探索大语言模型(LLM):提升 RAG 性能的全方位优化策略
提升 RAG 性能的全方位优化策略:从理论到实践
在大语言模型(LLM)应用日益普及的今天,检索增强生成(RAG)技术已成为连接外部知识与模型推理的核心桥梁。然而,基础版 RAG 系统往往难以满足复杂业务场景的需求,如何提升其准确性、效率和鲁棒性成为开发者关注的焦点。本文将基于 Milvus 官方技术文档,深入解析 RAG 流水线的优化策略,涵盖查询增强、索引优化、检索器升级、生成器调优及全流程增强等多个维度,助力开发者打造高性能 RAG 应用。
一、RAG 基础:从标准流水线说起
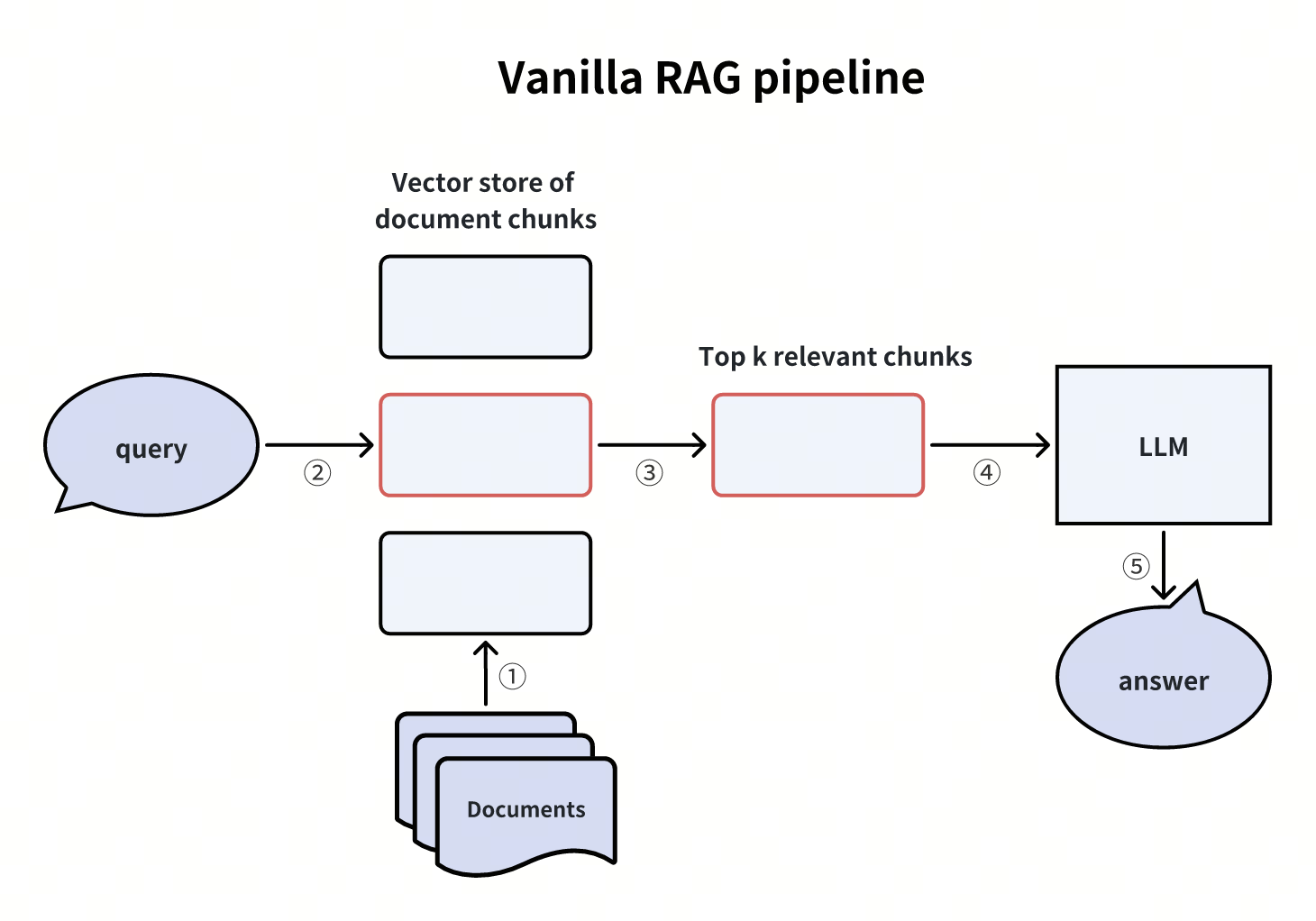
在探讨优化策略前,我们先回顾标准 RAG 流水线的核心流程:
- 检索:根据用户的查询内容,从知识库中获取相关信息,通过相似性搜索找出最匹配的数据。
- 增强:将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中。
- 生成:将经过检索增强的提示词内容输入到大语言模型中,以生成所需的输出。
这些步骤共同构成了RAG的工作流程,旨在提高生成模型的准确性和可靠性。
尽管基础流程简单,但实际应用中需应对跨域检索不对称、复杂查询处理困难等问题。以下将从五个维度展开优化方案。
二、查询增强:让问题 “问对方向”
查询是 RAG 的起点,优化查询表达能直接提升检索精度。主流方法包括:
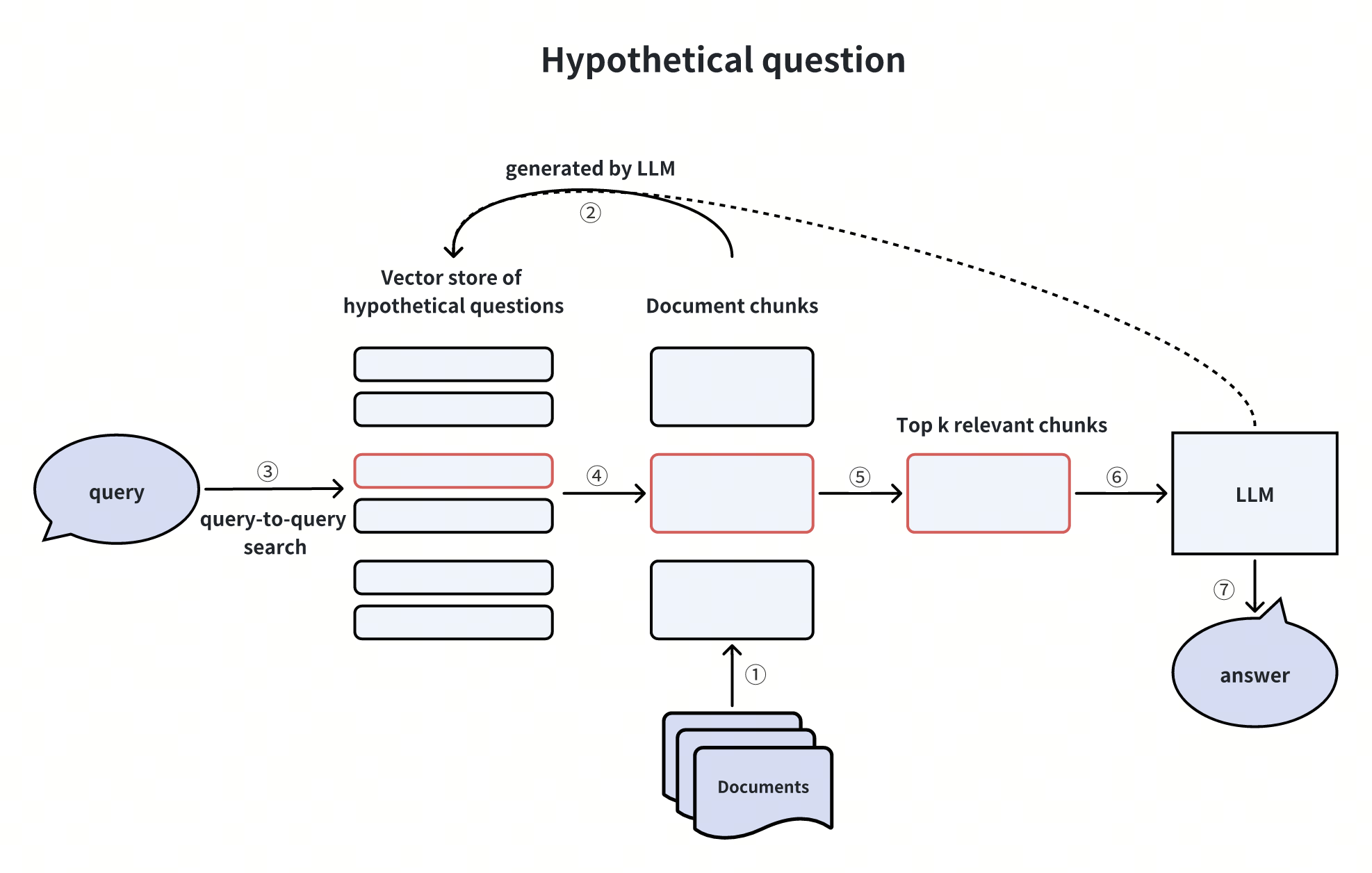
1. 生成假设性问题(Hypothetical Questions)
通过 LLM 为每个文档 chunk 生成可能的用户问题,将这些问题存入向量库。用户查询时,先检索最相关的假设性问题,再关联其对应的文档 chunk。
优势:通过 “查询 - 查询” 匹配规避跨域向量检索偏差;
局限:增加了预生成问题的计算开销。
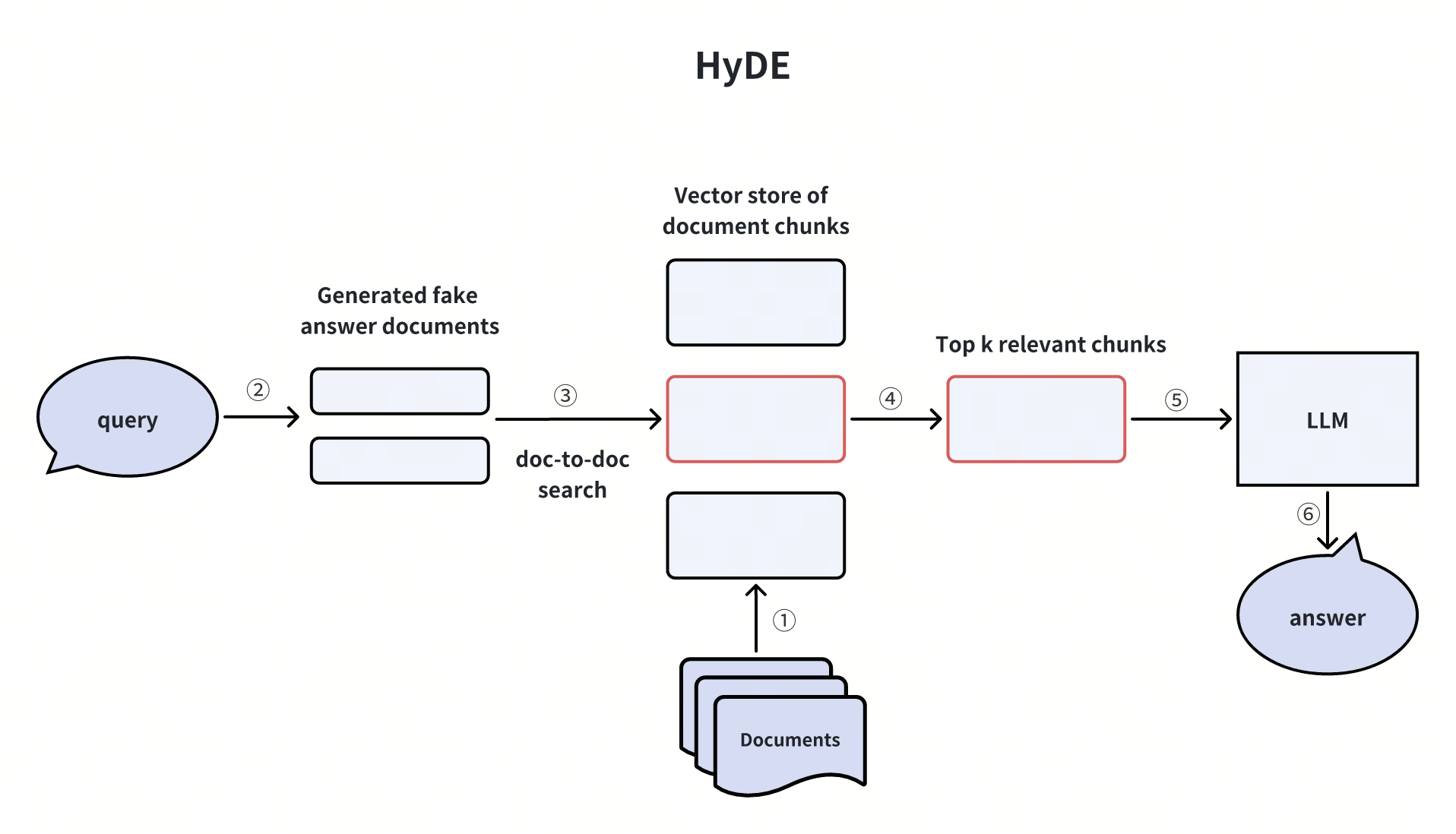
2. 假设性文档嵌入(HyDE)
用 LLM 为用户查询生成 “假文档”(模拟理想答案),将假文档的向量嵌入用于检索真实文档 chunk。
适用场景:用户查询模糊或领域术语复杂时,通过假文档校准检索方向。
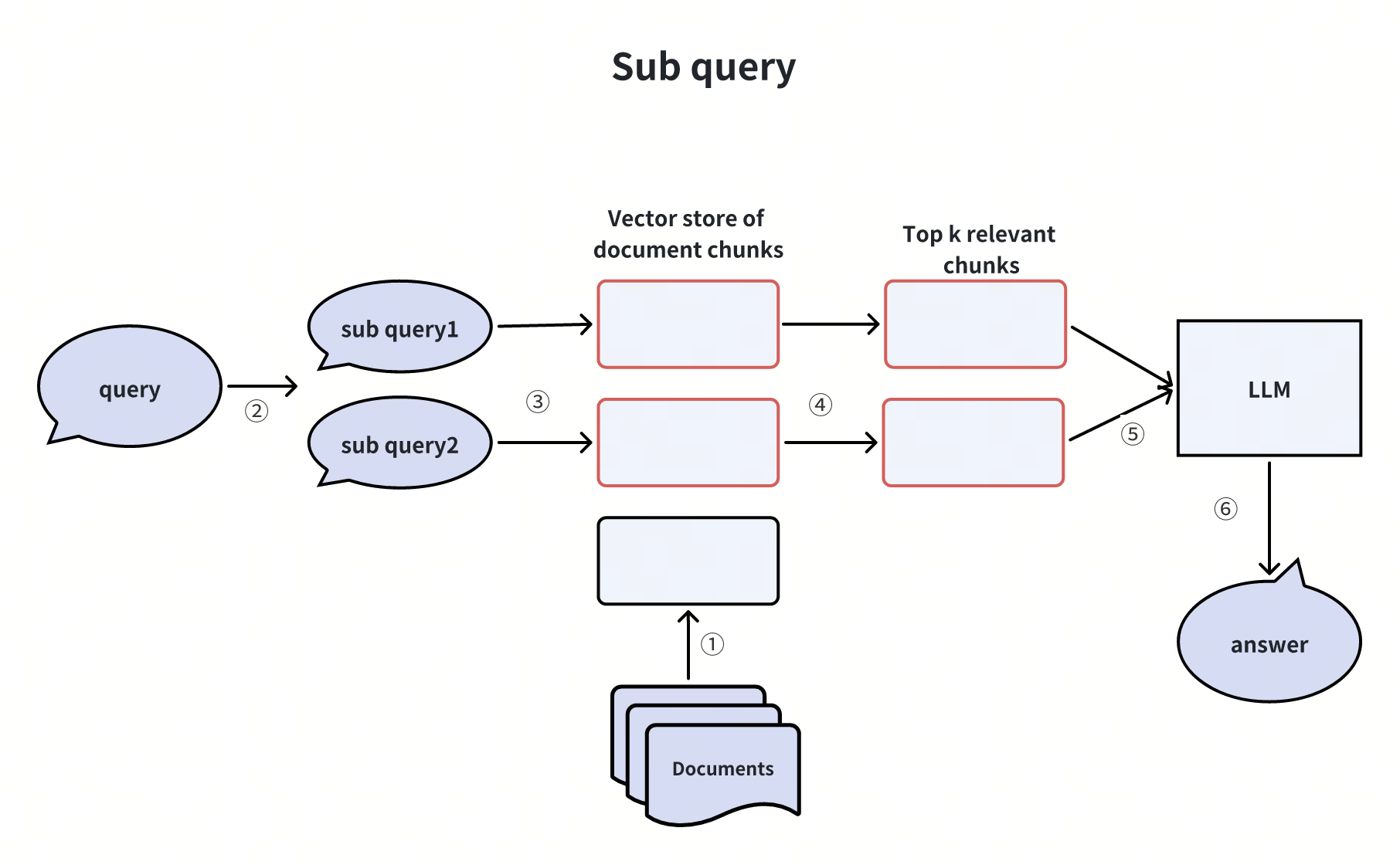
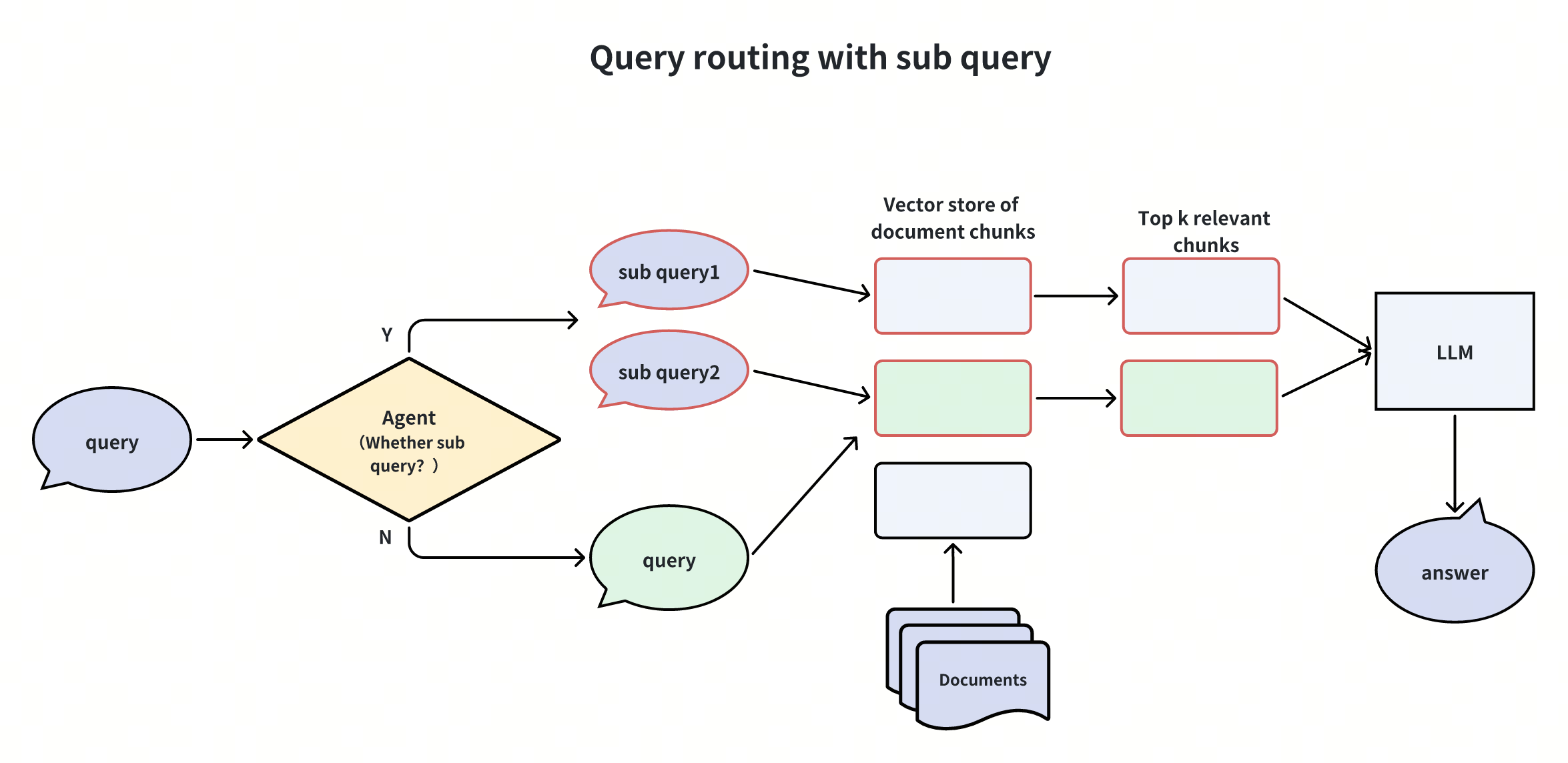
3. 子查询拆分(Sub-Queries)
将复杂问题拆解为简单子问题,分别检索后汇总结果。例如,“Milvus 与 Zilliz Cloud 的功能差异” 可拆分为两个子查询:
-
“Milvus 的核心功能是什么?”
-
“Zilliz Cloud 的核心功能是什么?”
优势:降低复杂查询的检索难度,提升信息覆盖率。
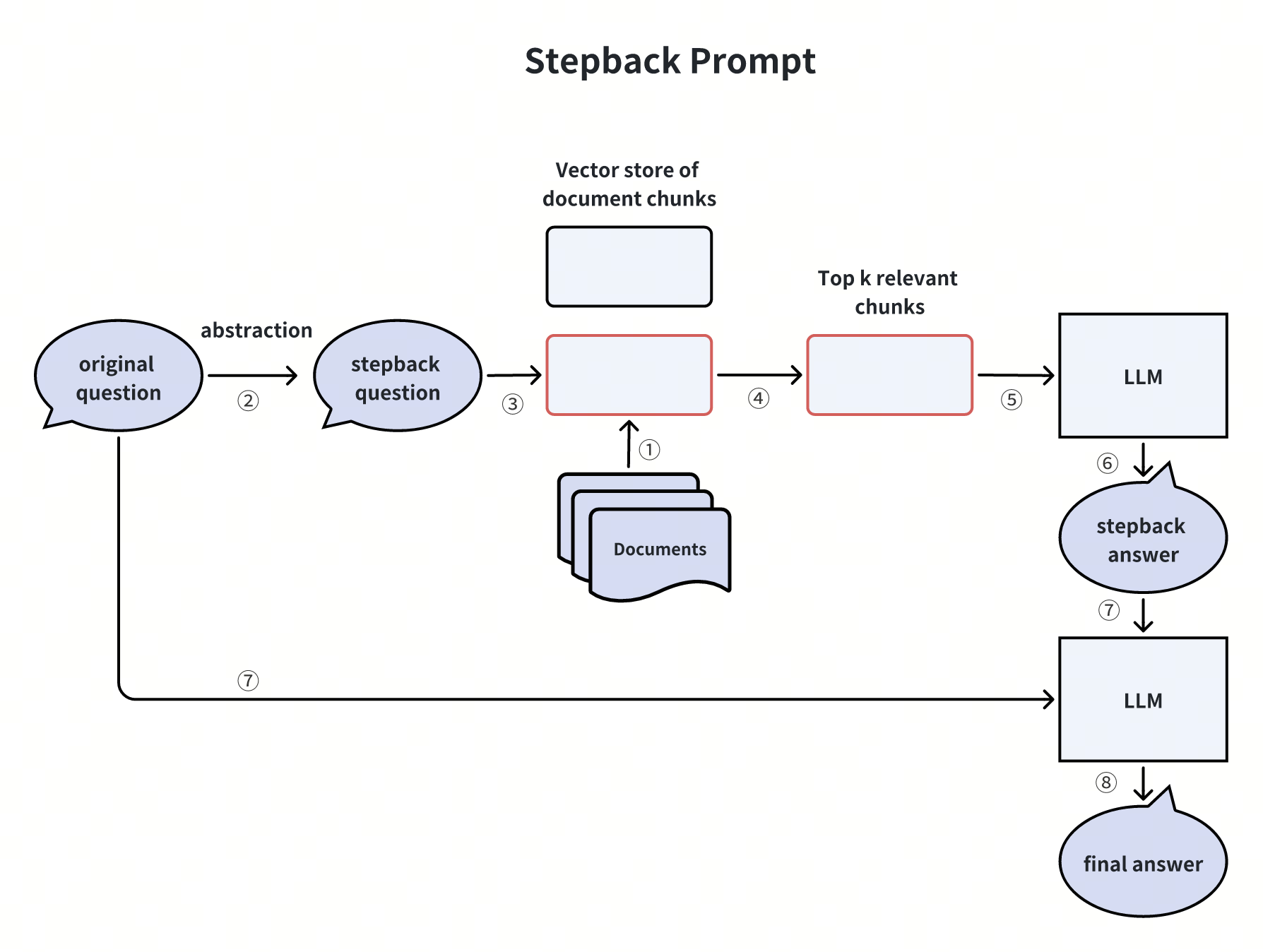
4. 回溯提示(Stepback Prompts)
将具体问题抽象为更通用的 “回溯问题”。例如,“100 亿条记录能否存入 Milvus?” 可抽象为 “Milvus 支持的数据集规模上限是多少?”
价值:通过高层问题定位核心知识,避免因细节束缚检索范围。
三、索引增强:构建更高效的检索基础
索引是检索的基石,优化索引结构可显著提升检索效率与准确性。
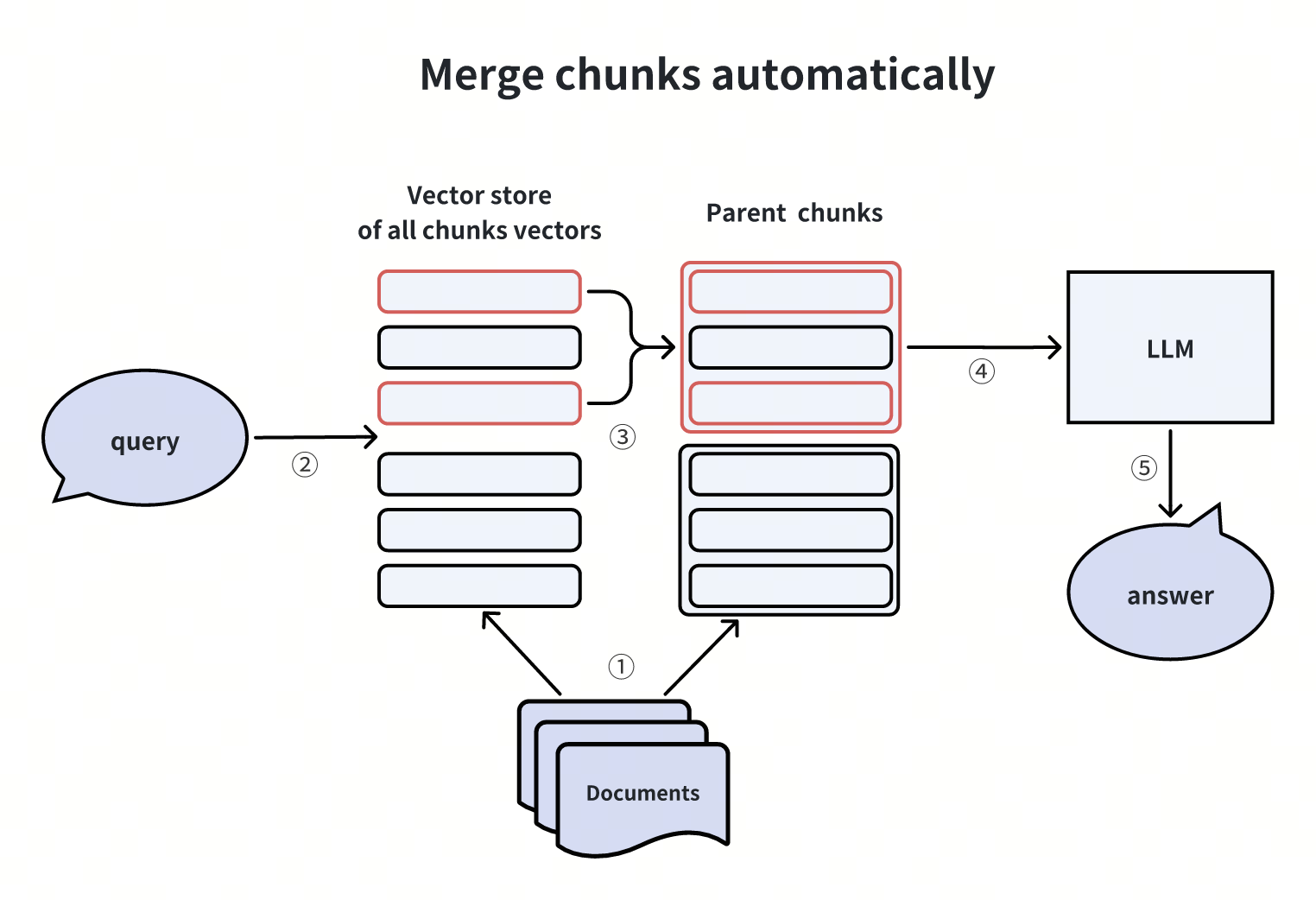
1. 自动合并文档 Chunk
采用 “子 chunk + 父 chunk” 两级粒度:先检索细粒度子 chunk,若前 k 个子 chunk 中有 n 个来自同一父 chunk,则将父 chunk 作为上下文输入 LLM。
实现参考:LlamaIndex 已集成该功能,适用于需要上下文连贯性的场景。
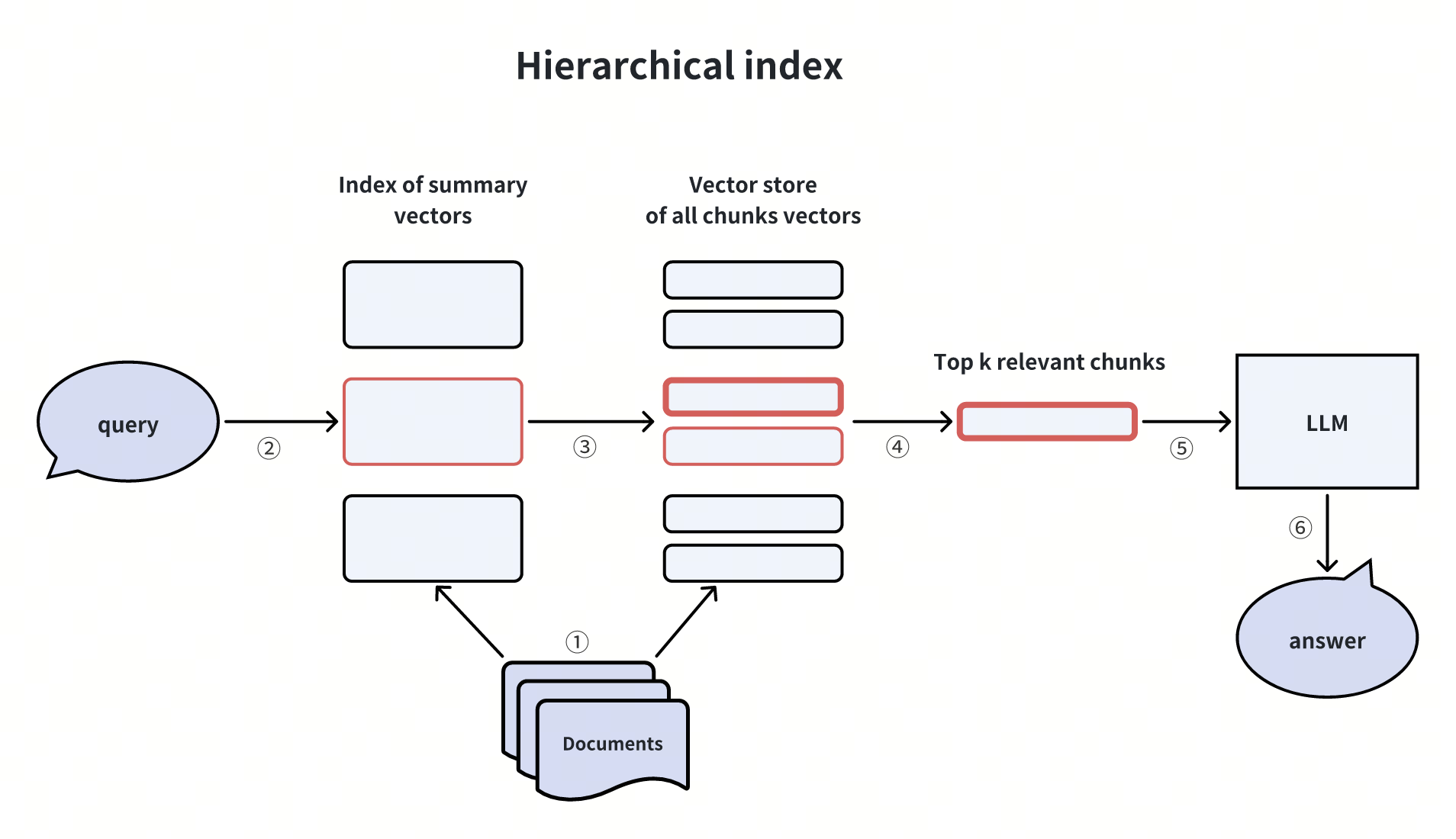
2. 分层索引(Hierarchical Indices)
构建 “文档摘要索引 + 文档 chunk 索引” 两级结构:
-
先通过摘要筛选相关文档;
-
仅在筛选出的文档内检索具体 chunk。
适用场景:海量数据或层级化内容(如图书馆馆藏)的检索。
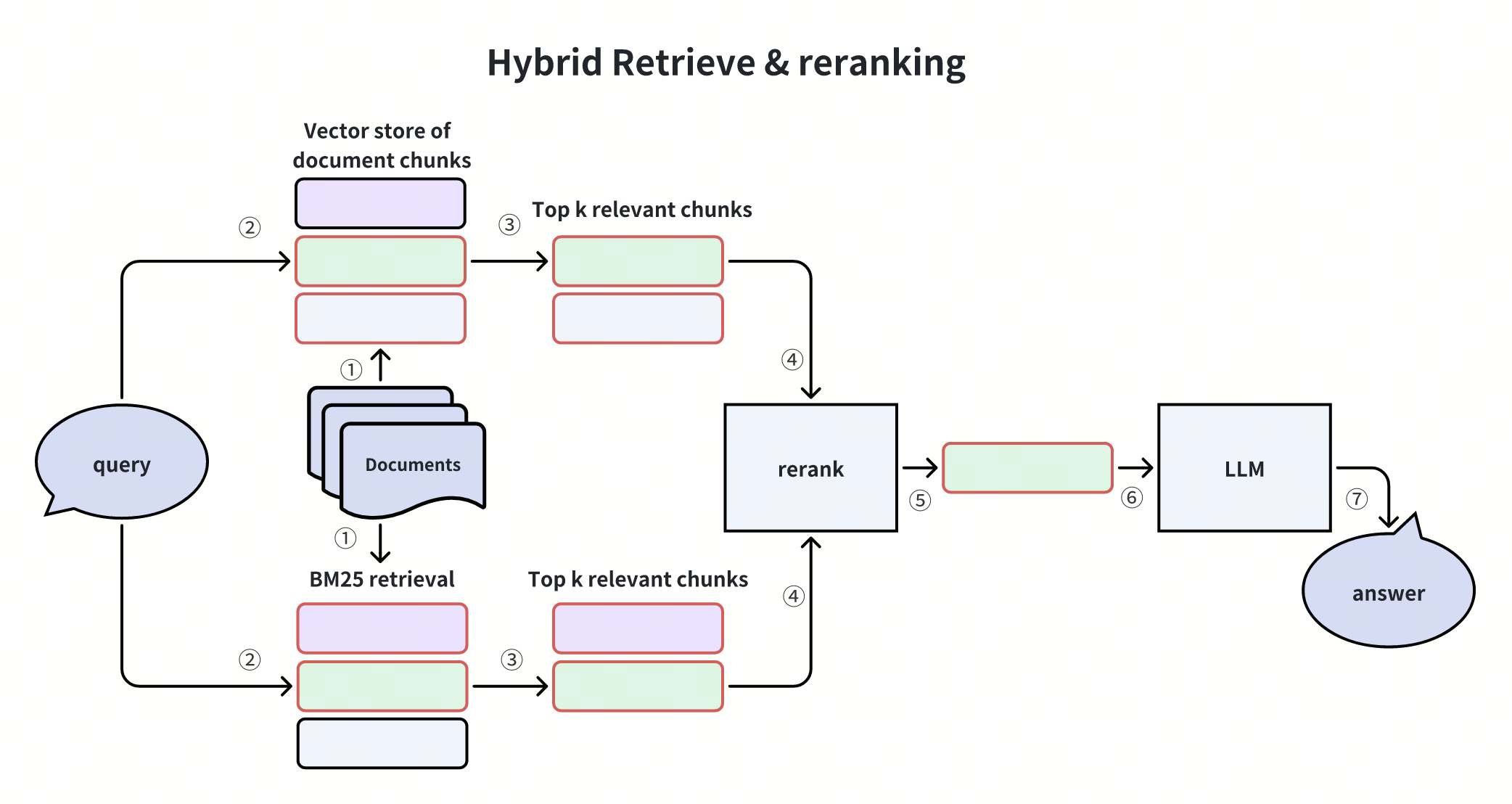
3. 混合检索与重排序(Hybrid Retrieval & Reranking)
结合向量检索(如 Milvus 的向量相似度搜索)与其他检索方法(如 BM25 词频统计、Splade 稀疏嵌入),再通过重排序模型(如 Cross-Encoder)优化结果顺序。
优势:弥补单一检索方法的盲区,提升召回率。
四、检索器增强:精准定位关键信息
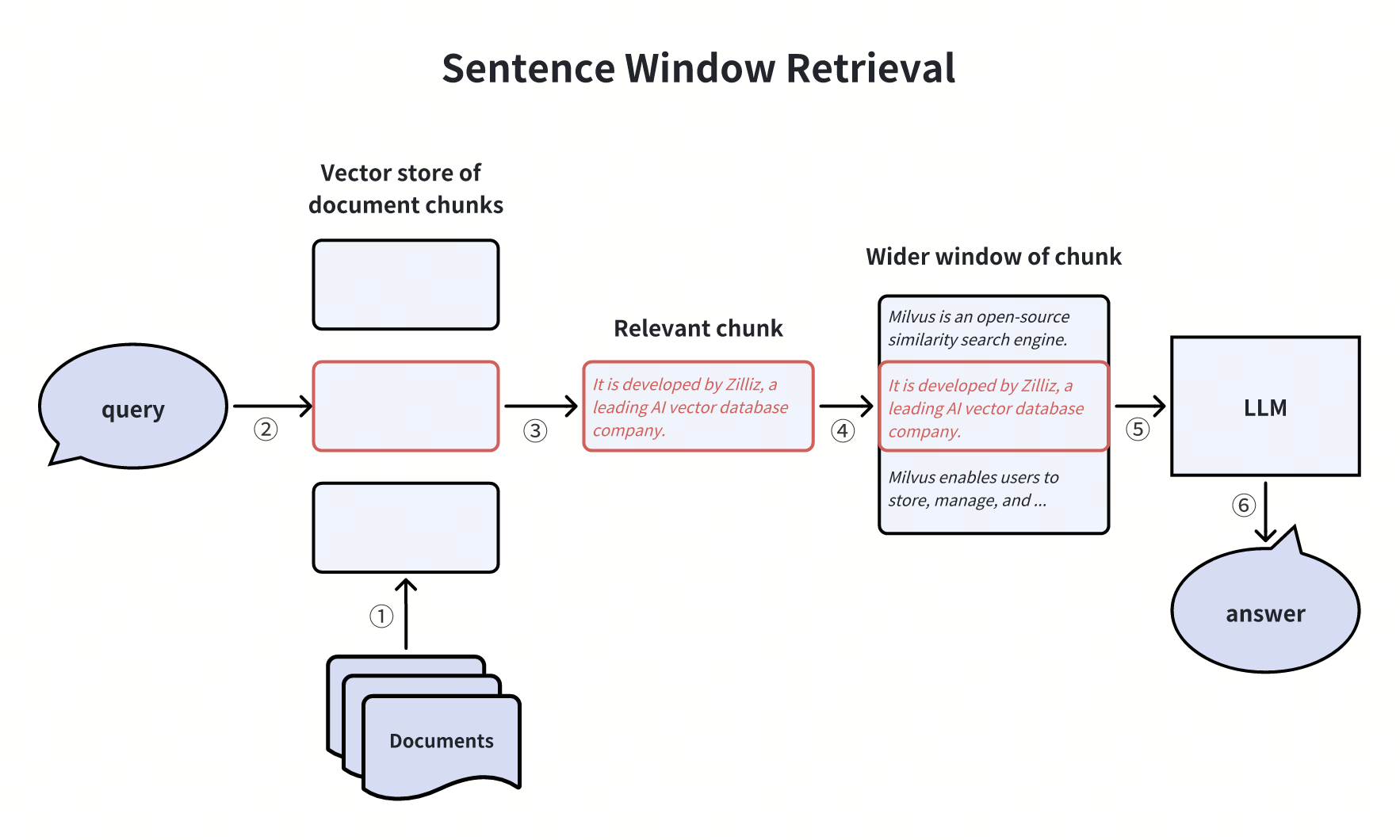
1. 句子窗口检索(Sentence Window Retrieval)
将检索到的句子 chunk 扩展为更大的上下文窗口(如包含前后段落),减少信息丢失。需注意平衡窗口大小与噪声引入的问题。
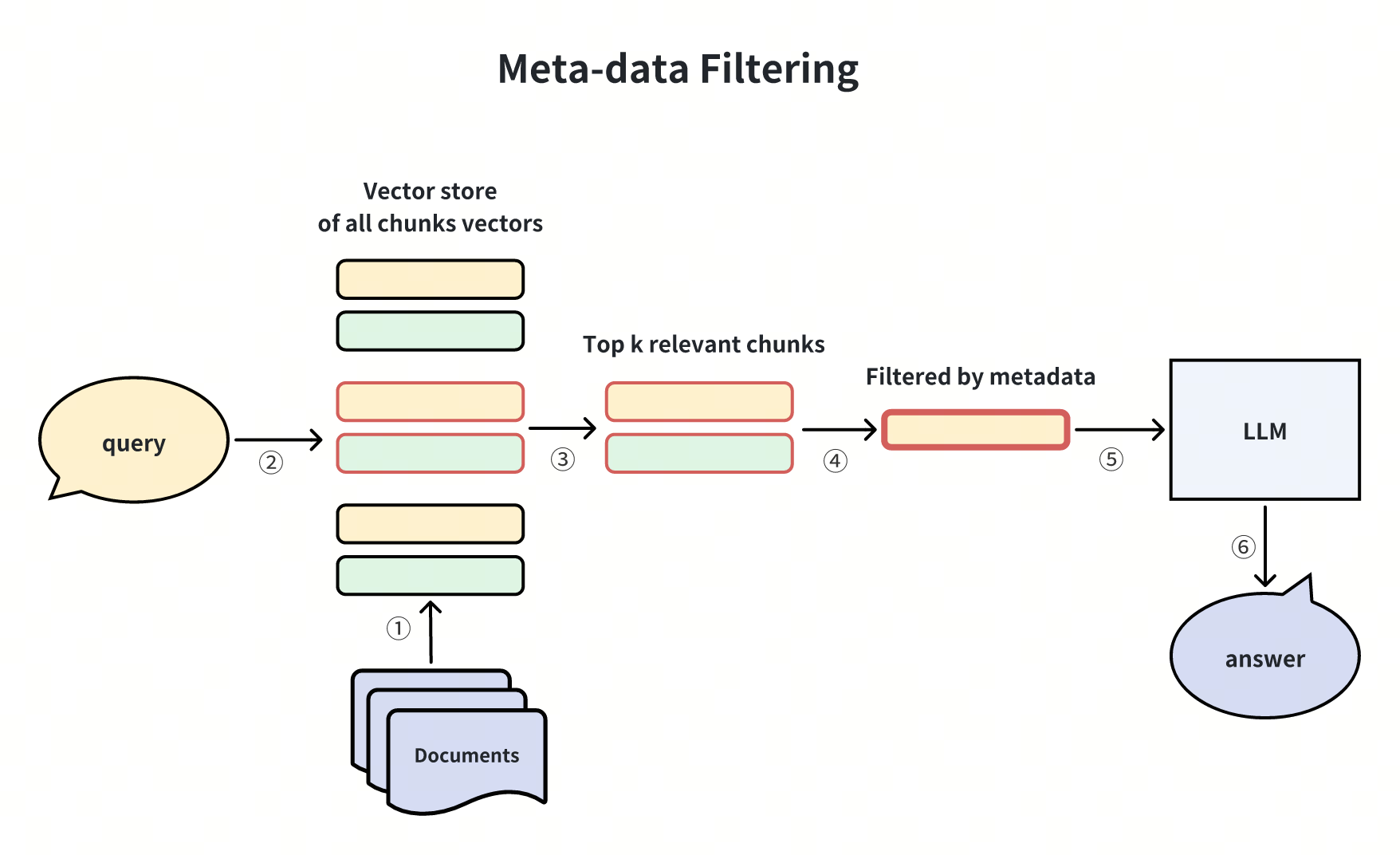
2. 元数据过滤(Meta-data Filtering)
基于时间、类别等元数据筛选检索结果。例如,在金融报告检索中,通过 “年份 = 2024” 过滤过时信息,提升相关性。
五、生成器增强:让答案更可靠
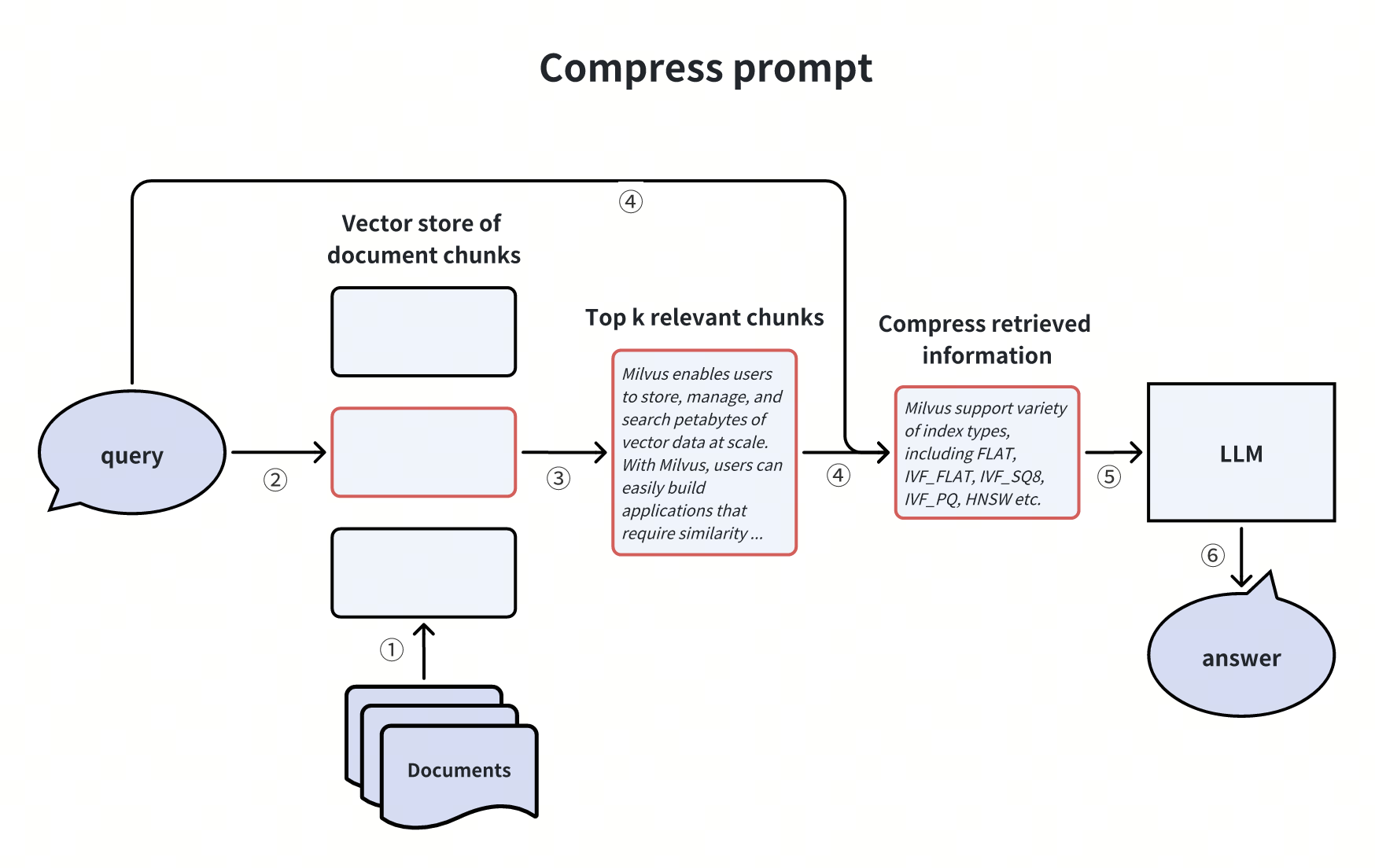
1. 压缩 LLM 提示(Compressing Prompts)
剔除检索到的 chunk 中的冗余信息,聚焦核心内容,缓解 LLM 上下文窗口限制。例如,提炼 “Milvus 支持的索引类型” 相关 chunk 时,仅保留关键技术参数。
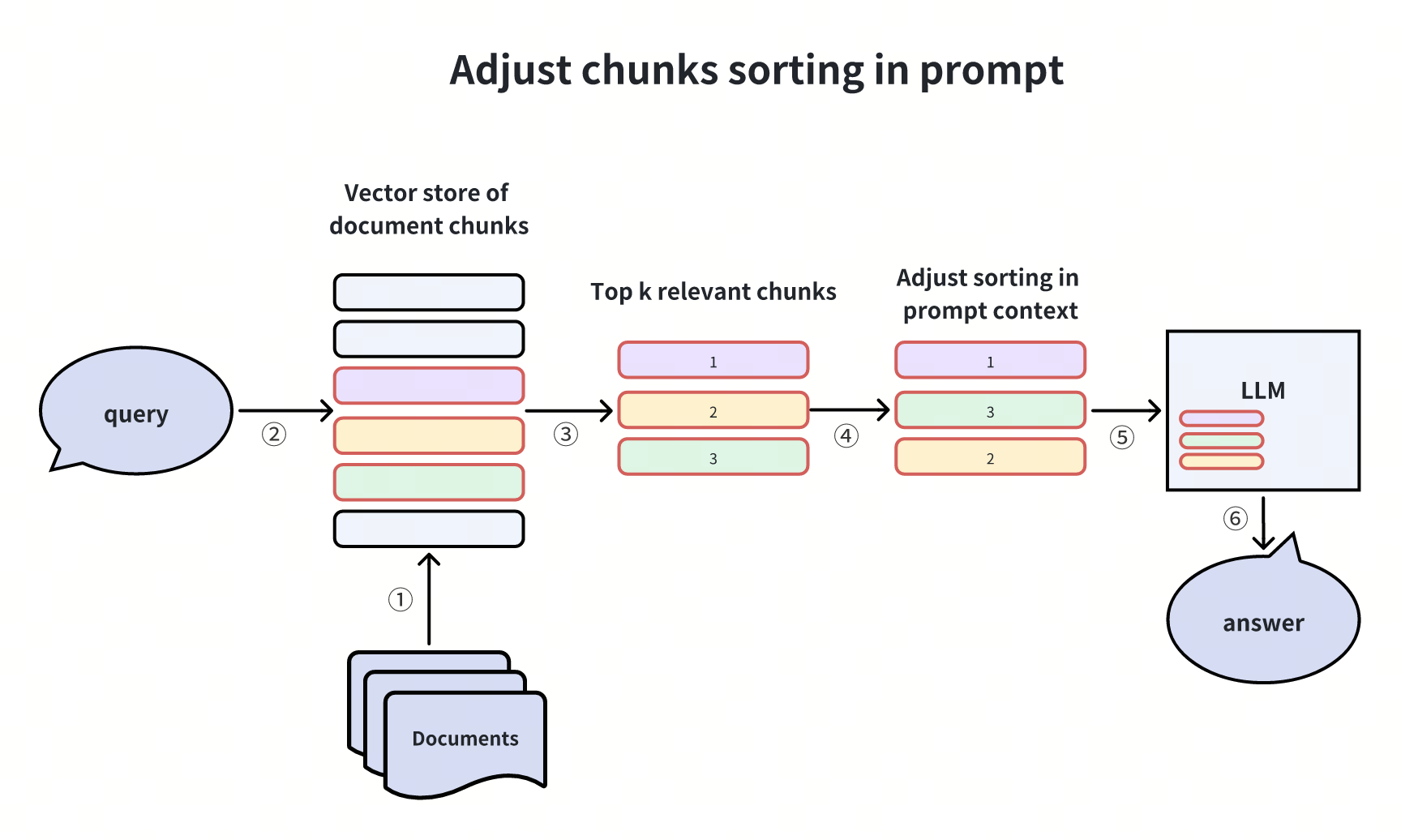
2. 调整 Prompt 中 Chunk 顺序
研究表明,LLM 倾向于关注首尾位置的信息(“Lost in the middle” 现象)。因此,可将高置信度 chunk 置于首尾,低置信度 chunk 放在中间。
六、全流水线增强:动态优化端到端流程
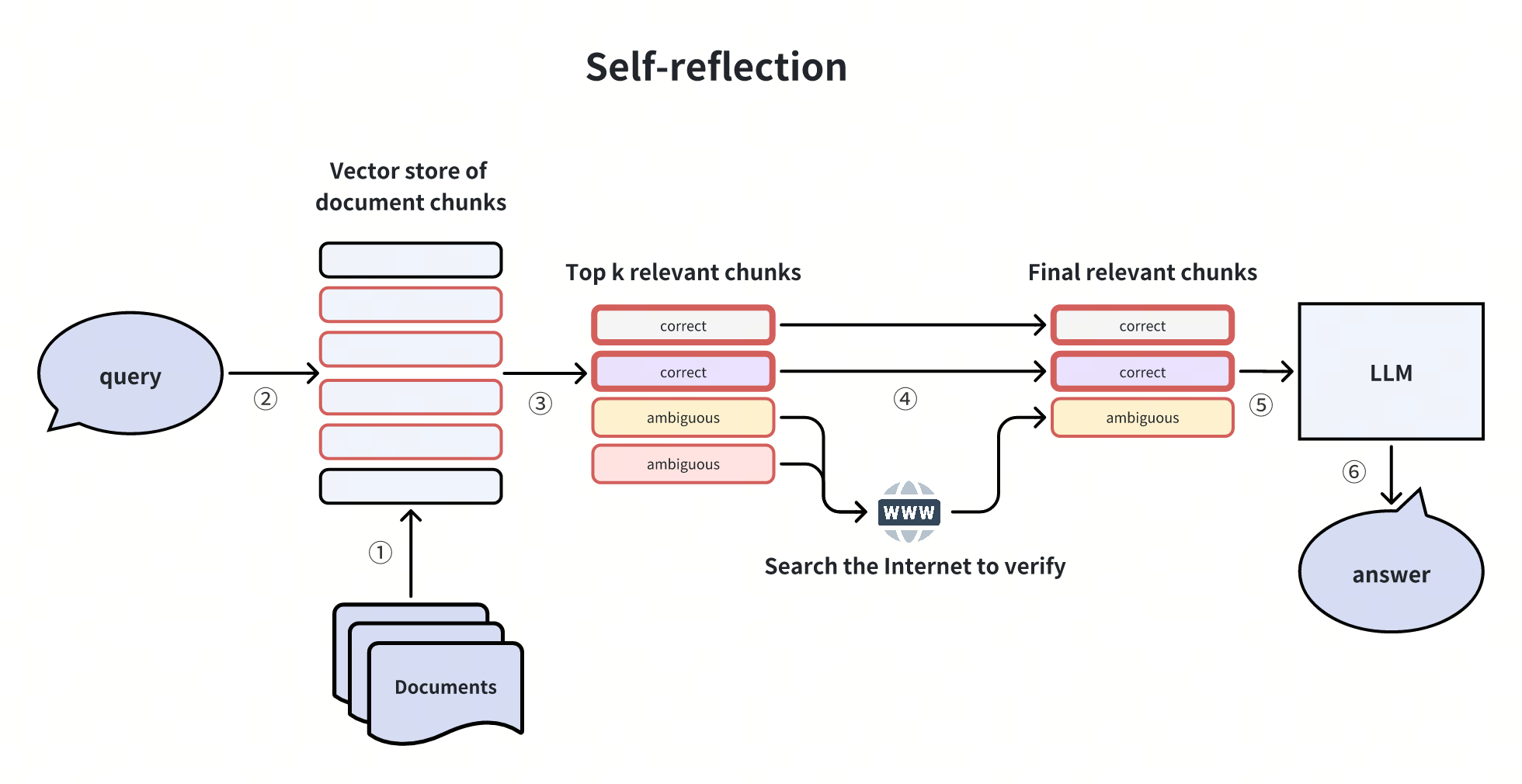
1. 自反思(Self-reflection)
对初检结果进行二次验证,通过 NLI 模型或工具(如互联网搜索)判断 chunk 是否能回答问题,过滤无效信息。参考项目:Self-RAG、Corrective RAG。
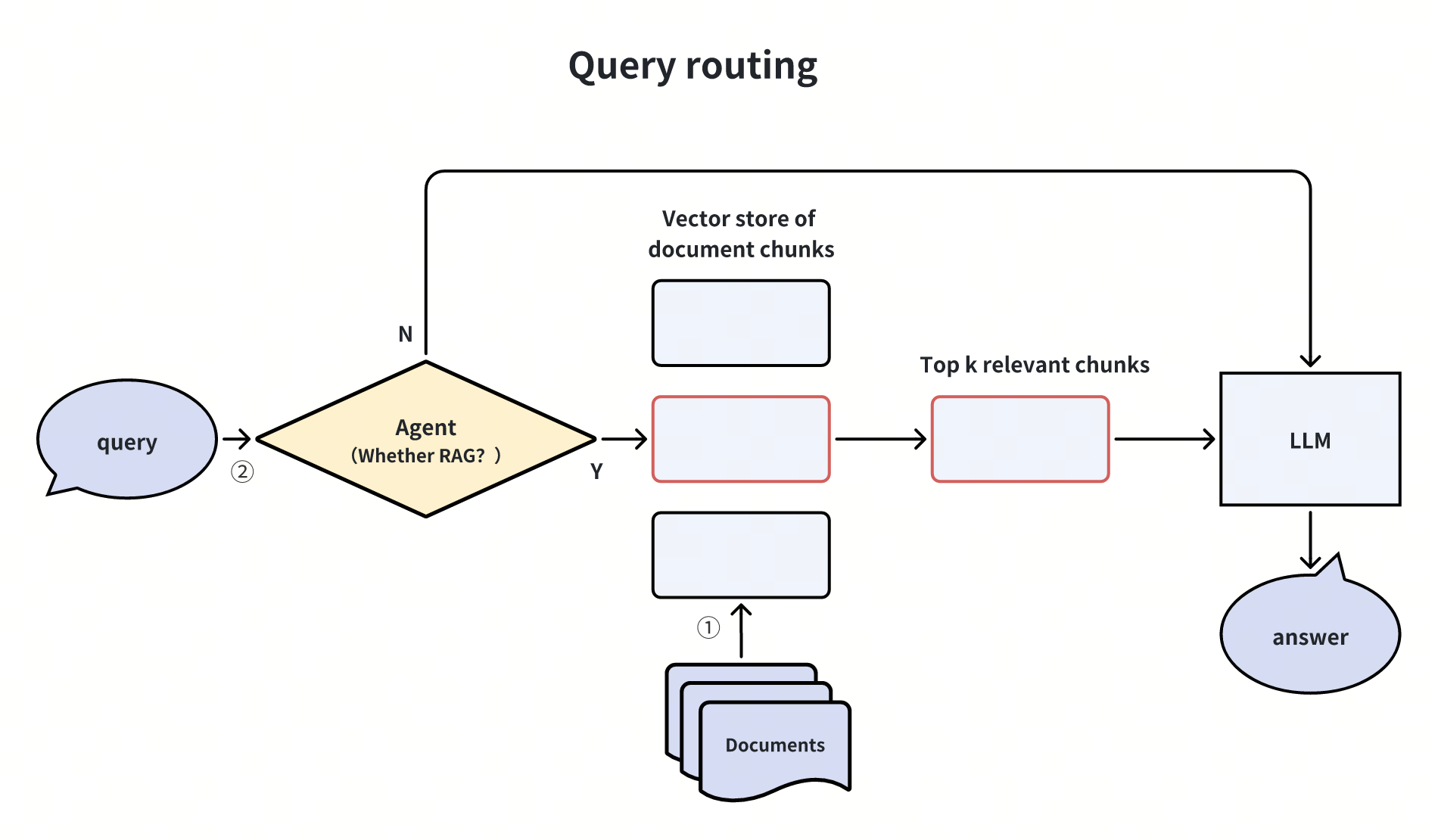
2. 基于 Agent 的查询路由
通过 Agent 判定查询是否需要调用 RAG:
-
简单问题(如 “2+2 等于几”)直接由 LLM 回答;
-
复杂问题(如 “Milvus 与 Elasticsearch 的性能对比”)触发 RAG 流程。
延伸:扩展路由逻辑至工具调用(如网页搜索、子查询生成),实现动态流程调度。
七、总结与实践建议
RAG 性能优化需结合业务场景选择合适技术:
-
复杂查询优先尝试子查询或回溯提示;
-
海量数据场景推荐分层索引与混合检索;
-
对响应速度敏感的应用可引入查询路由减少冗余计算。