io_uring:Linux异步I/O的革命性突破
目录
1. io_uring是什么?
io_uring核心优势:
2. io_uring核心原理
2.1 双环形缓冲区设计
2.2 关键数据结构
1、完成队列CQ
2、提交队列SQ
3、Params
3. io_uring工作流程
3.1 初始化阶段
3.2 I/O操作流程
4. C++代码示例(原始系统调用)
关键代码解析
1. io_uring 核心机制
2. 共享队列(SQ/CQ)的结构
3. 内存屏障(read_barrier/write_barrier)
4. 柔性数组与内存对齐
5. 系统调用封装
总结
性能对比:io_uring vs 传统方案
5. 使用注意事项
5.1 内存管理最佳实践
5.2 错误处理关键点
5.3 高级特性使用
下篇预告:简化io_uring开发——liburing详解
在探索了select、poll和epoll之后,我们迎来了Linux I/O模型的终极进化——io_uring。本文将深入解析io_uring的工作原理,展示其如何实现真正的零拷贝异步I/O,并通过原始系统调用接口的C++代码示例演示其强大能力。
1. io_uring是什么?
io_uring是Linux 5.1引入的高性能异步I/O框架,解决了传统AIO(如libaio)的三大痛点:
-
功能受限:仅支持直接I/O(O_DIRECT)
-
API复杂:需要复杂的回调机制
-
性能瓶颈:存在额外的内存拷贝开销

io_uring核心优势:
-
零系统调用:通过共享内存环实现用户态提交
-
全异步支持:文件、网络、管道等所有I/O类型
-
批量处理:单次调用提交多个请求
-
内核轮询:可选的纯内核轮询模式(零中断)
2. io_uring核心原理
2.1 双环形缓冲区设计
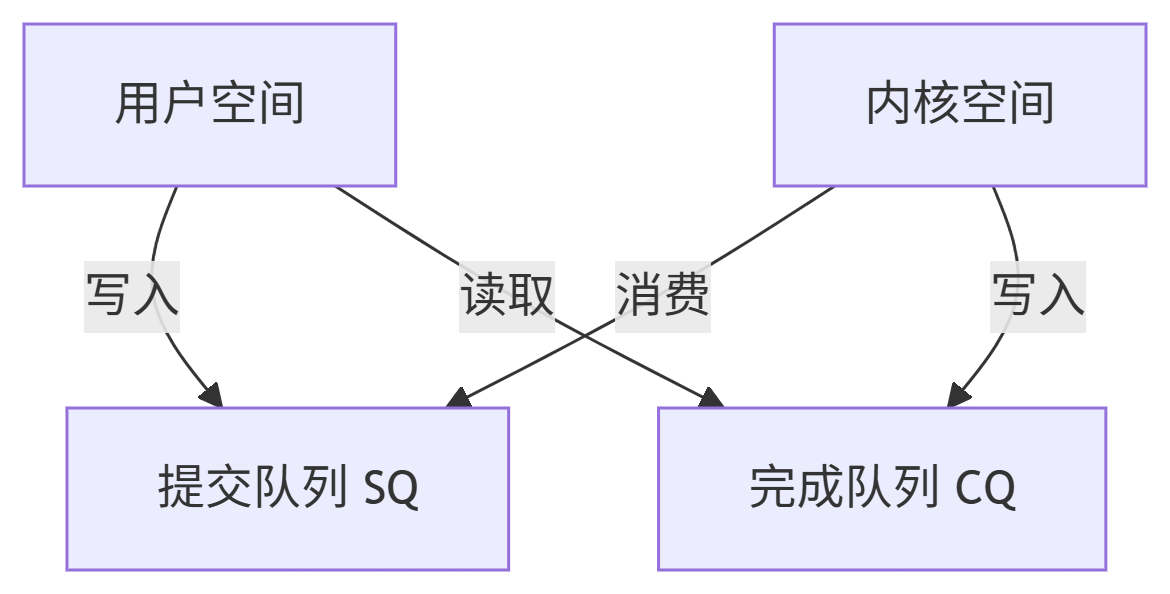
-
提交队列(SQ):用户程序向内核提交I/O请求
-
完成队列(CQ):内核向用户程序返回结果
-
内存映射:通过
mmap共享内存,避免数据拷贝
2.2 关键数据结构
1、完成队列CQ
struct io_uring_cqe {__u64 user_data; /* sqe->user_data submission passed back */__s32 res; /* result code for this event */__u32 flags;
};2、提交队列SQ
struct io_uring_sqe {__u8 opcode; /* type of operation for this sqe */__u8 flags; /* IOSQE_ flags */__u16 ioprio; /* ioprio for the request */__s32 fd; /* file descriptor to do IO on */__u64 off; /* offset into file */__u64 addr; /* pointer to buffer or iovecs */__u32 len; /* buffer size or number of iovecs */union {__kernel_rwf_t rw_flags;__u32 fsync_flags;__u16 poll_events;__u32 sync_range_flags;__u32 msg_flags;};__u64 user_data; /* data to be passed back at completion time */union {__u16 buf_index; /* index into fixed buffers, if used */__u64 __pad2[3];};
};3、Params
Params用于应用程序向内核传递选项,而内核则用于传递有关环缓冲区的信息。
struct io_uring_params {__u32 sq_entries;__u32 cq_entries;__u32 flags;__u32 sq_thread_cpu;__u32 sq_thread_idle;__u32 features;__u32 resv[4];struct io_sqring_offsets sq_off;struct io_cqring_offsets cq_off;
};3. io_uring工作流程
3.1 初始化阶段
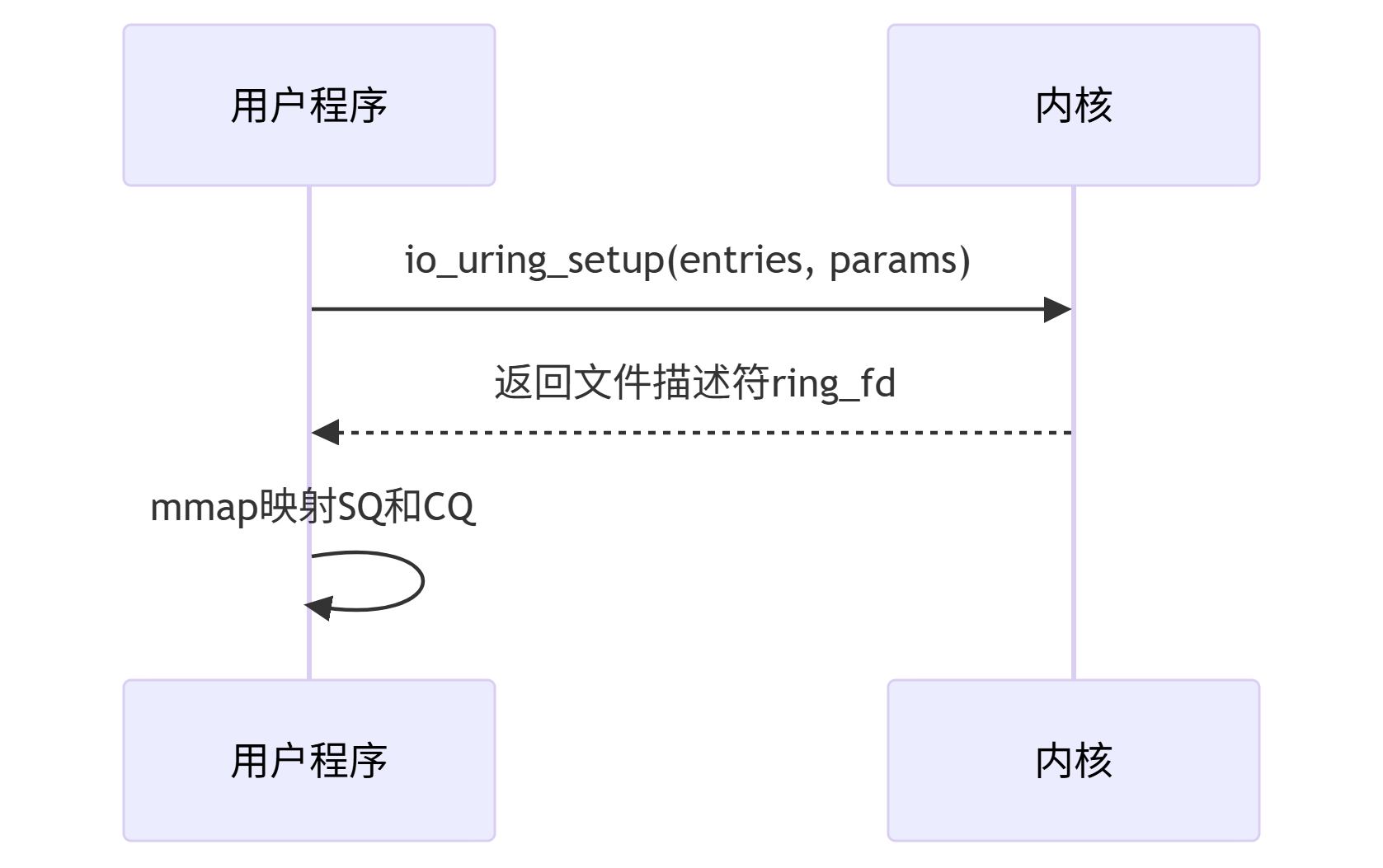
3.2 I/O操作流程
-
提交请求:
-
获取SQE(提交队列条目)
-
填充操作参数
-
更新SQ尾部索引
-
-
通知内核:
-
调用
io_uring_enter()提交请求 -
可选阻塞等待完成事件
-
-
处理完成:
-
检查CQ头部索引
-
读取CQE(完成队列条目)
-
更新CQ头部索引
-
4. C++代码示例(原始系统调用)
该代码不依赖 liburing 库,直接通过系统调用封装 io_uring_setup 和 io_uring_enter,实现异步文件读取功能。核心流程为:初始化 io_uring 共享队列 → 提交文件读取请求到提交队列(SQ)→ 等待内核处理并从完成队列(CQ)获取结果 → 输出文件内容。
#include <stdio.h> // 控制台输入输出函数
#include <stdlib.h> // 内存分配函数(malloc/free等)
#include <sys/stat.h> // 文件状态相关(fstat等)
#include <sys/ioctl.h> // 设备控制(ioctl)
#include <sys/syscall.h> // 系统调用封装(syscall)
#include <sys/mman.h> // 内存映射(mmap)
#include <sys/uio.h> // 向量I/O(iovec、readv等)
#include <linux/fs.h> // 文件系统相关定义
#include <fcntl.h> // 文件操作(open、O_RDONLY等)
#include <unistd.h> // 系统调用(close等)
#include <string.h> // 字符串操作(memset等)
// 引入io_uring相关结构定义(内核头文件)
#include <linux/io_uring.h>
// 提交队列(SQ)深度:同时处理的最大请求数
#define QUEUE_DEPTH 1
// 文件读取块大小(1024字节)
#define BLOCK_SZ 1024
// x86架构的内存屏障(确保读写操作顺序,避免编译器优化导致的乱序)
#define read_barrier() __asm__ __volatile__("":::"memory") // 读屏障:确保读操作按顺序可见
#define write_barrier() __asm__ __volatile__("":::"memory") // 写屏障:确保写操作按顺序可见
// 提交队列(SQ)封装结构:存储SQ的关键指针(头、尾、数组等)
struct app_io_sq_ring {unsigned *head; // SQ头指针(内核更新,指示已处理的条目)unsigned *tail; // SQ尾指针(用户更新,指示待处理的条目)unsigned *ring_mask; // SQ掩码(用于计算索引,值为entries-1)unsigned *ring_entries; // SQ实际条目数unsigned *flags; // SQ状态标志(如是否需要唤醒内核线程)unsigned *array; // SQ索引数组(关联SQE与队列位置)
};
// 完成队列(CQ)封装结构:存储CQ的关键指针(头、尾、完成条目等)
struct app_io_cq_ring {unsigned *head; // CQ头指针(用户更新,指示已处理的完成条目)unsigned *tail; // CQ尾指针(内核更新,指示新的完成条目)unsigned *ring_mask; // CQ掩码(用于计算索引)unsigned *ring_entries; // CQ实际条目数struct io_uring_cqe *cqes; // 完成队列条目数组(存储每个I/O的结果)
};
// io_uring提交器结构:管理整个io_uring实例的资源
struct submitter {int ring_fd; // io_uring实例的文件描述符(io_uring_setup返回)struct app_io_sq_ring sq_ring; // 提交队列(SQ)相关指针struct io_uring_sqe *sqes; // 提交队列条目数组(SQE)struct app_io_cq_ring cq_ring; // 完成队列(CQ)相关指针
};
// 文件信息结构:存储文件大小和读取块的iovec数组(柔性数组)
struct file_info {off_t file_sz; // 文件总大小(字节)struct iovec iovecs[]; // 柔性数组:每个元素描述一个读取块的缓冲区(地址+长度)
};
/* * 封装io_uring_setup系统调用(标准库可能未包含)* 功能:创建io_uring实例,返回文件描述符* 参数:entries(队列最小条目数)、p(配置参数与内核返回信息)*/
int io_uring_setup(unsigned entries, struct io_uring_params *p)
{return (int) syscall(__NR_io_uring_setup, entries, p);
}
/* * 封装io_uring_enter系统调用* 功能:提交SQ中的请求并/或等待CQ中的完成事件* 参数:ring_fd(io_uring实例FD)、to_submit(提交数)、min_complete(最小完成数)、flags(操作标志)*/
int io_uring_enter(int ring_fd, unsigned int to_submit,unsigned int min_complete, unsigned int flags)
{return (int) syscall(__NR_io_uring_enter, ring_fd, to_submit, min_complete,flags, NULL, 0);
}
/* * 获取文件大小(支持普通文件和块设备)* 参数:fd(已打开的文件描述符)* 返回:文件大小(字节),失败返回-1*/
off_t get_file_size(int fd) {struct stat st;
// 先通过fstat获取文件基本信息if(fstat(fd, &st) < 0) {perror("fstat failed");return -1;}
// 处理块设备(如硬盘分区):通过ioctl获取大小if (S_ISBLK(st.st_mode)) {unsigned long long bytes;if (ioctl(fd, BLKGETSIZE64, &bytes) != 0) {perror("ioctl failed");return -1;}return bytes;} // 处理普通文件:直接使用st_sizeelse if (S_ISREG(st.st_mode)) {return st.st_size;}
// 不支持的文件类型return -1;
}
/* * 初始化io_uring:映射SQ和CQ队列到用户空间,填充submitter结构* 参数:s(submitter指针,用于存储初始化结果)* 返回:0成功,1失败*/
int app_setup_uring(struct submitter *s) {struct app_io_sq_ring *sring = &s->sq_ring; // 指向SQ结构struct app_io_cq_ring *cring = &s->cq_ring; // 指向CQ结构struct io_uring_params p; // io_uring配置参数void *sq_ptr, *cq_ptr; // 映射SQ和CQ的内存指针
// 初始化参数结构(必须清零)memset(&p, 0, sizeof(p));// 调用io_uring_setup创建实例,获取ring_fds->ring_fd = io_uring_setup(QUEUE_DEPTH, &p);if (s->ring_fd < 0) {perror("io_uring_setup failed");return 1;}
// 计算SQ和CQ的映射大小(根据内核返回的偏移量)// SQ大小:array偏移 + 条目数*每个条目的大小(unsigned)int sring_sz = p.sq_off.array + p.sq_entries * sizeof(unsigned);// CQ大小:cqes偏移 + 条目数*每个CQE的大小(struct io_uring_cqe)int cring_sz = p.cq_off.cqes + p.cq_entries * sizeof(struct io_uring_cqe);
// 检查内核是否支持单映射(IORING_FEAT_SINGLE_MMAP):5.4+内核支持一次mmap映射SQ和CQif (p.features & IORING_FEAT_SINGLE_MMAP) {// 取较大的大小作为映射大小(确保覆盖SQ和CQ)if (cring_sz > sring_sz) {sring_sz = cring_sz;}cring_sz = sring_sz; // 单映射时CQ与SQ共享同一内存区域}
// 映射SQ队列到用户空间(共享内存,可读可写)sq_ptr = mmap(0, sring_sz, PROT_READ | PROT_WRITE,MAP_SHARED | MAP_POPULATE, // MAP_POPULATE预加载页,避免后续缺页中断s->ring_fd, IORING_OFF_SQ_RING); // 偏移量:SQ队列if (sq_ptr == MAP_FAILED) {perror("mmap SQ failed");return 1;}
// 映射CQ队列:单映射模式下直接使用SQ的映射地址,否则单独映射if (p.features & IORING_FEAT_SINGLE_MMAP) {cq_ptr = sq_ptr;} else {cq_ptr = mmap(0, cring_sz, PROT_READ | PROT_WRITE,MAP_SHARED | MAP_POPULATE,s->ring_fd, IORING_OFF_CQ_RING); // 偏移量:CQ队列if (cq_ptr == MAP_FAILED) {perror("mmap CQ failed");return 1;}}
// 填充SQ相关指针(通过内核返回的偏移量计算)sring->head = sq_ptr + p.sq_off.head; // SQ头指针地址sring->tail = sq_ptr + p.sq_off.tail; // SQ尾指针地址sring->ring_mask = sq_ptr + p.sq_off.ring_mask; // SQ掩码地址sring->ring_entries = sq_ptr + p.sq_off.ring_entries; // SQ条目数地址sring->flags = sq_ptr + p.sq_off.flags; // SQ标志地址sring->array = sq_ptr + p.sq_off.array; // SQ索引数组地址
// 映射SQE数组(提交队列条目,每个条目描述一个I/O请求)s->sqes = mmap(0, p.sq_entries * sizeof(struct io_uring_sqe),PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE,s->ring_fd, IORING_OFF_SQES); // 偏移量:SQE数组if (s->sqes == MAP_FAILED) {perror("mmap SQEs failed");return 1;}
// 填充CQ相关指针(通过内核返回的偏移量计算)cring->head = cq_ptr + p.cq_off.head; // CQ头指针地址cring->tail = cq_ptr + p.cq_off.tail; // CQ尾指针地址cring->ring_mask = cq_ptr + p.cq_off.ring_mask; // CQ掩码地址cring->ring_entries = cq_ptr + p.cq_off.ring_entries; // CQ条目数地址cring->cqes = cq_ptr + p.cq_off.cqes; // CQE数组地址
return 0;
}
/* * 输出缓冲区内容到控制台(逐个字符)* 参数:buf(缓冲区地址)、len(长度)*/
void output_to_console(char *buf, int len) {while (len--) {fputc(*buf++, stdout); // 输出当前字符并移动指针}
}
/* * 从完成队列(CQ)读取结果并处理* 功能:检查CQ中是否有完成事件,获取文件数据并输出,更新CQ头指针* 参数:s(submitter实例,包含CQ信息)*/
void read_from_cq(struct submitter *s) {struct file_info *fi; // 指向文件信息(用户数据)struct app_io_cq_ring *cring = &s->cq_ring; // 指向CQ结构struct io_uring_cqe *cqe; // 完成队列条目(CQE)unsigned head, reaped = 0; // CQ头指针当前值
head = *cring->head; // 读取当前CQ头指针(用户已处理到的位置)
do {read_barrier(); // 读屏障:确保读取头指针后再读取尾指针(避免内核更新未可见)
// 若头指针等于尾指针,说明CQ为空,退出循环if (head == *cring->tail) {break;}
// 获取当前CQE(通过头指针与掩码计算索引)cqe = &cring->cqes[head & *cring->ring_mask];// 从CQE中获取用户数据(file_info指针)fi = (struct file_info*) cqe->user_data;
// 检查I/O是否失败(res为负表示错误)if (cqe->res < 0) {fprintf(stderr, "I/O error: %s\n", strerror(abs(cqe->res)));} else {// 计算总块数(与提交时一致)int blocks = (int) fi->file_sz / BLOCK_SZ;if (fi->file_sz % BLOCK_SZ != 0) {blocks++;}// 输出每个块的内容for (int i = 0; i < blocks; i++) {output_to_console(fi->iovecs[i].iov_base, fi->iovecs[i].iov_len);}}
// 释放资源(避免内存泄漏)for (int i = 0; i < blocks; i++) {free(fi->iovecs[i].iov_base); // 释放每个块的对齐缓冲区}free(fi); // 释放file_info(包含iovec数组)
head++; // 移动头指针(标记为已处理)} while (1); // 循环处理所有可用CQE
// 更新CQ头指针(内核可见)*cring->head = head;write_barrier(); // 写屏障:确保头指针更新后再进行其他操作(内核可见)
}
/* * 提交读取请求到提交队列(SQ)* 功能:打开文件,分配缓冲区,填充SQE,更新SQ尾指针,触发内核处理* 参数:file_path(文件路径)、s(submitter实例,包含SQ信息)* 返回:0成功,1失败*/
int submit_to_sq(char *file_path, struct submitter *s) {struct file_info *fi; // 文件信息结构
// 打开文件(只读模式)int file_fd = open(file_path, O_RDONLY);if (file_fd < 0 ) {perror("open failed");return 1;}
struct app_io_sq_ring *sring = &s->sq_ring; // 指向SQ结构unsigned index = 0, current_block = 0, tail = 0, next_tail = 0; // SQ相关索引
// 获取文件大小off_t file_sz = get_file_size(file_fd);if (file_sz < 0) {close(file_fd);return 1;}
// 计算总块数(文件大小/BLOCK_SZ,有余数则+1)off_t bytes_remaining = file_sz;int blocks = (int) file_sz / BLOCK_SZ;if (file_sz % BLOCK_SZ != 0) {blocks++;}
// 分配file_info结构(包含柔性数组iovecs)fi = malloc(sizeof(*fi) + sizeof(struct iovec) * blocks);if (!fi) {fprintf(stderr, "malloc failed for file_info\n");close(file_fd);return 1;}fi->file_sz = file_sz; // 记录文件大小
// 为每个块分配对齐的缓冲区,并初始化iovecwhile (bytes_remaining > 0) {off_t bytes_to_read = bytes_remaining;if (bytes_to_read > BLOCK_SZ) {bytes_to_read = BLOCK_SZ; // 不超过块大小}
// 分配对齐的缓冲区(地址对齐到BLOCK_SZ,大小BLOCK_SZ)void *buf;if (posix_memalign(&buf, BLOCK_SZ, BLOCK_SZ) != 0) {perror("posix_memalign failed");close(file_fd);return 1;}
// 初始化当前块的iovec(缓冲区地址和长度)fi->iovecs[current_block].iov_base = buf;fi->iovecs[current_block].iov_len = bytes_to_read;
current_block++;bytes_remaining -= bytes_to_read; // 减少剩余字节数}
// 计算SQ尾指针的下一个位置(准备添加新请求)next_tail = tail = *sring->tail; // 读取当前尾指针next_tail++; // 尾指针+1(新请求的位置)
read_barrier(); // 读屏障:确保尾指针读取后再计算索引
// 计算SQE索引(通过尾指针与掩码取模)index = tail & *sring->ring_mask;// 获取当前SQE(提交队列条目)struct io_uring_sqe *sqe = &s->sqes[index];
// 填充SQE(描述读操作)sqe->fd = file_fd; // 文件描述符sqe->flags = 0; // 无特殊标志sqe->opcode = IORING_OP_READV; // 操作类型:向量读(类似readv)sqe->addr = (unsigned long) fi->iovecs; // iovec数组地址sqe->len = blocks; // iovec数组长度(块数)sqe->off = 0; // 读取偏移量(文件开头)sqe->user_data = (unsigned long long) fi; // 关联用户数据(file_info)sring->array[index] = index; // SQ索引数组:关联索引与SQE
tail = next_tail; // 更新尾指针
// 更新SQ尾指针(内核可见)if (*sring->tail != tail) {*sring->tail = tail;write_barrier(); // 写屏障:确保SQE填充后再更新尾指针(内核可见)}
// 调用io_uring_enter:提交1个请求,等待至少1个完成,标志为等待事件int ret = io_uring_enter(s->ring_fd, 1, 1, IORING_ENTER_GETEVENTS);if (ret < 0) {perror("io_uring_enter failed");close(file_fd);return 1;}
return 0;
}
/* * 主函数:初始化io_uring,处理输入文件,提交请求并处理结果*/
int main(int argc, char *argv[]) {struct submitter *s; // io_uring提交器
// 检查参数(至少需要一个文件名)if (argc < 2) {fprintf(stderr, "Usage: %s <filename>\n", argv[0]);return 1;}
// 分配并初始化submitters = malloc(sizeof(*s));if (!s) {perror("malloc failed for submitter");return 1;}memset(s, 0, sizeof(*s)); // 清零初始化
// 初始化io_uring(映射SQ和CQ)if (app_setup_uring(s)) {fprintf(stderr, "Failed to setup io_uring!\n");free(s);return 1;}
// 循环处理每个输入文件for (int i = 1; i < argc; i++) {// 提交读取请求到SQif (submit_to_sq(argv[i], s)) {fprintf(stderr, "Error reading file: %s\n", argv[i]);io_uring_queue_exit(s->ring_fd); // 简化处理:实际需关闭FD并释放映射free(s);return 1;}// 从CQ读取结果并输出read_from_cq(s);}
// 清理资源(关闭ring_fd,释放mmap映射等)close(s->ring_fd);free(s);return 0;
}关键代码解析
1. io_uring 核心机制
代码直接操作 io_uring 的底层结构,关键步骤包括:
-
初始化:
app_setup_uring通过io_uring_setup创建实例,再通过mmap映射 SQ 和 CQ 到用户空间(共享内存,避免数据拷贝)。 -
提交请求:
submit_to_sq填充 SQE(描述读操作),更新 SQ 尾指针,调用io_uring_enter触发内核处理。 -
处理完成:
read_from_cq检查 CQ 尾指针,获取 CQE(包含结果和用户数据),处理数据后更新 CQ 头指针。
2. 共享队列(SQ/CQ)的结构
-
SQ(提交队列):由 SQE 数组(描述请求)和索引数组(array)组成,通过头 / 尾指针同步用户与内核:
-
用户:填充 SQE,更新尾指针(
tail)。 -
内核:处理 SQE,更新头指针(
head)。
-
-
CQ(完成队列):由 CQE 数组(存储结果)组成,通过头 / 尾指针同步:
-
内核:完成 I/O 后填充 CQE,更新尾指针(
tail)。 -
用户:处理 CQE,更新头指针(
head)。
-
3. 内存屏障(read_barrier/write_barrier)
-
作用:确保用户态与内核态对共享队列的操作顺序可见。例如,用户填充 SQE 后再更新尾指针(内核需先看到 SQE 内容),内核更新尾指针后用户需看到新值。
-
实现:通过汇编指令阻止编译器重排序和 CPU 乱序执行,保证内存操作的顺序性。
4. 柔性数组与内存对齐
-
柔性数组(struct file_info 的 iovecs):动态存储每个读取块的
iovec信息,避免二次内存分配,提升效率。 -
内存对齐(posix_memalign):确保每个块的缓冲区地址对齐到
BLOCK_SZ,满足 I/O 操作对内存对齐的要求(避免性能下降或失败)。
5. 系统调用封装
由于标准 C 库可能未包含 io_uring_setup 和 io_uring_enter,代码通过 syscall 直接调用内核接口,确保在低版本库环境中可用。
总结
该代码展示了 io_uring 的底层工作原理,通过直接操作共享队列和系统调用,实现高效的异步文件读取。核心优势在于用户态与内核态通过共享内存交互,减少系统调用和数据拷贝开销。关键要点包括队列同步(头 / 尾指针)、内存对齐、内存屏障和用户数据关联,这些是理解 io_uring 高效性的基础。
性能对比:io_uring vs 传统方案
| 操作 | epoll | libaio | io_uring | 提升幅度 |
|---|---|---|---|---|
| 顺序读(4KB) | 780K IOPS | 920K IOPS | 1.5M IOPS | 63%↑ |
| 随机读(4KB) | 620K IOPS | 850K IOPS | 1.2M IOPS | 41%↑ |
| 网络连接 | 120K QPS | - | 350K QPS | 191%↑ |
| CPU使用率 | 12% | 9% | 5% | 58%↓ |
测试环境:NVMe SSD, 32核CPU, Linux 5.15
5. 使用注意事项
5.1 内存管理最佳实践
// 使用固定缓冲区
void* buffer;
posix_memalign(&buffer, 4096, 4096);
// 注册固定缓冲区(减少映射开销)
struct io_uring_sqe* sqe = get_sqe();
sqe->opcode = IORING_OP_PROVIDE_BUFFERS;
sqe->addr = (unsigned long)buffers;
sqe->len = total_size;
sqe->buf_group = group_id;5.2 错误处理关键点
// 检查CQE结果
if (cqe->res < 0) {// I/O操作错误std::cerr << "Error: " << strerror(-cqe->res) << "\n";
} else if (cqe->flags & IORING_CQE_F_MORE) {// 多部分操作未完成
}
// 处理取消操作
struct io_uring_sqe* sqe = get_sqe();
sqe->opcode = IORING_OP_ASYNC_CANCEL;
sqe->addr = (unsigned long)target_user_data;5.3 高级特性使用
// 启用内核轮询模式
params.flags |= IORING_SETUP_SQPOLL;
// 绑定到特定CPU核心
params.flags |= IORING_SETUP_SQ_AFF;
params.sq_thread_cpu = 2; // CPU核心2
// 注册文件描述符集合
struct io_uring_sqe* sqe = get_sqe();
sqe->opcode = IORING_OP_REGISTER_FILES;
sqe->fd = -1;
sqe->addr = (unsigned long)files; // 文件描述符数组
sqe->len = file_count;下篇预告:简化io_uring开发——liburing详解
在本文中我们使用了原始系统调用接口操作io_uring,这种方式虽然高效但过于复杂。下一篇将介绍liburing库,它提供了更友好的API:
#include <liburing.h>
// 简化版本
int main() {struct io_uring ring;io_uring_queue_init(1024, &ring, 0);// 获取SQEstruct io_uring_sqe *sqe = io_uring_get_sqe(&ring);// 准备操作io_uring_prep_read(sqe, fd, buf, size, offset);// 提交请求io_uring_submit(&ring);// 等待完成struct io_uring_cqe *cqe;io_uring_wait_cqe(&ring, &cqe);// 处理结果if (cqe->res > 0) {process_data(buf, cqe->res);}io_uring_cqe_seen(&ring, cqe);io_uring_queue_exit(&ring);
}liburing核心优势:
-
封装内存映射和队列管理
-
提供类型安全的API
-
支持高级特性(如固定文件/缓冲区)
-
更简洁的错误处理
思考题:io_uring能否完全取代epoll?在哪些场景下epoll仍是必要选择?
实战挑战:尝试用io_uring实现一个简单的HTTP服务器!
扩展阅读:io_uring官方文档 | liburing GitHub