PostgreSQL并发控制
文章目录
- 1 事务隔离
- 1_读已提交
- 2_可重复读
- 3_可序列化
- 4_MVCC
- 5_保存点
- 2 锁
- 1_ 表级锁
- 2_行级锁
- 3_页级锁
PostgreSQL 通过多版本并发控制(MVCC)机制,为开发者提供了高效的并发访问管理工具。
MVCC 的核心理念是为每个 SQL 语句提供一个数据快照,使其在执行期间看到的数据始终一致,从而避免由于并发事务修改数据而产生的不一致问题。
与传统数据库依赖加锁不同,MVCC 避免了读写之间的冲突:查询不会阻塞写操作,写操作也不会阻塞查询,即使在可序列化快照隔离(SSI)这种最高级别的事务隔离中,这种读写无冲突的特性也依然保持。
虽然 PostgreSQL 也支持表级和行级锁,供需要显式控制并发的场景使用,但大多数情况下,恰当使用 MVCC 能够提供更优的性能。
此外,还应由应用定义相关的咨询锁,用于跨事务管理资源的并发控制。
1 事务隔离
SQL标准定义了四种隔离级别:
脏读:一个事务读取了其他事务未提交写入的数据。
不可重复读:一个事务重新读取了之前读取过的数据,发现数据已被另一个事务修改(自初始读取以来其他事务已提交)。
幻读:一个事务重新执行一个返回满足搜索条件的一组行的查询,并发现由于另一个最近提交的事务而导致满足条件的行集发生了变化。
序列化异常:成功提交一组事务的结果与依次运行这些事务的所有可能顺序不一致。
SQL 标准和 PostgreSQL 实现的事务隔离级如下表:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 序列化异常 |
|---|---|---|---|---|
| 读未提交 | 允许,但不在 PG 中 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 允许,但不在 PG 中 | 可能 |
| 可序列化 | 不可能 | 不可能 | 不可能 | 不可能 |
PostgreSQL 中内部只实现了三种不同的隔离级别,读未提交模式的行为和读已提交是相同的。
也就是说提供“读未提交”模式只是为了完整性,可以通过如下命令设置隔离级别为四种标准事务隔离级别中的任意一种:
SET transaction ISOLATION LEVEL SERIALIZABLE;
-- ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
注意:如果执行 SET TRANSACTION 之前没有 START TRANSACTION 或者 BEGIN,它会发出一个警告并且不会有任何效果(SET TRANSACTION can only be used in transaction blocks)。
会话默认的事务模式也可以通过配置参数 default_transaction_isolation、 default_transaction_read_only 和 default_transaction_deferrable 来设置或检查。
还有一个问题就是:对一个序列的修改(以及用 serial 声明的一列的计数器)是立刻对所有其他事务可见的,也就是说这一序列被修改时是不会回滚的(插入一个行,序列被用了,回滚后行消失,但是序列号加一了,不会回滚)。
测试数据准备,每个隔离级别前重新初始化数据
DROP TABLE IF EXISTS test_data;
CREATE TABLE test_data (id SERIAL PRIMARY KEY,name TEXT,value INTEGER
);
INSERT INTO test_data (name, value) VALUES ('A', 1), ('B', 2), ('C', 3);
1_读已提交
“读已提交”是 PostgreSQL 中的默认隔离级别。
set default_transaction_isolation = "read committed";
每条 SQL 语句在执行时,看到的是开始执行时刻的数据库快照,不会看到未提交数据。
-- 会话1:
BEGIN;
UPDATE test_data SET value = 100 WHERE name = 'A';-- 会话2:
SELECT * FROM test_data WHERE name = 'A'; -- value 仍然为 1,因为会话1还未提交-- 会话1:
COMMIT;-- 会话2:
SELECT * FROM test_data WHERE name = 'A'; -- 现在看到 value = 100
同一事务中前面语句提交的更改,后续语句可见。
-- 会话1:
BEGIN;
UPDATE test_data SET value = 200 WHERE name = 'B';
SELECT * FROM test_data WHERE name = 'B'; -- 可见 value = 200
ROLLBACK;
并发事务提交的数据,可能在事务内的后续语句中变得可见(因为每条语句都刷新快照)。
-- 会话1:
BEGIN;
SELECT * FROM test_data WHERE name = 'C'; -- value = 3-- 会话2:
BEGIN;
UPDATE test_data SET value = 999 WHERE name = 'C';
COMMIT;-- 会话1:
SELECT * FROM test_data WHERE name = 'C'; -- value = 999(可见了)
COMMIT;
不带 FOR UPDATE 的 SELECT 只看查询开始前已经提交的数据,不会看到未提交的或执行中事务所做的更改(非当前读)。
-- 会话1:
BEGIN;
UPDATE test_data SET value = 888 WHERE name = 'A';-- 会话2:
BEGIN;
SELECT * FROM test_data WHERE name = 'A'; -- 看不到 888,value 仍是旧值
SELECT * FROM test_data WHERE name = 'A' FOR UPDATE; -- 阻塞,等到会话1提交后看到 value 888
ROLLBACK;-- 会话1:
ROLLBACK;
修改行为(UPDATE / DELETE / SELECT FOR UPDATE):
- 在定位目标行时也是基于执行时的快照。
- 若目标行正在被其它事务修改,该命令会等待对方提交或回滚:
- 若对方回滚:这行变得可更新。
- 若对方提交:系统会重新验证该行是否仍符合查询条件,决定是否更新或跳过。
-- 会话1:
BEGIN;
UPDATE test_data SET value = 777 WHERE name = 'B';-- 会话2:
BEGIN;
UPDATE test_data SET value = 666 WHERE name = 'B'; -- 会被阻塞
-- 等待会话1提交或回滚-- 会话1:
ROLLBACK;-- 会话2:
-- 被唤醒,更新成功,value = 666
COMMIT;
INSERT 带有 ON CONFLICT DO XX 行为的子句类似(冲突解决式插入语句):
ON CONFLICT DO UPDATE:即使存在冲突事务不可见,也会尝试更新。
-- 保证唯一约束存在:
CREATE UNIQUE INDEX ON test_data(name);-- 会话1:
BEGIN;
INSERT INTO test_data(name, value) VALUES ('D', 4);
-- 不提交-- 会话2:尝试插入 name = 'D',如果表中已经有 name = 'D',
-- 那就更新它的 value 字段为 999,而不是插入失败
INSERT INTO test_data(name, value) VALUES ('D', 999)
ON CONFLICT (name) DO UPDATE SET value = EXCLUDED.value; -- 会被阻塞直到会话1提交/回滚-- 会话1:
ROLLBACK;-- 会话2:
-- 插入成功,value = 999
ON CONFLICT DO NOTHING:如果存在看不见的冲突(因并发事务),可能什么都不做。
-- 会话1:
BEGIN;
INSERT INTO test_data(name, value) VALUES ('E', 5);
-- 不提交-- 会话2:
INSERT INTO test_data(name, value) VALUES ('E', 100)
ON CONFLICT DO NOTHING; -- 由于冲突行不可见,插入失败,但无报错
-- 实际什么也没做
读已提交级别下会存在一些潜在问题:
- 每条命令独立快照:同一事务中的连续操作,可能因并发修改导致行为不一致。
- 复杂查询(如涉及集合、范围、聚合等)可能会因并发变动而产生不符合预期的结果。
- 例如两个事务同时更新同一账户余额,行为是可控的;
但一个事务更新所有 hits +1,另一个事务删除 hits=10 的行时,就可能导致该行“消失”。
-- 重新初始化数据:
DELETE FROM test_data;
INSERT INTO test_data(name, value) VALUES ('W1', 9), ('W2', 10);-- 会话1:
BEGIN;
UPDATE test_data SET value = value + 1; -- 所有行变成 10 和 11,但未提交-- 会话2:
DELETE FROM test_data WHERE value = 10; -- 由于快照中只有旧值,找不到任何 value=10 的行
-- 实际 DELETE 什么也没删除-- 会话1:
COMMIT;-- 会话2:
SELECT * FROM test_data; -- DELETE 没有作用,所有数据都还在
这个示例稍微让我大脑转了一下,当时不理解为什么删除失败,无论是更新前还是更新后不都是有满足 value=10 的条件吗?
主要就是因为 快照隔离 + 并发未提交数据不可见,看起来这么说有点高端。
其实就是会话2删除时是基于旧值的也就是数据还没加一,还是(‘W1’, 9), (‘W2’, 10)的时候的,所以它要删除的是 W2。
但是 W2 的最新版本实际上在会话1中被更新为 11,这个新版本是不可见的,而旧版本被标记为“已被更新”,也不能再被访问。
会话1提交后 DELETE 结束阻塞,W2不满足条件了, 没有可见的 value=10 的行 ,最后什么也没删除,如果是回滚就能成功删了。
既然如此,如果希望 DELETE 能等会话1提交后再判断怎么办?
可以使用:
-- 阻塞等待最新结果
SELECT * FROM test_data WHERE value = 10 FOR UPDATE;
-- 基于最新结果删除
DELETE FROM test_data WHERE value = 10;
或者使用更高的隔离级别,比如 REPEATABLE READ 或 SERIALIZABLE,不过这可能带来锁竞争和性能成本。
2_可重复读
可重复读隔离级别仅能看到事务开始之前提交的数据;从不看到未提交的数据或其他事务中途提交的数据。
-- 设置默认隔离级别
set default_transaction_isolation = "repeatable read";
show default_transaction_isolation;
PostgreSQL 在执行事务的第一个查询(非事务控制语句) 时,会创建一个数据库快照(snapshot)。
后续所有 SQL 查询(SELECT, UPDATE, DELETE, SELECT FOR UPDATE 等)都基于这个快照执行,看不到其他事务后续对数据库的改动。
这样,哪怕别的事务后续提交了新数据,当前事务也看不到:
-- 会话1:
BEGIN ISOLATION LEVEL REPEATABLE READ;
SELECT * FROM test_data; -- 看到 A=1, B=2, C=3-- 会话2:
BEGIN;
INSERT INTO test_data(name, value) VALUES ('D', 4);
COMMIT;-- 回到会话1:
SELECT * FROM test_data; -- 仍然只有 A=1, B=2, C=3,看不到 D=4
COMMIT;
每个查询能看到当前事务中之前自己写入的修改,即使还没提交:
-- 会话1:
BEGIN ISOLATION LEVEL REPEATABLE READ;
INSERT INTO test_data(name, value) VALUES ('E', 5);
SELECT * FROM test_data WHERE name = 'E'; -- 可见刚刚写入的 E=5
ROLLBACK;
SQL 标准规定 REPEATABLE READ 只需避免“不可重复读”和“脏读”,但 PostgreSQL 实现中还避免了“幻读”,接近 Serializable 的效果。
唯一可能发生的问题是:两个事务互相依赖彼此的修改,会冲突被回滚(即所谓的“serialization failure”)。
-- 会话1:
BEGIN ISOLATION LEVEL REPEATABLE READ;
SELECT COUNT(*) FROM test_data WHERE value = 99; -- 结果为0-- 会话2:
BEGIN;
INSERT INTO test_data(name, value) VALUES ('X', 99);
COMMIT;-- 回到会话1:
SELECT COUNT(*) FROM test_data WHERE value = 99; -- 仍为0,不可见 X
COMMIT;
可重复读与读已提交(READ COMMITTED)的最大区别是:整个事务用一个固定快照。
UPDATE、DELETE、SELECT FOR UPDATE 等命令查找行也是基于快照执行。
即使想要更新或锁定一行,也只能作用于在事务快照中看得见的那一版数据:
-- 初始化:
UPDATE test_data SET value = 10 WHERE name = 'A'; -- 确保 A=10-- 会话1:
BEGIN ISOLATION LEVEL REPEATABLE READ;
SELECT * FROM test_data; -- 查询数据-- 会话2:
BEGIN;
UPDATE test_data SET value = 30 WHERE value = 10; -- 成功更新
COMMIT;-- 会话1:
UPDATE test_data SET value = 20 WHERE value = 10; -- 更新失败
COMMIT;
-- could not serialize access due to concurrent update
如果当前事务发现目标行已被其他事务更新了,就等它结束;如果其它事务已提交修改,当前事务则会被回滚:
-- 初始化:
UPDATE test_data SET value = 100 WHERE name = 'B';-- 会话1:
BEGIN ISOLATION LEVEL REPEATABLE READ;
UPDATE test_data SET value = 101 WHERE name = 'B';-- 会话2:
BEGIN ISOLATION LEVEL REPEATABLE READ;
UPDATE test_data SET value = 102 WHERE name = 'B';
COMMIT;-- 会话1:回滚
COMMIT; -- ERROR: could not serialize access due to concurrent update
PostgreSQL 的可重复读并非使用行锁,而是通过版本快照+冲突检测来实现一致性。
所以不能在发生序列化(顺序)冲突后继续操作,必须回滚 + 重试整个事务(只读不存在此问题)。
-- 初始化:
INSERT INTO test_data(name, value) VALUES ('Y', 777);-- 会话1:
BEGIN ISOLATION LEVEL REPEATABLE READ READ ONLY;
SELECT * FROM test_data WHERE name = 'Y'; -- 可见 Y=777-- 会话2:
BEGIN;
DELETE FROM test_data WHERE name = 'Y';
COMMIT;-- 会话1:
SELECT * FROM test_data WHERE name = 'Y'; -- 仍然可见 Y,视图不变
COMMIT;
虽然快照隔离视图一致,但不保证看到的数据是“业务上”一致的。
比如,当前事务查询到 “订单状态 = 已完成”,但却没看到对应的“发货记录”(因为两者是不同事务提交的)。
这种情况无法用快照隔离解决,除非改为更高级的 Serializable 隔离级别。
3_可序列化
Serializable(可串行化) 是 PostgreSQL 中最强的事务隔离级别,确保多个事务的执行结果与某种顺序逐个执行的效果完全一致。
它不会真的让事务一个一个排队执行,而是让并发事务看起来像是顺序执行的;
- 基于快照隔离(SI) 扩展为 可序列化快照隔离(SSI)
- 结合 MVCC(多版本并发控制)、谓词锁(Predicate Locks) 和 冲突检测;
- 并不强制阻塞,而是识别潜在冲突,在必要时中止事务并返回 ;
若两个并发事务互相依赖对方结果(如分别基于 class=1 和 class=2 的聚合结果再写入对方),系统将检测到冲突,并中止其中之一,以避免数据不一致。
-- 初始化表:
DROP TABLE IF EXISTS mytab;
CREATE TABLE mytab (class INT, value INT);
INSERT INTO mytab VALUES (1, 10), (1, 20), (2, 100), (2, 200);-- ====================
-- 会话1(事务 A)开始:
BEGIN ISOLATION LEVEL SERIALIZABLE;-- 会话1 执行聚合:
-- 得到 class = 1 的和为 30
SELECT SUM(value) FROM mytab WHERE class = 1;-- 暂停执行,等待会话 2 进行
-- ====================-- ====================
-- 会话2(事务 B)开始:
BEGIN ISOLATION LEVEL SERIALIZABLE;-- 会话2 执行聚合:
-- 得到 class = 2 的和为 300
SELECT SUM(value) FROM mytab WHERE class = 2;-- 会话2 插入结果到 class = 1:
INSERT INTO mytab (class, value) VALUES (1, 300);-- 会话2 提交:
COMMIT;
-- ====================-- ====================
-- 会话1 继续执行:
-- 插入 class = 2 中
INSERT INTO mytab (class, value) VALUES (2, 30);-- 会话1 提交(将失败,因为这里class1再会话2提交后变为330,与第一次查询结果不同了,互相影响):
COMMIT;
-- 报错:
-- ERROR: could not serialize access due to read/write dependencies among transactions
-- ====================
即使事务在插入前显式检查唯一键是否存在,仍可能出现唯一约束冲突。
正确做法是让所有事务遵循检查+插入的完整协议(先查询不存在后再添加)。
性能和调优建议:
- 优化参数如
max_pred_locks_per_transaction等,避免内存不足导致关系级锁; - 通过调整查询代价参数鼓励使用索引扫描,降低序列化失败率;
- 使用
READ ONLY、控制活跃连接数、避免事务空闲等方式优化性能; - 移除不再需要的
SELECT FOR UPDATE等显式锁语句。
补充——谓词锁:
- 用于监控“读-写依赖”,确保并发事务组合不会破坏串行一致性;
- 显示为
SIReadLock,不会造成阻塞或死锁; - 某些只读事务可延迟执行,以确保读取一致快照。
4_MVCC
首先要清楚,为什么要有 MVCC。
如果一个数据库,频繁的进行读写操作,为了保证安全,采用锁的机制。但是如果采用锁机制,如果一些事务在写数据,另外一个事务就无法读数据。会造成读写之间相互阻塞。 大多数的数据库都会采用 多版本并发控制 MVCC 来解决这个问题。
比如你要查询一行数据,但是这行数据正在被修改,事务还没提交,如果此时对这行数据加锁,会导致其他的读操作阻塞,需要等待。
如果采用 MVCC,他的内部会针对这一行数据保存多个版本,如果数据正在被写入,包就保存之前的数据版本。让读操作去查询之前的版本,不需要阻塞。
等写操作的事务提交了,读操作才能查看到最新的数据。 这几个及时可以确保 读写操作没有冲突 ,这个就是MVCC的主要特点。
写写操作,和MVCC没关系,那个就是加锁的方式!
Ps:这里的MVCC是基于 读已提交 去聊的,如果是串行化,那就读不到了。
在操作之前,先了解一下PGSQL中,每张表都会自带两个字段:
| 字段名 | 含义 |
|---|---|
| xmin | 插入该行的事务 ID |
| xmax | 删除该行的事务 ID(如果该行被删除或更新) |
xmin:给当前事务分配的数据版本。如果有其他事务做了写操作,并且提交事务了,就给 xmin 分配新的版本。
xmax:当前事务没有存在新版本,xmax 就是0。如果有其他事务做了写操作,未提交事务,将写操作的版本放到 xmax 中。提交事务后,xmax 会分配到 xmin 中,然后 xmax 归 0。
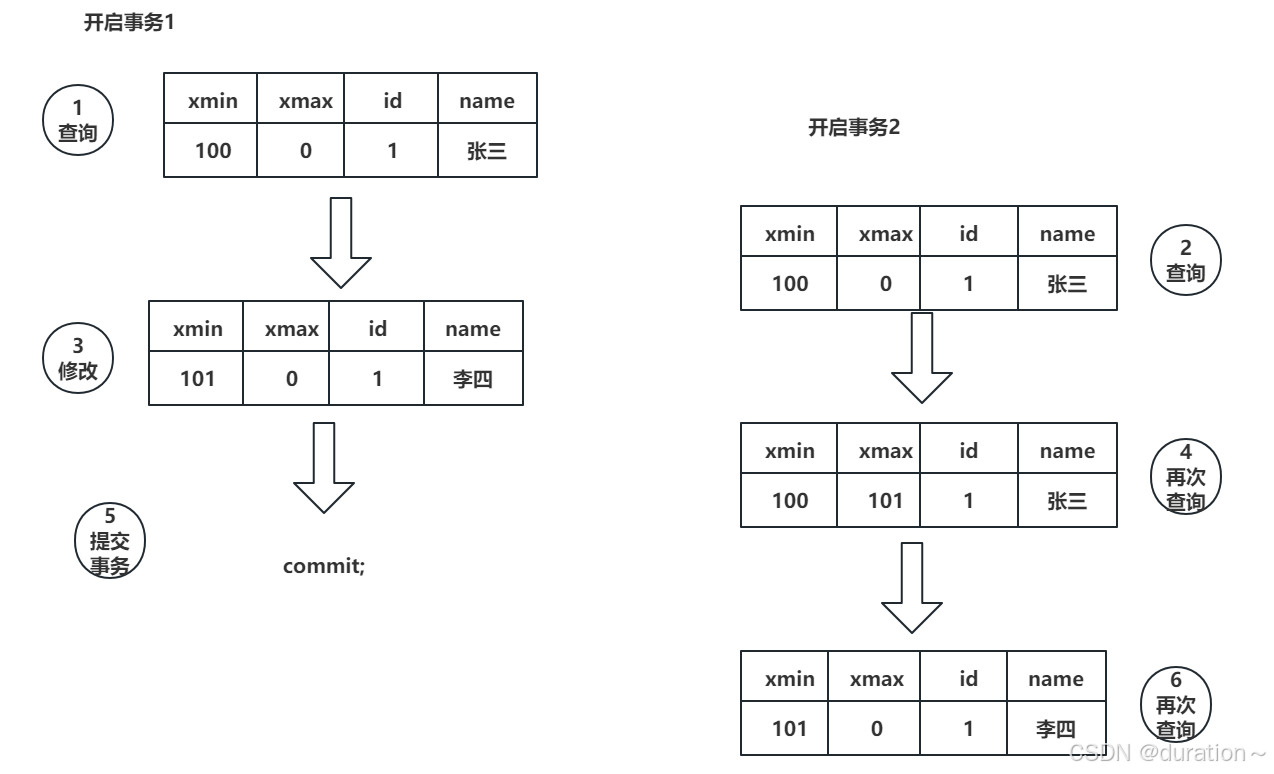
基于上图的操作查看一波效果
事务A
-- 左,事务A
--1、开启事务
begin;
--2、查询某一行数据, xmin = 630,xmax = 0
select xmin,xmax,* from test where id = 8;
--3、每次开启事务后,会分配一个事务ID 事务id=631
select txid_current();
--7、修改id为8的数据,然后在本事务中查询 xmin = 631, xmax = 0
update test set name = '铃铛' where id = 8;
select xmin,xmax,* from test where id = 8;
--9、提交事务
commit;
事务B
-- 右,事务B
--4、开启事务
begin;
--5、查询某一行数据, xmin = 630,xmax = 0
select xmin,xmax,* from test where id = 8;
--6、每次开启事务后,会分配一 个事务ID 事务id=632
select txid_current();
--8、事务A修改完,事务B再查询 xmin = 630 xmax = 631
select xmin,xmax,* from test where id = 8;
--10、事务A提交后,事务B再查询 xmin = 631 xmax = 0
select xmin,xmax,* from test where id = 8;
可见性验证条件(假设当前事务 id 为 T,xmin = x1,xmax = x2):
x1 已提交 AND x1 << T(早于当前事务)
AND (x2 是 null (表示该行未被删除 → 可见)OR x2 未提交OR x2 >> T(比当前事务还晚:删除/更新事务 x2 是在当前事务 T 之后才启动的,即删除操作是“未来”事务做的。)
)
-- 特殊情况:
-- 如果是当前事务自己插入的行,则可见;
-- 如果是当前事务自己删除或更新的行,行为取决于 SQL 的具体操作类型。
-- 总的来说就是如下两个条件:
-- 1. 插入该行的事务(xmin)已经提交,并且在当前事务开启之前就存在(因此其 XID 必然小于当前事务 ID);
-- 2. 删除该行的事务(xmax)要么还没提交、要么不可见(取决于隔离级别)。
操作细节:
| 操作 | 细节 |
|---|---|
| INSERT | 插入一条新记录,系统分配当前事务 ID 作为 xmin;xmax 为 null,表示未被删除;其他事务根据 xmin 判断这条记录是否可见。 |
| UPDATE | 实际是“删除旧记录 + 插入新记录”的组合操作:原记录的 xmax 设置为当前事务 ID(其它事务中可见);插入一个新版本记录,xmin 为当前事务 ID,xmax = null;多版本并存,决定谁看到哪个版本依赖于可见性判断。 |
| DELETE | 将目标记录的 xmax 设置为当前事务 ID(其它事务可见);并不真正删除数据,只是标记为“逻辑删除”;实际数据清理由后续的 VACUUM 或 HOT(Heap Only Tuple)操作完成。 |
PostgreSQL 支持的隔离级别:
| 隔离级别 | MVCC 视图行为说明 |
|---|---|
| Read Committed | 每条语句获取一个新的快照,能看到已提交事务的变化 |
| Repeatable Read | 整个事务只使用一个快照,事务期间读到的内容保持不变 |
| Serializable | 基于 Repeatable Read + 依赖冲突检测(SSI)来保障串行一致性 |
5_保存点
比如项目中有一个大事务操作,不好控制,超时有影响,回滚会造成一切重来,成本太高。
可以针对大事务,拆分成几个部分,第一部分完成后,构建一个保存点。如果后面操作失败了,需要回滚,不需要全盘回滚,回滚到之前的保存点,继续重试。
有人会发现,破坏了整体事务的原子性。
But,只要操作合理,可以在保存点的举出上,做重试,只要重试不成功,依然可以全盘回滚。
比如一个电商项目,下订单,扣库存,创建订单,删除购物车,增加用户积分,通知商家…………。这个其实就是一个大事务。可以将扣库存和下订单这种核心功能完成后,增加一个保存点,如果说后续操作有失败的,可以从创建订单成功后的阶段,再做重试。
不过其实上述的业务,基于最终一致性有更好的处理方式,可以保证可用性。
-- savepoint操作
-- 开启事务
begin;
-- 插入一条数据
insert into test_data values (8,'铃铛',55);
-- 添加一个保存点
savepoint ok1;
-- 再插入数据,比如出了一场
insert into test_data values (9,'大唐官府',66);
-- 回滚到之前的提交点
rollback to savepoint ok1;
-- 就可以开始重试操作,重试成功,commit,失败可以rollback;
commit;
2 锁
PostgreSQL 中主要有两种锁,一个表锁一个行锁;
PostgreSQL 中也提供了页锁,咨询锁,But,这个不需要关注,他是为了锁的完整性。
1_ 表级锁
PostgreSQL 提供多种表级锁模式,用于协调多个事务对同一表的访问。
这些锁在执行 DDL 和某些 DML 时自动加锁,也可通过 LOCK 显式获取。
表锁的模式很多,其中最核心的两个:
- ACCESS SHARE:共享锁(读锁),读读操作不阻塞,但是不允许出现写操作并行
- ACCESS EXCLUSIVE:互斥锁(写锁),无论什么操作进来,都阻塞。
语法:

基于 LOCK 开启表锁,指定表的名字 name,其次在 MODE 中指定锁的模式,NOWAIT 可以指定是否在没有拿到锁时,一直等待:
-- 111号连接
-- 基于互斥锁,锁住test表
-- 先开启事务
begin;
-- 基于默认的ACCESS EXCLUSIVE锁住test表
lock test_data in ACCESS SHARE mode;
-- 操作
select * from test_data;
-- 提交事务,锁释放
commit;
当111号连接基于事务开启后,锁住当前表之后,如果使用默认的 ACCESS EXCLUSIVE,其他连接操作表时,会直接阻塞住。
如果111号是基于 ACCESS SHARE 共享锁时,其他线程查询当前表是不会锁住的。
锁模式及用途(ALL):
| 锁模式 | 用途 |
|---|---|
| ACCESS SHARE | 普通 SELECT查询 |
| ROW SHARE | SELECT ... FOR UPDATE/SHARE |
| ROW EXCLUSIVE | INSERT, UPDATE, DELETE, MERGE |
| SHARE UPDATE EXCLUSIVE | VACUUM, ANALYZE, CREATE INDEX CONCURRENTLY |
| SHARE | CREATE INDEX(非并发) |
| SHARE ROW EXCLUSIVE | CREATE TRIGGER, 一些 ALTER TABLE |
| EXCLUSIVE | REFRESH MATERIALIZED VIEW CONCURRENTLY |
| ACCESS EXCLUSIVE | 强制独占,如 DROP, TRUNCATE, ALTER TABLE |
所有锁之间的冲突如下:
| 锁冲突 | ACCESS SHARE | ROW SHARE | ROW EXCL. | SHARE UPDATE EXCL. | SHARE | SHARE ROW EXCL. | EXCL. | ACCESS EXCL. |
|---|---|---|---|---|---|---|---|---|
ACCESS SHARE | X | |||||||
ROW SHARE | X | X | ||||||
ROW EXCL. | X | X | X | X | ||||
SHARE UPDATE EXCL. | X | X | X | X | X | |||
SHARE | X | X | X | X | X | |||
SHARE ROW EXCL. | X | X | X | X | X | X | ||
EXCL. | X | X | X | X | X | X | X | |
ACCESS EXCL. | X | X | X | X | X | X | X | X |
2_行级锁
PostgreSQL 的行锁和 MySQL 的基本是一模一样的,基于 select for update 就可以指定行锁。
MySQL 中有一个问题,for update 时,如果 select 的查询没有命中索引,可能会锁表。
PostgerSQL 有个特点,一般情况,在 select 的查询没有命中索引时,他不一定会锁表,依然会实现行锁。
PostgreSQL 的行锁,就玩俩,一个for update,一个for share(共享锁和排它锁)。
-- 先开启事务
begin;
-- 基于for update 锁住id为3的数据
select * from test_data where id = 3 for update;
update test_data set name = 'v1' where id = 3;
-- 提交事务,锁释放
commit;
所有行锁总结表格:
| 锁模式 | 用途 | 阻塞对象 |
|---|---|---|
| FOR UPDATE | 行将被修改或删除 | 阻塞任何修改/锁定尝试(和其他锁都有冲突) |
| FOR NO KEY UPDATE | 修改非键字段 | 比 FOR UPDATE 弱,阻塞除 FOR KEY SHARE 外的所有锁 |
| FOR SHARE | 查询共享内容 | 阻塞修改,允许其他共享查询 |
| FOR KEY SHARE | 外键引用等只读检查 | 最弱,阻塞 FOR UPDATE,不会阻塞 FOR NO KEY UPDATE |
3_页级锁
PostgreSQL 内部使用的低层级锁,控制对页的访问,在读取或修改页时加锁,随后立即释放。开发者无需显式处理。
还有其他的比如咨询锁:由应用显式控制、系统不自动施加的锁。可在会话级别或事务级别获取;用于控制应用层逻辑同步,如模拟文件锁、分布式协调等;使用 pg_advisory_lock() 系列函数