数字孪生映射探索驱动的具身导航!MorphoNavi:面向对象映射的空地机器人导航

作者: Sausar Karaf, Mikhail Martynov, Oleg Sautenkov, Zhanibek Darush, Dzmitry Tsetserukou
单位:俄罗斯斯科尔科沃科学技术研究院智能空间机器人实验室
论文标题:MorphoNavi: Aerial-Ground Robot Navigation with Object Oriented Mapping in Digital Twin
论文链接:https://arxiv.org/pdf/2504.16914
主要贡献
提出了面向通用空地机器人的单目相机映射方法,能够在无需针对特定环境微调的情况下检测多种物体并估计其位置。
通过模拟搜索救援场景验证了该方法的有效性,MorphoGear机器人成功定位到机器狗,为开发能够在非结构化环境中运行的智能多模态机器人系统做出了贡献。
该方法在保留物体语义信息的同时,减少了对高带宽通信的需求,且与现有的机器人感知系统兼容,可作为低成本替代方案,适用于仅配备相机和有限计算资源的机器人。
研究背景
近年来,机器人领域发展迅速,尤其是基于RGB图像的视觉语言模型(VLMs)成为执行任务的强大工具,其仅需图像和文本提示输入,无需昂贵的激光雷达和深度相机等传感器。
传统的映射技术(如点云、八叉树和网格恢复技术)主要关注物体形状的保留,而本研究提出的方法还保留了物体的语义信息,有助于实现更高层次的理解,例如推断房间功能、规划多阶段任务等。
单目深度估计是机器人感知的关键部分,相关技术如ZoeDepth、Depth-Anything等在相对深度估计和度量深度估计方面取得了进展。同时,YOLO系列、Detectron2等模型在目标检测方面表现出色,但存在类别限制,需要额外训练。而零样本和开放词汇检测器(如Grounding DINO 1.5 Pro、DINO X)以及基于变换器架构的模型(如OWL-ViT、OWLV2)为识别预训练类别之外的物体提供了可能。
视觉语言模型(VLMs)如Molmo、ChatGPT等在整合视觉和文本数据方面取得了突破,但其训练主要基于二维图像-文本对应关系,缺乏三维空间推理或深度感知能力,限制了其在机器人导航等需要三维环境理解的应用中的使用。为解决这一问题,出现了视觉语言行动(VLA)模型,如RT-1、PaLM-E等,但它们依赖于大规模、特定任务的数据集,且数据收集成本高、适用范围有限。
研究方法
系统由MorphoGear空地机器人、带有控制界面的笔记本电脑以及配备定位系统的环境组成。所有计算在机器人(控制)或个人电脑(映射)上进行,使用Unity游戏引擎进行模拟和控制。
MorphoGear机器人

是一种具有地面移动、物体抓取和空中运动能力的无人空地车辆(AGV),其硬件包括OrangePi 5b伴生计算机、OrangeCube飞行控制器、基于STM32的自定义肢体控制器和ELP-USBFHD05H 2MP 2.8-12mm 1:1.4 1/2.7” MJPEG相机。软件基于ROS2 Iron,包含用于高级命令的Python节点和mavros,ROS#用于生成肢体运动。
地面站

操作员使用配备Unity和Python的笔记本电脑作为地面站,开发了机器人的数字孪生模型,用于虚拟实验和作为控制面板。机器人将状态发送到Unity,Unity仅作为可视化工具。通过ROS-TCP-Connector将Unity中的命令发送到机器人。
环境
实验在一个6x10x4米的房间内进行,工作空间由网限制,路径规划网格为5x8x3米,配备了VICON定位系统。
映射算法
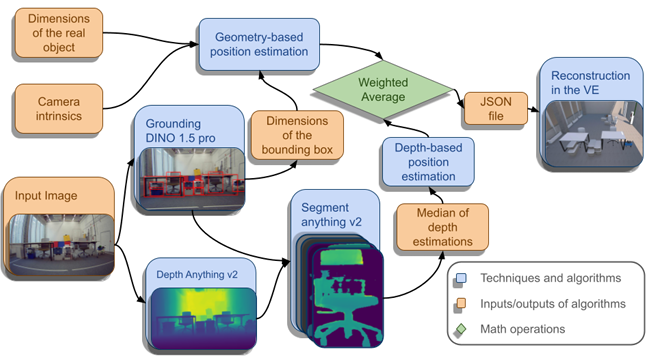
系统以单目RGB图像作为输入,通过检测物体并根据其已知几何尺寸估计其位置来导航。在开发过程中,评估了包括OWLv2、OWL-ViT和DINO-X在内的多种目标检测模型,最终选择了OWLv2和Grounding DINO 1.5 Pro模型。
基于已知的物体尺寸、相机内参和目标检测器获得的边界框,利用公式估算物体距离,并结合Depth Anything v2和Segment Anything v2的深度估计结果,计算最终物体距离。处理后的物体数据被封装成JSON文件并传输到基于Unity的模拟环境中。
实验
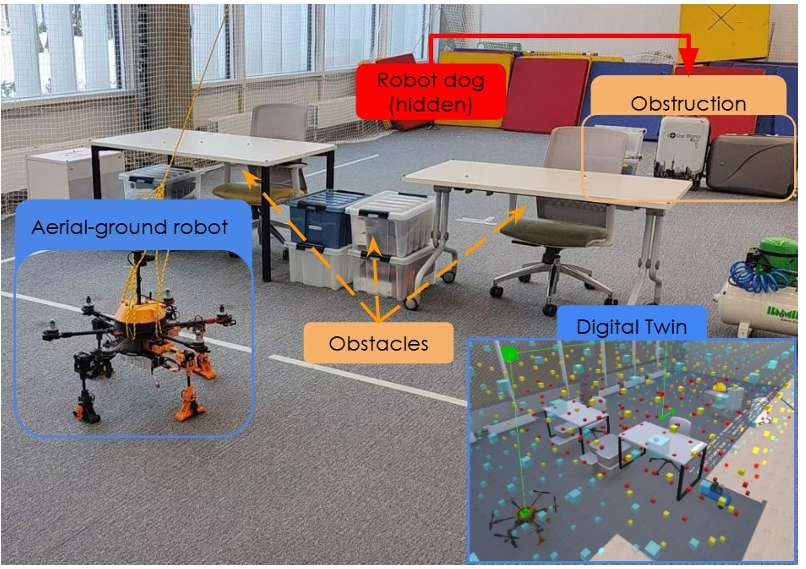
通过模拟搜索救援场景评估所提出的系统,设置了一个机器狗遇到问题需要外部干预的案例,MorphoGear机器人的任务是定位机器狗。
实验设置
在测试环境中放置了桌子、箱子和椅子等障碍物,限制了机器人的初始视野,使全图观察变得困难。机器狗被放置在由堆叠箱子组成的障碍物后面,以验证MorphoGear机器人在地面和空中运动模式之间的转换能力。
实验过程
任务开始时,空地车辆捕获环境的初始图像,该图像被映射管道处理,计算物体位置并发送到Unity基础的GUI进行可视化和规划。使用生成的地图和机器人的位置构建障碍物网格,并由A*算法为MorphoGear机器人规划轨迹。
实验结果
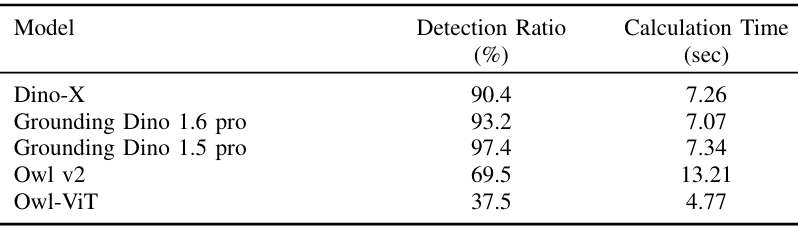
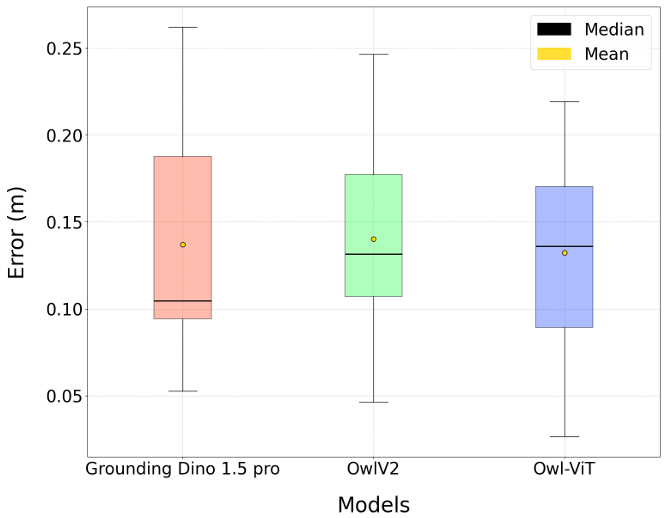
系统成功检测并定位了场景中97.4%的目标物体,平均位置估计误差为13.6厘米,平均每张图像的处理时间为7.34秒。
尽管系统在受控实验室条件下表现良好,但仍存在一些局限性,如遮挡问题导致物体位置精度下降,对于未知形状和不同方向的物体,基于单目的距离估计算法不够准确,且系统尚未实现实时处理。
结论与未来工作
- 结论:
论文提出了一种利用单目相机的通用空地机器人映射方法,能够在复杂环境中检测多种物体并估计其位置,无需针对特定环境进行微调。
通过模拟搜索救援场景验证了该方法的有效性,MorphoGear机器人成功定位到机器狗,系统在目标检测率、位置估计准确性和处理时间方面表现出色。
- 未来工作:
尽管如此,仍有一些需要改进的地方,如遮挡问题、未知形状和不同方向物体的距离估计准确性以及实时处理能力。
未来的工作将探索层次化和基于深度学习的方法来解决这些问题,还将研究将该映射系统与视觉语言模型(VLMs)集成,以增强其空间理解和认知推理能力,并探索实时优化策略以减少处理延迟,使系统更适合动态搜索救援场景。
