JAVA面试宝典 -《容灾设计:异地多活架构实践》
文章目录
- 🧭 容灾设计:异地多活架构实践——从理论到Java工程落地
- 🧠 引言:为什么要做异地多活?
- 架构演进对比
- 🧱 一、单元化架构设计:构建容灾基础设施
- 🧠 1.1 核心思想
- 🗂️ 1.2 路由策略实战(城市级划分)
- 🧭 1.3 隔离部署拓扑
- 🔁 二、数据一致性:双写同步机制
- 🧠 2.1 核心挑战
- 🔁 2.2 最终一致性方案
- 🧬 2.3 Java端幂等实现
- 🔁 2.4 补偿机制设计
- 🧪 三、故障切换演练:打造秒级切换能力
- 🧰 3.1 混沌工程工具链
- 🔁 3.2 演练流程(自动化编排)
- 🚦 3.3 安全规范
- ⚙️ 四、配置中心跨机房同步:Nacos实战
- 🧭 4.1 部署模型
- 🔁 4.2 同步一致性保障
- 📌 关键配置:
- 🌐 五、流量调度:DNS+VIP联合智能路由
- 🧠 5.1 三层调度模型
- 🛰️ 5.2 VIP自动漂移方案
- 🕵️♂️ 六、真实案例:大型电商多活踩坑复盘
- 🔍 6.1 血泪教训
- 🚀 6.2 性能优化三原则
- 🧮 七、关键决策与成本平衡
- 🧭 结语:异地多活——不是万能钥匙,但为业务兜底!
🧭 容灾设计:异地多活架构实践——从理论到Java工程落地
🧠 异地多活不是“高可用的终极答案”,但它是“保障核心业务最后一道防线”。
本文深度解析异地多活架构的核心设计,包含单元化路由、数据同步、故障演练等关键技术,并给出Java代码实战与高可用设计避坑指南。当城市级灾难发生时,你的系统能否实现"分钟级切换+用户无感知"? 本文将揭晓答案。
🧠 引言:为什么要做异地多活?
核心驱动力:当单机房故障导致业务全挂时,企业损失可达千万/小时量级。异地多活(Multi-Site Active/Active) 通过多地独立部署单元,解决单点故障、机房断网、自然灾害等致命问题。
架构演进对比
| 方案 | 可用性 | 数据延迟 | 故障影响范围 | 成本 |
|---|---|---|---|---|
| 单机房部署 | 99.9% | 0ms | 全局宕机 | 低 |
| 主备冷备 | 99.95% | 分钟级 | 分钟级中断 | 中 |
| 同城双活 | 99.99% | <5ms | 秒级切换 | 中高 |
| 异地多活 | 99.995%+ | 百毫秒级 | 用户无感 | 高 |
💡 类比理解:单机房如同独栋房屋,火灾全毁;异地多活则是多个自带水电系统的独立避难所。
🧱 一、单元化架构设计:构建容灾基础设施
🧠 1.1 核心思想
- 定义:将系统按用户维度(如UID前缀、地理位置)拆分为独立自治单元(Cell)
- 目标:故障隔离 + 就近访问 + 弹性扩缩
🗂️ 1.2 路由策略实战(城市级划分)
// 基于ShardingSphere实现用户单元路由
public class CellRouterAlgorithm implements StandardShardingAlgorithm<String> {@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> shardingValue) {// 按UID前缀映射城市单元:如BJ_北京, SH_上海String uid = shardingValue.getValue();String cityCode = getCityCodeByUid(uid); // 根据UID解析城市编码// 匹配逻辑单元: user_db_bj, user_db_shfor (String dbName : availableTargetNames) {if (dbName.endsWith(cityCode)) {return dbName;}}throw new IllegalStateException("未匹配到单元: " + cityCode);}
}// 配合DNS解析实现就近访问
// 用户请求 → GSLB解析 → 上海单元接入点 → 路由到user_db_sh
🧭 1.3 隔离部署拓扑
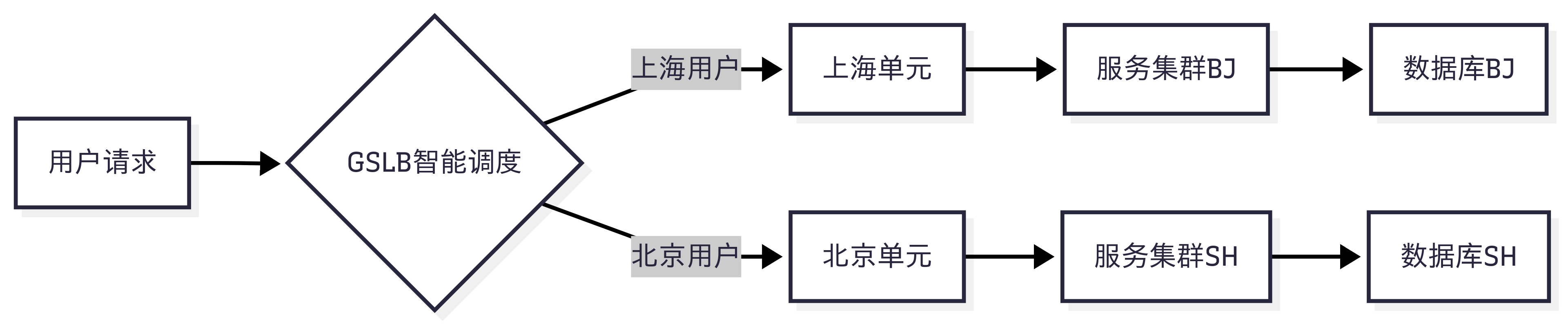
⚠️ 踩坑提醒:
- 单元拆分需避免跨单元事务(如拆分后订单和库存必须在同单元)
- 全局配置数据需特殊处理(如采用广播表)
🔁 二、数据一致性:双写同步机制
🧠 2.1 核心挑战
- 跨机房网络延迟(通常100ms~300ms)
- 脑裂风险(网络分区时双主写入冲突)
🔁 2.2 最终一致性方案
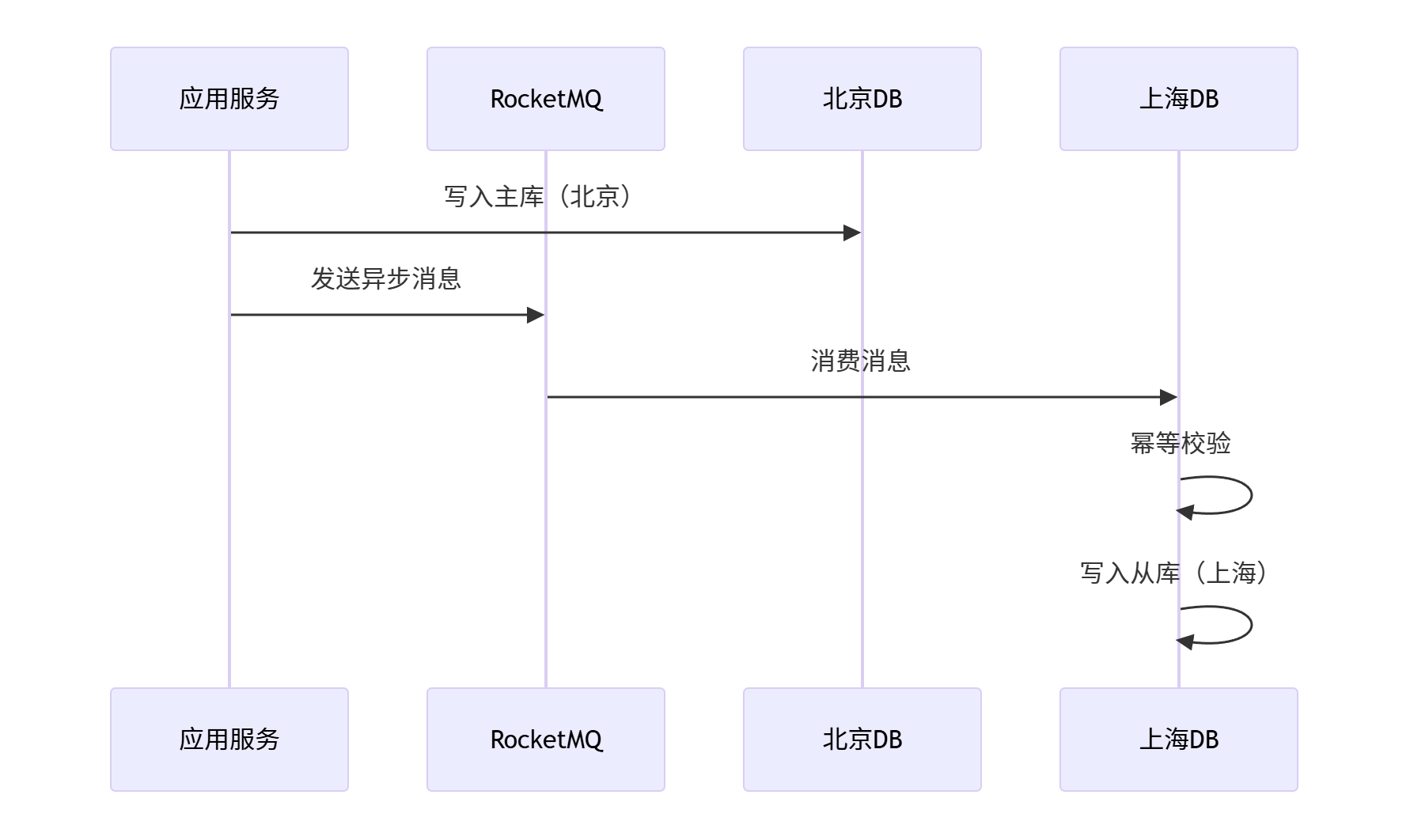
🧬 2.3 Java端幂等实现
// 基于Redis的请求去重
public boolean idempotentCheck(String messageId) {String key = "msg:" + messageId;// SETNX 原子操作实现唯一性校验Boolean result = redisTemplate.opsForValue().setIfAbsent(key, "1", 5, TimeUnit.MINUTES);return Boolean.TRUE.equals(result);
}
🔁 2.4 补偿机制设计
// 使用Quartz调度补偿任务
@Scheduled(cron = "0 */5 * * * ?")
public void dataSyncCompensate() {List<SyncRecord> failures = syncFailDao.queryFailedRecords();failures.forEach(record -> {if (idempotentCheck(record.getMessageId())) {retrySync(record); // 指数退避重试}});
}
🚨 避坑指南:
- 禁用数据库级联复制(避免环形复制)
- 消息队列需跨机房部署(如RocketMQ中继模式)
🧪 三、故障切换演练:打造秒级切换能力
🧰 3.1 混沌工程工具链
| 工具 | 作用 | 适用场景 |
|---|---|---|
| ChaosMonkey | 随机杀死节点 | 服务容错测试 |
| ChaosBlade | 网络延迟/断网 | 跨机房故障模拟 |
| JMeter | 流量激增压测 | 切换后负载测试 |
🔁 3.2 演练流程(自动化编排)

🚦 3.3 安全规范
- 黄金指标监控:成功率、延迟、吞吐量
- 流量灰度切换:按1%、5%、10%…阶梯放量
- 强制熔断机制:数据延迟超阈值时自动禁用同步
⚙️ 四、配置中心跨机房同步:Nacos实战
🧭 4.1 部署模型
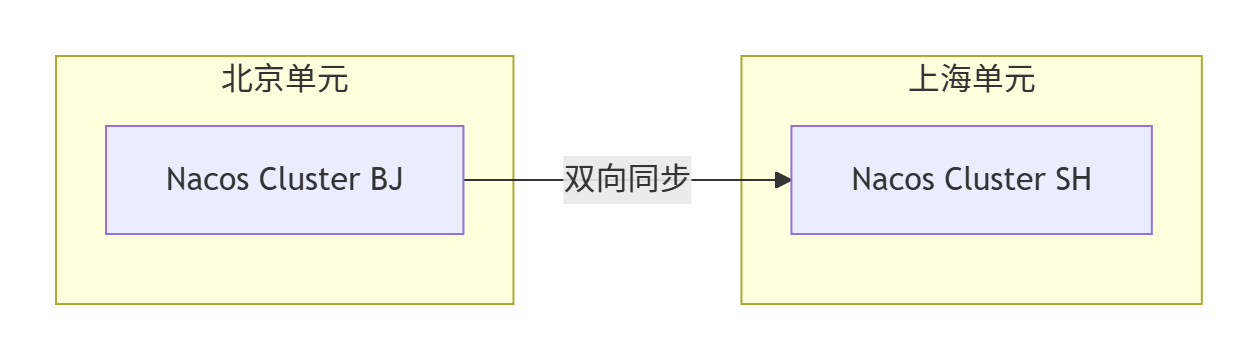
🔁 4.2 同步一致性保障
// Nacos 集群间同步拦截器(基于HTTP钩子)
public class CrossClusterSyncInterceptor implements RequestInterceptor {@Overridepublic void apply(RequestTemplate template) {// 标记跨机房请求头template.header("X-Nacos-CrossCluster", "true"); }
}// 服务端校验:拒绝非跨机房节点的直接修改
if (!isCrossClusterRequest() && isFromOtherCluster()) {throw new IllegalStateException("禁止跨集群直连修改!");
}
📌 关键配置:
# 启用Nacos跨集群同步
nacos.remote.route.enable=true
nacos.remote.route.addr=sh.nacos.com:8848,bj.nacos.com:8848
🌐 五、流量调度:DNS+VIP联合智能路由
🧠 5.1 三层调度模型
| 层 | 技术 | 切换速度 | 精度 |
|---|---|---|---|
| 全局调度 | DNSGSLB | 分钟级 | 城市级 |
| 区域调度 | BGP Anycast/VIP | 秒级 | 机房级 |
| 服务调度 | Nacos/SpringCloud | 毫秒级 | 服务实例级 |
🛰️ 5.2 VIP自动漂移方案

✨ 优势:BGP Anycast实现用户->最近机房的直连访问,网络延迟降低40%
🕵️♂️ 六、真实案例:大型电商多活踩坑复盘
🔍 6.1 血泪教训
- "幽灵数据"事件:
- 现象:用户看到已删除的购物车商品
- 根因:跨单元同步消息丢失+无补偿机制
- 解决:增加校验对账任务,修复率100%
- 切流雪崩:
- 现象:上海单元切10%流量后CPU飙升
- 根因:未预热JIT编译+本地缓存穿透
- 解决:切流前主动触发编译+缓存预热
🚀 6.2 性能优化三原则
- 读写分离 :跨单元只读,本单元读写
- 数据分治 :全局表降级为本地表+定期合并
- 链路过载保护 :跨机房调用线程池隔离
🧮 七、关键决策与成本平衡
| 决策点 | 低成本方案 | 高可用方案 | 建议 |
|---|---|---|---|
| 数据一致性 | 异步复制 | 分布式事务 | 异步+补偿 |
| 部署密度 | 两地三中心 | 三地五中心 | 按业务重要性选 |
| 同步网络 | 公网VPN | 专线+SD-WAN | 专线+公网备 |
🔥 核心公式:
业务损失成本 > 多活投入成本 → 必须做多活
写冲突率 < 0.1% → 适合单元化架构
🧭 结语:异地多活——不是万能钥匙,但为业务兜底!
通过本文可快速掌握异地多活的核心设计模式与Java工程实践,但需谨记:
- 避免"为了多活而多活"(中小业务主备更经济)
- 单元化是基础,数据同步是关键,自动化演练是保障
- 容灾能力=技术+流程+组织协作
真正的高可用系统,能在黑暗中依然稳定运行。