详解Mysql Order by排序底层原理
MySQL 的 ORDER BY 子句实现排序是一个涉及查询优化、内存管理和磁盘 I/O 的复杂过程。其核心目标是高效地将结果集按照指定列和顺序排列。
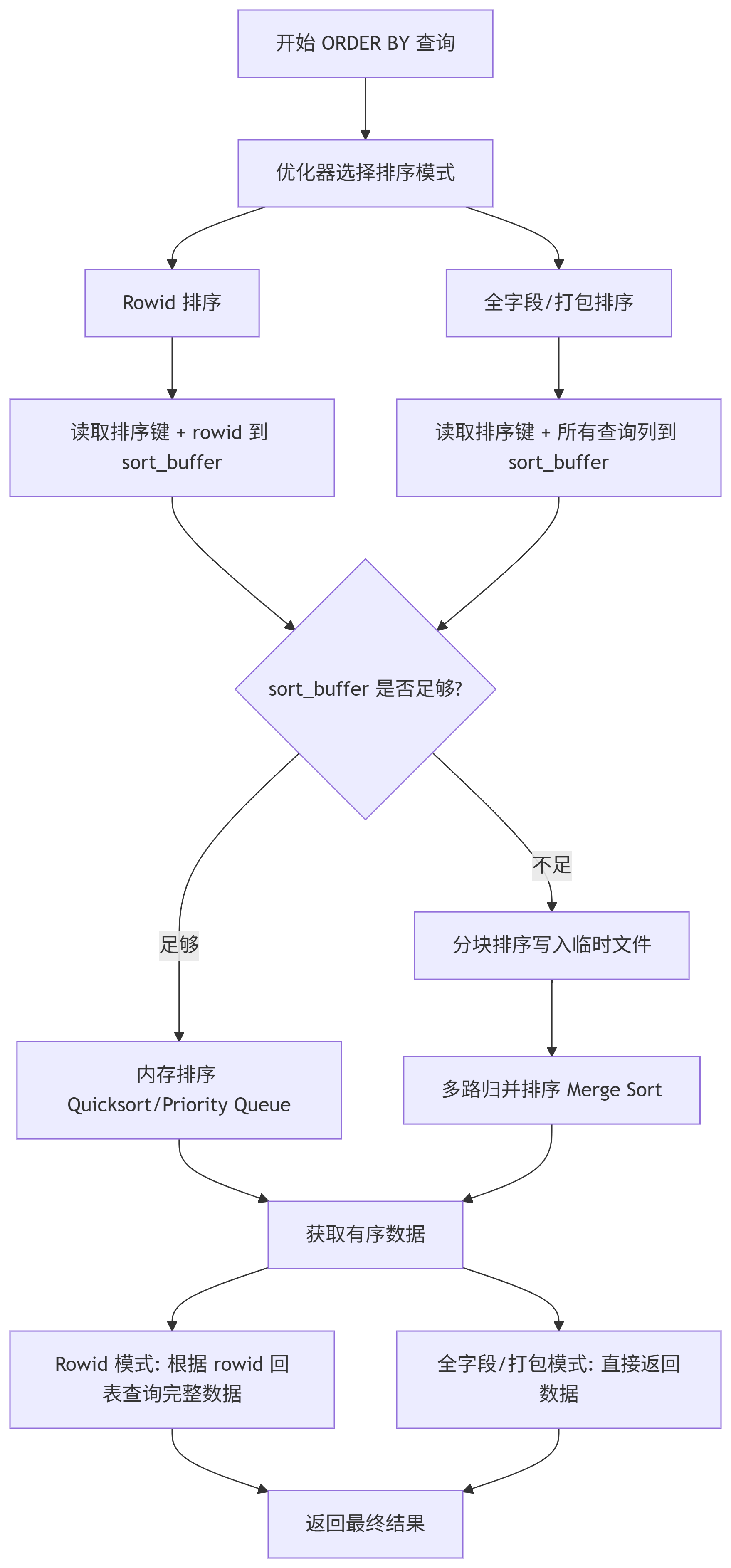
一、确定排序模式 (Sort Mode)
MySQL 根据查询特性和系统变量决定采用哪种排序策略:
1.1 Rowid 排序
<sort_key, rowid>模式 (Rowid 排序):仅将排序键 (ORDER BY 的列) 和 行指针 (通常是主键或行 ID) 放入
sort_buffer内存缓冲区。在内存中对这些
<sort_key, rowid>元组进行排序。排序完成后,根据行指针回表查询完整的数据行。
优点:
sort_buffer能容纳更多元组,减少内存不足时落磁盘的次数。缺点: 排序后需要额外的回表操作,可能增加随机 I/O。
触发条件:
max_length_for_sort_data系统变量设置较小,或者SELECT的列总长度较大时,优化器倾向于选择此模式。
1.2 全字段排序
<sort_key, additional_fields>模式 (全字段排序):将 排序键 (ORDER BY 的列) 和 查询需要返回的所有列 放入
sort_buffer。在内存中直接对包含完整数据的元组进行排序。
排序完成后,直接从
sort_buffer返回结果,无需回表。优点: 避免排序后的回表操作,减少随机 I/O。
缺点: 如果查询返回的列很多或很宽,
sort_buffer能容纳的元组数量会显著减少,更容易触发磁盘临时文件。触发条件:
max_length_for_sort_data设置较大,或者查询返回的列总长度较小时,优化器倾向于选择此模式。
1.3 打包排序
<sort_key, packed_additional_fields>模式 (打包排序 - MySQL 8.0+ 优化):MySQL 8.0.20 引入的进一步优化。
类似于全字段排序,但对
sort_buffer中存储的额外字段进行了更紧凑的打包处理。优点: 比传统全字段排序更节省
sort_buffer空间,容纳更多数据,减少落盘。触发条件: MySQL 8.0.20 及以后版本默认启用,替代传统的全字段排序。
二、利用 sort_buffer 内存排序
MySQL 分配一块称为
sort_buffer的内存区域专门用于排序。服务器线程将需要排序的行(根据选择的模式,可能是部分列或全列)放入
sort_buffer。如果
sort_buffer足够容纳所有需要排序的行:MySQL 直接在内存中对数据进行排序。通常使用高效的快速排序 (Quicksort) 算法。
对于
ORDER BY ... LIMIT N这类只需要前 N 条结果的查询,MySQL 优化器可能使用优先级队列 (Priority Queue Heap Sort) 算法。它在内存中维护一个大小为 N 的堆,只保留最终需要的 N 条有序结果,避免对所有数据进行完全排序,极大提升效率。
三、处理大数据集:外部排序 (External Sort)
如果
sort_buffer无法容纳所有需要排序的行:分块排序: MySQL 会将数据分成若干块 (chunks)。对每一块数据在
sort_buffer中进行快速排序,然后将排好序的块写入磁盘上的临时文件。这个过程称为 "run generation"。多路归并 (Multi-way Merge): 当所有块都排序并写入临时文件后,MySQL 使用归并排序 (Merge Sort) 算法将这些已排序的块合并成一个完整有序的结果集。它使用一个缓冲区同时读取多个临时文件的开头部分,找出当前最小的元素输出,然后从相应文件补充新元素,直到所有文件处理完毕。
归并路数: 同时合并的文件数由
merge_buffer_size控制。MySQL 会尽量多路归并以减少磁盘 I/O 轮次。
四、返回结果
无论排序是在内存中完成还是经过外部排序,最终都会得到一个完全按照
ORDER BY要求排序的结果集。服务器按顺序读取这个有序的结果集并返回给客户端。
五、关键影响因素和优化点:
sort_buffer_size: 控制分配给每个排序操作的内存缓冲区大小。增大它可以减少甚至避免磁盘临时文件的使用,提升排序速度。但设置过大可能导致系统内存资源紧张(尤其是在高并发排序时)。max_length_for_sort_data: 决定优化器选择 Rowid 排序还是全字段/打包排序的阈值。增大它可能促使优化器选择全字段/打包排序(避免回表),但可能导致sort_buffer容纳行数减少(更容易落盘)。需要根据实际情况权衡。tmpdir: 指定磁盘临时文件的存储目录。使用更快的存储设备(如 SSD)可以显著提升外部排序阶段的速度。ORDER BY ... LIMIT N: 优化器会优先尝试使用优先级队列算法,性能通常很好。使用覆盖索引: 如果
ORDER BY的列和SELECT的列都包含在一个索引中(覆盖索引),MySQL 可以直接按索引顺序读取数据,完全避免排序操作 (Using index)。这是性能最优的方式。innodb_disable_sort_file_cache: (InnoDB 相关) 控制是否对临时文件使用操作系统文件缓存。在某些场景下禁用可能有轻微性能提升。监控指标:
Sort_merge_passes: 归并排序的次数。次数多表明外部排序发生频繁,可能需要增大sort_buffer_size。Sort_range/Sort_scan: 分别表示通过范围扫描和全表扫描执行的排序次数。Sort_rows: 排序的总行数。Created_tmp_disk_tables/Created_tmp_files: 创建的磁盘临时表和临时文件数,反映内存排序不足的情况。
六、总结流程:
合理设计索引(尤其是覆盖索引)来避免排序。
根据查询特征和服务器配置调整
sort_buffer_size和max_length_for_sort_data。解读执行计划 (
EXPLAIN) 中的Using filesort(表示发生了排序)并判断其成本。监控服务器状态以识别潜在的排序性能瓶颈。
编写更高效的 SQL 查询(例如,利用
LIMIT优化)。