深入理解指针(三)
深入理解指针(三)
- 前言
- 一、数组名的理解
- 1.1 数组名与首元素地址的等价性
- 1.2 数组名的两个例外情况
- 例外1:`sizeof(数组名)`
- 例外2:`&数组名`
- 1.3 地址的本质区别:通过+1操作验证
- 二、使用指针访问数组
- 2.1 指针与数组名的等价性
- 2.2 指针下标与数组下标的等价性
- 2.3 数组的指针移动:
- (1).核心差异
- (2).关键区别
- (3).使用建议
- 三、一维数组传参的本质
- 3.1 数组传参的误区:函数内部无法获取数组长度
- 3.2 数组传参的本质:传递首元素地址
- 四、冒泡排序
- 冒泡排序的基本实现
- 五、二级指针
- 5.1 二级指针的定义
- 5.2 二级指针的操作
- 六、指针数组
- 指针数组的定义与初始化
- 七、指针数组模拟二维数组
- 7.1 模拟实现与访问
- 结语
前言
本讲将继续深入探讨指针与数组的关系、指针数组、二级指针等核心概念
一、数组名的理解
数组名是C语言中一个看似简单却暗藏玄机的概念。很多新手与小白会认为数组名就是数组的首地址,但实际情况更为复杂。但是我们接下来就来进行详细了解一下。
1.1 数组名与首元素地址的等价性
先看一组基础代码:
#include <stdio.h>
int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};printf("&arr[0] = %p\n", &arr[0]); // 打印首元素地址printf("arr = %p\n", arr); // 打印数组名return 0;
}

那么这个时候,我们会发现两者的地址是相同的
结论:数组名
arr与首元素地址&arr[0]的值完全相同,这说明在大多数情况下,数组名本质上就是数组首元素的地址。
1.2 数组名的两个例外情况
数组名并非在所有场景下都等同于首元素地址,存在两个关键例外:
但是我们先来回顾一下基础的内容:
数组的元素多少即长度是 sizeof(数组名)/sizeof(数组首元)
1个地址的字节是4或8个字节;
64位的环境下为8字节,32位环境下为4字节
解引用是修改在原来存储在指针变量的值
指针变量的类型就是对于解引用的操作权限的大小
例外1:sizeof(数组名)
#include <stdio.h>
int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};printf("%d\n", sizeof(arr)); // 计算数组名的大小return 0;
}

解析:
int类型在32位环境下占4字节,10个元素的数组总大小为10×4=40字节- 此处
sizeof(arr)中的arr代表整个数组,而非首元素地址,因此计算的是整个数组的字节数 - 若
arr是首元素地址,sizeof(arr)应返回4(32位)或8(64位),但实际结果为40,那么就验证了这种情况
例外2:&数组名
#include <stdio.h>
int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};printf("&arr[0] = %p\n", &arr[0]); // 首元素地址printf("arr = %p\n", arr); // 数组名(首元素地址)printf("&arr = %p\n", &arr); // 数组的地址return 0;
}
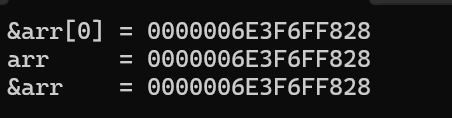
表面现象:三个地址值完全相同,容易让人误以为它们是同一个概念。
1.3 地址的本质区别:通过+1操作验证
为了揭示三者的差异,我们通过+1操作观察地址变化:
#include <stdio.h>
int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};printf("&arr[0] = %p\n", &arr[0]);printf("&arr[0] + 1 = %p\n", &arr[0] + 1);printf("arr = %p\n", arr);printf("arr + 1 = %p\n", arr + 1);printf("&arr = %p\n", &arr);printf("&arr + 1 = %p\n", &arr + 1);return 0;
}
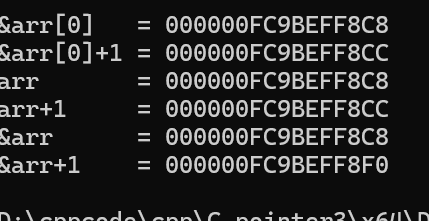
分析结果:
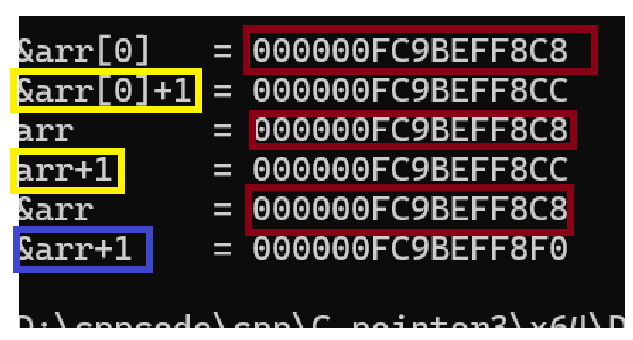
红色的均是代表的数组的首个元素;
而黄色的地址我们会发现地址多走了4个字节,那么走了一个地址,也就是走了1个元素
而蓝色的代表是走了28个,通过16进制,可以是相差了40个字节,那就是相差了10个元素
结论:
&arr[0]和arr均为首元素地址,+1后跳过1个元素(4字节)&arr是数组的地址,+1后跳过整个数组(40字节),证明其指向的是整个数组- 三者的起始地址相同,但指向的“对象”不同:
&arr[0]指向首元素,&arr指向整个数组
&arr表示的是数组指针,下一节我们会进行详细介绍;
结论:数组名arr就是数组首元素的地址
注意:但是有两个特例:
1.sizeof的括号单独放入了一个数组名的时候,数组名表示整个数组,计算出的整个数组的大小,单位是字节
2.&数组名 这里面的数组名也表示整个数组,取出的是这个数组的整体的地址
二、使用指针访问数组
数组与指针的关系密不可分,掌握指针访问数组的技巧是提升代码效率的关键。
2.1 指针与数组名的等价性
#include <stdio.h>
int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};int* p = arr; // 指针p接收数组名(首元素地址)int sz = sizeof(arr) / sizeof(arr[0]); // 计算数组长度// 方法1:通过*(p + i)访问for (int i = 0; i < sz; i++){printf("%d ", *(p + i));}printf("\n");// 方法2:通过p++移动指针访问p = arr; // 重置指针位置for (int i = 0; i < sz; i++){printf("%d ", *p);p++; // 指针后移1个元素}printf("\n");return 0;
}
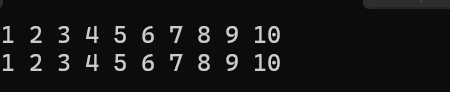
解析:
p与arr等价,均为指向首元素的指针(int*类型)*(p + i)等价于arr[i],编译器会将数组访问自动转换为指针运算p++操作使指针每次移动1个int的大小(4字节),高效遍历数组
2.2 指针下标与数组下标的等价性
#include <stdio.h>
int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};int* p = arr;int sz = sizeof(arr) / sizeof(arr[0]);printf("通过arr[i]访问:");for (int i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");printf("通过p[i]访问:");for (int i = 0; i < sz; i++){printf("%d ", p[i]);}printf("\n");return 0;
}

核心原理:
- 编译器将
arr[i]解析为*(arr + i),将p[i]解析为*(p + i) - 由于
arr和p均为int*类型的指针,因此arr[i]与p[i]完全等价 - 这一特性使得指针可以像数组一样通过下标访问,增加了代码的灵活性
2.3 数组的指针移动:
在数组的环境里,p + i 和 p++ 存在明显不同:
(1).核心差异
p + i:它不会改变指针p原本的值,只是计算出指针p向后移动i个元素后的地址p++:会让指针p自身的值增加,也就是让指针向后移动一个元素的位置,并且返回的是p原来的值
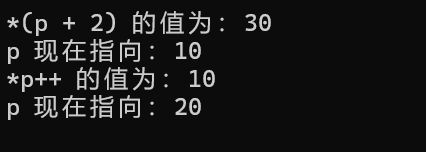
#include <stdio.h>int main() {int arr[5] = {10, 20, 30, 40, 50};int *p = arr; // 此时p指向arr[0]// 示例1:使用p + iprintf("*(p + 2) 的值为:%d\n", *(p + 2)); // 输出30printf("p 现在指向:%d\n", *p); // 输出10,说明p的值没有变化// 示例2:使用p++printf("*p++ 的值为:%d\n", *p++); // 输出10,先取值,然后p向后移动printf("p 现在指向:%d\n", *p); // 输出20,表明p已经移动到了下一个元素
}
(2).关键区别
| 操作 | 是否改变p的值 | 返回值 | 常见使用场景 |
|---|---|---|---|
p + i | 否 | p 后面第 i 个元素的地址 | 用于随机访问数组元素 |
p++ | 是(p 会增加) | p 原来的值 | 用于遍历数组(比如在循环里) |
(3).使用建议
- 当你需要访问数组里的某个特定元素,同时又不想改变指针当前的位置时,应该使用
p + i - 若你要逐个遍历数组元素,并且希望指针能够自动移动到下一个元素,那么可以使用
p++
理解这两者的差异,这是对于正确操作数组指针是很重要的
三、一维数组传参的本质
数组传参是初学者容易混淆的知识点,很多人误以为数组会“完整传递”给函数,实际情况并非如此。
3.1 数组传参的误区:函数内部无法获取数组长度
#include <stdio.h>// 尝试在函数内部计算数组长度
void print_arr(int arr[])
{int sz2 = sizeof(arr) / sizeof(arr[0]); // 错误做法for (int i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};int sz1 = sizeof(arr) / sizeof(arr[0]); // 正确计算长度printf("main函数中sz = %d\n", sz);print_arr(arr); // 传递数组名return 0;
}

我们发现打印结果为2个,那么应该函数print_arr 的数组长度为1个,所以我们会发现了在函数中是没有办法去求出数组的长度的
原因:
数组在传参的时候,不会将整个数组传递过去,arr是数组的首个元素,所以上述的传递的就是arr的首个元素的地址
3.2 数组传参的本质:传递首元素地址
核心结论:
- 数组传参时,编译器会将数组名转换为首元素地址,因此函数形参本质上是一个指针
- 函数形参的
int arr[]写法只是语法糖,等价于int* arr
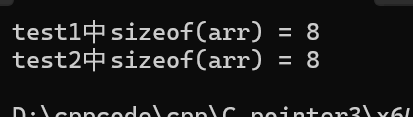
#include <stdio.h>// 两种形参写法等价
void test1(int arr[])
{printf("test1中sizeof(arr) = %d\n", sizeof(arr)); // 指针大小
}void test2(int* arr)
{printf("test2中sizeof(arr) = %d\n", sizeof(arr)); // 指针大小
}int main()
{int arr[10] = {0};test1(arr);test2(arr);return 0;
}
正确的数组传参方式:
必须同时传递数组首地址和长度:
#include <stdio.h>// 正确写法:接收指针和长度
void print_arr(int arr[], int sz)
{for (int i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};int sz = sizeof(arr) / sizeof(arr[0]);print_arr(arr, sz); // 同时传递地址和长度return 0;
}
四、冒泡排序
冒泡排序是经典的排序算法,核心思想是通过两两相邻元素的比较与交换,使最大(或最小)的元素“浮”到数组末尾。结合指针知识,我们可以更高效地实现冒泡排序
冒泡排序的基本实现
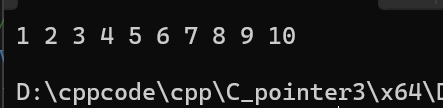
#include <stdio.h>// 冒泡排序:升序
void bubble_sort(int arr[], int sz)
{// 外层循环:控制排序趟数(n-1趟)for (int i = 0; i < sz - 1; i++){// 内层循环:每趟比较的次数(每趟减少1次)for (int j = 0; j < sz - i - 1; j++){// 相邻元素比较,前大后小则交换if (arr[j] > arr[j + 1]){int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}}
}int main()
{int arr[] = {3,1,7,5,8,9,0,2,4,6};int sz = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, sz); // 排序// 打印结果for (int i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}
算法解析:
- 外层循环
i从0到sz-2,共sz-1趟,每趟确定一个最大元素的位置 - 内层循环
j从0到sz-i-2,每趟比较次数随i增加而减少(已排好的元素无需再比较) - 每次比较
arr[j]和arr[j+1],若逆序则交换,确保大元素向后移动
当数组已经有序时,基本实现仍会执行所有趟数,效率较低
优化思路是:若某趟未发生交换,说明数组已有序,可提前退出
#include <stdio.h>void bubble_sort(int arr[], int sz)
{for (int i = 0; i < sz - 1; i++){int flag = 1; // 标志位:1表示有序,0表示无序for (int j = 0; j < sz - i - 1; j++){if (arr[j] > arr[j + 1]){int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;flag = 0; // 发生交换,标记为无序}}if (flag == 1) // 若本趟无交换,直接退出{break;}}
}
int main()
{int arr[] = {1,2,3,5,4,6,7,8,9,10}; // 接近有序的数组int sz = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, sz);for (int i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}
优化效果:
- 对于上述接近有序的数组,基本实现需要9趟,优化后只需2趟(第1趟交换5和4,第2趟无交换则退出)
- 时间复杂度从
O(n²)优化为最佳情况O(n)(完全有序时)
五、二级指针
指针变量也是变量,因此也有地址。二级指针就是用于存放一级指针地址的变量。
5.1 二级指针的定义
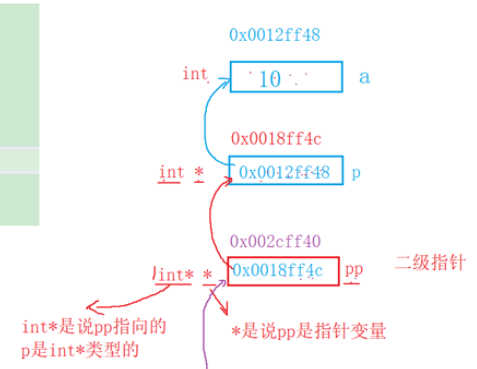
#include <stdio.h>int main()
{int a = 10; // 普通变量int* p = &a; // 一级指针:存放a的地址int** pp = &p; // 二级指针:存放p的地址// 打印各变量的地址和值printf("a的地址:&a = %p,a的值:a = %d\n", &a, a);printf("p的地址:&p = %p,p的值:p = %p(指向a)\n", &p, p);printf("pp的地址:&pp = %p,pp的值:pp = %p(指向p)\n", &pp, pp);return 0;
}

5.2 二级指针的操作
通过二级指针可以间接访问和修改原变量的值:
#include <stdio.h>int main()
{int a = 10;int* p = &a;int** pp = &p;// 访问a的值printf("a = %d\n", a); // 直接访问printf("*p = %d\n", *p); // 一级指针访问printf("**pp = %d\n", **pp); // 二级指针访问// 修改a的值**pp = 20; // 等价于*p = 20; 等价于a = 20;printf("修改后a = %d\n", a);// 修改p的指向(让p指向新变量b)int b = 30;*pp = &b; // 等价于p = &b;printf("*p = %d(现在指向b)\n", *p);return 0;
}

操作规则:
*pp等价于p(通过二级指针访问一级指针)**pp等价于*p等价于a(通过二级指针访问原变量)- 二级指针的主要用途是在函数中修改一级指针的指向
(如动态内存分配中调整指针指向)
六、指针数组
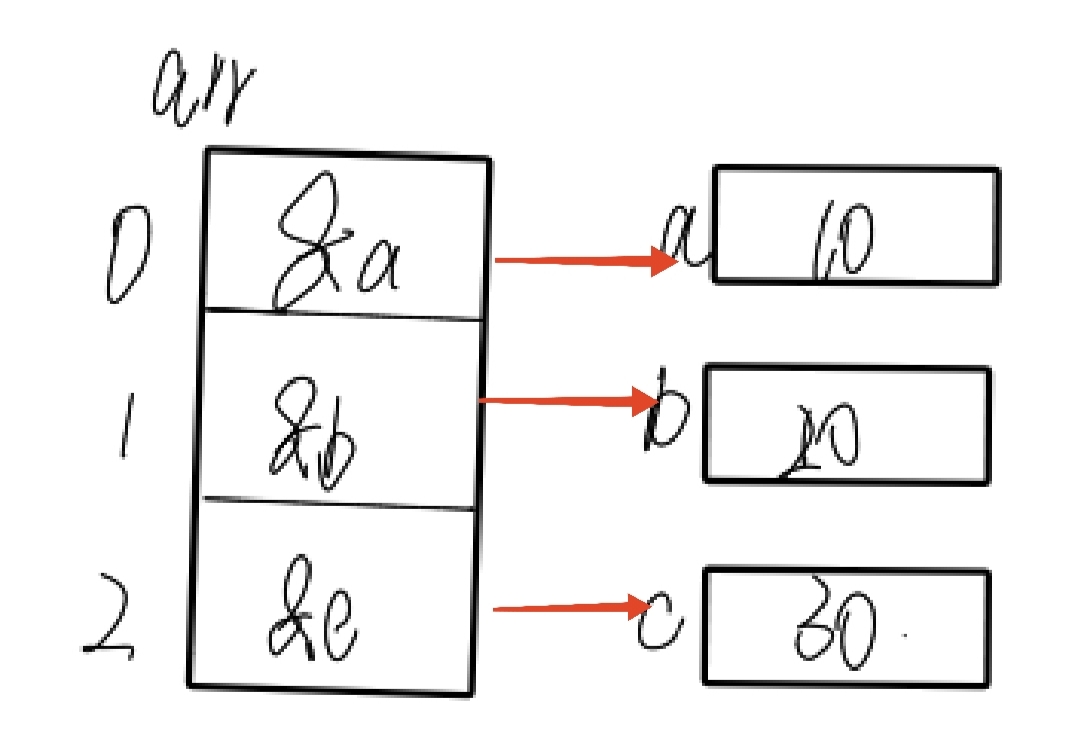
指针数组是数组,其元素是指针(地址)
类比于整型数组是存放整型的数组,字符数组是存放字符的数组,那么指针数组就是专门用于存放指针(地址)的数组。
例如图示:
指针数组的定义与初始化
#include <stdio.h>int main()
{int a = 10, b = 20, c = 30;// 指针数组:每个元素都是int*类型的指针int* arr[3] = {&a, &b, &c}; // 存放a、b、c的地址// 遍历指针数组,访问指向的变量值for (int i = 0; i < 3; i++){printf("%d ", *(arr[i])); // 解引用指针数组元素}return 0;
}

总结:
int* arr[3]中,arr是数组,包含3个元素,每个元素类型为int*- 数组名
arr是指针的指针(int**类型),因为其元素是int*类型
七、指针数组模拟二维数组
二维数组在内存中是连续存储的,而指针数组可以通过存放多个一维数组的首地址,模拟二维数组的访问方式(尽管内存不连续)。
7.1 模拟实现与访问
#include <stdio.h>int main()
{// 定义3个一维数组int arr1[] = {1,2,3,4,5};int arr2[] = {2,3,4,5,6};int arr3[] = {3,4,5,6,7};// 指针数组:存放3个一维数组的首地址int* parr[3] = {arr1, arr2, arr3};// 模拟二维数组访问:parr[i][j]for (int i = 0; i < 3; i++) // 行{for (int j = 0; j < 5; j++) // 列{printf("%d ", parr[i][j]); // 等价于*(*(parr + i) + j)}printf("\n");}return 0;
}
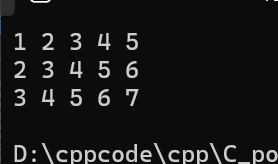
访问原理:
parr[i]获取第i个一维数组的首地址(如arr1)parr[i][j]等价于*(parr[i] + j),即访问第i个数组的第j个元素
结语
指针的学习没有捷径,唯有多写、多调、多思考。这一讲内容就先到这里了,当然如果有什么地方不足的,欢迎大家在评论区中指出不足,下一讲我们将继续探讨指针的高级应用,感谢大家支持!