强化学习算法笔记【AMP】
文章目录
- AMP简介
- 算法解析
- 主要参数
- 计算优势函数
- 算法更新
- 代码实现
- 参考资料
AMP简介
AMP是一种无模型、基于随机政策的政策梯度算法(通过GAIL和PPO的组合进行训练),用于基于物理的动画的反向学习。它使角色能够从大型非结构化数据集中模仿各种行为,而无需运动规划器或其他剪辑选择机制。
算法解析
主要参数


计算优势函数

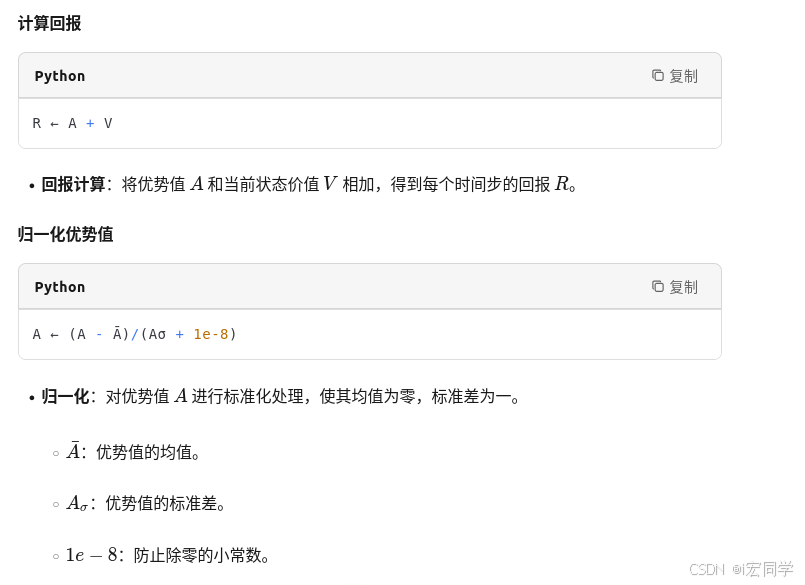
伪代码中的公式用于计算每个时间步的优势值(Advantage),这是强化学习中用于指导策略更新的关键因素。
反向迭代:伪代码从最后一行(时间步)开始向前计算,这是因为在强化学习中,后续时间步的值对当前时间步的值有直接影响,反向计算可以更高效地利用这些信息。

算法更新

(1)更新参考运动数据集
- 操作:收集一批大小为 amp_batch_size 的参考运动数据,并将其添加到数据集 M 中。
- 目的:确保数据集 M 包含最新的参考运动数据,用于后续训练判别器。
(2)计算组合奖励

- task_reward_weight:任务奖励的权重。
- style_reward_weight:风格奖励的权重。
- discriminator_reward_scale:对风格奖励进行缩放的系数。
(3)计算回报和优势值

(4)从经验重放区中采样小批量数据

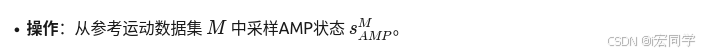

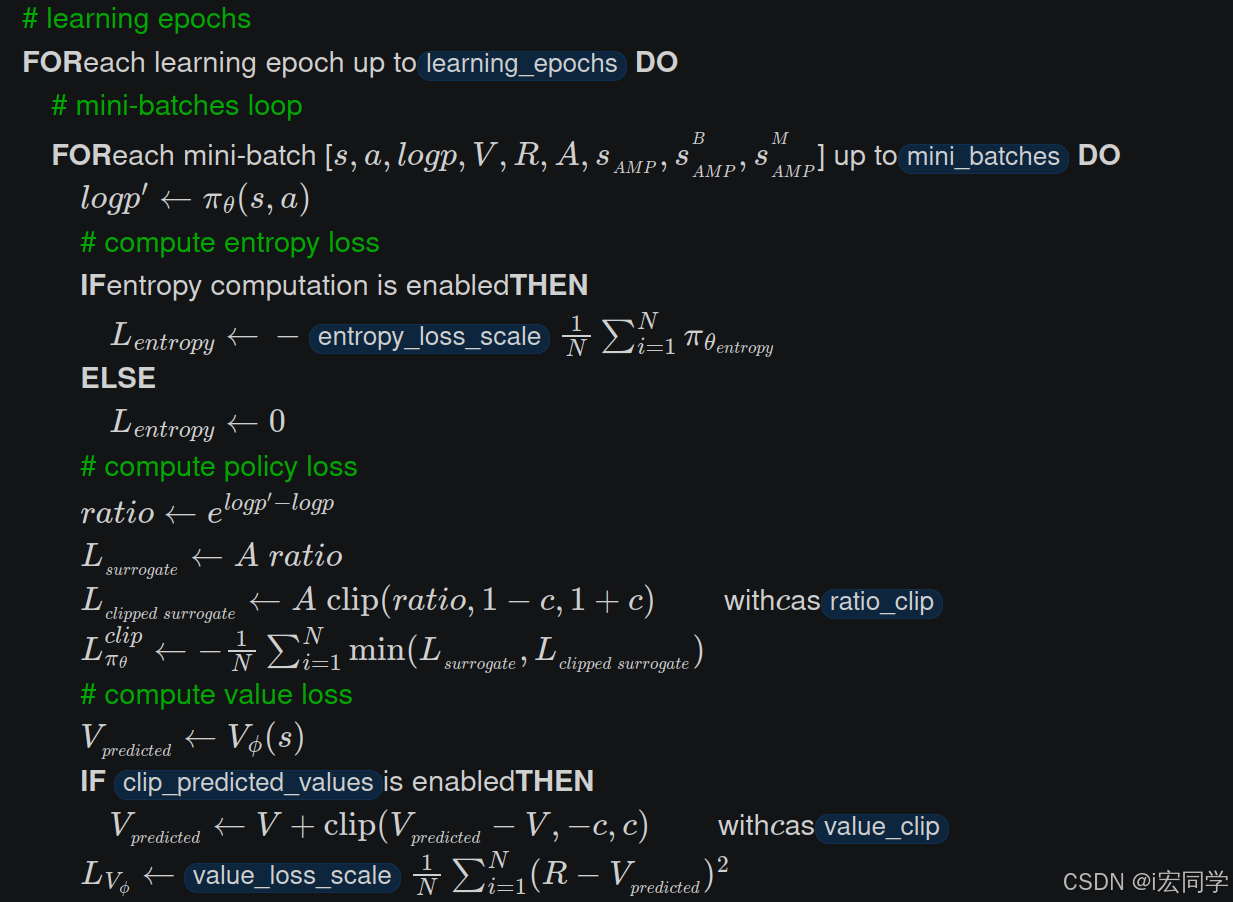
(1)计算新的动作对数概率

(2)计算熵损失

(3)计算策略损失

(4)计算价值损失

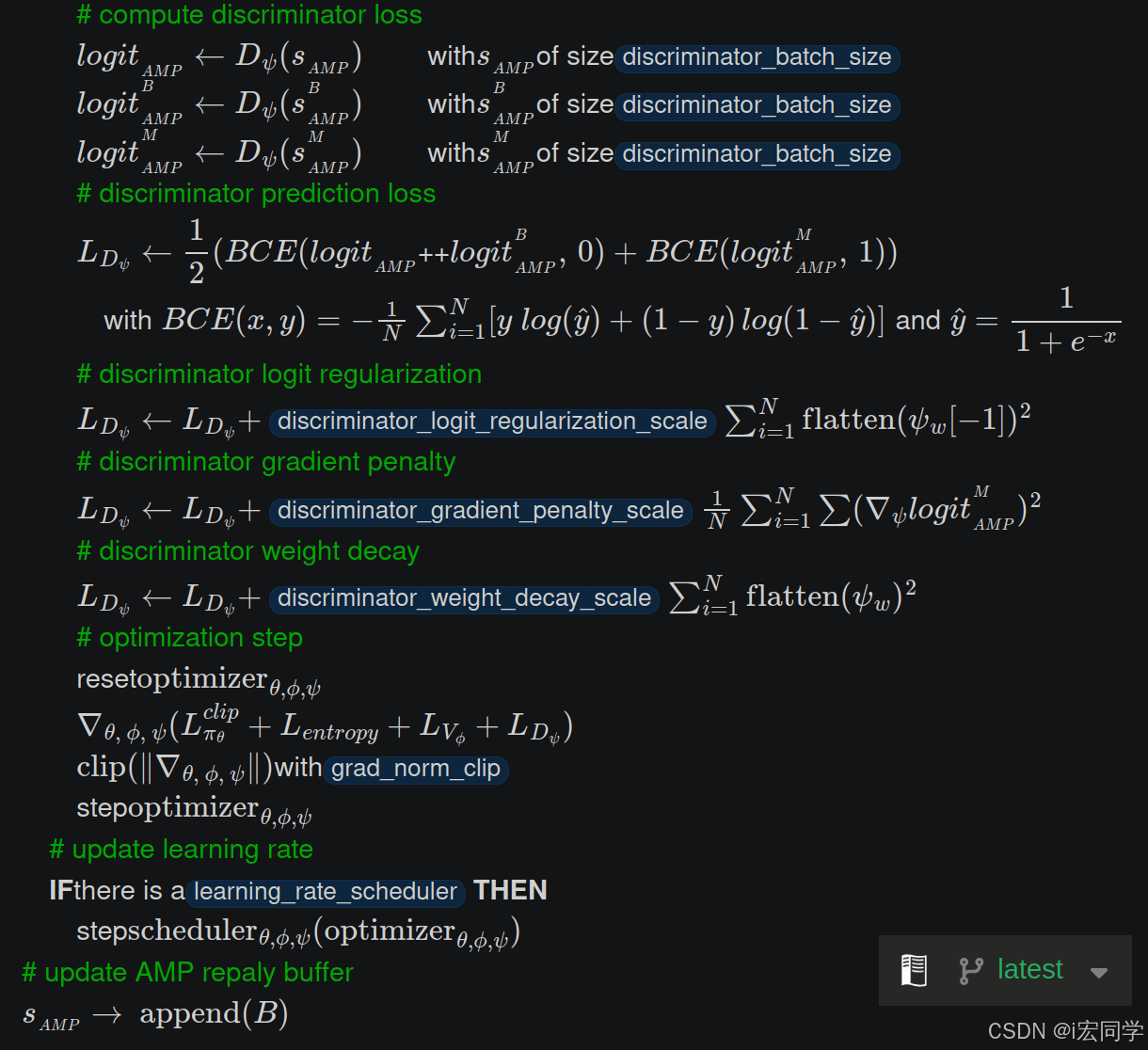
(1)计算判别器的预测损失
- logit_AMP:判别器对当前AMP状态S_AMP的预测




(2)判别器Logit正则化


(3)判别器梯度惩罚

(4)判别器权重衰减

(5)step

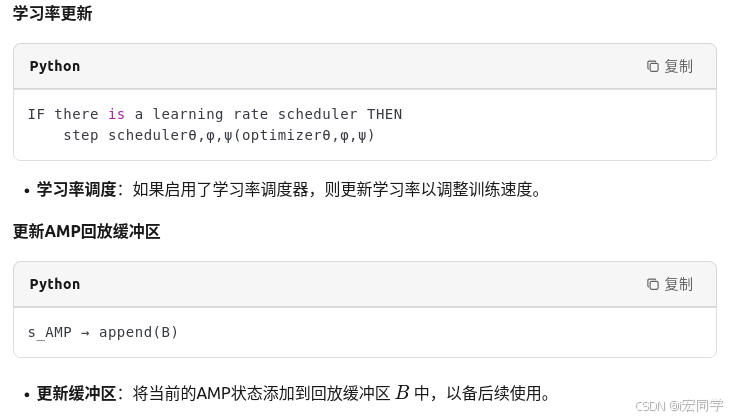
(6)学习率更新和更新AMP回放区
代码实现
# import the agent and its default configuration
from skrl.agents.torch.amp import AMP, AMP_DEFAULT_CONFIG# instantiate the agent's models
models = {}
models["policy"] = ...
models["value"] = ... # only required during training
models["discriminator"] = ... # only required during training# adjust some configuration if necessary
cfg_agent = AMP_DEFAULT_CONFIG.copy()
cfg_agent["<KEY>"] = ...# instantiate the agent
# (assuming a defined environment <env> and memory <memory>)
# (assuming defined memories for motion <motion_dataset> and <reply_buffer>)
# (assuming defined methods to collect motion <collect_reference_motions> and <collect_observation>)
agent = AMP(models=models,memory=memory, # only required during trainingcfg=cfg_agent,observation_space=env.observation_space,action_space=env.action_space,device=env.device,amp_observation_space=env.amp_observation_space,motion_dataset=motion_dataset,reply_buffer=reply_buffer,collect_reference_motions=collect_reference_motions,collect_observation=collect_observation)
AMP_DEFAULT_CONFIG = {"rollouts": 16, # number of rollouts before updating"learning_epochs": 6, # number of learning epochs during each update"mini_batches": 2, # number of mini batches during each learning epoch"discount_factor": 0.99, # discount factor (gamma)"lambda": 0.95, # TD(lambda) coefficient (lam) for computing returns and advantages"learning_rate": 5e-5, # learning rate"learning_rate_scheduler": None, # learning rate scheduler class (see torch.optim.lr_scheduler)"learning_rate_scheduler_kwargs": {}, # learning rate scheduler's kwargs (e.g. {"step_size": 1e-3})"state_preprocessor": None, # state preprocessor class (see skrl.resources.preprocessors)"state_preprocessor_kwargs": {}, # state preprocessor's kwargs (e.g. {"size": env.observation_space})"value_preprocessor": None, # value preprocessor class (see skrl.resources.preprocessors)"value_preprocessor_kwargs": {}, # value preprocessor's kwargs (e.g. {"size": 1})"amp_state_preprocessor": None, # AMP state preprocessor class (see skrl.resources.preprocessors)"amp_state_preprocessor_kwargs": {}, # AMP state preprocessor's kwargs (e.g. {"size": env.amp_observation_space})"random_timesteps": 0, # random exploration steps"learning_starts": 0, # learning starts after this many steps"grad_norm_clip": 0.0, # clipping coefficient for the norm of the gradients"ratio_clip": 0.2, # clipping coefficient for computing the clipped surrogate objective"value_clip": 0.2, # clipping coefficient for computing the value loss (if clip_predicted_values is True)"clip_predicted_values": False, # clip predicted values during value loss computation"entropy_loss_scale": 0.0, # entropy loss scaling factor"value_loss_scale": 2.5, # value loss scaling factor"discriminator_loss_scale": 5.0, # discriminator loss scaling factor"amp_batch_size": 512, # batch size for updating the reference motion dataset"task_reward_weight": 0.0, # task-reward weight (wG)"style_reward_weight": 1.0, # style-reward weight (wS)"discriminator_batch_size": 0, # batch size for computing the discriminator loss (all samples if 0)"discriminator_reward_scale": 2, # discriminator reward scaling factor"discriminator_logit_regularization_scale": 0.05, # logit regularization scale factor for the discriminator loss"discriminator_gradient_penalty_scale": 5, # gradient penalty scaling factor for the discriminator loss"discriminator_weight_decay_scale": 0.0001, # weight decay scaling factor for the discriminator loss"rewards_shaper": None, # rewards shaping function: Callable(reward, timestep, timesteps) -> reward"time_limit_bootstrap": False, # bootstrap at timeout termination (episode truncation)"mixed_precision": False, # enable automatic mixed precision for higher performance"experiment": {"directory": "", # experiment's parent directory"experiment_name": "", # experiment name"write_interval": "auto", # TensorBoard writing interval (timesteps)"checkpoint_interval": "auto", # interval for checkpoints (timesteps)"store_separately": False, # whether to store checkpoints separately"wandb": False, # whether to use Weights & Biases"wandb_kwargs": {} # wandb kwargs (see https://docs.wandb.ai/ref/python/init)}
}
参考资料
https://skrl.readthedocs.io/en/latest/api/agents/amp.html