「源力觉醒 创作者计划」深度讲解大模型之在百花齐放的大模型时代看百度文心大模型4.5的能力与未来
目录
前言
一、文心大模型4.5简介
1、gitcode文心大模型专题
2、ERNIE-4.5-VL-424B-A47B技术亮点
3、ERNIE-4.5-VL-424B-A47B的开源展示
4、文心大模型生态
二、文心大模型4.5的性能测试
1、文心4.5预训练模型
2、ERNIE-4.5-300B-A47B 后训练模型
3、ERNIE-4.5-21B-A3B 后训练模型
4、多模态后训练模型(支持思考)
5、多模态后训练模型(关闭思考)
三、多平台部署实战及应用
1、PP飞浆平台的快速部署及使用
2、百度智能云千帆大模型集成
四、总结
前言
一起来轻松玩转文心大模型吧!文心大模型免费下载地址:https://ai.gitcode.com/theme/1939325484087291906
在人工智能飞速发展的时代,大模型技术犹如一颗璀璨的明珠,吸引了科技界、学术界和产业界的广泛关注。作为一名IT从业者,了解大模型,熟悉大模型已经不是可选项,而是必选项。众多企业和研究机构纷纷投身于大模型的研发与应用,使得这一领域呈现出百花齐放的景象。百度文心大模型 4.5 在此背景下脱颖而出,凭借其卓越的技术性能和广泛的应用潜力,成为大模型时代的重要代表之一。百度文心大模型 4.5 是百度发布的新一代多模态基础大模型,是百度人工智能核心产品体系的重要升级版本。该模型通过 FlashMask 动态注意力掩码、多模态异构专家扩展等技术,在多模态理解、文本生成和逻辑推理等方面取得了显著提升。其在多项基准测试中表现优异,尤其在指令遵循、世界知识记忆、视觉理解和多模态推理任务上效果突出。文心大模型 4.5 不仅在技术上实现了突破,还通过开源的方式,为开发者提供了灵活的使用选择,推动了整个 AI 生态系统的建设。
文心大模型 4.5 的多模态理解能力是其一大亮点。作为百度首个原生多模态大模型,它能够对文字、图片、音频、视频等多种形式的数据进行综合理解。这种多模态融合的能力极大地拓展了人工智能在实际应用中的可能性,使其能够在智能客服、教育、医疗等多个领域实现更加自然和流畅的人机交互。例如,在智能客服场景中,文心大模型 4.5 可以同时理解用户的文字描述和相关图片信息,从而更准确地判断问题并提供解决方案。
在文本处理方面,文心大模型 4.5 同样展现出了强大的能力。它具备优秀的语言理解、生成、逻辑推理和记忆能力,能够生成高质量的文本内容。无论是撰写营销文案、报告摘要,还是进行文学创作,文心大模型 4.5 都能够满足用户的需求。此外,其去幻觉能力的显著提升,也使得生成的文本内容更加准确和可靠。文心大模型 4.5 的开源,更是为开发者和企业带来了巨大的价值。百度于 2025 年 6 月 30 日正式开源了文心大模型 4.5 系列模型,涵盖多种参数配置。开源的预训练权重和推理代码,使得开发者能够根据自身需求进行灵活的定制和优化。同时,其 API 调用价格仅为同类产品 GPT-4.5 的 1%,极大地降低了使用成本。这种低成本、高效能的服务模式,使得更多的企业和开发者能够将文心大模型 4.5 应用于实际项目中,推动了 AI 技术的广泛应用和创新。
2025年4月9日,在南京召开的中国人工智能产业发展联盟第十四次全体会议上,中国人工智能产业发展联盟正式发布“方升”大模型基准测试结果(2025年1季度)。在权威发布环节,AIIA 总体组组长、中国信通院人工智能研究所所长魏凯发布了“方升”人工智能基准测试结果及测试观察。在大语言模型测试结果中,文心大模型4.5在基础能力结果、文心大模型X1在推理能力结果中均名列前茅。
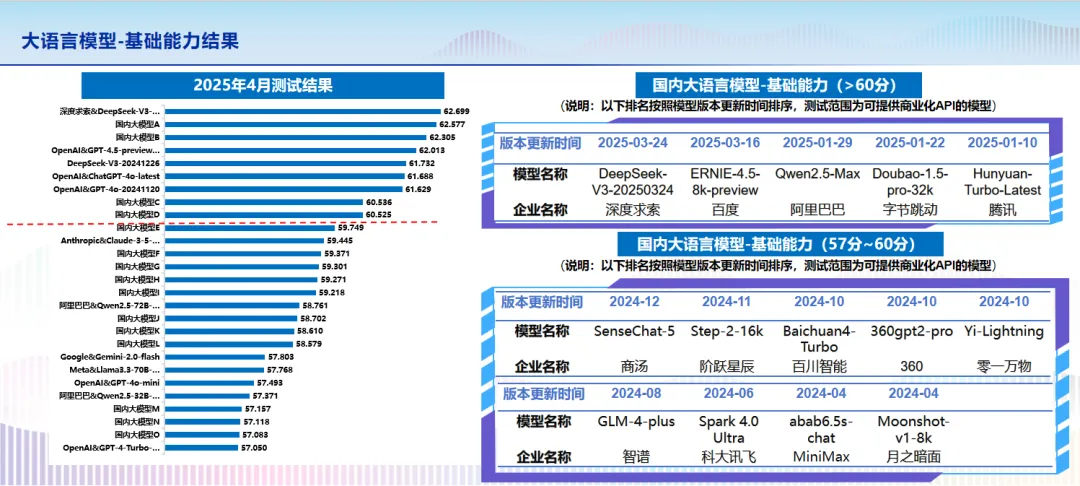
大语言模型-基础能力测试结果
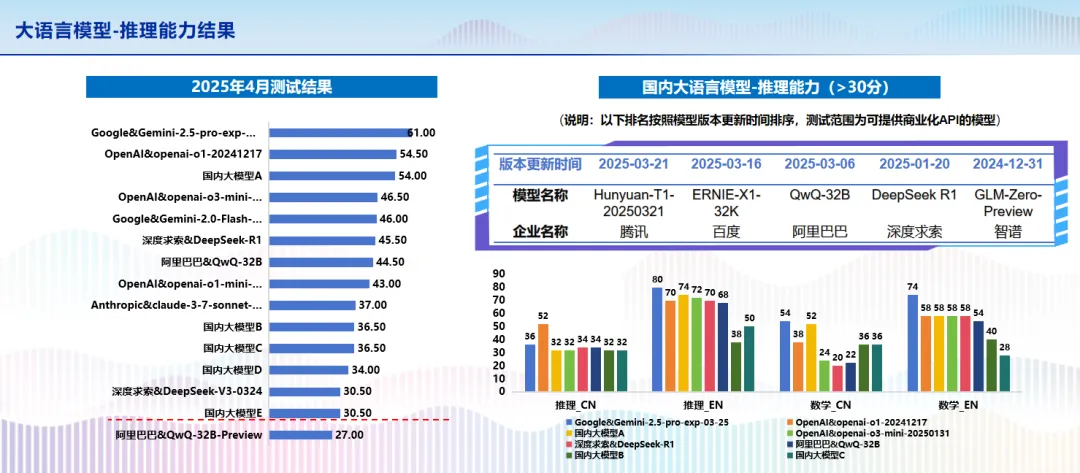
大语言模型-推理能力测试结果
展望未来,文心大模型 4.5 的发展充满无限可能。一方面,随着技术的不断进步,模型的专业化趋势将愈发明显。针对不同垂直领域的专用版本有望陆续推出,进一步提升模型在特定领域的应用效果。另一方面,推理效率的持续提升也将是未来的重要发展方向。新的压缩和加速技术的不断涌现,将使得文心大模型 4.5 在保持高性能的同时,进一步降低计算资源的消耗。此外,多模态能力的进一步增强,将使文心大模型 4.5 在文本、图像、音频的联合理解上达到更高的水平,为人工智能的未来发展奠定坚实基础。在百花齐放的大模型时代,百度文心大模型 4.5 以其卓越的技术性能、广泛的应用场景和开源的开放态度,成为了推动人工智能发展的重要力量。它不仅为开发者和企业提供了强大的技术支持,也为整个 AI 生态系统的繁荣做出了重要贡献。随着技术的不断进步和应用场景的不断拓展,文心大模型 4.5 必将在未来的人工智能发展中发挥更加重要的作用,引领我们走向更加智能化的未来。
本文将对百度的文心大模型进行详细的介绍,通过它的开源社区和集成平台来进行学习和模拟。通过模型的集成部署,让大家不仅详细的了解大模型的相关技术,同时可以掌握大模型的部署、训练和使用全过程讲解。
一、文心大模型4.5简介
本节将详细介绍百度的文心大模型4.5在哪里可以找到。既然是开源,首先要解决的就是让大家很方便的找到仓库地址,同时方便大家下载相应的源码。这里将从以下几个方面进行介绍,首先介绍在GitCode中的文心大模型专题,然后介绍开源的大模型的技术亮点、开源介绍以及文心大模型的生态等。
1、gitcode文心大模型专题
本次发布的文心大模型4.5的开源地址直接发布在gitcode上。在其官网上直接创建了文心大模型的专题,gitcode文心大模型专题。大家在浏览器中输入连接地址后可以看到以下内容。
大家进入到上面的界面后,可以看到很多的开源模型,可以根据自己的实际情况来查看具体的模型信息。以第一个文本生成的模型为例,在7月09号的时候进行更新的,截止目前的下载量差不多是7322左右,看来大家比较喜欢部署的是这个模型,因此下面我们来看看这个模型的一些基本信息。
2、ERNIE-4.5-VL-424B-A47B技术亮点
ERNIE-4.5-VL-424B-A47B 是百度推出的多模态MoE大模型,支持文本与视觉理解,总参数量424B,激活参数量47B。基于异构混合专家架构,融合跨模态预训练与高效推理优化,具备强大的图文生成、推理和问答能力。适用于复杂多模态任务场景。 ERNIE 4.5 模型的先进能力,特别是基于 MoE 的 A47B 和 A3B 系列,得到了几项关键技术创新的支撑:
-
多模态异构 MoE 预训练: 我们模型在文本和视觉模态上共同训练,以更好地捕捉多模态信息的细微差别,并提高在文本理解与生成、图像理解以及跨模态推理任务上的性能。为了实现这一目标,不让一种模态阻碍另一种模态的学习,我们设计了 异构 MoE 结构,引入了 模态隔离路由,并采用了 路由正交损失 和 多模态标记平衡损失。这些架构选择确保了两种模态的有效表示,在训练过程中实现相互增强。
-
扩展效率化的基础设施: 我们为 ERNIE 4.5 模型的有效训练提出了一种新颖的异构混合并行性和分层负载平衡策略。通过使用节点内专家并行性、内存效率化的管道调度、FP8 混合精度训练和细粒度重计算方法,我们实现了显著的预训练吞吐量。对于推理,我们提出了 多专家并行协作 方法和 卷积码量化 算法,实现了 4 位/2 位无损量化。此外,我们引入了 PD 解耦与动态角色切换,以有效利用资源,增强 ERNIE 4.5 MoE 模型的推理性能。基于 PaddlePaddle,ERNIE 4.5 在广泛的硬件平台上提供了高性能的推理。
-
模态特定后训练: 为了满足实际应用的多样化需求,我们对预训练模型的不同模态变体进行了微调。我们的 LLMs 优化用于通用目的的语言理解与生成。VLMs 专注于视觉语言理解,并支持思考和和非思考模式。每个模型都采用了 监督微调(SFT)、直接偏好优化(DPO) 或名为 统一偏好优化(UPO) 的改进型强化学习方法进行后训练。
在视觉语言模型微调阶段,视觉与语言的深度整合对于模型在理解、推理和生成等复杂任务中的性能起着决定性作用。为了提高模型在多模态任务上的泛化能力和适应性,我们专注于三个核心能力—图像理解、特定任务微调和多模态思维链推理,并进行系统的数据构建和训练策略优化。此外,我们使用 RLVR(带有可验证奖励的强化学习)进一步改进对齐和性能。经过 SFT 和 RL 阶段后,我们得到了 ERNIE-4.5-VL-424B-A47B。
3、ERNIE-4.5-VL-424B-A47B的开源展示
在对ERNIE-4.5-VL-424B-A47B模型有了简单的介绍后,我们在开源地址可以看到以下的信息,其中包含已经训练好的模型文件,单个模型文件大约是在4GB左右。
ERNIE-4.5-VL-424B-A47B 是基于 ERNIE-4.5-VL-424B-A47B-Base 的 424B 总参数、每 token 激活 47B 参数的多模态 MoE 聊天模型。下面来看看一下模型的配置细节:
| 关键字 | 值 |
|---|---|
| 模态 | 文本 & 视觉 |
| 训练阶段 | 微调 |
| 参数(总/激活) | 424B / 47B |
| 层数 | 54 |
| 头数(Q/KV) | 64 / 8 |
| 文本专家(总/激活) | 64 / 8 |
| 视觉专家(总/激活) | 64 / 8 |
| 上下文长度 | 131072 |
4、文心大模型生态
首先分享一个文心大模型的生态圈系统图,从两个方面来进行说明。第一个是模型的介绍,第二个是基于基础模型的平台工具,通过不断繁荣的生态来连接更多的应用和场景,同时为更多行业进行赋能。
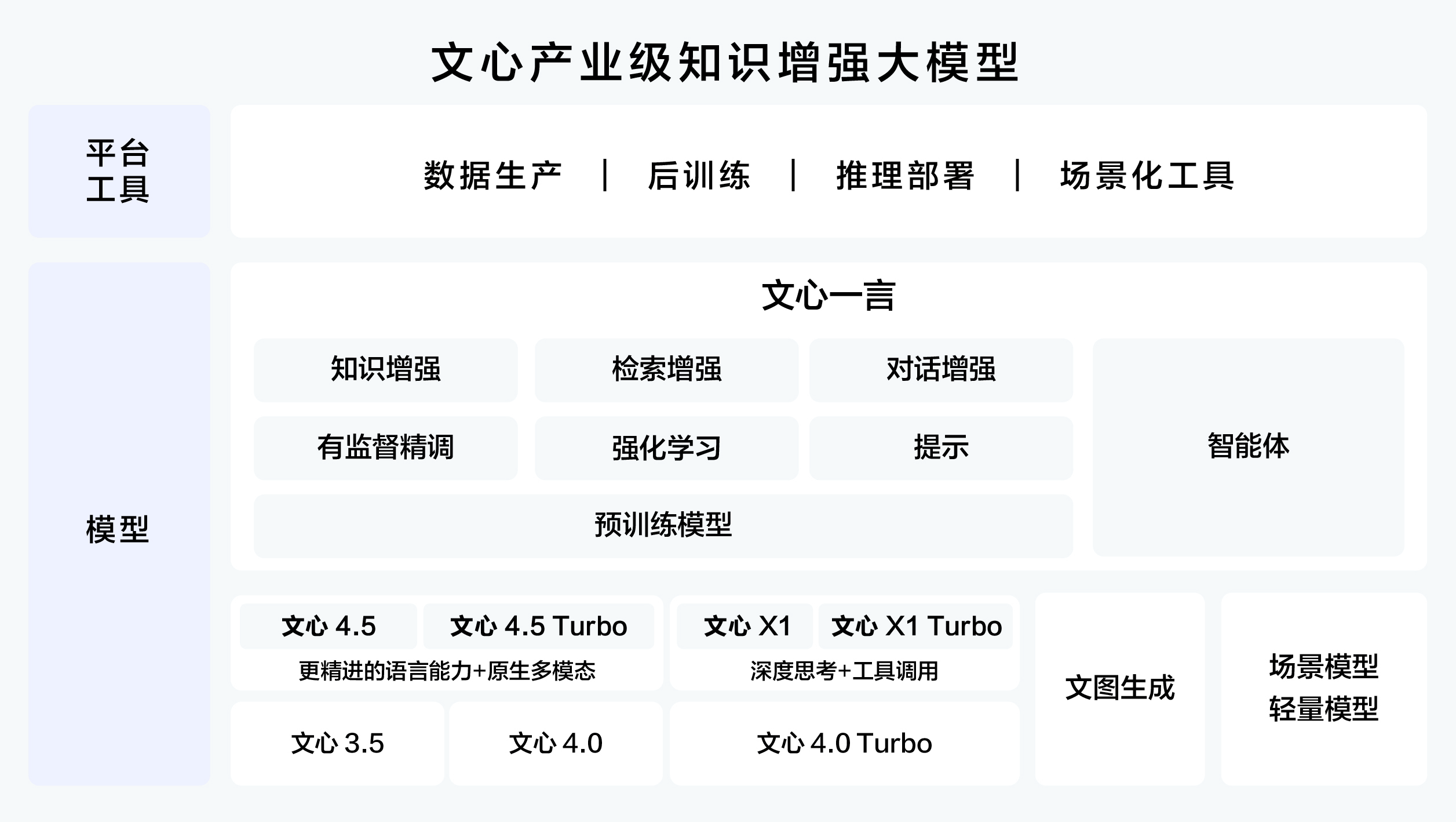
在上图中,比较详细的说明了文心不同版本的大模型之间的知识,通过组件类的支持让大家对此有了比较直观的认识。
二、文心大模型4.5的性能测试
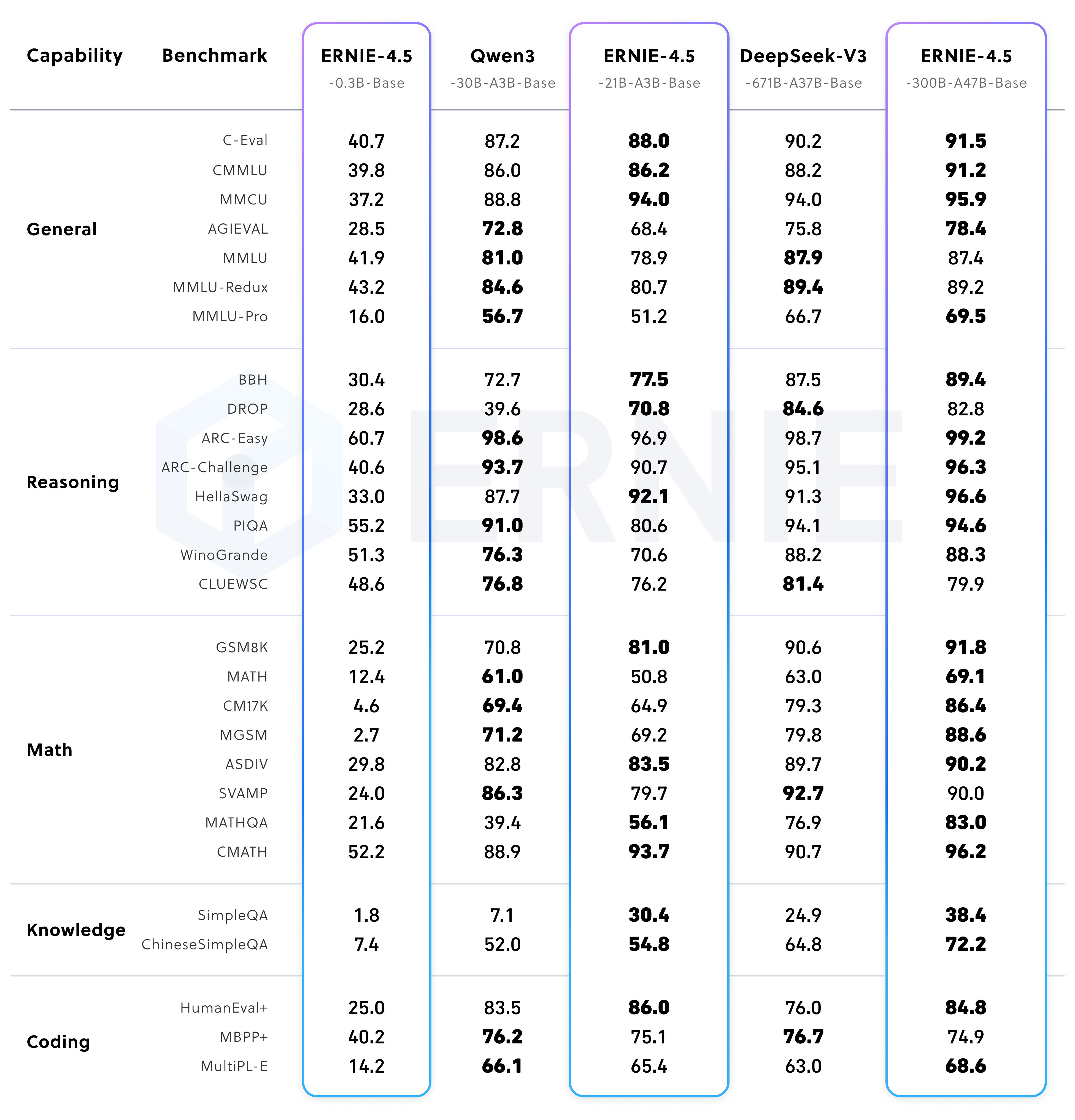
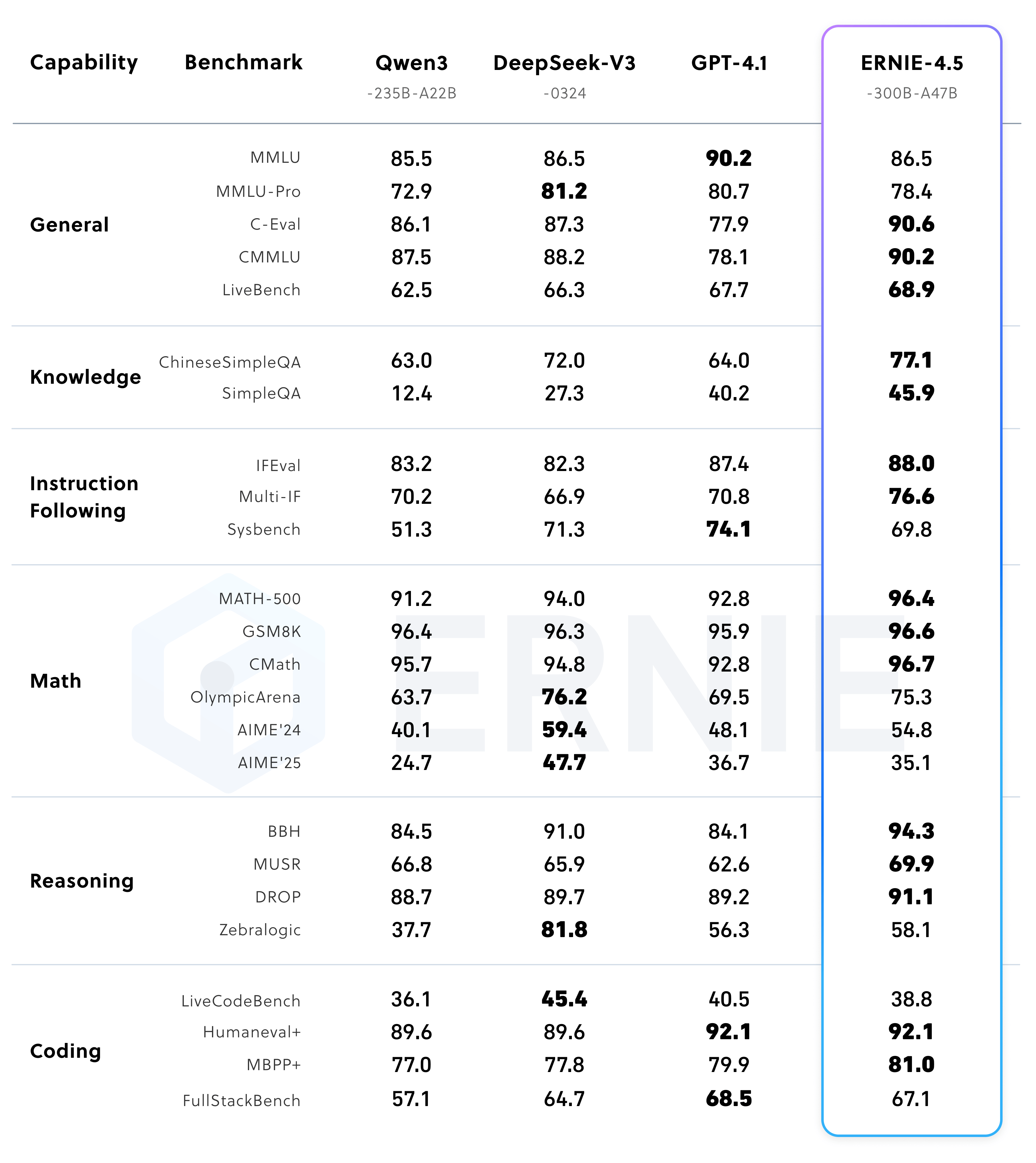
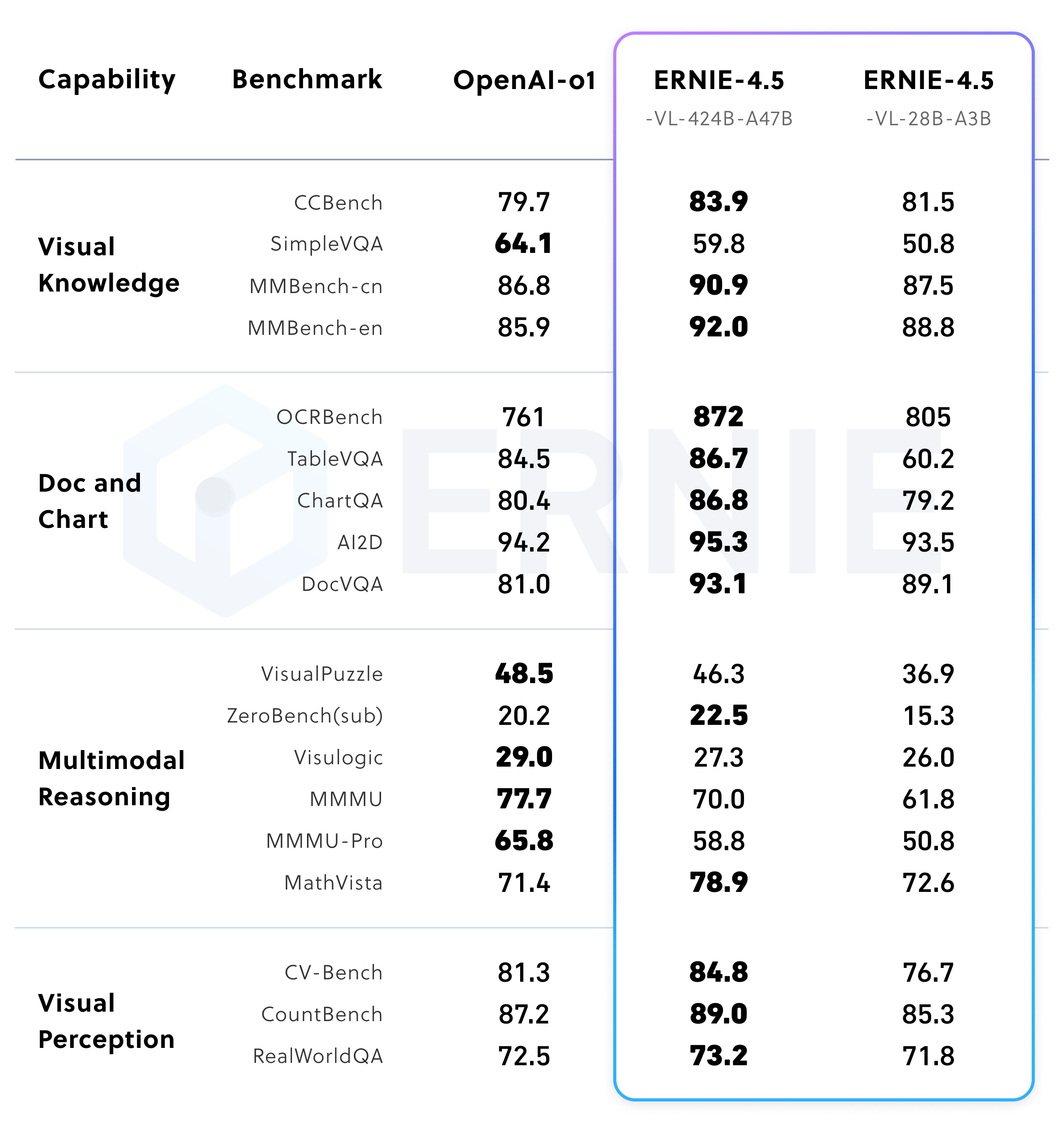
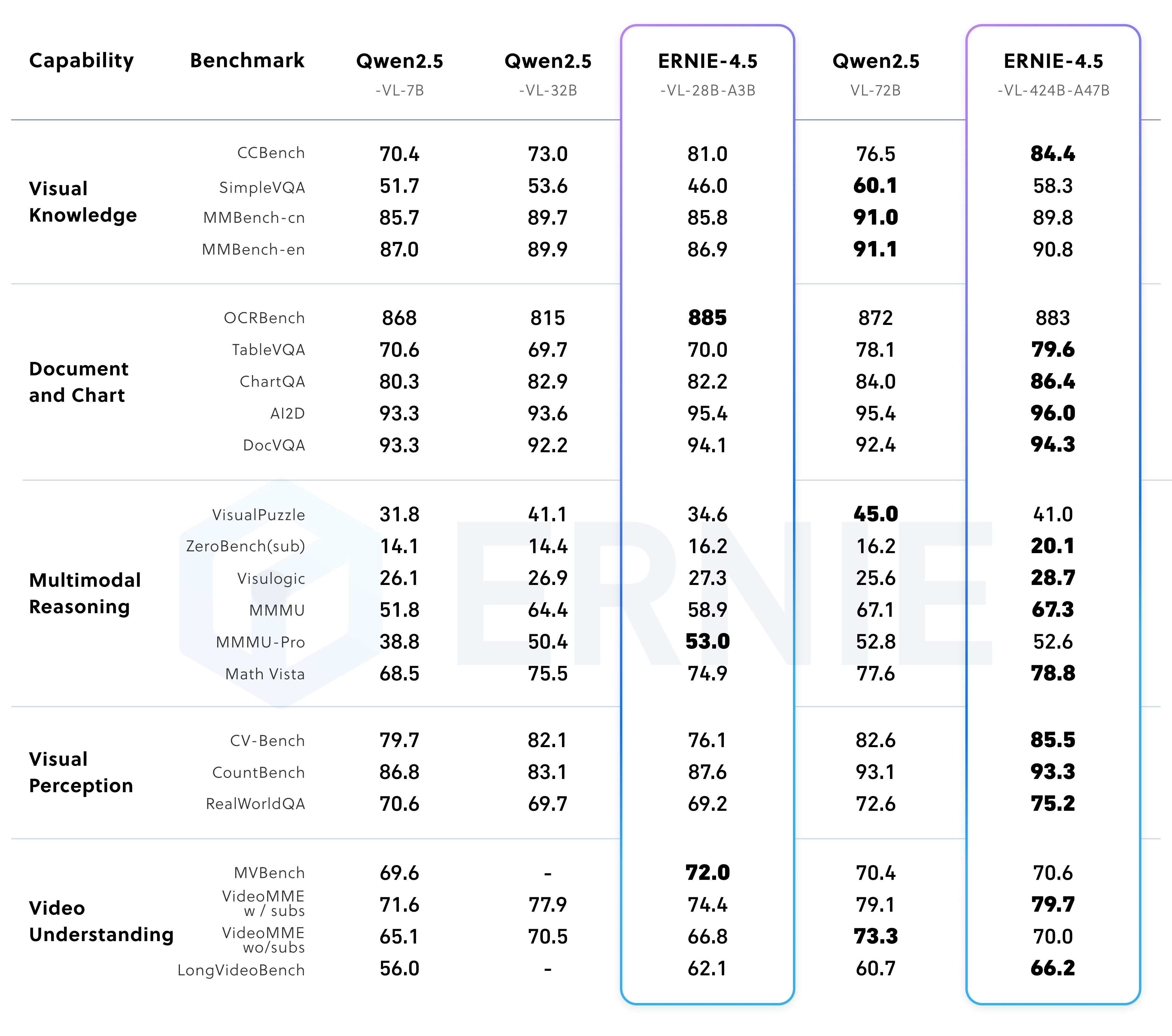
本节将重点介绍文心大模型4.5的性能测试,通过性能测试来展示不同的大模型的实际能力。分别从文心4.5预训练模型、ERNIE-4.5-300B-A47B 后训练模型、ERNIE-4.5-21B-A3B 后训练模型、多模态后训练模型(支持思考)、多模态后训练模型(关闭思考)等来进行详细介绍ERNIE-4.5-300B-A47B-Base 在 28 个基准测试中的 22 个超越了 DeepSeek-V3-671B-A37B-Base,在所有主要能力类别中均有领先的表现。相对于其他SOTA模型,在泛化能力、推理和知识密集型任务方面的显著提升。ERNIE-4.5-21B-A3B-Base 总参数量为 210 亿(约为 Qwen3-30B 的 70%),在包括 BBH 和 CMATH 在内的多个数学和推理基准上效果优于 Qwen3-30B-A3B-Base。尽管ERNIE-4.5-21B-A3B-Base 更小,但模型效果突出,实现了效果和效率的平衡。经过后训练的 ERNIE-4.5-300B-A47B 模型,在指令遵循和知识类任务方面表现出显著优势,其在 IFEval、Multi-IF、SimpleQA 和 ChineseSimpleQA 等基准测试中取得了业界领先的效果。轻量级模型 ERNIE-4.5-21B-A3B 尽管总参数量减少了约 30%,但与 Qwen3-30B-A3B 相比,仍取得了具有竞争力的性能。在非思考模式下,ERNIE-4.5-VL 在视觉感知、文档与图表理解以及视觉知识方面效果突出,在一系列基准测试中表现优异。在思考模式下,ERNIE-4.5-VL 不仅展现出比非思考模式更强的推理能力,还保留了非思考模式的强大感知能力。ERNIE-4.5-VL-424B-A47B 在所有多模态评估基准中均取得了突出效果。其思考模式在以推理为中心的任务上表现出了明显的优势,在 MathVista、MMMU 和 VisualPuzzle 等高难度基准上实现了与 OpenAI-o1的差距缩小,甚至性能超越,并在以感知为主的数据集(如 CV-Bench 和 RealWorldQA)上保持了不错的效果。尽管使用显著少的激活参数,轻量级视觉语言模型 ERNIE-4.5-VL-28B-A3B 在大多数基准测试中,相较于 Qwen2.5-VL-7B 和 Qwen2.5-VL-32B,效果相当甚至更优。此外,文心4.5轻量级模型也同时支持思考和非思考两种模式,提供了与 ERNIE-4.5-VL-424B-A47B 一致的功能。相应的测试结果以测试表格的形式给出。
1、文心4.5预训练模型
2、ERNIE-4.5-300B-A47B 后训练模型
3、ERNIE-4.5-21B-A3B 后训练模型
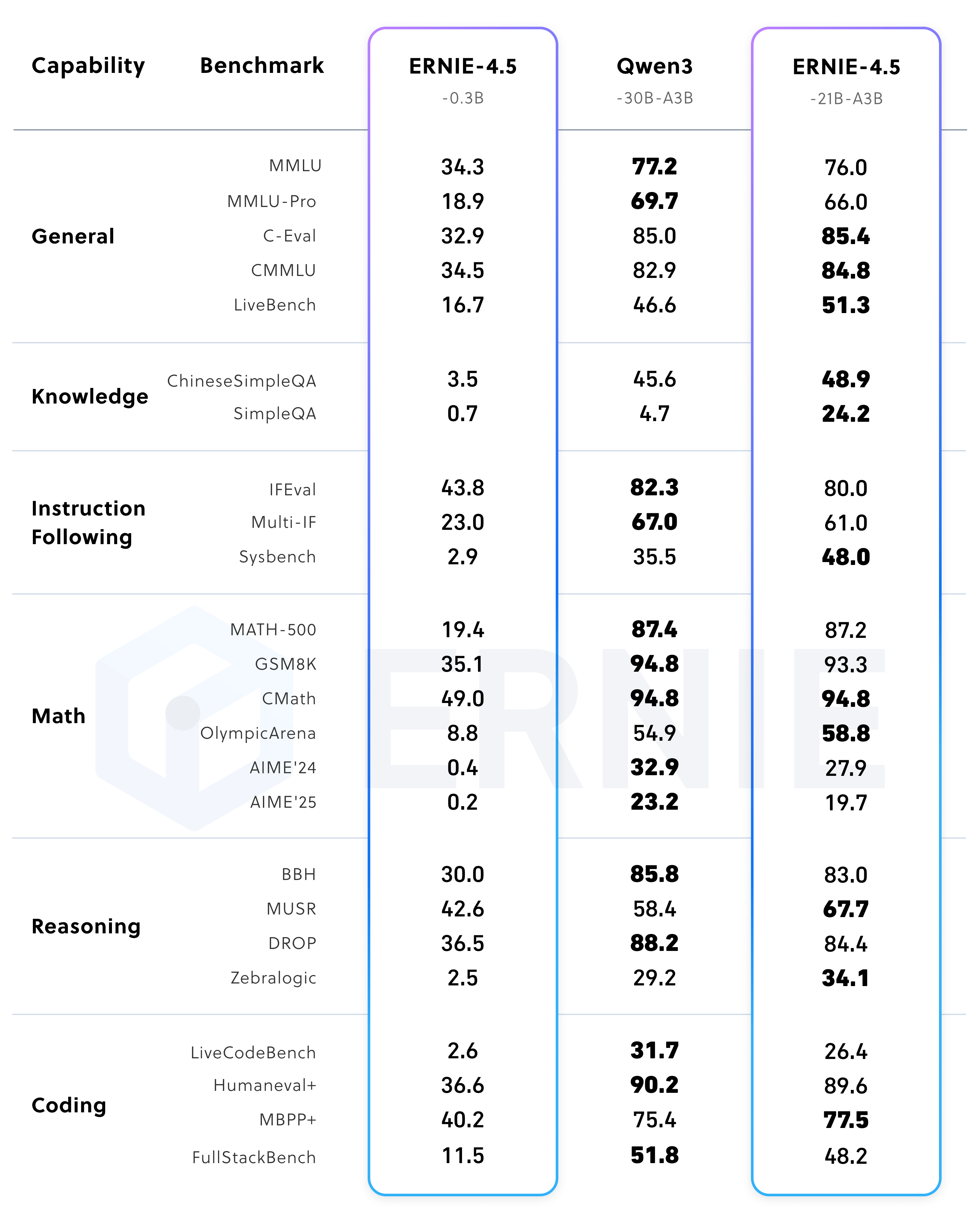
4、多模态后训练模型(支持思考)
5、多模态后训练模型(关闭思考)
三、多平台部署实战及应用
文心大模型开源后,大家可以选择多种平台来进行部署。如果本地有充足的服务器资源和算力,那么在本地部署一个大模型也未尝不是一种很好的方法,但通常情况下,个人开发者的算力和存储都是比较有限的,因此想部署一个大模型,还是建议大家使用在线的算力系统和平台来进行,这样不仅省时省力,也能将主要精力集中到业务实现当中,而不是投入到冗长的大模型部署工作当中。本节将来介绍几种百度文心大模型的部署方式,希望对大家有所帮助。
1、PP飞浆平台的快速部署及使用
ERNIE 4.5模型使用飞桨(PaddlePaddle)框架进行训练。以下部分介绍了飞桨生态中用于精调和部署ERNIE 4.5模型的工具和资源。对于使用 PyTorch 的开发者,ERNIE 4.5 模型也提供 PyTorch 格式的模型。
ERNIEKit:精调与对齐
ERNIE 是一个面向 ERNIE 4.5 的产业级开发套件。它提供了模型训练和压缩功能,包括预训练,SFT,LoRA, DPO,量化感知训练(QAT)和训练后量化(PTQ)等技术。大家可以进入到飞浆平台来进行平台的部署和调试使用。
ERNIE-4.5-VL-424B-A47B为例所需要的资源依赖为: 需要 80GB x 8 GPU 资源。--quantization 参数支持指定 wint4 或 wint8 用于 4 位或 8 位量化的部署。
在飞浆中进行模型的调用和结果验证,
以下是大模型的一些交互回答结果,问:未来还有哪些可以优化的?
我作为大模型学习助手,在功能和服务上确实还有不少可以优化的空间,以下是我针对当前能力的一些优化方向和具体措施:1. **增强技术深度与广度**:- 持续跟踪大模型领域的最新研究成果,如新的架构设计、训练技巧、评估方法等,确保提供的信息始终处于技术前沿。- 扩展对多模态大模型(如视觉-语言模型、音频-语言模型等)的支持,提供更全面的技术解读和实战指导。2. **提升交互体验**:- 优化对话流程,使回答更加简洁明了,同时保持信息的完整性和准确性。- 引入更多的交互元素,如图表、代码示例、架构图等,以更直观的方式呈现复杂的技术概念。- 提供个性化的学习路径推荐,根据用户的学习进度和兴趣点,定制专属的学习计划。3. **加强实战指导**:- 增加更多的实战案例和代码示例,涵盖从基础到高级的各个层面,帮助用户更好地将理论知识转化为实践能力。- 提供模型训练和调优的详细指南,包括数据准备、模型选择、参数设置、训练过程监控等各个环节。- 引入在线编程环境或集成开发环境(IDE)的支持,使用户能够在对话中直接编写、运行和调试代码。4. **优化问题解答与讨论**:- 提升问题解答的准确性和效率,对于常见问题提供快速回答,对于复杂问题则进行深入分析并提供解决方案。- 鼓励用户之间的交流和讨论,提供论坛或社区支持,促进知识的共享和传播。- 引入专家评审机制,邀请领域内的专家对我的回答进行评审和反馈,不断提升回答的质量。5. **增强可访问性与可用性**:- 优化界面设计,使其更加友好和易于使用,同时考虑不同设备和屏幕尺寸的兼容性。- 提供多语言支持,满足不同国家和地区用户的需求。- 考虑引入语音交互功能,为用户提供更加便捷的交互方式。总的来看,我将不断努力优化自己的功能和服务,以更好地满足用户的需求和期望。如果你有任何具体的建议或需求,欢迎随时告诉我,我会尽力为你提供更好的帮助。2、百度智能云千帆大模型集成
除了百度本身带的飞浆平台之外,在百度智能云的千帆大模型集成平台中也可以进行深度的集成使用。以下是在千帆大模型的一些集成和测试过程,百度智能云。
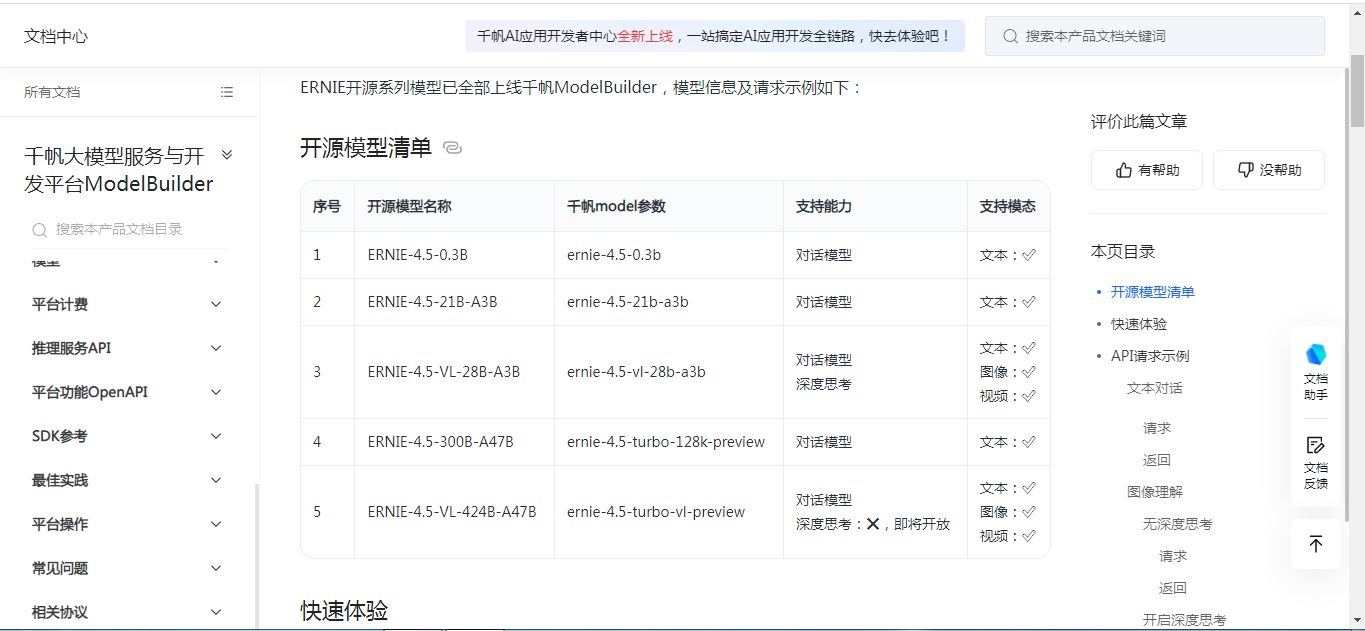
开源模型清单
| 序号 | 开源模型名称 | 千帆model参数 | 支持能力 | 支持模态 |
|---|---|---|---|---|
| 1 | ERNIE-4.5-0.3B | ernie-4.5-0.3b | 对话模型 | 文本:✅ |
| 2 | ERNIE-4.5-21B-A3B | ernie-4.5-21b-a3b | 对话模型 | 文本:✅ |
| 3 | ERNIE-4.5-VL-28B-A3B | ernie-4.5-vl-28b-a3b | 对话模型 深度思考 | 文本:✅ 图像:✅ 视频:✅ |
| 4 | ERNIE-4.5-300B-A47B | ernie-4.5-turbo-128k-preview | 对话模型 | 文本:✅ |
| 5 | ERNIE-4.5-VL-424B-A47B | ernie-4.5-turbo-vl-preview | 对话模型 深度思考:❌,即将开放 | 文本:✅ 图像:✅ 视频:✅ |
同样也是可以进行直接的集成和测试使用的。下面以文本对话和无深度思考的图片理解为例说明如何进行API交互。
文本对话场景:
curl --location 'https://qianfan.baidubce.com/v2/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer your-key' \
--data '{"messages": [{"role": "user","content": "你好"}],"stream": false,"model": "ernie-4.5-0.3b"
}'发送之后得到的响应如下:
{"id": "as-t7y0cuhqxu","object": "chat.completion","created": 1751210799,"model": "ernie-4.5-0.3b","choices": [{"index": 0,"message": {"role": "assistant","content": "你好呀!今天过得怎么样?有什么新鲜事想和我分享吗?无论是生活趣事,还是小建议,我都在这儿等你哟!"},"finish_reason": "stop","flag": 0}],"usage": {"prompt_tokens": 9,"completion_tokens": 30,"total_tokens": 39}
}无深度思考的图片理解
请求报文的信息如下:
curl --location 'https://qianfan.baidubce.com/v2/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer your-key' \
--data '{"model": "ernie-4.5-turbo-vl-preview","messages": [{"role": "user","content": [{"type": "text","text": "图片当中是哪个乐队组合"},{"type": "image_url","image_url": {"url": "https://bucket-demo-bj.bj.bcebos.com/pic/wuyuetian.png","detail": "high"}}]}],"stream": false
}'请注意,这里的图片是一张公开的照片,大家可以实测改成自己本地的。

请求发送后,返回的测试数据为:
{"id": "as-u39err54g0","object": "chat.completion","created": 1751203207,"model": "ernie-4.5-turbo-vl-preview","choices": [{"index": 0,"message": {"role": "assistant","content": "这张图片中的乐队组合是**五月天(Mayday)**。五月天是一支台湾的流行摇滚乐队,成立于1997年,由五位成员组成:阿信(主唱)、怪兽(吉他手)、石头(吉他手)、玛莎(贝斯手)和冠佑(鼓手)。他们以其充满活力的音乐风格和富有感染力的现场表演而闻名,在华语乐坛拥有广泛的影响力和庞大的粉丝群体。"},"finish_reason": "stop","flag": 0}],"usage": {"prompt_tokens": 1378,"completion_tokens": 87,"total_tokens": 1465}
}通过图片的解析和返回的文本,基本表达的内容是符合我们的需要的。而且响应是比较快速地。
四、总结
以上就是本文的主要内容,本文将对百度的文心大模型进行详细的介绍,通过它的开源社区和集成平台来进行学习和模拟。通过模型的集成部署,让大家不仅详细的了解大模型的相关技术,同时可以掌握大模型的部署、训练和使用全过程讲解。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。
1、与其它大模型的对比
ERNIE-4.5-VL-28B-A3B-Paddle 百度文心 4.5 系列的多模态 MoE 大模型,以 28B 总参数与 3B 激活参数的高效设计,通过多模态异构 MoE 预训练、规模效率化基础设施及模态特定后训练三大技术创新,在跨模态理解与生成、长文本处理等领域表现卓越,部署流程便捷且适配多场景,与 DeepSeek-R1 相比,在多模态融合与实用场景落地中展现出差异化竞争力
✅多模态原生融合能力更强:ERNIE-4.5-VL-28B-A3B-Paddle 借异构 MoE 和模态隔离路由,原生支持图文识别等多模态任务,DeepSeek-R1 是单语言模型,处理多模态需额外适配,原生跨模态能力不足
✅长文本处理效率与精度更优:ERNIE-4.5-VL-28B-A3B-Paddle 131072 长上下文,在长文本场景中信息抓取与逻辑连贯性远超 DeepSeek-R1,DeepSeek-R1 相比较易遗漏信息或逻辑断裂
✅本土化部署与生态适配更完善:ERNIE-4.5-VL-28B-A3B-Paddle 基于 PaddlePaddle 深度优化,全流程工具链完善,适配国内硬件与行业场景;DeepSeek-R1 虽开源宽松,但本土化生态与场景方案覆盖不足
2、对文心大模型的期望
1、模型参数从0.3B到474B(参数丰富,可选择多),跨度大,可以根据自己的需求选择使用不同参数规模的模型,兼顾性能和效率。
2、基于GitCode托管的模型,我们可以实现模型的高速下载,基于百度自研的飞桨框架,我们可以实现一条命令快速部署。
3、文心大模型多模态理解识别能力强,可以非常准确的识别人物和验证码图片,未来我们甚至可以直接使用文心大模型4.5替代复杂的视觉类识别算法。
4、文心大模型的场景化能力非常强,可以帮助我们高效的完成自媒体创作领域的辅助工作,让我们的创作效率直线提升。
站在巨人的肩膀上才能看得更远,本文在行文中参考以下连接:
| 序号 | 参考链接 |
| 1 | 名列前茅!百度文心大模型4.5及X1在中国信通院“方升”大模型基准测试中表现优异 |
| 2 | ERNIE-4.5-VL-424B-A47B-Paddle 开源地址 |
| 3 | 文心模型介绍 |
一切的介绍都需要您亲自来动手实践,想要体验百度文心大模型的能力可以进以下入口:
一起来轻松玩转文心大模型吧!文心大模型免费下载地址:https://ai.gitcode.com/theme/1939325484087291906