01人工智能中优雅草商业实战项目视频字幕翻译以及声音转译之底层处理逻辑阐述-卓伊凡|莉莉
01人工智能中优雅草商业实战项目视频字幕翻译以及声音转译之底层处理逻辑阐述-卓伊凡|莉莉
今天优雅草卓伊凡收到商业实战项目讨论,关于处理视频中对配音以及字幕直接进行AI处理,在之前基本都是人工处理,工作量巨大,甲方需要让我们制作一款软件来实现自动化处理,每天要处理的视频按1000个视频左右来计算,那么我们要处理这件事,首先我们对底层逻辑必须要有清晰认知,
以下是人工智能处理视频中语音语言转换和字幕翻译的底层逻辑详解,从音频分离到最终字幕生成的完整技术流程:
一、语音语言转换的底层逻辑
1. 音频分离与预处理
- 步骤:
- 音轨提取:使用FFmpeg等工具从MP4中分离音频流(如WAV格式)。
- 降噪处理:通过滤波算法(如谱减法)去除背景噪声,提升语音清晰度。
- 分帧处理:将音频切分为20-40ms的短帧(如STFT时频变换),供模型逐段分析。
这一层通常用处理软件 也可以手动处理,诸如AU,剪映之类。
2. 语音识别(ASR)

- 核心模型:
- 端到端模型(如Whisper、Conformer):直接输入音频波形,输出文本序列。
- 编码器-解码器结构:
# 伪代码示例(Whisper架构)
audio_embedding = Encoder(audio_waveform) # 提取语音特征
text_tokens = Decoder(audio_embedding) # 生成文本- 关键技术:
- 声学模型:将语音信号映射为音素(如CTC损失函数)。
- 语言模型:纠正发音相似词(如GPT-3用于上下文修正)。
3. 语音翻译(SLT, Speech-to-Text Translation)
- 直接翻译模型(如Google的Translatotron):
- 输入语音→输出另一种语言的语音(无需中间文本)。
- 缺点:训练数据稀缺,效果不如分步方案。
- 分步翻译(主流方案):
、

- TTS合成(如VITS、Tacotron2):将英文文本转为语音,保留原说话人音色(需音色克隆技术)。
4. 音视频对齐
- 时间戳匹配:
- ASR输出的文本带时间戳(如每句话的起止时间)。
- 合成英文语音时,按原时间戳分段生成,确保口型同步。
二、字幕翻译的底层逻辑
1. 字幕提取与时间轴处理
- 硬字幕提取(如OCR技术):
- 使用CNN+LSTM模型(如CRNN)识别视频帧中的文字。

- 软字幕处理:直接解析SRT/ASS文件,保留时间轴标记。
# SRT文件格式示例
1
00:00:05,000 --> 00:00:10,000
你好,世界!2. 文本翻译
- 神经机器翻译(NMT)模型:
- 架构:Transformer(自注意力机制)
# 伪代码:Transformer编码器-解码器
encoded = Encoder("你好,世界!") # 编码中文语义
decoded = Decoder(encoded, target_lang="en") # 解码为英文
output = "Hello, world!"- 上下文处理:
- 长视频字幕需分段翻译,但使用缓存机制维持上下文连贯性(如缓存前5句的隐藏状态)。
3. 字幕生成与嵌入
- 动态排版:
- 根据英文文本长度调整字幕显示时间(如长句自动拆分多行)。
- 视频合成:
- 使用libass等库将英文字幕烧录到视频中,或生成外挂字幕文件。
三、关键技术挑战与解决方案
- 语音翻译的语义丢失
- 解决方案:
- 在翻译阶段引入上下文感知(如GPT-4的对话记忆能力)。
- 使用领域适配(如医疗视频需加载专业术语库)。
- 多说话人场景
- 解决方案:
- 声纹分离(如PyAnnote聚类区分说话人)。
- 为每个说话人单独生成字幕(标记Speaker 1/2)。
- 低质量音频处理
- 解决方案:
- 数据增强训练(如添加噪声的对抗训练)。
- 语音增强模型(如NVIDIA的RNNoise)。
- 文化差异表达
- 解决方案:
- 本地化翻译模型(如将“龙”译为“dragon”或“loong”按受众选择)。
四、典型AI模型与工具链
- 开源工具
- ASR:Whisper、DeepSpeech
- 翻译:OPUS-MT、MarianNMT
- TTS:VITS、Coqui TTS
- 字幕工具:Aegisub(手动校对)
- 端到端商业API
- Azure Video Indexer:直接输入视频,输出多语言字幕+翻译。
- Google Media Translation API:实时语音翻译+字幕生成。
五、完整流程示例
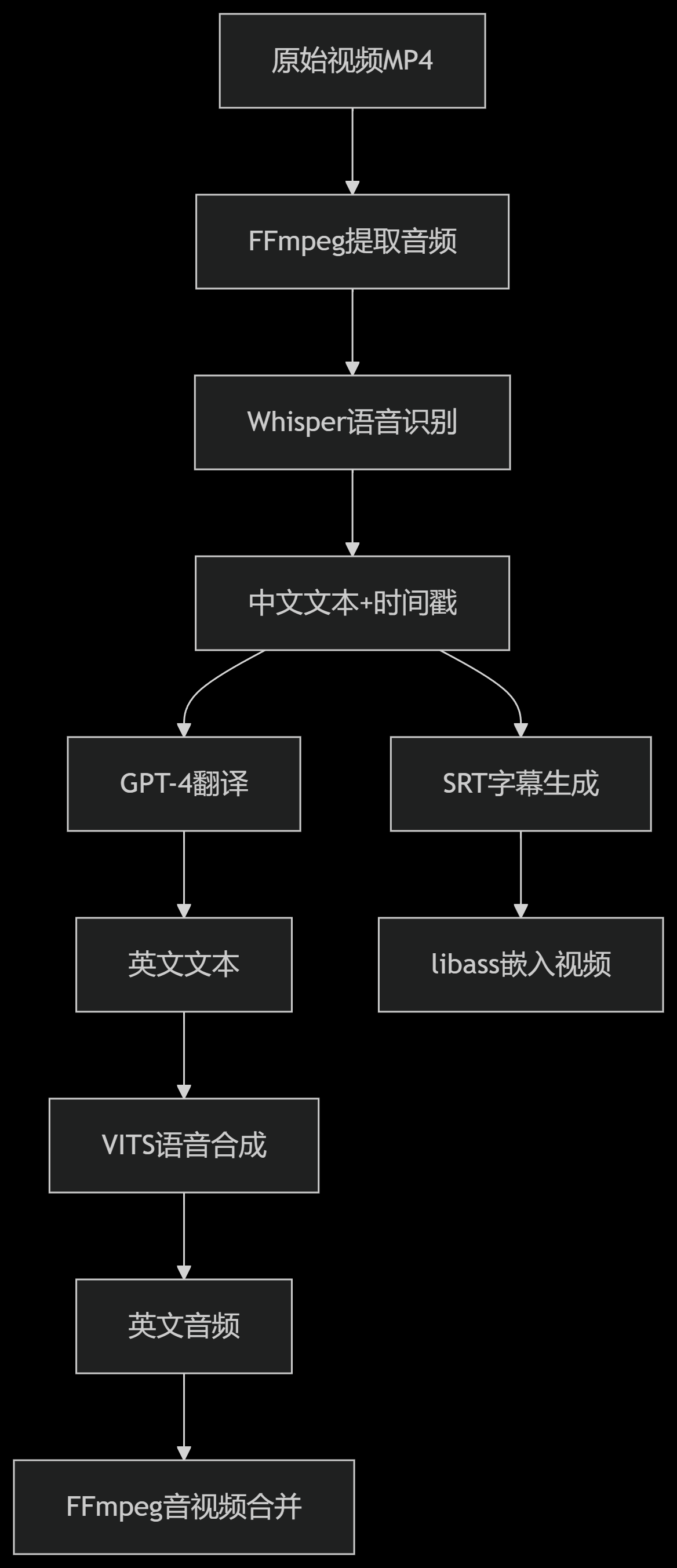
所以 其实看似一个很简单的功能 并没有你们想象中那么简单,就算是要通过各种AI工具也是有一个过程和流程的,下一篇我们具体实现方案。