sglang笔记1: 后端详细阅读版
后端code walk through从launcher_server.py开始着手阅读 详细篇
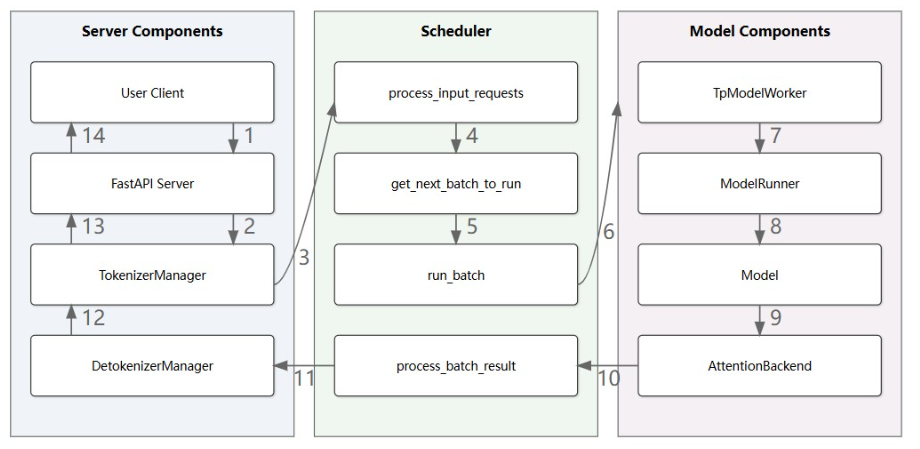
1. 用户启动 Server ,初始化 FastAPI App、TokenizerManager、DetokenizerManager 和 Scheduler,每个组件运行各自的无限事件循环(infinite event loop)
--> python\sglang\srt\entrypoints\http_server.py的launch_server函数
定义TokenizerManager Scheduler DetokenizerManager
def launch_server(server_args: ServerArgs,pipe_finish_writer: Optional[multiprocessing.connection.Connection] = None,launch_callback: Optional[Callable[[], None]] = None,):"""Launch SRT (SGLang Runtime) Server.The SRT server consists of an HTTP server and an SRT engine.- HTTP server: A FastAPI server that routes requests to the engine.- The engine consists of three components:1. TokenizerManager: Tokenizes the requests and sends them to the scheduler.2. Scheduler (subprocess): Receives requests from the Tokenizer Manager, schedules batches, forwards them, and sends the output tokens to the Detokenizer Manager.3. DetokenizerManager (subprocess): Detokenizes the output tokens and sends the result back to the Tokenizer Manager.Note:1. The HTTP server, Engine, and TokenizerManager both run in the main process.2. Inter-process communication is done through IPC (each process uses a different port) via the ZMQ library."""
2.用户向 FastAPI Server 发送/v1/chat/completions 请求,Server 通过 v1_chat_completions endpoint 将请求转发到 TokenizerManager。
--> python\sglang\srt\entrypoints\http_server.py
##### OpenAI-compatible API endpoints #####@app.post("/v1/completions", dependencies=[Depends(validate_json_request)])async def openai_v1_completions(request: CompletionRequest, raw_request: Request):"""OpenAI-compatible text completion endpoint."""return await raw_request.app.state.openai_serving_completion.handle_request(request, raw_request)@app.post("/v1/chat/completions", dependencies=[Depends(validate_json_request)])async def openai_v1_chat_completions(request: ChatCompletionRequest, raw_request: Request):"""OpenAI-compatible chat completion endpoint."""return await raw_request.app.state.openai_serving_chat.handle_request(request, raw_request)这里的raw_app.state.xxxx定义在lifespan处定义,然后定义fastapi起
@asynccontextmanagerasync def lifespan(fast_api_app: FastAPI):# Initialize OpenAI serving handlersfast_api_app.state.openai_serving_completion = OpenAIServingCompletion(_global_state.tokenizer_manager, _global_state.template_manager)fast_api_app.state.openai_serving_chat = OpenAIServingChat(_global_state.tokenizer_manager, _global_state.template_manager)fast_api_app.state.openai_serving_embedding = OpenAIServingEmbedding(_global_state.tokenizer_manager, _global_state.template_manager)fast_api_app.state.openai_serving_score = OpenAIServingScore(_global_state.tokenizer_manager)fast_api_app.state.openai_serving_rerank = OpenAIServingRerank(_global_state.tokenizer_manager)server_args: ServerArgs = fast_api_app.server_argsif server_args.warmups is not None:await execute_warmups(server_args.disaggregation_mode,server_args.warmups.split(","),_global_state.tokenizer_manager,)logger.info("Warmup ended")warmup_thread = getattr(fast_api_app, "warmup_thread", None)if warmup_thread is not None:warmup_thread.start()yield# Fast APIapp = FastAPI(lifespan=lifespan,openapi_url=None if get_bool_env_var("DISABLE_OPENAPI_DOC") else "/openapi.json",)3. v1_chat_completions函数将请求转换为 ChatCompletionRequest,再转换为 GenerateReqInput,并调用 TokenizerManager 的 generate_request 方法。
以此为例
--> python\sglang\srt\entrypoints\http_server.py
##### OpenAI-compatible API endpoints #####@app.post("/v1/completions", dependencies=[Depends(validate_json_request)])async def openai_v1_completions(request: CompletionRequest, raw_request: Request):"""OpenAI-compatible text completion endpoint."""return await raw_request.app.state.openai_serving_completion.handle_request(request, raw_request) #将请求转换为 ChatCompletionRequest
然后到python\sglang\srt\entrypoints\openai\serving_base.py
看class OpenAIServingBase(ABC)类有个函数handle_request
async def handle_request(self, request: OpenAIServingRequest, raw_request: Request) -> Union[Any, StreamingResponse, ErrorResponse]:"""Handle the specific request type with common pattern"""try:# Validate requesterror_msg = self._validate_request(request)if error_msg:return self.create_error_response(error_msg)# Convert to internal formatadapted_request, processed_request = self._convert_to_internal_request(request) #这里转换为GenerateReqInput# Note(Xinyuan): raw_request below is only used for detecting the connection of the clientif hasattr(request, "stream") and request.stream:return await self._handle_streaming_request(adapted_request, processed_request, raw_request)else:return await self._handle_non_streaming_request(adapted_request, processed_request, raw_request)这里_handle_streaming_request和_handle_non_streaming_request都到子类去找
class OpenAIServingCompletion(OpenAIServingBase):"""Handler for /v1/completion requests"""def __init__(self,tokenizer_manager: TokenizerManager,template_manager: TemplateManager,):super().__init__(tokenizer_manager)self.template_manager = template_manager......async def _handle_streaming_request( #self,adapted_request: GenerateReqInput,request: CompletionRequest,raw_request: Request,) -> StreamingResponse:"""Handle streaming completion request"""return StreamingResponse(self._generate_completion_stream(adapted_request, request, raw_request),media_type="text/event-stream",background=self.tokenizer_manager.create_abort_task(adapted_request),)async def _generate_completion_stream( #self,adapted_request: GenerateReqInput,request: CompletionRequest,raw_request: Request,) -> AsyncGenerator[str, None]:"""Generate streaming completion response"""created = int(time.time())# State tracking for streamingstream_buffers = {}n_prev_tokens = {}# Usage trackingprompt_tokens = {}completion_tokens = {}cached_tokens = {}hidden_states = {}try:async for content in self.tokenizer_manager.generate_request(adapted_request, raw_request):index = content.get("index", 0)text = content["text"]prompt_tokens[index] = content["meta_info"]["prompt_tokens"]completion_tokens[index] = content["meta_info"]["completion_tokens"]cached_tokens[index] = content["meta_info"].get("cached_tokens", 0)hidden_states[index] = content["meta_info"].get("hidden_states", None)stream_buffer = stream_buffers.get(index, "")# Handle echo for first chunkif not stream_buffer: # The first chunkif request.echo:echo_text = self._get_echo_text(request, index)text = echo_text + text......async def _handle_non_streaming_request(self,adapted_request: GenerateReqInput,request: CompletionRequest,raw_request: Request,) -> Union[CompletionResponse, ErrorResponse, ORJSONResponse]:"""Handle non-streaming completion request"""try :generator = self.tokenizer_manager.generate_request(adapted_request, raw_request)ret = await generator.__anext__()except ValueError as e:return self.create_error_response(str(e))if not isinstance(ret, list):ret = [ret]response = self._build_completion_response(request,ret,int(time.time()),)return response都用到self.tokenizer_manager.generate_request
4.TokenizerManager 对请求进行 tokenization,并以 Python 对象(
pyobj)形式将其转发给 Scheduler,同时调用 TokenizerManager 的 _wait_one_response 方法。
python\sglang\srt\managers\tokenizer_manager.py
async def generate_request(self,obj: Union[GenerateReqInput, EmbeddingReqInput],request: Optional[fastapi.Request] = None,):async with self.model_update_lock.reader_lock:if obj.is_single:tokenized_obj = await self._tokenize_one_request(obj) #对请求进行 tokenizationstate = self._send_one_request(obj, tokenized_obj, created_time) #以 Python 对象(
pyobj)形式将其转发给 Schedulerasync for response in self._wait_one_response(obj, state, request): #调用 TokenizerManager 的 _wait_one_response 方法 获取结果yield responseelse:async for response in self._handle_batch_request(obj, request, created_time): #一样的 展开批量做这些处理而已,略yield response
5. Scheduler 在事件循环 event_loop_normal 中处理请求:
Scheduler 通过 recv_requests 接收请求,调用 process_input_requests 处理输入,通过 handle_generate_request 管理生成请求的逻辑,并将其加入 waiting_queue。
python\sglang\srt\managers\scheduler.py
@DynamicGradMode()
def event_loop_normal(self):"""A normal scheduler loop."""while True:recv_reqs = self.recv_requests() #通过 recv_requests 接收请求self.process_input_requests(recv_reqs) #调用 process_input_requests 处理输入batch = self.get_next_batch_to_run()self.cur_batch = batchif batch:result = self.run_batch(batch)self.process_batch_result(batch, result)else:# When the server is idle, do self-check and re-init some statesself.check_memory()self.new_token_ratio = self.init_new_token_ratioself.maybe_sleep_on_idle()self.last_batch = batch
在def process_input_requests函数里:
def process_input_requests(self, recv_reqs: List):for recv_req in recv_reqs:# If it is a health check generation request and there are running requests, ignore it.if is_health_check_generate_req(recv_req) and (self.chunked_req is not None or not self.running_batch.is_empty()):self.return_health_check_ct += 1continueoutput = self._request_dispatcher(recv_req)if output is not None:if isinstance(output, RpcReqOutput):if self.recv_from_rpc is not None:self.recv_from_rpc.send_pyobj(output)else:self.send_to_tokenizer.send_pyobj(output)#这里self._request_dispatcher = TypeBasedDispatcher([(TokenizedGenerateReqInput, self.handle_generate_request),....])
#通过 handle_generate_request 管理生成请求的逻辑 这里dispatcher意思是遇到TokenizedGenerateReqInput 用handle_generate_request处理从 waiting_queue 中,Scheduler 使用 get_next_batch_to_run 为即将处理的请求创建 ScheduleBatch。
@DynamicGradMode()
def event_loop_normal(self):"""A normal scheduler loop."""while True:recv_reqs = self.recv_requests() self.process_input_requests(recv_reqs)batch = self.get_next_batch_to_run()#从 waiting_queue 中,Scheduler 使用 get_next_batch_to_run 为即将处理的请求创建 ScheduleBatch。self.cur_batch = batch......def get_next_batch_to_run(self) -> Optional[ScheduleBatch]:# Merge the prefill batch into the running batchchunked_req_to_exclude = set()if self.chunked_req:# Move the chunked request out of the batch so that we can merge# only finished requests to running_batch.chunked_req_to_exclude.add(self.chunked_req)self.tree_cache.cache_unfinished_req(self.chunked_req)# chunked request keeps its rid but will get a new req_pool_idxself.req_to_token_pool.free(self.chunked_req.req_pool_idx)if self.last_batch and self.last_batch.forward_mode.is_extend():if self.last_batch.chunked_req is not None:# In the context pipeline parallelism, after the last chunk, the current microbatch still track outdated chunked_req.# We need to discard it.chunked_req_to_exclude.add(self.last_batch.chunked_req)# Filter batchlast_bs = self.last_batch.batch_size()self.last_batch.filter_batch(chunked_req_to_exclude=list(chunked_req_to_exclude))if self.last_batch.batch_size() < last_bs:self.running_batch.batch_is_full = False# Merge the new batch into the running batchif not self.last_batch.is_empty():if self.running_batch.is_empty():self.running_batch = self.last_batchelse:# Merge running_batch with prefill batchself.running_batch.merge_batch(self.last_batch)new_batch = self.get_new_batch_prefill()need_dp_attn_preparation = require_mlp_sync(self.server_args)if need_dp_attn_preparation and not self.spec_algorithm.is_none():# In speculative decoding, prefill batches and decode batches cannot be processed in the same DP attention group.# We prepare idle batches in advance to skip preparing decode batches when there are prefill batches in the group.new_batch = self.prepare_mlp_sync_batch(new_batch)need_dp_attn_preparation = new_batch is Noneif new_batch is not None:# Run prefill first if possibleret = new_batchelse:# Run decodeif not self.running_batch.is_empty():self.running_batch = self.update_running_batch(self.running_batch)ret = self.running_batch if not self.running_batch.is_empty() else Noneelse:ret = None# Handle DP attentionif need_dp_attn_preparation:ret = self.prepare_mlp_sync_batch(ret)return retScheduler 执行 run_batch 函数,将 ScheduleBatch 转换为 ModelWorkerBatch。
Scheduler 调用 TpModelWorker 的 forward_batch_generation,等待 logits_output 和 next_token_ids。
python\sglang\srt\managers\scheduler.py
@DynamicGradMode()def event_loop_normal(self):"""A normal scheduler loop."""while True:recv_reqs = self.recv_requests()self.process_input_requests(recv_reqs)batch = self.get_next_batch_to_run()self.cur_batch = batchif batch:result = self.run_batch(batch)#将 ScheduleBatch 转换为 ModelWorkerBatch。.....def run_batch(self, batch: ScheduleBatch) -> Union[GenerationBatchResult, EmbeddingBatchResult]:"""Run a batch."""self.forward_ct += 1# Whether to run the profilerself._profile_batch_predicate(batch)if self.forward_sleep_time is not None:logger.info(f"Scheduler.run_batch sleep {self.forward_sleep_time}s")time.sleep(self.forward_sleep_time)# Run forwardif self.is_generation:if self.spec_algorithm.is_none():model_worker_batch = batch.get_model_worker_batch()# update the consumer index of hicache to the running batchself.tp_worker.set_hicache_consumer(model_worker_batch.hicache_consumer_index)if self.pp_group.is_last_rank:logits_output, next_token_ids, can_run_cuda_graph = (self.tp_worker.forward_batch_generation(model_worker_batch)) #TpModelWorker 的 forward_batch_generation返回logits_output 和 next_token_ids。else:pp_hidden_states_proxy_tensors, _, can_run_cuda_graph = (self.tp_worker.forward_batch_generation(model_worker_batch))bid = model_worker_batch.bidelse:(logits_output,next_token_ids,bid,num_accepted_tokens,can_run_cuda_graph,) = self.draft_worker.forward_batch_speculative_generation(batch)bs = batch.batch_size()self.spec_num_total_accepted_tokens += num_accepted_tokens + bsself.spec_num_total_forward_ct += bsself.num_generated_tokens += num_accepted_tokensif self.pp_group.is_last_rank:batch.output_ids = next_token_ids# These 2 values are needed for processing the output, but the values can be# modified by overlap schedule. So we have to copy them here so that# we can use the correct values in output processing.if batch.return_logprob or self.spec_algorithm.is_eagle():extend_input_len_per_req = [req.extend_input_len for req in batch.reqs]else:extend_input_len_per_req = Noneif batch.return_logprob:extend_logprob_start_len_per_req = [req.extend_logprob_start_len for req in batch.reqs]else:extend_logprob_start_len_per_req = Noneret = GenerationBatchResult(logits_output=logits_output if self.pp_group.is_last_rank else None,pp_hidden_states_proxy_tensors=(pp_hidden_states_proxy_tensorsif not self.pp_group.is_last_rankelse None),next_token_ids=next_token_ids if self.pp_group.is_last_rank else None,extend_input_len_per_req=extend_input_len_per_req,extend_logprob_start_len_per_req=extend_logprob_start_len_per_req,bid=bid,can_run_cuda_graph=can_run_cuda_graph,)else: # embedding or reward modelmodel_worker_batch = batch.get_model_worker_batch()embeddings = self.tp_worker.forward_batch_embedding(model_worker_batch)ret = EmbeddingBatchResult(embeddings=embeddings, bid=model_worker_batch.bid)return retTpModelWorker 初始化 ForwardBatch,将其转发至 ModelRunner,并等待 logits_output。
def forward_batch_generation(self,model_worker_batch: ModelWorkerBatch,launch_done: Optional[threading.Event] = None,skip_sample: bool = False,) -> Tuple[Union[LogitsProcessorOutput, torch.Tensor], Optional[torch.Tensor], bool]:forward_batch = ForwardBatch.init_new(model_worker_batch, self.model_runner)#初始化 ForwardBatchpp_proxy_tensors = Noneif not self.pp_group.is_first_rank:pp_proxy_tensors = PPProxyTensors(self.pp_group.recv_tensor_dict(all_gather_group=self.get_attention_tp_group()))if self.pp_group.is_last_rank:logits_output, can_run_cuda_graph = self.model_runner.forward(forward_batch, pp_proxy_tensors=pp_proxy_tensors) # ModelRunner 处理获得logits_outputif launch_done is not None:launch_done.set()if skip_sample:next_token_ids = Noneelse:next_token_ids = self.model_runner.sample(logits_output, model_worker_batch)return logits_output, next_token_ids, can_run_cuda_graphelse:pp_proxy_tensors, can_run_cuda_graph = self.model_runner.forward(forward_batch,pp_proxy_tensors=pp_proxy_tensors,)return pp_proxy_tensors.tensors, None, can_run_cuda_graphModelRunner 处理 ForwardBatch,调用 forward_extend 执行模型的前向计算(forward pass)。
python\sglang\srt\model_executor\model_runner.py
def forward_extend(self,forward_batch: ForwardBatch,skip_attn_backend_init: bool = False,pp_proxy_tensors=None,) -> LogitsProcessorOutput:if not skip_attn_backend_init:self.attn_backend.init_forward_metadata(forward_batch)kwargs = {}if self.support_pp:kwargs["pp_proxy_tensors"] = pp_proxy_tensorsif forward_batch.input_embeds is not None:kwargs["input_embeds"] = forward_batch.input_embeds.bfloat16()if not self.is_generation:kwargs["get_embedding"] = Truereturn self.model.forward(forward_batch.input_ids,forward_batch.positions,forward_batch,**kwargs,)模型通过 AttentionBackend 加速生成 logits,返回给 ModelRunner,进而返回给 TpModelWorker。
关于attentionbackend定义
def init_attention_backend(self):"""Init attention kernel backend."""if self.server_args.enable_two_batch_overlap and not self.is_draft_worker:self.attn_backend = TboAttnBackend.init_new(self._get_attention_backend)else:self.attn_backend = self._get_attention_backend()# TODO unify with 6338
def _get_attention_backend(self):if self.server_args.attention_backend == "flashinfer": #用这个比较多if not self.use_mla_backend:from sglang.srt.layers.attention.flashinfer_backend import (FlashInferAttnBackend,)# Init streamsif self.server_args.speculative_algorithm == "EAGLE":self.plan_stream_for_flashinfer = torch.cuda.Stream()return FlashInferAttnBackend(self)else:from sglang.srt.layers.attention.flashinfer_mla_backend import (FlashInferMLAAttnBackend,)return FlashInferMLAAttnBackend(self)elif self.server_args.attention_backend == "aiter":from sglang.srt.layers.attention.aiter_backend import AiterAttnBackendreturn AiterAttnBackend(self)elif self.server_args.attention_backend == "ascend":from sglang.srt.layers.attention.ascend_backend import AscendAttnBackendreturn AscendAttnBackend(self)elif self.server_args.attention_backend == "triton":assert not self.model_config.is_encoder_decoder, ("Cross attention is not supported in the triton attention backend. ""Please use `--attention-backend flashinfer`.")if self.server_args.enable_double_sparsity:from sglang.srt.layers.attention.double_sparsity_backend import (DoubleSparseAttnBackend,)return DoubleSparseAttnBackend(self)else:from sglang.srt.layers.attention.triton_backend import TritonAttnBackendreturn TritonAttnBackend(self)elif self.server_args.attention_backend == "torch_native":from sglang.srt.layers.attention.torch_native_backend import (TorchNativeAttnBackend,)return TorchNativeAttnBackend(self)elif self.server_args.attention_backend == "flashmla":from sglang.srt.layers.attention.flashmla_backend import FlashMLABackendreturn FlashMLABackend(self)elif self.server_args.attention_backend == "fa3":assert (torch.cuda.get_device_capability()[0] == 8 and not self.use_mla_backend) or torch.cuda.get_device_capability()[0] == 9, ("FlashAttention v3 Backend requires SM>=80 and SM<=90. ""Please use `--attention-backend flashinfer`.")from sglang.srt.layers.attention.flashattention_backend import (FlashAttentionBackend,)return FlashAttentionBackend(self)elif self.server_args.attention_backend == "cutlass_mla":from sglang.srt.layers.attention.cutlass_mla_backend import (CutlassMLABackend,)return CutlassMLABackend(self)elif self.server_args.attention_backend == "intel_amx":from sglang.srt.layers.attention.intel_amx_backend import (IntelAMXAttnBackend,)logger.info(f"Intel AMX attention backend is enabled.")return IntelAMXAttnBackend(self)else:raise ValueError(f"Invalid attention backend: {self.server_args.attention_backend}")TpModelWorker 从 ModelRunner 接收 logits_output,调用 ModelRunner 的 sample 方法生成 next_token_ids,并将其发送回 Scheduler。
def forward_batch_generation(self,model_worker_batch: ModelWorkerBatch,launch_done: Optional[threading.Event] = None,skip_sample: bool = False,) -> Tuple[Union[LogitsProcessorOutput, torch.Tensor], Optional[torch.Tensor], bool]:forward_batch = ForwardBatch.init_new(model_worker_batch, self.model_runner)pp_proxy_tensors = Noneif not self.pp_group.is_first_rank:pp_proxy_tensors = PPProxyTensors(self.pp_group.recv_tensor_dict(all_gather_group=self.get_attention_tp_group()))if self.pp_group.is_last_rank:logits_output, can_run_cuda_graph = self.model_runner.forward(forward_batch, pp_proxy_tensors=pp_proxy_tensors)if launch_done is not None:launch_done.set()if skip_sample:next_token_ids = Noneelse:next_token_ids = self.model_runner.sample( #这个方法logits_output, model_worker_batch)return logits_output, next_token_ids, can_run_cuda_graphelse:pp_proxy_tensors, can_run_cuda_graph = self.model_runner.forward(forward_batch,pp_proxy_tensors=pp_proxy_tensors,)return pp_proxy_tensors.tensors, None, can_run_cuda_graphdef sample(self,logits_output: LogitsProcessorOutput,forward_batch: ForwardBatch,) -> torch.Tensor:"""Sample and compute logprobs and update logits_output.Args:logits_output: The logits output from the model forwardforward_batch: The forward batch that generates logits_outputReturns:A list of next_token_ids"""# For duplex models with multiple output streams.if isinstance(logits_output, tuple):return torch.stack([self.sample(values, forward_batch) for values in logits_output],axis=-1,)self._preprocess_logits(logits_output, forward_batch.sampling_info)# Sample the next tokensnext_token_ids = self.sampler(logits_output,forward_batch.sampling_info,forward_batch.return_logprob,forward_batch.top_logprobs_nums,forward_batch.token_ids_logprobs,)return next_token_ids然后到python\sglang\srt\layers\sampler.py
这里面top_k_top_p_sampling_from_probs 的函数 简直是手撕sample的完美借鉴材料
class Sampler(nn.Module):def __init__(self):super().__init__()self.use_nan_detection = global_server_args_dict["enable_nan_detection"]self.tp_sync_group = get_tp_group().device_groupif global_server_args_dict["enable_dp_attention"]:self.tp_sync_group = get_attention_tp_group().device_groupdef forward(self,logits_output: LogitsProcessorOutput,sampling_info: SamplingBatchInfo,return_logprob: bool,top_logprobs_nums: List[int],token_ids_logprobs: List[List[int]],):"""Run a sampler & compute logprobs and update logits_output accordingly.Args:logits_output: The logits from the model forwardsampling_info: Metadata for samplingreturn_logprob: If set, store the output logprob information tologits_outputtop_logprobs_nums: Number of top lobprobs per sequence in a batchbatch_next_token_ids: next token IDs. If set, skip sampling and onlycompute output logprobs It is used for speculative decoding whichperforms sampling in draft workers."""logits = logits_output.next_token_logits# Apply the custom logit processors if registered in the sampling info.if sampling_info.has_custom_logit_processor:apply_custom_logit_processor(logits, sampling_info)if self.use_nan_detection and torch.any(torch.isnan(logits)):logger.warning("Detected errors during sampling! NaN in the logits.")logits = torch.where(torch.isnan(logits), torch.full_like(logits, -1e5), logits)if crash_on_warnings():raise ValueError("Detected errors during sampling! NaN in the logits.")if sampling_info.is_all_greedy:# Use torch.argmax if all requests use greedy samplingbatch_next_token_ids = torch.argmax(logits, -1)if return_logprob:logprobs = torch.nn.functional.log_softmax(logits, dim=-1)else:# Post process logitslogits.div_(sampling_info.temperatures)logits[:] = torch.softmax(logits, dim=-1)probs = logitsdel logitsif True: # Keep this redundant check to simplify some internal code syncif global_server_args_dict["sampling_backend"] == "flashinfer":if sampling_info.need_min_p_sampling:probs = top_k_renorm_prob(probs, sampling_info.top_ks)probs = top_p_renorm_prob(probs, sampling_info.top_ps)batch_next_token_ids = min_p_sampling_from_probs(probs, sampling_info.min_ps)else:batch_next_token_ids = top_k_top_p_sampling_from_probs(probs.contiguous(),sampling_info.top_ks,sampling_info.top_ps,filter_apply_order="joint",check_nan=self.use_nan_detection,)elif global_server_args_dict["sampling_backend"] == "pytorch":# A slower fallback implementation with torch native operations.batch_next_token_ids = top_k_top_p_min_p_sampling_from_probs_torch(probs,sampling_info.top_ks,sampling_info.top_ps,sampling_info.min_ps,sampling_info.need_min_p_sampling,)else:raise ValueError(f"Invalid sampling backend: {global_server_args_dict['sampling_backend']}")if return_logprob:# clamp to avoid -inflogprobs = torch.log(probs).clamp(min=torch.finfo(probs.dtype).min)# Attach logprobs to logits_output (in-place modification)if return_logprob:if any(x > 0 for x in top_logprobs_nums):(logits_output.next_token_top_logprobs_val,logits_output.next_token_top_logprobs_idx,) = get_top_logprobs(logprobs, top_logprobs_nums)if any(x is not None for x in token_ids_logprobs):(logits_output.next_token_token_ids_logprobs_val,logits_output.next_token_token_ids_logprobs_idx,) = get_token_ids_logprobs(logprobs, token_ids_logprobs)logits_output.next_token_logprobs = logprobs[torch.arange(len(batch_next_token_ids), device=sampling_info.device),batch_next_token_ids,]if SYNC_TOKEN_IDS_ACROSS_TP or sampling_info.grammars:# For performance reasons, SGLang does not sync the final token IDs across TP ranks by default.# This saves one all-reduce, but the correctness of this approach depends on the determinism of several operators:# the last all-reduce, the last lm_head matmul, and all sampling kernels.# These kernels are deterministic in most cases, but there are some rare instances where they are not deterministic.# In such cases, enable this env variable to prevent hanging due to TP ranks becoming desynchronized.# When using xgrammar, this becomes more likely so we also do the sync when grammar is used.torch.distributed.all_reduce(batch_next_token_ids,op=dist.ReduceOp.MIN,group=self.tp_sync_group,)return batch_next_token_idsScheduler 通过 process_batch_result 处理批次结果,使用 tree_cache.cache_finished_req(req) 缓存请求,并通过 check_finished 验证完成状态。对于未完成的请求,Scheduler 继续其事件循环,直到这个请求满足结束条件;对于已完成的请求,则转发到 Scheduler 的 stream_output。
@DynamicGradMode()def event_loop_normal(self):"""A normal scheduler loop."""while True:recv_reqs = self.recv_requests()self.process_input_requests(recv_reqs)batch = self.get_next_batch_to_run()self.cur_batch = batchif batch:result = self.run_batch(batch)self.process_batch_result(batch, result)else:# When the server is idle, do self-check and re-init some statesself.check_memory()self.new_token_ratio = self.init_new_token_ratioself.maybe_sleep_on_idle()self.last_batch = batch#这里
def process_batch_result(self,batch: ScheduleBatch,result: Union[GenerationBatchResult, EmbeddingBatchResult],launch_done: Optional[threading.Event] = None,):if batch.forward_mode.is_decode():self.process_batch_result_decode(batch, result, launch_done)#这里elif batch.forward_mode.is_extend():self.process_batch_result_prefill(batch, result, launch_done)#这里elif batch.forward_mode.is_idle():if self.enable_overlap:self.tp_worker.resolve_last_batch_result(launch_done)self.set_next_batch_sampling_info_done(batch)elif batch.forward_mode.is_dummy_first():self.set_next_batch_sampling_info_done(batch)if self.return_health_check_ct:# Return some signal for the health check.# This is used to prevent the health check signal being blocked by long context prefill.# However, one minor issue is that this code path does not check the status of detokenizer manager.self.return_health_check_ct -= 1self.send_to_tokenizer.send_pyobj(HealthCheckOutput())
#至于请求的安置
self.process_batch_result_decode()或者self.process_batch_result_prefill()
都有tree_cache.cache_finished_req(req) 缓存执行完的请求
之前提到的process_input_requests
def process_input_requests(self, recv_reqs: List):for recv_req in recv_reqs:# If it is a health check generation request and there are running requests, ignore it.if is_health_check_generate_req(recv_req) and (self.chunked_req is not None or not self.running_batch.is_empty()):self.return_health_check_ct += 1continueoutput = self._request_dispatcher(recv_req)#这里的输出if output is not None:if isinstance(output, RpcReqOutput):if self.recv_from_rpc is not None:self.recv_from_rpc.send_pyobj(output)else:self.send_to_tokenizer.send_pyobj(output)有_request_dispatcher函数
self._request_dispatcher = TypeBasedDispatcher([(TokenizedGenerateReqInput, self.handle_generate_request),(TokenizedEmbeddingReqInput, self.handle_embedding_request),]handle_generate_request处理:
对于未完成的请求,Scheduler 继续其事件循环,直到这个请求满足结束条件;
对于已完成的请求,则转发到 Scheduler 的 stream_output。
def handle_generate_request(self,recv_req: TokenizedGenerateReqInput,):# Create a new requestif (recv_req.session_params is Noneor recv_req.session_params.id is Noneor recv_req.session_params.id not in self.sessions):if recv_req.input_embeds is not None:# Generate fake input_ids based on the length of input_embedsseq_length = len(recv_req.input_embeds)fake_input_ids = [1] * seq_lengthrecv_req.input_ids = fake_input_idsif recv_req.bootstrap_port is None:# Use default bootstrap portrecv_req.bootstrap_port = self.server_args.disaggregation_bootstrap_portreq = Req(recv_req.rid,recv_req.input_text,recv_req.input_ids,recv_req.sampling_params,return_logprob=recv_req.return_logprob,top_logprobs_num=recv_req.top_logprobs_num,token_ids_logprob=recv_req.token_ids_logprob,stream=recv_req.stream,lora_path=recv_req.lora_path,input_embeds=recv_req.input_embeds,custom_logit_processor=recv_req.custom_logit_processor,return_hidden_states=recv_req.return_hidden_states,eos_token_ids=self.model_config.hf_eos_token_id,bootstrap_host=recv_req.bootstrap_host,bootstrap_port=recv_req.bootstrap_port,bootstrap_room=recv_req.bootstrap_room,data_parallel_rank=recv_req.data_parallel_rank,)req.tokenizer = self.tokenizerif self.disaggregation_mode != DisaggregationMode.NULL:# Invalid request for disaggregated modeif recv_req.bootstrap_room is None:error_msg = (f"Invalid request: Disaggregated request received without "f"boostrap room id. {req.rid=}")logger.error(error_msg)prepare_abort(req, error_msg)self.stream_output([req], req.return_logprob)returnif (recv_req.session_params is not Noneand recv_req.session_params.id is not None):req.set_finish_with_abort(f"Invalid request: session id {recv_req.session_params.id} does not exist")self._add_request_to_queue(req)returnelse:# Create a new request from a previous sessionsession = self.sessions[recv_req.session_params.id]req = session.create_req(recv_req, self.tokenizer)if isinstance(req.finished_reason, FINISH_ABORT):self._add_request_to_queue(req)return- 在 stream_output 函数中,Scheduler 处理输出,将其包装成 BatchTokenIDOut,并发送给 DetokenizerManager。
python\sglang\srt\managers\scheduler_output_processor_mixin.py
因为class scheduler(SchedulerOutputProcessorMixin):
def stream_output(self: Scheduler,reqs: List[Req],return_logprob: bool,skip_req: Optional[Req] = None,):"""Stream the output to detokenizer."""if self.is_generation:self.stream_output_generation(reqs, return_logprob, skip_req)else: # embedding or reward modelself.stream_output_embedding(reqs)def stream_output_generation(self: Scheduler,reqs: List[Req],return_logprob: bool,skip_req: Optional[Req] = None,):rids = []finished_reasons: List[BaseFinishReason] = []decoded_texts = []decode_ids_list = []read_offsets = []output_ids = []skip_special_tokens = []spaces_between_special_tokens = []no_stop_trim = []prompt_tokens = []completion_tokens = []cached_tokens = []spec_verify_ct = []output_hidden_states = Noneif return_logprob:input_token_logprobs_val = []input_token_logprobs_idx = []output_token_logprobs_val = []output_token_logprobs_idx = []input_top_logprobs_val = []input_top_logprobs_idx = []output_top_logprobs_val = []output_top_logprobs_idx = []input_token_ids_logprobs_val = []input_token_ids_logprobs_idx = []output_token_ids_logprobs_val = []output_token_ids_logprobs_idx = []else:input_token_logprobs_val = input_token_logprobs_idx = (output_token_logprobs_val) = output_token_logprobs_idx = input_top_logprobs_val = (input_top_logprobs_idx) = output_top_logprobs_val = output_top_logprobs_idx = (input_token_ids_logprobs_val) = input_token_ids_logprobs_idx = output_token_ids_logprobs_val = (output_token_ids_logprobs_idx) = Nonefor req in reqs:if req is skip_req:continue# Multimodal partial stream chunks break the detokenizer, so drop aborted requests here.if self.model_config.is_multimodal_gen and req.to_abort:continueif req.finished():if req.finished_output:# With the overlap schedule, a request will try to output twice and hit this line twice# because of the one additional delayed token. This "continue" prevented the dummy output.continuereq.finished_output = Trueshould_output = Trueelse:if req.stream:stream_interval = (req.sampling_params.stream_interval or self.stream_interval)should_output = (len(req.output_ids) % stream_interval == 1if not self.model_config.is_multimodal_genand stream_interval > 1else len(req.output_ids) % stream_interval == 0)else:should_output = (len(req.output_ids) % DEFAULT_FORCE_STREAM_INTERVAL == 0if not self.model_config.is_multimodal_genelse False)if should_output:send_token_offset = req.send_token_offsetsend_output_token_logprobs_offset = (req.send_output_token_logprobs_offset)rids.append(req.rid)finished_reasons.append(req.finished_reason.to_json() if req.finished_reason else None)decoded_texts.append(req.decoded_text)decode_ids, read_offset = req.init_incremental_detokenize()if self.model_config.is_multimodal_gen:decode_ids_list.append(decode_ids)else:decode_ids_list.append(decode_ids[req.send_decode_id_offset :])req.send_decode_id_offset = len(decode_ids)read_offsets.append(read_offset)if self.skip_tokenizer_init:output_ids.append(req.output_ids[send_token_offset:])req.send_token_offset = len(req.output_ids)skip_special_tokens.append(req.sampling_params.skip_special_tokens)spaces_between_special_tokens.append(req.sampling_params.spaces_between_special_tokens)no_stop_trim.append(req.sampling_params.no_stop_trim)prompt_tokens.append(len(req.origin_input_ids))completion_tokens.append(len(req.output_ids))cached_tokens.append(req.cached_tokens)if not self.spec_algorithm.is_none():spec_verify_ct.append(req.spec_verify_ct)if return_logprob:if (req.return_logproband not req.input_logprob_sent# Decode server does not send input logprobsand self.disaggregation_mode != DisaggregationMode.DECODE):input_token_logprobs_val.append(req.input_token_logprobs_val)input_token_logprobs_idx.append(req.input_token_logprobs_idx)input_top_logprobs_val.append(req.input_top_logprobs_val)input_top_logprobs_idx.append(req.input_top_logprobs_idx)input_token_ids_logprobs_val.append(req.input_token_ids_logprobs_val)input_token_ids_logprobs_idx.append(req.input_token_ids_logprobs_idx)req.input_logprob_sent = Trueelse:input_token_logprobs_val.append([])input_token_logprobs_idx.append([])input_top_logprobs_val.append([])input_top_logprobs_idx.append([])input_token_ids_logprobs_val.append([])input_token_ids_logprobs_idx.append([])if req.return_logprob:output_token_logprobs_val.append(req.output_token_logprobs_val[send_output_token_logprobs_offset:])output_token_logprobs_idx.append(req.output_token_logprobs_idx[send_output_token_logprobs_offset:])output_top_logprobs_val.append(req.output_top_logprobs_val[send_output_token_logprobs_offset:])output_top_logprobs_idx.append(req.output_top_logprobs_idx[send_output_token_logprobs_offset:])output_token_ids_logprobs_val.append(req.output_token_ids_logprobs_val[send_output_token_logprobs_offset:])output_token_ids_logprobs_idx.append(req.output_token_ids_logprobs_idx[send_output_token_logprobs_offset:])req.send_output_token_logprobs_offset = len(req.output_token_logprobs_val)else:output_token_logprobs_val.append([])output_token_logprobs_idx.append([])output_top_logprobs_val.append([])output_top_logprobs_idx.append([])output_token_ids_logprobs_val.append([])output_token_ids_logprobs_idx.append([])if req.return_hidden_states:if output_hidden_states is None:output_hidden_states = []output_hidden_states.append(req.hidden_states)if (req.finished()and self.tp_rank == 0and self.server_args.enable_request_time_stats_logging):req.log_time_stats()# Send to detokenizerif rids:if self.model_config.is_multimodal_gen:returnself.send_to_detokenizer.send_pyobj( #包装成 BatchTokenIDOut送到DetokenizerManagerBatchTokenIDOut(rids,finished_reasons,decoded_texts,decode_ids_list,read_offsets,output_ids,skip_special_tokens,spaces_between_special_tokens,no_stop_trim,prompt_tokens,completion_tokens,cached_tokens,spec_verify_ct,input_token_logprobs_val,input_token_logprobs_idx,output_token_logprobs_val,output_token_logprobs_idx,input_top_logprobs_val,input_top_logprobs_idx,output_top_logprobs_val,output_top_logprobs_idx,input_token_ids_logprobs_val,input_token_ids_logprobs_idx,output_token_ids_logprobs_val,output_token_ids_logprobs_idx,output_hidden_states,))6.DetokenizerManager 在其事件循环中接收 BatchTokenIDOut,处理后生成 BatchStrOut 并返回给 TokenizerManager。
detokenizermanager中event_loop一直进行,output = self._request_dispatcher(recv_obj)中_request_dispatcher设置(BatchTokenIDOut, self.handle_batch_token_id_out), 然后到函数handler_batch_token_id_out处理生成BatchStrOut
python\sglang\srt\managers\detokenizer_manager.py
class DetokenizerManager:"""DetokenizerManager is a process that detokenizes the token ids."""def __init__(self,server_args: ServerArgs,port_args: PortArgs,):# Init inter-process communicationcontext = zmq.Context(2)self.recv_from_scheduler = get_zmq_socket(context, zmq.PULL, port_args.detokenizer_ipc_name, True)self.send_to_tokenizer = get_zmq_socket(context, zmq.PUSH, port_args.tokenizer_ipc_name, False)if server_args.skip_tokenizer_init:self.tokenizer = Noneelse:self.tokenizer = get_tokenizer(server_args.tokenizer_path,tokenizer_mode=server_args.tokenizer_mode,trust_remote_code=server_args.trust_remote_code,revision=server_args.revision,)self.decode_status = LimitedCapacityDict(capacity=DETOKENIZER_MAX_STATES)self.is_dummy = server_args.load_format == "dummy"self._request_dispatcher = TypeBasedDispatcher([(BatchEmbeddingOut, self.handle_batch_embedding_out),(BatchTokenIDOut, self.handle_batch_token_id_out),(BatchMultimodalDecodeReq, self.handle_multimodal_decode_req),])def event_loop(self):"""The event loop that handles requests"""while True:recv_obj = self.recv_from_scheduler.recv_pyobj()output = self._request_dispatcher(recv_obj)self.send_to_tokenizer.send_pyobj(output)def handle_batch_token_id_out(self, recv_obj: BatchTokenIDOut):bs = len(recv_obj.rids)# Initialize decode statusread_ids, surr_ids = [], []for i in range(bs):rid = recv_obj.rids[i]if rid not in self.decode_status:s = DecodeStatus(decoded_text=recv_obj.decoded_texts[i],decode_ids=recv_obj.decode_ids[i],surr_offset=0,read_offset=recv_obj.read_offsets[i],)self.decode_status[rid] = selse:s = self.decode_status[rid]s.decode_ids.extend(recv_obj.decode_ids[i])read_ids.append(self.trim_matched_stop(s.decode_ids[s.surr_offset :],recv_obj.finished_reasons[i],recv_obj.no_stop_trim[i],))surr_ids.append(s.decode_ids[s.surr_offset : s.read_offset])# TODO(lmzheng): handle skip_special_tokens/spaces_between_special_tokens per requestsurr_texts = self.tokenizer.batch_decode(surr_ids,skip_special_tokens=recv_obj.skip_special_tokens[0],spaces_between_special_tokens=recv_obj.spaces_between_special_tokens[0],)read_texts = self.tokenizer.batch_decode(read_ids,skip_special_tokens=recv_obj.skip_special_tokens[0],spaces_between_special_tokens=recv_obj.spaces_between_special_tokens[0],)# Incremental decodingoutput_strs = []for i in range(bs):try:s = self.decode_status[recv_obj.rids[i]]except KeyError:raise RuntimeError(f"Decode status not found for request {recv_obj.rids[i]}. ""It may be due to the request being evicted from the decode status due to memory pressure. ""Please increase the maximum number of requests by setting ""the SGLANG_DETOKENIZER_MAX_STATES environment variable to a bigger value than the default value. "f"The current value is {DETOKENIZER_MAX_STATES}. ""For more details, see: https://github.com/sgl-project/sglang/issues/2812")new_text = read_texts[i][len(surr_texts[i]) :]if recv_obj.finished_reasons[i] is None:# Streaming chunk: update the decode statusif len(new_text) > 0 and not new_text.endswith("�"):s.decoded_text = s.decoded_text + new_texts.surr_offset = s.read_offsets.read_offset = len(s.decode_ids)new_text = ""else:new_text = find_printable_text(new_text)output_str = self.trim_matched_stop(s.decoded_text + new_text,recv_obj.finished_reasons[i],recv_obj.no_stop_trim[i],)# Incrementally send text.incremental_output = output_str[s.sent_offset :]s.sent_offset = len(output_str)output_strs.append(incremental_output)return BatchStrOut(rids=recv_obj.rids,finished_reasons=recv_obj.finished_reasons,output_strs=output_strs,output_ids=None,prompt_tokens=recv_obj.prompt_tokens,completion_tokens=recv_obj.completion_tokens,cached_tokens=recv_obj.cached_tokens,spec_verify_ct=recv_obj.spec_verify_ct,input_token_logprobs_val=recv_obj.input_token_logprobs_val,input_token_logprobs_idx=recv_obj.input_token_logprobs_idx,output_token_logprobs_val=recv_obj.output_token_logprobs_val,output_token_logprobs_idx=recv_obj.output_token_logprobs_idx,input_top_logprobs_val=recv_obj.input_top_logprobs_val,input_top_logprobs_idx=recv_obj.input_top_logprobs_idx,output_top_logprobs_val=recv_obj.output_top_logprobs_val,output_top_logprobs_idx=recv_obj.output_top_logprobs_idx,input_token_ids_logprobs_val=recv_obj.input_token_ids_logprobs_val,input_token_ids_logprobs_idx=recv_obj.input_token_ids_logprobs_idx,output_token_ids_logprobs_val=recv_obj.output_token_ids_logprobs_val,output_token_ids_logprobs_idx=recv_obj.output_token_ids_logprobs_idx,output_hidden_states=recv_obj.output_hidden_states,)7.TokenizerManager 在其事件循环中接收结果,通过 handle_loop 处理并更新内部状态,然后将响应返回给Server 。
回到4这一步 在TokenizerManager 的函数generate_request
async def generate_request(self,obj: Union[GenerateReqInput, EmbeddingReqInput],request: Optional[fastapi.Request] = None,):created_time = time.time()async with self._cond:await self._cond.wait_for(lambda: not self._updating)self.auto_create_handle_loop() #通过 handle_loop 处理并更新内部状态obj.normalize_batch_and_arguments()async with self.model_update_lock.reader_lock:if obj.is_single:tokenized_obj = await self._tokenize_one_request(obj)state = self._send_one_request(obj, tokenized_obj, created_time)async for response in self._wait_one_response(obj, state, request):yield response#在其事件循环中接收结果else:async for response in self._handle_batch_request(obj, request, created_time):yield response #在其事件循环中接收结果
def auto_create_handle_loop(self):if self.no_create_loop:returnself.no_create_loop = Trueloop = asyncio.get_event_loop()self.asyncio_tasks.add(loop.create_task(print_exception_wrapper(self.handle_loop))) #反复跑handle_loopself.event_loop = loop# We cannot add signal handler when the tokenizer manager is not in# the main thread due to the CPython limitation.if threading.current_thread() is threading.main_thread():signal_handler = SignalHandler(self)loop.add_signal_handler(signal.SIGTERM, signal_handler.sigterm_handler)# Update the signal handler for the process. It overrides the sigquit handler in the launch phase.loop.add_signal_handler(signal.SIGQUIT, signal_handler.running_phase_sigquit_handler)else:logger.warning("Signal handler is not added because the tokenizer manager is ""not in the main thread. This disables graceful shutdown of the ""tokenizer manager when SIGTERM is received.")self.asyncio_tasks.add(loop.create_task(print_exception_wrapper(self.sigterm_watchdog)))#一直开着接收返回的结果信号
async def handle_loop(self):"""The event loop that handles requests"""while True:recv_obj = await self.recv_from_detokenizer.recv_pyobj()self._result_dispatcher(recv_obj)self.last_receive_tstamp = time.time()对应3 继续往下返回
python\sglang\srt\entrypoints\openai\serving_base.py
看class OpenAIServingBase(ABC)类有个函数handle_request返回
8.FastAPI Server 最后封装完成的响应并将其返回给用户。
对应2 return await raw_request.app.state.openai_serving_completion.handle_request(
request, raw_request
)
##### OpenAI-compatible API endpoints #####
@app.post("/v1/completions", dependencies=[Depends(validate_json_request)])
async def openai_v1_completions(request: CompletionRequest, raw_request: Request):"""OpenAI-compatible text completion endpoint."""return await raw_request.app.state.openai_serving_completion.handle_request(request, raw_request)
@app.post("/v1/chat/completions", dependencies=[Depends(validate_json_request)])
async def openai_v1_chat_completions(request: ChatCompletionRequest, raw_request: Request
):"""OpenAI-compatible chat completion endpoint."""return await raw_request.app.state.openai_serving_chat.handle_request(request, raw_request)