【AI论文】MiroMind-M1:通过情境感知多阶段策略优化实现数学推理的开源新进展
摘要:近期,大型语言模型已从流畅的文本生成发展至能在多个领域进行高级推理,由此催生了推理语言模型(RLMs)。在众多领域中,数学推理堪称代表性基准,因为它需要精确的多步骤逻辑与抽象推理能力,且这种能力可推广至其他任务。虽然像GPT-o3这样的闭源推理语言模型展现出了惊人的推理能力,但其专有属性限制了透明度和可复现性。尽管许多开源项目旨在弥补这一差距,但其中多数因省略了数据集和详细训练配置等关键资源而缺乏足够的开放性,进而阻碍了可复现性。为推动推理语言模型开发实现更高透明度,我们推出了MiroMind-M1系列模型,这是一套基于Qwen-2.5主干构建的完全开源的推理语言模型,其性能可媲美或超越现有的开源推理语言模型。具体而言,我们的模型分两个阶段进行训练:先在精心整理的、包含71.9万个数学推理问题及已验证思维链(CoT)轨迹的语料库上进行监督微调(SFT),随后在6.2万个具有挑战性且可验证的问题上进行基于验证的强化学习(RLVR)。为增强RLVR过程的稳健性和效率,我们引入了情境感知多阶段策略优化算法,该算法将渐进式长度训练与自适应重复惩罚相结合,以鼓励基于情境感知的强化学习训练。我们的模型在AIME24、AIME25和MATH基准测试中,在基于Qwen-2.5的开源70亿(7B)和320亿(32B)参数模型中取得了最先进或具有竞争力的性能,且具有更高的标记(token)效率。为便于复现,我们公开了全套资源:模型(MiroMind-M1-SFT-7B、MiroMind-M1-RL-7B、MiroMind-M1-RL-32B);数据集(MiroMind-M1-SFT-719K、MiroMind-M1-RL-62K);以及所有训练和评估配置。我们希望这些资源能支持进一步的研究并推动社区发展。Huggingface链接:Paper page,论文链接:2507.14683
研究背景和目的
研究背景:
近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著进展,尤其是基于Transformer架构的模型,通过大规模预训练和上下文学习能力,在规划、推理和问题解决等方面表现出色。然而,尽管这些模型在文本生成上非常流畅,但在复杂推理任务上仍面临挑战。推理语言模型(RLMs)作为专门训练以产生多步思维链(CoT)的模型,逐渐成为研究热点。特别是在数学推理领域,由于其需要精确的多步骤逻辑和抽象推理能力,成为评估RLMs性能的理想基准。
尽管闭源RLMs如GPT-o3和Claude Sonnet 4展示了令人印象深刻的推理能力,但其专有性限制了透明度和可复现性。虽然许多开源项目试图弥补这一差距,但大多数项目因缺乏关键资源(如精心整理的数据集和详细的训练配置)而不足以支持完全的可复现性。这种不透明性阻碍了科学创新的进一步发展,尤其是在需要高度透明度和可验证性的推理任务中。
研究目的:
本研究旨在通过开发一个完全开源的RLMs系列——MiroMind-M1,来提高RLMs开发的透明度,并推动该领域的进一步研究。具体目标包括:
- 构建一个高质量的数学推理数据集,用于监督微调(SFT)和基于验证的强化学习(RLVR)。
- 提出一种情境感知多阶段策略优化(CAMPO)算法,以提高RLVR过程的稳健性和效率。
- 开发一系列基于Qwen-2.5主干的开源RLMs,在数学推理基准测试上达到或超过现有开源模型的性能。
- 公开所有模型、数据集和训练配置,以支持进一步的研究和社区发展。
研究方法
数据集构建:
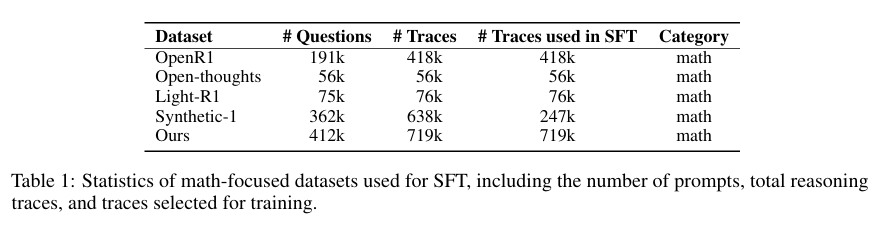
研究从多个公开来源收集数学推理问题,包括OpenR1、OpenThoughts、Light-R1和Synthetic-1等数据集。通过严格的去重和去污染处理,确保数据质量,并避免与评估基准的数据泄露。最终构建了包含71.9万个数学推理问题的SFT数据集(MiroMind-M1-SFT-719K)和6.2万个具有挑战性且可验证问题的RLVR数据集(MiroMind-M1-RL-62K)。
模型训练:
- 监督微调(SFT): 使用Qwen-2.5-Math-7B作为初始检查点,在71.9万个数学推理问题上进行了3个epoch的SFT训练。采用无填充(no-packing)策略,设置峰值学习率为5.0×10^-5,批量大小为128,最大位置嵌入增加到32,768。
- 基于验证的强化学习(RLVR): 在6.2万个具有挑战性且可验证的问题上进行了RLVR训练。采用多阶段训练策略,逐步增加最大响应长度,从初始的16,384逐步增加到32,768和49,152。引入CAMPO算法,通过长度渐进式训练和自适应重复惩罚,提高训练的稳健性和效率。
CAMPO算法:
CAMPO算法通过多阶段训练策略,结合长度渐进式训练和自适应重复惩罚,鼓励情境感知的强化学习训练。具体实现包括:
- 多阶段训练: 逐步增加最大响应长度,提高训练效率。
- 自适应重复惩罚: 通过动态调整重复惩罚系数,减少冗余输出,提高输出多样性。
- 准确的验证器: 改进数学验证器,提高奖励信号的准确性,减少验证错误对训练的干扰。
研究结果
模型性能:
MiroMind-M1系列模型在AIME24、AIME25和MATH基准测试上取得了显著性能提升。具体而言:
- MiroMind-M1-RL-32B在AIME24上达到了77.5%的准确率,在AIME25上达到了65.6%,在MATH500上达到了96.4%。
- MiroMind-M1-RL-7B在AIME24上达到了73.4%的准确率,在AIME25上达到了57.8%,在MATH500上达到了96.7%。
效率提升:
通过CAMPO算法,MiroMind-M1系列模型在保持高性能的同时,显著提高了标记效率。特别是在较短的响应长度下,MiroMind-M1-RL-32B和MiroMind-M1-RL-7B均表现出比基准模型更高的准确率。
开源贡献:
研究公开了所有模型、数据集和训练配置,包括MiroMind-M1-SFT-7B、MiroMind-M1-RL-7B和MiroMind-M1-RL-32B模型,MiroMind-M1-SFT-719K和MiroMind-M1-RL-62K数据集,以及详细的训练和评估配置。这些资源为进一步的研究和社区发展提供了有力支持。
研究局限
尽管MiroMind-M1系列模型在数学推理任务上取得了显著进展,但研究仍存在一些局限性:
- 数据集覆盖有限: 尽管研究构建了大规模的数学推理数据集,但仍可能无法覆盖所有类型的数学问题。特别是某些高度专业化或复杂的数学领域,可能需要更多的数据进行训练。
- 模型规模限制: 当前研究主要基于Qwen-2.5系列的7B和32B参数模型。虽然这些模型在数学推理任务上表现出色,但更大规模的模型可能进一步提高性能。然而,更大规模模型的训练需要更多的计算资源和数据支持。
- 评估稳定性: 在AIME24和AIME25等具有挑战性的基准测试上,评估结果的稳定性成为一个问题。由于这些基准测试包含的问题数量较少,微小的正确答案数量变化可能导致性能波动较大。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
- 扩展数据集覆盖: 进一步收集和整理更多类型的数学推理问题,特别是那些高度专业化或复杂的数学领域。同时,考虑引入多语言和多领域的推理问题,提高模型的泛化能力。
- 开发更大规模的模型: 利用更多的计算资源和数据支持,开发基于更大规模预训练模型的RLMs。通过增加模型参数和复杂度,进一步提高模型在数学推理任务上的性能。
- 提高评估稳定性: 探索更稳定的评估方法和指标,减少因问题数量较少导致的性能波动。例如,可以增加评估问题数量、采用多次运行取平均值等方法,提高评估结果的可靠性和稳定性。
- 探索其他推理任务: 将MiroMind-M1系列模型的研究方法应用于其他类型的推理任务,如科学推理、逻辑推理和代码生成等。通过扩展模型的应用领域,进一步验证CAMPO算法的有效性和普适性。
- 优化训练过程: 进一步研究CAMPO算法的优化策略,如更精细的长度渐进式训练计划、更智能的自适应重复惩罚机制等。通过优化训练过程,提高模型的训练效率和性能表现。
总之,本研究通过开发完全开源的MiroMind-M1系列模型,提高了RLMs开发的透明度,并在数学推理任务上取得了显著进展。未来研究可以从扩展数据集覆盖、开发更大规模的模型、提高评估稳定性、探索其他推理任务和优化训练过程等方面展开,进一步推动RLMs领域的发展。