爬虫小知识
目录
一、爬虫的介绍
1、网络爬虫库
2 、robots.txt 规则
二、requests库和网页源代码
1、request库的安装
2、网页源代码
三、获取网页资源
1、get()函数
1、基本语法
2、核心参数(常用)
2、用get()搜索信息
3、get()添加信息
4、返回Response对象
四、小项目案例:处理获取的网页信息
一、爬虫的介绍
1、网络爬虫库
网络爬虫通俗来讲就是使用代码将HTML网页的内容下载到本地的过程。爬取网页主要是为了获取网的中的关键信息,例如网页中的数据、图片、视频等。Python语言中提供了多个具有爬虫功能的库,下面将具体介绍
urllib库:是Python自带的标准库,无须下载、安装即可直接使用。urllib库中包含大量的爬虫功能,但其代码编写略显复杂。
reguests库:是Python的第三方库,需要下载、安装之后才能使用。由于requests库是在urllib库的基的上建立的,它包含urllib库的功能,这使得requests库中的函数和方法的使用更加友好,因此requests库使用起来更方便。
scrapy库:是Python的第三方库,需要下载、安装之后才能使用。是一个适用于专业应用程序开发的网络爬虫库。scrapy库集合了爬虫的框架,通过框架可创建一个专业爬虫系统。
selenium库:是Python的第三方库,需要下载、安装后才能使用。selenium库可用于驱动计算机中的浏览器执行相关命令,而无须用户手动操作。常用于自动驱动浏览器实现办公自动化和Web应用程序测试。
2 、robots.txt 规则
在正式学习网络爬虫之前,需要掌握爬取规则,不是网站中的所有信息都允许被爬取,也不是所有的网站都允许被爬取。在大部分网站的根目录中存在一个robots.txt文件,该文件用于声明此网站中禁止访问的url和可以访问的url。用户只需在网站域名后面加上/robots.txt即可读取此文件的内容。
例如要获取豆瓣官网中的robots.txt文件,打开浏览器输入豆瓣官网域名并在域名后加上/robots.txt,按Enter键即可
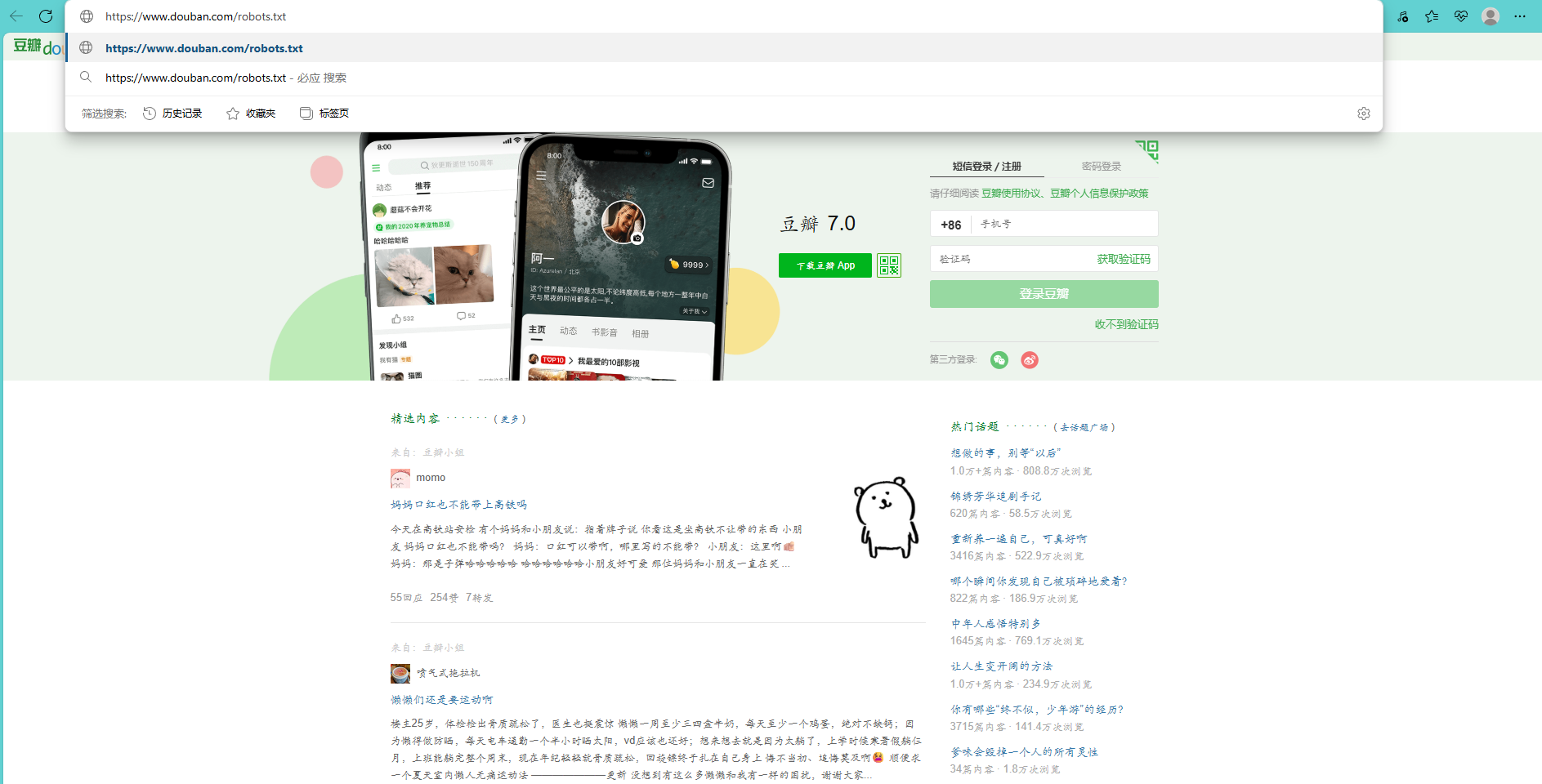
User - agent:指定 “谁” 要遵守规则,* 代表所有爬虫;像 Wandoujia Spider 就是豌豆荚爬虫,Mediapartners - Google 是谷歌广告合作爬虫
Disallow:跟在 User - agent 后,说明 “不让爬啥”,比如 Disallow: /search ,就是不让对应爬虫爬搜索相关页面
Allow:明确 “让爬啥”,像 Allow: /ads.txt ,允许爬广告验证文件
Sitemap:给爬虫站点地图地址,比如 Sitemap: https://www.douban.com/sitemap_index.xml ,方便爬虫了解站点结构
Crawl - delay:Crawl - delay: 5 是说爬虫访问间隔至少 5 秒,别太频繁压服务器
有些网站没有限制,比如人民邮电出版社
二、requests库和网页源代码
1、request库的安装
终端口令安装
pip install requests安装完成后可以用以下命令查看库的信息
pip show requests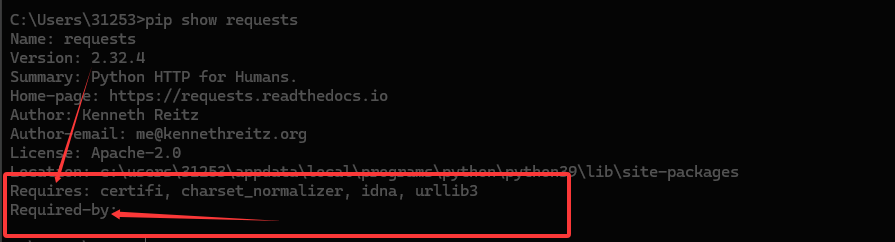
Requires:列出 requests 库运行所依赖的其他 Python 包 ,这里 certifi(用于证书验证)、charset_normalizer(字符集归一化处理 )、idna(处理国际化域名相关 )、urllib3(底层的 HTTP 客户端库,requests 基于它封装 ),安装 requests 时,这些依赖一般会自动装好,保证 requests 功能正常。
Required-by:显示哪些已安装的 Python 包依赖于 requests 库 ,不过当前截图里这部分内容没显示出来(可能是系统里暂没其他包明确依赖 requests ,或命令输出没完整呈现 ),要是有值,就会列出依赖 requests 的包名,说明这些包运行时需要 requests 提供的功能。
2、网页源代码
用户在浏览器可以打开网页源代码

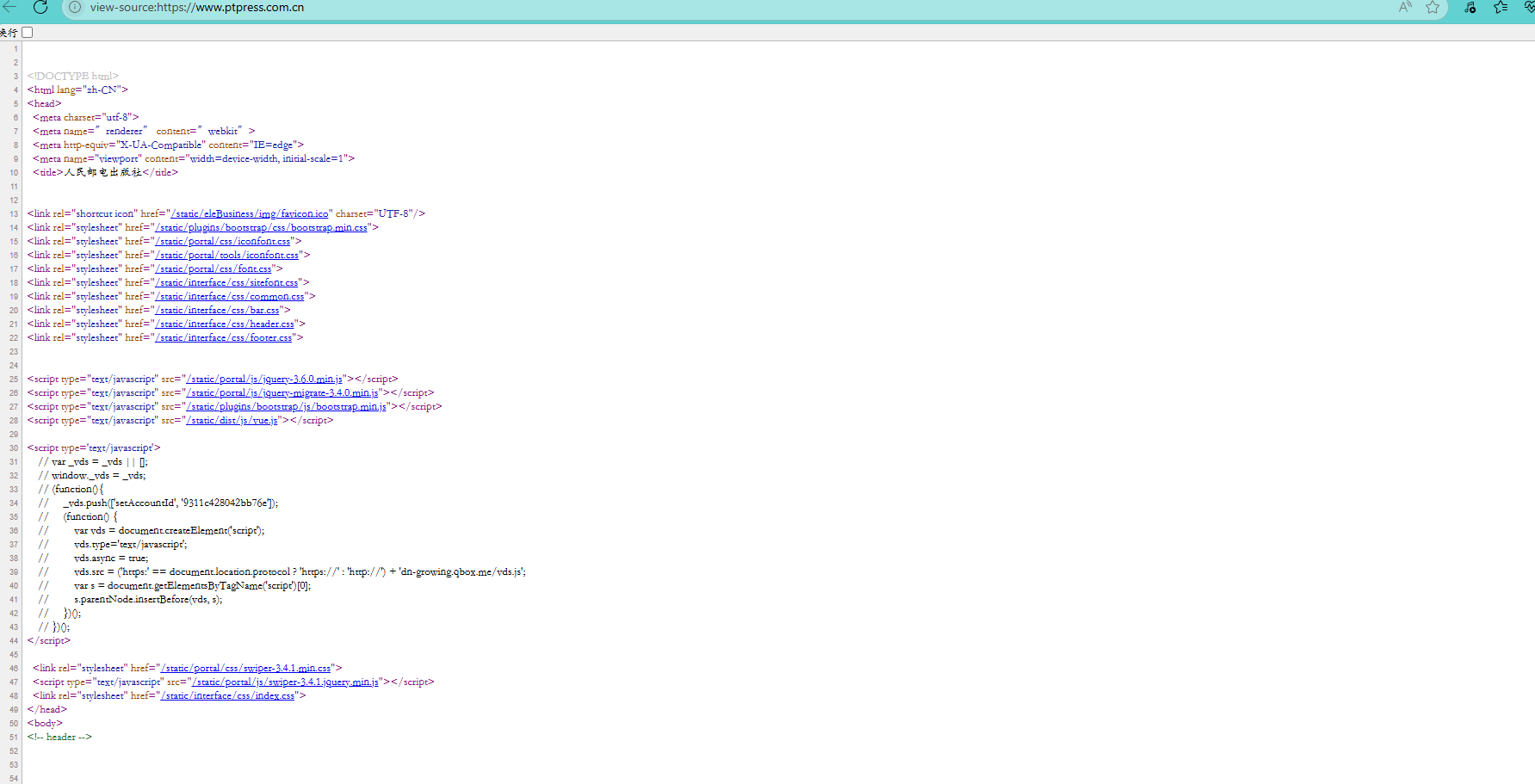
该源代码用的是HTML语言
这里看的是源代码,但我们平时看的网页是渲染后的代码,渲染后的代码也是可以查看的
在空白处左键,然后点击检查

在这里可以看到一些图片,视频等数据的url(数据的源地址),需要完整的url码只需要在前面加入网站主地址即可。
三、获取网页资源
requests库中有获取网页资源的功能
1、get()函数
requests.get() 是 requests 库中用于发送 HTTP GET 请求的核心方法,专门用于从指定 URL 对应的服务器获取资源(如网页、数据、文件等)。以下是对该方法的详细介绍:
1、基本语法
requests.get(url, params=None, headers=None, cookies=None, auth=None, timeout=None, ...)
2、核心参数(常用)
-
url(必填):字符串类型,指定要请求的资源地址(如https://www.example.com)。这是唯一必须传入的参数。 -
params(可选):用于传递 URL 查询参数(即 URL 中?后面的键值对)。- 类型:字典、列表、元组或字节序列。
- 作用:自动将参数拼接成
url?key1=value1&key2=value2的格式,避免手动拼接 URL 可能出现的错误。
-
常见用途:设置headers(可选):字典类型,用于设置请求头信息,模拟浏览器行为或传递额外信息。User-Agent(浏览器标识)以避免被服务器识别为爬虫 -
作用:避免请求因网络问题无限期等待,超过时间会抛出timeout(可选):数值或元组类型,设置请求超时时间(单位:秒)。Timeout异常。 -
cookies(可选):字典或CookieJar对象,用于传递 cookies 信息(如登录状态) -
auth(可选):用于 HTTP 认证(如 Basic Auth),接收一个元组(用户名, 密码)
2、用get()搜索信息
示例代码:
import requests
r = requests.get('https://www.ptpress.com.cn/')
print(r.text)
代码作用:获取网页的源代码
import requests
r = requests.get('https://www.ptpress.com.cn/search?keyword=excel')
print(r.text)代码作用:用于实现在网站上查找关键词为“excel”的信息。
3、get()添加信息
示例代码:
import requests
info ={'keyword':'excel' }
r = requests.get('https://www.ptpress.com.cn/search',params=info)
print(r.url)
print(r.text)
代码作用
info = {'keyword': 'excel'}
定义存储请求参数的字典:键keyword是网站规定的搜索参数名,值excel是要搜索的关键词。
r = requests.get('https://www.ptpress.com.cn/search', params=info)
调用get()方法向邮电出版社搜索接口发送请求,参数params=info会自动将字典转为?keyword=excel拼接到 URL 后。变量r接收服务器返回的响应对象。
该方法 可以用遍历来大量读取不同标签网页的内容
4、返回Response对象
通过get()函数获取HTML网页内容后,由于网页多样性,通常还需要对网页返回Reaponse对象进行设置
1、核心作用
Response 对象封装了服务器返回的全部数据,是开发者与服务器 “对话” 的结果载体。通过它可以获取请求是否成功、返回的具体内容、服务器的附加信息等,是处理网络请求的核心对象。
2、常用属性(直接获取信息)
1. status_code
-
含义:HTTP 状态码,整数类型,用于判断请求是否成功。
-
常见值:
-
200:请求成功(服务器正常返回数据); -
404:请求的 URL 不存在(页面未找到); -
403:服务器拒绝请求(可能被识别为爬虫,无访问权限); -
500:服务器内部错误(服务器端出问题)。
-
-
示例:若
r.status_code == 200,说明本次请求成功。
2. url
-
含义:字符串类型,返回实际请求的完整 URL(包含拼接的参数)。
-
作用:验证请求的地址是否正确,尤其是当参数自动拼接时(如
params参数)。 -
示例:在之前的代码中,
r.url会返回https://www.ptpress.com.cn/search?keyword=excel。
3. text
-
含义:字符串类型,以文本形式返回服务器响应的内容(默认使用
encoding编码解析)。 -
适用场景:处理 HTML 网页、JSON 文本、普通文本等字符型数据。
-
注意:若内容包含中文乱码,可通过
r.encoding = "utf-8"手动设置编码解决。
4. content
-
含义:二进制字节流(
bytes类型),返回原始的响应内容(未经过编码处理)。 -
适用场景:处理图片、视频、音频、压缩包等非文本资源(需保存为文件时使用)。
-
示例:若请求的是图片 URL,
r.content就是图片的二进制数据,可通过open("image.jpg", "wb").write(r.content)保存为本地图片。
5. encoding
-
含义:字符串类型,返回当前解析响应内容的编码方式(如
utf-8、ISO-8859-1等)。 -
作用:解决文本乱码问题。若
r.text显示乱码,可手动设置r.encoding = "utf-8"(需根据网页实际编码调整)。
6. headers
-
含义:字典类型,包含服务器返回的响应头信息(服务器对本次响应的附加说明)。
-
常见键值:
-
Content-Type:说明响应内容的类型(如text/html表示 HTML 网页,application/json表示 JSON 数据); -
Server:服务器的类型(如nginx、Apache); -
Set-Cookie:服务器返回的 Cookie 信息(用于维持登录状态等)。
-
-
示例:
r.headers["Content-Type"]可获取响应内容的类型。
7. cookies
-
含义:
CookieJar对象,包含服务器返回的 Cookie 信息(键值对形式)。 -
作用:用于后续请求携带 Cookie(如模拟登录状态,避免重复登录)。
-
示例:
r.cookies.get("session_id")可获取名为session_id的 Cookie 值。
示例代码:
1、状态码
import requests
r = requests.get('https://www.ptpress.com.cn')
print(r.status_code)
if r.status_code==200:print(r.text)
else:print('本次访问失败')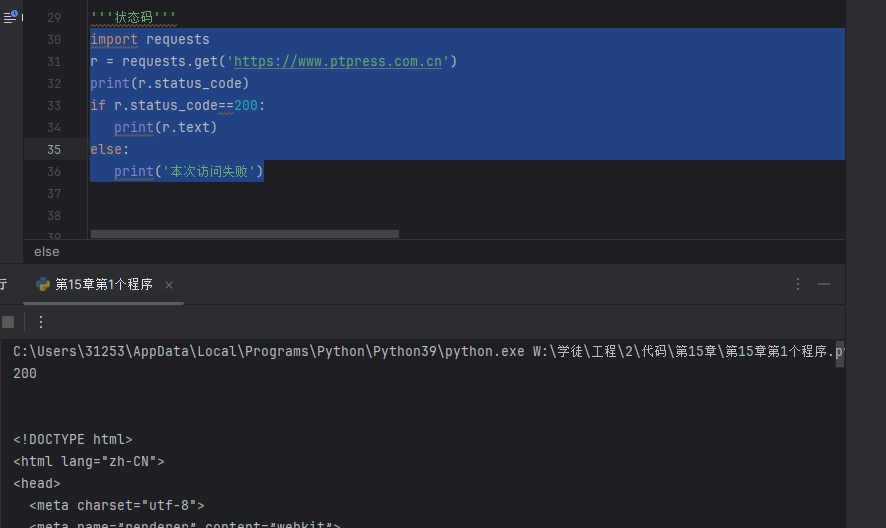
2、设置编码,可以解决网页编码识别不了的问题
import requests
r = requests.get('https://www.baidu.com')
r.encoding = r.apparent_encoding
print(r.text)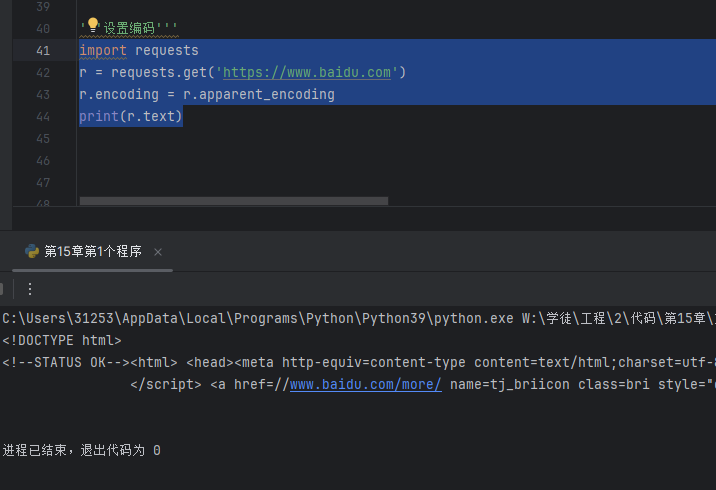
四、小项目案例:处理获取的网页信息
任务:在某个网站上上架了新书,现在需要用request方法获取所有新书的书名
示例代码:
import requests
import re
r = requests.get('https://www.ryjiaoyu.com/book')
result = re.findall(r'title=(.+?)">(.+?)</a></h4>',r.text)
for i in range(len(result)):print('第',i+1,'本书: ',result[i][1])运行结果
