BEVformer个人理解与解读
BEVformer个人理解与解读
- 1、背景
- 1.1、视觉BEV感知
- 2、Method/Strategy——BEVFormer
- 2.1、Overall Architecture
- 2.2、BEV Queries
- 2.3、SCA: Spatial cross-attention
- 2.4、 TSA: Temporal self-attention
- 补充:
- 参考:
1、背景
1.1、视觉BEV感知
在介绍BEVformer之前首先先大致了解一下为什么要使用BEV进行视觉感知,其实原因就在于相机图像是经过相机成像模型 (针孔、鱼眼成像模型) 后会将距离信息赋1,也可以理解为丢失了距离信息。但是车辆行驶是出于3D的世界,因此丢失距离信息的图像是缺乏空间理解力的,这就和一部分驾驶新手一样,对周围情况完全没有感知。
此外相应的问题也会出现在相机多视角融合的过程中:
在每个相机上进行目标检测,然后对目标进行跨相机融合。如2021 TESLA AI Day给出的图1,带拖挂的卡车分布在多个相机感知野内,在这种场景下试图通过目标检测和融合来真实地描述卡车在真实世界中的姿态,存在非常大的挑战。

为了解决这些问题,很多公司采用硬件补充深度感知能力,如引入毫米波雷达或激光雷达与相机结合,辅助相机把图像平面感知结果转换到自车所在的3D世界,描述这个3D世界的专业术语叫做BEV map或BEV features(鸟瞰图或鸟瞰图特征),如果忽略高程信息,就把拍扁后的自车坐标系叫做BEV坐标系(即鸟瞰俯视图坐标系)。
而传统获取BEV map/features基本是基于相机内外参以及平行平面假设进行,也即IPM(逆投影变换) 算法。但是传统算法存在一定缺陷,首先就是其与相机内外参有着强关联,因此在面对多视角的时候易受到环境变化导致相机外参的变化从而导致多视角的拼接融合出现一定问题。其次就是传统算法是基于平行平面假设进行的,因此如果遇到上下坡情况,则需要在上下坡的部分新加入坡度补偿,因此在此阶段也易引入误差。
2、Method/Strategy——BEVFormer
2.1、Overall Architecture
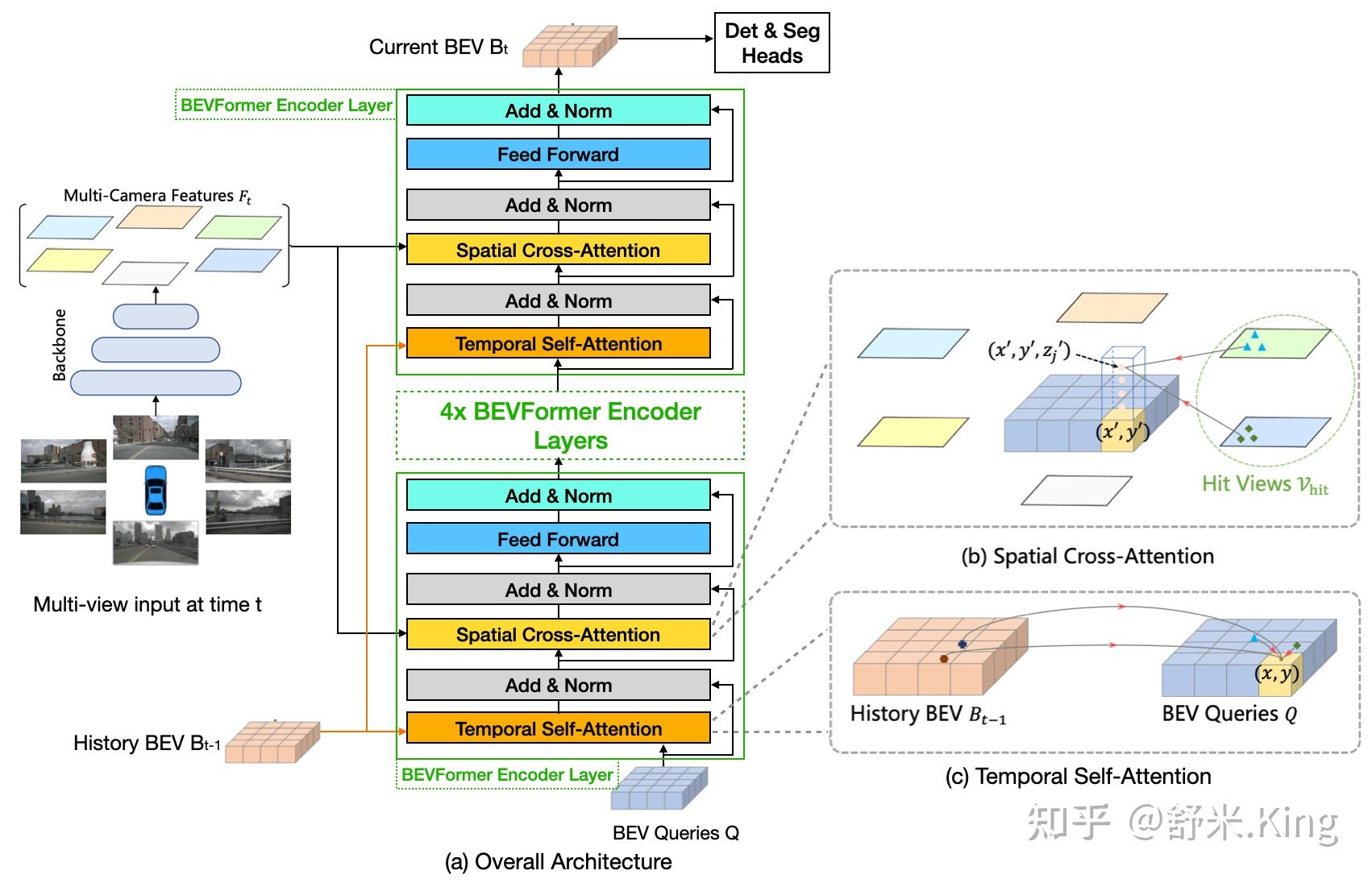
如下图2所示:
- BEVFormer主体部分有6层结构相同的BEVFormer encoder layers(以encoder表示),每一层都是由以attention(transformer) 组成的modules(TSA+SCA),再加上FF、Add和Norm组成。。
- encoder结构中有3个特别的设计:BEV Queries, Spatial Cross-attention(SCA)和Temporal Self-attention(TSA)。
- 其中BEV Queries是栅格形可学习参数,承载着通过attention机制在multi-camera views中查询、聚合的features。
- SCA和TSA是以BEV Queries作为输入的注意力层,负责实施查询、聚合空间features(来自multi-camera images)和时间features(来自历史BEV)的过程。
而BEVformer的前向推理过程大致为:
- 在t时刻,输入车上多个视角相机的图像到backbone,输出各图像的多尺度特征(multi-scale features):Ft={Fti}i=1NviewF_t = \{F_t^i\}_{i=1}^{N_{view}}Ft={Fti}i=1Nview ,其中FtiF_t^ iFti是第i个视角相机的feature, 是多个相机视角的总数。同时,还要保留t-1时刻的BEV Features Bt−1B_{t-1}Bt−1 。
- 在每个Encoder layer中,首先用BEV Queries Q通过TSA模块从 Bt−1B_{t-1}Bt−1中查询并融合时域信息(the temporal information),得到修正后的BEV QueriesQ′Q'Q′
- 然后在同一个Encoder layer中,对TSA“修证”过的BEV Queries Q′Q'Q′,通过SCA模块从multi-camera features 查询并融合空域信息(spatial information),得到进一步修正的BEV Queries Q′′Q''Q′′ 。
- 这一层encoder layer把经过两次修正的BEV features (也可以叫做BEV Queries)进行FF计算,然后输出,作为下一个encoder layer的输入。
- 如此堆叠6层,即经过6轮微调,t时刻的统一BEV features BtB_tBt就生成了。
- 最后,以BEV Features BtB_tBt作为输入,3D detection head和map segmentation head预测感知结果,例如3D bounding boxes和semantic map。
2.2、BEV Queries
BEV Queries是预定义的一组栅格化高维特征向量空间,也可以如博客1理解成可学习的栅格化参数,但是此处需要注意,在Queries在学习完后就变成了BEV features了,也即捕获了围绕车身的BEV特征。,因此学习完的Queries是对应实际物理空间的特征。其定义为Q∈RH×W×CQ \in R^{H\times W\times C}Q∈RH×W×C。这里可以理解为在学习完后将历史帧以及多视角图像经过提取(聚合)后就得到了最终的BEV feature。
BEV Queries的H、W与BEV平面在x、y方向的栅格尺寸定义一致,根据多篇博客的说法说此处的H、W具有与BEV平面类似的特性,也就是直观的映射车辆周围的空间。我个人觉得这个逻辑关系说不通,但是从博客2中有关于Deformable Attention的解读,H、W确实与BEV平面存在显性的关系,因为可变形注意力由局部注意力代替了全局注意力,因此此处的话H、W就必须与BEV平面存在显性关联,但是C维根据博客2的代码解读显示应该是256,其既不对应lift的D+C维也不对应实际的物理空间。
另有位于p=(x,y)p=(x,y)p=(x,y)处的某个query Qp∈R1×CQ_p \in R^{1\times C}Qp∈R1×C,表示BEV queries中的一个栅格。在输入到BEVFormer之前,要给BEV Queries加上了可学习的位置编码(learnable positional embedding)了。而这个位置编码根据博客2所言应该是为了解决前后时刻由于前后时刻车自身是不断运动以及车周围的物体也在一定范围内运动导致的BEV特征不对齐的情况。
2.3、SCA: Spatial cross-attention
如图2(b)所示,作者设计了一种空间交叉注意力机制,使 BEV queries 从多个相机的image Features中提取所需信息并转换为BEV Features。
每个BEV栅格的query在image features的哪些范围提取信息呢?这里有3个方案:
- 从image features的所有点上提取信息,即global attention。
- 从BEV栅格在image features的投影点上提取信息。
- 从BEV栅格在image features的投影点及其周围取信息,即deformable attention。
在这里第一条就是原始的attetion机制,其计算开销非常大,第二条非常依赖相机内外参,而且回到了视觉SLAM的领域了,因此也不关注投影点周围信息,这样于做目标检测不利。
而方案三就是作者选择的方案,也是论文的重要创新点之一:BEV中的每个cell,都可以求出对应世界坐标系下的二维坐标,这个二维坐标作者给了一组z,这个z是作者预先定义的。这样每个cell都对应了一组世界坐标系下的三维坐标。你知道相机模型的话,就可以很容易把这组三维坐标投影到左侧像素坐标系下,再就可以对应到左侧那几个feature map下的位置了。当然它只会对应到左侧特定的一个或者两个特征图。这么一来,Q向量完全不用去做globle attention,它只需要和特定几个地方的特征去做attention就行了,这样一来就大大减少了计算量。具体他用到了deformable attention。这样就生成了这个cell中新的特征,这个特征会更好。3这样在进行BEV Que的特征提取时,就只需要与特定视角的image fea进行交互(一开始就提到了是多个视角)。同样这样也在一定程度上降低了对内外参的高精度依赖(具体在TSA模块有一个对齐,以及这是网格化特征提取,因此不需要点对点对的完全对齐)

公式二是SCA模块的公式,其中Qp、P(p,i,j)、FtiQ_p、P(p,i,j)、F_t^iQp、P(p,i,j)、Fti分别表示query, reference points和 输入特征。
通俗理解公式:在BEV Query对应的图像2D features 有效区域附近计算注意力,把图像2D features加权融合到BEV Query作为SCA的输出。
参考图(b)和上述公式2,总结Spatial cross-attention的实现方式:
- 对于每一个位于(x,y)(x,y)(x,y)位置的 BEV query QpQ_pQp,计算其对应真实世界的坐标 (x′,y′)(x',y')(x′,y′)。然后将 BEV query 在z方向进行 lift 操作4,设置 NrefN_{ref}Nref 个 3D参考点,即对应NrefN_{ref}Nref 个世界坐标系下的3D空间参考点。
- 通过相机内外参,把第j个3D参考点投影到vhitv_{hit}vhit个相机图像上。受相机感知范围限制,每个3D参考点一般只在 1-2 个相机上找到有效的投影点(反过来描述,每个相机的features只与部分BEV queries构成有效投影关系)。
- 投影的2D点只能落在某些视图上,而其他视图则没有。所以,将命中视图称为VhitV_{hit}Vhit。之后,我们将这些2D点视为查询QpQ_pQp的参考点并围绕这些参考点从命中视图VhitV_{hit}Vhit中采样特征(这里为什么要做采样是因为直接将3D投影到2D会有误差5),得到sampled features。
- 最后,对Vhit、NrefV_{hit}、N_{ref}Vhit、Nref个sampled features进行加权求和,作为spatial cross-attention的输出来更新BEV query,从而完成 spatial 空间的特征聚合。
其中关于如何计算(x’,y’)是基于论文给出的公式6:
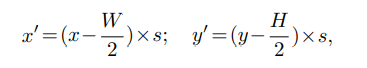
其中,H,W是BEV查询的空间形状,s是BEV网格的分辨率大小,(x’,y’)是以自车位置为原点的坐标
计算第j个3D参考点投影到第i个相机图像上的2D参考点坐标6:
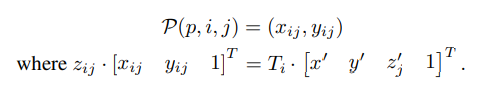
这里,P(p,i,j)是从第j个3D点(x’,y’,zj’)得来的的第i个视图上的2D点,Ti是第i个相机的已知投影矩阵。
2.4、 TSA: Temporal self-attention
时间信息对于视觉系统理解周围环境也很重要。例如,在没有时间线索的情况下,从静态图像中推断运动物体的速度或检测高遮挡物体是很有挑战性的。为解决这个问题,作者设计了时间自我注意,它可以通过结合历史BEV特征来表示当前环境。
从经典 RNN 网络获得启发,将 BEV 特征Bt视为能够传递序列信息的 memory。每一时刻生成的 BEV 特征Bt都从上一时刻的 BEV 特征Bt-1获取所需的时序信息,这样能保证动态地获取所需的时序特征,而非像堆叠不同时刻 BEV 特征那样只能获取定长的时序信息。
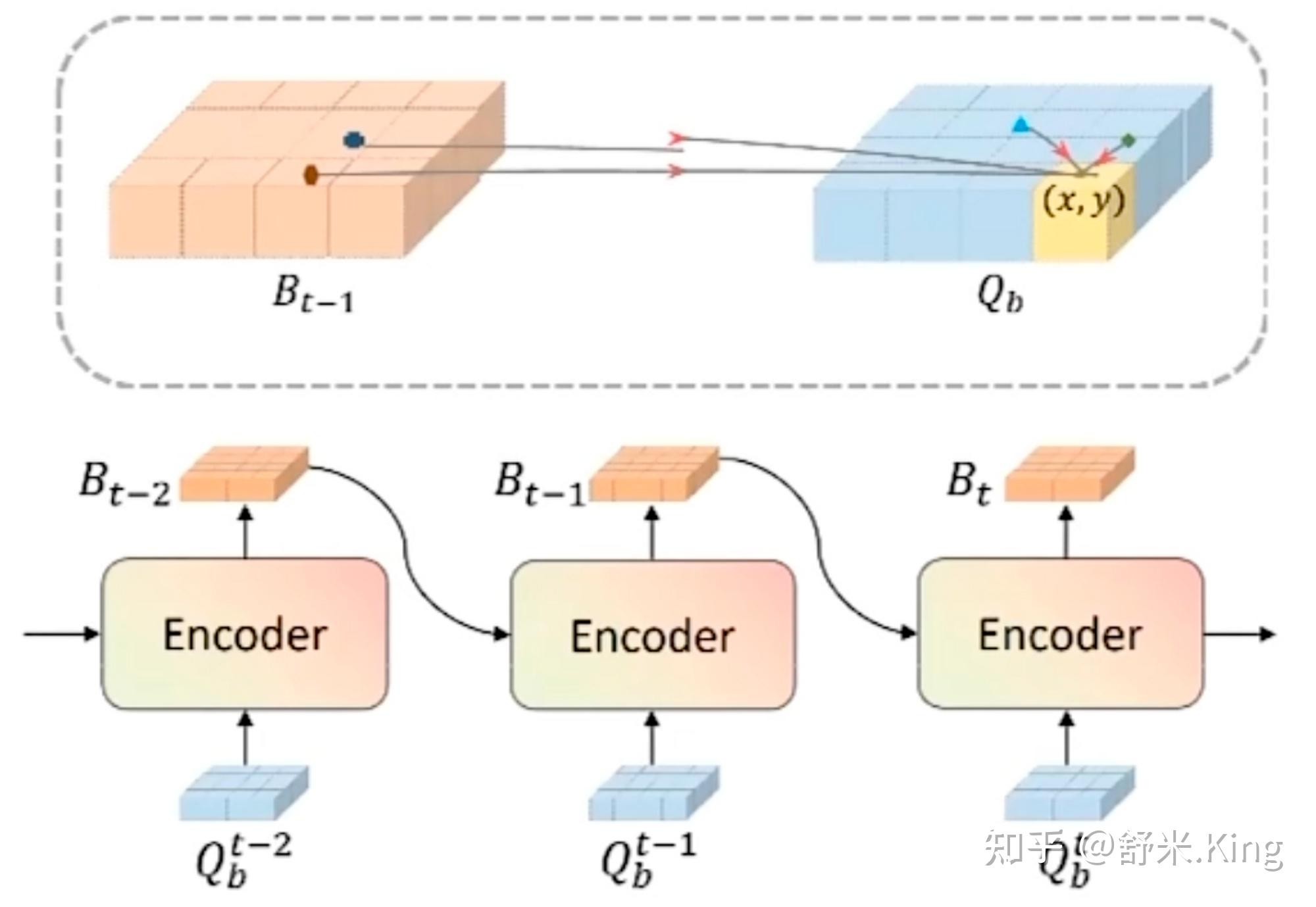
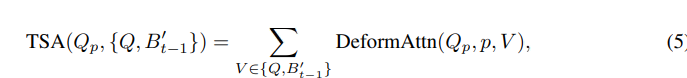
参考图4和上述公式5,总结temporal self-attention的实现方法:
- 给定t-1时刻的 BEV 特征Bt-1,先根据 ego motion 将Bt-1对齐到t时刻,来确保Bt-1和Bt在相同index位置的栅格对应于现实世界的同一位置,把时间对齐后的BEV特征记作 B’t-1。
- t时刻位于(x,y)处的 BEV query所表征的物体可能静态或者动态,它在t-1时刻会出现在 B’t-1的(x,y)周围,因此利用 deformable attention 以(x,y)作为参考点在其周围进行特征采样。
在这里吗BEV特征的对齐是如此实现的:通过旋转和平移变换实现 BEV 特征的对齐,对于平移部分是通过对参考点加上偏移量shift体现的7
上述方法没有显式地设计遗忘门,而是通过 attention 机制中的 attention wights 来平衡历史时序特征和当前 BEV 特征的融合过程。
关于TSA的后记:BEVFormer V2对 BEVFormer的时域融合方法TSA做了修改。1 (此处我还没有看过V2,因此直接复制粘贴,等事后看过之后再添加自己的理解)
BEVFormer中TSA采用了继承式的时域信息融合方式:利用attention机制在t时刻融合了t-1时刻的BEV features信息,由于t-1时刻的BEV features 也融合了更早时刻(t-2)的信息,因此t时刻BEV features间接地融合了比t-1时刻更早的信息。
但是这种继承式时域融合方式有遗忘的特点,即不能有效利用较长时间的历史信息。
BEVFormer V2把时域融合改成了:根据ego motion,把过去多个时刻的BEV features 对齐到当前时刻,然后在channel 维度把这些对齐后的BEV features 与当前时刻BEV features串联,然后用Residual 模块降低channel数,就完成了时域融合。
综合2.3和2.4节,观察6个 BEVFormer Encoder Layers的完整结构会发现, BEV query 既能通过 spatial cross-attention 聚合空间特征,又能通过 temporal self-attention 聚合时序特征,这个过程会重复多次,让时空特征融合能够相互促进,最终得到更好的融合BEV features。
补充:
bevformer或者说BEV空间的目标检测网络是能无缝衔接至OCC网络的,只需要在decoder将head加一个OCC head或者将原有的detect head改为OCC head就行。具体的理解可以参考2D目标检测和分割认为,其中backbone与neck都是可以共用的。
参考:
一文读懂BEVFormer论文
万字长文理解纯视觉感知算法 —— BEVFormer
LSS (Lift, Splat, Shoot) 论文+源码万字长文解析
BEV感知—LSS详解(Lift模块)
原论文
知乎回答
BEVFormer论文笔记(详细版)
一文读懂BEVFormer论文 ↩︎ ↩︎
万字长文理解纯视觉感知算法 —— BEVFormer ↩︎ ↩︎ ↩︎
知乎回答 ↩︎
BEV感知—LSS详解(Lift模块) ↩︎
BEVFormer论文笔记(详细版) ↩︎
原论文 ↩︎ ↩︎
LSS (Lift, Splat, Shoot) 论文+源码万字长文解析 ↩︎