核心概念:
超级块是文件系统元数据(Metadata)中最关键的结构之一。它存储了描述整个文件系统全局属性的信息,相当于文件系统的“总控制台”或“目录册封面”。
关键特性:
- 位置:
为了容错,很多现代文件系统(如 ext3/ext4)会在文件系统的不同位置保存多个超级块的备份。如果主超级块损坏,可以用备份恢复。
通常位于文件系统所在分区或卷的开头(物理或逻辑块号 0 或 1,具体取决于文件系统类型)。
内容(包含哪些信息):
超级块存储的信息用于操作系统识别和管理该文件系统,主要包括:文件系统魔数: 一个唯一的标识符,用于确认该块设备上确实存在某种特定类型的文件系统(例如,
0xEF53表示 ext2/3/4)。文件系统状态: 标记文件系统是“干净”卸载的(Clean)还是“脏”的(Dirty,可能因崩溃导致未正确卸载)。挂载前检查状态是必要的。
块大小: 文件系统使用的块(Block)的大小(例如 1KB, 4KB)。
总块数: 文件系统包含的总数据块数量。
空闲块数: 当前可用的空闲块数量。
总 inode 数: 文件系统支持的 inode 总数(决定了最大文件数量)。
空闲 inode 数: 当前可用的空闲 inode 数量。
第一个 inode: 通常是根目录
/的 inode 号。这是访问文件系统目录树的起点。文件系统类型/版本: 具体类型(如 ext4, XFS, NTFS)和版本号。
挂载信息: 上次挂载时间、最后一次写入时间、挂载次数等。
块组信息(对于基于块组的文件系统如 ext*): 描述块组结构的关键参数。
卷名/标签: 文件系统的可选名称或标签。
校验和: 用于检测超级块本身是否损坏。
作用:
文件系统识别: 操作系统通过读取超级块的魔数和类型信息来判断分区上的文件系统类型。
挂载基础: 挂载文件系统时,内核必须首先读取超级块来获取管理该文件系统所需的所有关键参数(块大小、inode 信息、状态等)。
文件系统一致性检查和修复:
fsck等工具严重依赖超级块的信息(如块大小、总块数、inode 信息、状态标志)来检测和修复文件系统错误。备份超级块是恢复的关键。空间管理: 空闲块数和空闲 inode 数帮助操作系统快速判断是否有空间创建新文件或目录。
提供根起点: 通过第一个 inode(根 inode)找到文件系统的根目录,从而遍历整个目录树。
重要注意事项:
脆弱性: 超级块包含的信息极其关键。如果主超级块损坏且没有可用的有效备份,恢复整个文件系统将变得非常困难甚至不可能。
日志: 现代日志文件系统(如 ext3/ext4, XFS, NTFS)会将对超级块(以及其它关键元数据)的更改记录到日志中。这大大减少了因系统崩溃导致超级块不一致的风险,并加速了
fsck的恢复过程。不同文件系统: 不同文件系统(ext4, XFS, Btrfs, NTFS, APFS, ZFS)的超级块具体结构和包含的字段各不相同,但它们都服务于相同的核心目的:存储描述整个文件系统的全局信息。
/*
* Structure of the super block
*/
struct ext2_super_block {__le32 s_inodes_count; /* Inodes count */__le32 s_blocks_count; /* Blocks count */__le32 s_r_blocks_count; /* Reserved blocks count */__le32 s_free_blocks_count; /* Free blocks count */__le32 s_free_inodes_count; /* Free inodes count */__le32 s_first_data_block; /* First Data Block */__le32 s_log_block_size; /* Block size */__le32 s_log_frag_size; /* Fragment size */__le32 s_blocks_per_group; /* # Blocks per group */__le32 s_frags_per_group; /* # Fragments per group */__le32 s_inodes_per_group; /* # Inodes per group */__le32 s_mtime; /* Mount time */__le32 s_wtime; /* Write time */__le16 s_mnt_count; /* Mount count */__le16 s_max_mnt_count; /* Maximal mount count */__le16 s_magic; /* Magic signature */__le16 s_state; /* File system state */__le16 s_errors; /* Behaviour when detecting errors */__le16 s_minor_rev_level; /* minor revision level */__le32 s_lastcheck; /* time of last check */__le32 s_checkinterval; /* max. time between checks */__le32 s_creator_os; /* OS */__le32 s_rev_level; /* Revision level */__le16 s_def_resuid; /* Default uid for reserved blocks */__le16 s_def_resgid; /* Default gid for reserved blocks *//** These fields are for EXT2_DYNAMIC_REV superblocks only.** Note: the difference between the compatible feature set and* the incompatible feature set is that if there is a bit set* in the incompatible feature set that the kernel doesn't* know about, it should refuse to mount the filesystem.** e2fsck's requirements are more strict; if it doesn't know* about a feature in either the compatible or incompatible* feature set, it must abort and not try to meddle with* things it doesn't understand...*/__le32 s_first_ino; /* First non-reserved inode */__le16 s_inode_size; /* size of inode structure */__le16 s_block_group_nr; /* block group # of this superblock */__le32 s_feature_compat; /* compatible feature set */__le32 s_feature_incompat; /* incompatible feature set */__le32 s_feature_ro_compat; /* readonly-compatible feature set */__u8 s_uuid[16]; /* 128-bit uuid for volume */char s_volume_name[16]; /* volume name */char s_last_mounted[64]; /* directory where last mounted */__le32 s_algorithm_usage_bitmap; /* For compression *//** Performance hints. Directory preallocation should only* happen if the EXT2_COMPAT_PREALLOC flag is on.*/__u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/__u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */__u16 s_padding1;/** Journaling support valid if EXT3_FEATURE_COMPAT_HAS_JOURNAL set.*/__u8 s_journal_uuid[16]; /* uuid of journal superblock */__u32 s_journal_inum; /* inode number of journal file */__u32 s_journal_dev; /* device number of journal file */__u32 s_last_orphan; /* start of list of inodes to delete */__u32 s_hash_seed[4]; /* HTREE hash seed */__u8 s_def_hash_version; /* Default hash version to use */__u8 s_reserved_char_pad;__u16 s_reserved_word_pad;__le32 s_default_mount_opts;__le32 s_first_meta_bg; /* First metablock block group */__u32 s_reserved[190]; /* Padding to the end of the block */
};
关键字段详解(基于struct ext2_super_block)
| 字段名 | 数据类型 | 含义 | 运维意义 |
|---|---|---|---|
s_inodes_count | __le32 | inode总量 | df -i查看使用率 |
s_blocks_count | __le32 | 数据块总量 | 计算磁盘容量 |
s_free_blocks_count | __le32 | 空闲块数量 | df -h显示剩余空间 |
s_free_inodes_count | __le32 | 空闲inode数量 | 文件创建上限预警 |
s_first_data_block | __le32 | 首个数据块位置(0或1,取决于Boot Sector大小) | 定位数据起始位置 |
s_log_block_size | __le32 | 块大小对数(值=0:1KB, 1:2KB, 2:4KB) | 影响最大文件尺寸(见下表) |
s_blocks_per_group | __le32 | 每组块数量(固定值) | 计算块组总数 |
s_inodes_per_group | __le32 | 每组inode数量 | 格式化时设定,影响文件密度 |
s_mtime / s_wtime | __le32 | 最后挂载/写入时间戳 | 故障恢复时间参考 |
s_feature_compat | __le32 | 兼容性特性(如dir_index加速目录查找) | 扩展功能开关 |
s_uuid[16] | __u8 | 文件系统唯一ID | 挂载时校验防止误挂载 |
块大小与文件系统限制的关系:
| 块大小 | 最大文件尺寸 | 最大文件系统尺寸 |
|---|---|---|
| 1KB | 16GB | 2TB |
| 2KB | 256GB | 8TB |
| 4KB | 2TB | 16TB |
冗余备份机制
- 备份策略:块组0的超级块为主副本,其他块组(如1、3、5)存储冗余副本。
- 恢复流程:
- 系统启动时读取块组0的超级块。
- 若校验失败(如Magic签名错误),自动加载其他块组的备份副本。
- 使用
e2fsck -b 8193可指定备份超级块修复(8193为块组1的超级块位置).
GDT(Group Descriptor Table)
核心概念:
文件系统分块组:
为了提升性能(减少寻道时间、并行化操作)和增强可靠性(分散关键数据结构),像 ext2/3/4 这样的文件系统会将整个存储空间(分区)划分为多个连续的、大小相等的块组(Block Group)。
每个块组包含:
数据块(存储文件实际内容)
inode(存储文件元数据)
关键的管理结构(主要是该块组的副本:超级块和 GDT 条目本身)
用于跟踪空闲空间的位图(bitmap)
GDT 的角色:
GDT 是一个数组(表),文件系统中有多少个块组,这个数组就有多少个条目(Group Descriptor)。
每个条目(Group Descriptor)精确地描述了一个特定块组的关键信息,相当于该块组的“管理档案”。
位置: GDT 通常紧跟在超级块(Super Block)之后存储。在 ext2/3/4 中,它位于块组 0 的开头区域(紧随超级块之后)。
GDT 条目(Group Descriptor)包含的关键信息:
每个 Group Descriptor 条目主要包含指向其管理的块组内部关键数据结构位置的指针,以及一些统计信息:
块位图块号(Block Bitmap Block):
指明存储该块组的块位图(Block Bitmap) 的数据块号。
块位图作用: 一个比特位代表该块组内的一个数据块。位值为
0表示对应的数据块空闲,1表示已分配(被使用)。这是管理块组内空闲空间的核心数据结构。
inode 位图块号(Inode Bitmap Block):
指明存储该块组的 inode 位图(Inode Bitmap) 的数据块号。
inode 位图作用: 一个比特位代表该块组内的一个 inode。位值为
0表示对应的 inode 空闲,1表示已分配(被使用)。这是管理块组内空闲 inode 的核心数据结构。
inode 表起始块号(Inode Table Block):
指明该块组的 inode 表(Inode Table) 开始的第一个数据块号。
inode 表作用: 一个连续的块序列,存储了该块组内所有 inode 结构本身。每个 inode 包含了一个文件或目录的所有元数据(权限、大小、时间戳、指向数据块的指针等)。
空闲块数(Free Blocks Count):
记录该块组内当前空闲数据块的数量。用于快速判断该块组是否有空间分配新数据块。
空闲 inode 数(Free Inodes Count):
记录该块组内当前空闲 inode 的数量。用于快速判断该块组是否可以创建新文件/目录(需要分配 inode)。
已用目录数(Used Directories Count)(ext2/3/4 较新版本):
记录该块组内有多少个目录。这个信息有助于文件系统分配器(Allocator)策略性地将新目录分散到不同的块组中,以平衡目录树的分布和提高查找效率。
组描述符(Group Descriptor)
// 磁盘级blockgroup的数据结构
/*
* Structure of a blocks group descriptor
*/
struct ext2_group_desc
{__le32 bg_block_bitmap; /* Blocks bitmap block */__le32 bg_inode_bitmap; /* Inodes bitmap */__le32 bg_inode_table; /* Inodes table block*/__le16 bg_free_blocks_count; /* Free blocks count */__le16 bg_free_inodes_count; /* Free inodes count */__le16 bg_used_dirs_count; /* Directories count */__le16 bg_pad;__le32 bg_reserved[3];
};
- 作用:定位块组内元数据位置(如通过
bg_inode_table找到inode表)。 - 全局管理:所有组描述符组成 GDT表(Group Descriptor Table) ,紧跟超级块.
GDT 的重要性:
定位关键元数据: 当文件系统需要操作一个特定块组内的文件或目录时(例如,创建文件、分配空间),它首先通过 GDT 找到该块组对应的 Group Descriptor。从这个条目中,文件系统就能迅速定位到该块组的块位图、inode 位图和 inode 表的具体位置。
空间管理: 空闲块数和空闲 inode 数提供了块组级别的空间使用快照,是文件系统分配器决策的基础(例如,选择哪个块组来分配新的 inode 或数据块)。
分配策略支持:
Used Directories Count等信息支持更智能的分配策略(如将相关文件和目录尽量放在同一个块组,或将新目录分散放置)。元数据冗余与恢复:
与超级块类似,GDT 在整个文件系统中也有多个备份!通常,每个块组的开头(或者至少是某些关键块组的开头)都会保存一份 GDT 的副本。
这种冗余设计是文件系统容错的关键。如果块组 0 的 GDT(主副本)损坏了,
e2fsck(文件系统检查修复工具)可以使用其他块组中的 GDT 备份来尝试恢复文件系统的结构信息。注意: 恢复时,
e2fsck需要依赖超级块的备份来知道 GDT 备份的位置(因为超级块里记录了块组大小等信息)。
GDT vs. Super Block:
| 特性 | 超级块 (Super Block) | 块组描述符表 (GDT) |
|---|---|---|
| 作用范围 | 整个文件系统 | 每个块组(包含所有块组的描述符) |
| 描述对象 | 文件系统的全局属性 | 每个块组的内部结构和状态 |
| 关键信息 | 魔数、状态、总大小、块大小、总 inode 数、根 inode、挂载信息等 | 块位图位置、inode位图位置、inode表位置、本组空闲块/inode数、目录数等 |
| 数量 | 一个主副本 + 多个备份 | 一个主表(在块组0) + 每个块组有备份(或部分备份) |
| 依赖关系 | 独立存在,是挂载起点 | 依赖超级块(需要超级块信息才能找到并解析GDT) |
| 类比 | 图书馆的总目录册封面和总索引 | 每个分区阅览室(块组)的详细物品清单和管理簿 |
| 修复关键性 | 损坏后文件系统可能无法识别/挂载 | 损坏可能导致其描述的块组无法访问,但可用备份恢复 |
没有 GDT,文件系统就无法知道每个块组内部的关键元数据在哪里,也就无法有效地管理和访问存储在该块组中的文件和目录数据。 它是连接全局视图(超级块)和局部管理(块组内部)的核心纽带。
块位图(Block Bitmap)
核心概念:
想象一个巨大的仓库(文件系统所在的磁盘分区)被划分成无数个大小相同的储物格(数据块, Block)。块位图的作用就是用一个极其简洁高效的表格来记录:仓库里每一个储物格当前是空的(可以放东西)还是已经被占用(放了东西)。
位置与归属:
块位图不是全局唯一的,而是每个块组(Block Group)都有一个专属的块位图。
它位于其所属的块组内部。
具体位置由该块组对应的 GDT(Group Descriptor Table)条目中的
块位图块号(Block Bitmap Block)字段明确指出。操作系统通过 GDT 找到它。
数据结构:
块位图本质上是一个连续的比特序列(bit array)。
这个比特序列存储在一个或多个物理的数据块中(通常是1个块,除非块组非常大)。
每个比特(bit)代表块组中的一个数据块:
0: 表示该比特对应的数据块是空闲的(Free),可以用于存储新数据。1: 表示该比特对应的数据块是已分配的(Allocated/Used),正在被某个文件或目录(的 inode)使用,或者用于存储文件系统本身的元数据(如另一个位图、inode表的一部分等)。
比特位与数据块的映射:
比特位在序列中的索引号(Index) 直接对应着块组内数据块的编号(Block Number within the Group)。
例如,块位图中的第
0位代表块组中的第0个数据块;第1位代表第1个数据块,以此类推。
作用:
快速空间查找: 当需要为新文件分配空间或为现有文件追加数据时,文件系统分配器(Allocator)会扫描块位图(通常从上次分配的位置开始或根据策略),寻找值为
0的比特位。找到后,就知道对应的数据块是空闲可用的。这是分配操作的核心依据。空间释放: 当删除文件或截断文件时,文件系统会将文件释放出来的数据块对应的比特位从
1置为0,标记这些块为空闲。空间状态统计: 通过计算块位图中
0的数量,可以快速得到该块组内空闲块的数量。这个信息会被汇总并更新到 GDT 条目的空闲块数(Free Blocks Count)字段,有时也会反映到超级块的全局统计中(虽然全局统计可能不完全实时同步)。分配策略基础: 文件系统分配器利用块位图和 GDT 中的空闲块数信息,结合其他因素(如将相关文件的数据块尽量放在同一块组或相邻块组以提高访问效率、负载均衡等策略),决定在哪个块组的哪个具体位置分配新块。
重要特性:
高效性: 用1个比特管理1个数据块,空间开销极小。例如,对于一个4KB大小的数据块,管理它只需要1/32768(1 bit / (4KB * 8 bits/byte))的空间开销。这使得块位图本身通常只需要占用1个数据块就能管理非常大的块组。
微观性: 它管理的是块组内部最细粒度的数据块分配状态。
依赖GDT: 操作系统必须先通过 GDT 条目找到块位图所在的物理块号,才能读取或修改它。
易失性与持久化: 块位图是文件系统元数据的一部分。对它的修改(分配/释放块)必须同步写回磁盘才能保证一致性。现代日志文件系统(如 ext3/ext4)会将位图的更改作为事务的一部分写入日志(Journal),然后再写入实际位置,大大提高了崩溃恢复的能力和速度。
损坏影响: 如果块位图损坏(例如,一个空闲块被错误标记为已用,或者反之),会导致严重问题:
标记已用但实际空闲:造成空间浪费(空间泄露)。
标记空闲但实际已用:可能导致数据覆盖(一个块被分配给两个不同的文件),这是灾难性的数据损坏。
文件系统检查工具
fsck/e2fsck的核心任务之一就是通过扫描 inode 和数据块的引用关系,来验证和修复块位图中的错误。
块位图与其他结构的关系:
与 GDT: 密不可分。GDT 条目是找到块位图的地图和钥匙。GDT 条目中的
块位图块号指向存储位图的物理块,空闲块数则来源于位图的统计。与超级块(Super Block): 超级块存储全局的空闲块总数(可能来自所有块组 GDT 中空闲块数的总和)。块位图是底层实际管理每个块状态的基础,支撑着这个全局统计。
与 inode: 当需要为一个文件分配新数据块时:
分配器扫描块位图找到空闲块。
将该块的编号(或间接块指针)写入文件的 inode 或间接块中。
将块位图中对应的比特位置
1。
与 inode 位图(Inode Bitmap): 两者结构类似,但管理对象不同。inode 位图管理块组内 inode 的分配状态(每个比特代表一个 inode),块位图管理数据块的分配状态。它们通常位于同一个块组内相邻的位置(都由 GDT 指向)。
总结:
块位图是文件系统中空间管理的基石:
它是什么? 每个块组内一个由比特(0/1)组成的数组,每个比特精确对应块组内的一个数据块,标识其空闲或已用状态。
它在哪里? 存储在块组内的数据块中,位置由该块组的 GDT 条目指定。
它干什么?
提供最快速、最细粒度的空闲块查找机制。
执行数据块的分配(置1)和释放(置0)。
支撑块组和全局的空闲块数量统计。
为什么重要?
高效: 用极小空间开销管理大量块。
关键: 所有文件数据的读写分配都依赖其准确性。
脆弱: 损坏会导致空间错误或数据损坏,需要日志和
fsck保障。基础: 是实现文件系统分配策略(如局部性、负载均衡)的底层依据。
简单类比:
仓库(磁盘分区) 被分成多个 区域(块组)。
每个区域有一个 电子看板(块位图)。
看板上每个 指示灯(比特位) 对应区域内的一个 储物格(数据块)。
绿灯(0):格子空,可用。
红灯(1):格子已占用。
管理员(文件系统) 通过查看看板(扫描块位图)快速知道哪里有空格子(空闲块),并更新灯的状态(分配/释放)。
inode位图(Inode Bitmap)
核心概念:
想象一个巨大的档案馆(文件系统)。这个档案馆里有许多档案柜(块组, Block Group)。每个档案柜里存放着许多档案袋(inode)。每个档案袋里装着一份档案(文件)的详细目录和存放位置信息(元数据),但不包含档案内容本身(内容存放在仓库/数据块里)。
inode位图的作用: 它就是一个简洁的登记簿,精确记录着某个特定档案柜(块组)里,哪些档案袋(inode)是空的(可以装新档案),哪些已经被占用(装着某个档案的信息)。
关键特性详解:
位置与归属:
和块位图一样,inode位图不是全局唯一的,而是每个块组(Block Group)都有一个专属的inode位图。
它位于其所属的块组内部。
具体位置由该块组对应的 GDT(Group Descriptor Table)条目中的
inode位图块号(Inode Bitmap Block)字段明确指出。操作系统通过 GDT 找到它。
数据结构:
inode位图本质上也是一个连续的比特序列(bit array)。
这个比特序列存储在一个或多个物理的数据块中(通常只需要1个块,除非块组内inode数量巨大)。
每个比特(bit)代表块组中的一个inode槽位:
0: 表示该比特对应的inode是空闲的(Free),可以分配给新创建的文件或目录。1: 表示该比特对应的inode是已分配的(Allocated/Used),它正被某个文件或目录使用,存储着该文件/目录的关键元数据。
比特位与inode的映射:
比特位在序列中的索引号(Index) 直接对应着块组内inode的编号(Inode Number within the Group)。
例如,inode位图中的第
0位代表块组中的第0号inode;第1位代表第1号inode,以此类推。全局inode号 = 块组起始inode号 + 块组内inode索引号。超级块或GDT通常记录了块组的起始inode号。
作用:
快速inode分配: 当需要创建新文件或目录时,文件系统分配器会扫描目标块组的inode位图,寻找值为
0的比特位。找到后,就知道该inode是空闲可用的,可以分配给新文件/目录。这是创建文件系统对象的第一步。inode释放: 当删除文件或目录时,文件系统会将该对象占用的inode对应的比特位从
1置为0,标记该inode为空闲,可供后续分配。空闲inode统计: 通过计算inode位图中
0的数量,可以快速得到该块组内空闲inode的数量。这个信息会被更新到 GDT 条目的空闲inode数(Free Inodes Count)字段。全局的空闲inode数(可能在超级块)也来源于此。分配策略基础: 文件系统利用inode位图和GDT中的空闲inode数信息,结合其他策略(如将新目录的inode分配到空闲inode较多的块组、尝试将文件inode与其数据块放在同一块组等),决定在哪个块组分配新inode。
重要特性:
高效性: 用1个比特管理1个inode,空间开销极小。管理一个inode通常只需要几十到几百字节(存储其元数据),但管理它的状态只需要1个比特。
管理对象: 它管理的是inode本身的分配状态,而不是inode指向的数据块(那是块位图的工作)。
依赖GDT: 操作系统必须先通过 GDT 条目找到inode位图所在的物理块号,才能读取或修改它。
易失性与持久化: inode位图也是关键元数据。对它的修改(分配/释放inode)必须同步写回磁盘以保证一致性。在日志文件系统中,对inode位图的修改也会被记录到日志(Journal) 中。
损坏影响: inode位图损坏会导致严重问题:
标记已用但实际空闲:造成inode资源浪费(inode泄露),可能导致“No space left on device”错误(即使数据块还有空间,因为inode用光了)。
标记空闲但实际已用:可能导致元数据覆盖(一个新文件分配到这个inode,覆盖了原有文件的元数据),这通常意味着原有文件的所有数据丢失(因为找不到指向数据块的指针了),是灾难性的。
fsck/e2fsck会检查inode位图与实际inode表内容的引用关系来修复错误。
inode位图与其他结构的关系:
与 GDT: 密不可分。GDT 条目是找到inode位图的钥匙(
inode位图块号字段),并记录着该块组inode位图反映出的空闲inode数。与 inode表(Inode Table):
这是最直接的关系! inode位图指向 inode表的管理状态,而 inode表存储 inode结构的实际内容。
当分配器通过inode位图找到一个空闲inode(位为0)时,它就知道可以去该块组的inode表中对应的位置(由inode索引号决定)初始化一个新的inode结构。
当删除文件时,在将inode位图置0前,通常需要先释放该inode指向的数据块(通过块位图)和清空inode表项。
GDT 条目中的
inode表起始块号(Inode Table Block)指向了inode表的位置。
与块位图(Block Bitmap): 两者结构类似(都是位图),但管理对象不同:
inode位图: 管理 inode槽位 的分配状态。
块位图: 管理 数据块 的分配状态。
创建文件时,通常先分配inode(扫描inode位图),再根据需要分配数据块(扫描块位图)。
删除文件时,先释放数据块(更新块位图),再释放inode(更新inode位图)(顺序很重要,避免数据块“泄露”)。
与目录项(Directory Entry): 目录项(如
mydoc.txt)存储的是文件名和它对应的inode号。当通过文件名查找文件时,最终需要通过目录项找到inode号,然后通过inode号(结合块组信息)定位到具体的inode位图和inode表。
总结:
inode位图是文件系统中 inode资源管理的关键:
它是什么? 每个块组内一个由比特(0/1)组成的数组,每个比特精确对应块组内的一个inode槽位,标识其空闲或已用状态。
它在哪里? 存储在块组内的数据块中,位置由该块组的 GDT 条目指定。
它干什么?
提供最快速、最细粒度的空闲inode查找机制。
执行inode的分配(置1)和释放(置0)。
支撑块组和全局的空闲inode数量统计。
是创建/删除文件或目录操作中管理inode资源的基石。
为什么重要?
高效: 极小开销管理大量inode状态。
关键: 文件/目录的创建、访问(通过inode)、删除都直接依赖其准确性。没有空闲inode,就无法创建新文件,即使磁盘还有空间!
脆弱: 损坏会导致inode资源错误或元数据/数据丢失,日志和
fsck是其保障。基础: 与inode表紧密协作,共同管理文件系统的核心元数据——inode。
简单类比(延续档案馆):
每个档案柜(块组) 有一个 inode登记簿(inode位图)。
登记簿上每一行(比特位)对应柜子里的一个 档案袋槽位(inode槽位)。
空白(0):槽位空,可以放新档案袋。
已登记(1):槽位已有档案袋(装着某档案的目录)。
管理员(文件系统) :
要新建档案(文件):查登记簿找空白行 -> 在对应槽位放新档案袋 -> 在登记簿上标记该行为“已登记”。
要销毁档案(删文件):找到对应档案袋 -> 取出里面记录的仓库位置(数据块指针),去仓库清空储物格(更新块位图)-> 清空/回收档案袋(inode表项)-> 在登记簿上标记该行为“空白”。
i节点表(Inode Table)
核心概念:
想象一个巨大的档案馆(文件系统):
超级块 (Super Block) 是整个档案馆的总目录册封面(全局信息)。
GDT (Group Descriptor Table) 是各个档案柜(块组)的管理员名单和钥匙清单。
Inode位图 (Inode Bitmap) 是每个档案柜的档案袋槽位登记簿(记录哪些槽位空/满)。
块位图 (Block Bitmap) 是每个档案柜的储物格(数据块)状态看板(记录哪些格子空/满)。
Inode表 (Inode Table) 就是档案柜里存放档案袋(inode)的物理抽屉。每个档案袋(inode)里装着一份文件的详细目录信息(元数据),但不包含文件内容本身。
关键特性详解:
位置与归属:
Inode表不是全局唯一的,而是每个块组(Block Group)都有一个专属的inode表。
它位于其所属的块组内部。
具体位置和范围由该块组对应的 GDT(Group Descriptor Table)条目中的
inode表起始块号(Inode Table Block)字段明确指出。操作系统通过 GDT 找到它的起始位置。Inode表在块组内占用一组连续的数据块。
数据结构:
Inode表本质上是一个数组(表)。
数组中的每个元素就是一个
inode 结构。一个块组内有多少个 inode(即 inode 表有多大),是在格式化文件系统 (
mkfs) 时决定的(通常基于总空间和预期文件数量比例计算)。每个 inode 结构的大小是固定的(例如,在 ext2/3 中是 128 字节,在 ext4 中默认是 256 字节)。这意味着一个 4KB 的数据块可以存储
4096 / 128 = 32个 ext2 inode。
Inode 结构的内容(元数据):
每个 inode 结构存储了它所代表的文件或目录的所有关键属性(除了文件名和文件内容本身):文件模式 (File Mode): 包含文件类型(普通文件、目录、符号链接、设备文件等)和访问权限(读、写、执行权限位,针对用户、组、其他)。
所有者信息 (Owner Information): 文件所有者的用户ID(UID)和组ID(GID)。
大小 (Size): 文件的逻辑大小(以字节为单位)。对于常规文件,这是文件内容的总字节数。对于目录,通常是其目录项列表的大小。
时间戳 (Timestamps):
访问时间 (Access Time / atime): 文件内容最后一次被读取的时间。
修改时间 (Modification Time / mtime): 文件内容最后一次被修改的时间。
Inode变更时间 (Change Time / ctime): Inode 元数据(权限、所有者、链接数等)最后一次被改变的时间(包括 mtime 改变也会触发 ctime 更新)。
创建时间 (Birth Time / btime/crtime): 文件的创建时间(并非所有文件系统都支持,ext4 支持)。
链接计数 (Link Count): 指向该 inode 的硬链接总数。当此计数降为 0 时,文件系统可以安全地删除该文件(释放其数据块和 inode)。
数据块指针 (Block Pointers): 这是 inode 最核心的功能!它存储了指向实际包含文件内容的数据块的物理块号。由于文件大小差异很大,inode 采用多级索引机制:
直接指针 (Direct Blocks): 通常有 12 个(ext*)。每个直接指向一个存储文件数据的数据块。适合小文件。
一级间接指针 (Single Indirect Block): 指向一个数据块,但这个块里不存文件数据,而是存储更多的块指针(例如,一个 4KB 块能存 1024 个 4 字节块指针)。用于中等文件。
二级间接指针 (Double Indirect Block): 指向一个一级间接块指针块。该块再指向多个一级间接块。用于较大文件。
三级间接指针 (Triple Indirect Block): 指向一个二级间接块指针块。用于非常大的文件(理论支持巨大文件)。
文件标志 (File Flags / Attributes): 如不可修改(immutable)、仅追加(append-only)、不更新访问时间(noatime)等(通过
chattr设置)。文件版本 (Generation Number): (用于 NFS)或 文件校验和 (Inode Checksum) (ext4):用于检测 inode 本身是否损坏。
扩展属性 (Extended Attributes): (可选)指向存储文件扩展属性(如 SELinux context)的位置。
文件 ACL (Access Control List): (可选)更细粒度的访问控制信息位置。
目录项偏移 (Directory Entry Offset): (仅目录 inode)优化目录查找。
作用:
存储文件元数据: 这是 inode 表最根本的作用,保存了文件除名字和内容外的所有信息。
定位文件数据: 通过解析 inode 中的多级块指针,操作系统可以找到文件内容存储在磁盘上的具体物理位置。
文件访问控制: 权限位和 ACL 信息决定谁可以访问该文件以及如何访问。
维护文件状态: 时间戳、大小、链接数等反映了文件的当前状态和历史操作。
组织目录结构: 目录本身也是一个文件,它的 inode 类型是“目录”。目录文件的内容是目录项(Dirent)列表,每个目录项包含一个文件名和它对应的 inode 号。通过目录文件的 inode 找到其数据块(存储目录项),再通过目录项中的 inode 号找到目标文件/子目录的 inode,如此层层递进,构建出整个目录树。
重要特性:
唯一标识符: 每个 inode 在整个文件系统内有一个唯一的编号 (inode number)。
ls -i命令可以查看文件的 inode 号。与文件名分离: 文件名实际上存储在目录文件的目录项中,并与 inode 号关联。一个文件可以有多个文件名(硬链接),它们指向同一个 inode。删除文件实际上是减少其 inode 的链接计数,当计数为 0 时才真正删除。
依赖 GDT 和 Inode 位图:
GDT 提供 inode 表的物理位置。
Inode 位图告诉文件系统 inode 表中哪些槽位(inode)是空闲可用的。
易失性与持久化: Inode 表是极其关键的元数据。对 inode 内容的修改(如更新文件大小、时间戳、分配新块指针)必须同步写回磁盘。日志文件系统会将对 inode 的更改作为事务写入日志(Journal)。
损坏影响: 如果某个 inode 结构损坏:
元数据丢失: 权限、所有者、时间戳、大小等信息错误。
数据丢失: 块指针损坏可能导致无法读取文件内容(指向错误或无效的块)。
文件系统不一致: 可能导致
fsck运行时报错,甚至文件系统无法挂载。
大小限制: 文件系统支持的最大文件数受限于 inode 表的总大小(即格式化时设定的 inode 总数)。用
df -i可以查看 inode 使用情况。
Inode 表与其他结构的关系:
| 结构 | 与 Inode 表的关系 |
|---|---|
| Inode 位图 | 密不可分! Inode 位图是 inode 表的索引状态图。位图标记 inode 表中哪些 inode 是已分配/空闲的。分配新 inode 时,通过位图找到空闲槽位,然后初始化该位置的 inode 结构。 |
| GDT | 关键依赖! GDT 条目提供了 inode 表在磁盘上的物理起始位置和范围(通过块组大小和 inode 数可以推算)。没有 GDT,系统无法定位 inode 表。 |
| 块位图 | 数据关联! 当 inode 需要为文件分配新数据块时,它依赖块位图找到空闲块,然后将该块的指针写入 inode。删除文件时,inode 释放的块通过块位图标记为空闲。 |
| 超级块 | 全局关联! 超级块记录整个文件系统的 inode 总数 和 空闲 inode 数(可能由各块组 GDT 汇总)。根目录 (/) 的 inode 号也存储在超级块中,是访问文件树的起点。 |
| 目录项 (Dirent) | 核心纽带! 目录项存储在目录文件的数据块中。它包含 文件名 和其对应的 inode 号。系统通过目录项找到文件名对应的 inode 号,然后用 inode 号去访问 inode 表,最终找到文件元数据和内容。 |
| 数据块 | 目标指向! Inode 中的块指针直接指向存储文件实际内容的数据块。没有 inode 的指针,数据块只是一堆无意义的字节。 |
总结:
Inode 表是文件系统的 “文件元数据仓库”:
它是什么? 每个块组内一个连续的数组,存储着固定大小的 inode 结构。每个结构代表文件系统中的一个对象(文件、目录等),包含其所有元数据和数据块指针。
它在哪里? 存储在块组内的一组连续数据块中,位置由该块组的 GDT 条目指定。
它干什么?
存储文件/目录的核心属性(类型、权限、大小、时间戳、所有者等)。
维护文件的链接计数。
提供查找文件内容的关键数据块指针(直接、间接)。
构成目录树的基础(目录 inode 指向存储目录项的数据块)。
为什么重要?
文件身份的核心: 文件名只是别名,inode 号才是文件在文件系统内的唯一身份标识。
数据访问的钥匙: 没有正确的 inode 和其块指针,就无法读取文件内容。
元数据的家园: 所有关于文件的描述信息(除了名字)都在这里。
目录树的基石: 目录结构通过目录 inode 和目录项链接起来。
资源管理的终点: Inode 位图管理的目标就是 inode 表的槽位;文件操作最终落脚于读写 inode 表项。
系统健壮性的关键: Inode 表的完整性和一致性至关重要,损坏通常意味着数据丢失。日志机制是其重要保障。
简单类比(延续档案馆):
每个档案柜(块组) 有一个 inode抽屉(inode表)。
抽屉里放着很多档案袋(inode结构),每个档案袋有唯一编号(inode号)。
每个档案袋里装着:
档案的属性卡片(类型、权限、所有者、大小、创建/修改时间等)。
一份储物格位置清单(指向存放档案实际内容的仓库储物格/数据块)。
一份引用登记(有多少个别名/硬链接指向这个档案袋)。
管理员(文件系统):
当要访问文件
report.txt:查目录本(目录文件)-> 找到report.txt对应的档案袋编号(inode号)-> 打开对应编号的档案袋(读取inode表项)-> 根据属性卡片检查权限 -> 根据储物格清单去仓库取内容。当创建新文件:查登记簿(inode位图)找空档案袋槽位 -> 在抽屉(inode表)对应位置放新档案袋 -> 初始化属性卡片 -> 去仓库看板(块位图)找空储物格 -> 在储物格清单(块指针)上记录位置 -> 在目录本(目录文件)里添加新条目(文件名 + 新档案袋编号)。
当删除文件:在目录本里划掉条目(减少一个引用)-> 找到档案袋 -> 划掉储物格清单上所有记录(通知仓库那些格子空了/更新块位图)-> 清空档案袋(可选,或标记为待回收)-> 在登记簿上标记该档案袋槽位为空(更新inode位图)。只有当所有目录本里都没有这个档案袋的条目(链接数=0)时,才会执行后两步。
数据块(Data Block)
核心概念:
想象一个巨大的仓库(磁盘分区)被划分成无数个大小相同的储物格。这些储物格就是数据块(Data Block)。文件系统的核心任务之一就是高效、可靠地管理这些储物格,将文件内容(文本、图片、代码等)以及必要的元数据(如目录项列表)存储在其中,并在需要时快速存取。
关键特性详解:
基本单元:
数据块是文件系统进行空间分配、读写和管理的最小逻辑单元。
块大小(Block Size)是在格式化文件系统(
mkfs)时确定的常见选项(如 1024B, 2048B, 4096B)。现代文件系统(如 ext4, XFS, NTFS)通常默认使用 4KB (4096 字节) 的块大小,以匹配现代内存页大小和磁盘扇区(通常 512B 或 4K)特性。整个分区或逻辑卷的空间(除了开头预留的元数据区域)都被划分为连续的数据块。
存储内容:
文件内容 (File Content): 这是数据块最主要的用途。一个文件的内容被分割(如果需要)并存储在一个或多个数据块中。文本、二进制代码、图片像素、视频帧等最终都存储在这里。
目录项列表 (Directory Entries / Dirents):
目录本身在文件系统中也被视为一种特殊类型的文件。
目录文件的内容就是一个数据块(或多个数据块),里面存储着 目录项(Dirent) 的列表。
每个目录项通常包含:文件名、对应的 inode 号、目录项长度、文件类型标识等。
通过读取目录文件的数据块,才能知道该目录下有哪些文件和子目录及其对应的 inode。
间接块指针 (Indirect Block Pointers):
当文件较大,无法用 inode 中的直接指针完全表示时,就需要使用间接块。
一级/二级/三级间接块本身也是特殊用途的数据块。它们里面存储的不是文件内容,而是指向其他数据块(存储文件内容)的块指针数组。
扩展属性 (Extended Attributes): 如果文件设置了扩展属性(如 SELinux context),并且属性值较大,它们可能会被存储在单独分配的数据块中,inode 里只存储指向这些块的指针。
符号链接目标 (Symbolic Link Target): 如果符号链接指向的路径名很短(通常小于 60 字节),它可以直接存储在 inode 的某个字段里(称为“快速符号链接”)。如果路径名很长,则需要分配一个数据块来存储这个目标路径字符串。
文件系统内部数据结构 (Internal Data Structures): 如块位图 (Block Bitmap)、inode 位图 (Inode Bitmap)、inode 表 (Inode Table)、组描述符表 (GDT) 等核心元数据,它们本身也存储在数据块中!只是这些块被文件系统保留用于特定元数据,通常位于块组的开头区域。
管理机制:
块位图 (Block Bitmap): 如前所述,每个块组都有一个块位图。位图中的每个比特(bit)对应块组内的一个数据块。
0表示空闲,1表示已分配。这是空间管理的基石。inode 块指针: 文件或目录的 inode 结构中包含指向其内容所在数据块的指针(直接指针、间接指针)。这是访问文件数据的导航图。
分配器 (Allocator): 文件系统内核模块中负责分配和释放数据块的组件。当需要为新文件或增长的文件分配空间时:
根据策略(如局部性、负载均衡)选择合适的块组。
查询该块组的块位图,寻找连续(或尽量连续)的空闲块。
将找到的块标记为已用(块位图置
1)。将这些块的物理号写入文件 inode 的指针区域(或间接块)。
更新 GDT 中的空闲块计数。
释放: 当文件被删除或截断时:
通过 inode 找到文件占用的所有数据块(包括间接块)。
在对应块组的块位图中将这些块标记为空闲(置
0)。(可选)清除块中原有数据(出于安全或性能考虑,通常延迟进行)。
更新 GDT 中的空闲块计数。
块地址映射: 文件系统维护着从逻辑块号(文件内的偏移量换算而来) 到物理块号(磁盘上的实际位置) 的映射关系。这个映射就是通过 inode 的指针结构(直接、间接)建立的。
重要特性:
匿名性: 数据块本身不存储任何标识信息说明它属于哪个文件。它完全由管理它的元数据(inode 指针、块位图)来定义其归属和用途。同一个块可以被错误地指向多次(位图损坏导致),造成数据覆盖。
依赖元数据: 没有元数据(inode 和位图),数据块只是一堆无法解读的字节。文件系统的健壮性严重依赖于元数据的正确性和一致性。
性能关键: 文件的读写性能很大程度上取决于数据块在磁盘上的布局(连续 vs 碎片化)以及访问模式(顺序 vs 随机)。文件系统分配器会尽量分配连续块(ext4 的 extent 特性就是为了优化此点)或将相关文件(同一目录)的块放在相近位置。
碎片 (Fragmentation): 随着文件的创建、删除和大小变化,空闲空间会变得不连续。当为大文件分配空间时,可能无法找到足够的连续块,导致文件内容分散在磁盘各处(碎片化),降低顺序读取性能。文件系统(或
fsck/defrag工具)有时需要整理碎片。预分配 (Preallocation) 与 延迟分配 (Delayed Allocation):
预分配: 提前为预计会增长的文件预留连续的磁盘块(如数据库文件),避免未来碎片。
fallocate()系统调用用于此目的。延迟分配 (ext4, XFS 等): 当应用程序写入文件时,文件系统先不立即分配数据块,而是将数据缓存在内存中。直到数据需要真正刷新到磁盘(或达到阈值)时,分配器才一次性分配所需的所有块。这提高了分配连续性(有机会找到更大的连续空间)和效率(减少小块分配次数),是现代文件系统的重要优化。
稀疏文件 (Sparse Files): 文件可以包含大片的“空洞”(逻辑偏移量有,但实际未写入数据)。文件系统不会为空洞分配实际的数据块,节省空间。读取空洞返回零。
lseek()+fallocate(FALLOC_FL_PUNCH_HOLE)可显式创建空洞。
数据块与其他结构的关系:
| 结构 | 与数据块 (Data Block) 的关系 |
|---|---|
| inode / inode 表 | 核心导航! inode 通过块指针(直接/间接) 指向文件内容所在的数据块。没有 inode 的指针,数据块就无法被文件访问。 |
| 块位图 (Block Bitmap) | 管理状态! 块位图的每个比特位对应一个数据块,标记其空闲/已用状态。分配和释放数据块必须更新块位图。 |
| GDT (Group Descriptor Table) | 组级统计! GDT 条目记录其管理的块组内空闲数据块的总数,为分配器提供快速决策依据。 |
| 目录项 (Dirent) | 存储位置 & 目标关联! 1. 存储位置: 目录项列表存储在目录文件的数据块中。 2. 目标关联: 目录项中的 inode 号 指向目标文件/目录的 inode,而该 inode 则指向目标内容的数据块。通过目录项找到文件名对应的 inode,再通过 inode 找到文件内容块。 |
| 间接块 (Indirect Block) | 扩展寻址! 间接块本身是特殊的数据块。它们存储指向实际文件内容数据块的指针数组。用于解决 inode 直接指针数量有限的问题,支持大文件。 |
| 超级块 (Super Block) | 全局统计! 超级块可能存储整个文件系统的总数据块数和总空闲块数(汇总自各 GDT)。 |
总结:
数据块是文件系统持久化存储的最终载体:
它是什么? 磁盘空间被划分成的固定大小的逻辑单元(通常 4KB)。是整个分区/卷中占比最大的部分。
它存储什么?
文件的实际内容(主要用途)。
目录项列表(目录文件的内容)。
间接块指针(扩展寻址)。
扩展属性值(大值时)。
长符号链接的目标路径。
文件系统元数据本身(位图、inode表、GDT 等也存储在特殊的数据块中)。
如何管理?
块位图 (Block Bitmap) 跟踪每个块组内数据块的分配状态(空闲/已用)。
inode 块指针 建立文件逻辑偏移到物理数据块的映射。
分配器 (Allocator) 负责分配/释放块,力求连续性和高效性(利用延迟分配等策略)。
为什么重要?
数据的最终归宿: 所有用户文件和大部分元数据的物理存储位置。
性能核心: 数据块的布局(连续/碎片)直接影响 I/O 性能(尤其是顺序读写)。
空间管理对象: 文件系统空间分配和回收操作的核心目标就是管理数据块。
资源基础: 文件系统的总容量和可用空间由数据块的数量和状态决定。
依赖元数据: 其意义和归属完全由上层元数据(inode, 位图)定义,凸显元数据一致性的极端重要性。
简单类比(延续档案馆与仓库):
仓库 (磁盘分区) 被划分成无数个大小相同的储物格 (数据块)。
档案袋 (inode) 里有一份 储物格清单 (块指针),记录了该档案内容具体存放在哪些储物格里。
储物格状态看板 (块位图) 实时显示每个储物格是 空 (0) 还是 已占用 (1)。
目录本 (目录文件) 本身也是一个档案袋(inode),它的内容(即目录本里的条目)存储在某些储物格(数据块) 里。目录本条目记录了文件名和对应的档案袋编号 (inode号)。
管理员 (文件系统分配器):
要存新档案(写文件):找个空档案袋(分配 inode)-> 查看板(扫描块位图)找连续的空储物格 -> 在档案袋的储物格清单(块指针)上记录位置 -> 把档案内容放进这些格子 -> 在看板上标记这些格子已占用。
要取档案(读文件):查目录本(读目录块)找档案袋编号 -> 打开档案袋(读 inode)-> 按储物格清单(块指针)去仓库格子取内容。
要销毁档案(删文件):划掉目录本里的条目(减少链接)-> 找到档案袋 -> 根据清单(块指针)把对应储物格在看板上的标记清空(块位图置 0)-> 回收档案袋(inode 位图置 0)。只有当所有目录本里都没这档案袋条目时,才清储物格和回收档案袋。
inode 和 datablock 映射机制详解
一、inode 中的块指针结构
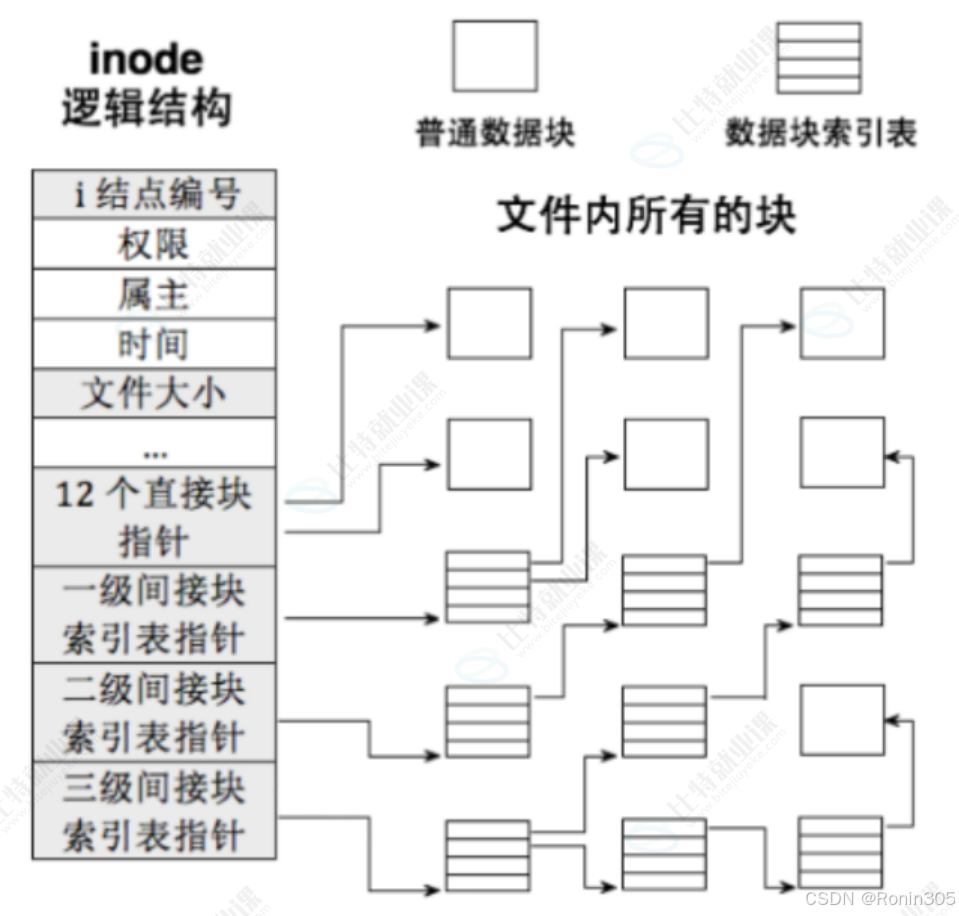
每个 ext2 inode 包含 15 个块指针,分为四类,用于不同大小的文件:
(假设块大小 = 4KB,指针大小 = 4字节)
| 指针类型 | 数量 | 指向的内容 | 最大寻址范围(4KB块) | 文件大小支持 |
|---|---|---|---|---|
| 直接指针 | 12 | 文件数据块 | 12 块 → 48KB | ≤ 48KB |
| 一级间接指针 | 1 | 间接块(存储块指针) | 1024 块 → 4MB | ≤ 48KB + 4MB = 4.05MB |
| 二级间接指针 | 1 | 指向一级间接块指针 | 1024² 块 → 4GB | ≤ 4.05MB + 4GB ≈ 4GB |
| 三级间接指针 | 1 | 指向二级间接块指针 | 1024³ 块 → 4TB | ≤ 4GB + 4TB ≈ 4TB |
📌 计算说明(以一级间接指针为例):
一个数据块大小 = 4KB = 4096 字节
每个指针占 4 字节 → 一个块可存储指针数 =
4096 / 4 = 1024一级间接指针指向的间接块包含 1024 个块指针,支持
1024 × 4KB = 4MB数据。
二、映射机制详解
1. 小文件(≤ 48KB)
直接使用 12 个直接指针,无需额外索引:
inode → [直接块1, 直接块2, ..., 直接块12] → 数据块
优势:一次访问即可定位数据块(O(1)时间复杂度)。
2. 中等文件(48KB < Size ≤ 4.05MB)
启用 一级间接指针:
inode → 一级间接块(存储1024个指针) → 数据块
访问流程:
读取 inode 中的一级间接指针,定位到间接块。
从间接块中查找目标逻辑块号对应的指针。
访问数据块。
时间复杂度:O(2)(两次磁盘访问)。
3. 大文件(4.05MB < Size ≤ 4GB)
启用 二级间接指针:
inode → 二级间接块 → 一级间接块 → 数据块
层级关系:
二级间接块存储 1024 个一级间接块指针。
每个一级间接块存储 1024 个数据块指针。
最大支持:
1024 × 1024 = 1,048,576块 ≈ 4GB。时间复杂度:O(3)。
4. 超大文件(4GB < Size ≤ 4TB)
启用 三级间接指针:
inode → 三级间接块 → 二级间接块 → 一级间接块 → 数据块
最大支持:
1024³ = 1,073,741,824块 ≈ 4TB。时间复杂度:O(4)。
三、关键设计特点
1. 平衡效率与空间开销
小文件高效:直接指针避免额外 I/O。
大文件支持:通过间接块以少量 inode 空间支持超大文件(三级索引仅占用 inode 中 3×4=12 字节)。
空间浪费控制:间接块仅在需要时分配。
2. 碎片问题
ext2 的弱点:频繁写入/删除后,文件块可能分散在磁盘各处(碎片化),影响顺序读写性能。
后续优化:ext4 引入 Extents(连续块组描述)替代间接块,显著减少碎片。
3. 块分配策略
块组局部性:
ext2 将磁盘分为多个 块组(Block Group),每个组包含独立的数据块和 inode。
分配器优先将同一文件的数据块和其 inode 放在同一块组,减少磁头移动。
四、示例:读取一个文件的第 15,000 个逻辑块
假设块大小 = 4KB,需访问文件中偏移量 15,000 × 4KB = 60MB 处的数据:
计算逻辑块号:
15,000。判断索引层级:
直接指针覆盖 0–11 块(0–48KB)
一级间接覆盖 12–1023 块(48KB–4.05MB)
二级间接覆盖 1024–1,048,575 块(4.05MB–4GB)
→ 15,000 属于二级间接范围!
访问路径:
Step 1:读 inode 的二级间接指针,定位二级间接块。
Step 2:在二级间接块中查找第
⌊(15000-1024)/1024⌋ = 13项,定位一级间接块。Step 3:在一级间接块中查找第
(15000-1024) mod 1024 = 728项,获取数据块指针。Step 4:访问数据块。
⚠️ 实际优化:内核缓存高频使用的间接块,减少磁盘 I/O。
五、ext2 vs ext4:映射机制的演进
| 特性 | ext2 | ext4(优化点) |
|---|---|---|
| 映射结构 | 多级索引(间接块) | Extents(连续块区间描述) |
| 最大文件 | 4TB(理论) | 1EB(实际受文件系统限制) |
| 碎片控制 | 较差 | 优秀(预分配、延迟分配) |
| 小文件效率 | 高 | 更高(内联数据、Tail Packing) |
🔍 ext4 的 Extents 示例:
一个 extent =<起始块号, 连续块数>,例如(1000, 50)表示从块 1000 开始的连续 50 个块。
优势:单次 I/O 可读写大量连续数据,显著提升性能!
📌 思考:
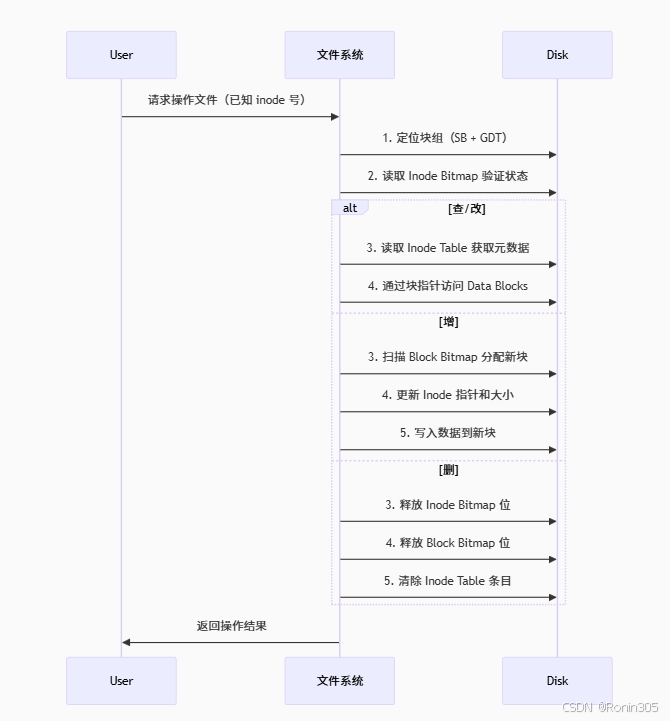
已知 inode 号且在指定分区时,对文件进行的增、删、查、改是在做什么?
inode 号的关键作用
全局唯一编号 = 块组位置 + 组内 inode 索引
计算公式:
目标块组 = inode号 / (每块组inode数量) 组内索引 = inode号 % (每块组inode数量)
文件操作本质解析(已知 inode 号)
1. 查(Read)
步骤:
通过 inode 号定位目标块组(读 GDT)
在块组内找到 Inode Table
用组内索引读取 inode 结构体
获取内容:
直接读 inode 中的元数据(权限、大小等)
通过 inode 的 块指针 访问 Data Blocks 获取文件内容
2. 改(Modify)
修改元数据(如权限、时间戳):
直接更新 Inode Table 中对应 inode 结构体的字段修改内容:
通过 inode 的块指针找到数据块
修改后写回磁盘
特殊情况:
若文件增大需分配新块:
查询 Block Bitmap 找空闲块
更新 inode 指针(直接/间接指针)
更新 Block Bitmap 和 GDT 空闲计数
3. 增(Append/Write)
核心操作:分配新数据块
扫描 Block Bitmap 寻找空闲块
将空闲块标记为已用(Block Bitmap 置 1)
将新块号写入 inode 的指针区:
小文件 → 直接指针
大文件 → 更新间接指针块
将数据写入新分配块
更新 inode 中的文件大小字段
更新 GDT 空闲块计数
4. 删(Delete)
关键动作:释放资源
将 inode 在 Inode Bitmap 中的标记置 0(释放 inode 槽位)
将 inode 指向的所有数据块在 Block Bitmap 中置 0
清除 Inode Table 中该 inode 结构体
更新 GDT 中的空闲计数(inode 和 blocks)
注意:
目录文件需递归删除其内容
硬链接需减少链接计数(link count)
新建文件流程示例
我们通过对ext2文件系统,从宏观认识到文件系统中每一个结构的认识,那具体新建一个文件的流程我们心里也就大概清楚了,下面就是一个流程示例:
分配空闲 inode
扫描目标块组的 Inode Bitmap,寻找第一个值为
0的空闲位将该位设置为
1(标记为已使用)更新块组的 GDT 中的
空闲 inode 计数(减1)获得全局唯一的 inode 号
初始化 inode 结构
在 Inode Table 中定位到分配的 inode 位置
初始化元数据:
文件类型(普通文件/目录等)
权限位(rwx 权限)
所有者和组(UID/GID)
时间戳(创建时间 atime/mtime/ctime)
链接计数 = 1
文件大小 = 0
所有块指针清零
创建目录项
在父目录的数据块中分配新条目
写入:
文件名(1-255字节)
分配的 inode 号
文件类型
记录长度
更新fu目录的:
文件大小
mtime/ctime
分配数据块(可选)
若创建时写入内容:
扫描 Block Bitmap 寻找空闲块
分配连续块(ext2)或 extent(ext4)
将块号写入 inode 的 直接指针区
大文件时分配 间接指针块
更新文件大小字段
更新全局元数据
更新 GDT 中的空闲块计数(若分配了数据块)
更新 Superblock 的:
总空闲 inode 计数
总空闲块计数
文件系统修改时间
同步所有元数据变更到磁盘
关键数据结构变更示例
| 操作 | Inode Bitmap | Block Bitmap | Inode Table | 目录数据块 | GDT |
|---|---|---|---|---|---|
| 创建前 | 0 (空闲) | 0 (空闲) | 空条目 | 无记录 | 空闲计数=N |
| 创建后 | 1 (已用) | 1 (若分配块) | 初始化元数据 | 新增文件名+inode号 | 空闲计数=N-1 |
性能优化机制
块组局部性
优先在与父目录相同的块组分配 inode
文件数据块尽量与 inode 同块组
延迟分配(ext4)
数据块实际分配延后到 write() 调用
一次性分配连续块减少碎片
预分配
为预期增⻓的⽂件预留空间
避免后续频繁分配
💡 统计显⽰:在 SSD 上创建空文件约需 20-50μs,其中 80% 时间花费在元数据更新和日志记录上。
创建文件的本质是 "inode 分配 + 目录项注册 + 元数据链式更新" 的过程,核⼼在于维护文件系统元数据(位图/inode/目录项)的一致性。
1.4 目录与文件名
在前文中,我们有提到目录也是一种特殊的文件,下面我们再来重点介绍一下
一、本质剖析
目录的真实身份
目录是一种特殊类型的文件,其内容不是普通数据,而是 目录项(Dirent)列表。// 目录项结构示例(ext2) struct ext2_dir_entry {__u32 inode; // 指向的 inode 号__u16 rec_len; // 目录项总长度__u8 name_len; // 文件名长度__u8 file_type; // 文件类型(普通/目录等)char name[255]; // 文件名(变长) };文件名的定位
文件名 不存储于 inode 中,而是存在于 父目录的目录项 内。
比喻:📂 目录 = 电话簿,
📝 目录项 = 联系人条目(文件名 = 姓名,inode号 = 电话号码),
📞 inode = 联系人详细信息(地址、职业等)。
二、关键操作解析
1. 路径查找示例:/home/user/a.txt

每一步都需要:
解析目录项获取下级 inode 号
通过 inode 号定位目标元数据
2. 创建新文件 b.log
| 步骤 | 操作 | 影响的数据结构 |
|---|---|---|
| 1 | 在父目录数据块中分配新目录项 | 目录文件大小↑ |
| 2 | 写入文件名 b.log 和分配的 inode 号 | 目录项新增条目 |
| 3 | 更新父目录的 mtime/ctime | 父目录 inode 变更 |
3. 重命名 a.txt → c.txt
本质:修改父目录中对应目录项的 文件名字段
关键操作:
在原目录项中更新
name为"c.txt"更新
name_len长度刷新父目录的
mtime/ctime
注:若跨目录移动,需删除原目录项 + 在新目录创建项
4. 删除文件 c.txt
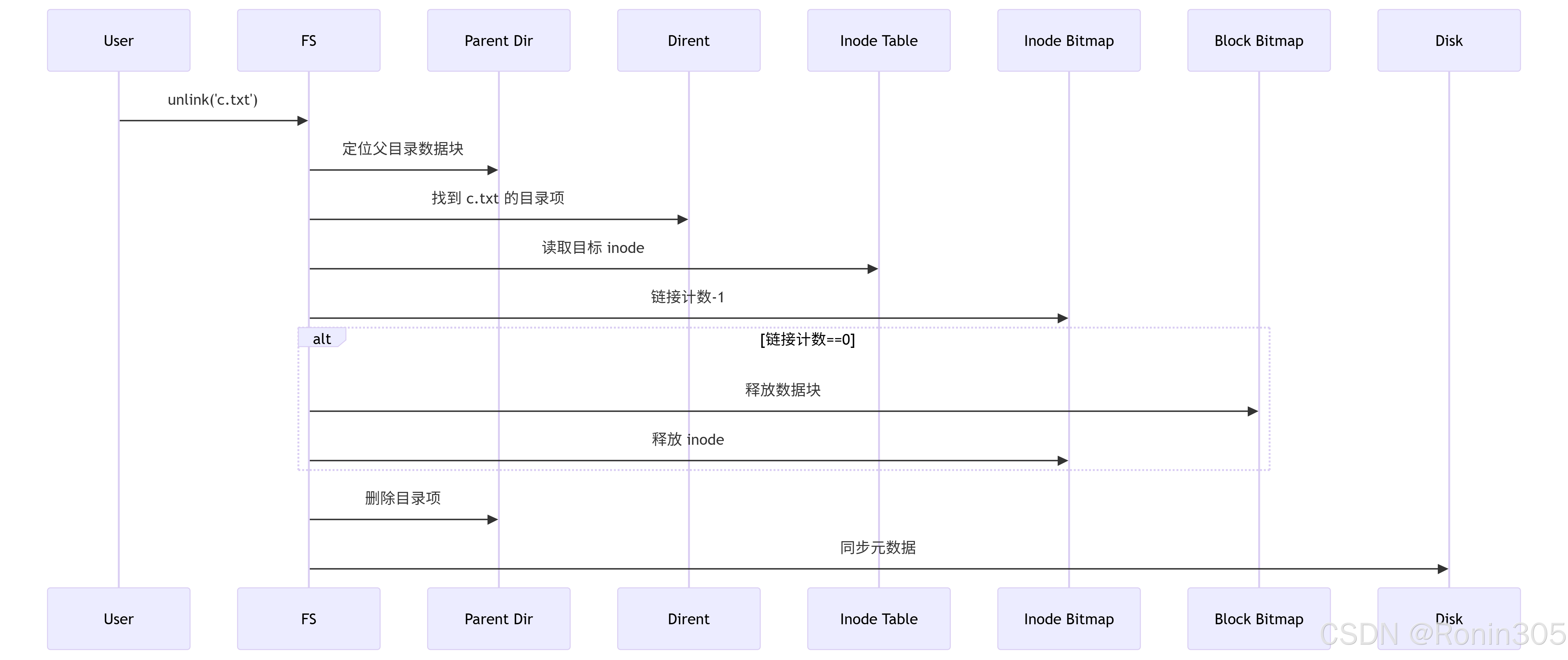
总结:目录与文件名的本质
| 概念 | 物理存储位置 | 作用 | 依赖机制 |
|---|---|---|---|
| 文件名 | 父目录文件的数据块中 | 用户可读标识 | 目录项结构 |
| 目录 | 特殊文件(存储目录项列表) | 组织文件层次结构 | inode 类型标记为目录 |
| 路径 | 无直接存储,运行时解析 | 定位文件的导航链 | 递归目录项查找 |
💡 关键结论:
删除文件 = 删除目录项 + 减少 inode 链接计数(实际数据可能仍存留直到覆盖)
rm -rf / 的灾难性:递归删除目录本质是深度优先遍历目录树,释放所有 inode 和数据块
恢复文件可能:若目录项未被覆盖,可用
debugfs等工具根据 inode 号重建目录项
1.5 路径解析
一、路径解析的核心流程:以/home/user/file.txt为例
起点:根目录的inode
根目录inode号固定为2,其位置由超级块的
s_first_data_block和GDT确定。读取inode 2的
i_block[],获取根目录的数据块地址。
逐级目录项查找
内核递归执行以下步骤:读取当前目录的数据块(存储
ext2_dir_entry_2数组)。线性遍历或HTree索引(大目录)匹配文件名(如
home)。获取下一级目录的inode号(如
home的inode号)。加载下一级目录的inode,重复直至找到目标。特殊目录项的处理
.:指向当前目录inode(不推进路径)。..:指向父目录inode(回退一级)。

特殊目录项的处理
.:指向当前目录inode(不推进路径)。..:指向父目录inode(回退一级)。
二、性能优化机制
缓存加速
Inode缓存:高频访问的inode驻留内存,避免重复读盘。
路径缓存:存储最近解析的路径到inode的映射。
目录查找优化
小目录:线性扫描(高效)。
大目录:HTree索引(B树变种),将目录项哈希分桶,降低时间复杂度至O(log n)。
块组局部性
分配器优先将同一目录下的文件/子目录置于相同块组,减少磁头寻道。
三、异常处理与边界场景
文件不存在
目录项匹配失败时返回
ENOENT错误。
符号链接解析
若目标为符号链接(
file_type = EXT2_FT_SYMLINK):短链接(<60字符):路径名直接存于inode的
i_block[]。长链接:读取链接指向的数据块,递归解析新路径。
崩溃一致性
日志机制(ext3/4引入):元数据操作作为事务记录日志,避免断电导致位图与目录项不一致。
1.6 路径缓存(dentry cache)
一、路径缓存的核心价值
问题根源:
每次路径解析(如/a/b/c)需递归:
读父目录数据块 → 查找目录项 → 获取inode号
加载下一级inode → 重复至叶子节点
磁盘I/O成为性能瓶颈(尤其是深路径/大目录)。
解决方案:
在内存中构建 路径组件 → inode 的映射缓存,避免重复解析。
二、内核实现机制(Linux VFS层)
1. 核心数据结构
struct dentry {struct inode *d_inode; // 关联的inodestruct dentry *d_parent; // 父目录dentrystruct qstr d_name; // 文件名(哈希值+字符串)struct list_head d_subdirs; // 子dentry链表struct hlist_node d_hash; // 哈希表节点// ...
};
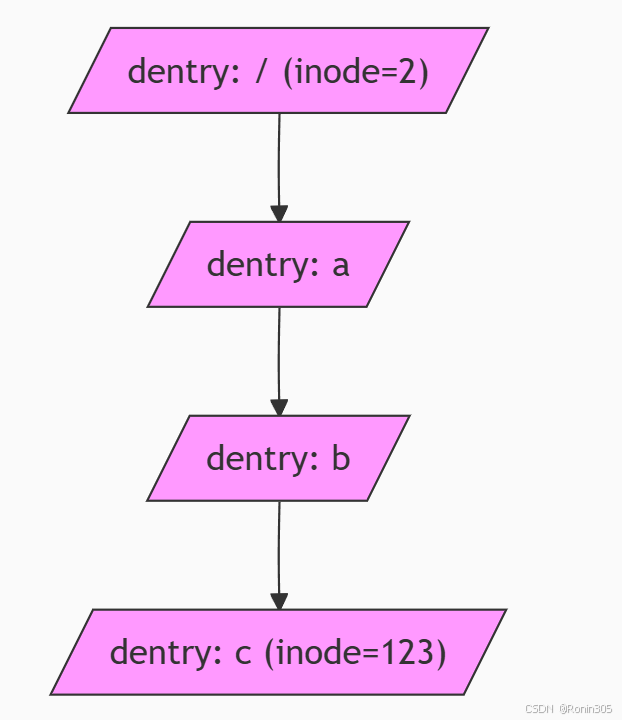
dentry:缓存路径组件的节点(如
a,b,c各对应一个dentry)dcache:以哈希表组织的全局dentry集合
2. 缓存结构示意图
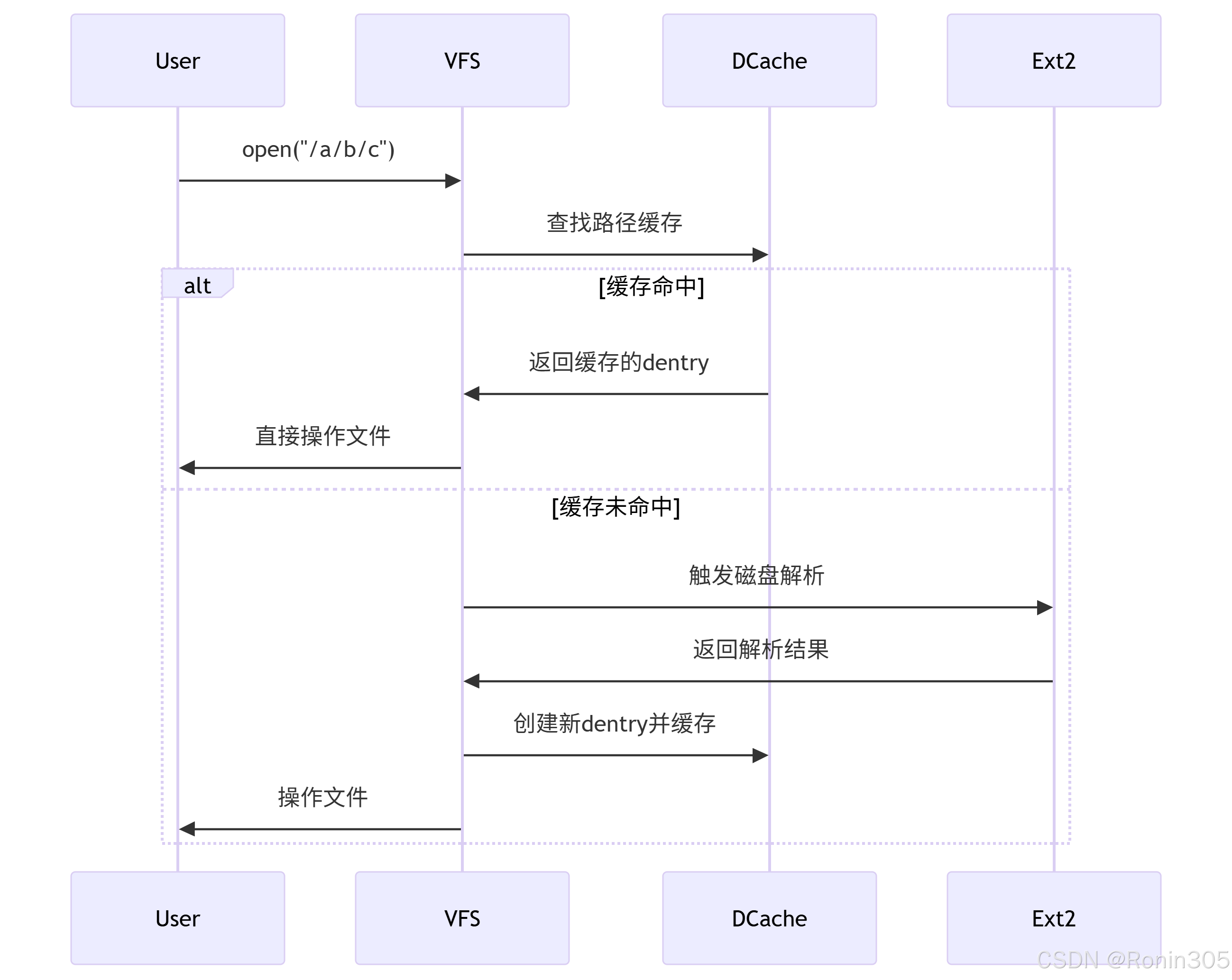
3. 缓存运作流程
场景:访问路径 /a/b/c
三、ext2路径缓存的加速策略
1. 缓存查找优化
哈希索引:
文件名哈希值 → 定位哈希桶 → 遍历桶内dentryhash = hash_name(parent_dentry, filename); // 计算文件名哈希 bucket = dcache_hash_bucket(hash); // 定位哈希桶 hlist_for_each_entry(dentry, bucket, d_hash) // 遍历匹配快速匹配:
先检查哈希值,再精确比对字符串
2. 缓存预热机制
父目录优先缓存:
解析/a/b/c时,/a和/a/b的dentry同步缓存邻近性预测:
访问/a/b后,主动缓存其子目录项(如c,d)
3. 缓存淘汰策略
LRU链表:
内核维护两个链表:dentry_unused:未被引用的dentry(优先回收)dentry_lru:近期使用过的dentry
内存压力响应:
当系统内存不足时,按LRU顺序释放dentry
四、缓存失效与同步
1. 失效场景
| 事件 | 失效范围 | 触发方式 |
|---|---|---|
| 文件删除 | 目标文件dentry | d_delete() |
| 文件移动/重命名 | 原路径+新路径dentry | d_move() |
| 文件内容修改 | 关联inode缓存 | inode->i_version++ |
| 文件系统卸载 | 所有相关dentry | shrink_dcache_parent() |
2. 一致性保障
写时同步:
文件操作(如rename)后立即标记相关dentry失效内存屏障:
确保多核间缓存状态同步日志辅助:
ext4通过jbd2日志保证元数据操作原子性,避免缓存与磁盘不一致
五、与ext2特性的协作
HTree目录索引
ext2大目录使用HTree(类B树)加速磁盘查找 → 减少缓存未命中时的惩罚inode缓存联动
dentry缓存命中后,直接关联 inode缓存(避免读inode表)块组局部性
dentry缓存暗示文件物理位置 → 预读相邻文件
总结:路径缓存的意义
性能核心:
将路径解析的 时间复杂度从O(n)降至O(1)(n为路径深度)资源复用:
避免重复解析相同路径(90%+的路径请求命中缓存)层次化加速:
与inode缓存、页缓存形成三级加速体系:

透明优化:
对应用程序零感知,无需修改代码即可获得性能提升
路径缓存是文件系统应对 "目录树复杂度爆炸" 的核心武器,其设计充分体现了 "空间换时间"
拓展:LRU链表:操作系统中的高效缓存淘汰机制
一、LRU核心思想与基本原理
LRU(Least Recently Used,最近最少使用) 是一种基于时间局部性的缓存淘汰算法,其核心原则是:
最近最少使用的数据最可能在未来被淘汰
基本工作原理
访问提升:当缓存项被访问时,将其移动到链表头部(MRU端)
淘汰策略:当缓存满时,从链表尾部(LRU端)移除最久未使用的项
结构示意:

新访问项插入头部,淘汰从尾部开始
二、Linux内核中的LRU实现(以页缓存为例)
多级LRU链表结构
Linux采用优化的双链表LRU策略:
// 内核数据结构
struct lruvec {struct list_head lists[NR_LRU_LISTS]; // 5个LRU链表
};// LRU链表类型定义
enum lru_list {LRU_INACTIVE_ANON = 0, // 非活跃匿名页LRU_ACTIVE_ANON = 1, // 活跃匿名页LRU_INACTIVE_FILE = 2, // 非活跃文件页LRU_ACTIVE_FILE = 3, // 活跃文件页LRU_UNEVICTABLE = 4, // 不可回收页NR_LRU_LISTS
};
三、LRU在实际系统的应用
1. 数据库缓冲池(如InnoDB)

2. Linux文件系统缓存
Page Cache:使用活跃/非活跃双链表
Dentry Cache:LRU链表+哈希表
Inode Cache:每CPU变量优化
3. Redis键淘汰策略
# 配置文件设置
maxmemory-policy volatile-lru
volatile-lru:从过期键中使用LRU淘汰
allkeys-lru:所有键中使用LRU淘汰
LRU的本质:在有限资源下,通过时间局部性原理最大化缓存效用。其变种算法仍在各类系统中发挥核心作用,是平衡性能与资源的关键机制。
1.7 挂载分区
挂载的本质与核心概念
1. 挂载的定义
挂载(Mounting) 是将存储设备(如硬盘分区)的文件系统连接到操作系统目录树特定位置(挂载点)的过程。挂载后,用户可通过该目录访问设备内容。
- 设计目标:
- 统一命名空间:将多个独立分区整合为单一目录树(如将数据盘挂到
/home)。 - 资源隔离:不同分区可独立格式化、备份或加密(如系统盘用 ext4,数据盘用 XFS)。
- 动态扩展:无需重启即可接入新存储设备(如 U 盘挂载到
/media/usb)。
- 统一命名空间:将多个独立分区整合为单一目录树(如将数据盘挂到
2. 关键术语
| 术语 | 说明 | 示例 |
|---|---|---|
| 设备文件 | 代表物理设备的特殊文件 | /dev/sda1, /dev/nvme0n1p2 |
| 文件系统 | 数据组织结构(如ext4, NTFS) | ext4, Btrfs, XFS |
| 挂载点 | 连接设备的目录位置 | /mnt/data, /home |
| 挂载表 | 系统当前挂载信息记录 | /proc/mounts, /etc/mtab |
3. 技术原理
| 组件 | 作用 | |
|---|---|---|
| 分区表 | 记录磁盘划分信息(如 MBR/GPT 定义 /dev/sda1 边界) | |
| 文件系统抽象层 | 屏蔽不同文件系统差异(如 ext4/NTFS 的统一读写接口) | |
| 挂载点目录 | 空目录作为访问入口(如 /mnt/newpart),挂载后显示分区内容而非原目录文件 | |
| 元数据更新 | 挂载信息写入内核数据结构(struct vfsmount),路径解析时重定向到分区 |
挂载流程详解(以Linux为例)
1. 挂载操作全流程
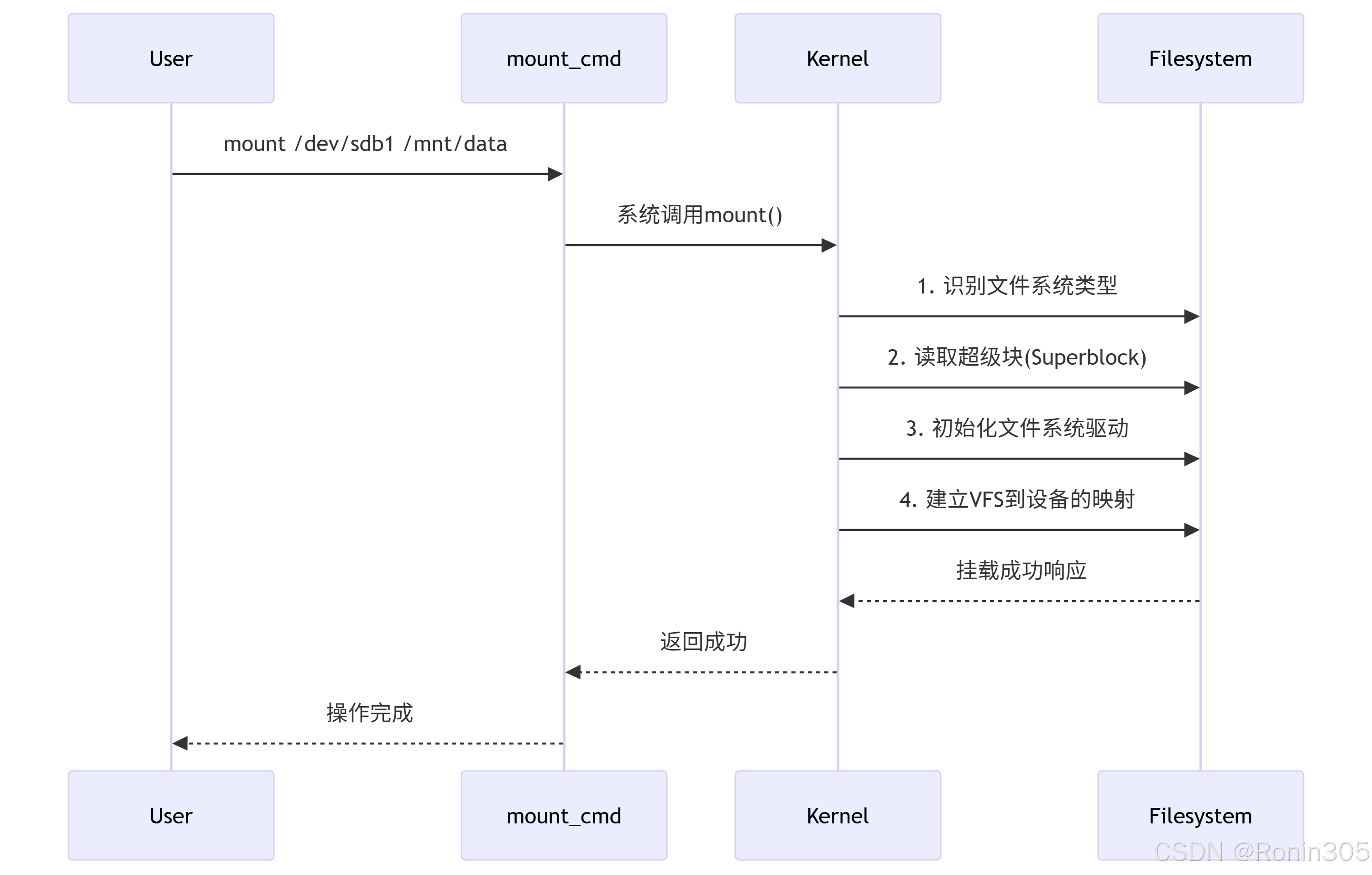
2. 内核级关键操作
设备识别:通过设备号(主/次)定位物理设备
超级块读取:验证文件系统完整性
VFS挂载:创建
vfsmount结构体struct vfsmount {struct dentry *mnt_root; // 挂载点目录项struct super_block *mnt_sb; // 超级块指针int mnt_flags; // 挂载选项 };目录树注入:将设备文件系统链接到挂载点
示例1:基本硬盘分区挂载
# 查看可用设备
sudo fdisk -l# 创建挂载点
sudo mkdir /mnt/mydrive# 挂载ext4分区
sudo mount -t ext4 /dev/sdb1 /mnt/mydrive# 验证挂载
df -hT | grep mydrive
输出:
/dev/sdb1 ext4 1.8T 256G 1.5T 15% /mnt/mydrive
示例2:临时内存盘挂载
# 创建512MB内存盘
sudo mount -t tmpfs -o size=512m tmpfs /mnt/ramdisk# 测试写入速度
dd if=/dev/zero of=/mnt/ramdisk/testfile bs=1M count=500
速度对比:
| 存储类型 | 写入速度 | 读取速度 |
|---|---|---|
| 内存盘 | 5.2 GB/s | 6.1 GB/s |
| SSD | 0.5 GB/s | 2.1 GB/s |
示例3:网络文件系统挂载(NFS)
# 服务端导出目录
echo "/shared 192.168.1.0/24(rw,sync)" | sudo tee -a /etc/exports
sudo systemctl restart nfs-server# 客户端挂载
sudo mount -t nfs 192.168.1.100:/shared /mnt/nfs-share
常用命令对比
| 命令 | 功能 | 示例 |
|---|---|---|
mount | 挂载设备 | mount /dev/sdc1 /backups |
umount | 卸载设备 | umount /backups |
findmnt | 查看挂载树 | findmnt -n --target /home |
lsblk | 块设备列表 | lsblk -f |
blkid | 设备UUID | blkid /dev/nvme0n1p2 |
设计哲学与技术演进
1. 核心设计思想
- 透明访问:用户通过路径访问文件,无需感知物理设备(如
/home可能跨多个磁盘)。 - 解耦设计:
- 物理层:磁盘分区(如
/dev/sda1) - 逻辑层:文件系统(如 ext4)
- 访问层:目录树(如
/mnt)
- 物理层:磁盘分区(如
2. 技术演进
| 特性 | 传统方案 | 现代优化 |
|---|---|---|
| 挂载管理 | 静态 /etc/fstab | 动态 systemd-mount(按需挂载) |
| 性能提升 | 同步写入 | async 选项延迟写(风险数据丢失) |
| 安全增强 | noatime 减少元数据更新 | SELinux 上下文绑定 |
总结:挂载分区的核心价值
- 资源整合:将离散存储设备组织为 统一目录树,简化数据访问路径。
- 灵活管理:支持动态挂载/卸载,适应热插拔设备与存储扩展需求。
- 安全控制:通过权限选项隔离敏感数据(如
noexec防止恶意程序执行)。
最终实现:用户通过
/path/to/file透明访问跨物理设备的数据,系统通过挂载机制完成路径到磁盘块的映射。
1.8 文件系统总结
下面用几张图总结,图片来源于网络
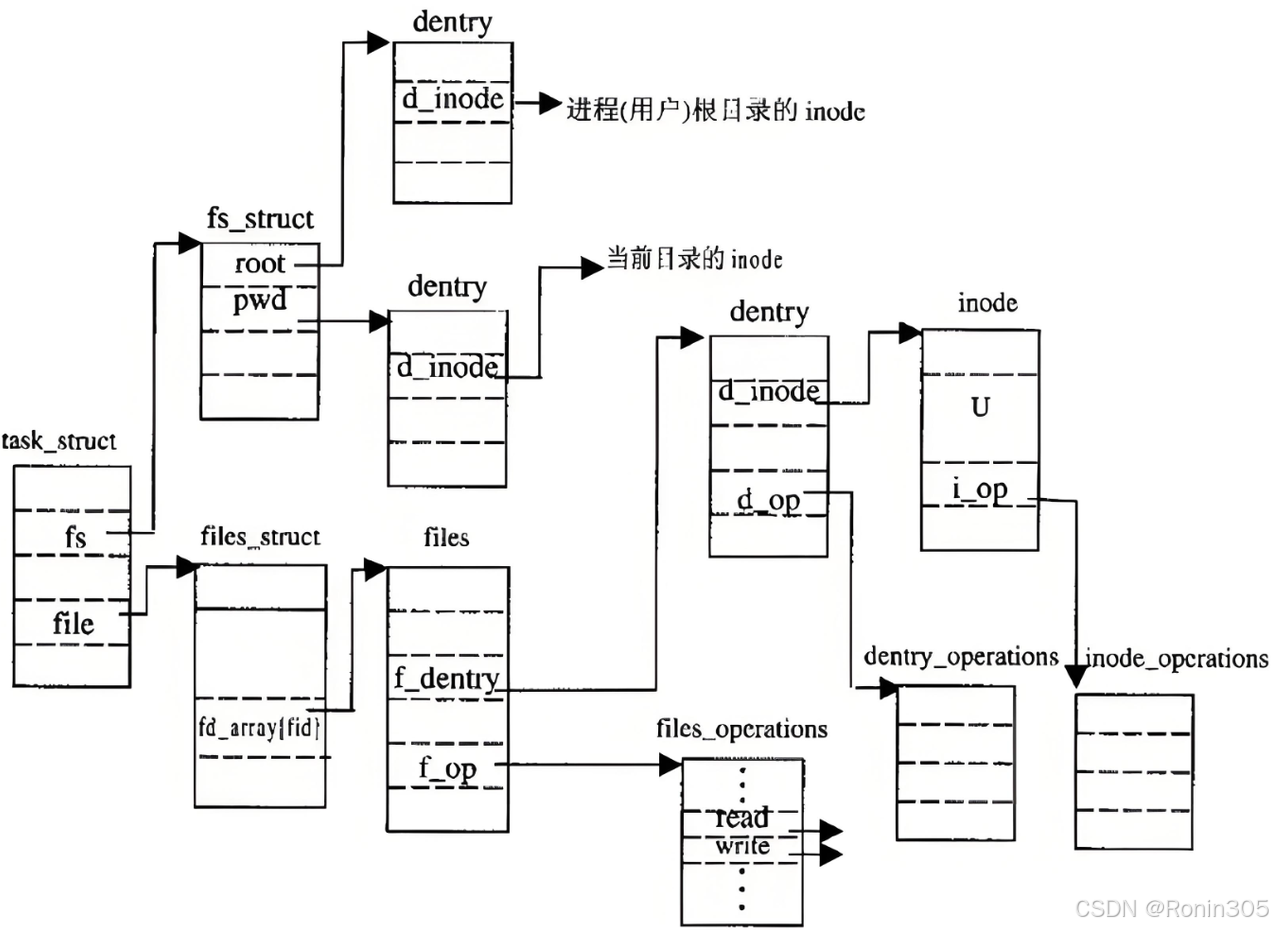
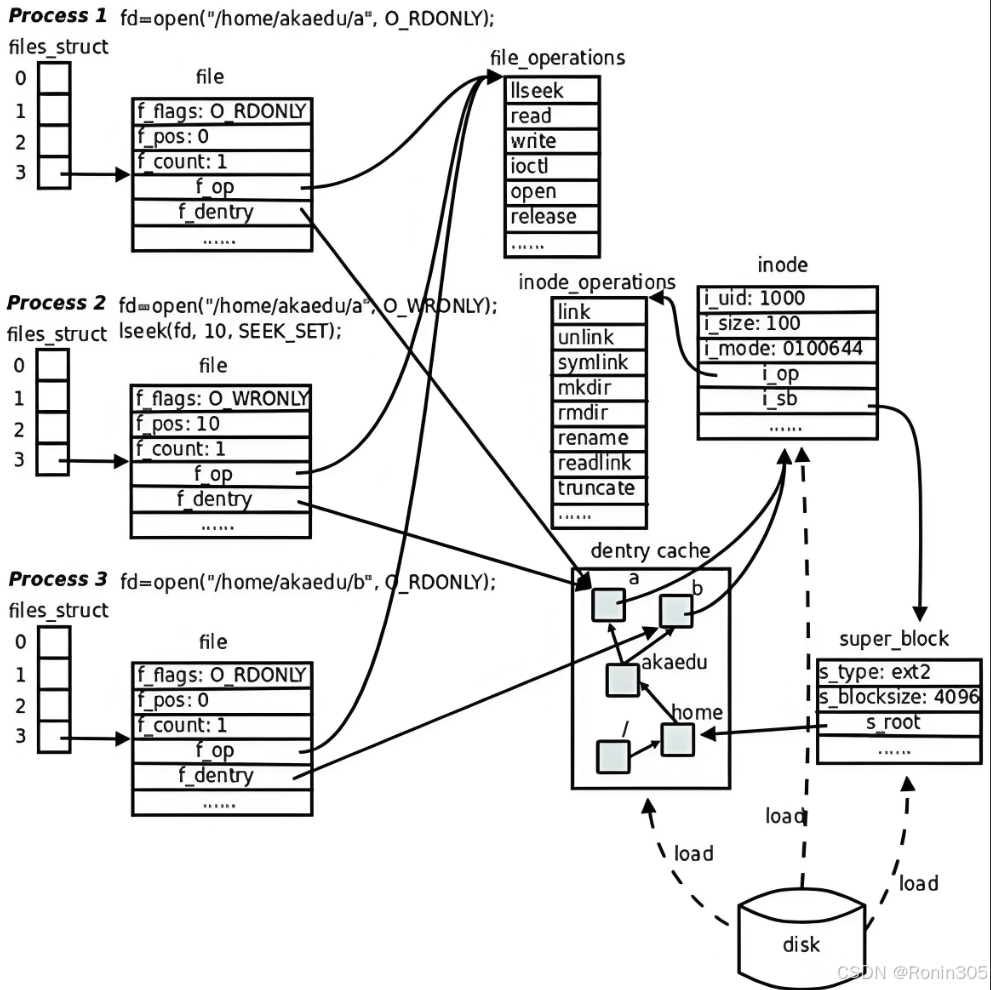
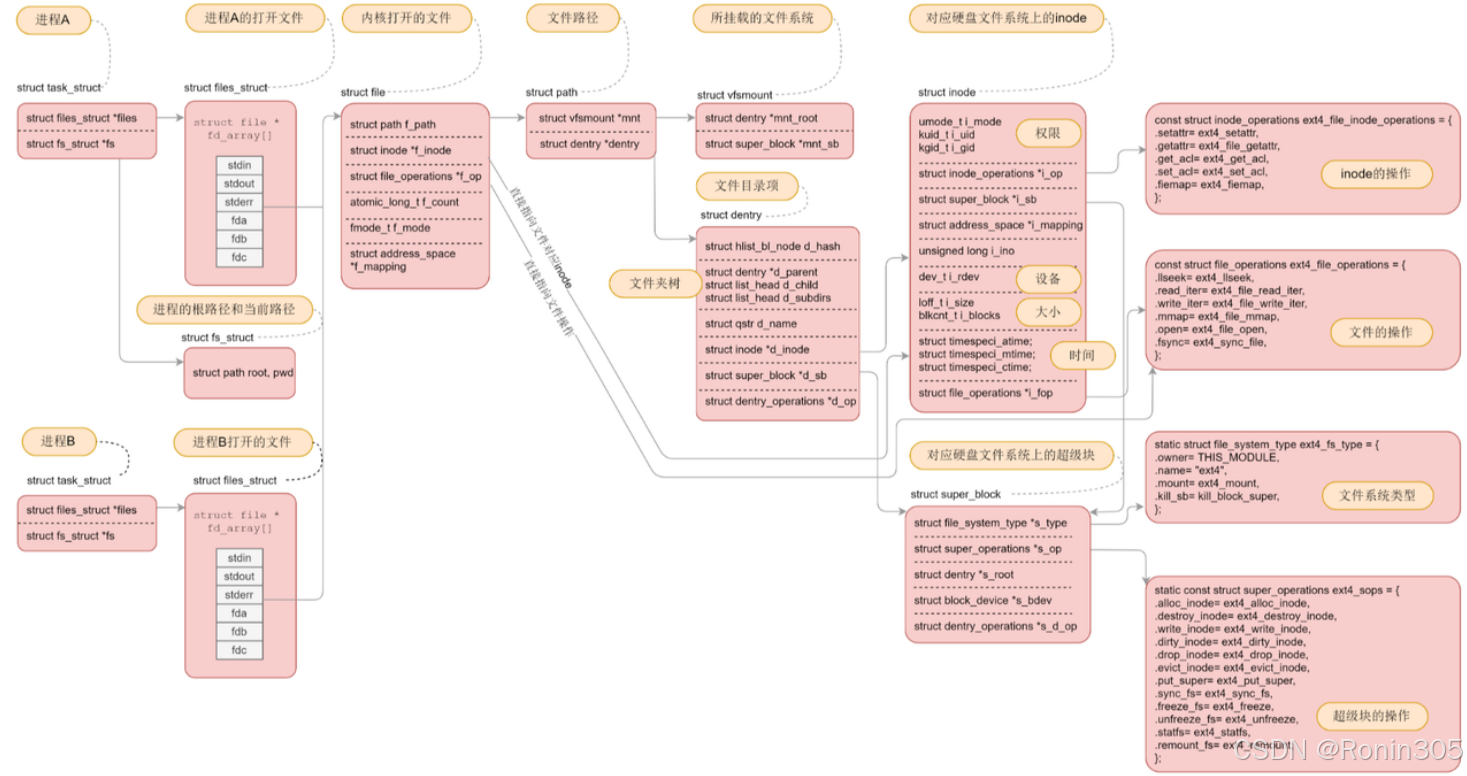
🌟 一句话总结
文件系统是操作系统的"图书馆管理系统":
它把硬盘分区变成书架(块组),给每本书(文件)建立档案卡(inode),用目录当图书索引,通过路径快速找书。
📚 核心概念类比
| 技术概念 | 现实比喻 | 核心作用 |
|---|---|---|
| 超级块 | 图书馆总目录 | 记录书架数量/位置 |
| 块组 | 分层书架 | 分区管理(如1楼文学区) |
| inode | 图书档案卡 | 记录书名/位置/借阅信息 |
| 数据块 | 书架上放书的格子 | 实际存储书的内容 |
| 目录 | 图书索引标签 | 通过标签(如"科幻小说")找书 |
| 路径解析 | 按索引标签逐层找书 | /科幻/三体.txt → 具体书 |
| 挂载 | 把新书库接入图书馆大楼 | 让新硬盘能被访问 |
🔧 关键操作解析
创建文件(新书上架):
领档案卡(分配inode)
写档案信息(设置权限/时间)
贴索引标签(在目录中添加条目)
分配书架格子(数据块)
删除文件(旧书下架):
撕掉索引标签(删除目录项)
回收档案卡(释放inode)
清空书架格子(释放数据块)
挂载分区(开新书库):
# 把 /dev/sdb1 硬盘接到 /mnt/library 目录 mount /dev/sdb1 /mnt/library效果:访问
/mnt/library就像进入新书库
⚡ 性能优化秘诀
路径缓存:
管理员记住常找的书位置(缓存路径→inode映射),下次秒找
例:第二次找《三体》比第一次快10倍LRU淘汰策略:
书架满了优先下架最久没人借的书(最近最少使用)
类比:图书馆定期清理冷门书籍
💎 记住三个本质
inode是核心:
知道inode号 = 知道书在哪个书架的哪个格子
增删查改本质是操作inode和关联数据块
目录只是索引:
文件名不在inode里 → 类似"书名"写在索引标签上
移动文件 = 换个标签位置(inode不变)
格式化=建图书馆:
mkfs.ext4 /dev/sdb1 # 把空仓库变成标准图书馆创建书架(块组)
印制空档案卡(inode表)
准备空白索引系统(目录结构)
🚀 终极总结
文件系统通过 inode(档案卡) + 数据块(书架) + 目录(索引) 的三元组,把冷冰冰的硬盘变成了可高效管理的"数字图书馆"。而挂载就是给这个图书馆安装大门的过程!
2. 软硬链接
2.1 软硬链接深度解析
简单概括:
| 硬链接(Hard Link) | 软链接(Symbolic Link) | |
|---|---|---|
| 本质 | 文件的“别名”(多个门牌指向同一套房) | 文件的“快捷方式”(导航纸条) |
| 底层 | 共享同一个 inode | 独立 inode + 存储目标路径 |
| 限制 | 不可跨分区/文件系统 | 可跨分区/磁盘/网络 |
一、硬链接(Hard Link)详解
1. 本质与底层机制
物理结构:
- 硬链接是同一文件数据的多个目录入口,与源文件共享相同的inode和数据块
- 创建硬链接时,仅新增目录项指向源文件inode,inode引用计数(
i_count)+1
ln source.txt hardlink.txt # 创建硬链接 ls -i source.txt hardlink.txt # 查看inode号(相同)关键特性:
特性 技术原理 存储开销 仅增加目录项(约64字节),不占用额外数据块 删除安全性 删除源文件后,文件数据仍可通过其他硬链接访问(inode引用计数未归零) 同步性 修改任一硬链接,所有链接同步更新(因共享数据块) 限制 ❌ 不可跨文件系统(不同文件系统inode独立)
❌ 不可链接目录(防目录环死锁)
2. 应用场景
重要文件防误删:为关键数据创建多个硬链接,即使误删源文件仍可恢复
ln database.db backup_db # 数据库文件防误删节省存储空间:大文件(如视频)需在多个目录访问时,避免复制造成的空间浪费
版本控制优化:Git等工具用硬链接加速仓库克隆(
git clone --local)
二、软链接(Symbolic Link)详解
1. 本质与底层机制
物理结构:
- 软链接是独立文件,拥有专属inode和数据块,数据块存储目标文件的路径字符串
- 路径长度影响空间占用(短路径存于inode内,长路径占用独立数据块)
ln -s /opt/app/bin/launcher \~/Desktop/run # 创建软链接 ls -l \~/Desktop/run # 显示指向路径:/opt/app/bin/launcher关键特性:
特性 技术原理 路径解析 访问软链接时,内核需逐级解析目标路径(额外I/O开销) 悬挂风险 目标文件被删除或移动后,软链接失效("dangling link") 灵活性 ✅ 可跨文件系统/设备
✅ 可链接目录
✅ 支持动态目标切换(如版本管理)权限模型 自身拥有独立权限( lrwxrwxrwx),但访问时受目标文件权限限制
2. 应用场景
软件版本管理:通过软链接快速切换运行时版本
ln -s /usr/bin/python3.11 /usr/bin/python # 指定默认Python版本跨设备路径整合:统一访问不同磁盘中的数据
ln -s /mnt/disk1/project /home/user/project # 跨磁盘整合路径复杂目录快捷访问:简化深层路径(如
ln -s /var/log/nginx/error.log \~/nginx_errors)
三、软硬链接核心对比
| 维度 | 硬链接 | 软链接 | 技术根源 |
|---|---|---|---|
| 物理存储 | 共享源文件inode与数据块 | 独立inode,数据块存储目标路径 | 硬链接是文件实体的别名;软链接是路径代理 |
| 跨文件系统 | ❌ 不可跨设备/分区 | ✅ 支持跨设备、网络文件系统 | 硬链接依赖inode全局唯一性;软链接仅依赖路径字符串 |
| 链接目录 | ❌ 系统禁止(防目录环) | ✅ 可自由链接目录 | 硬链接目录可能导致find等命令陷入死循环 |
| 删除目标文件 | 数据仍可通过其他硬链接访问 | 软链接失效(ENOENT错误) | 硬链接通过引用计数保护数据;软链接无计数机制 |
| 存储开销 | 极小(仅目录项) | 中等(inode + 路径数据块) | 路径越长,软链接空间占用越大 |
| 相对路径解析 | 相对于当前工作目录 | 相对于软链接所在目录 | 软链接存储绝对/相对路径字符串,解析时以链接位置为基准 |
| 性能 | ⚡️ 直接访问数据块(无解析开销) | ⚠️ 需路径解析(多次I/O) | 硬链接适合高频访问场景;软链接适合低频快捷访问 |
示例验证:
# 硬链接同步性验证 echo "Hello" > source.txt; ln source.txt hardlink.txt echo "World" >> hardlink.txt; cat source.txt # 输出"Hello World"# 软链接悬挂验证 ln -s source.txt symlink.txt; rm source.txt cat symlink.txt # 报错:No such file or directory
四、设计哲学与工程启示
硬链接:实体复用主义
- 核心思想:通过多入口共享实体数据,实现零冗余存储与数据强一致性
- 工业应用:Git对象存储、容器镜像分层(OverlayFS硬链接优化)
软链接:路径抽象代理
- 核心思想:解耦访问路径与物理位置,提供动态路由与跨域访问能力
- 工业应用:Kubernetes配置文件热切换、微服务动态路由
选择策略:
需求场景 推荐方案 原因 防误删+节省空间 硬链接 数据安全且无存储浪费 跨设备/动态目标 软链接 灵活指向任意位置 高频访问的低延迟要求 硬链接 避免路径解析开销 目录链接或版本切换 软链接 硬链接不支持目录
五、风险规避与最佳实践
1. 硬链接风险
- 循环链接预防:系统禁止目录硬链接,但用户需避免手动操作inode制造环路
- 权限管理:
chmod修改任一硬链接将影响所有关联文件
2. 软链接风险
悬挂链接检测:定期扫描失效软链接
find /path -type l ! -exec test -e {} \; -delete # 删除失效软链接路径安全:使用绝对路径创建软链接,避免移动后失效
权限隔离:软链接自身权限需与目标一致(如
chown同步所有权)
3. 混合使用案例
# 数据安全+灵活访问方案
ln bigfile.dat /backups/hardlink_backup # 硬链接防误删
ln -s /backups/hardlink_backup \~/Desktop/quick_access # 软链接快捷访问
总结:核心差异与本质价值
| 链接类型 | 本质 | 核心价值 | 典型场景 |
|---|---|---|---|
| 硬链接 | 文件实体的多个别名 | 数据强一致性 + 存储零冗余 | 防误删备份、版本库优化 |
| 软链接 | 路径的间接代理 | 动态路由 + 跨域访问 | 软件版本切换、目录快捷方式、跨盘整合 |
设计哲学启示:
- 硬链接体现 "实体共享" 思想(类比C++的引用)
- 软链接体现 "间接寻址" 思想(类比C++的指针)
2.2 问题拓展:
说到这里,也许你会有这样的问题,我们都知道每个目录下都有两个隐藏目录 . 和 .. ,既然目录不能硬链接,那为什么每个目录下都有.和..分别指向当前目录和上级目录,为什么软链接可以链接目录还不会造成死循环呢?
一、目录硬链接为何被禁止?核心矛盾与设计约束
循环引用风险
若允许目录硬链接,用户可创建指向父目录的硬链接(如
ln /parent child/link_to_parent),形成循环路径:parent/ └── child/ └── link_to_parent → parent/ # 循环指向自身遍历灾难:命令如
find或rm -rf会陷入无限循环,消耗系统资源直至崩溃
父目录唯一性破坏
目录的硬链接会创造 多个等效父目录,违反文件系统树形结构的根本原则:
/dirA/subdir 的父目录是 /dirA /dirB/hardlink 指向 /dirA/subdir → 此时 /dirA/subdir 的父目录也是 /dirB导致路径解析歧义,破坏
..的逻辑一致性
系统资源管理冲突
- 硬链接会增加目录的 引用计数(
i_nlinks) ,但目录删除需满足:- 目录为空(仅含
.和..) - 无其他硬链接指向该目录
- 目录为空(仅含
- 若允许多个硬链接指向目录,引用计数机制失效,安全删除无法保障
- 硬链接会增加目录的 引用计数(
二、. 与 .. 的特殊性:为何它们是“合法硬链接”?
操作系统内部特权
.和..是 文件系统创建目录时自动生成的硬链接,由内核直接管理:- 新建目录
/dir时,内核自动添加:/dir/.→ 硬链接指向/dir自身/dir/..→ 硬链接指向父目录
- 用户无权手动创建此类链接,规避了循环风险
- 新建目录
路径解析的安全设计
- 内核在遍历路径时 显式忽略
.和..的递归效应:- 遇到
..时直接跳转至父目录,而非重复解析当前目录 - 例如
cd ..被翻译为inode = parent_inode,无循环检查开销
- 遇到
- 内核在遍历路径时 显式忽略
引用计数的受控更新
- 目录的硬链接数由内核原子更新:
- 创建子目录
/dir/sub时:/dir的链接数 +1(因子目录的..指向它)/sub的链接数初始为 2(含.和..)
- 用户操作无法干扰此机制
- 创建子目录
- 目录的硬链接数由内核原子更新:
三、软链接链接目录为何安全?防循环机制
类型识别与递归深度控制
软链接是 独立文件,其 inode 标记为
S_IFLNK类型:$ ls -l /path/to/symlink lrwxrwxrwx 1 user group 11 Jul 28 10:00 symlink → /target/dir- 内核在遍历时识别符号链接类型,避免误认为真实目录
路径解析的熔断机制
内核限制 连续解析软链接的最大深度(通常为 8~40 次):
// Linux 内核源码:fs/namei.c #define MAXSYMLINKS 40 if (++depth > MAXSYMLINKS) return -ELOOP; // 终止遍历,返回"循环链接"错误- 防止恶意构造的循环链(如
ln -s /a /b; ln -s /b /a)
- 防止恶意构造的循环链(如
规范路径(Canonical Path)转换
系统调用(如
open())会将路径中的软链接 解析为绝对路径:/home/user/docs → 可能解析为 /mnt/disk1/docs- 循环路径会被简化为唯一标准形式(
realpath()函数)
- 循环路径会被简化为唯一标准形式(
四、设计哲学对比:安全与灵活的权衡
| 机制 | 安全设计 | 灵活性 | 代表案例 |
|---|---|---|---|
| 目录硬链接 | ❌ 禁止用户创建(防循环/父目录冲突) | ❌ 无用户操作空间 | 仅限内核管理的./.. |
| 目录软链接 | ✅ 类型识别 + 深度熔断 | ✅ 支持跨文件系统/动态目标 | ln -s /mnt/data \~/data |
./..硬链接 | ✅ 内核特权 + 路径跳转 | ❌ 仅限固定逻辑(当前/父目录) | 所有目录内置 |
核心结论:
- 目录硬链接的禁止是文件系统树形结构的必然要求,避免循环引用与父目录歧义。
.和..作为“合法硬链接” ,因内核完全掌控其创建、解析与删除,无用户干预风险。- 软链接的安全机制依赖于类型标记、深度熔断和路径规范化,以有限递归代价换取跨目录链接的灵活性。
五、运维意义:开发者与管理员须知
- 避免目录循环的实践:
- 软链接循环可通过
find -L /path -type l -exec test -e {} \; -delete清理
- 软链接循环可通过
- 硬链接的替代方案:
- 需目录级“链接”时,使用 绑定挂载(
mount --bind) 或 软链接
- 需目录级“链接”时,使用 绑定挂载(
- 特殊目录的权限管理:
- 防止用户篡改
./..:chmod 755 .仅影响当前目录,..权限由父目录控制。
- 防止用户篡改
文件系统设计的底层逻辑可概括为——通过约束机制(硬链接限制)保障基础安全,通过代理机制(软链接)扩展功能边界,而
./..则是二者平衡的典范