java集合框架面试点(2)
目录
HashMap
HashMap的put流程
如果重写equals方法,没重写hashcode方法,put会发送什么呢
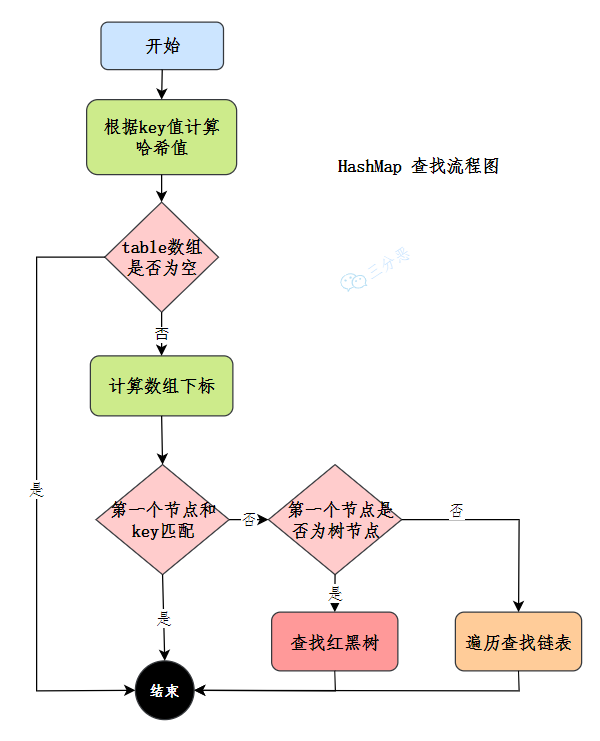
HashMap的查找
HashMap的hash函数是怎么设计的
为什么哈希可以减少冲突
为什么HashMap容量是2的幂次方
如果初始化HashMap,传一个17容量怎么处理?
解决哈希冲突
HashMap的扩容机制
HashMap是线程安全的吗
怎么解决
HashMap是无序的
LinkedHashMap是怎么实现有序的?
TreeMap是怎么实现有序地
TreeMap和HashMap的区别
HashSet的实现原理
hashset和arrayList的区别
HashMap
HashMap的put流程
哈希寻址 处理哈希冲突(链表还是红黑树) 判断是否扩容 插入/覆盖节点
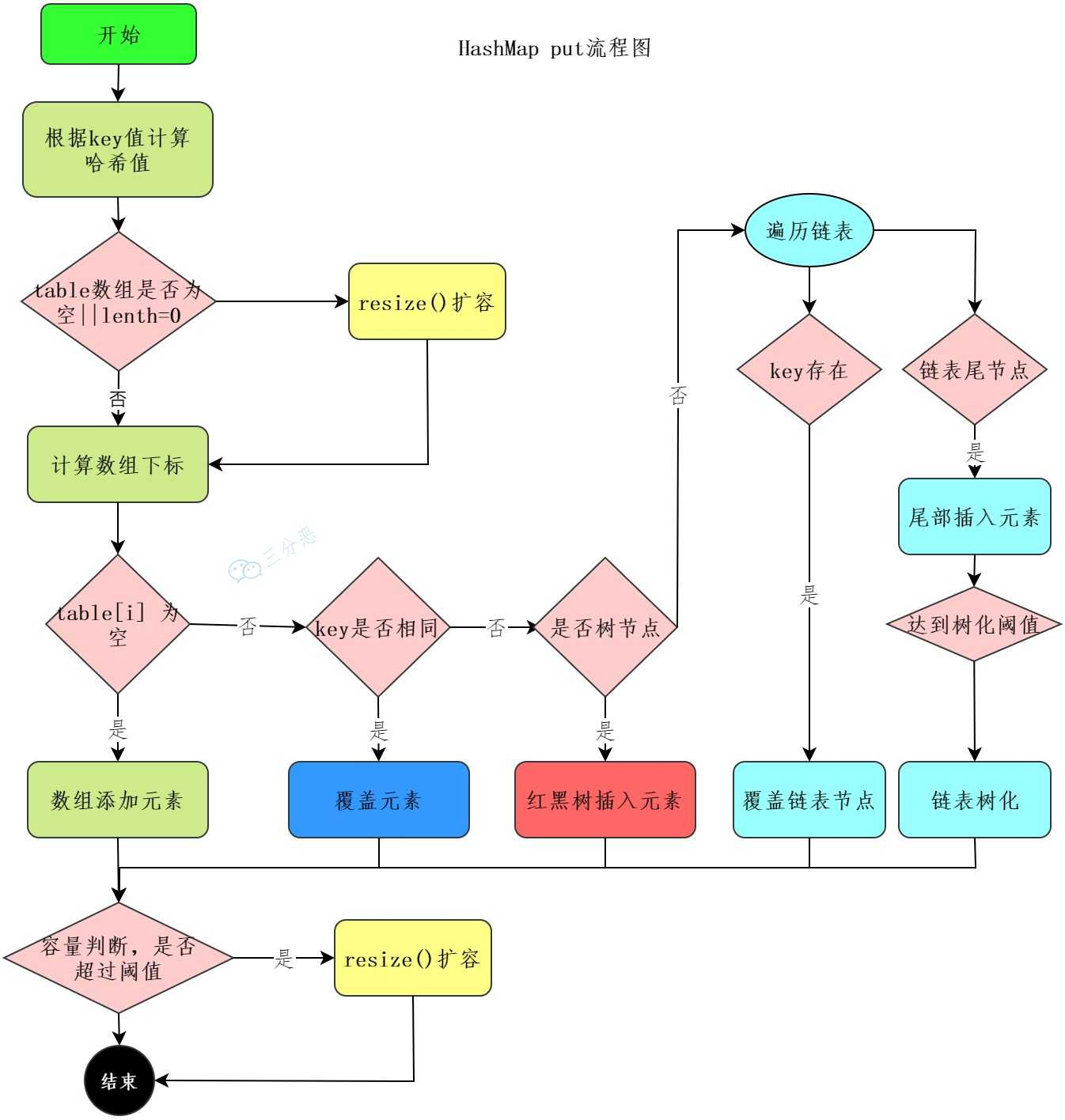
第一步 通过hash方法扰动,以减少冲突
static final int hash(Object key){int h;return (key==null)?0:(h=key.hashcode())^(h>>>16);
}第二步 进行第一次的数组扩容resize() 并使用哈希值和数组长度进行取模运算,确定索引位置
if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);如果当前的位置为空 直接将键值对插入,不为空,那么就判断当前位置的第一个节点是否和新节点的key相同。相同则覆盖value,否则发送哈希冲突
如果是链表,将新节点遍历链表,找到相同key赋值value,遍历到链表尾部没找到相同的key,那么插入链表尾部 如果链表长度>8 且数组>64 那么进行转换成红黑树,如果没有满足64则进行数组扩容
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果 table 为空,先进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算索引位置,并找到对应的桶
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); // 如果桶为空,直接插入
else {
Node<K,V> e; K k;
// 检查第一个节点是否匹配
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 覆盖
// 如果是树节点,放入树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 如果是链表,遍历插入到尾部
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表长度达到阈值,转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break; // 覆盖
p = e;
}
}
if (e != null) { // 如果找到匹配的 key,则覆盖旧值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount; // 修改计数器
if (++size > threshold)
resize(); // 检查是否需要扩容
afterNodeInsertion(evict);
return null;
}
每次插入新元素后,检查是否需要扩容,如果当前元素个数大于阈值(capacity * loadFactor),则进行扩容,扩容后的数组大小是原来的 2 倍;并且重新计算每个节点的索引,进行数据重新分布。
如果重写equals方法,没重写hashcode方法,put会发送什么呢
如果只重写equals方法,没有重写hashcode方法,那么会导致equals相等的两个对象,hashcode不同,这样的话 两个对象会被put到数组的不同为止,导致get得不到正确的值
HashMap的查找
通过哈希定位索引,定位桶,查找第一个节点,遍历链表或红黑树查找,返回结果
HashMap的hash函数是怎么设计的
先拿到key的哈希值,是一个32位的int数值,然后再让哈希的高十六位和低十六位进行异或操作,这样可以保证哈希分布均匀。
为什么哈希可以减少冲突
哈希表的索引是通过 h & (n-1) 计算的,n 是底层数组的容量;n-1 和某个哈希值做 & 运算,相当于截取了最低的四位。如果数组的容量很小,只取 h 的低位很容易导致哈希冲突。通过异或操作将 h 的高位引入低位,可以增加哈希值的随机性,从而减少哈希冲突。
以初始长度 16 为例,16-1=15。2 进制表示是0000 0000 0000 0000 0000 0000 0000 1111。只取最后 4 位相等于哈希值的高位都丢弃了。
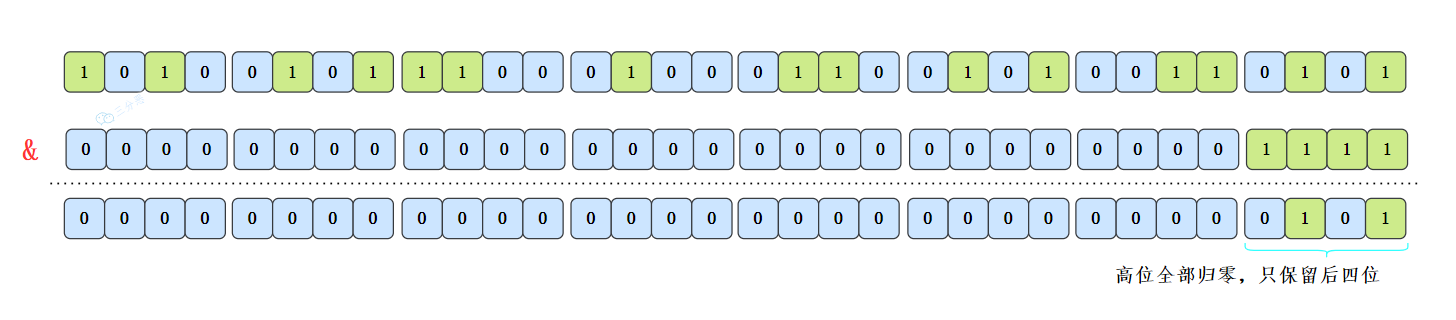
比如说 1111 1111 1111 1111 1111 1111 1111 1111,取最后 4 位,也就是 1111。
1110 1111 1111 1111 1111 1111 1111 1111,取最后 4 位,也是 1111。
不就发生哈希冲突了吗?
这时候 hash 函数 (h = key.hashCode()) ^ (h >>> 16) 就派上用场了。
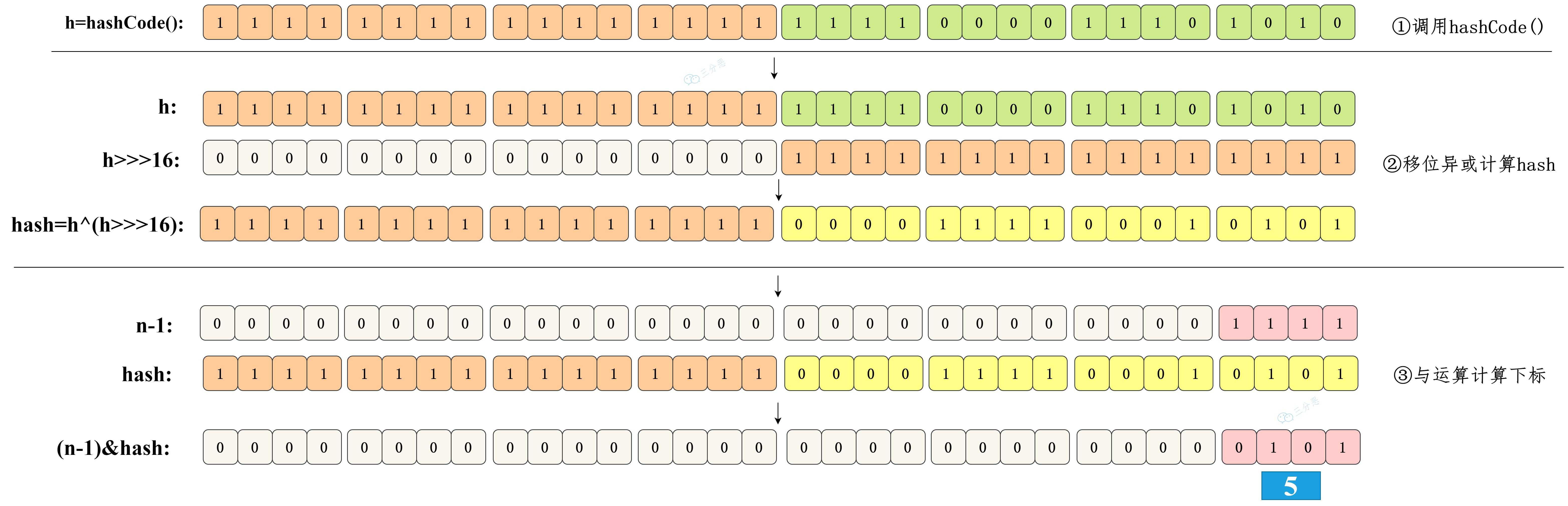
将哈希值无符号右移 16 位,意味着原哈希值的高 16 位被移到了低 16 位的位置。这样,原始哈希值的高 16 位和低 16 位就可以参与到最终用于索引计算的低位中。
选择 16 位是因为它是 32 位整数的一半,这样处理既考虑了高位的信息,又没有完全忽视低位原本的信息,从而达到了一种微妙的平衡状态。
举个例子(数组长度为 16)。
- 第一个键值对的键:h1 = 0001 0010 0011 0100 0101 0110 0111 1000
- 第二个键值对的键:h2 = 0001 0010 0011 0101 0101 0110 0111 1000
如果没有 hash 函数,直接取低 4 位,那么 h1 和 h2 的低 4 位都是 1000,也就是说两个键值对都会放在数组的第 8 个位置。
来看一下 hash 函数的处理过程。
①、对于第一个键h1的计算:
原始: 0001 0010 0011 0100 0101 0110 0111 1000
右移: 0000 0000 0000 0000 0001 0010 0011 0100
异或: ---------------------------------------
结果: 0001 0010 0011 0100 0100 0100 0100 1100②、对于第二个键h2的计算:
原始: 0001 0010 0011 0101 0101 0110 0111 1000
右移: 0000 0000 0000 0000 0001 0010 0011 0101
异或: ---------------------------------------
结果: 0001 0010 0011 0101 0100 0100 0100 1101通过上述计算,我们可以看到h1和h2经过h ^ (h >>> 16)操作后得到了不同的结果。
现在,考虑数组长度为 16 时(需要最低 4 位来确定索引):
- 对于
h1的最低 4 位是1100(十进制中为 12) - 对于
h2的最低 4 位是1101(十进制中为 13)
这样,h1和h2就会被分别放在数组的第 12 个位置和第 13 个位置上,从而避免了哈希冲突。
为什么HashMap容量是2的幂次方
数组长度-1 正好相当于一个“低位掩码”——掩码的低位最好全是 1,这样 & 运算才有意义,否则结果一定是 0。
2 幂次方刚好是偶数,偶数-1 是奇数,奇数的二进制最后一位是 1,也就保证了 hash &(length-1) 的最后一位可能为 0,也可能为 1(取决于 hash 的值),这样可以保证哈希值的均匀分布。
如果初始化HashMap,传一个17容量怎么处理?
HashMap会将容量调整为大于等于17的最小的2的幂次方,也就是32
如果预先知道 Map 将存储大量键值对,提前指定一个足够大的初始容量可以减少因扩容导致的重哈希操作。
因为每次扩容时,HashMap 需要将现有的元素插入到新的数组中,这个过程相对耗时,尤其是当 Map 中已有大量数据时。
当然了,过大的初始容量会浪费内存,特别是当实际存储的元素远少于初始容量时。如果不指定初始容量,HashMap 将使用默认的初始容量 16。
解决哈希冲突
在哈希法,准备两套哈希算法,当发生哈希冲突的时候,使用另外一种哈希算法,直到找到空槽为止。对哈希算法的设计要求比较高
开放地址法
遇到哈希冲突的时候,就去寻找下一个空的槽。有 3 种方法:
- 线性探测:从冲突的位置开始,依次往后找,直到找到空槽。
- 二次探测:从冲突的位置 x 开始,第一次增加 个位置,第二次增加 ,直到找到空槽。
- 双重哈希:和再哈希法类似,准备多个哈希函数,发生冲突的时候,使用另外一个哈希函数。
拉链法
也就是链地址法,当发生哈希冲突的时候,使用链表将冲突的元素串起来。HashMap 采用的正是拉链法。
HashMap的扩容机制
扩容时,HashMap 会创建一个新的数组,其容量是原来的两倍。然后遍历旧哈希表中的元素,将其重新分配到新的哈希表中。
如果当前桶中只有一个元素,那么直接通过键的哈希值与数组大小取模锁定新的索引位置:e.hash & (newCap - 1)。
如果当前桶是红黑树,那么会调用 split() 方法分裂树节点,以保证树的平衡。
如果当前桶是链表,会通过旧键的哈希值与旧的数组大小取模 (e.hash & oldCap) == 0 来作为判断条件,如果条件为真,元素保留在原索引的位置;否则元素移动到原索引 + 旧数组大小的位置。
HashMap是线程安全的吗
HashMap 不是线程安全的
怎么解决
在早期的 JDK 版本中,可以用 Hashtable 来保证线程安全。Hashtable 在方法上加了 synchronized。
另外,可以通过 Collections.synchronizedMap 方法返回一个线程安全的 Map,内部是通过 synchronized 对象锁来保证线程安全的,比在方法上直接加 synchronized 关键字更轻量级。
更优雅的解决方案是使用并发工具包下的ConcurrentHashMap
HashMap是无序的
LinkedHashMap是怎么实现有序的?
LinkedHashMap 在 HashMap 的基础上维护了一个双向链表,通过 before 和 after 标识前置节点和后置节点。
TreeMap是怎么实现有序地
TreeMap通过key的比较器来决定元素的顺序,如果没有比较器,必须实现Comparable接口
TreeMap和HashMap的区别
①、HashMap 是基于数组+链表+红黑树实现的,put 元素的时候会先计算 key 的哈希值,然后通过哈希值计算出元素在数组中的存放下标,然后将元素插入到指定的位置,如果发生哈希冲突,会使用链表来解决,如果链表长度大于 8,会转换为红黑树。
②、TreeMap 是基于红黑树实现的,put 元素的时候会先判断根节点是否为空,如果为空,直接插入到根节点,如果不为空,会通过 key 的比较器来判断元素应该插入到左子树还是右子树。
在没有发生哈希冲突的情况下,HashMap 的查找效率是 O(1)。适用于查找操作比较频繁的场景。
TreeMap 的查找效率是 O(logn)。并且保证了元素的顺序,因此适用于需要大量范围查找或者有序遍历的场景。
HashSet的实现原理
HashSet 是由 HashMap 实现的,只不过值由一个固定的 Object 对象填充,而键用于操作。
实际开发中,HashSet 并不常用,比如,如果我们需要按照顺序存储一组元素,那么 ArrayList 和 LinkedList 更适合;如果我们需要存储键值对并根据键进行查找,那么 HashMap 可能更适合。
HashSet 主要用于去重,比如,我们需要统计一篇文章中有多少个不重复的单词,就可以使用 HashSet 来实现。
hashset和arrayList的区别
- ArrayList 是基于动态数组实现的,HashSet 是基于 HashMap 实现的。
- ArrayList 允许重复元素和 null 值,可以有多个相同的元素;HashSet 保证每个元素唯一,不允许重复元素,基于元素的 hashCode 和 equals 方法来确定元素的唯一性。
- ArrayList 保持元素的插入顺序,可以通过索引访问元素;HashSet 不保证元素的顺序,元素的存储顺序依赖于哈希算法,并且可能随着元素的添加或删除而改变