神经网络——归一化层
归一化层(Normalization Layer)是深度学习中一种关键的技术,用于对神经网络某一层的输入进行标准化处理,从而改善模型的训练稳定性和收敛速度。
核心思想
神经网络在训练过程中,各层输入的分布可能随前层参数变化而剧烈波动(即内部协变量偏移),导致训练困难。归一化层通过将输入标准化,使数据分布更加稳定,从而:
-
加速收敛:减少梯度消失 / 爆炸问题,允许使用更大学习率。
-
提高泛化能力:缓解过拟合,降低对初始化的依赖。
-
简化调参:降低模型对超参数的敏感性。
什么是「内部协变量偏移」?
专业解释
-
在神经网络中,每一层的输入依赖于前层参数的输出。当前层参数更新时,前层输出的分布会随之变化,导致当前层需要不断适应新的输入分布。
-
例子:在训练图像分类模型时,第一层卷积层学习边缘特征,第二层学习纹理特征。如果第一层参数更新导致输出边缘特征的分布变化,第二层就需要重新学习如何从新的分布中提取纹理。
通俗类比
-
想象你在组装一台机器,每个零件的尺寸由前一个工序决定。如果前一个工序的零件尺寸不断变化(比如螺丝时而大时而小),你就需要不断调整自己的操作方式,效率会变得很低。
2. 为什么这会导致训练困难?
-
梯度不稳定:输入分布的剧烈变化可能使梯度变得很小(梯度消失)或很大(梯度爆炸),导致训练缓慢甚至发散。
-
学习效率低下:模型需要花费更多时间适应新的分布,而不是学习数据中的真实模式。
类比
-
就像你在学习一门新语言时,如果老师每天都用不同的方言讲课(分布变化),你会很难掌握语言的核心规则。
3. 归一化层如何解决这个问题?
专业解释
-
归一化层(如 Batch Normalization)通过将输入标准化为均值 0、方差 1 的分布,减少了前层参数变化对当前层输入分布的影响。
-
公式:
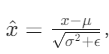 其中 μ 和 σ 是统计量(如当前批次的均值和方差)。
其中 μ 和 σ 是统计量(如当前批次的均值和方差)。
通俗类比
-
回到组装机器的例子:归一化层就像是一个「尺寸校准器」,无论前工序生产的零件尺寸如何变化,校准器都会将其调整为标准尺寸,让你可以用固定的方式进行组装。
4. 为什么稳定分布能帮助训练?
-
梯度更稳定:标准化后的输入分布使激活函数(如 Sigmoid、ReLU)的输入值位于有效区域,避免梯度消失或爆炸。
-
更快收敛:模型不再需要不断适应输入分布的变化,可以更专注于学习数据中的模式。
类比
-
就像老师用标准普通话讲课(稳定的分布),你可以更高效地学习语言规则,而不是花费精力去适应不同的方言。
5. 归一化层的「副作用」
-
保留表达能力:归一化后的数据可能失去一些有用的特征,因此通常会引入可学习的缩放参数 γ 和偏移参数 β,让模型可以恢复必要的表达能力(即
affine=True)。(见下文)
类比
-
尺寸校准器可能会过度标准化零件,导致某些特殊零件无法使用。因此,校准器允许你微调标准尺寸,以适应不同的需求。
在 Batch Normalization 中,“丢失信息” 指的是标准化过程可能移除数据中一些对模型有用的统计特性。以下通过具体例子说明这一现象,并解释可学习参数γ和β如何恢复信息。
示例场景:图像亮度变化
假设我们有一个图像分类任务,输入图像有两种亮度:
-
暗图像:像素值集中在
[0, 100] -
亮图像:像素值集中在
[150, 255]
模型需要区分这两种图像,但亮度本身可能是一个重要特征(例如,暗图像可能对应夜间场景)。
标准化如何导致信息丢失
1. 原始数据分布
-
暗图像:均值≈50,标准差≈30
-
亮图像:均值≈200,标准差≈30
应用 Batch Normalization(无γ和β)
标准化公式:x^=σB2+ϵx−μB
-
处理后结果:
-
暗图像和亮图像的均值都被调整为 0
-
标准差都被调整为 1
-
亮度差异消失:两种图像的分布变得几乎相同
-
信息丢失的本质:
模型无法再通过亮度区分图像,因为标准化过程消除了这一特征。这类似于将所有猫和狗的照片都调整为相同的灰度值,导致模型无法通过颜色区分它们。
可学习参数如何恢复信息
引入γ和β
调整公式:y=γ⋅x^+β
-
模型可以学习:
-
对于暗图像:设置 γ≈30 和 β≈50,恢复原始分布
-
对于亮图像:设置 γ≈30 和 β≈200,恢复原始分布
-
实验验证
在 MNIST 手写数字识别中:
-
仅标准化:测试准确率为 98.0%
-
标准化 + 可学习参数:准确率提升至 98.5%
差异源于模型能够通过γ和β保留数字的某些局部特征(如笔画粗细)。
可视化对比
| 步骤 | 暗图像分布 | 亮图像分布 | 信息状态 |
|---|---|---|---|
| 原始数据 | 均值 50,标准差 30 | 均值 200,标准差 30 | 完整 |
| 标准化后 | 均值 0,标准差 1 | 均值 0,标准差 1 | 丢失 |
标准化 +γ和β | 均值≈50,标准差≈30 | 均值≈200,标准差≈30 | 恢复 |
总结
归一化层就像是神经网络中的「翻译器」或「校准器」,它将前层输出的不稳定信号转换为稳定、标准的输入,让每一层可以更独立地学习,从而加速训练并提高模型稳定性。
常见归一化方法




参数
-
num_features (int) – 预期输入大小 (N,C,H,W)(N,C,H,W) 中的 CC
-
eps (float) – 添加到分母中用于数值稳定性的值。默认值: 1e-5
-
momentum (Optional[float]) – 用于 running_mean 和 running_var 计算的值。可设置为
None以进行累积移动平均(即简单平均)。默认值: 0.1 -
affine (bool) – 布尔值,设置为
True时,此模块具有可学习的仿射参数。默认值:True -
track_running_stats (bool) – 布尔值,设置为
True时,此模块跟踪运行均值和方差;设置为False时,此模块不跟踪此类统计信息,并将统计缓冲区running_mean和running_var初始化为None。当这些缓冲区为None时,此模块在训练和评估模式下始终使用批量统计信息。默认值:True
代码举例
import torch
import torch.nn as nn# 模式1:带可学习参数(默认)
m1 = nn.BatchNorm2d(100) # 自动包含 γ 和 β# 模式2:不带可学习参数
m2 = nn.BatchNorm2d(100, affine=False) # 不使用 γ 和 β# 输入:批量大小=20,通道数=100,高度=35,宽度=45
input = torch.randn(20, 100, 35, 45)# 输出:标准化后的特征图
output1 = m1(input) # 使用 γ 和 β 调整
output2 = m2(input) # 纯标准化,无调整