用KNN实现手写数字识别:基于 OpenCV 和 scikit-learn 的实战教学 (超级超级超级简单)
用KNN实现手写数字识别:基于 OpenCV 和 scikit-learn 的实战教学
在这篇文章中,我们将使用 KNN(K-Nearest Neighbors)算法对手写数字进行分类识别。我们会用 OpenCV 读取图像并预处理数据,用 scikit-learn 构建并训练模型,最终识别新的数字图像。
为什么像素可以被代码读取为数据:
图像的本质:像素的数字矩阵
任何数字图像(如照片、截图、手写数字图片)都是由无数个微小的 “像素点”(Pixel)组成的
每个像素点的数值含义:
- 对于灰度图(如代码中的手写数字),每个像素用一个 0-255 的整数表示亮度:0 代表纯黑,255 代表纯白,中间值表示不同深浅的灰色。
- 对于彩色图(如 RGB 格式),每个像素由三个数值(R、G、B)组成,分别对应红、绿、蓝三种颜色的亮度,组合后呈现出各种颜色。
(可以在调试时看一看代码里的‘gray’参数里面 单个数字图像的矩阵)
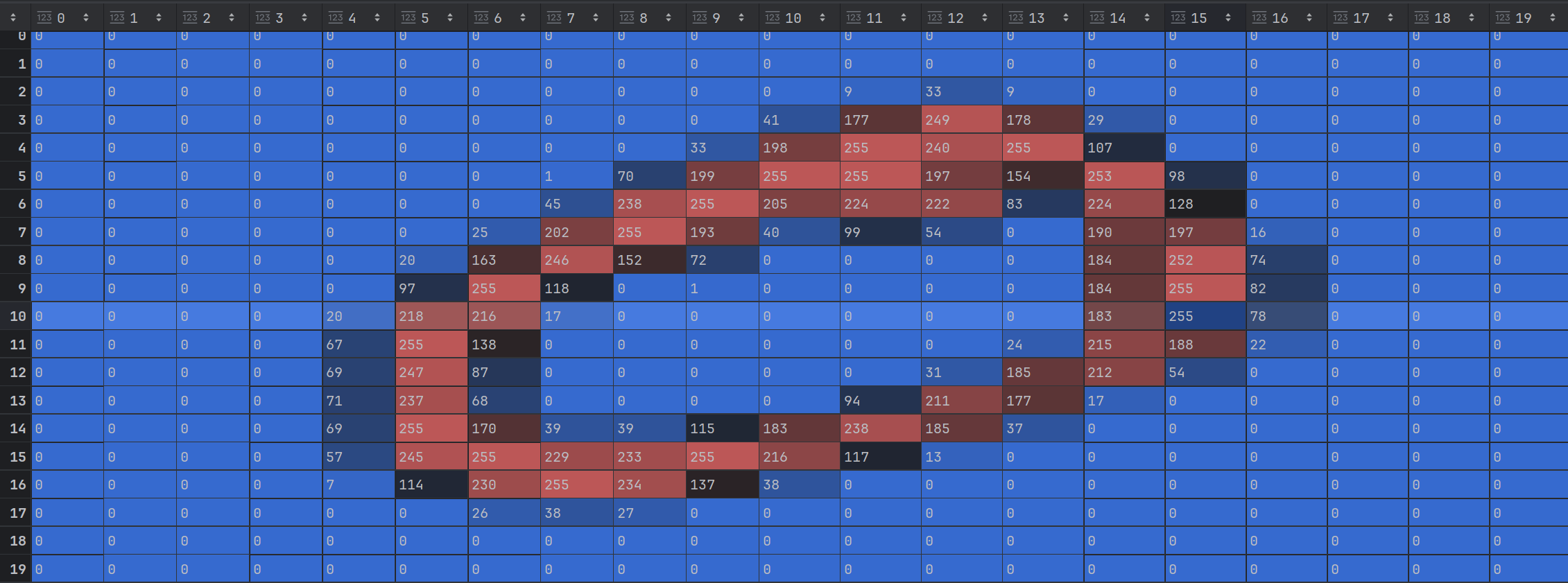
此20×20 像素的数字图像就是一个数字矩阵显示出的一个大大的 0
使用的数据集
我们使用的是一个包含 5000 个手写数字(0-9) 的图像文件(digits5000.png),每种数字500个,总共10类。图像被排布成了一个 50 行 × 100 列 的网格,每个小格是一个 20×20 像素的数字图像。
数据图像:
保存下面代码所需的三张图片:

![]()
![]()
上面的 ‘3’,‘6’ 图片可在‘开始’里的‘画图’中,可以创建我们想要自定义的数字图片:
然后使用画笔写一个数字后(笔粗一点):
把比例调到 20×20 像素
即可得到。
完整代码:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import cv2# 读取包含5000个手写数字的大图,每个数字为20x20像素
img = cv2.imread('digits5000.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图# 将大图分割为50行100列的小单元格,每个单元格包含一个手写数字
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]# 将单元格列表转换为四维数组: (50行, 100列, 20像素高, 20像素宽)
x = np.array(cells)# 准备训练集和测试集数据
# 前50列作为训练集,后50列作为测试集
# 数据重塑为: (样本数, 特征数),每个样本包含400个像素值
train = x[:,:50].reshape(-1,400)
test = x[:,50:].reshape(-1,400)# 创建标签数据
n = np.arange(10) # 创建数字0-9的数组
# 每个数字对应250个样本(50行×5列),生成训练标签
tags = np.repeat(n,250)
tag = tags[:,np.newaxis] # 转换为二维数组,形状为(2500, 1)# 创建并训练KNN分类器,使用k=5最近邻
knn = KNeighborsClassifier(n_neighbors=5) #给初学者的建议:在此处设置断点 或 直接在import处设置断点,开启调试一行一行地运行,更好的看到每一个参数的变化
knn.fit(train, tag)# 评估模型在训练集上的准确率
predictions_train = knn.predict(train) #此行结果没有运行,建议在开启调试,可看到
accuracy_train = knn.score(train, tag)
print(f"训练集准确率: {accuracy_train:.4f}")# 评估模型在测试集上的准确率
predictions_test = knn.predict(test)
accuracy_test = knn.score(test, tag)
print(f"测试集准确率: {accuracy_test:.4f}")# 预测外部数字3的图像
digit3 = cv2.imread('digit3.png')
digit3gray = cv2.cvtColor(digit3, cv2.COLOR_BGR2GRAY)
digit3test = digit3gray.reshape(-1,400) # 重塑为模型期望的输入格式
predictions_digit3 = knn.predict(digit3test)
print(f"预测数字3的结果: {predictions_digit3}")# 预测外部数字6的图像
digit6 = cv2.imread('digit6.png')
digit6gray = cv2.cvtColor(digit6, cv2.COLOR_BGR2GRAY)
digit6test = digit6gray.reshape(-1,400) # 重塑为模型期望的输入格式
predictions_digit6 = knn.predict(digit6test)
print(f"预测数字6的结果: {predictions_digit6}")红色断点:

调试:
点击 单步执行 或 其他 ,多尝试尝试
点击“作为...查看”即可清晰查看
所需库导入
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import cv2
numpy: 用于矩阵操作。sklearn.neighbors.KNeighborsClassifier: 实现KNN分类器。cv2: OpenCV库,用于图像读取与处理。
图像加载与预处理
img = cv2.imread('digits5000.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imread()读取图像。cv2.cvtColor()将图像从彩色(BGR)转换为灰度(GRAY),便于处理。
图像分割成小数字图块
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
x = np.array(cells)
使用
np.vsplit()将图像竖直切成50行(每行包含100个数字)。对每行使用
np.hsplit()水平切分成100列,最终每个小格是一个20x20的数字图像。得到的
x是一个形状为(50, 100, 20, 20)的数组。
构建训练集与测试集
train = x[:,:50].reshape(-1,400)
test = x[:,50:].reshape(-1,400)
将每个 20×20 图像展开为 1×400 的一维向量。
前 50 列作为训练集,后 50 列作为测试集。
train和test的形状均为(2500, 400)。
构造标签
n = np.arange(10) #(0123456789)
tags = np.repeat(n,250) #每个数字重复250次 -> [0,...0,1,...,1,...9,...9]
tag = tags[:,np.newaxis] #添加新维度,变成列向量
# test_tag = np.repeat(n,250)[:np.newaxis]
tags是长度为 2500 的一维标签数组。tag是形状为(2500, 1)的列向量,作为训练和测试的真实标签。
为什么重复250次,因为我们把数据从中间对半切开,每个数字有500个,左二百五十为训练集,右二百五十个为测试集。
所以其实训练集和测试集的标签是一样的,标签就是每一个20x20数字图像所显示的数字。
训练模型并评估准确率
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(train, tag)predictions_train = knn.predict(train)
accuracy_train = knn.score(train, tag)
print(accuracy_train)predictions_test = knn.predict(test)
accuracy_test = knn.score(test, tag)
print(accuracy_test)
初始化一个 KNN 分类器,选择
k=5。使用
.fit()训练模型。使用
.predict()和.score()对训练集和测试集进行预测和评分。打印准确率:理论上训练集精度应很高,测试集略低(但通常也超过 97%)。
识别自定义手写数字
digit3 = cv2.imread('digit3.png') #图片中的数字是3
digit3gray = cv2.cvtColor(digit3, cv2.COLOR_BGR2GRAY)
digit3test = digit3gray.reshape(-1,400)
predictions_digit3 = knn.predict(digit3test)
print(predictions_digit3)digit6 = cv2.imread('digit6.png') #图片中的数字是6
digit6gray = cv2.cvtColor(digit6, cv2.COLOR_BGR2GRAY)
digit6test = digit6gray.reshape(-1,400)
predictions_digit6 = knn.predict(digit6test)
print(predictions_digit6)
读取两张额外图像
digit3.png和digit6.png。将其转换为灰度、再reshape成与训练数据一致的
(1, 400)形状。使用模型预测数字类别。
总结
我们用 KNN 成功实现了手写数字的分类识别,关键步骤包括:
图像预处理和切分
标签构造与数据 reshape
使用
KNeighborsClassifier建模预测未知图像的数字类别