大型微服务项目:听书——12 数据一致性自定义starter封装缓存操作
12 数据一致性&自定义starter封装缓存操作
12.1 缓存和数据库的数据一致性
-
使用缓存的主要目的是为了提升查询的性能。大多数情况下,使用缓存的过程如下图:
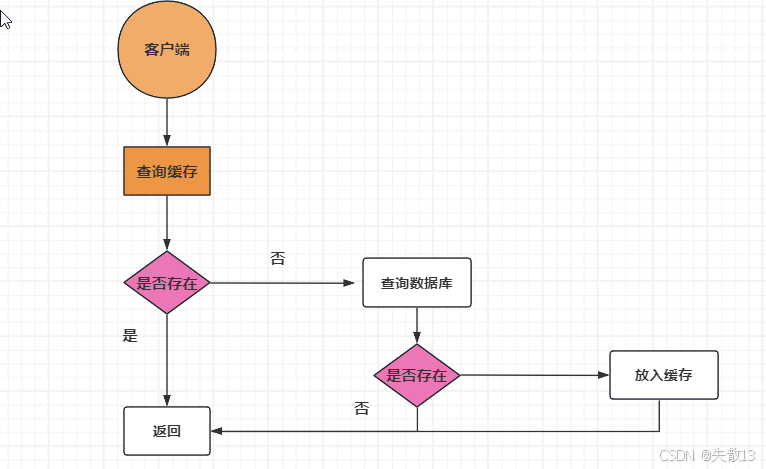
- 当应用程序需要从数据库读取数据时,先检查缓存数据是否命中;
- 如果缓存未命中,则查询数据库数据,同时将数据写到缓存中,以便后续读取相同的数据会命中缓存,最后在把数据返回给调用者;
- 如果缓存命中,直接返回;
-
缓存不一致产生的原因:
- A线程修改数据库,接着修改缓存;
- 在A线程执行操作期间,B线程来读取缓存中数据,此时如果A线程还未将数据同步到缓存,那么B线程读到的就是缓存的旧数据;
- A将更新后的数据同步到缓存会有一个时间差,因此在并发读写的时候可能就会出现缓存不一致的问题;
-
写数据的流程无非以下四种:
- 先更新缓存在更新数据库
- 先删除缓存在更新数据库
- 先更新数据库在更新缓存
- 先更新数据库在删除缓存
对于缓存,大多还是选择删除,为什么?因为相比于删除缓存,计算机更新缓存的成本更高
-
那么是先操作缓存?还是先操作数据库?
-
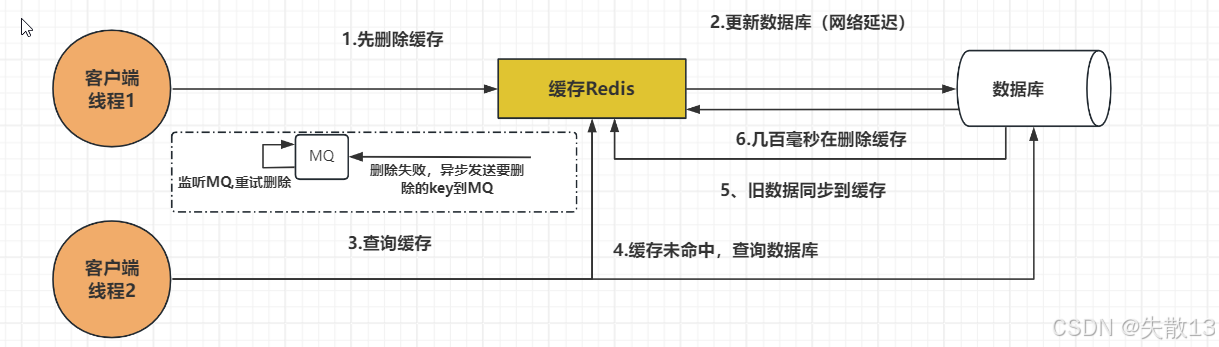
先删除缓存,再更新数据库
- 在多线程情况下,当A线程把缓存删除后,B线程过来读缓存;
- 但A已经把缓存删除了,所以B线程会因为缓存未命中就会直接去读数据库,然后将读到的数据去更新缓存;
- 此时A线程才来更新数据库,这就造成了缓存脏数据的情况;
- 而且,如果不采用给B更新到缓存中的数据设置过期时间,那么该数据永远都是脏数据;
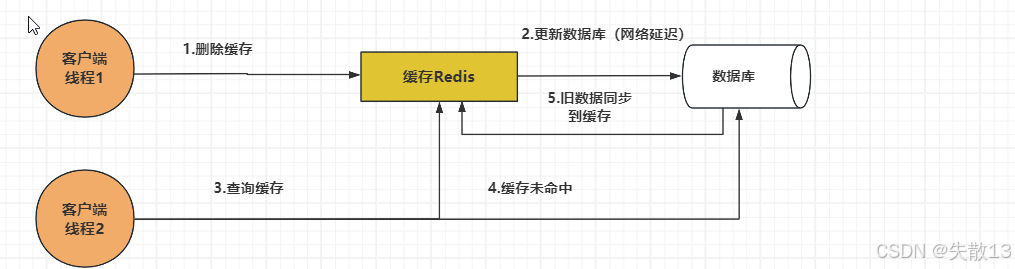
通过2pc、Paxos算法或者分布式锁保持一致性,即在A将“删除缓存,更新数据库”这一套操作执行完后,其它线程才能来查询缓存和数据库;
但是这可能会影响系统吞吐量、增加系统响应时间,因此通常采用相对宽松的一致性方法,称为最终一致性;
-
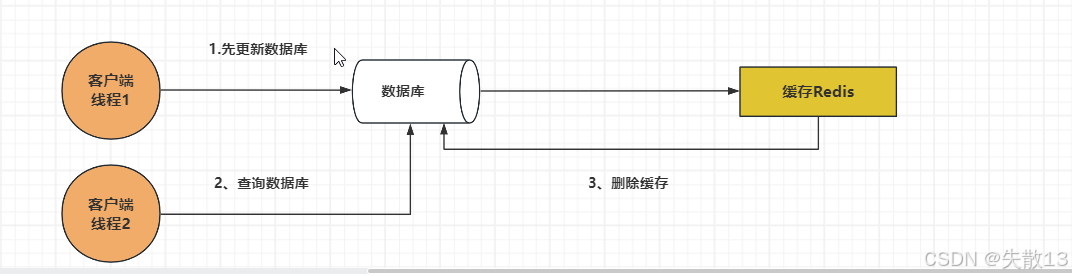
先更新数据库,再删除缓存
- 在多线程情况下,当A线程直接去更新数据库,B线程读取缓存数据,此时B读到的是缓存的旧数据;
- A线程更新完数据库后就会更新缓存,这时缓存就正常了,只产生了一次脏读;
-
-
最终一致性
-
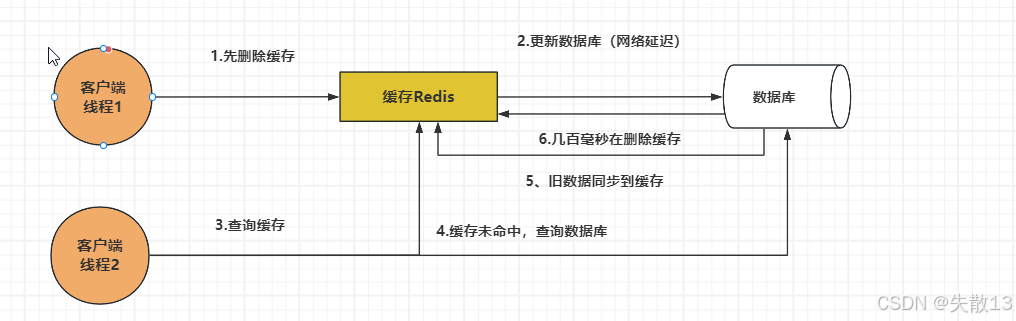
延迟双删
- 对于“先删除缓存,再更新数据库”的方式,可以用延迟双删来解决,即:先删除缓存,再更新数据库,休眠一段时间后,再删除缓存;
- 对于“先更新数据库,再删除缓存”的方式,也可以使用延迟双删,防止第一次删除缓存失败;
- 休眠时间怎么确定呢?需要自行压测项目读取数据的业务逻辑耗时(即第二个线程从数据库读取数据然后完成写入缓存),防止二次删除不起作用;
-
删除缓存的重试机制
-
如果缓存删除失败怎么办?比如延迟双删的第二次删除缓存失败,那岂不是无法删除脏数据?
-
可以启用删除缓存的重试机制,以保证删除缓存成功;
-
在高并发下,重试最好使用异步方式,比如发送消息到 MQ 中实现异步解耦;
-
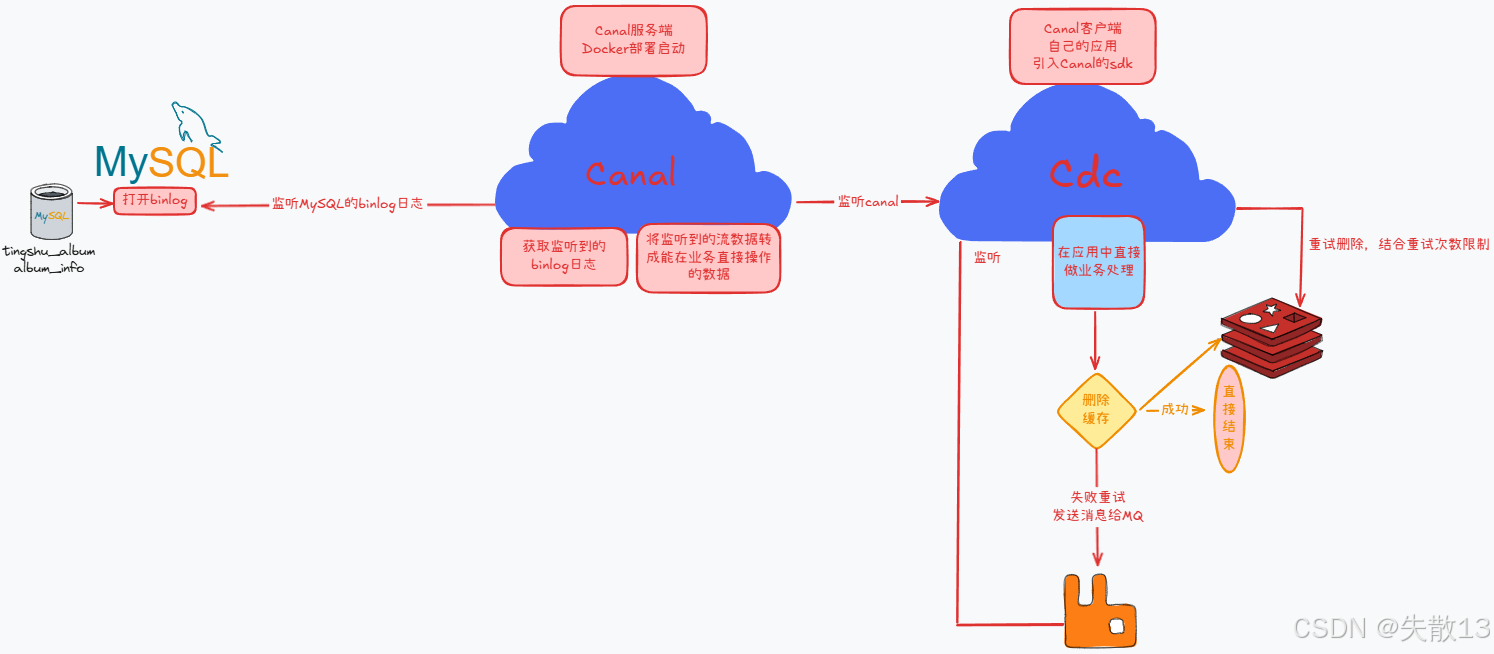
该方案有个缺点,就是会对业务代码造成侵入, 那么可以启动一个专门订阅数据库 binlog 的服务去读取需要删除的数据然后进行缓存删除操作;
-
-
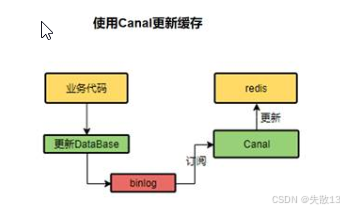
读取 binlog 异步删除
-
Canal 是阿里的一款开源框架,主要用途是基于 MySQL 数据库的增量日志解析,提供增量数据订阅和消费,且 Canal 提供了各种语言的客户端,当Canal监听到 binlog 变化时,会通知 Canal 的客户端;
-
可以利用 Canal 提供的 Java 客户端,监听 Canal 的通知消息。当收到数据变化的消息时,完成对缓存的更新;
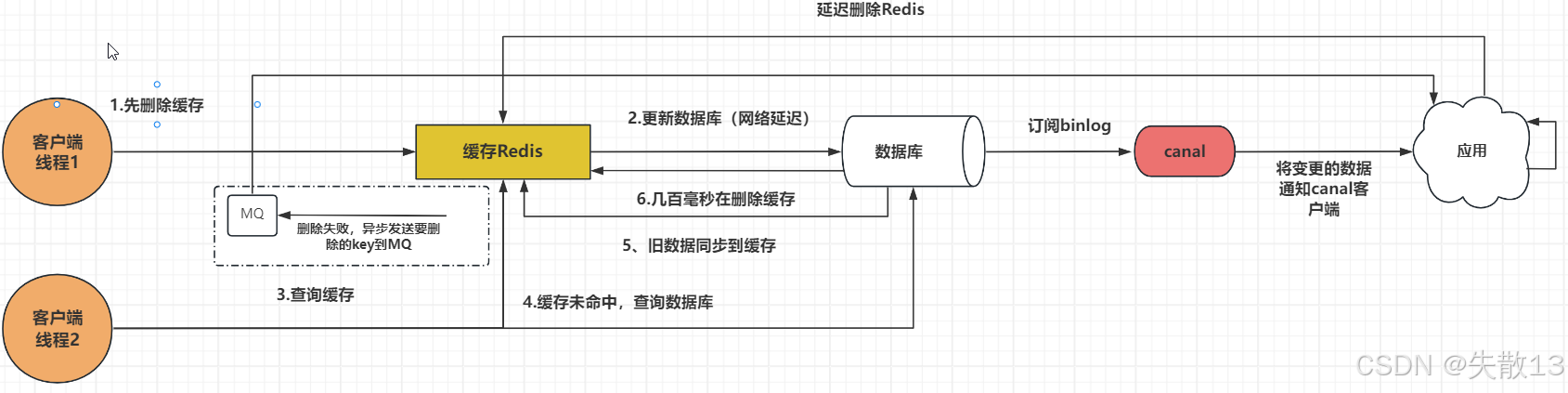
- 更新数据库
- 数据库会把操作信息记录在 binlog 日志中
- Canal 订阅了 binlog 日志,在数据库发生变动时,会获取目标数据和key,并通知缓存处理服务
- 缓存处理服务获取到 Canal 发来的数据,解析得到目标 key,尝试删除缓存
- 如果缓存处理服务处理删除缓存失败,异步发送 key 给 MQ,缓存处理服务或者其他服务会订阅队列的key,继续重试删除缓存
-
-
12.2 Canal
12.2.1 简介
-
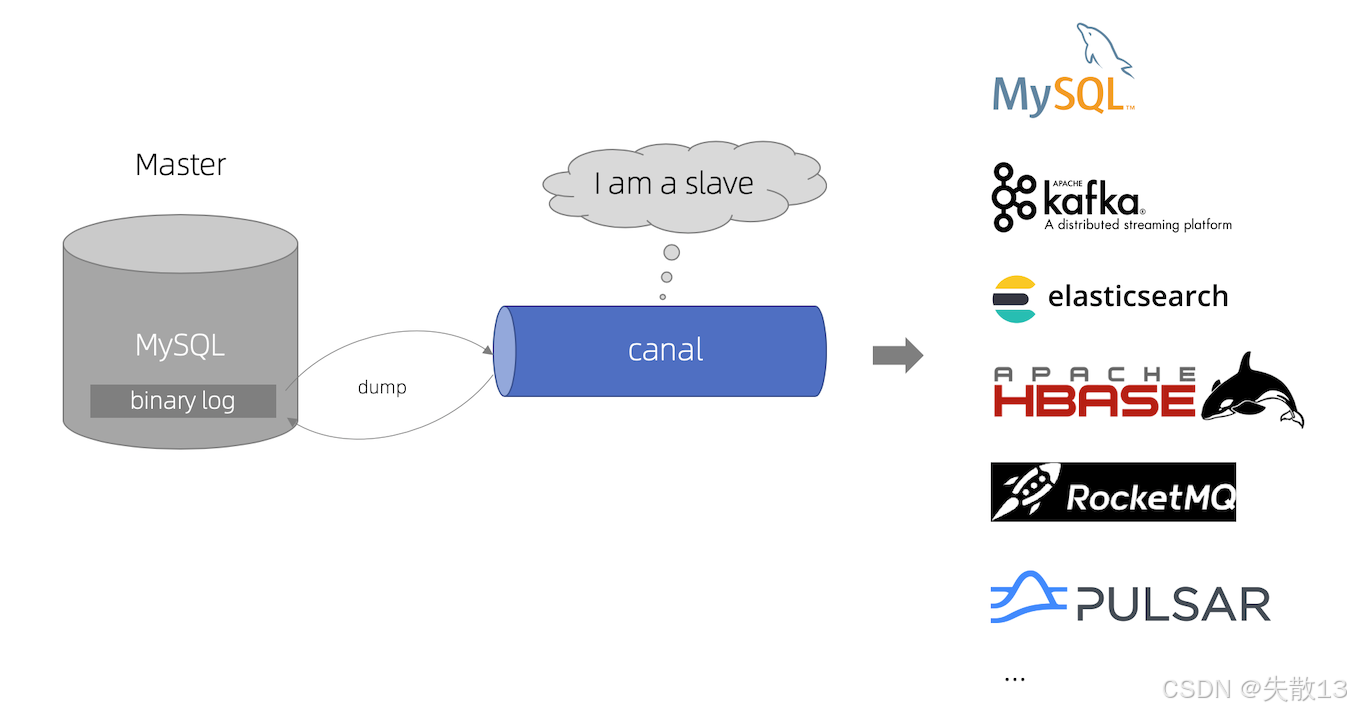
Canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费;
-
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务;
-
GitHub:GitHub - alibaba/canal: 阿里巴巴 MySQL binlog 增量订阅&消费组件
-
特点:
- 高性能:Canal 采用了基于网络协议的方式来解析和同步 MySQL 的增量日志,相较于数据库级别的触发器或轮询方式,可以提供更高的同步性能;
- 支持多种数据格式:Canal 可以将 MySQL 的增量日志解析为多种数据格式,包括 JSON、XML 等,方便用户进行二次开发和数据处理;
- 多种同步方式:Canal 支持多种同步方式,包括基于缓存、MQ、HTTP 接口等多种方式,可以根据业务需求选择不同的同步方式;
- 灵活的订阅机制:Canal 支持灵活的订阅机制,可以根据表、库、列等维度进行精确的订阅,同时也支持动态增加和删除订阅;
- 多种部署方式:Canal 可以在单机、集群等多种环境下进行部署,同时也支持 Docker 容器化部署;
- 易于扩展:Canal 采用了插件化的设计,支持用户自定义插件,可以方便地扩展新的功能;
-
总的来说,Canal 是一款功能强大、性能高效、易于使用、可扩展的数据同步工具,被广泛应用于阿里巴巴和其他企业的数据同步场景中。
12.2.2 工作原理
-
Canal 的工作原理是将自己伪装成 Mysql 的 slave 节点(即从节点),来订阅 MySQL binlog 的变更,所以在配置启动 Canal 前,需要先配置 MySQL;
-
MySQL 主从复制原理
- MySQL master 将数据变更写入二进制日志(即binary log),其中的记录叫做二进制日志事件 binary log events,可以通过
show binlog events进行查看; - MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log);
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据;
- MySQL master 将数据变更写入二进制日志(即binary log),其中的记录叫做二进制日志事件 binary log events,可以通过
-
Canal 工作原理
- Canal 模拟 MySQL slave 的交互协议,将自己伪装成 MySQL slave ,向 MySQL master 发送 dump 协议;
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave(即 Canal);
- Canal 解析 binary log 对象(原始为 byte 流)。
12.2.3 安装 Cannl
-
先查看当前 MySQL 是否开启了 binlog 模式
# 进入到MySQL容器的工作目录下 docker exec -it 3a0532e74496 bash# 登录MySQL mysql -uroot -proot# 开启binlog模式 SHOW VARIABLES LIKE '%log_bin%';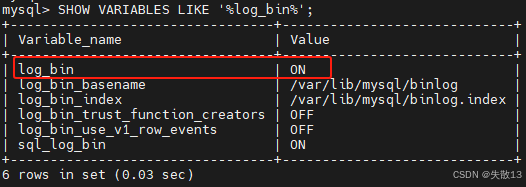
-
创建账号并授权
- 创建
canal用户,允许远程连接; - 授予
SELECT、REPLICATION SLAVE、REPLICATION CLIENT、SUPER权限,使 Canal 能读取binlog并监控数据库变更; - 修改认证方式(针对 MySQL 8.0+ 兼容性);
- 刷新权限,确保配置立即生效;
# 创建 canal 用户并设置密码 create user canal@'%' IDENTIFIED by 'canal'; # canal@'%':创建一个用户名为 canal,允许从 任意主机(% 表示所有IP) 连接 MySQL # IDENTIFIED BY 'canal':设置该用户的密码为 canal# 授予 canal 用户必要的权限 GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%'; # SELECT:允许查询数据(Canal 需要读取 binlog,因此需要查询权限) # REPLICATION SLAVE:允许作为从库读取主库的 binlog(Canal 模拟 MySQL 从库拉取变更日志) # REPLICATION CLIENT:允许查看主库/从库状态(Canal 需要检查复制状态) # SUPER:允许执行某些管理命令(如 SET GLOBAL,某些 MySQL 版本 Canal 需要此权限) # ON *.*:对所有数据库(*.*)生效。# 修改 canal 用户的认证方式(MySQL 8.0+ 需要) ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal'; # mysql_native_password:使用 旧版密码认证(MySQL 8.0+ 默认使用 caching_sha2_password,但部分客户端(如 Canal)可能不支持,需切换回旧方式) # BY 'canal':保持密码不变。# 刷新权限,使更改立即生效 FLUSH PRIVILEGES; - 创建
-
安装 Canal 容器:先执行两次
exit,退出MySQL,退出MySQL容器docker run -p 11111:11111 --name canal --restart=always \ -e canal.destinations=tingshuTopic \ -e canal.instance.master.address=服务器ip地址:3307 \ -e canal.instance.dbUsername=canal \ -e canal.instance.dbPassword=canal \ -e canal.instance.connectionCharset=UTF-8 \ -e canal.instance.tsdb.enable=true \ -e canal.instance.gtidon=false \ -e canal.instance.filter.regex=tingshu_album.album_info \ -d registry.cn-shanghai.aliyuncs.com/atguiguhzk/canal:v1.0 # destinations定义了Canal需要监听的MySQL实例名称 # address指定Cannal连接 MySQL 数据库地址 # dbUsername指定Cannal连接MySQL数据库的用户名 # dbPassword指定Cannal连接MySQL数据库的密码 # connectionCharset用于指定Cannal连接MySQL数据库时使用的字符集编码为UTF-8 # tsdb用于存储和查询元数据信息,例如数据库表的结构、字段类型等。启用TSDB功能后,Canal可以更好地管理和维护这些元数据信息,从而提高数据同步的准确性和效率 # gtion用于决定Canal是否启用GTID(全局事务标识符)支持确保数据的一致性和完整性。如果设置为false,那么Canal不会使用GTID来同步数据,而是依赖于传统的二进制日志位置(binlog position)来进行数据同步 # regex即正则表达式,用于指定需要订阅的数据库和表 比如.*\\..* 表示监听所有库表 -
查看启动日志。看完
Ctrl+C终止一下
-
服务器记得开放防火墙。
12.3 搭建service-cdc工程
-
在
service模块下新建子模块service-cdc(Change Data Capture,变更数据捕获):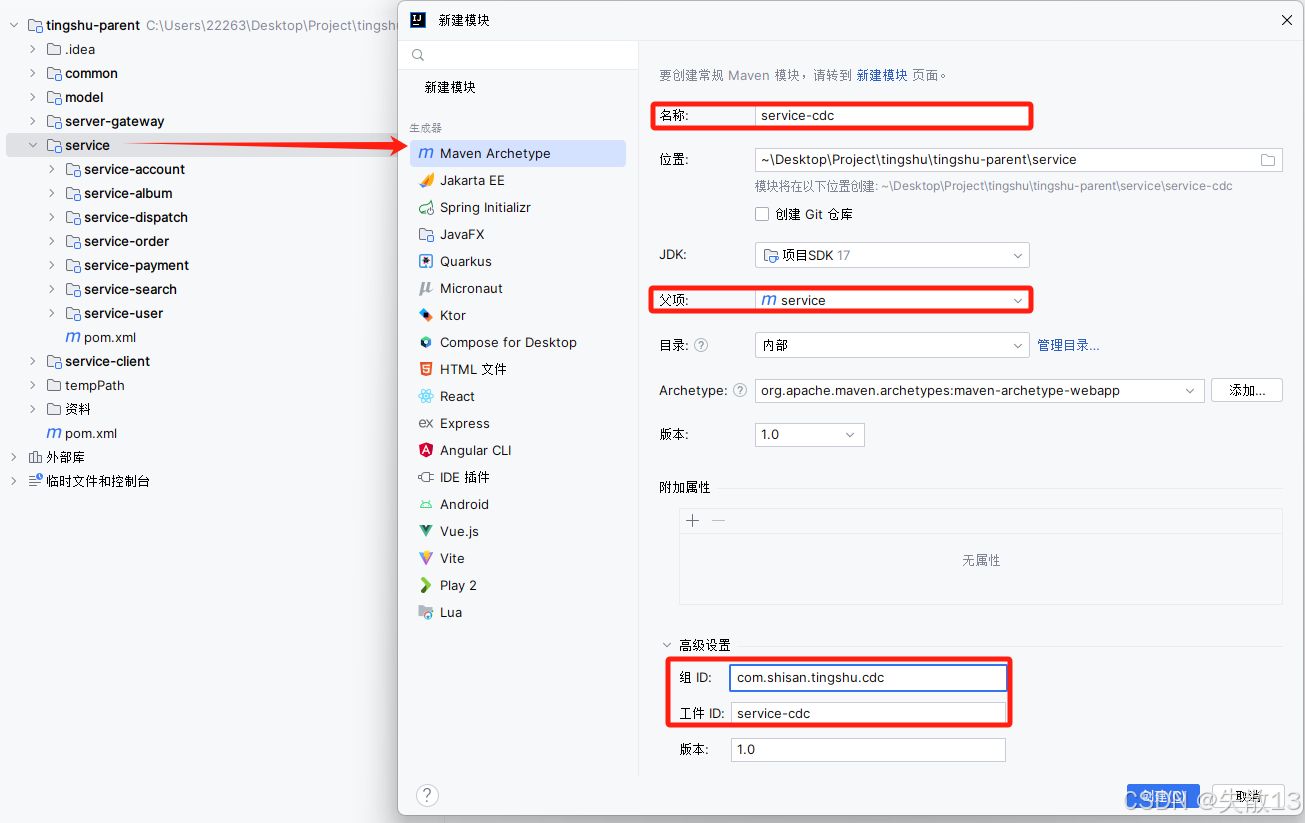
-
pom.xml:<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.6.RELEASE</version><!--relativePath标签用于定位父工程的pom文件,默认去找上一层的pom文件--><!--如果需要找同级的,比如可以写../service-album/pom.xml--><!--如果relativePath标签中什么都不写,或者写成下面的单标签形式。代表直接从本地仓库找spring-boot-starter-parent的pom文件,本地仓库找不到就去远程仓库找--><relativePath/></parent><groupId>com.shisan.tingshu.cdc</groupId><artifactId>service-cdc</artifactId><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>top.javatool</groupId><artifactId>canal-spring-boot-starter</artifactId><version>1.2.1-RELEASE</version></dependency><dependency><groupId>javax.persistence</groupId><artifactId>persistence-api</artifactId><version>1.0</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-autoconfigure</artifactId></dependency><!--<dependency>--><!-- <groupId>com.shisan.tingshu</groupId>--><!-- <artifactId>rabbit-util</artifactId>--><!-- <version>1.0</version>--><!--</dependency>--></dependencies> </project> -
配置
application.yaml:server:port: 10001 spring:redis:host: 服务器ip地址port: 6379password: 123456application:name: service-cdc # canal canal:destination: tingshuTopic # 和安装Cannl容器时指定的一样server: 服务器ip地址:11111 -
修改项目的JDK版本为 JDK8:每刷新一次Maven这个设置就会重置,所以如果有刷新Maven的话,需要重新操作一次
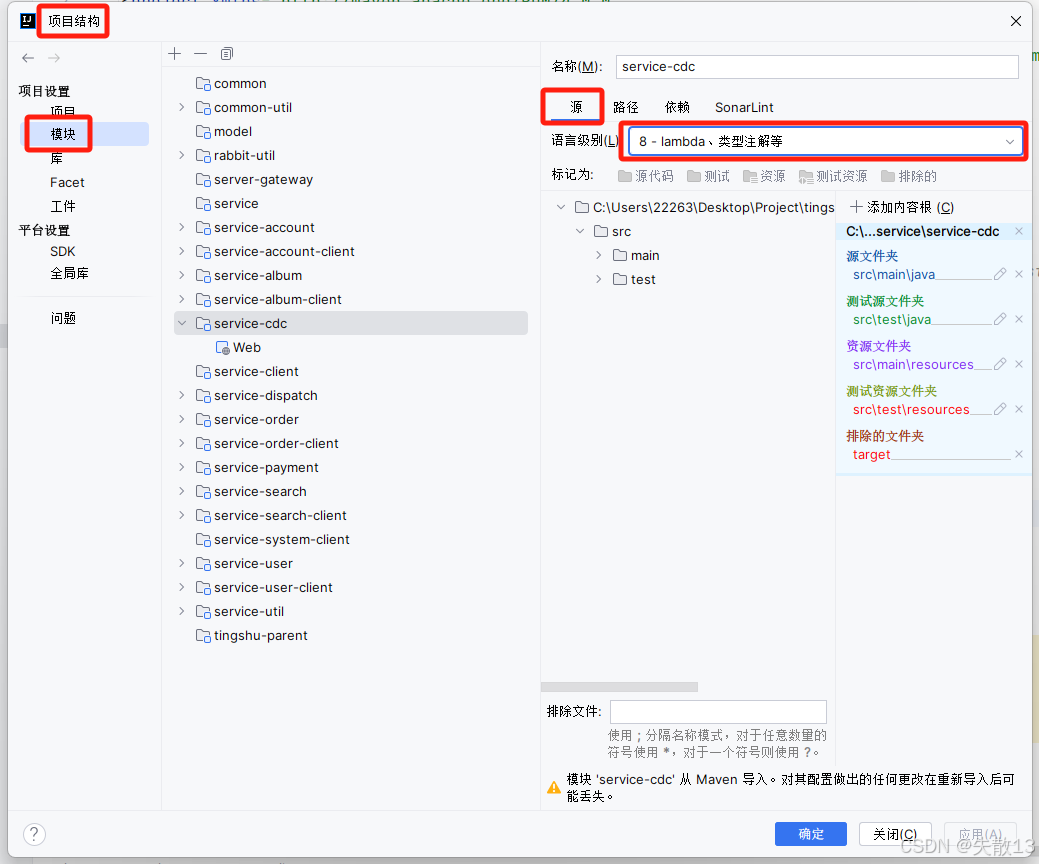
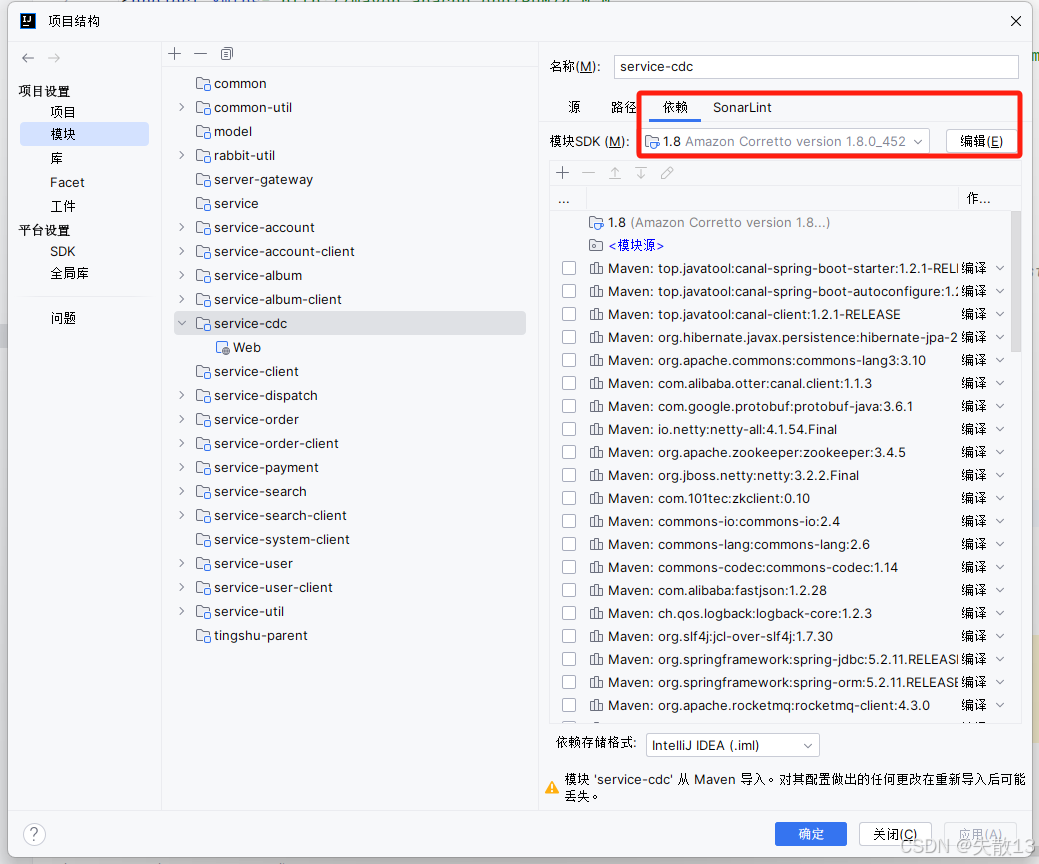
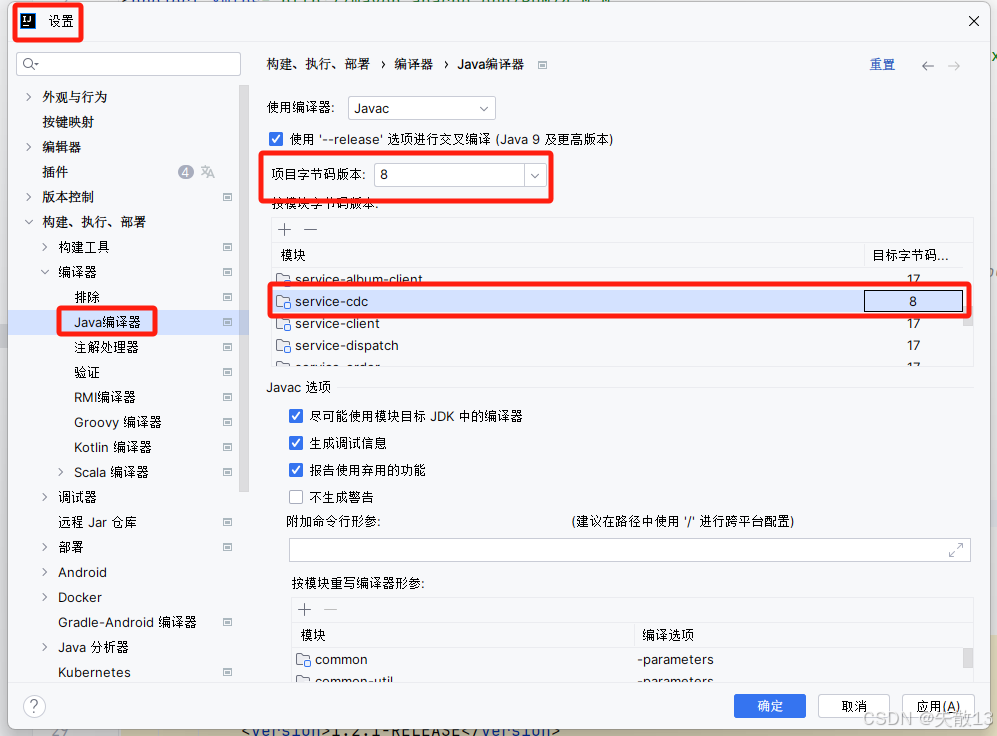
-
启动项目:
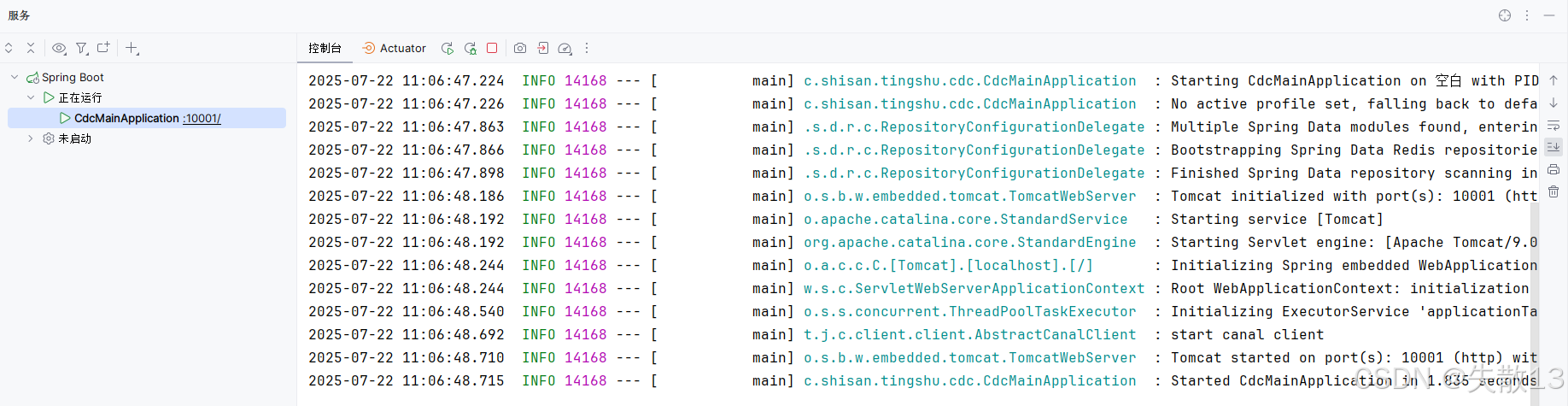
-
新建实体类:
package com.shisan.tingshu.cdc.entity;import lombok.Data;import javax.persistence.Column;/*** 映射对应(监听的)表中的字段*/ @Data public class CdcEntity {@Column(name = "id")private Long id; // 只需要监听到表中的id字段,所以只用定义一个属性就可以了 } -
编写处理器自定义实现
EntryHandler接口:-
EntryHandler接口的作用是处理 Canal 数据变更事件;- 在阿里巴巴的开源项目 Canal 中,该接口用于监听数据库表的数据变更,并将变更的数据进行处理和存储;
- 具体来说,当 Canal 客户端连接到 Canal 服务器并订阅了相应的数据库表后,每当表中的数据发生变更时,Canal 服务器会将变更的数据封装成一个
Entry对象,然后通过 Canal 协议将这个对象发送给 Canal 客户端。Canal 客户端接收到这个Entry对象后,会调用EntryHandler类的相应方法来处理这个对象;
-
实现
EntryHandler接口的类通常需要实现以下三个方法:public interface EntryHandler<T> {//监听到数据添加default void insert(T t) {}//监听到数据修改default void update(T before, T after) {}//监听数据删除default void delete(T t) {} } -
在
EntryHandler接口的实现类上会加上一个@CanalTable注解,需要传入一个参数来指定一个表名,用于在 MyBatisPlus 中与 Canal 进行数据同步。当 MyBatisPlus 执行数据库操作时,它会将操作记录到 Canal 中,然后通过监听器将 Canal 中的数据同步到目标数据库。通过使用@CanalTable注解,可以指定要同步的表名,以便只同步特定的表; -
新建:
@Component @CanalTable("album_info") // 监听变更表 @Slf4j public class CdcEntityHandler implements EntryHandler<CdcEntity> {/*** 监听的表中有数据新增的时候,会回调该方法* @param cdcEntity*/@Overridepublic void insert(CdcEntity cdcEntity) {log.info("Canal客户端监听到了album_info表中有数据的新增的id:{}", cdcEntity.getId());}/*** 监听的表中有数据变更的时候,会回调该方法* @param before 修改之前的老数据* @param after 修改后的新数据*/@Overridepublic void update(CdcEntity before, CdcEntity after) {log.info("Canal客户端监听到了album_info表中有数据的修改,修改之前的id:{}", before.getId());log.info("Canal客户端监听到了album_info表中有数据的修改,修改之后的id:{}", after.getId());}/*** 监听的表中有数据删除的时候,会回调该方法* @param cdcEntity 删除的对象*/@Overridepublic void delete(CdcEntity cdcEntity) {log.info("Canal客户端监听到了album_info表中有数据的删除,删除的数据的id:{}", cdcEntity.getId());} }
-
12.4 先删除缓存再更新数据库实现
-
流程:
-
修改:
@Component @CanalTable("album_info") // 监听变更表 @Slf4j public class CdcEntityHandler implements EntryHandler<CdcEntity> {@Autowiredprivate StringRedisTemplate redisTemplate;// @Autowired // private RabbitService rabbitService;/*** 监听的表中有数据新增的时候,会回调该方法* @param cdcEntity*/@Overridepublic void insert(CdcEntity cdcEntity) {log.info("Canal客户端监听到了album_info表中有数据的新增的id:{}", cdcEntity.getId());}/*** 监听的表中有数据变更的时候,会回调该方法* @param before 修改之前的老数据* @param after 修改后的新数据*/@Overridepublic void update(CdcEntity before, CdcEntity after) {log.info("Canal客户端监听到了album_info表中有数据的修改,修改之前的id:{}", before.getId());log.info("Canal客户端监听到了album_info表中有数据的修改,修改之后的id:{}", after.getId());String cacheKey = "cache:info:" + after.getId();// 创建一个线程池ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2);// 延迟300毫秒删除缓存try {scheduledExecutorService.schedule(new Runnable() {@Overridepublic void run() {redisTemplate.delete(cacheKey);}}, 300, TimeUnit.MICROSECONDS);} catch (Exception e) {// TODO 使用MQ进行重试删除操作 // rabbitService.sendMessage()}}/*** 监听的表中有数据删除的时候,会回调该方法* @param cdcEntity 删除的对象*/@Overridepublic void delete(CdcEntity cdcEntity) {log.info("Canal客户端监听到了album_info表中有数据的删除,删除的数据的id:{}", cdcEntity.getId());} } -
新建:
package com.shisan.tingshu.cdc.listener;import org.springframework.stereotype.Component;@Component public class CdcInfoListener {/*** TODO:监听重试发送3次*/ } -
由于包名不一致的问题,
service-cdc中有一层cdc包,所以需要在启动类上加上@Import(RabbitService.class)注解,这样才能导入rabbit-util依赖; -
修改:
/*** 修改专辑信息* @param albumId* @param albumInfoVo*/ @Transactional(rollbackFor = Exception.class) @Override public void updateAlbumInfo(Long albumId, AlbumInfoVo albumInfoVo) {// 先删除缓存,再更新数据库,在CdcEntityHandler中使用异步线程,再次删除缓存,同时加入了消息队列重试机制String cacheKey = RedisConstant.CACHE_INFO_PREFIX + albumId;redisTemplate.delete(cacheKey);// …… 其它逻辑 }
12.5 SpringEL 入门
-
SpringEL(Spring Expression Language)是Spring框架提供的一种强大的表达式语言,用于在运行时动态查询和操作对象图,支持方法调用、属性访问、运算符运算等特性;
-
简单使用:
@Test public void testApi1() {// 创建解析表达式的解析器对象ExpressionParser parser = new SpelExpressionParser();Expression expression1 = parser.parseExpression("'Hello World'.concat('!')"); // 直接将表达式作为参数传入并解析Object message1 = expression1.getValue();System.out.println(message1); // Hello World!String expression2 = "'abc'.length()"; // 定义一个表达式Expression exp2 = parser.parseExpression(expression2); // 计算abc.length的值Object message2 = exp2.getValue();System.out.println(message2); // 3String expression3 = "1+1";Expression exp3 = parser.parseExpression(expression3); // 计算1+1的值Object message3 = exp3.getValue();System.out.println(message3); // 2String expression4 = "1==1";Expression exp4 = parser.parseExpression(expression4); // 判断1==1的布尔值Object message4 = exp4.getValue();System.out.println(message4); // true }/*** 表达式中有变量*/ @Test public void testApi2() {Long[] longs = {1l, 2l, 3l};// 创建解析表达式的解析器对象ExpressionParser parser = new SpelExpressionParser();// 创建计算上下文对象StandardEvaluationContext standardEvaluationContext = new StandardEvaluationContext();standardEvaluationContext.setVariable("args", longs);// 从args变量中获取第二个元素Expression expression = parser.parseExpression("#args[1]");// 获取结果Object value = expression.getValue(standardEvaluationContext);System.out.println(value); // 2 }/*** 表达式中有临界符*/ @Test public void testApi3() {// 创建解析表达式的解析器对象ExpressionParser parser = new SpelExpressionParser();// 创建一个解析上下文模版对象【临界符】TemplateParserContext templateParserContext = new TemplateParserContext();// 定义表达式String expression = "album:Info:#{1+1}";Expression exp = parser.parseExpression(expression, templateParserContext);Object value = exp.getValue();System.out.println(value); // album:Info:2 }/*** 表达式中既有变量,又有临界符*/ @Test public void testApi4() {Long[] values = {1l, 2l, 3l};// 创建解析表达式的解析器对象ExpressionParser parser = new SpelExpressionParser();// 创建一个解析上下文模版对象【临界符】TemplateParserContext templateParserContext = new TemplateParserContext();// 创建计算上下文对象StandardEvaluationContext standardEvaluationContext = new StandardEvaluationContext();standardEvaluationContext.setVariable("args", values);// 定义表达式String expression="album:info:#{#args[0]}";// 解析Expression exp = parser.parseExpression(expression, templateParserContext);String value = exp.getValue(standardEvaluationContext, String.class);System.out.println(value); // album:info:1 }
12.6 自定义starter封装缓存操作
-
随着业务中缓存及分布式锁的加入,业务代码变的复杂起来,除了需要考虑业务逻辑本身,还要考虑缓存及分布式锁的问题,增加了程序员的工作量及开发难度;
- 接下来将对于缓存的操作都封装成一个 starter,彻底与业务代码解耦,作为一个只操作缓存的依赖来使用(谁要用谁依赖即可);
- 再借助 AOP 和自定义注解,谁需要操作缓存,就加上注解,并传入指定参数即可;
-
新建:
-
pom.xml:<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.0.5</version><relativePath/></parent><groupId>org.shisan.cache</groupId><artifactId>cache-starter</artifactId><version>1.0</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.25.0</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><skip>true</skip> <!--未来cache-starter打成的jar包不用执行,直接让对方依赖就行--></configuration></plugin></plugins></build> </project> -
项目目录的最终结构:
-
自定义注解
Cacheable接口:package org.shisan.cache.aspect.annotaion;import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;@Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface Cacheable {String cacheKey() default "";// 定义缓存keyString lockKey(); // 定义锁的keyString bloomKey(); // 定义布隆过滤器的keyboolean enableBloomFilter() default false; // 布隆开关boolean enableLock() default false; // 锁的开关 } -
自定义注解的AOP逻辑
CacheAspect类:package org.shisan.cache.aspect;import org.springframework.expression.Expression; import com.fasterxml.jackson.core.type.TypeReference; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.reflect.MethodSignature; import org.redisson.api.RBloomFilter; import org.redisson.api.RLock; import org.redisson.api.RedissonClient; import org.shisan.cache.aspect.annotaion.Cacheable; import org.shisan.cache.constant.CacheAbleConstant; import org.shisan.cache.service.CacheOpsService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.expression.common.TemplateParserContext; import org.springframework.expression.spel.standard.SpelExpressionParser; import org.springframework.expression.spel.support.StandardEvaluationContext; import org.springframework.stereotype.Component;import java.lang.annotation.Annotation; import java.lang.reflect.Method; import java.lang.reflect.Type;//@Component 此处采用SPI机制注入容器 @Aspect public class CacheAspect {@Autowiredprivate CacheOpsService cacheOpsService;@Autowiredprivate RedissonClient redissonClient;@Autowiredprivate RBloomFilter rBloomFilter;/*** 切面逻辑:查询缓存 >> 根据查询结果决定是否回源 >> 若回源则需要同步到缓存中* 使用环绕通知* 使用任何方法*/@Around(value = "@annotation(org.shisan.cache.aspect.annotaion.Cacheable)")public Object cacheCheck(ProceedingJoinPoint pjp) throws Throwable {// 1.获取目标方法的指定注解对象Cacheable cacheable = getMethodAnnotaion(pjp, Cacheable.class);// 2.获取目标方法的返回值类型(带泛型)Type genericReturnType = getMethodGerenicReturnType(pjp);// 3.定义变量// 3.1 定义缓存key表达式String cacheKeyExpression = cacheable.cacheKey();// 3.2 计算缓存keyString cacheKey = dynamicComputeKey(cacheKeyExpression, pjp, String.class);// 3.3 定义锁key表达式String lockKeyExpression = cacheable.lockKey();// 3.4 计算锁的keyString lockKey = dynamicComputeKey(lockKeyExpression, pjp, String.class);// 3.5 定义布隆过滤器的key表达式String bloomKeyExpression = cacheable.bloomKey();// 3.6 计算布隆过滤器的keyLong bloomKey = dynamicComputeKey(bloomKeyExpression, pjp, Long.class);// 3.7 获取分布式布隆过滤器的开关boolean enableBloomFilter = cacheable.enableBloomFilter();// 3.8 获取分布式锁的开关boolean enableLockFlag = cacheable.enableLock();// 4.使用布隆过滤器if (enableBloomFilter) {if (!rBloomFilter.contains(bloomKey)) {return null;}}// 5.没有使用布隆过滤器直接查询缓存Object dataFromCache = cacheOpsService.getDataFromCache(cacheKey, new TypeReference<Object>() {@Overridepublic Type getType() {return genericReturnType;}});// 6.缓存命中if (dataFromCache != null) {return dataFromCache;}// 7.缓存未命中且没有开启分布式锁if (!enableLockFlag) {// 7.1.回源Object proceed = pjp.proceed(); // 执行目标方法// 7.2 同步数据到缓存中cacheOpsService.saveDataToCache(cacheKey, proceed);// 7.3 返回数据return proceed;}// 8.开启分布式锁,获取锁对象RLock lock = redissonClient.getLock(lockKey);// 9.抢锁boolean acquireLock = lock.tryLock();// 10.抢锁成功if (acquireLock) {try {// 11.回源Object proceed = pjp.proceed(); // 执行目标方法// 12.同步数据到缓存中cacheOpsService.saveDataToCache(cacheKey, proceed);// 13.返回数据return proceed;} finally {lock.unlock(); // 释放锁}} else {// 14.抢锁失败Thread.sleep(CacheAbleConstant.DATA_SYNC_TTL); // 压测给一个精准值// 15.查询缓存Object result = cacheOpsService.getDataFromCache(cacheKey, new TypeReference<Object>() {@Overridepublic Type getType() {return genericReturnType;}});// 16. 缓存命中if (result != null) {return result;}// 17. 兜底继续回源return pjp.proceed(); // 执行目标方法}}/*** 获取目标方法带泛型的返回值类型* @param pjp* @return*/private static Type getMethodGerenicReturnType(ProceedingJoinPoint pjp) {MethodSignature methodSignature = (MethodSignature) pjp.getSignature();Method method = methodSignature.getMethod();Type genericReturnType = method.getGenericReturnType();return genericReturnType;}/*** 根据表达式获取key* @param cacheKeyExpression* @param pjp* @param resultClass* @return*/private <T> T dynamicComputeKey(String cacheKeyExpression, ProceedingJoinPoint pjp, Class<T> resultClass) {// 1.创建表达式解析器对象SpelExpressionParser spelExpressionParser = new SpelExpressionParser();// 2.创建计算上下文对象StandardEvaluationContext standardEvaluationContext = new StandardEvaluationContext();standardEvaluationContext.setVariable("args", pjp.getArgs()); // 和注解在使用时的变量名保持一致,都是args// 3.创建解析模版对象TemplateParserContext templateParserContext = new TemplateParserContext();// 4.解析表达式Expression expression = spelExpressionParser.parseExpression(cacheKeyExpression, templateParserContext);// 5.获取计算之后的值T value = expression.getValue(standardEvaluationContext, resultClass);// 6.返回缓存key的值return value;}/*** 获取目标方法的指定类型注解* @param pjp* @param tClass* @param <T>* @return*/private static <T extends Annotation> T getMethodAnnotaion(ProceedingJoinPoint pjp, Class<T> tClass) {MethodSignature methodSignature = (MethodSignature) pjp.getSignature();Method method = methodSignature.getMethod();T annotation = (T) method.getAnnotation(tClass);return annotation;} } -
在
CacheAutoConfiguration中借助 SPI 机制注入 Bean:package org.shisan.cache.configuration;import org.redisson.Redisson; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.shisan.cache.aspect.CacheAspect; import org.shisan.cache.constant.CacheAbleConstant; import org.shisan.cache.service.impl.CacheOpsServiceImpl; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.autoconfigure.data.redis.RedisProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.core.StringRedisTemplate;@Configuration // 该注解也可以省略 public class CacheAutoConfiguration {Logger logger = LoggerFactory.getLogger(this.getClass());@Autowiredprivate RedisProperties redisProperties;@Autowiredprivate StringRedisTemplate redisTemplate;/*** 定义Redisson客户端的Bean对象*/@Beanpublic RedissonClient redissonClient() {// 给Redisson设置配置信息Config config = new Config();config.useSingleServer() // 使用单机模式.setPassword(redisProperties.getPassword()).setAddress(CacheAbleConstant.CACHE_REDIS_PROTOCOL + redisProperties.getHost() + CacheAbleConstant.CACHE_REDIS_PORT_SPLIT + redisProperties.getPort());// 创建Redisson客户端RedissonClient redissonClient = Redisson.create(config);return redissonClient;}/*** 定义一个BloomFilter的Bean对象*/@Beanpublic RBloomFilter rBloomFilter(RedissonClient redissonClient) {// 如果在Redis中没有这个key,那么会自动创建,并返回这个key对应的布隆过滤器对象。反之 直接返回已经创建好的布隆过滤器// tryInit()方法返回true表示初始化成功(即之前不存在,现在新创建了),返回false表示已经存在(即之前已经初始化过)RBloomFilter<Object> albumIdBloomFilter = redissonClient.getBloomFilter(CacheAbleConstant.DISTRO_BLOOM_FILTER_NAME);// 加个锁,让分布式布隆过滤器只初始化一次且同步数据只做一次// 当锁存在的时候,表示布隆过滤器已经初始化过了,直接返回布隆过滤器对象String bloomFilterLockKey = CacheAbleConstant.DISTRO_BLOOM_FILTER_LOCK_KEY;Boolean aBoolean = redisTemplate.opsForValue().setIfAbsent(bloomFilterLockKey, CacheAbleConstant.DISTRO_BLOOM_FILTER_LOCK_VALUE);if (aBoolean) {// 初始化布隆过滤器boolean b = albumIdBloomFilter.tryInit(CacheAbleConstant.DISTRO_BLOOM_FILTER_EXCEPTED_INSERT, CacheAbleConstant.DISTRO_BLOOM_FILTER_FPP); // 利用分布式锁保证分布式布隆的初始化只做一次if (b) {logger.info("成功创建新的布隆过滤器,等待数据填充");} else {logger.info("布隆过滤器已存在,直接使用");}}return albumIdBloomFilter;}/*** 定义缓存切面类组件*/@Beanpublic CacheAspect cacheAspect() {return new CacheAspect();}/*** 定义操作缓存的业务组件*/@Beanpublic CacheOpsServiceImpl cacheOpsService() {return new CacheOpsServiceImpl();} } -
同时:

org.shisan.cache.configuration.CacheAutoConfiguration -
自定义常量类
CacheAbleConstant:package org.shisan.cache.constant;/*** 常量类*/ public class CacheAbleConstant {// 数据同步时间(需要通过压测得到)public static final Long DATA_SYNC_TTL = 200l;// 缓存协议public static final String CACHE_REDIS_PROTOCOL = "redis://";// 缓存端口的分隔符public static final String CACHE_REDIS_PORT_SPLIT = ":";// 布隆过滤器的名字public static final String DISTRO_BLOOM_FILTER_NAME = "albumIdBloomFilter";// 布隆过滤器的锁名public static final String DISTRO_BLOOM_FILTER_LOCK_KEY = "albumIdBloomFilter:lock";// 布隆过滤器的锁值public static final String DISTRO_BLOOM_FILTER_LOCK_VALUE = "1";// 布隆过滤器期望插入的元素个数public static final Long DISTRO_BLOOM_FILTER_EXCEPTED_INSERT = 1000000l;// 布隆过滤器的误判率public static final Double DISTRO_BLOOM_FILTER_FPP = 0.001;// 有数据的缓存时间public static final Long HAS_DATA_TTL = 60 * 60 * 24 * 7l;// 无数据的缓存时间public static final Long NO_DATA_TTL = 60 * 60 * 24l; } -
统一返回结果状态信息类
ResultCodeEnum:CV一下,由于cache-starter中没有引入 Lombok 依赖,所以无法使用@Data注解,需要实现get和set方法
-
自定义全局异常类
ShisanException:CV一下,由于cache-starter中没有引入 Lombok 依赖,所以无法使用@Data注解,需要实现get和set方法
-
对缓存进行读写操作的API封装:
CacheOpsService接口package org.shisan.cache.service;import com.fasterxml.jackson.core.type.TypeReference;/*** 对缓存进行读写操作的API封装*/ public interface CacheOpsService {/*** 将数据写入到缓存中(写操作)* cacheKey 将数据存储到缓存中用到的key* Object object 要保存进缓存的数据对象*/public void saveDataToCache(String cacheKey, Object object);/*** 从缓存中将数据读取出来(读操作),不带泛型* cacheKey 从缓存获取数据要用到的key* clazz 要从缓存中反序列化的类型*/public <T> T getDataFromCache(String cacheKey, Class<T> clazz);/*** 从缓存中将数据读取出来(读操作),带泛型* cacheKey 从缓存获取数据要用到的key* clazz 要从缓存中反序列化的类型*/public <T> T getDataFromCache(String cacheKey, TypeReference<T> tTypeReference); } -
对缓存进行读写操作的API封装:
CacheOpsService接口的实现类CacheOpsServiceImplpackage org.shisan.cache.service.impl;import com.fasterxml.jackson.core.type.TypeReference; import org.shisan.cache.constant.CacheAbleConstant; import org.shisan.cache.service.CacheOpsService; import org.shisan.cache.utils.Jsons; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.stereotype.Service; import org.springframework.util.StringUtils;import java.util.List; import java.util.concurrent.TimeUnit;//@Service 此处采用SPI机制注入容器 public class CacheOpsServiceImpl implements CacheOpsService {@Autowiredprivate StringRedisTemplate redisTemplate;@Overridepublic void saveDataToCache(String cacheKey, Object object) {// 将对象序列化成字符串 // String s = JSONObject.toJSONString(object);// 将字符串存储到缓存中 // redisTemplate.opsForValue().set(cacheKey,s);// 下面使用自定义的工具类完成对数据的序列化和反序列化操作String resultStr = Jsons.objToStr(object);long ttl = CacheAbleConstant.HAS_DATA_TTL;List<String> allRegexRules = Jsons.getAllRegexRules();for (String allRegexRule : allRegexRules) {if (Jsons.isMath(resultStr, allRegexRule)) {ttl = CacheAbleConstant.NO_DATA_TTL;}}// 将字符串存储到缓存中redisTemplate.opsForValue().set(cacheKey, resultStr, ttl, TimeUnit.SECONDS);}@Overridepublic <T> T getDataFromCache(String cacheKey, Class<T> clazz) {// 从缓存中获取数据// 将获取的数据反序列化成指定类型的对象// 返回指定类型的对象String resultStr = redisTemplate.opsForValue().get(cacheKey);if (StringUtils.isEmpty(resultStr)) {return null;}return Jsons.strToObj(resultStr, clazz);}@Overridepublic <T> T getDataFromCache(String cacheKey, TypeReference<T> tTypeReference) {// 1.从缓存中获取数据// 2.将获取的数据反序列化成指定类型的对象// 3.返回指定类型的对象String resultStr = redisTemplate.opsForValue().get(cacheKey);if (StringUtils.isEmpty(resultStr)) {return null;}return Jsons.strToObj(resultStr, tTypeReference);} } -
自定义完成对数据的序列化和反序列化操作
Jsons类:package org.shisan.cache.utils;import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.core.type.TypeReference; import com.fasterxml.jackson.databind.ObjectMapper; import org.shisan.cache.exception.ShisanException; import org.slf4j.Logger; import org.slf4j.LoggerFactory;import java.util.ArrayList; import java.util.List; import java.util.regex.Pattern;/*** 完成对数据的序列化和反序列化操作*/ public class Jsons {static Logger logger = LoggerFactory.getLogger(Jsons.class);static final ObjectMapper objectMapper = new ObjectMapper();/*** 序列化操作:接收对象,返回字符串*/public static String objToStr(Object content) {// 可以完成对任意数据的序列化和反序列化操作// @RequestBody注解的底层使用的就是ObjectMapper完成的操作:将字符串反序列化成对象// @ResponseBody注解的底层使用的就是ObjectMapper完成的操作:将对象转成字符串// 传过来的对象有以下几种情况// 1、对象有数据// 2、对象没数据:// 2.1 对象为空,传过来的就是null// 2.2 对象是一个Map(双列),为空时传过来的就是{}// 2.3 对象是是一个List(单列),为空时传过来的就是[]// 2.4 对象是是一个Set(单列),为空时传过来的就是[]// 2.5 对象是一个数组String[],为空时传过来的就是[]try {String resultStr = objectMapper.writeValueAsString(content);return resultStr;} catch (JsonProcessingException e) {logger.error("{}对象序列化成字符串失败,原因是{}", content, e.getMessage());throw new ShisanException(201, "数据在转换期间出现了序列化异常");}}/*** 反序列化操作:接收字符串,返回对象【指定的类型】(不带泛型)* @return*/public static <T> T strToObj(String content, Class<T> tClass) {try {// "{"name":"shisan","age":18}"--Map.class// "{}"---Map.class// "[]"---List.class Set.class Array.classT t = objectMapper.readValue(content, tClass);return t;} catch (JsonProcessingException e) {logger.error("{}字符串反序列化成对象失败,原因是{}", content, e.getOriginalMessage());throw new ShisanException(201, "数据在转换期间出现了反序列化异常");}}/*** 反序列化操作:接收字符串,返回对象【指定的类型】(带泛型)* @return*/public static <T> T strToObj(String content, TypeReference<T> tClass) {try {// "{"name":"shisan","age":18}"--Map.class// "{}"---Map.class// "[]"---List.class Set.class Array.classT t = objectMapper.readValue(content, tClass);return t;} catch (JsonProcessingException e) {logger.error("{}字符串反序列化成对象失败,原因:{}", content, e.getOriginalMessage());throw new ShisanException(201, "数据在转换期间出现了反序列化异常");}}public static List<String> getAllRegexRules() {ArrayList<String> list = new ArrayList<>();list.add("^null$");list.add("^\\{\\}$");list.add("^\\[\\]$");return list;}public static Boolean isMath(String compareContent, String regexRule) {return Pattern.matches(regexRule, compareContent);} }
12.7 cache-starter的使用之稍微解耦版
-
修改:引入
cache-starter依赖
<dependency><groupId>org.shisan.cache</groupId><artifactId>cache-starter</artifactId><version>1.0</version> </dependency> -
如果只是调用对缓存进行读写操作的API,即只调用
cache-starter依赖中的CacheOpsServiceImpl方法,步骤如下: -
修改:
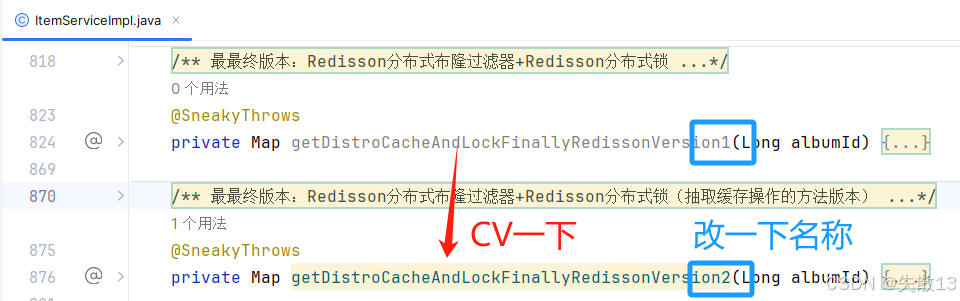
@Autowired private CacheOpsService cacheOpsService;/*** 根据专辑id查询专辑详情* @param albumId* @return*/ @Override public Map<String, Object> getAlbumInfo(Long albumId) {// 如果只是调用对缓存进行读写操作的API,即只调用`cache-starter`依赖中的`CacheOpsServiceImpl`方法return getDistroCacheAndLockFinallyRedissonVersion2(albumId); }/*** 最最终版本:Redisson分布式布隆过滤器+Redisson分布式锁(抽取缓存操作的方法版本)* @param albumId* @return*/ @SneakyThrows private Map getDistroCacheAndLockFinallyRedissonVersion2(Long albumId) {// 1.定义缓存keyString cacheKey = RedisConstant.CACHE_INFO_PREFIX + albumId; // 缓存keyString lockKey = RedisConstant.ALBUM_LOCK_SUFFIX + albumId; // 分布式锁keylong ttl = 0l; // 数据的过期时间// 2.查询分布式布隆过滤器boolean contains = rBloomFilter.contains(albumId);if (!contains) {return null;}// 3.查询缓存Map dataFromCache = cacheOpsService.getDataFromCache(cacheKey, Map.class);// 3.1 缓存命中if (dataFromCache != null) {return dataFromCache;}// 3.2 缓存未命中 查询数据库// 3.2.1 添加分布式锁RLock lock = redissonClient.getLock(lockKey);boolean accquireLockFlag = lock.tryLock(); // tryLock:非阻塞、自动续期if (accquireLockFlag) { // 抢到锁try {// 3.2.2 回源查询数据Map<String, Object> albumInfoFromDb = getAlbumInfoFromDb(albumId);// 3.2.3 同步数据到缓存中去cacheOpsService.saveDataToCache(cacheKey, albumInfoFromDb);return albumInfoFromDb;} finally {lock.unlock();// 释放锁}} else { // 没抢到锁。等同步时间之后,查询缓存即可Thread.sleep(200);Map result = cacheOpsService.getDataFromCache(cacheKey, Map.class);if (result != null) {return result;}return getAlbumInfoFromDb(albumId);} }
12.8 cache-starter的使用之彻底解耦版+测试
-
修改:给需要操作缓存的接口加上
@Cacheable注解
@GetMapping("/{albumId}") @Operation(summary = "根据专辑id查询专辑详情") @Cacheable(cacheKey = RedisConstant.CACHE_INFO_PREFIX + "#{#args[0]}", // 要传递方法中的第几个参数就写第几个参数lockKey = RedisConstant.ALBUM_LOCK_SUFFIX+"#{#args[0]}",bloomKey = "#{#args[0]}",enableBloomFilter = true,enableLock = true) public Result getAlbumInfo(@PathVariable(value = "albumId") Long albumId) {Map<String, Object> result = itemService.getAlbumInfo(albumId);return Result.ok(result); } -
修改:因为所有关于缓存、分布式锁、布隆过滤器的逻辑都在
cache-starter中实现了,所以只需要在原方法中回源查询数据库即可/*** 根据专辑id查询专辑详情* @param albumId* @return*/ @Override public Map<String, Object> getAlbumInfo(Long albumId) {// 回源查询数据库return getAlbumInfoFromDb(albumId); } -
测试:
-
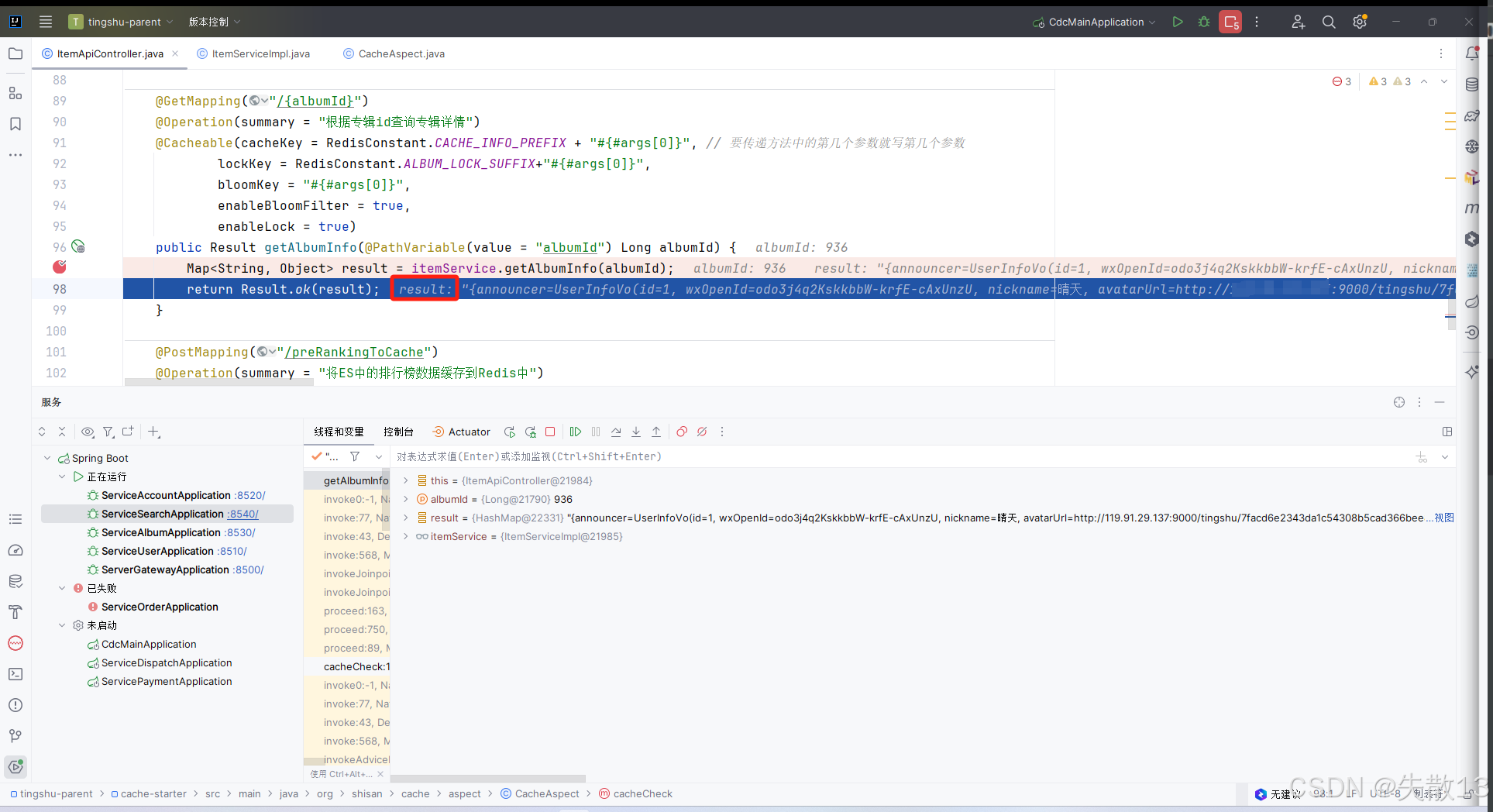
先打断点
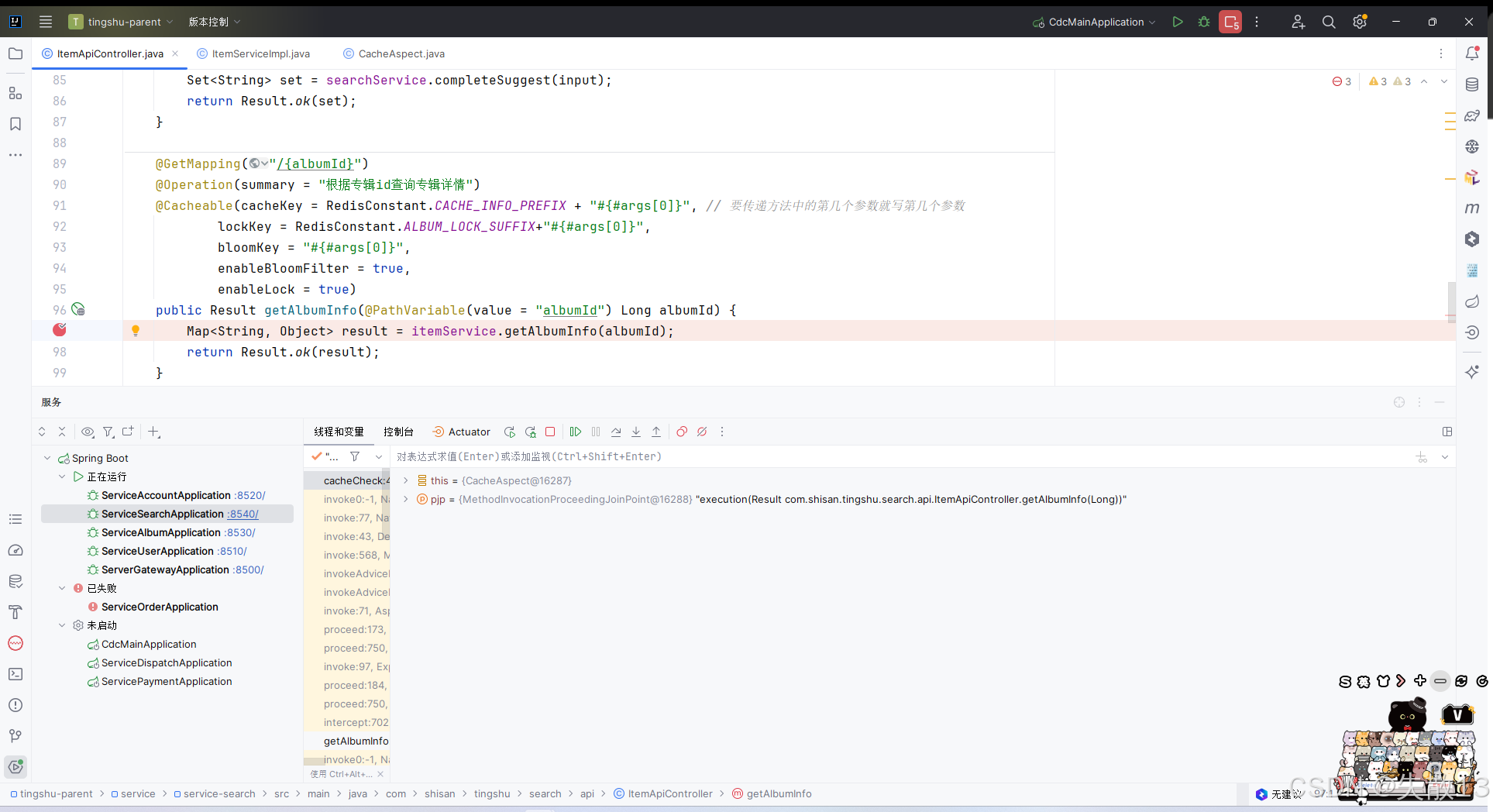
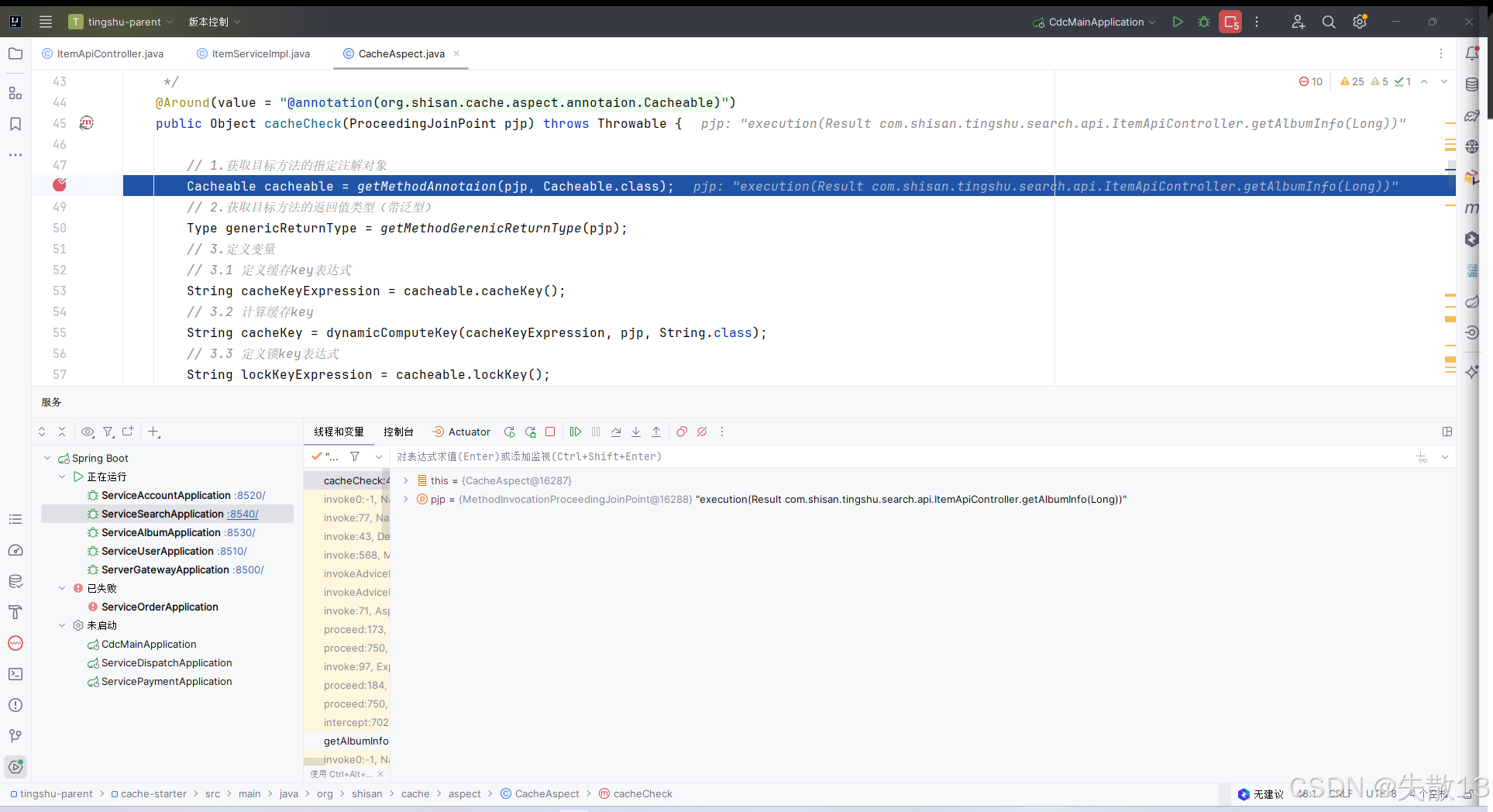
-
浏览器访问
http://localhost:8500/api/search/albumInfo/936,然后逐条步过: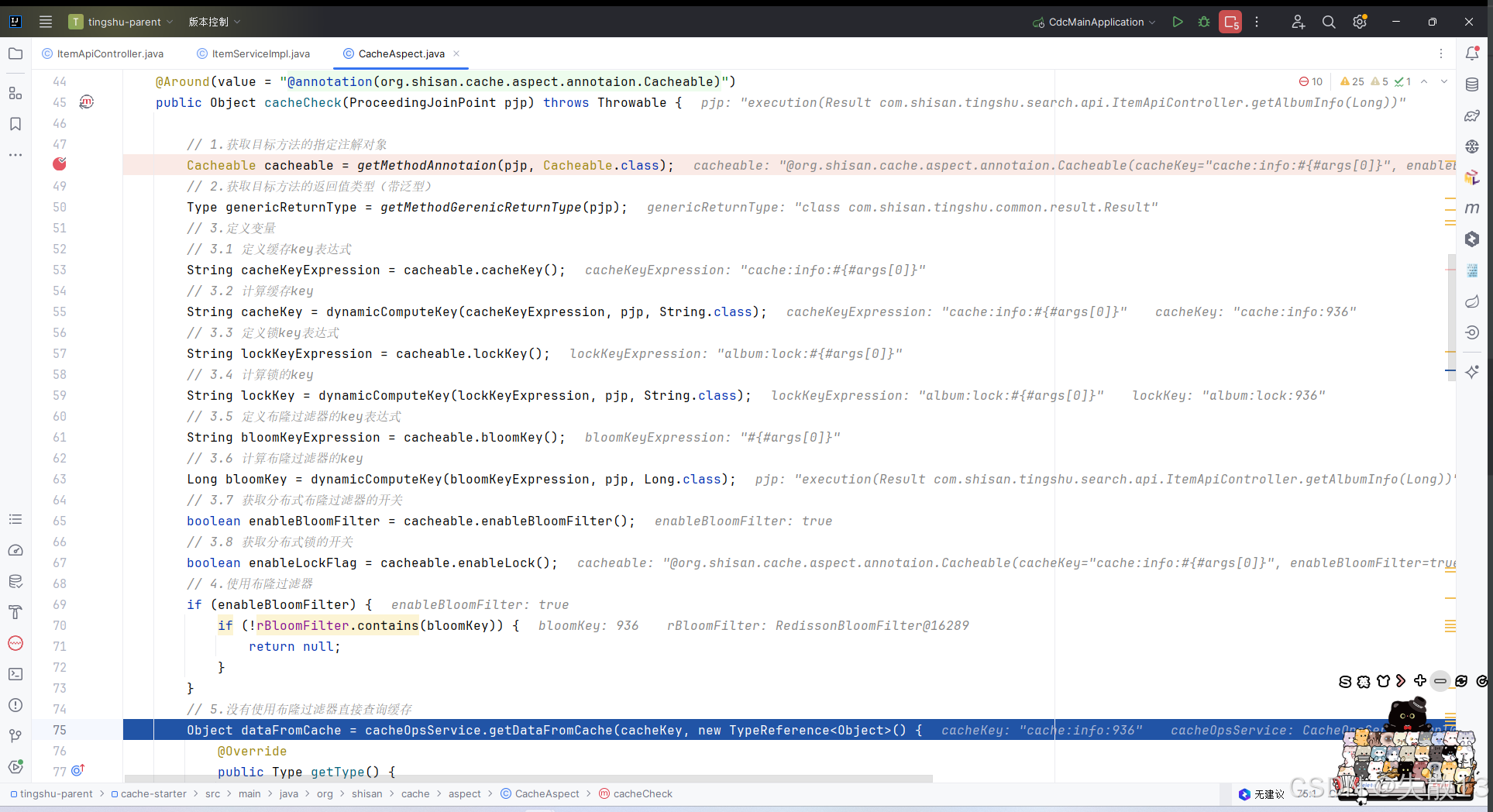
-
得到结果:
-
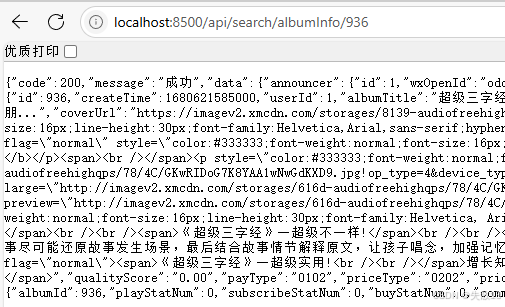
返回前端:
-