SmartETL循环流程的设计与应用
1. 引言
**检索增强生成(RAG)**是指通过检索对大模型生成进行增强的技术,通过充分利用信息检索(尤其是语义检索)相关技术,实现大模型快速扩展最新知识、有效减少幻觉的能力。主流RAG框架包括问题理解、知识检索、知识选择/重排、答案生成等几个过程,并且通常来说这几个步骤是顺序执行的(pipeline),如下图(图片引用自https://medium.com/@mayssamayel4/building-a-rag-system-with-gpt-4-a-step-by-step-guide-291711342f0d)所示:
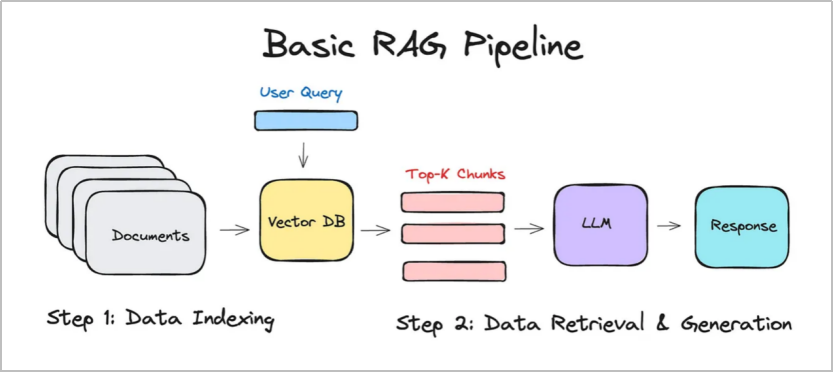
继RAG之后,研究人员提出了DeepSearch技术,主要是针对RAG的单轮串行流程可能无法进行准确回答的问题,提出通过多轮的问题扩展、检索、上下文判别的方式,实现对问题更加完整、准确的回答。DeepSearch流程不是顺序的pipeline,而是循环流程,如下图(图片引用自https://milvus.io/zh/blog/introduce-deepsearcher-a-local-open-source-deep-research.md)所示。
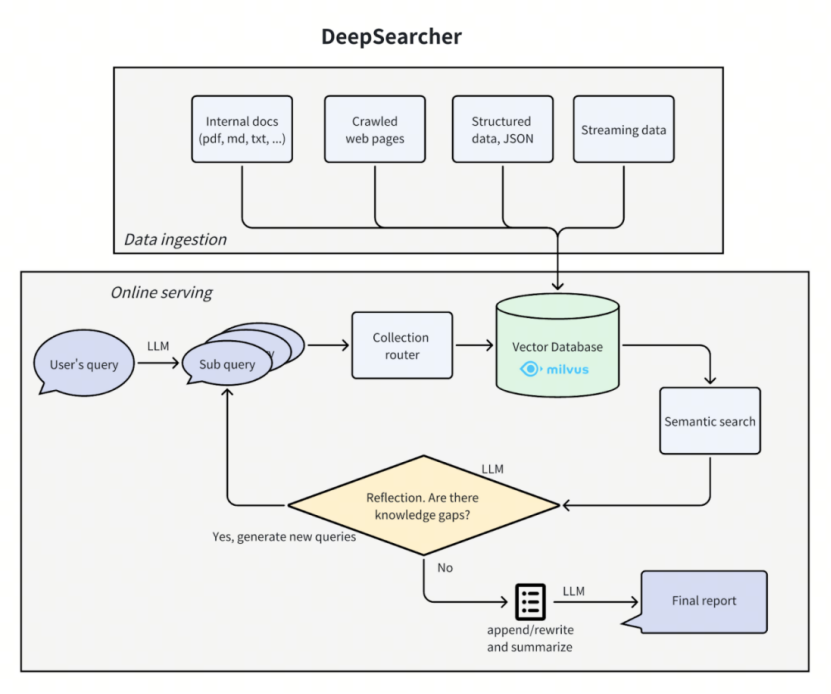
循环流程是指包含重复执行环节的流程。通常来说,普通的数据处理——也就是常见的ETL任务——都是线性流程,包括读取、转换、过滤、抽取、入库等流程节点,他们按照业务要求组合成完整流程,每条数据像水流一样按照顺序“流”经每一个节点。循环流程则能够基于指定的循环是否终止的判定,对指定的子流程进行重复执行。
SmartETL框架作为一个ETL框架,此前未考虑循环流程。DeepSearch的流程虽然通常是用于问答助手这类应用,但其实也可以用于实现基于大模型的数据处理,例如数据集构造、大模型蒸馏等。因此有必要在框架中增加循环流程的流程控制逻辑。
2.循环流程控制设计
新设计一个特殊的processor组件,命名为While,将可能循环的子流程(对应代码中的循环体)交给While组件托管,在所给定的条件(匹配或过滤节点)符合时执行子流程。
While组件的构造参数包括:
- 循环子流程,是另一个
Process组件,通常为Chain串联的一套流程 - 匹配条件,一个函数或函数式对象(实现了
__call__方法的类的对象),或者提供一个字段名,如果这个字段的值不为空,表示条件满足 - 最大迭代次数,避免进入死循环,且方便评估和控制流程的整体时延。
While组件重写了__process__方法,这是实现流程循环的关键。简单地说,在每一次迭代中,对每一条输入数据,检查匹配条件是否满足,如果满足则执行指定的子流程,并收集子流程的输出数据作为当前迭代的输出数据(子流程可能产生多条输出,比如包含Flat操作)。如果匹配条件不满足,需要注意,这里要将上一次迭代的输出数据(或整个While循环的输入)作为整个While循环的输出,以确保符合循环流程的逻辑。
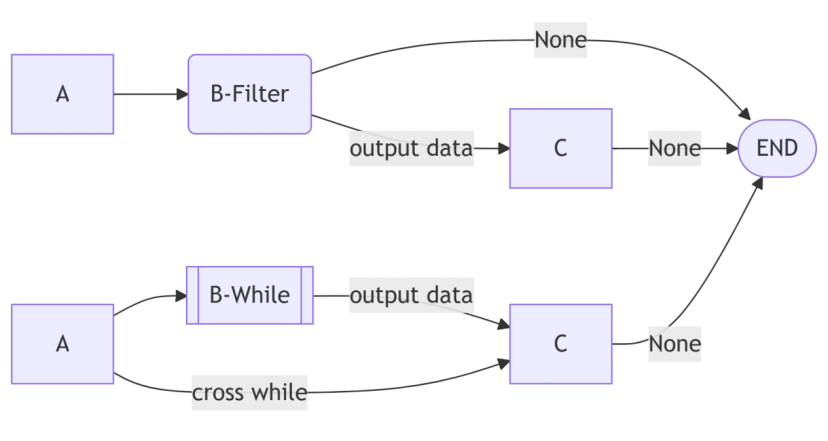
下图是一个对比普通过滤节点与循环节点的示意图,流程均为Chain(A, B, C)。在上半部分,数据通过节点B(普通节点或过滤节点)时,如果输出为None(即没有输出),则当前处理流程结束,否则数据传输给节点C。在下半部分中,B节点是一个循环节点,如果循环条件不满足,则数据直接传输给节点C,否则将B的子流程的输出数据传输给节点C。
3.DeepSearch应用
DeepSearch应用的处理过程可以看成一种对输入问题进行循环处理,最终输出问题答案的数据处理流程。利用循环流程机制,SmartETL可以实现DeepSearch应用,下面介绍这个流程是如何设计的。
首先,需要设计一种数据结构,对DeepSearch的各个阶段的状态进行统一表示。因为ETL框架与普通的编程语言或运行时环境不一样,ETL流程是以数据为驱动的,每个节点除了自身的配置信息(也称为组件的环境信息)和当前处理数据以外,通常无法获得全局信息。SmartETL也在考虑加入某种获取全局信息的机制。数据结构设计如下:
{“original_query”: “user query”, //原始查询“gap_queries”: [“query1”, “query2”], //当前的差距查询列表 最初由原始查询提示生成,后续通过提示大模型基于original_query、all_sub_queries和all_chunks生成“chunks”: [{“text”: “doc1”}], //当前查询的检索结果文档列表 基于当前gap_queries语义化检索得到“all_chunks”: [{“text”: “doc1”}, {“text”: “doc2”}], //当前已收集的全部相关文档 持续合并chunks相关的得到“all_sub_queries”: [“sub1”, “sub2”], //当前全部子查询 不断合并gap_queries得到“answer”: “xxxx” //最终答案 通过original_query、all_sub_queries和all_chunks提示给大模型进行生成
}
第二,流程设计。将整个流程划分为3个阶段,如下图所示:
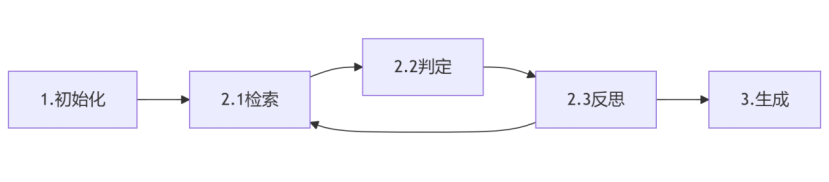
阶段1:初始化阶段,初始化all_chunks、all_sub_queries字段为空列表,并通过提示大模型生成最初的gap_queries。
阶段2:循环流程阶段,包括检索、判定、反思3个具体过程。检索过程对当前gap_queries进行向量化并检索,获得一批候选文档chunks。判定过程对当前候选文档进行相关性判定,相关的文档会合并到all_chunks中。反思过程是基于当前的original_query、all_sub_queries和all_chunks,提示大模型进行推理思考,确定是否还需要进一步搜索,得到的结果作为新的gap_queries字段,但为了保存全部子查询,这里在生成新的gap_queries之前,将gap_queries合并到all_sub_queries中。
阶段3:基于当前的original_query、all_sub_queries和all_chunks,提示大模型进行答案生成。虽然阶段2可以执行多次以尽量获得答案,但是也必须有限制,在达到迭代次数限制或Token超限之后,尽管没有获得完全足够的上下文信息,也需要让大模型进行生成,避免输出空的答案。
第三,流程yaml文件编写。基于已有的数据结构和流程设计,整个流程实现已经变得较为容易了。
不过存在一个问题:在阶段2中,需要多次对批量数据进行处理,包括对gap_queries进行向量化、基于向量化结果进行检索、对检索结果进行相干性判定。SmartETL框架已有的向量化、大模型调用等组件的设计不支持批量处理,并且这里需要进行逻辑对应,需要逐个gap_query进行向量化、检索相关文档,然后对结果文档逐个进行相关性判定,过滤掉不相关文档,最后把对应同一个原始查询的结果进行聚合,以便在阶段3进行答案生成。为了实现这个目的,在不增加批量处理算子的情况下,通过扁平化(Flat)、聚合(Group by)、分组收集操作,实现批处理。修改后的数据结果如下所示:
{“original_query”: “user query”, //原始查询“gap_queries”: [“query1”, “query2”], //当前的差距查询列表 最初由原始查询提示生成,后续通过提示大模型基于original_query、all_sub_queries和all_chunks生成“all_chunks”: [{“text”: “doc1”}, {“text”: “doc2”}], //当前已收集的全部相关文档 持续合并chunks相关的得到“all_sub_queries”: [“sub1”, “sub2”], //当前全部子查询 不断合并gap_queries得到“answer”: “xxxx”, //最终答案 通过original_query、all_sub_queries和all_chunks提示给大模型进行生成“sub_query”: “sub1”, //当前的一个子查询“sub_query_vector”: [0.5, 0.3, .... ], //当前子查询对应向量 基于sub_query向量化“chunks”: [{“text”: “doc1”}], //当前子查询的检索结果文档列表 基于sub_query_vector的语义检索“chunk”: {“text”: “doc1”}, //当前的一篇文档“selected”: true, //当前文档是否与问题相关 基于提示大模型进行相关性判定“chunks_selected”: [{“text”: “doc2”}] //当前检索结果中相关的文档
}
4.总结
本文面向DeepSearch应用的迭代处理需求,基于SmartETL框架设计了循环流程控制,使得支持部分子流程的循环处理。通过设计DeepSearch流程,验证了循环流程的有效性,并为其他具有循环结构的数据处理流程提供了参考。
附录
SmartETL项目地址:https://github.com/ictchenbo/SmartETL- 循环流程控制节点代码:https://github.com/ictchenbo/SmartETL/blob/main/wikidata_filter/iterator/flow_control.py
- 基于
SmartETL的DeepSearch应用流程:https://github.com/ictchenbo/SmartETL/blob/main/flows/agent/deepsearch-v2.yaml - 实现DeepSearch应用的所有大模型提示模板可以在这里找到:https://github.com/ictchenbo/SmartETL/blob/main/config/prompt/deepsearch
- Jina-DeepSearch实施指南:https://jina.ai/news/a-practical-guide-to-implementing-deepsearch-deepresearch/