cs336 Lecture2
Memory accounting
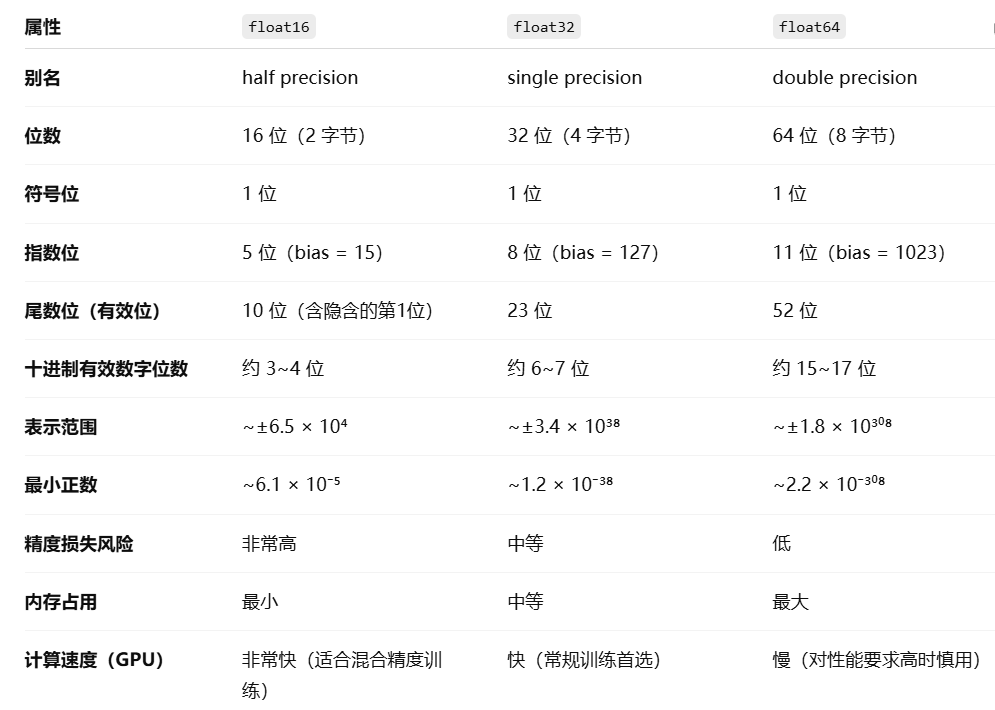
Tensor的内存占用取决于元素的个数以及每个元素的类别
example:
x = torch.zeros(4, 8)
assert x.dtype == torch.float32
assert x.size == torch.Size([4, 8])
assert x.numel() == 32
assert x.element_size() == 4 #float32 is 4 bytes
assert memory_usage(x) == 4 * 8 * 4
Float16在训练过程中由于精度较低的问题,容易出现overflow,underflow。
x = torch.tensor([1e-8], dtype=torch.float16)
assert x == 0 # underflow
为了解决这个问题,开发了bfloat16。
它具有和float32相同的动态范围,但是相应的,精度由小数部分决定,会更差,但是对ML来说不是很重要。
compute
Tensor在pytorch中实际上是指向已分配内存的一些指针。更具体的来说,Tensor是一个高级对象,包含数据指针和一些元数据(shape,dytpe,stride等)
张量的连续性(contiguity)
一个张量是“连续的”,意味着它的内存布局是按行优先(row-major)线性排布的。
例如,下面是一个连续张量的内存排布:
tensor([[1, 2, 3],[4, 5, 6]]) 实际内存:[1,2,3,4,5,6]
转置后:内存就不连续了,访问每一个列就要跳着都内存
tensor([[1, 4],[2, 5],[3, 6]]) 虽然形状变了,内存并没有被复制,而是通过stride来模拟行列互换
print(a.is_contiguous()) True
print(b.is_contiguous()) False
也就是说转置本质上不会复制数据,只是交换stride步长信息。它们共享同一块底层内存。
用 .contiguous():将非连续张量变为连续的。
b_contig = b.contiguous()
print(b_contig.is_contiguous()) True
这将会复制数据,让它在内存中线性存储。
对不连续的张量进行视图操作的话是行不通的。
这种情况下因为进行连续操作,所以二者不共享内存。
y = x.transpose(1, 0).contiguous().view(2, 3)
assert not same_storage(x, y)
张量操作的计算成本
FLOPs: 浮点数操作(已完成的计算量)
TearFLOP/s:每秒万亿次浮点运算能力,是衡量计算设备(如 GPU、TPU)计算能力的单位。
Intuitions: GPT-3 took 3.14e23 FLOPs、GPT-4 is speculated to take 2e25FLOPs
Linear model
一般的经验法则来说,矩阵相乘的浮点运算为维度的乘积的2倍。
前向传播的计算量是参数数量的2倍,反向传播的计算量是参数数量的4倍。总的计算量就是6倍。
import torchB = 16384
D = 32768
K = 8192
device = torch.device('cuda')x = torch.randn(B, D, device=device)
w = torch.randn(D, K, device=device)
y = torch.matmul(x, w)
actual_num_flops = B * D * K * 2通常来说,所有的运算都不如较大的矩阵运算耗时大,所以很多粗略计算非常简单,我们只需关注模型的矩阵乘法。
Model
模型参数在pytorch中被存储为nn.Parameter对象