Kafka基础理论速通
在4.0版本之后的kafka更新了全新的架构,使用KRafa模式,彻底摆脱了对zookeeper的依赖,在kafka的发展历程中zookeeper担任核心组件负责协调分布式系统中的元数据管理,Broker注册等功能。随着kafka功能的不断丰富,是的ZooKeeper的维护部管理更加困难。
使用Raft一致性算法的共识机制,Kafka将元数据管理内嵌于自身,实现了对ZooKeeper的无缝替代:
- 简化了部署和运维
- 增强可拓展性
- 提升了性能和稳定性
Kafka4.0的核心变革就是管理方式+部署架构发生了变革,其余核心机制并没有发生改变。
本章节的内容是以go语言的segmentio/kafka-go为案例,结合java的客户端进行一个对比学习
一.Kafka的基本概念
1.1 kafka是什么?
kafka是一个分布式,日志型,高吞吐消息的中间件。
1.2 核心组件
比如Producer,Consumer,Broker,Topic,Partition,Offset,Group
接下来说一下这些都是什么吧:
1.2.1 Broker,Topic和Partition
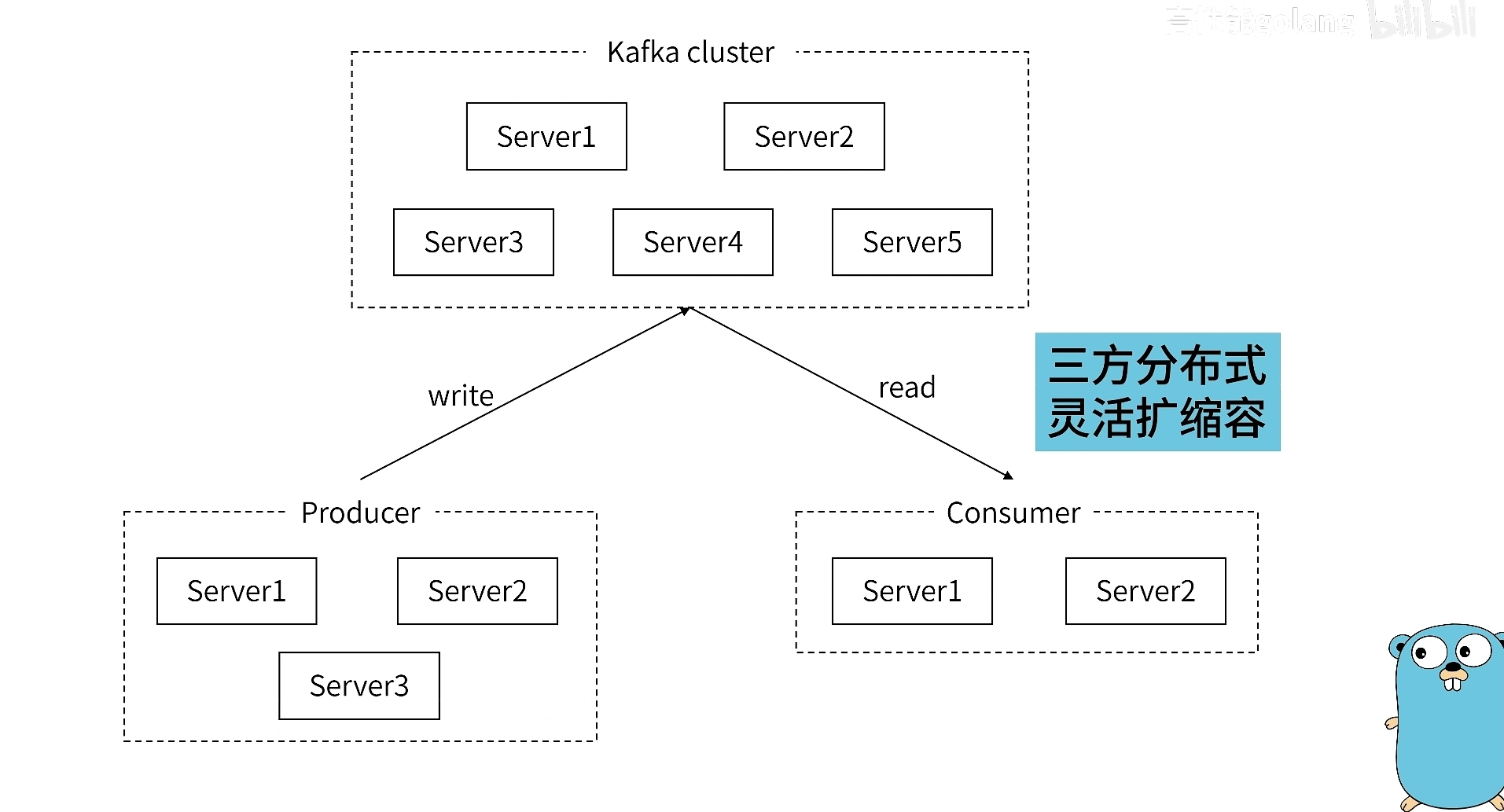
先来看一张大体的框架图:Producer和Consumer就不用多说了。
关键就是这个Kafka Cluster(集群)
- Borker:表示的就是一个Kafka进程
- Topic:不同类别的消息,比如衣服和裤子是不同的类别,kafka也会对不同的消息进行分类。
- Partiton:对不同类别的消息进行一个拆分,也就是对一个Topic进行划分为更小的partition
可以看两张图,来帮助我们加深理解:
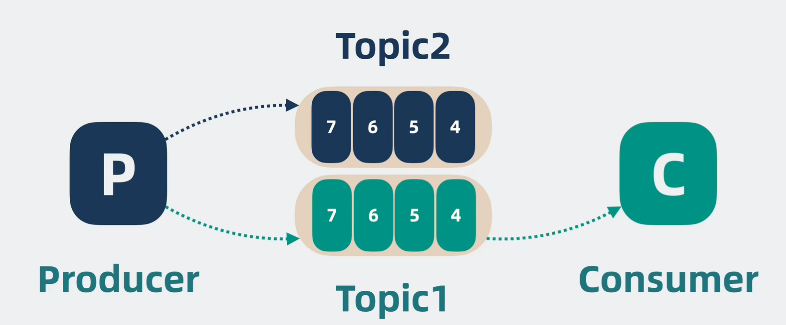
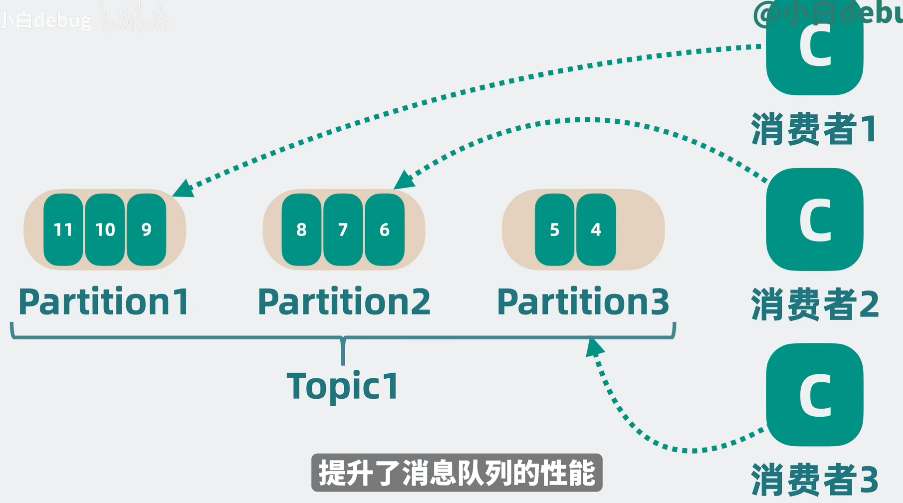
1.2.2 Offest和Group
Offest:表示读取partition的位置,避免读消息时宕机,导致不知道读到哪里了。
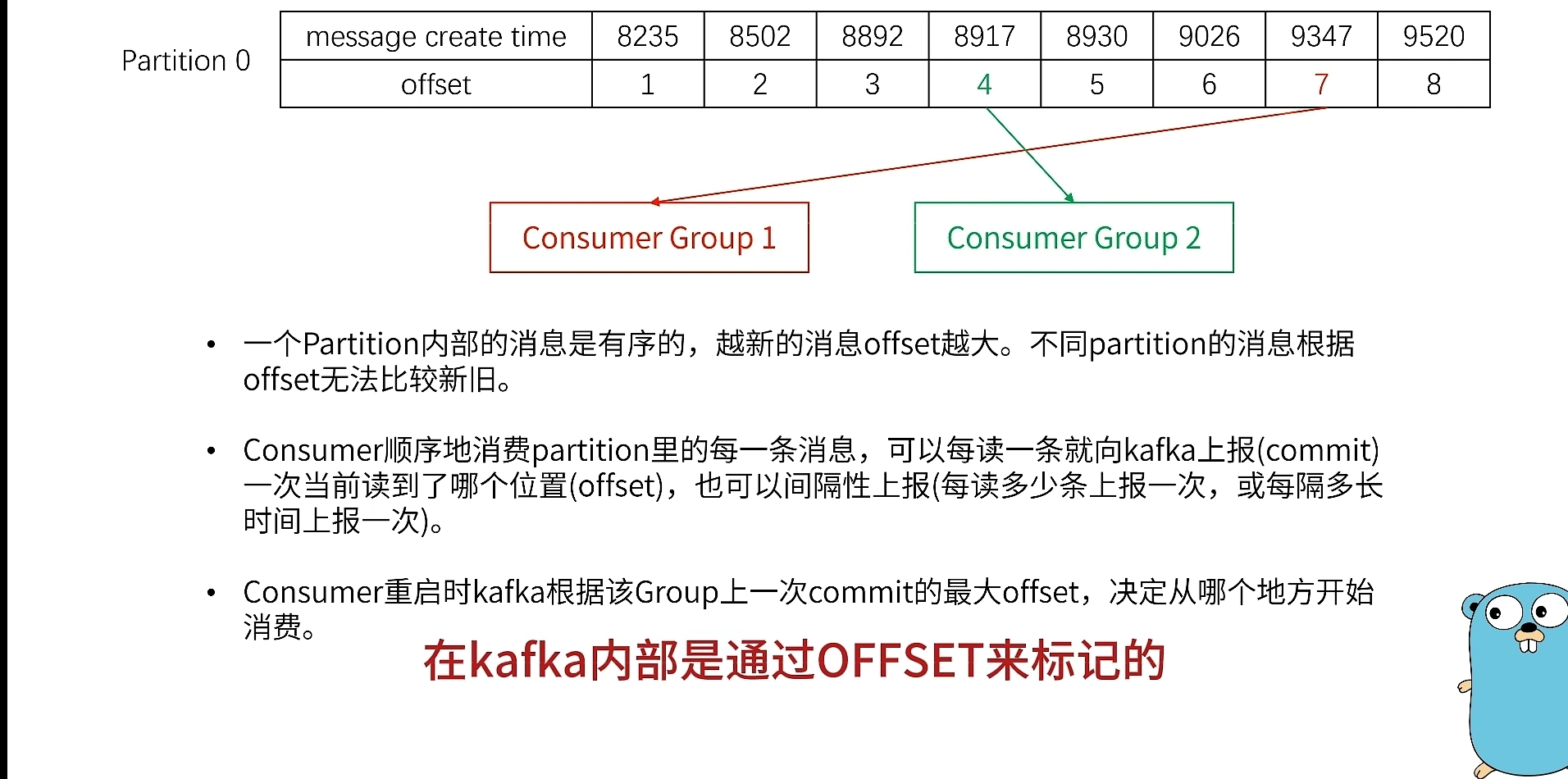
Group:也就是指的消费者组,每个消费者只消费自己对应的部分。
核心原则就是:一个分区只能被一个消费者消费,一个消费者可以消费多个分区。
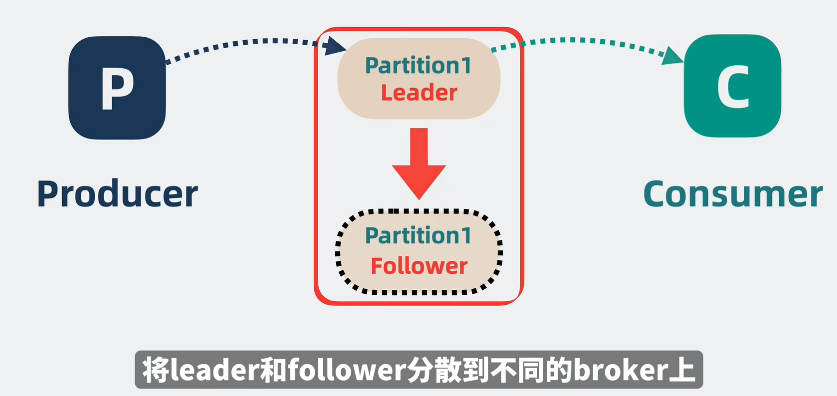
1.2.3 Leader和follower
Leader和follower,就表示主从。
在partition使用的过程中,可能会存在Leader挂掉,这个给时候就需要follower来替补上位。
至于Leader和follower的内容是都一样的
1.2.4 关于写入partition和响应
关于partition的写入主要就是考虑是写入哪一个partition
大致流程:producer -> 选择 topic -> 根据分区策略选择partition -> 将消息追加写入partition
topic就是对应分区的名字,接着确定对应的partition
- 当然你也可以选择你要写入的partition(当然也可以不选择)
- 如果不选择,就是根据分区器(也就是分区算法)来选择
- 如果既两者都没指定,就会默认进行轮询
一般分区器会选择就是对key进行hash,然后对总数取模,再决定要写入哪一个partition
接着,如果存在Leader和follower的
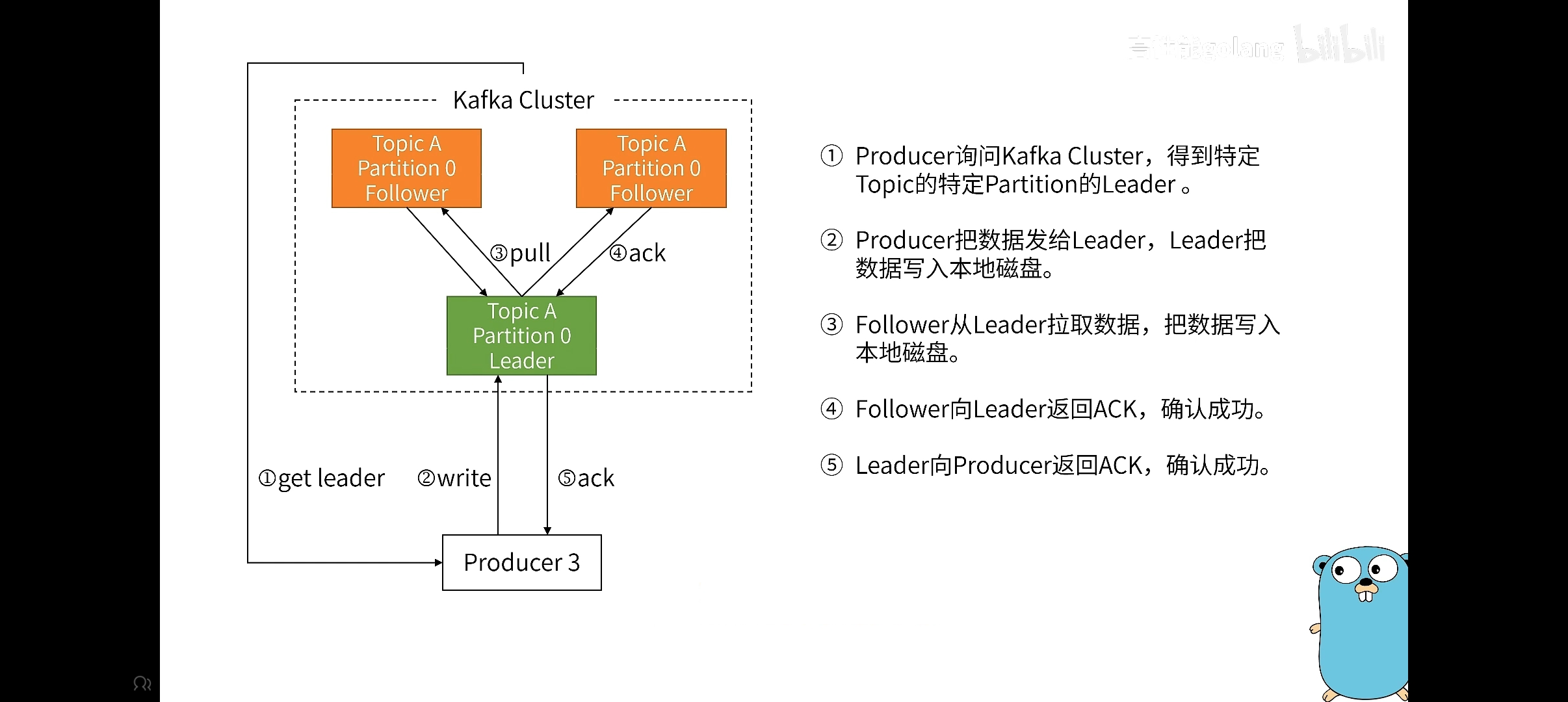
这里就来看一下整体的效果,对于这个ack响应,可以设置,分为很多种情况:
- 一种是你写入就可以,无需等消息队列的ack。
- 另外一种是只有leader返回ack,不管Follower是否拷贝成功。
- 最后一种就是全部成功再返回ack。
1.3 goland安装插件
安装完成之后的kafka的位置在右下角,会多出一个kafka的标志
点击之后可以看到对应的topic和group了
二.kafka客户端(go语言版本)
这里举一个简单的go语言
package mainimport ("context""errors""fmt""github.com/segmentio/kafka-go""os""os/signal""syscall""time"
)var (reader *kafka.Readertopic = "user_click"
)// 生产消息
func writeKafka(ctx context.Context) {// 类似文件操作writer := &kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: topic, // 指定要生产的topicBalancer: &kafka.Hash{}, // 哈希解决要使用哪一个partitionWriteTimeout: 10 * time.Second, // 超时等待RequiredAcks: kafka.RequireNone, // (三种模式,就是关于ack的响应)AllowAutoTopicCreation: true, // 自动创建topic*(实际工作是false)}defer writer.Close()for i := 0; i < 3; i++ {if err := writer.WriteMessages(ctx,// 具有两个字段,key和value,kay是用来选择partition// 注意这里的写入操作是原子的,下面的消息要成功全成功kafka.Message{Key: []byte("1"), Value: []byte("大大怪将军")},kafka.Message{Key: []byte("3"), Value: []byte("小小怪下士")},kafka.Message{Key: []byte("5"), Value: []byte("大大怪将军")},kafka.Message{Key: []byte("2"), Value: []byte("大大怪将军")},); err != nil {// 这里有两个不同的错误,1.topic没有设置 2.写入错误 在这里需要判断一下if errors.Is(err, kafka.LeaderNotAvailable) {// 允许重试,在外面嵌套for循环,进行一个监听time.Sleep(1 * time.Second)continue} else {fmt.Printf("批量写入失败:%v\n", err)}} else {fmt.Println("写入成功")// 如果成功就不需要循环了break}}
}// 消费消息
func readKafka(ctx context.Context) {reader = kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092"},Topic: topic, // 指定要消费的topicCommitInterval: 1 * time.Second, // 定期给kafka发生offest,判断消费到哪里了//GroupID: "rec_team_new", // 指定是哪一个消费组StartOffset: kafka.LastOffset, // 指定新来的消费者的消费位置(只针对新来的消费方有效)})//defer reader.Close()// 读消息属于是一直监听for {if message, err := reader.ReadMessage(ctx); err != nil {fmt.Printf("读kafka失败:%v\n", err)break} else {// 消息的内容有很多fmt.Printf("topic=%s,partition=%d,offset=%d,key=%s,value=%s\n", message.Topic, message.Partition, message.Offset, message.Key, message.Value)}}// 如果是kill会导致这个defer不会进行,就会导致reader不会关闭// 通常都是通过ctx进行监听
}// 监听消息
func listenSignal() {// 监听2和15可以确保进程结束之后,会做收尾工作// 都是终止程序,2就是ctrl+c 15则是系统管理员要求程序优雅推出c := make(chan os.Signal, 1)signal.Notify(c, syscall.SIGINT, syscall.SIGTERM)sig := <-cfmt.Println("接收到信号:", sig)if reader != nil {reader.Close()}os.Exit(0)
}func main() {ctx := context.Background()//writeKafka(ctx)go listenSignal()readKafka(ctx)
}
三.从客户端属性来梳理客户端工作机制
3.1 消费者分组消费机制
这里就是指每一个消费者都是属于一个消费者组,然后每个消费者消费不同的分区
可以看一下go语言实例代码:
reader = kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092"},Topic: topic, // 指定要消费的topicCommitInterval: 1 * time.Second, // 定期给kafka发生offest,判断消费到哪里了GroupID: "rec_team_new", // 指定是哪一个消费组StartOffset: kafka.LastOffset, // 指定新来的消费者的消费位置(只针对新来的消费方有效)})通过GroupID来确定对应的消费组,里面的消费者消费自己对应的partition。
消费者消费之后,需要提交消费记录,告诉kafka我已经消费了某些消息。
可以看到上述代码的这一段内容
CommitInterval: 1 * time.Second, // 定期给kafka发生offest,判断消费到哪里了
接下来就正式进入这个环节,来说说消费者组的机制:
首先看看kafka的设计理念:
- kafka默认只会让每个消费者组看到每条消息一次。
- kafka会记住每个GroupID对应的Topic的消费偏移量(offset),并从上次的offset开始消费。
在之前的代码中,会发现设置的有offset的位置,也就是后来的消费者都是从最后的offset开始消费,这样当然不能读出数据,需要你另外在写入数据的时候,他才可以监听到。
如果你想让这个新来的消费者可以读到消息,就需要改为kafka.FirstOffset,这样就可以读到之前并未消费的消息了,这一点是非常重要的。
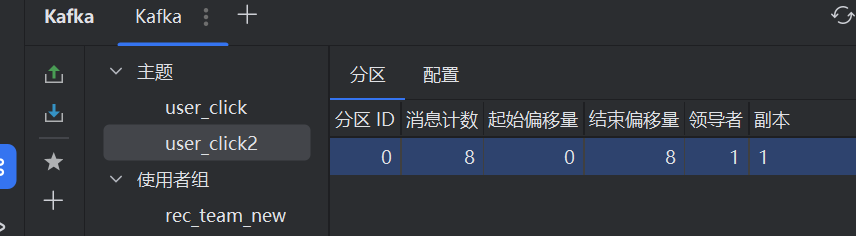
从这里就可以看到结束的偏移位置是8,所以当你在去读数据的时候,是没有的
这里有同学就会问了,为什么我没有加入消费者ID,就会重复读取消息呢?
本质上是kafka把这个当作了一个新的消费者,新的消费者会从头开始消费。
并且kafka设置如果没有消费者组ID,就不会帮你记录“你读到了哪里”
3.2 生产者拦截器机制
kafka的拦截器机制:是kafka提供的一种扩展点,可以让你的消息被序列化和发送到kafka之前进行一些自定义的处理:
- 增加/修改消息内容
- 记录日志
- 等
主要作用就是在发送请求和收到响应之后,能打印日志记录,方便查看。
在 confluent-kafka-go 的框架之下,并没有自带的拦截器,所以需要我们自己手动封装。
package mainimport ("context""log""time""github.com/segmentio/kafka-go"
)// 拦截器接口
type ProducerInterceptor interface {OnSend(message kafka.Message) *kafka.MessageOnAck(message kafka.Message, err error)
}// 示例拦截器:打印日志 + 添加时间戳
type LoggingInterceptor struct{}func (li *LoggingInterceptor) OnSend(msg kafka.Message) *kafka.Message {log.Printf("准备发送消息: %s\n", string(msg.Value))// 添加时间戳到 headermsg.Headers = append(msg.Headers, kafka.Header{Key: "sent_at",Value: []byte(time.Now().Format(time.RFC3339)),})return &msg
}func (li *LoggingInterceptor) OnAck(msg kafka.Message, err error) {if err != nil {log.Printf("消息发送失败: %v\n", err)} else {log.Printf("消息发送成功: %s\n", string(msg.Value))}
}// 包装发送函数,插入拦截器逻辑
func SendWithInterceptor(ctx context.Context, writer *kafka.Writer, msg kafka.Message, interceptor ProducerInterceptor) {// 拦截发送前处理modified := interceptor.OnSend(msg)if modified == nil {log.Println("消息被拦截器丢弃")return}// 真正发送err := writer.WriteMessages(ctx, *modified)// 拦截发送确认interceptor.OnAck(*modified, err)
}func main() {writer := &kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: "test-topic",Async: false, // 为了演示 onAck,需要同步发送}defer writer.Close()ctx := context.Background()// 创建拦截器interceptor := &LoggingInterceptor{}// 构造消息msg := kafka.Message{Key: []byte("user-id-1"),Value: []byte("你好,这是测试消息"),}// 发送带拦截器的消息SendWithInterceptor(ctx, writer, msg, interceptor)
}
3.3 消息序列化机制
总结就是一句话:在发送消息之前把数据变为字节流,在消费消息的时候,再把字节流转为原始数据
常见的序列化就是指json
比如常见的json序列化和放序列化函数:Marshal和Unmarshal
import ("context""encoding/json""github.com/segmentio/kafka-go"
)type User struct {ID int `json:"id"`Name string `json:"name"`Email string `json:"email"`
}func main() {writer := kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: "user-topic",}defer writer.Close()user := User{ID: 1, Name: "张三", Email: "zs@example.com"}// ✅ 序列化为 JSON 字节流data, err := json.Marshal(user)if err != nil {panic(err)}msg := kafka.Message{Key: []byte("user-1"),Value: data,}writer.WriteMessages(context.Background(), msg)
}
拿到这些数据之后在对其进行放序列化即可。
你可能会说,和一开始的案例的区别
kafka.Message{Key: []byte("1"),Value: []byte("大大怪将军"),
}对于这张,直接通过byte就转化为了字节流,打印的时候也不需要转化回来,直接打印就可以,因为它本身就是UTF-8编码的。
只有当我们传递的数据不是结构体的时候,就需要对其进行一个序列化,
json.Unmarshal(message.Value, &click)3.4 消息分区选择机制(重要)
消息分区选择机制:就是指一条消息最终会被写道Topic的哪一个分区上。
这个机制在文章开头简单说过,他对消息的顺序性,负载均衡,并发消费能力有非常大的影响。
接下来就来看看生产者的字段,以及如何设置
writer := &kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: topic, // 指定要生产的topicBalancer: &kafka.Hash{}, // 哈希解决要使用哪一个partitionWriteTimeout: 10 * time.Second, // 超时等待RequiredAcks: kafka.RequireNone, // (三种模式,就是关于ack的响应)AllowAutoTopicCreation: true, // 自动创建topic*(实际工作是false)
}主要看的就是Balancer字段,他就是选择的一个分区策略
接着就是取出的部分,也就是consumer选择取哪一个partition的消息
reader = kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092"},Topic: topic, // 指定要消费的topicPartition: 0,CommitInterval: 1 * time.Second, // 定期给kafka发生offest,判断消费到哪里了//GroupID: "rec_team_new", // 指定是哪一个消费组StartOffset: kafka.LastOffset, // 指定新来的消费者的消费位置(只针对新来的消费方有效)
})而有关partition的设置是根据kafka来设置的,并且设置好的分区,在后续只能增加,不能减少。
进一步来说说它的内容
其实主要要做的就是producer将消息放入Topic的哪一个partition里面,以及consumer要如何取对于partition里面的内容。
这里主要做的工作就是将partition和consumer进行绑定,以及万一消费者宕机了,又要如何重新建立等问题。
来看看它的分区机制
默认的分区机制:
- 如果指定了key:就会根据 分区 = hash(key)%分区总数 (来得到对应分区)
- 如果没有指定key:就采用轮询或者随机选择一个分区
kafka.Message{Key: []byte("1"),Value: []byte("大大怪将军"),
}当然你也可以直接就使用轮询的方式或者自定义的方式:
Balancer 类型 | 说明 |
| 默认使用 Key 进行哈希分区,保证 Key 有序性 |
| 轮询分区,不考虑 Key,适合无序批量写入 |
| 根据当前各分区负载动态路由,适合高吞吐 |
自定义 Balancer | 实现 |
3.5 生产者消息缓存机制
kafka生产者为了避免高并发消息对服务端造成过大的压力,每次发送消息时并不是一条一条往服务端发送,而是增加了一个高速缓存,将消息存入缓存,后续在批量发送。(这种缓存机制也是高并发时常用的机制)
首先看一下这个整体的流程:
kafka的消息缓存机制主要涉及两个关键组件:RecordAccumulator 和 sender
Kafka Producer Api → RecordAccumulator → Sender → Kafka Broker 其中:
- RecordAccumulator 是消息缓存的核心,用于临时缓存每个partition的消息(大小默认32M)
- kafka会在满足这些条件之后才会批量发送这些缓存的消息。
- Sender是一个线程,负责扫描RecordAccumulator,把满足的消息进行发送
- Dqueue就是一个双端队列的结构。
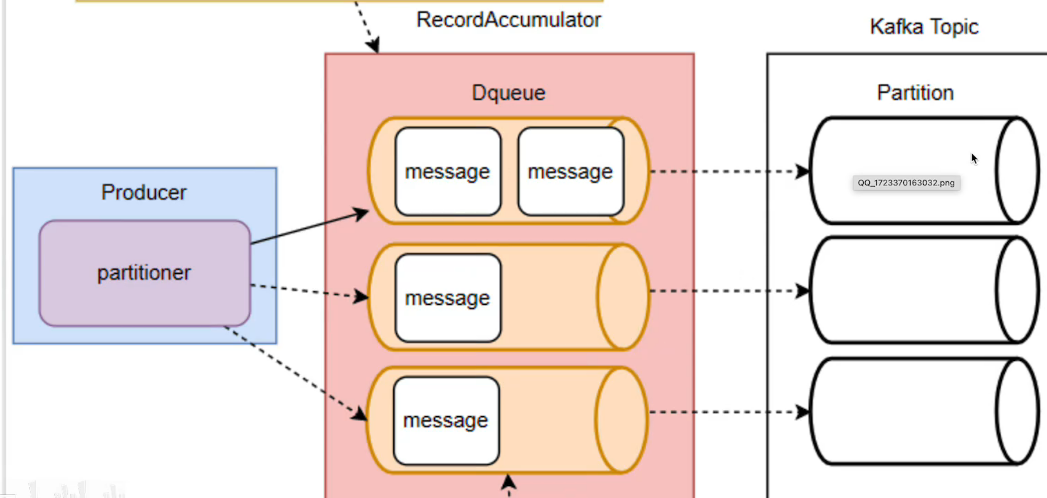
接着说一下sender
消息的发送实际上是靠的sender,拿到消息,放入Batches里面(拿消息就是message满足大小,默认是16KB,肯定也不会一直等待,可以设置定时拉取。)
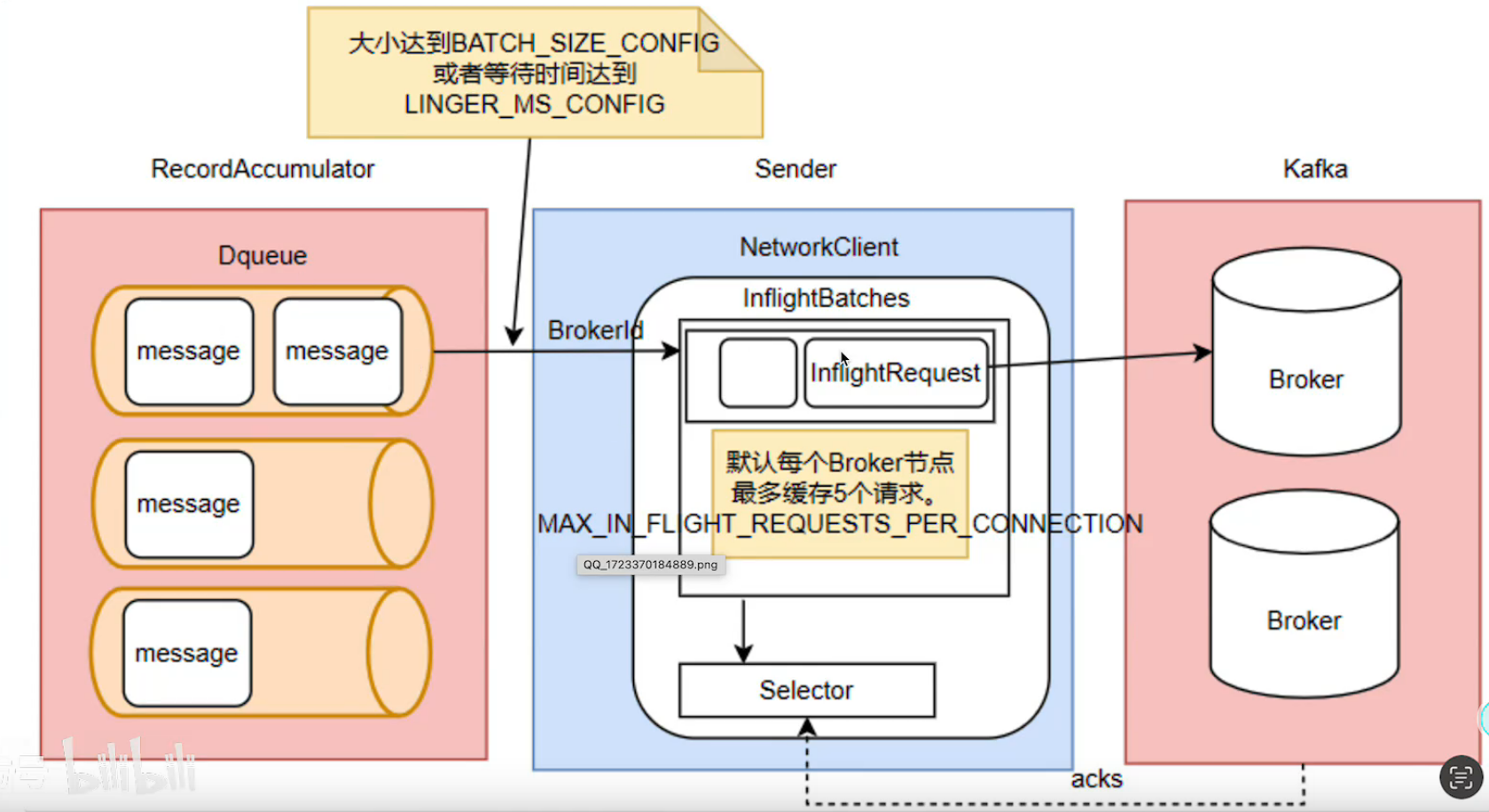
当然,也是可以通过三方库去实现这些相关的配置的
writer := &kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: topic, // 指定要生产的topicBalancer: &kafka.Hash{}, // 哈希解决要使用哪一个partitionWriteTimeout: 10 * time.Second, // 超时等待RequiredAcks: kafka.RequireNone, // (三种模式,就是关于ack的响应)AllowAutoTopicCreation: true, // 自动创建topic*(实际工作是false)BatchSize: 10, // 一批最多写 10 条BatchTimeout: 100 * time.Millisecond, // 如果不到10条,也在超时后发送
}这里需要知道,上述的大部分内容都是java kafka的客户端实现,而go语言 segmentio 的实现,并不是完全相同的,但是本质上是一致的。
Java Kafka Producer 中 | segmentio/kafka-go 中 |
|
|
| 组装好的 message slice |
| 背后起的 goroutine |
| 没有,用原生内存 |
3.6 发送应答机制(重要)
发送应答机制,就是关于一开始说的ack响应,这里深入的来说明一下这个机制。
它的作用是什么?----主要就是判断消息是否发送给了kafka
并且这个响应的选择是靠客户端决定的,而不是kafka
来看一下它的三种方式(之前也简单介绍过)
这里就来看一下整体的效果,对于这个ack响应,可以设置,分为很多种情况:
- 一种是你写入就可以,无需等消息队列的ack。
- 另外一种是只有leader返回ack,不管Follower是否拷贝成功。
- 最后一种就是全部成功再返回ack。
接着来看看go语言是如何实现的
writer := &kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: topic, // 指定要生产的topicBalancer: &kafka.Hash{}, // 哈希解决要使用哪一个partitionWriteTimeout: 10 * time.Second, // 超时等待RequiredAcks: kafka.RequireNone, // (三种模式,就是关于ack的响应)AllowAutoTopicCreation: true, // 自动创建topic*(实际工作是false)BatchSize: 10, // 一批最多写 10 条BatchTimeout: 100 * time.Millisecond, // 如果不到10条,也在超时后发送
}接下来看看它对应的参数:
配置 | 含义 | 性能 | 安全性 | 说明 |
| 不等待 Kafka 回复 | 高 | 低 | 可能丢消息 |
| 等待 Leader 写入 | 中 | 中 | 默认设置,推荐大多数业务使用 |
| Leader + 所有副本都确认 | 低 | 高 | 对可靠性要求高时使用(如金融场景) |
3.7 生产者消息幂等性
首先说一下它的概念:
消息幂等性:是指无论同一条消息发送一次还是多次,kafka最终只会保存一次这条消息。
为什么要考虑幂等性的问题?
这是因为在生产中,可能会出现消息重复写入。
举一个例子:像这种重试机制就可能导致消息重复写入。
for i := 0; i < 3; i++ {err := writer.WriteMessages(ctx, msg)if err == nil {break // 写入成功就退出}
}当你发送消息已经给了kafka,当时kafka没有返回响应,而此时的你接着发送消息给kafka,就会导致这个问题。
看一下kafka自带的幂等性
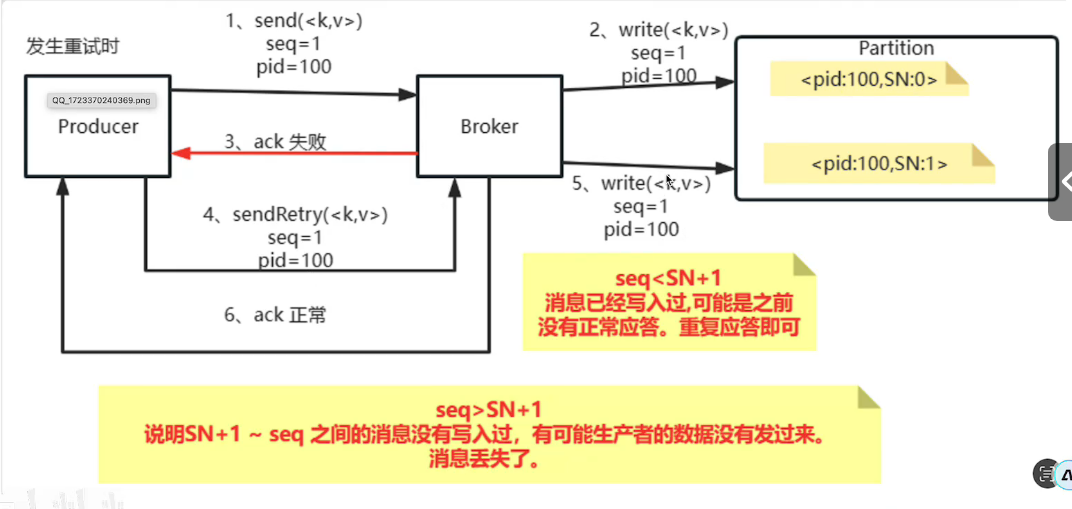
Kafka 的幂等性机制依赖于底层的 Producer ID(PID)、序列号(Seq No),如图所示
这个是它的流程:当broker写入到partition内,但是ack失败之后,他后续会重试,再次发送,会拿它的PID和SN比较,从而判断是不是已经写入过了。
接着说一下go语言中的幂等性实现
首先在go语言的这个库下,并没有自带的这个设置,需要我们自己手写。
主要有两种实现幂等的方法:
- 消息唯一键+下游去重
- 中间件/服务层做幂等缓存
消息唯一键就是指让每个消息都有唯一ID,如何在消费端进行去重(如mysql和redis,存入进行匹配)
而中间件的话就是在业务系统做一个kafka的消费中间件,加入一个幂等缓存层,用来处理(本质上还是一个唯一键,通过redis来处理)
如果真的要使用这些特性,可以使用 confluent-kafka-go
3.8 生产者消息压缩机制
压缩机制:是指在生产者发送消息是进行压缩
这样做的好处是:
- 减少网络传输量
- 减少磁盘空间占用
- 提高吞吐量
这样做也会带来一些CPU的开销
来看一下kafka支持的压缩算法
压缩方式 | 特点说明 |
| 不压缩(默认) |
| 通用压缩,压缩比高,速度较慢,比较常用 |
| Google 的算法,压缩速度快,适合高吞吐场景 |
| 压缩比高、解压快,Kafka 推荐使用 |
| Kafka 2.1+ 支持,压缩率高于 gzip,速度也快,现代场景推荐 |
这里要注意:kafka的压缩是“批量压缩”,而不是每条消息单独压缩,会先把一批消息聚合成一批,在对其进行压缩,在Borker落盘时也是压缩的状态,后续consumer拉取时再解压。
Go语言是如何设置的?
import ("github.com/segmentio/kafka-go""time"
)writer := kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: "test_topic",Balancer: &kafka.LeastBytes{},RequiredAcks: kafka.RequireAll,BatchSize: 100,BatchTimeout: 10 * time.Millisecond,//设置压缩算法Compression: kafka.Snappy, // 支持 None, Gzip, Snappy, Lz4, Zstd
}
再后续读的时候,是不需要解压操作的,读的时候他就已经被解压好了。
3.9 消息事务机制
Kafka 的消息事务机制(Transactional Messaging)是为了实现 “精确一次(Exactly-once)” 的语义 —— 在生产者端发送多个消息时,要么全部成功写入,要么全部失败,不写入任何消息,避免出现“部分写入”。
当然我们使用的这个segmentio/kafka-go也是不支持事务的。
confluent-kafka-go 这个库才支持:
这里的例子是gpt生成的,后续再做改进吧。
package mainimport ("fmt""log""github.com/confluentinc/confluent-kafka-go/kafka"
)func main() {// 初始化 Producer,开启幂等性和事务producer, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "localhost:9092","enable.idempotence": true,"transactional.id": "tx-producer-1",})if err != nil {log.Fatalf("Failed to create producer: %s", err)}defer producer.Close()// 初始化事务err = producer.InitTransactions(nil)if err != nil {log.Fatalf("InitTransactions error: %s", err)}// 开始事务err = producer.BeginTransaction()if err != nil {log.Fatalf("BeginTransaction error: %s", err)}// 准备发送两条消息topic := "order_topic"msgs := []*kafka.Message{{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Key: []byte("key1"), Value: []byte("message1")},{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Key: []byte("key2"), Value: []byte("message2")},}// 发送消息for _, msg := range msgs {err = producer.Produce(msg, nil)if err != nil {log.Printf("Failed to produce msg: %s", err)// 出错就回滚事务producer.AbortTransaction(nil)return}}// 成功则提交事务err = producer.CommitTransaction(nil)if err != nil {log.Fatalf("CommitTransaction failed: %s", err)}fmt.Println("Transaction committed successfully")
}四.补充
当我们在安装kafka的时候,在最新的4.0.0版本中和之前的版本稍有不同,它的不同在于没有使用 ZooKeeper 架构,而是使用的KRaft模式,要知道这点。
我在使用docker下载4.0.0版本之后呢,遇见了一些问题:(应该是新版本带来的问题)
他会缺少必要的配置,比如在KRaft模式下,需要明确指定节点的角色(broker或contoller),每个节点都需要唯一的整数ID。
由于是单节点使用,在单节点的Kafka KRaft集群中,该节点必须同时担任broker和controller两种角色,这是KRaft模式的基本要求
原因说明:KRaft模式下的重要变化
1. 不再依赖 ZooKeeper
Kafka 元数据(如 Topic、Broker 状态、ACL 等)不再托管在 ZooKeeper 中,而是由 Kafka 自身的 Raft 日志进行管理,极大简化了部署架构。
2. 明确的角色划分(Broker 与 Controller)
在 KRaft 模式下,每个 Kafka 节点都必须指定其角色:
broker:负责消息存储、读写、分区管理等传统功能;controller:负责集群级别的元数据管理,如:
- 分区副本选主(leader election)
- Topic 创建、删除
- ISR 列表管理
- 集群健康状态监控等
3. 节点 ID 要求
每个 Kafka 节点必须拥有:
- 唯一的
node.id(整数); - 角色标识:可以是 broker、controller 或两者(通常为单节点部署,两者必须同时拥有)
在使用docker这一方面上,对于这些指令或者问题不了解,可以直接问ai就行,关键是要知道为什么不可以这样,以及如何解决这些问题。
1.4.1 controller
Kafka 中的 Controller 是集群核心的管理组件。在 KRaft 模式下,Controller 由 Kafka 内部通过 Raft 协议实现(称为 KRaft Controller),其主要职责包括:
- 维护集群元数据(Topic、分区、副本、ACL 等);
- 协调分区副本和 leader 的选举;
- 追踪 broker 节点的存活状态;
- 通过 Kafka 内置的 Raft 共识算法实现高可用、强一致的元数据操作。
KRaft Controller 的引入,使 Kafka 集群在没有 ZooKeeper 的情况下,依然能保持一致性强、容灾能力高、架构简洁,这是 Kafka 向“自管理集群”演进的重要一步。